来到第11天,依旧教程乱指路,小白不友好,所以我又来边学变记录了
3.2.1 实验一:实现 MCP Hosted 模式 (云端动态加载)
实验目标:
- 从 ModelScope MCP 广场获取
@modelcontextprotocol/fetch云端配置; - 在三款客户端中配置并启用 Hosted 模式 fetch 工具;
- 调用工具抓取网页内容,验证云端工具可用性。
步骤 1:获取 fetch 云端配置
访问 ModelScope MCP 广场:https://www.modelscope.cn/mcp;
进入fetch工具详情页:https://modelscope.cn/mcp/servers/@modelcontextprotocol/fetch;
这个链接呢直接是打不开的,404的
所以只能手动点击
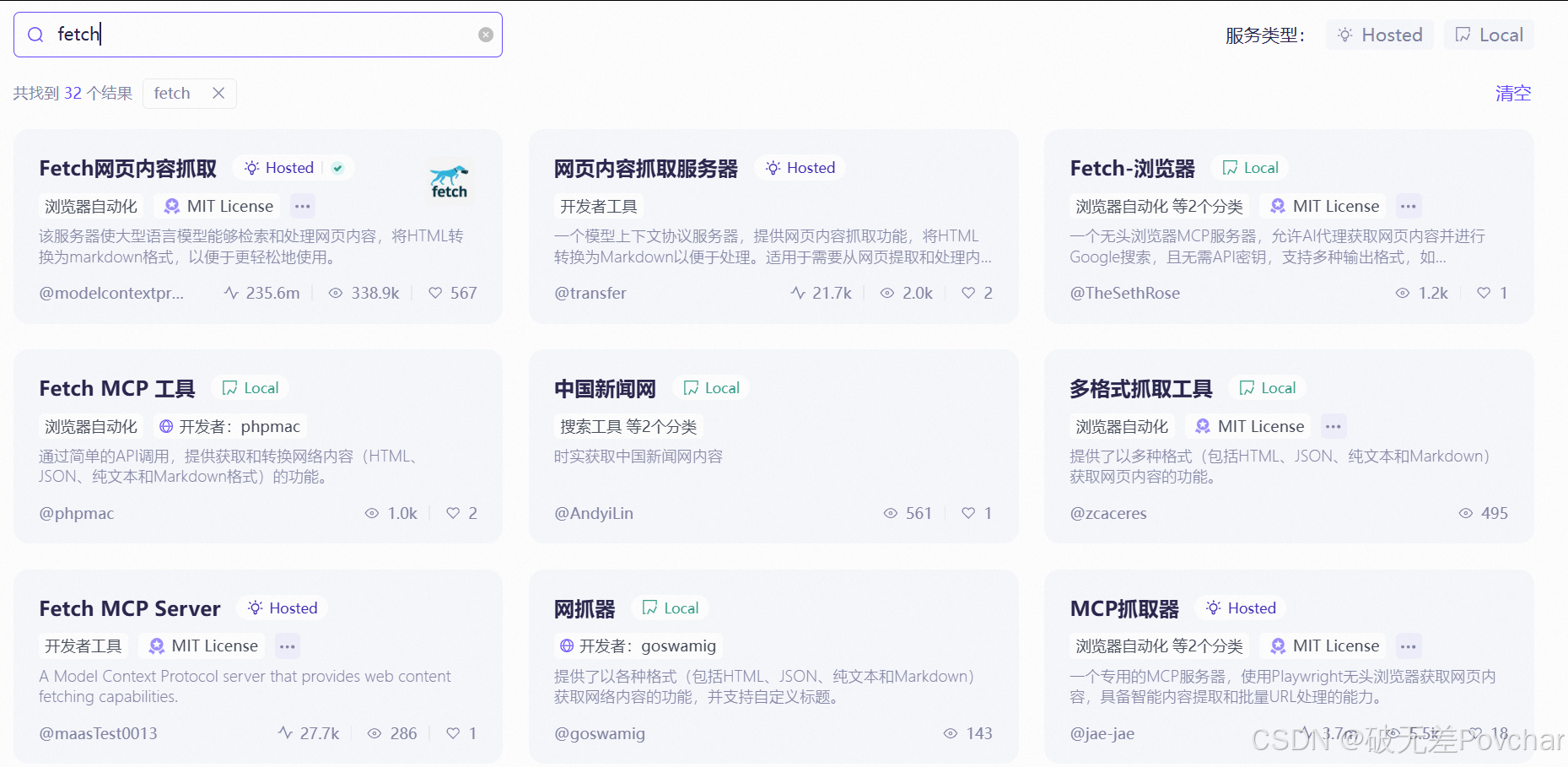
然后我搜出5个fetch,不知道该点哪个
经过我与deepseek一顿对话,得出结论:这个fetch就是Fetch 网页内容抓取 MCP
进入以后
教程:切换至「Hosted 模式」标签,复制完整 JSON 配置(示例如下):
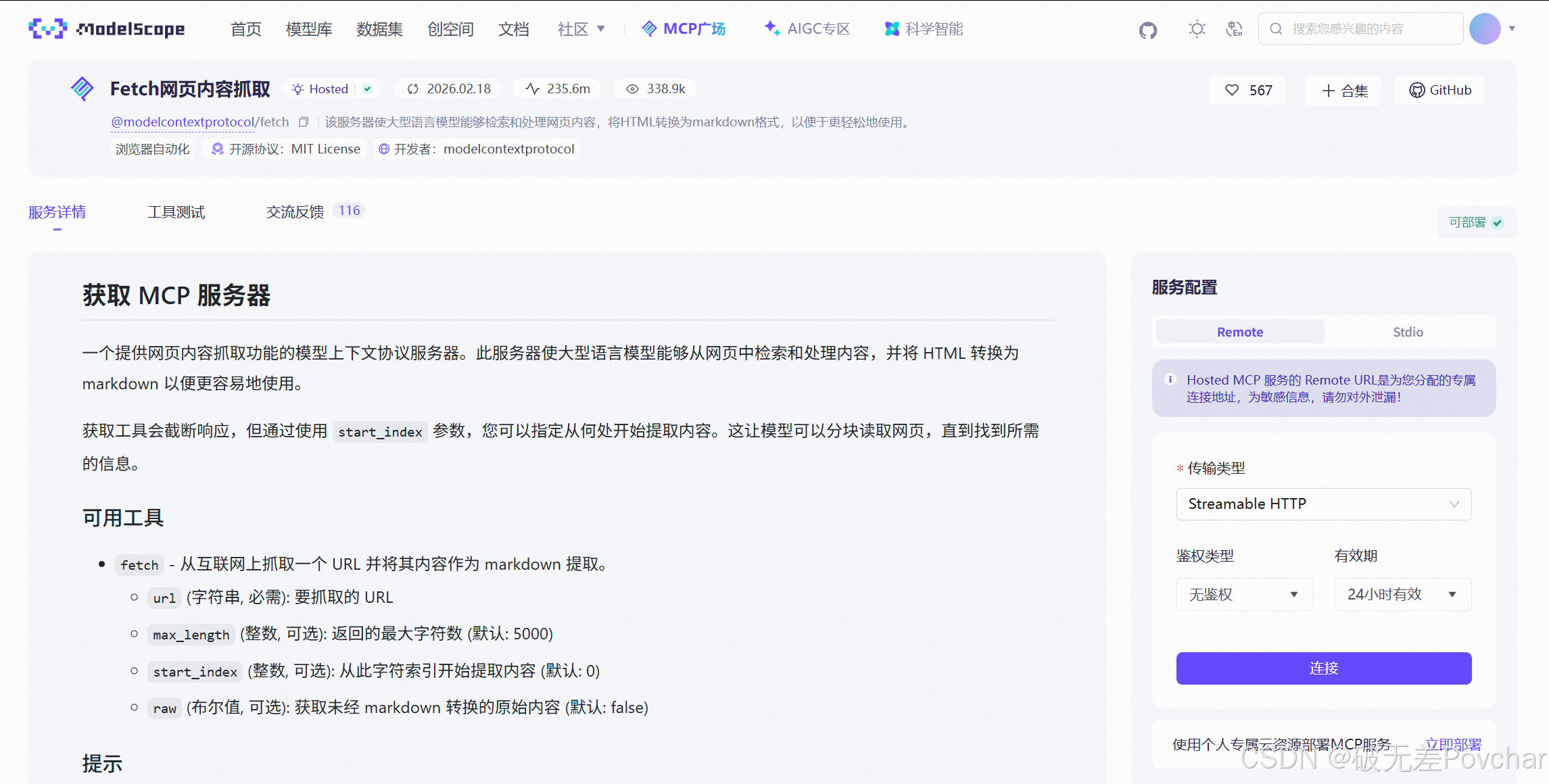
切换至「Hosted 模式」标签是什么也不说清楚的,反正我一通乱点
发现:应该点击"连接"
实验 3.2.2:实现 MCP fetch 工具 Local(本地)模式
实验目标:
- 本地启动
@modelcontextprotocol/fetch服务; - 在三款客户端中配置并启用 Local 模式 fetch 工具;
- 调用工具抓取网页,验证本地服务可用性。
将工具下载到本地运行。相比 Hosted 模式,Local 模式启动更快、版本更稳定,且方便进行二次修改。
步骤1:获取 fetch 本地配置
本次实验,我们将使用uvx直接运行mcp-server-fetch,因此不需要额外的安装步骤,只需要进行JSON文件的配置。
复制完整 JSON 配置(示例如下):
是的,它叫你复制,不说去哪里复制
好在我刚才乱点的时候看到过
点这个
来到实验3
3.2.3 多工具协作(fetch + filesystem)实现网页抓取写入 Obsidian
同时挂载 Fetch (联网) 和 Filesystem (本地读写) 两个工具。验证 AI 如何根据工具描述 (Description) 进行意图识别,自动在不同工具间切换。
实验目标:
- 配置 filesystem 工具(Hosted/Local),与 fetch 工具联动;
- 理解 MCP 工具路由机制,触发 "抓取 → 提取 → 写入" 自动化流程;
- 验证 Obsidian 笔记写入结果的正确性。
步骤1:获取 filesystem 工具配置
本次实验,我们将使用uvx直接运行@modelcontextprotocol/server-filesystem,因此不需要额外的安装步骤,只需要进行JSON文件的配置:
{"mcpServers": {"filesystem": {"command": "npx","args": ["-y","@modelcontextprotocol/server-filesystem","/home/wguo/Downloads/MyVault"]}}}
请参考实验2的步骤,将上述JSON配置文件导入到Clause Desktop、Cursor和Cherry Studio的 MCP 配置中。
额,补充友情提示:文件路径是要自己改的
步骤2:触发多工具路由并验证
输入以下 Prompt(替换 Obsidian 路径和目标网页):
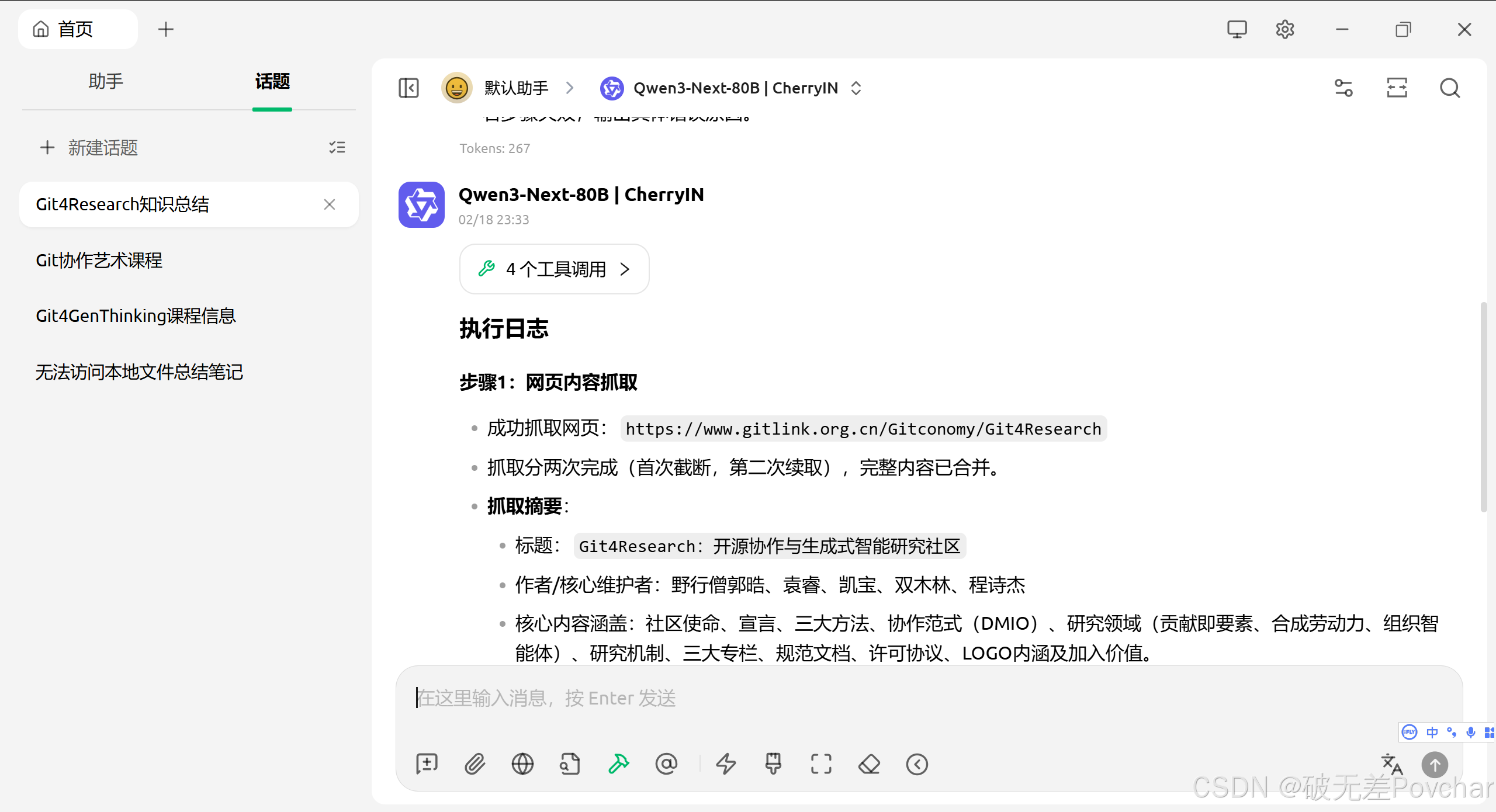
# 任务指令1. 调用 fetch 工具(@fetch-local),抓取网页:https://www.gitlink.org.cn/Gitconomy/Git4Research;2. 提取网页核心信息:标题、作者(如有)、核心知识点(整理为 Markdown 列表);3. 调用 filesystem 工具(@filesystem)将提取的内容写入 Obsidian 笔记:- 文件路径:/home/wguo/Downloads/MyVault/Tutorial.md;- 编码:utf-8;- 要求:写入前清空文件原有内容,格式为 Markdown,标题用 # 标注,知识点用- 标注。# 执行要求 - 严格按工具能力路由,先完成抓取再写入;- 输出执行日志,包括抓取结果摘要和写入状态;- 若步骤失败,输出具体错误原因。
依旧补充友情提示:文件路径是要自己改的
实验4
可以直接复制:
S (Role - 角色设定)
你是一位拥有文件系统权限的知识架构师。你擅长执行"Agentic Chunking"(代理式切片),并将切分后的原子化知识直接固化为本地文件。
C (Context - 语境背景)
我将提供一篇关于《2025年生成式AI数据工程》的长文本。
当前环境已挂载 `filesystem` 工具,你有权限在我的 `/Inbox` 目录下创建文件。
O (Objective - 任务目标)
请分析输入文本,识别出文中的核心概念(如特定的切片策略、架构模型),并**为每一个核心概念分别调用一次 `write_file` 工具**,将其保存为独立的原子化笔记。
R (Requirements - 工具调用契约)
**严禁**在对话框中直接输出 Markdown 正文。你必须严格遵守以下工具调用协议:
- **Action Protocol (动作协议)**:
识别出 N 个核心概念 = 调用 N 次 `write_file` 工具。
这是一个多步执行任务,请确保所有核心概念都被保存。
- **Parameter Constraints (参数约束)**:
`path`: 必须存储在 `/Inbox/` 目录下。文件名格式:`Atomic - {核心概念名}.md`。
`content`: 写入的内容必须是完整的 Markdown,且**首部必须包含 YAML Frontmatter**:
```yaml
type: atomic_note
source: GenAI_Report_2025
tags: AI, RAG, Chunking
created: {{date}}
```
- 正文结构:【定义/原理】->【优缺点/特征】->【核心公式/数据】。
- **Safety (安全边界)**:
文件名若包含特殊字符(如 `/`, `:`, `?`),请替换为 `-`。
确保内容进行了"去语境化"处理(De-contextualization),即代词"它"需替换为具体名词。
I (Input - 待处理文本)
{{\[Source-GenAI-Report-2025]}}
结束
教程制作不易,点个赞吧