awk------文本分析神器
1、awk 核心定位
awk 是一门 "面向数据处理" 的脚本语言,不同于 sed/grep 的 "编辑 / 搜索",awk 专注于结构化文本的分析、计算、统计------ 它将文本按 "行(记录)" 和 "列(字段)" 拆分,支持变量、循环、条件判断、函数等编程语言特性,是日志分析、数据报表生成的终极工具。
2、awk 基础语法
awk [选项] '模式 {动作}' 目标文件- 模式:筛选要处理的行(如行号、正则匹配、条件判断);
- 动作:对匹配行执行的操作(如打印、计算、赋值);
- 核心默认规则:按换行符分割行(记录),按空格 / 制表符分割列(字段)。
3、awk 核心概念:内置变量
awk 内置了大量用于描述文本结构的变量,高频如下:
| 变量 | 作用 | 示例 |
|---|---|---|
| $0 | 整行内容 | awk '{print $0}' test.txt(打印所有行) |
| 1−n | 第 1 到第 n 列内容 | awk '{print $1, $3}' test.txt(打印 1、3 列) |
| NF | 当前行的字段(列)数 | awk '{print NF}' test.txt(打印每行列数) |
| NR | 当前处理的行号(记录数) | awk '{print NR, $0}' test.txt(打印行号 + 内容) |
| FS | 字段分隔符(默认空格 / 制表符) | awk -F: '{print $1}' /etc/passwd(冒号分割列) |
4、awk 基础用法:字段提取与筛选
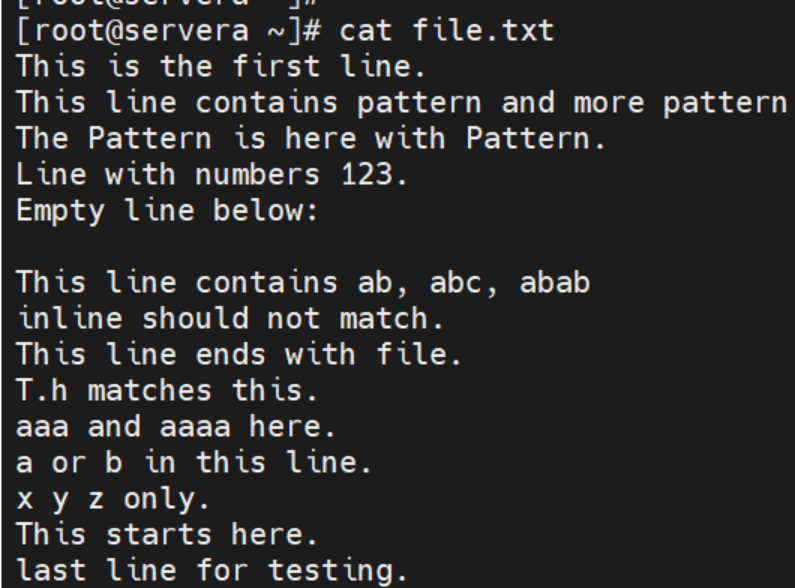
测试文件内容:
4.1 基础字段操作
常见用法:
# 1.1 提取指定列:从 passwd 中提取用户名(第1列)和登录Shell(第7列)
awk -F: '{print $1, $7}' /etc/passwd
# 1.2 按行号筛选:仅处理第 5-10 行
awk 'NR>=5 && NR<=10 {print $0}' test.txt
# 1.3 按字段条件筛选:提取第 2 列数值大于 30 的行
awk '$2 > 30 {print $1, $2}' text.txt
# 1.4 按正则筛选字段:第 3 列包含 "Engineer" 的行
awk '$3 ~ /Engineer/ {print $0}' text.txt 部分结果展示:
(1)打印每行内容

(2)打印每行的字段数(NF)+ 第一列内容($1)

4.2 自定义分隔符
常见用法:
# 用点号分割行
awk -F'.' '{print $1, $2}' file.txt | head -5
# 用空格或逗号分割行
awk -F'[ ,]' '{print $1, $3, $5}' file.txt | head -3部分结果展示:

5、awk 进阶:计算与统计
awk 支持变量、算术运算、循环,是数据统计的利器:
5.1 基础计算
常见用法:
# 统计字段数平均值
awk '{sum += NF; count++} END {print "每行平均字段数:", sum/count}' file.txt
# 查找字段数最大值
awk 'BEGIN {max_nf=0; line_num=0} {if (NF > max_nf) {max_nf=NF; line_num=NR}} END {print "字段数最多的行:", line_num, "行,字段数:", max_nf}' file.txt部分结果展示:
计算每行字段数的平均值

5.2 数组统计(词频 / 分类统计)
常见用法:
# 统计每行第一个单词的出现次数
awk '{word[$1]++} END {for (w in word) print w, word[w]}' file.txt结果展示:

6、awk 高级特性:条件判断与循环
6.1 条件判断(if-else)
常见用法:
# 按每行字段数分类(>5 为 "长行",否则为 "短行")
awk '{if (NF > 5) print NR "行:", $0, "→ 长行"; else print NR "行:", $0, "→ 短行"}' file.txt | head -5结果展示:

6.2 循环(for/while)
常见用法:
# for循环遍历第7行的所有列
awk 'NR==7 {for (i=1; i<=NF; i++) print "第" i "列:", $i}' file.txt
# while循环打印1-5
awk 'BEGIN {i=1; while(i<=5) {print i; i++}}'部分结果展示:
(1)遍历指定所有列

(2)while 循环打印 1-5

7、awk 内置函数:字符串 / 数值处理
7.1 字符串函数
常见用法:
# 打印前 5 行第一列的字符长度
awk '{print $1, "长度:", length($1)}' file.txt | head -5
# 大小写转换:将前 3 行第一列转大写、第三列转小写
awk '{print toupper($1), tolower($3)}' file.txt | head -3
# 子字符串:提取第1列前3个字符
awk '{print substr($1, 1, 3)}' file.txt 部分结果展示:
(1)打印前5行第一列字符长度

(2)转换大小写

7.2 数值函数
常见用法:
# 取整、平方根等
awk 'BEGIN {print "取整:", int(3.14); print "平方根:", sqrt(16)}' 结果展示:

8、awk 实战场景
8.1 日志分析
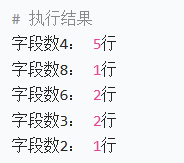
# 统计包含"a"的行的字段数分布
awk '/a/ {code[NF]++} END {for (c in code) print "字段数" c ":", code[c] "行"}' file.txt结果:
8.2 系统管理
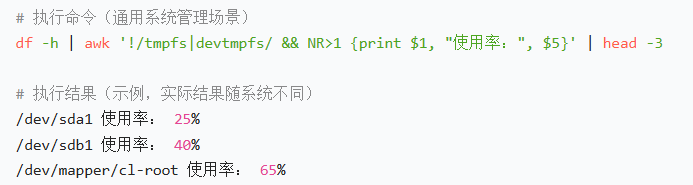
# 分析磁盘使用率(排除临时文件系统)
df -h | awk '!/tmpfs|devtmpfs/ && NR>1 {print $1, "使用率:", $5}' | head -3
# 计算内存使用率
free | awk '/^Mem:/ {printf "内存使用率:%.2f%%\n", ($2-$4-$7)*100/$2}'结果:

9、awk 与 sed/grep 的配合使用
常见用法:
# 步骤1:grep 筛选包含 "error" 的日志行
# 步骤2:sed 提取日志中的时间字段
# 步骤3:awk 统计每个小时的错误数
grep "a" file.txt | sed 's/a/A/g' | awk '{cnt=gsub(/A/,"A"); print $0, "→ A的数量:", cnt}' | head -3结果:

10、总结
awk 不是简单的 "工具",而是轻量级的 "数据处理语言"------ 它的核心优势是结构化数据拆分、数值计算、统计分析。掌握 "字段提取 + 变量计算 + 数组统计" 这三个核心能力,就能从简单的文本提取升级到复杂的数据分析,解决日志统计、报表生成、系统监控等高级场景。