一、Shell 三剑客概述
1. Shell 三剑客
Shell 三剑客是指 grep 、sed 和 awk 这三个在 Linux/Unix 系统中常用的命令行工具。
-
grep :grep 是一个文本搜索工具,用于根据给定的模式(正则表达式)在文件或输入流中搜索匹配的行。grep 的主要作用是 查找 和 过滤 特定文本。
-
sed:sed 是一个流编辑器,可以对文本进行查找、替换、删除等操作。它可以直接在文本流中编辑,不需要打开文件,非常适合批量处理。
-
awk:awk 是一个文本处理工具,适合对列进行处理和分析。它不仅可以进行查找和替换,还能执行数学计算和数据统计,特别适合处理以列形式组织的数据,如日志、CSV 文件等。
面试题:grep、sed、awk 有何区别?
-
grep 用于查找特定内容,适合快速过滤日志或配置文件。
-
sed 用于修改和编辑文本,非常适合批量替换或删除操作。
-
awk 更强大,适用于列状数据的处理,能够提取字段、统计数据或进行数学计算。
在运维工作中,我会根据不同的需求选择合适的工具:当需要简单查找时用 grep ,批量修改文件时用 sed ,处理复杂的日志或统计数据时使用 awk。
2. Shell 三剑客适用场景
-
日志处理与搜索:使用 grep 搜索关键词,结合 sed 和 awk 进行进一步处理和分析。
-
配置文件管理:使用 sed 和 awk 进行批量修改、添加或删除配置项。
-
数据提取与转换:利用 awk 提取、分析和转换结构化文本数据,处理 CSV、JSON 等格式。
-
监控与报警:使用 grep、sed 和 awk 提取关键信息生成监控报告,监控系统状态和性能。
-
日常运维任务:自动化任务如查找过期文件、清理日志、统计日志大小等。
-
系统管理:使用 sed 和 awk 处理系统状态信息,如用户信息、进程信息、磁盘使用情况等。
3. Shell 三剑客执行说明
默认情况下,grep、sed 以及 awk 在处理数据时默认都是按 行 处理。
二、Shell 三剑客之 grep 指令
1. grep 基本语法
grep 主要作用:过滤来自一个文件或标准输入匹配模式内容。
除了 grep 外,还有 egrep。egrep 是 grep 的扩展,相当于 grep -E。
基本语法: grep [OPTION]... PATTERN [FILE]...
| 支持的正则 | 描述 |
|---|---|
-E, --extended-regexp |
模式是扩展正则表达式 (ERE) => 字符簇、()、|或 |
-P, --perl-regexp |
模式是 Perl 正则表达式 => \d、\w、\s |
-i, --ignore-case |
忽略大小写 |
-w, --word-regexp |
模式匹配整个单词 |
-v, --invert-match |
打印不匹配的行 |
| 输出控制 | 描述 |
|---|---|
-n, --line-number |
打印行号 |
-h, --no-filename |
不输出文件名 |
-o, --only-matching |
只打印匹配的内容 |
-r, --recursive |
递归目录 |
-c, --count |
统计匹配行数 |
2. grep 案例演示
准备数据集
# vim demo.txt
Hello, this is an example file.
It contains some lines of text.
Let's use grep to search for specific patterns. 案例 1:在文件中搜索包含单词 "example" 的行
grep "example" demo.txt 案例 2:忽略大小写地搜索匹配模式的行
在文件中搜索不区分大小写的单词 "hello" 的行
grep -i "hello" demo.txt案例 3:反转匹配,只打印不匹配模式的行
在文件中搜索不包含 "text" 的行
grep -v "text" demo.txt案例 4:显示匹配行的行号
在文件中搜索包含单词 "example" 的行,并显示行号
grep -n "example" demo.txt案例 5:统计匹配的行数
grep -c "example" demo.txt案例 6:仅匹配整个单词
在文件中搜索包含单词 "example" 的行,是整个单词,而不是一个单词的一部分
grep -w "example" demo.txt案例 7:递归地搜索目录及其子目录下的文件
搜索 /root/ 目录下包含内容 "Hello, this is an example file." 的所有文件
grep -r "Hello, this is an example file." /root/三、Shell 三剑客之 sed 指令
作用: sed 命令功能比较全,可以进行增删改查操作 => 运维工作中:修改操作相对而言是最多。
1. sed 指令说明
我们都知道,在 Linux 中一切皆文件,比如配置文件,日志文件,启动文件等等。如果我们相对这些文件进行一些编辑查询等操作时,我们可能会想到一些 vi, vim, cat, more 等命令。但是这些命令效率不高,这就好比一块空地准备搭建房子,请了 10 个师傅拿着铁锹挖地基,花了一个月的时间才挖完,而另外一块空地则请了个挖土机,三下五除二就搞定了,这就是效率。而在 Linux 中的 "挖土机" 有三种型号:顶配 awk,中配 sed,标配 grep。使用这些工具,我们能够在达到同样效果的前提下节省大量的重复性工作,提高效率。
sed 是 Stream Editor(字符流编辑器)的缩写,简称流编辑器。什么是流?大家可以想象一下流水线,sed 就像一个车间一样,文件中的每行字符都是原料,运到 sed 车间,然后经过一系列的加工处理,最后从流水线下来就变成货物了。

以前工厂中没有流水线时,生产一件商品需要十几个工种互相配合,这样下来利润太低,后来就有了流水线,生产一件商品虽然还是有十几道工序,但都是机器化生产,工人只是辅助作用,这样利润就大大提高了,产量也大大提高了。
编辑文件也是这样,以前我们修改一个配置文件,需要移动光标到某一行,然后添加点文字,然后又移动光标到另一行,注释点东西......可能修改一个配置文件下来需要花费数十分钟,还有可能改错了配置文件,又得返工。这还是一个配置文件,如果数十个数百个呢?因此当你学会了 sed 命令,你会发现利用它处理文件中的一系列修改是很有用的。只要想到在大约 100 多个文件中,处理 20 个不同的编辑操作可以在几分钟之内完成,你就会知道 sed 的强大了。
2. 软件功能和版本
sed --version # 查看 sed 软件版本3. 语法格式
sed [options] [sed-commands] [input-file]
sed [选项] 【sed 命令】 【输入文件】说明:
-
注意 sed 软件以及后面选项,sed 命令和输入文件,每个元素之间都至少有一个空格。
-
为了避免混淆,笔记中称呼 sed 为 sed 软件。sed-commands(sed 命令) 是 sed 软件内置的一些命令选项,为了和前面的 options(选项)区分,故称为 sed 命令。
-
sed-commands 既可以是单个 sed 命令,也可以是多个 sed 命令组合。
-
input-file (输入文件) 是可选项,sed 还能够从标准输入如管道获取输入。
4. 命令执行流程
概括流程: sed 软件从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行....
小知识: 一次一行的设计使得 sed 软件性能很高,sed 在读取非常庞大的文件时不会出现卡顿的现象。大家都用过 vi 命令,用 vi 命令打开几十 M 或更大的文件,会发现有卡顿现象,这是因为 vi 命令打开文件是一次性将文件加载到内存,然后再打开,因此卡顿的时间长短就取决于从磁盘到内存的读取速度了。而且如果文件过大的话还会造成内存溢出现象。Sed 软件就很好的避免了这种情况,打开速度非常快,执行速度也很快。
详细流程: 现有一个文件 person.txt, 共有五行文本,sed 命令读入文件 person.txt 的第一行 "101, Tom, CEO", 并将这行文本存入模式空间(sed 软件在内存中的一个临时缓存,用于存放读取到的内容,比喻为工厂流水线的传送带。)
文件 person.txt 在模式空间的完整处理流程
-
判断第 1 行是否是需要处理的行,如果不是要处理的行就重新从文件读取下一行,如果是要处理的行,则接着往下走。
-
对模式空间的内容执行 sed 命令,比如 a(append 追加,在行之后),i(insert 插入,在行之前),s(替换)...
-
将模式空间中经过 sed 命令处理后的内容输出到屏幕上,然后清空模式空间。
-
读取下一行文本,然后重新执行上面的流程,直到文件结束。
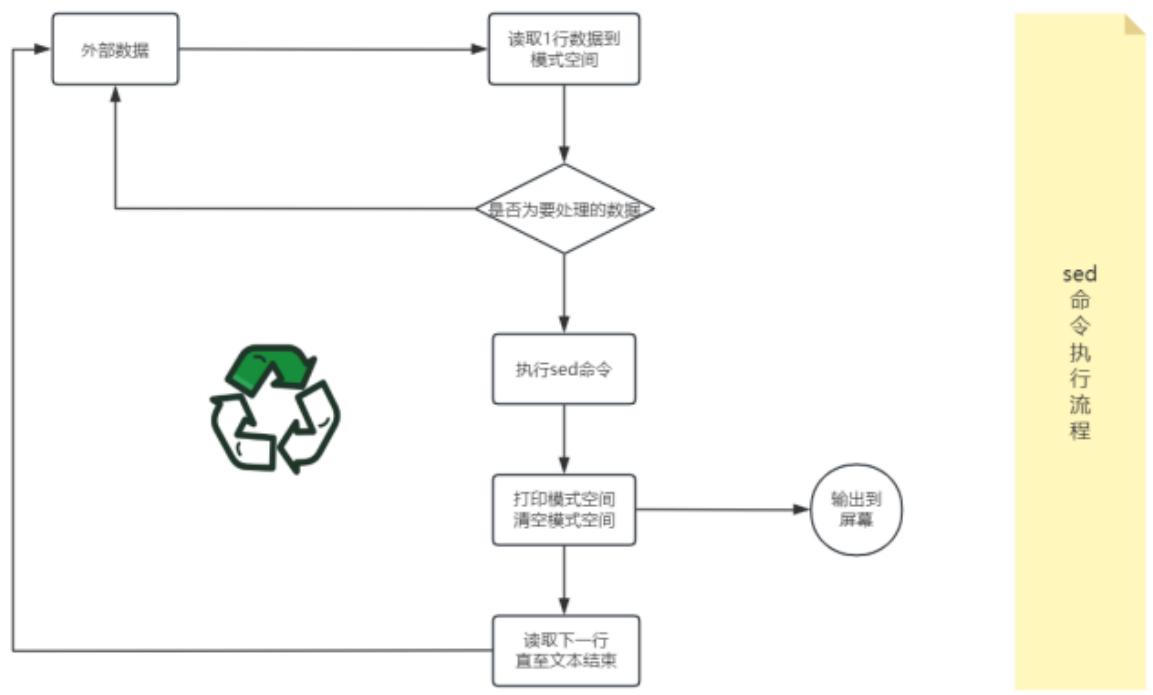
Sed 软件有两个内置的存储空间:
-
模式空间(pattern space):是 sed 软件从文本读取一行文本然后存入的缓冲区(这个缓冲区是在内存中的),然后使用 sed 命令操作模式空间的内容。
-
保持空间(hold space):是 sed 软件另外一个缓冲区,用来存放临时数据,也是在内存中,但是模式空间和保持空间的用途是不一样的。sed 可以交换保持空间和模式空间的数据,但是不能在保持空间上执行普通的 sed 命令,也就是说我们可以在保持空间存储数据。
5. sed 选项说明
sed 选项 sed 命令 文件
| option选项 | 解释说明(带*的为重点) |
|---|---|
-n |
取消默认的 sed 软件的输出,常与 sed 命令的 p 连用* |
-r |
使用扩展正则表达式(grep -E),默认情况 sed 只识别基本正则表达式* |
-i |
直接修改文件内容,而不是输出到终端,如果不使用 -i 选项 sed 软件只是修改在内存中的数据,并不会影响磁盘上的文件* |
| sed-commands | 解释说明(带*的为重点) |
|---|---|
a |
append 追加,在指定行后添加一行或多行文本* |
c |
change,取代指定的行 |
d |
delete,删除指定的行* |
i |
insert 插入,在指定行前添加一行或多行文本* |
p |
print,打印模式空间内容,通常 p 会与选项 -n 一起使用* |
q |
退出 sed |
r |
从指定文件读取数据 |
s |
取代,s#old#new#g===这里 g 是 s 命令的替代标志,注意和 g 命令区分。* |
重点记住:增删改查操作 => 增加 a、删除 d、修改 c 或 s、查询 p
| 特殊符号 | 解释说明(带*的为重点) |
|---|---|
! |
(取反),对指定行以外的所有行应用命令* |
= |
打印当前行行号 |
~ |
"first ~ step"表示从 first 行开始,以步长 step 递增 |
6. sed 增加操作
数据集准备
cat > person.txt <<EOF
101, Tom, CEO
102, Rose, CTO
103, Alex, COO
104, Jack, CFO
105, Jennifer, CIO
EOF
# EOF 必须成对出现,表示终止输入命令说明: 使用一条 cat 命令创建多行文本,文件包含上面的内容,后面的操作都会使用这个文件。
增加操作就是往文件指定位置追加或插入指定文本。
这个功能非常有用,比如我们平时往配置文件写入几行文本,最常用的是 vi 或 vim 命令,但是这 2 个命令是一种交互式的命令,还需要我们在 vi/vim 编辑器界面输入字符串然后保存退出,操作有些繁琐但是还能用。但是当我们学会了 Shell 脚本后,我们就会发现在脚本中不能正常使用 vi 或 vim 命令,为什么呢?
我们学习 Shell 脚本主要是为了解放我们的双手,执行一个脚本,然后自动往文件中写入数据,不需要我们再动手。因此我们想到了 sed 软件,它能够帮助我们实现目的。
这里我们需要用到 2 个 sed 命令,分别是:
-
"a": 追加文本到指定行后,记忆方法:a 的全拼是 append,意思是追加。 -
"i":插入文本到指定行前,记忆方法:i 的全拼是 insert,意思是插入。
单行增:
首先我们看一下单行增加的用法,说白了就是在文件中增加一行文本,我们以前学过 echo 命令可以在文件的末尾追加文本,比较简单,但是我们还有其他的复杂需求,比如在第 10 行插入一行数字等等,这里就需要 sed 出马了。我们来看一下面的例子:
sed '2a 106,Smith,CSO' person.txt 注:
-
2代表指定对第 2 行操作,其他的行忽略; -
a代表追加的意思,2a即在第 2 行后追加文本; -
2a后面加上空格,然后跟上你想要插入的多行文本即可。这里的每行文本使用\n连接就可以写成一行了。
多行增:
sed '2a 106,Eric,CSO\n107,Susan,CCO' person.txt 注: \n 代表换行符
小结:
-
sed 默认操作文件内容是在内存中的模式空间中进行实现,不会影响原文件内容。
-
增加操作有两种方式(行号 + i,指定行前面添加内容),(行号 + a,指定行后面添加内容)。
-
如果希望增加操作影响原文件,可以添加一个选项
-i。
7. sed 删除操作
删除指定行文本。
这个功能也是非常得有用,比如我们想删除文件中的某些行,以前最常用的是 vi 或 vim 命令,但现在我们知道了 sed 命令,就应该使用这个高逼格的命令完成任务了。
这里我们需要用到 1 个 sed 命令:
"d": 删除文本,记忆方法:d 的全拼是 delete,意思是删除。
因为删除功能比较简单,因此我们结合地址范围一起说明。我们前面学过 sed 命令可以对一行文本为目标进行处理(在单行前后增加一行或多行文本),接下来我们看一下如何对多行文本为目标操作。
指定执行的地址范围:
sed 软件可以对单行或多行文本进行处理。如果在 sed 命令前面不指定地址范围,那么默认会匹配所有行。
用法: n1[,n2]{sed-commands}
地址用逗号分隔开,n1,n2 可以用数字,正则表达式,或者二者的组合表示。
| 地址范围 | 含义 |
|---|---|
10 |
对第 10 行操作 |
10,20 |
对 10 到 20 行操作,包括第 10,20 行 |
1~2 |
first~step,对 1,3,5,7......行操作 |
10,$ |
对 10 到最后一行 ($代表最后一行) 操作,包括第 10 行 |
/Tom/ |
对匹配 Tom 的行操作 |
/Tom/,/Alex/ |
对匹配 Tom 的行到匹配 Alex 的行操作 |
/Tom/,$ |
对匹配 Tom 的行到最后一行操作 |
1,/Alex/ |
对第 1 行到匹配 Alex 的行操作 |
案例 1:下面用具体的例子演示一下 sed 删除操作实现
sed 'd' person.txt命令说明: 如果在 sed 命令前面不指定地址范围,那么默认会匹配所有行,然后使用 d 命令删除功能就会删除这个文件的所有内容。
案例 2:
sed '2d' person.txt命令说明: 这个单行删除想必大家能理解,指定删除第 2 行的文本。
案例 3:
sed '2,5d' person.txt命令说明: '2,5d' 指定删除第 2 行到第 5 行的内容,d 代表删除操作。
案例 4:
sed '/Jack/d' person.txt命令说明: 在 sed 软件中,使用正则的格式和 awk 一样,使用 2 个 / 包含指定的正则表达式,即 /正则表达式/。
案例 5:
sed '/Tom/,/Alex/d' person.txt命令说明: 这是正则表达式形式的多行删除,也是以逗号分隔 2 个地址,最后结果是删除包含 "Tom" 的行到包含 "Alex" 的行。
案例 6:
sed '3,$d' person.txt命令说明: 学过正则表达式后我们知道 $ 代表行尾,但是在 sed 中就有一些变化了,$ 在 sed 中代表文件的最后行。因此本例子的含义是删除第 3 行到最后一行的文本,包含第 3 行和最后一行,因此剩下第 1,2 行的内容。
案例 7:
sed '$a 106,Tom,CSO' person.txt命令说明: 为了不造成同学们实验文本改来改去导致不同意,因此我用上面的命令语句只是临时修改内存数据,然后通过管道符号传给 sed 软件。
特殊符号~(步长)解析
格式: "first~step" 表示从开始,以步长 step 递增,这个在数学中叫做等差数列。
使用:
-
1~2匹配 1,3,5,7... #--> 用于只输出奇数行,大伙仔细观察一下每个数字的差值。 -
2~2匹配 2,4,6,8... #--> 用于只输出偶数行。 -
1~3匹配 1,4,7,10... -
2~3匹配 2,5,8,11...
案例 8:
seq 10
1
2
3
4
5
6
7
8
9
10
seq 10 | sed -n '1~2p'
1
3
5
7
9 命令说明:
上面的命令主要验证特殊符号 ~ 的效果,其他 sed 命令用法 n 和 p 请见后文详解,大家只需要知道这个命令可以将 1~2 指定的行显示出来即可。
上面例子测试了 1~2 的效果,大家也可以手动测试一下 2~2,1~3,2~3,看一下他们的结果是不是符合等差数列。
案例 9:删除所有奇数行
sed '1~2d' person.txt命令说明: "1~2" 这是指定行数的另一种格式,从第 1 行开始以步长 2 递增的行(1,3,5),因此删掉第 1,3,5 行,即所有的奇数行。
案例 10:特殊符号!
感叹号 ! 我们在很多命令里都接触过,大部分都是 取反 的意思,在 sed 中也不例外。
sed '2,3!d' person.txt 命令说明: 在地址范围 2,3 后面加上 !,如果不加 ! 表示删除第 2 行和第 3 行,结果如下面的例子所示,然后加上 ! 的结果就是除了第 2 行和第 3 行以外的内容都删除,这个方法可以作为显示文件的第 2,3 行题目的补充方法。
小结:
-
sed 软件不仅可以添加数据行,也可以删除数据行,删除数据行必须使用(d)命令。
-
sed 删除软件 => (
sed '范围 d' 文件) => 默认都是在内存中完成,需要影响原文件,则添加一个-i。
8. sed 修改操作(重点)
sed 修改操作,我们最常见的操作就是改配置文件,改参数等等。
首先说一下按行替换,这个功能用的很少,所以大家了解即可。这里用到的 sed 命令是:"c":用新行取代旧行,记忆方法:c 的全拼是 change,意思是替换。
sed '2c 106,Smith,CSO' person.txt 命令说明: 使用 sed 命令 c 将原来第 2 行内容替换成 106,Smith,CSO, 整行替换。

关键词替换
接下来说的这个功能,有工作经验的同学应该非常的熟悉,因为使用 sed 软件 80% 的场景就是使用替换功能。
这里用到的 sed 命令,选项:
-
"s": 单独使用 --> 将每一行中第一处匹配的字符串进行替换 --> sed 命令。 -
"g": 每一行进行全部替换 --> sed 命令 s 的替换标志之一(全局替换),非 sed 命令。 -
"-i": 修改文件内容 ---> sed 软件的选项,注意和 sed 命令 i 区别。
sed 软件替换模型
sed -i 's/旧的内容/替换后内容/' 文件内容
sed -i 's/旧的内容/替换后内容/g' 文件内容
sed -i 's#旧的内容#替换后内容#g' 文件内容路径替换式:
s#/home#/root#g g: global 全局替换。
sed 本身按照行进行操作的,如果在 1 行中有多个要替换的关键词,不加 g,则代表只替换满足条件第一个关键词;如果添加 g,则代表替换满足条件的所有关键词!
观察特点:
-
两边是引号,引号里面的两边分别为 s 和 g,中间是三个一样的字符
/或#作为定界符。字符#能在替换内容包含字符/有助于区别。定界符可以是任意字符如:|等,但当替换内容包含定界符时,需要转义\。经过长期实践,建议大家使用#作为定界符。 -
定界符
/或#,第一个和第二个之间的就是被替换的内容,第二个和第三个之间的就是替换后的内容。 -
s#目标内容#替换内容#g,"目标内容" 能用正则表达式,但替换内容不能用,必须是具体的。因为替换内容使用正则的话会让 sed 软件无所适从,它不知道你要替换什么内容。 -
默认 sed 软件是对模式空间(内存中的数据)操作,而
-i选项会更改磁盘上的文件内容。
案例 1:
sed 's#Tom#Eric#g' person.txt 命令说明: 将需要替换的文本 "Tom" 放在第一个和第二个 # 之间,将替换后的文本 "Eric" 放在第二个和第三个 # 之间。结果为第二行的 "Tom" 替换为 "Eric"。
案例 2:指定行修改配置文件
sed '3s#0#9#' person.txt 命令说明: 前面学习的例子在 sed 命令 "s" 前没有指定地址范围,因此默认是对所有行进行操作。而这个案例要求只将第 3 行的 0 换成 9,这里就用到了我们前面学过的地址范围知识,在 sed 命令 "s" 前加上 3 就代表对第 3 行进行替换。
案例 3:分组替换 () 和 \1 的使用功能
sed 软件的 () 的功能可以记住正则表达式的一部分,其中,\1 为第一个记住的模式即第一个小括号中的匹配内容,\2 第二个记住的模式,即第二个小括号中的匹配内容,sed 最多可以记住 9 个。
案例 4:执行命令取出 linux 中的 ens33 的 IP 地址?
dnf install net-tools -y
# ifconfig ens33 | sed -n '2p'
inet 192.168.88.101 netmask 255.255.255.0 broadcast 192.168.88.255
# ifconfig ens33 | sed -n '2p' | sed -r 's#.*inet ([0-9.]+).*#\1#g'
192.168.88.101 正则解析:
-
.*匹配所有,但是受到 inet 影响,只能匹配 inet 前面内容。 -
inet ([0-9.]+),这个小括号中的内容,用于匹配 IP(只有数字和点号的情况), 放入 1 号分组。 -
IP 后面内容统一用
.*匹配。 -
\1引用刚才匹配的 IP 地址,然后替换整个前面一行内容,最后就剩 1 个 IP。
命令说明:
这道题是需要把 ifconfig ens33 执行结果的第 2 行的 IP 地址取出来,上面答案的思路是用 IP 地址来替换第 2 行的内容。
案例 5:
echo "I am eric teacher." | sed -r 's#^.*am ([a-z]+) tea.*#\1#g'
eric 9. sed 查询操作
这个功能也是非常得有用,比如我们想查看文件中的某些行,以前最常用的是 cat 或 more 或 less 命令等,但这些命令有些缺点,就是不能查看指定的行。而我们用了很久的 sed 命令就有了这个功能了。而且我们前面也说过使用 sed 比其他命令 vim 等读取速度更快!
这里我们需要用到 1 个 sed 命令:
"p":输出指定内容,但默认会输出 2 次匹配的结果,因此使用-n选项取消默认输出,记忆方法:p 的全拼是 print,意思是打印。
案例 1:
sed '2p' person.txt 命令说明: 选项 -n 取消默认输出,只输出匹配的文本,大家只需要记住使用命令 p 必用选项 -n。
sed -n '2p' person.txt案例 2:
sed -n '2,3p' person.txt命令说明: 查看文件的第 2 行到 3 行,使用地址范围 2,3。取行就用 sed,最简单。
案例 3:
sed -n '1~2p' person.txt 注意: 起始值~步长。
命令说明: 打印文件的 1,3,5 行。~ 代表步长。
案例 4:
sed -n 'p' person.txt命令说明: 不指定地址范围,默认打印全部内容。
案例 5:
sed -n '/CTO/p' person.txt命令说明: 打印含 CTO 的行。
案例 6:
sed -n '/CTO/,/CFO/p' person.txt命令说明: 打印含 CTO 的行到含 CFO 的行。
案例 7:
sed -i.bak 's#Tom#Peter#g' person.txt 命令行说明:
在 -i 参数的后边加上 .bak(. 任意字符),sed 会对文件进行先备份后修改。
特殊符号 = 获取行号(了解)
案例 8:
sed '=' person.txt 命令说明: 使用特殊符号 = 就可以获取文件的行号,这是特殊用法,记住即可。从上面的命令结果我们也发现了一个不好的地方:行号和行不在一行。
案例 9:
sed '1,3=' person.txt 命令说明: 打印 1,2,3 行的行号,同时打印输出文件中的内容。
案例 10:取不连续的行
sed -n '1p;3p;5p' person.txt小结:
-
sed 如果想对行进行打印输出,通常使用 (p) 命令,取消默认输出,使用选项(-n)。
-
sed 功能非常强大:支持(增删改查操作)。
四、Shell 三剑客之 awk 指令
作用: awk 可以完成复杂的数据分析,如日志分析等等。
1. awk 概述
awk 不仅仅是 Linux 系统中的一个命令,更可以理解为它是一种编程语言,可以用来处理数据和生成报告(excel)。处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入,awk 可以在命令行上直接编辑命令进行操作,也可以编写成 awk 程序来进行更为复杂的运用。本章主要讲解 awk 命令的运用。
2. awk 格式
awk 指令是由模式,动作,或者模式和动作的组合组成。
-
模式 既 pattern, 可以类似理解成 sed 的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的正则表达式。比如
NR==1,这就是模式,可以把他理解为一个条件。 -
动作 即 action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开。
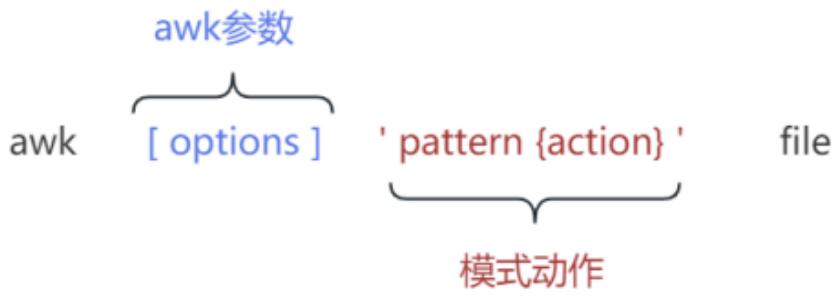
awk 处理的内容可以来自标准输入(<),一个或多个文本文件或管道。
options 既参数,使用最多的参数为 -F(Field,用于指定字段与字段之间的分隔符,列与列之间的分隔符,默认为空格)。
pattern 既模式,也可以理解为条件,也叫找谁,你找谁?高矮,胖瘦,男女?都是条件,既模式。
action 既动作,可以理解为干啥,找到人之后你要做什么。
注意: awk -F"分隔符" '模式和动作' file
模式和动作的详细介绍我们放在后面部分,现在大家先对 awk 结构有一个了解。
案例 1:基本模式与动作
awk -F":" 'NR>=2 && NR<=6{print NR, $1}' /etc/passwd
2 bin
3 daemon
4 adm
5 lp
6 sync命令说明:
-
-F指定分隔符为冒号,相当于以:为菜刀,进行字段的切割。 -
NR>=2 && NR<=6:这部分表示模式,是一个条件,表示取第 2 行到第 6 行。 -
{print NR, $1}:这部分表示动作,表示要输出 NR 行号和 $1 第一列。 -
NR = Number(数字、号码) + Record(记录、行) = 行号。
案例 2:只有模式
awk -F ":" 'NR>=2 && NR<=6' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync 命令说明:
-
-F指定分隔符为冒号。 -
NR>=2 && NR<=6这部分是条件,表示取第 2 行到第 6 行。 -
但是这里没有动作,这里大家需要了解如果只有条件(模式)没有动作,awk 默认输出整行。
案例 3:只有动作
awk -F":" '{print NR, $1}' /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
8 halt
9 mail
10 uucp
以下省略...命令说明:
-
-F指定分隔符为冒号。 -
这里没有条件,表示对每一行都处理。
-
{print NR,$1}表示动作,显示 NR 行号与 $1 第一列。 -
这里要理解没有条件的时候,awk 会处理每一行。
案例 4:多模式与多动作
awk -F":" 'NR==1{print NR, $1}; NR==2{print NR,$NF}' /etc/passwd
1 root
2 /sbin/nologin命令说明:
-
-F指定分隔符为冒号。 -
这里有多个条件与动作的组合。
-
NR==1表示条件,行号(NR)等于 1 的条件满足的时候,执行{print NR,$1}动作,输出行号与第一列。 -
NR==2表示条件,行号(NR)等于 2 的条件满足的时候,执行{print NR,$NF}动作,输出行号与最后一列($NF)。 -
NR:Number Record,行号信息。
-
NF:Number Field,注意:计数情况下,往往都代表最后一个,所以 NF 代表最后一列。
注意:
-
Pattern 和
{Action}需要用单引号引起来,防止 Shell 作解释。 -
Pattern 是可选的。如果不指定,awk 将处理输入文件中的所有记录。如果指定一个模式,awk 则只处理匹配指定的模式的记录。
-
{Action}为 awk 命令,可以是单个命令,也可以多个命令。整个 Action(包括里面的所有命令)都必须放在{和}之间。 -
Action 必须被
{ }包裹,没有被{ }包裹的就是 Pattern。 -
file 要处理的目标文件。
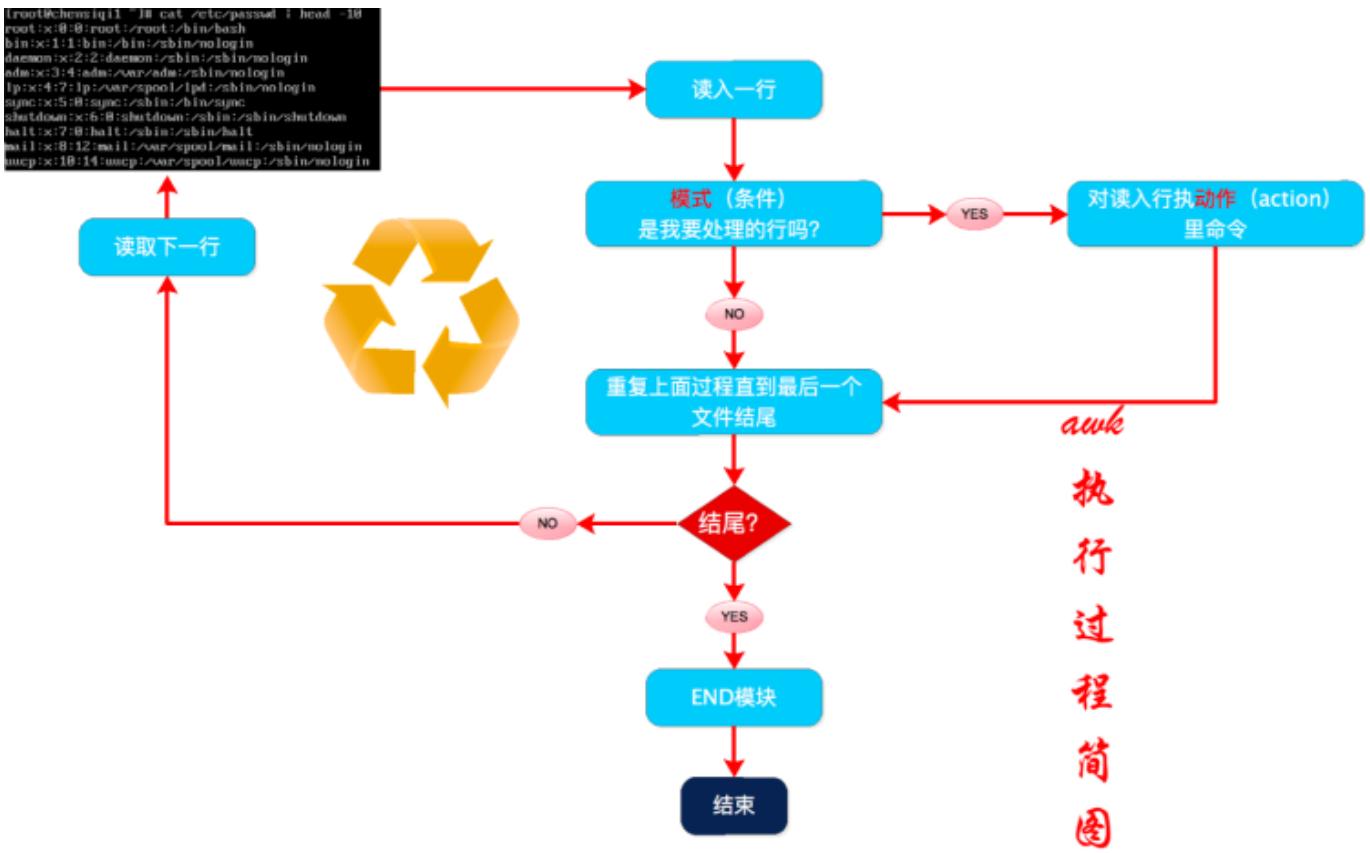
3. awk 执行过程
在深入了解 awk 前,我们需要知道 awk 如何处理文件的。
mkdir /server/files/ -p
head /etc/passwd > /server/files/awkfile.txt
cat /server/files/awkfile.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/sbin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/email:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin awk 执行过程演示:
awk 'NR>=2{print $0}' /server/files/awkfile.txt
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/email:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin 命令说明:
-
条件
NR>=2, 表示行号大于等于 2 时候,执行{print $0}显示整行。 -
awk 是通过一行一行的处理文件,这条命令中包含模式部分(条件)和动作部分(动作),awk 将处理模式(条件)指定的行。
-
$0代表所有列,$1代表第 1 列,$2代表第 2 列,...$NF代表最后 1 列。
awk 执行过程解析:
-
awk 读入第一行内容。
-
判断是否符合模式中的条件
NR>=2。-
如果匹配则执行对应的动作
{print $0}。 -
如果不匹配条件,继续读取下一行。
-
-
继续读取下一行。
-
重复过程 1-3,直到读取到最后一行(EOF:end of file)。
4. awk 记录(行)
记录和字段 接下来我给大家带来两个新概念记录和字段,这里为了方便大家理解可以把记录就当作行即记录 Record = 行,字段相当于列,字段 = 列。
| 名称 | 含义 |
|---|---|
| record | 记录,行 => NR(Number Record)行号 |
| field | 域,区域,字段,列 => NF(Number Field)列号,$NF 代表最后一列 |
数据集:
cat /server/files/awkfile.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/sbin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/sbin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/email:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin 思考:
一共有多少行呢?你如何知道的?通过什么标志?
awk 对每个要处理的输入数据认为都是具有格式和结构的,而不仅仅是一堆字符串。默认情况下,== 每一行内容都是一条记录 : ==,并以 : = 换行符 = = 分隔(\n)结束。
| RS$0 | Proto: | Recv-Q: | Send-Q: | Local Address: | Foreign Address: | State |
|---|---|---|---|---|---|---|
| tcp | 0 | 0 | 115.29.49.213:80: | 140.206.64.90:62291: | TIME_WAIT | |
| RS$0 | tcp | 0 | 0 | 115.29.49.213:80: | 49.80.146.230:13453: | FIN_WAIT2 |
| RS$0 | tcp | 0 | 0 | 115.29.49.213:80: | 49.80.146.230:13453: | ESTABLISHED |
| RS$0 | tcp | 0 | 0 | 115.29.49.213:80: | 113.104.25.50:56714: | ESTABLISHED |
| RS$0 | tcp | 0 | 0 | 115.29.49.213:80: | 113.104.25.50:56715: | TIME_WAIT |
awk 默认情况下每一行都是一个记录(record)。
-
RS 既 record separator 输入输出数据记录分隔符,每一行是怎么没的,表示每个记录输入的时候的分隔符,既行与行之间如何分隔,默认为
\n,可以调整为其他字符。 -
NR 既 number of record 记录(行)号,表示当前正在处理的记录(行)的号码。
-
ORS 既 output record separator 输出记录分隔符。
awk 使用内置变量 RS 来存放输入记录分隔符,RS 表示的是输入的记录分隔符,这个值可以通过 BEGIN 模块 == 重新定义修改。
案例 1:
awk 'BEGIN{RS="/"}{print NR,$0}' /server/files/awkfile.txt
1 root:x:0:0:root:
2 root:
3 bin
4 bash
bin:x:1:1:bin:
5 bin:
6 sbin
7 nologin
daemon:2:2:daemon:
8 sbin:
9 sbin
10 nologin
adm:3:4:adm:
11 var
12 adm:
13 sbin
14 nologin
lp:4:7:lp:
15 var
16 spool
17 lpd:
18 sbin
19 nologin
sync:5:0:sync:
20 sbin:
21 bin
22 sync
shutdown:6:0:shutdown:
23 sbin:
24 sbin
25 shutdown
halt:7:0:halt:
26 sbin:
27 sbin
28 halt
mail:8:12:mail:
29 var
30 spool
31 mail:
32 sbin
33 nologin
uucp:10:14:uucp:
34 var
35 spool
36 uucp:
37 sbin
38 nologin命令说明:
-
BEGIN:开始模块,在 awk 开始处理数据之前执行 1 次。
-
END:结束模块,在 awk 处理所有行后执行 1 次。
-
在每行的开始先打印输出 NR(记录号行号),并打印出每一行
$0(整行)的内容。 -
我们设置 RS(记录分隔符)的值为
/,表示一行(记录)以/结束。 -
在 awk 眼中,文件是从头到尾一段连续的字符串,恰巧中间有些
\n(回车换行符),\n也是字符哦。
我们回顾下"行(记录)"到底是什么意思?
行(记录):默认以 \n(回车换行)结束。而这个行的结束不就是记录分隔符嘛。
所以在 awk 中,RS(记录分隔符)变量表示着行的结束符号(默认是回车换行)。
在工作中,我们可以通过修改 RS 变量的值来决定行的结束标志,最终来决定"每行"的内容。
为了方便人们理解,awk 默认就把 RS 的值设置为 \n。
注意:
awk 的 BEGIN 模块,我会在后面(模式-BEGIN 模块)详细讲解,此处大家仅需要知道在 BEGIN 模块里面我们来定义一些 awk 内置变量即可。
对 $0 的认识
awk '{print NR,NF,$0,$1,$2,...}' -
NR:行号,打印行号。
-
**** :代表列号,如果前面添加了 ``,则代表最后一列。
-
$0:整行内容。
-
$1:按照分割后,1 代表分割后的第 1 列。
-
$2:按照分割后,2 代表分割后的第 2 列。
由以上代码运行可知:awk 中 $0 表示整行,其实使用 0 来表示整条记录。记录分隔符存在 RS 变量中或者说每个记录以 RS 内置变量结束。
另外,awk 对每一行的记录号都有一个内置变量 NR 来保存,每处理完一条记录,NR 的值就会自动 +1。
案例 2:NR 记录行号
awk '{print NR,$0}' /server/files/awkfile.txt
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin命令说明:
-
NR 既 number of record,当前记录的记录号,刚开始学也可以理解为行号。
-
$0 表示整行或者说整个记录。
企业面试题:按单词出现频率降序排序(计算文件中每个单词的重复数量)
sed -r '1,10s#[^a-zA-Z]+# #g' /etc/passwd |head > /server/files/count.txt
cat /server/files/count.txt
root x root root bin bash
bin x bin bin sbin nologin
daemon x daemon sbin sbin nologin
adm x adm var adm sbin nologin
lp x lp var spool lpd sbin nologin
sync x sync sbin bin sync
shutdown x shutdown sbin sbin shutdown
halt x halt sbin sbinhalt
mail x mail var spool mail sbin nologin
uucp x uucp var spool uucp sbin nologin 思路:
让所有单词排成一列,这样每个单词都是单独的一行。
-
设置 RS 值为空格。
-
将文件里面的所有空格替换为回车换行符
\n。 -
基于
sort + uniq -c实现词频统计。
方案一:
awk 'BEGIN{RS="[]+"} {print $0}' count.txt | sort |uniq -c|sort -nr 方案二:
cat count.txt | tr " " "\n" | sort |uniq -c |sort -nr 小结:
以后遇到词频统计,大致处理流程都是一样的:
-
想办法把每个单词单独放一行。
-
sort + uniq -c。 -
最后在升序或降序。
5. awk 记录知识小结
基本语法:
awk -F"分隔符" '模式 + 动作' 要处理的文件-
分隔符,需不需要根据某个符号提取某 1 列。
-
模式 ,匹配指定行信息 => NR,&& 逻辑与,
BEGIN{RS="行与行之间分隔符"}。 -
动作 ,拿到模式匹配的结果要做什么 ⇒
{print $0 $1 $2}。 -
NR 存放着每个记录的号(行号)读取新行时候会自动 +1。
-
RS 是输入数据的记录的分隔符,简单理解就是可以指定每个记录的结尾标志。
-
RS 作用 就是表示一个记录的结束。
-
当我们修改了 RS 的值,最好配合 NR(行)来查看变化,也就是修改了 RS 的值通过 NR 查看结果,调试 awk 程序。
-
ORS 输出数据的记录的分隔符。
awk 学习技巧一则:
大象放冰箱分几步?打开冰箱,把大象放进去,关闭冰箱门。
awk 也是一样的,一步一步来,先修改了 RS,然后用 NR 调试,看看到底如何分隔的。然后通过 sort 排序,uniq -c 去重。
6. awk 字段(列)
每条记录都是由多个区域(field)组成的,默认情况下区域之间的分隔符是由空格(即空格或制表符)来分隔,并且将分隔符记录在内置变量 FS 中,每行记录的区域数保存在 awk 的内置变量 NF 中。
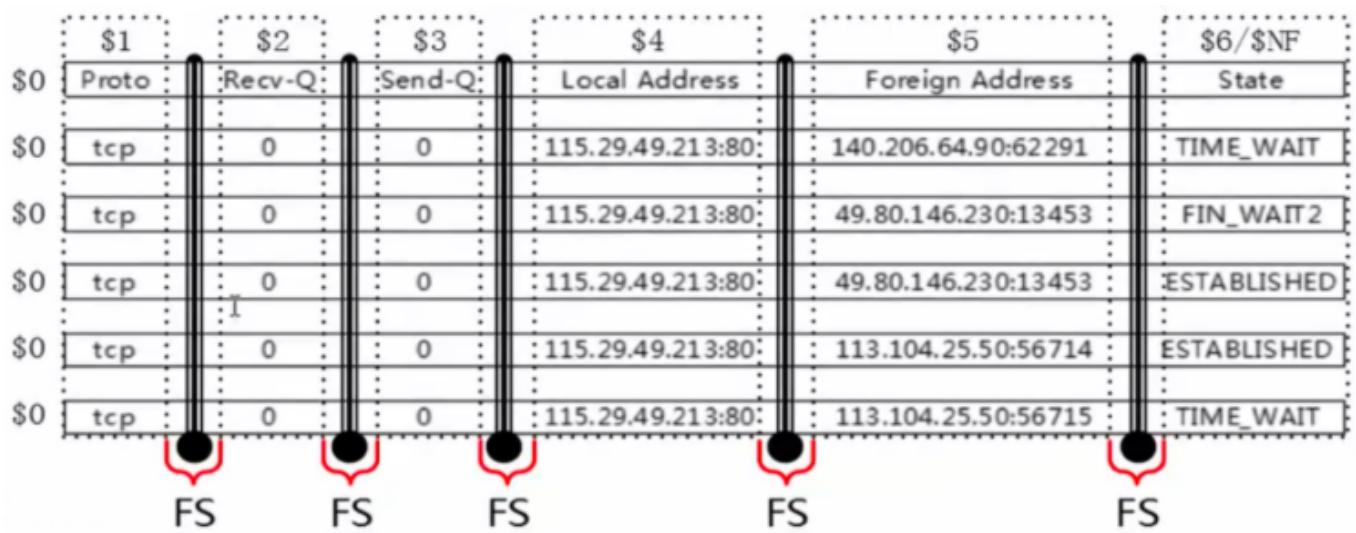
-
FS 既 field separator, 输入字段(列)分隔符。分隔符就是菜刀,把一行字符串切为很多个区域。
-
NF 既 number of fileds,表示一行中列(字段)的个数,可以理解为菜刀切过一行后,切成了多少份。
OFS 输出字段(列)分隔符
-
awk 使用内置变量 FS 来记录区域分隔符的内容,FS 可以在命令行上通过
-F参数来更改,也可以通过 BEGIN 模块来更改。 -
然后通过
$是整数,来取被切割后的区域,$1取第一个区域,$2取第二个区域,$NF取最后一个区域。
案例 1:指定分隔符
awk -F":" 'NR>=2&&NR<=5{print $1,$3}' /server/files/awkfile.txt
bin 1
daemon 2
adm 3
lp 4 命令说明:
以 :(冒号)为分隔符,显示第 2 行到第 5 行之间的第一区域和第三区域。
案例 2:提取字符串中的内容
echo "I am eric,my qq is 1234567890" >> /server/files/test.txt
cat /server/files/test.txt
I am eric,my qq is 1234567890 思路:
我们用默认的想法一次使用一把刀,需要配合管道的。如何同时使用两把刀呢?看下面的结果。
awk -F "[ ,]" '{print $3,$NF}' /server/files/test.txt
eric 1234567890命令说明:
-
通过命令
-F参数指定区域分隔符。 -
[ ,]是正则表达式里面的内容,它表示一个整体,"一个"字符,既空格或者逗号 (,),合并在一起,-F "[ ,]"就表示以空格或者逗号 (,) 为区域分隔符。
小技巧:
在动作('{print NF}')里面的逗号,表示空格,其实动作中的逗号就是 OFS 的值,我们会在后面说明。刚开始大家把动作中的都逗号,当作空格即可。
7. awk 分隔符
vim /server/files/awkblank.txt
inet addr:192.168.197.133 Bcast:192.168.197.255 Mask:255.255.255.0 默认分隔符时候
awk '{print $1}' /server/files/awkblank.txt
inet 指定分隔符时候
awk -F "[ :]+" '{print $1}' /server/files/awkblank.txt
# awk -F "[ :]+" '{print $2}' /server/files/awkblank.txt
inet 命令说明:
-
awk 默认的 FS 分隔符对于空格序列,一个空格或多个空格 tab 都认为是一样的,一个整体。
-
正常情况下,切割后,数据都是从
$1开始。 -
但是如果一个文件的开头有很多连续的空格,然后才是 inet 这个字符。
-
当我们使用默认的分隔符的时候,
$1是有内容。 -
当我们指定其他分隔符(非空格)时候,区域会有所变化,
$2才有内容。
8. ORS 和 OFS
-
RS 是输入记录分隔符,决定 awk 如何读取或分隔每行(记录) => 输入数据时,awk 认为行与行之间分隔符。
-
ORS 表示输出记录分隔符,决定 awk 如何输出一行(记录)的,默认是回车换行(
\n) => 输出数据时,awk 会在行与行之间设定 ORS,默认\n。 -
FS 是输入区域分隔符,决定 awk 读入一行后如何再分为多个区域 => 输入数据时,awk 认为列与列之间分隔符。
-
OFS 表示输出区域分隔符,决定 awk 输出每个区域的时候使用什么分隔她们 => 输出数据时,awk 会在列与列之间添加一个 OFS 符号,默认是空格。
awk 无比强大,你可以通过 RS,FS 决定 awk 如何读取数据。你也可以通过修改 ORS,OFS 的值指定 awk 如何输出数据。
9. 字段与记录小结
现在你应该会对 awk 的记录字段有所了解了,下面我们总结一下,学会给阶段性知识总结是学好运维的必备技能。

-
RS 记录分隔符,表示每行的结束标志。
-
NR 行号(记录号)。
-
FS 字段分隔符,每列的分隔标志或结束标志。
-
NF 就是每行有多少列,每个记录中字段的数量。
-
**** 符号表示取某个列(字段)`1
-
NF 表示记录中的区域(列)数量,
$NF取最后一个列(区域)。 -
FS(-F) 字段(列)分隔符,
-F(FS)":"<==>'BEGIN{FS=":"}'。 -
RS 记录分隔符(行的结束标识)。
-
NR 行号。
-
选好合适的刀 FS, RS, OFS, ORS。
-
分隔符
.==>结束标识。 -
记录与区域,你就对我们所谓的行与列,有了新的认识(RS,FS)。
10. awk 模式与动作进阶
awk 模式与动作
接下来就详细介绍下,awk 的模式都有几种:
-
正则表达式作为模式。
-
比较表达式作为模式。
-
范围模式。
-
特殊模式 BEGIN 和 END。
案例 1:awk 正则表达式匹配整行
sed '/正则表达式/'
awk '/正则表达式/'
awk '$0~/正则表达式/'awk -F ":" '/^root/' awkfile.txt 或
awk -F ":" '$0~/^root/' awkfile.txt命令解析:
awk 只用正则表达式的时候是默认匹配整行的即 $0~/root/ 和 /root/ 是一样的。
案例 2:awk 正则表达式匹配一行中的某一列
awk -F ":" '$5~/shutdown/' awkfile.txt 命令解析:
-
$5表示第五个区域(列)。 -
~表示匹配(正则表达式匹配)。 -
/shutdown/表示匹配 shutdown 这个字符串。 -
合在一起,
$5~/shutdown/表示第五个区域(列)匹配正则表达式/shutdown/,既第 5 列包含 shutdown 这个字符串,则显示这一行。
案例 3:某个区域中的开头和结尾
知道了如何使用正则表达式匹配操作符之后,我们来看看 awk 正则与 grep 和 sed 不同的地方。
awk 正则表达式:
| ^ | 匹配一个字符串的开头 |
|---|---|
| $ | 匹配一个字符串的结尾 |
数据集
cat >>/server/files/reg.txt<<KOF
Zhang Dandan 41117397 :250:175
Zhao Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Yujia 70271111 :250:80:75
Liu Bingbing 41117483 :250:175
Wang Yangming 3515064655 :50:95:135
Guan Tingting 1986787350 :250:168:200
Li Xinxin 918391635 :175:75:300
Liao Feifan 918391635 :250:175
KOF说明:
-
第一列是姓氏。
-
第二列是名字。
-
第一列第二列合起来就是姓名。
-
第三列是对应的 ID 号码。
-
最后三列是三次捐款数量。
练习题 1: 显示姓 Zhang 的人的第二次捐款金额及她的名字
awk -F "[ :]+" '$1~/^zhang/{print $2, $(NF-1)}' reg.txt 练习题 2: 显示 Xiaoyu 的名字和 ID 号码,并以逗号隔开
awk -F "[ :]+" '$2~/^xiaoyu$/{print $1", "$3}' reg.txt 练习题 3: 显示所有以 41 开头的 ID 号码的人的全名和 ID 号码
awk -F "[ :]+" '$3~/^(41)/{print $1,$2,$3}' reg.txt 练习题 4: 显示所有以一个 D 或 X 开头的人名全名
awk -F "[ :]+" '$2~/^D|^X/{print $1,$2}' reg.txt 练习题 5: 显示所有 ID 号码最后一位数字是 1 或 5 的人的全名
awk -F "[ :]+" '$3~/1$|5$/{print $1,$2}' reg.txt 特别说明: {print $2,$3} 这么写,代表使用默认分隔符(空格连接)。
特别说明: {print $2, $3}。
案例 4:取出网卡 ens33/ens160 的 ip 地址
-
VMware16 => ens33
-
VMware17 => ens160
-
网卡 => eth0
最简单: hostname -I
ifconfig ens33 |sed -n '2p' |awk -F"[ ]+" '{print $3}' 或
ifconfig ens160 |sed -n '2p' |awk -F"[ ]+" '{print $3}'案例 5:取出常用服务端口号
思路: linux 下面服务与端口信息的对应表格在 /etc/services 里面,所以这道题要处理 /etc/services 文件。
sed -n '23,30p' /etc/services
tcpmux 1/tcp # TCP port service multiplexer
tcpmux 1/udp # TCP port service multiplexer
rje 5/tcp # Remote Job Entry
rje 5/udp # Remote Job Entry
echo 7/tcp
echo 7/udp
discard 9/tcp sink null
discard 9/udp sink null 从 23 行开始基本上每一行第一列是服务名称,第二列的第一部分是端口号,第二列的第二部分是 tcp 或 udp 协议。
awk -F "[ /]+" '$1~/^(ssh)$|^(http)$|^(https)$|^(mysql)$|^(ftp)$/{print $1,$2}'
/etc/services |sort|uniq
ftp 21
http 80
https 443
mysql 3306
ssh 22 命令解析:
-
|是或者的意思,正则表达式。 -
sort是将输出结果排序。 -
uniq是去重复但不标记重复个数。 -
uniq -c去重复但标记重复个数。
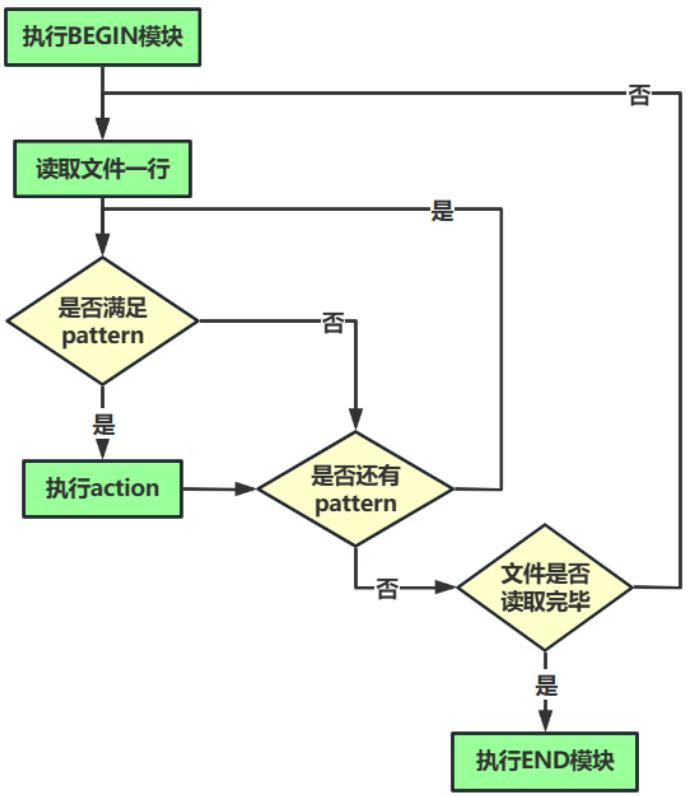
11. BEGIN 模式与 END 模式
BEGIN 模式
BEGIN 模块再 awk 读取文件之前就执行,一般用来定义我们的内置变量(预定义变量,eg: FS,RS), 可以输出表头(类似 excel 表格名称)。
BEGIN 模式之前我们有在示例中提到,自定义变量,给内容变量赋值等,都使用过。需要注意的是 BEGIN 模式后面要接跟一个 action 操作块,包含在大括号内。awk 必须在输入文件进行任何处理前先执行 BEGIN 里的动作(action)。我们可以不要任何输入文件,就可以对 BEGIN 模块进行测试,因为 awk 需要先执行完 BEGIN 模式,才对输入文件做处理。BEGIN 模式常常被用来修改内置变量 ORS,RS,FS,OFS 等值。
案例 1:可以使用 BEGIN 设定表头信息
awk -F: 'BEGIN{print "username","UID"}{print $1,$3}' awkfile.txt
username UID # 这就是输出的表头信息
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
uucp 10说明:
-
要在第一行输出一些 username 和 UID,我们应该想到
BEGIN{}这个特殊的条件(模式),因为BEGIN{}在 awk 读取文件之前执行的。 -
所以结果是
BEGIN{print "username","UID"}, 注意 print 命令里面双引号吃啥吐啥,原样输出。 -
然后我们实现了在输出文件内容之前输出 "username" 和 "UID",下一步输出文件的第一列和第三列即
{print $1, $3}。 -
最后结果就是
BEGIN{print "username","UID"}{print $1, $3}。
案例 2:awk 变量
直接定义,直接使用即可。
awk 命令不仅可以进行数据获取分析,还支持数学运算!
awk 中字母会被认为是变量,如果真的要给一个变量赋值字母(字符串),请使用 == 双引号 ==。
awk 'BEGIN{a=abcd;print a}'
awk 'BEGIN{abcd=123456;a=abcd;print a}'
123456
awk 'BEGIN{a="abcd";print a}'
abcd END 模式
作用: 与 BEGIN 相呼应,在 awk 处理文件结束后,会自动触发 END 模块(只会触发 1 次)。
案例 1:统计 /etc/servies 文件里的空行数量
思路:
a) 空行通过正则表达式来实现:^$。
b) 统计数量:
grep 方法:
grep "^$" /etc/services | wc -l
16
# grep -c "^$" /etc/services
16说明:
grep 命令 -c 表示 count 计数统计包含 ^$ 的行一共有多少。
awk 方法:
awk '/^$/{i=i+1} END{print "blank lines count:"i}' /etc/services 提示:
使用了 awk 的技术功能,很常用。
-
第一步:统计空行个数。
-
/^$/表示条件,匹配出空行,然后执行{i++}(i++等于i=i+1)即:/^$/{i=i+1}。 -
我们可以通过
/^$/{i=i+1;print i}来查看 awk 执行过程。
第二步:
awk 编程思想:
先处理,最后再 END 模块输出
{print NR,$0} body 模块处理,处理完毕后
END{print "end of file"} 输出一个结果案例 2:awk 支持数学运算
echo | awk '{print 1+2}'
echo | awk '{print 1+1.5}' 案例 3:文件 count.txt, 文件内容是 1 到 100(由 seq 100 生成),请计算文件每行值加起来的结果(计算 1 + ... + 100))
思路:
文件每一行都有且只有一个数字,所以我们要让文件的每行内容相加。
回顾一下上一道题我们用的是 i++ 即 i=i+1。
这里我们需要使用到第二个常用的表达式:
i=i+$0 对比一下,其实只是把上边的 1 换成了 $0。
awk '{i=i+$0} END{print i}' count.txt 12. awk 数组
awk 提供了 "数组" 来存放一组相关的值。
awk 是一种编程语言,肯定也支持数组的运用,但是又不同于 c 语言的数组。数组在 awk 中被称为关联数组,因为它的下标既可以是数字也可以是字符串。下标通常被称作 key,并且与对应的数组元素的值关联。数组元素的 key 和值都存储在 awk 程序内部的一张表中,通过一定散列算法来存储,所以数组元素都不是按顺序存储的。打印出来的顺序也肯定不是按照一定的顺序,但是我们可以通过管道来对所需的数据再次操作来达到自己的效果。
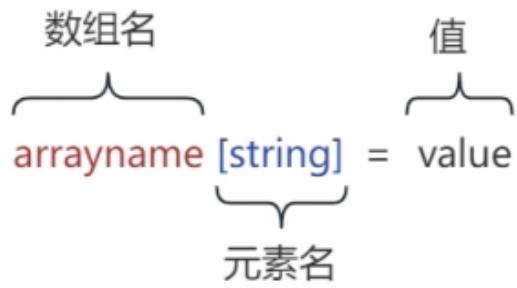
students[a]="张三"
students[b]="李四"
students[c] = "王五"数组 索引值 = "元素值",要求:索引值在数组中是不重复的。
白话讲数组: awk 数组就和酒店一样。数组的名称就像是酒店名称,数组元素名称就像酒店房间号码,每个数组元素里面的内容就像是酒店房间里面的人。
假设我们有一个酒店:
酒店 <=> hotel酒店里面有几个房间 110,119,120,114 这几个房间。
-
酒店 110 房间
<==>hotel[110] -
酒店 120 房间
<==>hotel[120] -
酒店 119 房间
<---->hotel[119] -
酒店 114 房间
<=>hotel[114]
酒店房间入驻客人
-
酒店 110 房间住着 xiaoyu
<=>hotel[110]="xiaoyu" -
酒店 119 房间住着 ruxue
<==>hotel[119] = "ruxue" -
酒店 120 房间住着 dandan
<==>hotel[120] = "dandan" -
酒店 114 房间住着 bingbing
<==>hotel[114] = "bingbing"
案例 1:
awk
'BEGIN{hotel[110]="xiaoyu"; hotel[119]="ruxue"; hotel[120]="dandan"; hotel[114]="bingbing"
;print hotel[110], hotel[119], hotel[120], hotel[114]}
xiaoyu ruxue dandan bingbing 案例 2:
awk
'BEGIN{hotel[110]="xiaoyu";hotel[119]="ruxue";hotel[120]="dandan";hotel[114]="bingbing" ;for(i in hotel) print i,hotel[i]}'
110 xiaoyu
120 dandan
114 bingbing
119 ruxue案例 3:统计域名访问次数
www.itheima.com 3
post.itheima.com 2
mp3.ittheima.com 1
# cat file
http://www.itheima.com/index.htm
http://www.itheima.com/1.htm
http://post.itheima.com/index.htm
http://mp3.itheima.com/index.htm
http://www.itheima.com/3.htm
http://post.itheima.com/2.htm 思路:
-
以斜线为刀取出第二列(域名)。
-
创建一个数组。
-
把第二列(域名)作为数组的下标。
-
通过类似于
i++的形式进行计数。 -
统计后把结果输出。
第一步:查看一下内容
awk -F "[\/]+" '{print $2}' file 第二步:计数
awk -F "[\/]+" '{i++;print $2,i}' file命令说明: i++: i 最开始是空的,当 awk 读取一行,i 自身 +1。
第三步:用数组替换 i
awk -F "[\/]+" '{h[$2]++;print $2,h["www.itheima.com"]} ' file 命令说明:
-
将 i 替换成
h[$2]; 相当于我创建了一个数组h[],然后用$2作为我的房间号。但是目前房间里是没有东西的。也就是说h[$2] = 1h["www.itheima.com"]andh["post.itheima.com"]andh["mp3.itheima.com"]但是具体房间里是没有东西的也就是空。 -
h[$2]++. 就等于i++:也就是说我开始给房间里加东西;当出现同样的东西,我就++。 -
print h["www.itheima.com"]: 意思就是说我开始要输出了。我要输出的是房间号为 "<www.itheima.com>" 里面的内容。这里面的内容最早是空的,随着 awk 读取每一行一旦出现房间号为 "<www.itheima.com>" 的房间时,我就给房间里的内容进行++。 -
综上,输出的结果中,每次出现 <www.itheima.com> 时,
h["www.itheima.com"]就会++。因此最后的输出数字是 3。
第四步:输出最终计数结果
awk -F "[\/]+" '{h[$2]++} END{for(i in h) print i,h[i]}' file h[www.itheima.com] = 3
h[post.itheima.com] = 2
h[mp3.itheima.com] = 1文件内容:
http://www.itheima.com/index.html
http://www.itheima.com/1.html
http://post.itheima.com/index.html
http://mp3.itheima.com/index.html
http://www.itheima.com/3.html
http://post.itheima.com/2.html针对以上文件,一行一行读取
-
读取第 1 行,发现与 <www.itheima.com> 这个索引对应的数组元素一致,进行 +1。
-
读取第 2 行,发现与 <www.itheima.com> 这个索引对应的数组元素一致,进行 +1。