一、分库分表核心认知
1.1 分库分表的必要性
MySQL 作为单机关系型数据库,不适合存储 TB 级海量数据 ,且单机并发能力有限;但电商交易类系统(订单、支付)必须使用 MySQL,因为其能提供金融级事务保证 ,而分布式事务方案目前仍不完善。分库分表是解决 MySQL海量数据存储 和高并发访问的最终方案,核心是将大表 / 大库拆分为多个小表 / 小库,降低单库单表的数据量和访问压力。
1.2 分库 vs 分表的区别与适用场景
| 维度 | 分表 | 分库 |
|---|---|---|
| 拆分对象 | 单数据库实例内的多张表 | 多个独立的 MySQL 数据库实例 |
| 解决问题 | 数据量过大导致的查询慢 | 并发请求量过高的问题 |
| 核心原理 | 减少单表数据量,优化 B + 树 | 分散并发请求到多个实例 |
| 适用场景 | 只读查询可缓存,事务内 CRUD 慢 | 单实例数据库连接池打满、QPS 过高 |
核心原则 :能不拆就不拆,拆分越分散,系统维护成本、故障概率越高,一般业务需同时做分库分表,根据预估并发量和数据量计算拆分数量。
1.3 分库分表的实现方式对比
分库分表在代码层的实现有 3 种方式,面试高频考点为优缺点及选型 ,核心推荐组件方式:
| 实现方式 | 具体做法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 纯手工方式 | 修改 DAO 层,定义多数据源,硬编码指定数据源 | 实现简单,无额外依赖 | 代码侵入性极强,维护成本高,扩展性差 | 超简单微服务(仅少量 SQL)、无合适组件的编程语言 |
| 组件方式 | 应用内集成 Sharding-JDBC 等组件,代理数据库请求并自动路由 | 代码侵入性低,性能 / 稳定性兼顾,支持读写分离 + 分库分表 | 需引入组件并做少量配置 | 绝大多数 Java 电商 / 分布式系统(推荐) |
| 代理方式 | 应用与数据库间部署 Atlas/Sharding-Proxy 代理,代理伪装为单节点 MySQL | 对应用完全透明,无需修改代码 | 增加调用链路,性能损失,代理节点易成瓶颈 / 故障点 | 多语言技术栈、无需应用改造的老旧系统 |
二、订单系统分库分表规划
以电商订单系统 为实战案例,讲解分库分表的核心规划步骤,是 Java 开发面试项目实战高频考点。
2.1 数据量预估与拆分数量计算
核心前提
MySQL 单表数据量不宜超过 2000W(保证 B + 树高度,维持查询性能),单条订单数据约 1KB。
订单系统数据预估
- 月订单量:2000W,年订单量:2.4 亿
- 单订单平均商品数:10 个,年订单详情数:24 亿
拆分数量决策
- 仅按订单表计算:2.4 亿 / 2000W = 12 张,取 2 的幂为16 张;
- 考虑订单详情表:24 亿 / 2000W = 120 张,取 2 的幂为128 张;
- 实际最终决策:订单表 + 订单详情表均拆分为 32 张 (订单详情表单表数据量达 8000W)。
- 决策原因:兼顾表关联性能 (订单表与详情表一一关联,表数量一致可避免跨表关联)和维护成本(128 张表维护成本过高)。
2.2 分片键选择
2.2.1 分片键定义
分片键(Sharding Key)是分库分表的拆分依据列 ,选择原则:与业务访问方式高度匹配 ,避免出现全表扫描 / 全分片查询(性能极差)。
2.2.2 订单系统分片键的问题与解决
问题 1:单一分片键的缺陷
- 选订单 ID:按用户 ID 查询「我的订单」时,无法定位分片,需全分片查询;
- 选用户 ID:按订单 ID 查询时,无法定位分片,需全分片查询。
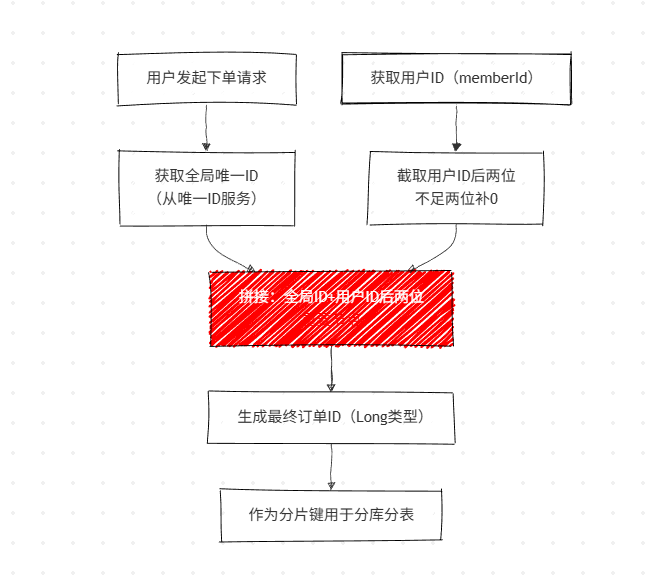
解决方案:订单 ID 融合用户 ID
生成订单 ID 时,将用户 ID 的后两位拼接至全局唯一订单 ID 后 ,使订单 ID 同时包含用户 ID 特征 ,既支持按订单 ID 定位分片,也支持按用户 ID 定位分片。核心代码实现:
/**
* 生成订单ID:全局唯一ID + 用户ID后两位
* @param memberId 用户ID
* @return 最终订单ID
*/
public Long generateOrderId(Long memberId) {
// 从唯一ID服务获取全局唯一订单ID
String leafOrderId = unqidFeignApi.getSegmentId(OrderConstant.LEAF_ORDER_ID_KEY);
String strMemberId = memberId.toString();
// 截取用户ID后两位,不足两位补0
String orderIdTail = memberId < 10 ? "0" + strMemberId : strMemberId.substring(strMemberId.length() - 2);
Log.debug("生成订单的orderId,组成元素为:{},{}", leafOrderId, orderIdTail);
// 拼接并转换为Long
return Long.valueOf(leafOrderId + orderIdTail);
}问题 2:多维度查询的解决
订单系统除了用户 ID / 订单 ID 查询 ,还有商家按店铺 ID 查询、报表统计 等场景,分库分表后无法直接支持。解决方案 :数据异构
- 构建以店铺 ID 为分片键的只读订单库,专供商家查询;
- 将订单数据同步到 HDFS 等分布式存储,通过大数据技术生成报表;
- 核心思路:分库分表库负责交易写操作,异构库负责多维度读操作,读写分离。
2.3 分片算法选择
订单系统选用哈希分片(取模算法),是分布式系统中最常用的分片算法,面试需掌握其原理与实现。
核心原理
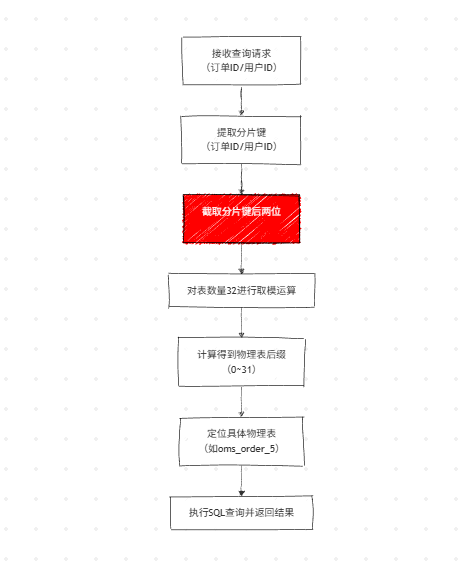
对分片键(订单 ID / 用户 ID)的后两位 进行表数量(32)取模,计算得到具体的物理表后缀,定位分片。
核心代码片段
// 截取订单号/客户ID的后两位 → 转int → 对表数量取模 → 定位物理表
.map(id -> id.substring(id.length()-2))
.distinct()
.map(Integer::new)
.map(idSuffix -> idSuffix % availableTargetNames.size())分片算法对比
| 分片算法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 哈希取模 | 分片键哈希后对分片数取模 | 数据分布均匀,查询速度快 | 扩容时数据迁移量大 | 订单 / 用户等无规律数据 |
| 范围分片 | 按分片键范围拆分(如时间 / ID) | 扩容简单,适合排序查询 | 数据易倾斜 | 日志 / 流水等按时间增长的数据 |
| 查表法 | 维护分片映射表,按表查询 | 灵活性高 | 映射表成瓶颈,维护成本高 | 定制化业务场景 |
三、订单系统分库分表具体实现
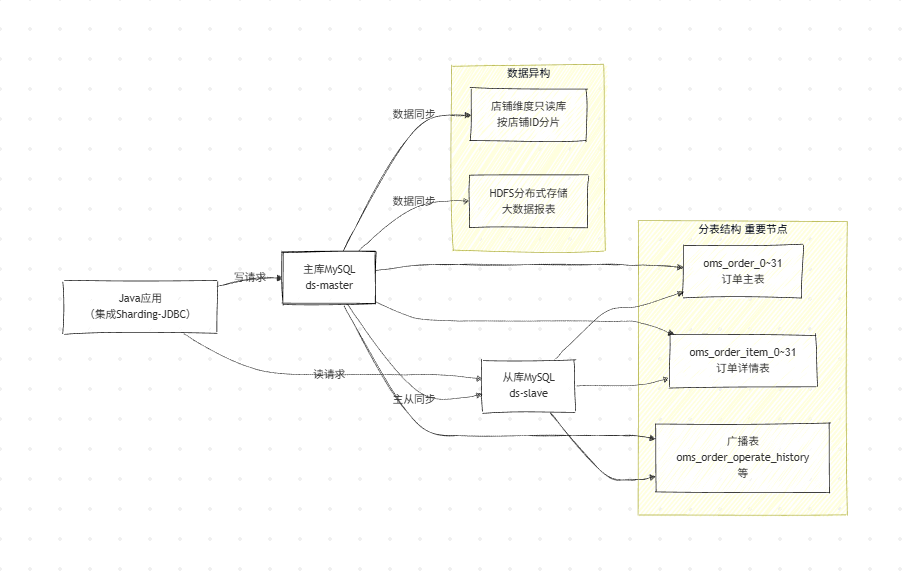
订单系统选用Sharding-JDBC 实现分库分表 + 读写分离,是 Java 开发面试技术选型 + 配置高频考点,以下为核心配置与代码实现。
3.1 核心配置
包含数据源配置、分库分表配置、读写分离配置,关键配置做注释说明:
# 分库分表核心配置(ShardingSphere)
shardingsphere:
# 数据源配置:主库+从库
datasource:
names: ds-master,ds-slave
# 主库数据源
ds-master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.65.223:3306/tl_mall_order?serverTimezone=UTC&useSSL=false&useUnicode=true
username: tlmall
password: tlmall123
initialSize: 5
minIdle: 10
maxActive: 30
validationQuery: SELECT 1 FROM DUAL
# 从库数据源
ds-slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.65.137:3306/tl_mall_order?serverTimezone=UTC&useSSL=false&useUnicode=true
username: tlmall
password: tlmall123
initialSize: 5
minIdle: 10
maxActive: 30
validationQuery: SELECT 1 FROM DUAL
# 分库分表配置
sharding:
default-data-source-name: ds-master # 默认数据源
default-database-strategy: none # 暂不分库,仅分表
tables:
# 订单主表:oms_order_0~31
oms_order:
actual-data-nodes: ds_ms.oms_order_$->{0..31} # 物理表节点
table-strategy:
complex: # 复合分片键(id+member_id)
sharding-columns: id,member_id # 分片键
algorithm-class-name: com.tuling.tulingmall.ordercurr.sharding.OmsOrderShardingAlgorithm # 自定义分片算法
# 订单详情表:oms_order_item_0~31
oms_order_item:
actual-data-nodes: ds_ms.oms_order_item_$->{0..31}
table-strategy:
complex:
sharding-columns: order_id # 分片键(关联订单主表ID)
algorithm-class-name: com.tuling.tulingmall.ordercurr.sharding.OmsOrderItemShardingAlgorithm # 自定义分片算法
binding-tables: oms_order,oms_order_item # 绑定表(避免跨表关联)
broadcast-tables: oms_order_operate_history,oms_company_address # 广播表(全部分片同步,数据量小)
# 读写分离配置
master-slave-rules:
ds_ms: # 主从数据源逻辑名
master-data-source-name: ds-master # 主库
slave-data-source-names: [ds-slave] # 从库(支持多个)
load-balance-algorithm-type: ROUND_ROBIN # 负载均衡算法:轮询
# 显示SQL解析结果(调试用)
props:
sql:
show: true3.2 核心分片算法实现
自定义两个分片算法类:OmsOrderShardingAlgorithm(订单主表)、OmsOrderItemShardingAlgorithm(订单详情表),核心逻辑一致,以下为订单主表实现核心代码:
/**
* 订单主表自定义分片算法:复合分片键(id+member_id),取后两位取模32
*/
public class OmsOrderShardingAlgorithm implements ComplexKeysShardingAlgorithm<String> {
// 分片键常量
private static final String COLUMN_ORDER_SHARDING_KEY = "id";
private static final String COLUMN_CUSTOMER_SHARDING_KEY = "member_id";
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<String> complexKeysShardingValue) {
// 1. 获取分片键值:订单ID、用户ID
Collection<String> orderIds = complexKeysShardingValue.getColumnNameAndShardingValuesMap().getOrDefault(COLUMN_ORDER_SHARDING_KEY, new ArrayList<>());
Collection<String> memberIds = complexKeysShardingValue.getColumnNameAndShardingValuesMap().getOrDefault(COLUMN_CUSTOMER_SHARDING_KEY, new ArrayList<>());
// 2. 合并分片键值,避免重复
List<String> ids = new ArrayList<>(16);
if (Objects.nonNull(orderIds)) {
ids.addAll(orderIds);
}
if (Objects.nonNull(memberIds)) {
ids.addAll(memberIds);
}
// 3. 核心分片逻辑:截取后两位 → 取模32 → 定位物理表
return ids.stream()
.filter(Objects::nonNull)
.map(id -> id.substring(id.length() - 2)) // 截取后两位
.distinct() // 去重
.map(Integer::new) // 转int
.map(idSuffix -> idSuffix % availableTargetNames.size()) // 对表数量取模
.map(String::valueOf) // 转字符串
// 匹配物理表名(如oms_order_0)
.map(tableSuffix -> availableTargetNames.stream()
.filter(targetName -> targetName.endsWith(tableSuffix))
.findFirst()
.orElse(null))
.filter(Objects::nonNull)
.collect(Collectors.toList());
}
}3.3 重点概念
- 绑定表:指分片规则一致的关联表(如订单主表 + 订单详情表),Sharding-JDBC 会优化绑定表的关联查询,避免跨分片关联,提升性能;
- 广播表:指所有分片都同步的表,数据量小且极少修改(如订单操作历史、公司地址),无需分片,全部分片保存一份;
- 复合分片键:指多个列共同作为分片键(如订单表的 id+member_id),支持多维度查询的分片定位;
- 主从负载均衡:Sharding-JDBC 支持轮询(ROUND_ROBIN)、随机(RANDOM)等算法,实现从库的负载均衡。
五、流程图解
5.1 订单 ID 生成流程
5.2 订单系统分库分表 + 读写分离架构
5.3 哈希分片定位流程