1. 内存模型
1.1 系统的内存模型
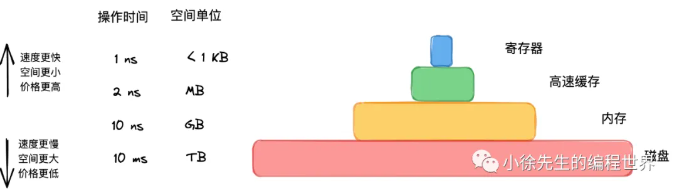
从上图我们可以看出在系统的内存模型中也采用的是分层结构
-
顶层:寄存器
- 操作时间:
1 ns(纳秒级) ------ 极快,几乎与 CPU 同频。 - 空间单位:
< 1 KB------ 容量极小。 - 说明: 位于 CPU 内部,用于存储 CPU 即将执行的指令和数据。
- 操作时间:
-
第二层:高速缓存 (Cache)
- 操作时间:
2 ns - 空间单位:
MB - 说明: 通常指 L1/L2/L3 缓存。它是 CPU 和内存之间的桥梁,利用局部性原理存储常用的数据,以减少 CPU 等待内存的时间。
- 操作时间:
-
第三层:内存 (Memory / RAM)
- 操作时间:
10 ns - 空间单位:
GB - 说明: 我们通常说的"内存条"(DRAM)。这是程序运行时数据的主要存放地。
- 操作时间:
-
底层:磁盘 (Disk)
- 操作时间:
10 ms(毫秒级) - 空间单位:
TB - 说明: 硬盘(机械硬盘 HDD 或 固态硬盘 SSD)。用于持久化存储数据。
- 关键点: 注意单位的变化!10 ms = 10,000,000 ns 。这意味着磁盘的操作速度比内存慢了100万倍(10^7 ns vs 10^1 ns)。这就是为什么在编程中,IO 操作(读写磁盘)往往是性能瓶颈的原因。
- 操作时间:
1.2 虚拟内存与物理内存
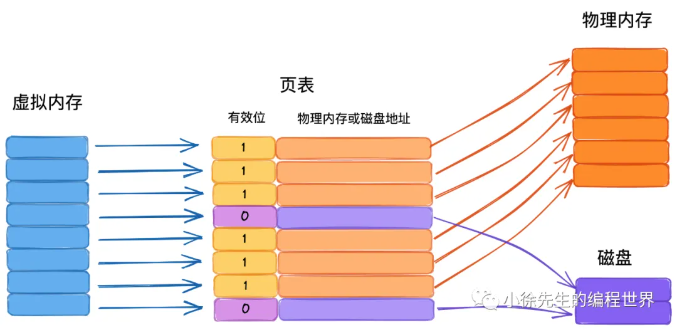
在物理上,你的电脑内存(RAM)可能只有 16GB,而且同时跑着微信、浏览器、Golang 或者是游戏。它们必须挤在这一块物理条子上。
但在虚拟内存空间里,操作系统告诉每个一个程序:
兄弟,这台电脑所有的内存地址都是你一个人用的,随便用,从0x0000到0xFFFF 都是你的
- 对程序来说:它的代码写起来比较简单,不用担心别人占用了地址,也不用关系物理内存地址是8G还是16G。
- 实际情况:程序以为自己拥有一整栋大楼,实际上他只拥有大楼里面的零碎的几个房间(物理页框)。
既然每个程序都以为自己有独占的空间,那么当 Go 程序说"我要读地址 0x1000 的数据"时,硬件 (MMU-内存管理单元) 和操作系统会进行配合:
- 虚拟地址:从go程序里面打印出来的指针地址,是假的,是一个逻辑地址
- 物理地址:这是数据真正在内存条上的电信号地址
- 页表:这就是那个 "映射表"。操作系统里面会记录着,Page1 对应 物理地内存的Page50
比喻: 你去住酒店(程序),前台(操作系统)给了你一张房卡,上面写着"1号房间"(虚拟地址)。
- 对你来说,你只认"1号"。
- 但实际上,酒店内部系统里,"1号"可能对应的是大楼的第 3 层第 5 间(物理地址)。
- 明天你再来,前台可能还是给你"1号卡",但这次可能对应第 8 层第 2 间。你不需要知道真实的房间号,只要卡能刷开就行。
虚拟内存空间允许程序申请比物理 RAM 更大的内存。怎么做到的?
如果你的 Go 程序申请了 20GB 内存,但物理内存只有 16GB:
- 操作系统会答应下来(分配虚拟空间)。
- 当你真正用到那些还没加载到 RAM 的数据时,操作系统会触发缺页中断 (Page Fault) 。
- 它会把 RAM 里暂时不用的数据踢到磁盘上(Swap/Pagefile),腾出空间。
- 然后再把你要的数据从磁盘读回 RAM。
理解要点:
- 如果你在两个不同进程里运行这段代码,它们甚至可能会打印出完全相同的地址。
- 在物理世界里面,同一个位置不可能存在两个不同的10。
- 虚拟表的作用:每个进程都有自己独立的映射表,互不干扰(隔离性)。
1.3 分页管理
操作系统中通常会将虚拟内存和物理内存切割成固定的尺寸,于虚拟内存而言叫作"页",于物理内存而言叫作"帧"。
为什么要有页?
"页" ( page ) 之所以存在,本质上是操作系统把内存管理做成了按 固定大小块 ( chunk ) 来管理。这样做能同时解决一堆现实问题;如果没有 Page ,虚拟内存几乎做不起来,或者非常复杂、非常慢。
虚拟内存要把一个进程看到的连续地址空间,映射到实际零散的物理内存上。
- 如果按照 "字节" 映射:每个字节都要一条映射记录,页表会大到不可用。
- 如果按照 "任意大小的段" 映射:每次分配或者回收要维护复杂的数据结构,容易碎片化,管理成本高
用 "页" (固定大小,比如 4KB、16KB) 映射
- 页表只需要记录 "每一页去哪里了" ,规模可控
- 硬件(MMU)也更容易用固定规则快速翻译地址。
用页管理的代价就是会有一点 "内存碎片",比如只用了1KB ,也可能占用 4KB 的一页。
linux 页/帧的大小固定,为 4KB(这实际是由实践推动的经验值,太粗会增加碎片率,太细会增加分配频率影响效率)
什么是外部碎片,内部碎片?
比喻:
外部碎片
-
场景:
- 酒店一共有 100 间房。
- 旅游团 A 住了 1-30 号房(占30间)。
- 旅游团 B 住了 50-80 号房(占30间)。
- 中间空着 31-49 号(20间),后面空着 81-100 号(20间)。
- 现在的状态: 总共空余 40 间房。
-
问题来了:
- 现在来了一个 30 人的旅游团 C,要求必须住在一起(连续内存地址) 。
- 虽然你总共有 40 个空位,但最大的连续空位只有 20 个。
- 结果: 旅游团 C 没法住进来。
-
这就是外部碎片: 内存里总的空闲空间足够大,但因为被零散地分割成了很多小块,导致无法分配给需要大块连续内存的进程。这些散落在已分配区域之外的、无法利用的空隙,就是外部碎片。
分页机制下,内存被切成了一块块 4KB 的标准积木。逻辑上连续的虚拟内存,在物理上可以随便放。
- 旅游团 C 要 30 间房?没问题,31-49号给你,81-91号也给你。
- 虽然物理上不在一起,但在"虚拟内存"的账本上,它们是连续的。
内部碎片
-
场景:
- 酒店规定:不按床位卖,只按房间卖。 一个房间(一页)有 4 张床(4KB)。
- 只要你来住,哪怕只有 1 个人,也得包下一整间房。
-
问题来了:
- 来了一个只有 1 个人的背包客(一个小进程,或者进程的最后一点数据)。
- 系统分配给他一个房间(4个床位)。
- 他睡了 1 张床,剩下的 3 张床空着。
- 但这间房已经被标记为"占用",别人不能进来。
-
这就是内部碎片: 已经被分配给进程的内存块(页)内部,有一部分空间根本没被利用,但系统也没法把它分给别人。这部分浪费在"房间内部"的空间,就是内部碎片。
1.4 Golang 内存模型
由于每次向操作系统申请内存的操作很重,那么不妨一次多申请一些,以备后用.
- 以空间换时间,一次缓存,多次复用
Golang 中的堆 mheap 正是基于该思想,产生的数据结构. 我们可以从两个视角来解决 Golang 运行时的堆:
-
对操作系统而言,这是用户进程中缓存的内存
-
对于 Go 进程内部,堆是所有对象的内存起源,堆是起点
• 多级缓存,实现无/细锁化
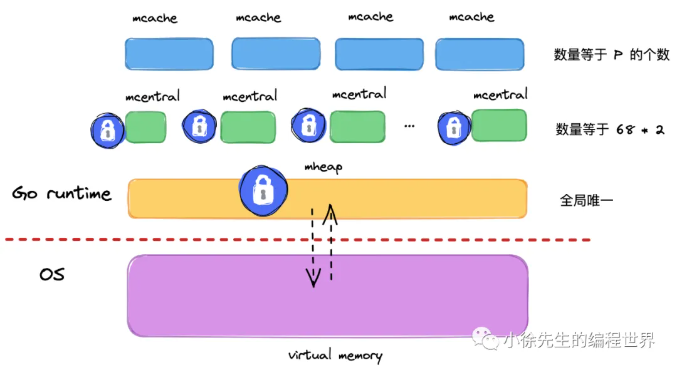
堆是 Go 运行时中最大的临界共享资源,这意味着每次存取都要加锁,在性能层面是一件很可怕的事情,每次都加锁获取,性能严重降低
为了解决"锁竞争"的问题,Go 模仿了现代 CPU 的 L1/L2/L3 缓存架构。在解决这个问题,Golang 在堆 mheap 之上,依次细化粒度,建立了 mcentral、mcache 的模型,下面对三者作个梳理:
-
L1 级:mcache (线程私有缓存)
- 地位: 就像你口袋里的零钱。
- 特点: 每个 P(Processor,可以理解为处理内存分配的 CPU 核心)独享一个 mcache。
- 优势: 完全无锁! 因为只有我一个人能动我口袋里的钱。分配速度极快。
- 缺点: 容量小。
-
L2 级:mcentral (中心缓存)
- 地位: 就像部门的"小金库"。
- 特点: 归所有 P 共享。
- 机制: 需要加锁,但锁的粒度较细。当 mcache 没钱了,就来这里按"批发价"拿一组内存走。
-
L3 级:mheap (全局堆)
- 地位: 银行总部。
- 特点: 全局唯一的。直接管辖整个堆内存。
- 职责: 向操作系统申请一大块虚拟内存(比如 64MB),切分好,交给 mcentral。我们之前讨论的
pallocSum和Radix Tree就在这一层工作。
这些概念,我们在第 2 节中都会再作详细展开,此处可以先不深究,注重于宏观架构即可.
• 多级规格,提高利用率
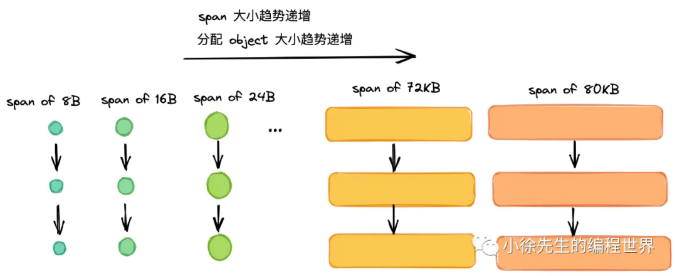
Go 的内存世界是由"页"组成的。首先理下 page 和 mspan 两个概念:
(1)page:最小的存储单元.
Golang 借鉴操作系统分页管理的思想,每个最小的存储单元也称之为页 page,但大小为 8 KB
(2)mspan:最小的管理单元.
mspan 大小为 page 的整数倍,且从 8B 到 80 KB 被划分为 67 种不同的规格,分配对象时,会根据大小映射到不同规格的 mspan,从中获取空间.
它的名字叫 span(跨度),意思是它跨越 了几个连续的"页"。一个 mspan 是由 1 个或多个连续的 Go Page 组成的内存块。
于是,我们回头小节多规格 mspan 下产生的特点:
-
根据规格大小,产生了等级的制度
-
消除了外部碎片,但不可避免会有内部碎片
-
宏观上能提高整体空间利用率
-
正是因为有了规格等级的概念,才支持 mcentral 实现细锁化
mspan 结构体里有两个非常重要的字段:
-
nelems:这里面总共有多少个格子?(比如 256 个) -
allocBits (位图) :这是一个一连串的0 和1。- 第 0 位是
1→\rightarrow→ Object0 已经被占用了。 - 第 1 位是
0→\rightarrow→ Object1 是空的,可以分配!
- 第 0 位是
可以用一个 "公司报销流程" 的生活化比喻来对应 mcache、mcentral 和 mheap。
假设你是一个员工(Goroutine),你需要申请办公用品(内存)。
1. mcache:你工位旁边的"备品盒"
-
对应角色: 每个 P(处理器)独有的本地缓存。
-
场景: 你需要一支笔(分配一个小对象)。
-
操作: 你直接伸手去工位旁边的盒子里拿。
-
特点:
- 无锁 (Lock-free): 因为这个盒子只有你(当前在 P 上运行的 G)能碰,别人碰不到,所以不需要申请,不需要填表,不需要排队,速度最快。
- 微观管理: 盒子里按大小分类放好了(比如笔放一格、本子放一格),这对应了不同的 跨度类 (Span Class) 。
2. mcentral:部门的"物资柜"
-
对应角色: 中心缓存,按规格分类。
-
场景: 你工位盒子里的笔用完了。
-
操作: 你走到部门的物资柜去拿一整盒笔(一个 Span)回来补充到你的工位盒子里。
-
特点:
- 细粒度锁 (Fine-grained Lock): 物资柜是大家共享的,所以需要排队(加锁)。但是,Go 把物资柜做了拆分: "笔柜"、"本子柜"、"订书机柜"是分开的(68种规格) 。
- 你要拿笔,只需要锁"笔柜";与此同时,同事小王要拿本子,他锁"本子柜"。你们互不影响。
- 这大大减少了竞争,比所有东西都锁在一个大仓库里要快得多。
3. mheap:总公司的"总仓库"
-
对应角色: 全局堆,内存的源头。
-
场景: 部门物资柜里的笔也发光了。
-
操作: 部门管理员向总公司仓库申请进货。总仓库不仅要给"笔柜"补货,还要应付其他部门的请求,甚至要向外部供应商(操作系统 OS)采购原材料。
-
特点:
- 全局锁 (Global Lock): 这里是流量汇聚点,必须严格控制,加一把大锁。
- 代价最高: 竞争最激烈,处理最慢。
- 兜底机制: 只有前两级缓存都搞不定时,才会走到这里。Go 的设计目标就是尽量让 99% 的内存分配都在 mcache 和 mcentral 解决,极少触碰 mheap。
从下往上(申请内存):
- Goroutine (代码) 需要内存。
- 先看 mcache (本地无锁):有吗?有就直接拿走。 (最快,纳秒级)
- 没有?去 mcentral (分类有锁):申请一个 Span (一大块内存) 拿回 mcache 切着用。
- 还不行?去 mheap (全局大锁):申请一大块 Arena,切分好给 mcentral。
- 实在不行?找 OS (操作系统):系统调用,申请物理内存。
为什么要这么设计? 这就是典型的 "空间换时间" 策略。
- 如果每次分配内存都要去抢
mheap的那把大锁,多核 CPU 并发执行时,大部分时间都在等待锁释放 ,性能会随着 CPU 核数增加而下降。 - 通过
mcache,Go 实现了在 P 的本地无锁分配,这使得 Go 在高并发下创建小对象(比如局部变量逃逸)的代价极低,这也是 Go 适合高并发服务的重要原因之一。
• 全局总览,留个印象
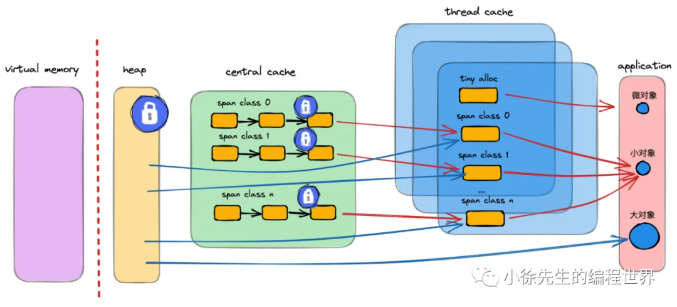
上图是 Thread-Caching Malloc 的整体架构图,Golang 正是借鉴了该内存模型. 我们先看眼架构,有个整体概念,后续小节中,我们会不断对细节进行补充.
2 核心概念梳理
2.1 内存单元 mspan
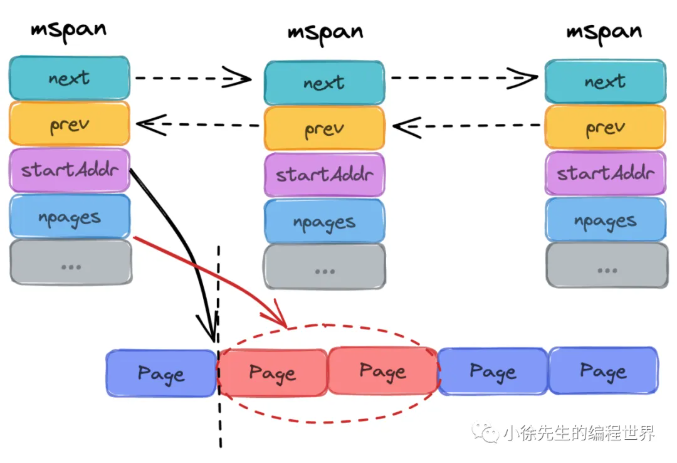
分点阐述 mspan 的特质:
-
mspan 是 Golang 内存管理的最小单元
mheap 在分配内存时,不会给你"半个"mspan。它要么给你一整个mspan,要么不给。
mspan 结构体里记录了非常关键的信息:比如这块内存是从哪开始的(startAddr)、包含几个页(npages)、里面对象的大小(elemsize)等。没有这些元数据,GC(垃圾回收)就不知道这块内存里存的是什么。 -
mspan 大小是 page 的整数倍(Go 中的 page 大小为 8KB),且内部的页是连续的(至少在虚拟内存的视角中是这样)
因为页是连续的,只要知道 startAddr,加上偏移量就能算出任何一个 Object 的地址。虽然物理内存可能支离破碎,但在虚拟地址空间 中,Go 要求一个
mspan 内的页必须是连续的。这极大地方便了指针运算。 -
每个 mspan 根据空间大小以及面向分配对象的大小,会被划分为不同的等级(2.2小节展开)
如果随机分配大小,内存会像"狗啃的"一样,到处是无法利用的小缝隙。Go 预设了约 67 种规格(加上 0 级的特殊规格)
-
同等级的 mspan 会从属同一个 mcentral,最终会被组织成链表,因此带有前后指针(prev、next)
同一种规格的
mspan 就像同一类商品。mcentral 挂载两个链表:- Partial 链表: 还有空位的
mspan。 - Full 链表: 已经装满的
mspan。
当 mcache 缺货时,mcentral 从 Partial 链表里摘下一个 mspan 递过去;当 mspan 里的对象被 GC 回收变空后,它又会被重新挂回 Partial 链表。
- Partial 链表: 还有空位的
-
由于同等级的 mspan 内聚于同一个 mcentral,所以会基于同一把互斥锁管理
每个规格一把锁。你申请 8B 的内存(锁 1 号 mcentral),我申请 16B 的内存(锁 2 号 mcentral),我们并行执行。这在高并发场景下是巨大的性能优势。
-
mspan 会基于 bitMap 辅助快速找到空闲内存块(块大小为对应等级下的 object 大小),此时需要使用到 Ctz64 算法.
mspan 内部维护一个 64 位的整数(通常是allocCache)。每一位0 代表空闲,1 代表已分配。
2.2 内存单元等级 spanClass
mspan 根据空间大小和面向分配对象的大小,被划分为 67 种等级(1-67,实际上还有一种隐藏的 0 级,用于处理更大的对象,上不封顶)
下表展示了部分的 mspan 等级列表,数据取自 runtime/sizeclasses.go 文件中:
| class | bytes/obj | bytes/span | objects | tail waste | max waste |
|---|---|---|---|---|---|
| 1 | 8 | 8192 | 1024 | 0 | 87.50% |
| 2 | 16 | 8192 | 512 | 0 | 43.75% |
| 3 | 24 | 8192 | 341 | 8 | 29.24% |
| 4 | 32 | 8192 | 256 | 0 | 21.88% |
| ... | |||||
| 66 | 28672 | 57344 | 2 | 0 | 4.91% |
| 67 | 32768 | 32768 | 1 | 0 | 12.50% |
对上表各列进行解释:
(1)class:mspan 等级标识,1-67
(2)bytes/obj:该大小规格的对象会从这一 mspan 中获取空间. 创建对象过程中,大小会向上取整为 8B 的整数倍,因此该表可以直接实现 object 到 mspan 等级 的映射
(3)bytes/span:该等级的 mspan 的总空间大小
(4)object:该等级的 mspan 最多可以 new 多少个对象,结果等于 (3)/(2)
(5)tail waste:(3)/(2)可能除不尽,于是该项值为(3)%(2)
(6)max waste:通过下面示例解释:
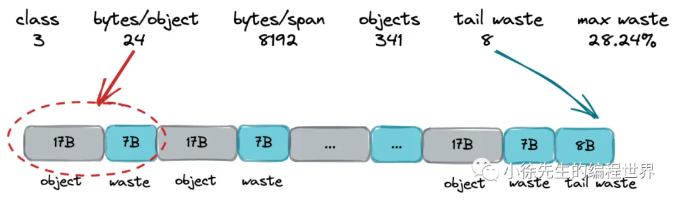
以 class 3 的 mspan 为例,class 分配的 object 大小统一为 24B,由于 object 大小 <= 16B 的会被分配到 class 2 及之前的 class 中,因此只有 17B-24B 大小的 object 会被分配到 class 3.
最不利的情况是,当 object 大小为 17B,会产生浪费空间比例如下:
((24-17)*341 + 8)/8192 = 0.292358 ≈ 29.24%除了上面谈及的根据大小确定的 mspan 等级外,每个 object 还有一个重要的属性叫做 nocan,标识了 object 是否包含指针,在 gc 时是否需要展开标记。
Go 为了加速垃圾回收(GC),把每种规格又拆分成了两种:
- scan span(含指针): 这个托盘里的对象包含指针(比如结构体里有个字段是
*int)。GC 必须扫描它,看看它指向哪里。 - noscan span(不含指针): 这个托盘里的对象全是纯数字、布尔值(比如
int,byte)。GC 可以直接无视它,因为它不可能引用别的对象。
在 Golang 中,会将 span class + nocan 两部分信息组装成一个 uint8,形成完整的 spanClass 标识. 8 个 bit 中,高 7 位表示了上表的 span 等级(总共 67 + 1 个等级,8 个 bit 足够用了),最低位表示 nocan 信息.
2.3 线程缓存 mcache
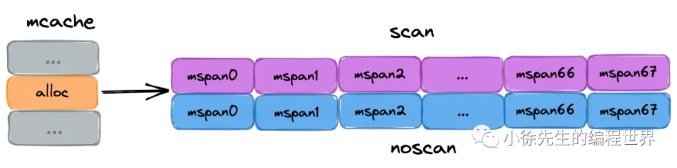
要点:
(1)mcache 是每个 P 独有的缓存,因此交互无锁
(2)mcache 将每种 spanClass 等级的 mspan 各缓存了一个,总数为 2(nocan 维度) * 68(大小维度)= 136
(3)mcache 中还有一个为对象分配器 tiny allocator,用于处理小于 16B 对象的内存分配,在 3.3 小节中详细展开.
2.4 中心缓存 mcentral
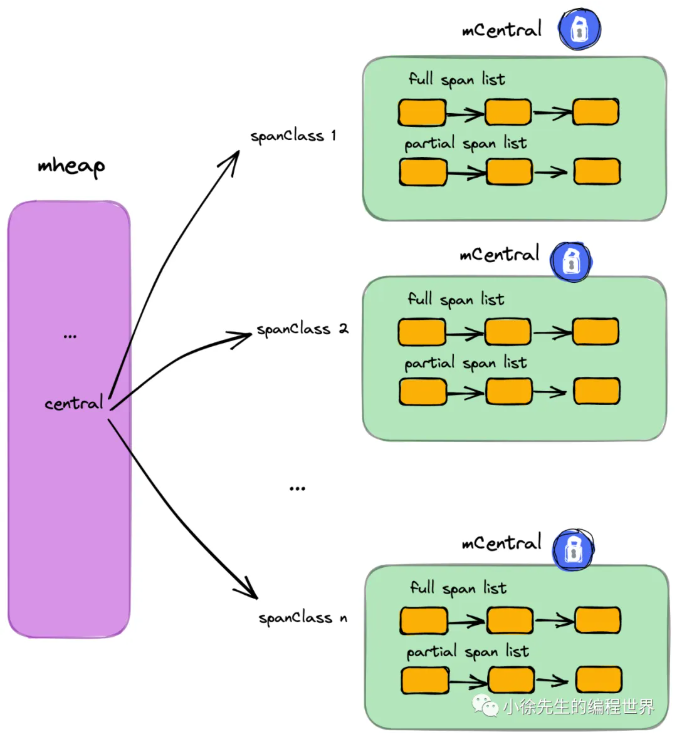
要点:
(1)每个 mcentral 对应一种 spanClass
(2)每个 mcentral 下聚合了该 spanClass 下的 mspan
(3)mcentral 下的 mspan 分为两个链表,分别为有空间 mspan 链表 partial 和满空间 mspan 链表 full
(4)每个 mcentral 一把锁
-
系统里有 136 种
mspanclass(68种大小 ×\times× 2种是否包含指针)。 -
因此: 全局就有 136 个
mcentral 结构体。 -
专职专责:
- 管理"8字节"的那个
mcentral,绝对不会 去碰"16字节"的mspan。 - 它就像是一个专卖店仓库:卖鞋的仓库只管鞋,卖衣服的仓库只管衣服。
- 管理"8字节"的那个
2.5 全局堆缓存 mheap
要点:
- 对于 Golang 上层应用而言,堆是操作系统虚拟内存的抽象
- 以页(8KB)为单位,作为最小内存存储单元
- 负责将连续页组装成 mspan
- 全局内存基于 bitMap 标识其使用情况,每个 bit 对应一页,为 0 则自由,为 1 则已被 mspan 组装
- 通过 heapArena 聚合页,记录了页到 mspan 的映射信息(2.7小节展开)
- 建立空闲页基数树索引 radix tree index,辅助快速寻找空闲页(2.6小节展开)
- 是 mcentral 的持有者,持有所有 spanClass 下的 mcentral,作为自身的缓存
- 内存不够时,向操作系统申请,申请单位为 heapArena(64M)
2.6 空闲页索引 pageAlloc
与 mheap 中,与空闲页寻址分配的基数树索引有关的内容较为晦涩难懂. 网上能把这个问题真正讲清楚的文章几乎没有.
所幸我最后找到这个数据结构的作者发布的笔记,终于对方案的原貌有了大概的了解,这里粘贴链接,供大家自取:https://go.googlesource.com/proposal/+/master/design/35112-scaling-the-page-allocator.md
要理清这棵技术树,首先需要明白以下几点:
(1)数据结构背后的含义:
I 2.5 小节有提及,mheap 会基于 bitMap 标识内存中各页的使用情况,bit 位为 0 代表该页是空闲的,为 1 代表该页已被 mspan 占用.
II 每棵基数树聚合了 16 GB 内存空间中各页使用情况的索引信息,用于帮助 mheap 快速找到指定长度的连续空闲页的所在位置
III mheap 持有 2^14 棵基数树,因此索引全面覆盖到 2^14 * 16 GB = 256 T 的内存空间.
(2)基数树节点设定
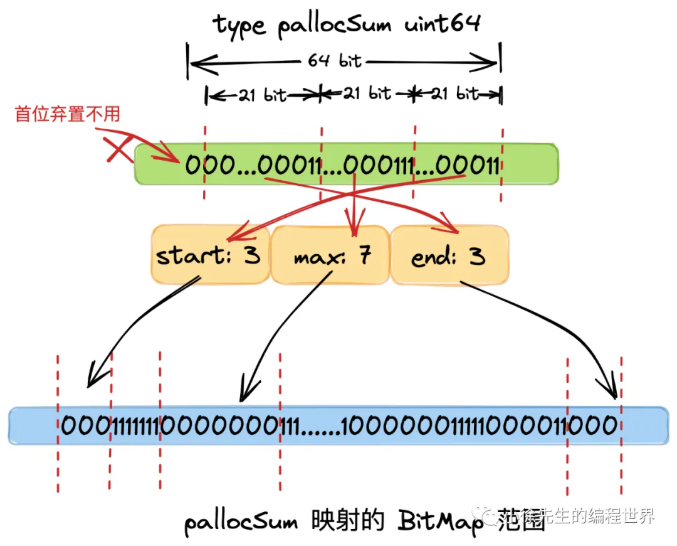
基数树中,每个节点称之为 PallocSum,是一个 uint64 类型,体现了索引的聚合信息,包含以下四部分:
- start:最右侧 21 个 bit,标识了当前节点映射的 bitMap 范围中首端有多少个连续的 0 bit(空闲页),称之为 start;
- max:中间 21 个 bit,标识了当前节点映射的 bitMap 范围中最多有多少个连续的 0 bit(空闲页),称之为 max;
- end:左侧 21 个 bit,标识了当前节点映射的 bitMap 范围中最末端有多少个连续的 0 bit(空闲页),称之为 end.
- 最左侧一个 bit,弃置不用
一个PallocSum管理1个Chunk,Chunk 就是蓝色部分的。一个Chunk 管理512页 ,然后使用bitmap来识别,页 是否被使用了。Chunk 不存储页面(Page)本身,它只存储页面的状态(0 或 1)。
Chunk 就是 Bitmap(位图)。
因为这个 Bitmap 刚好有 512 个 bit。
而每个 bit 唯一对应物理内存中的 1 个 Page。
Chunk 是一个 "状态记录表" ,它监控着 512 个物理页。
因为 Chunk 虽然只是位图,但它还是有 512 个 bit(64 字节)。
如果要判断"这里面有没有 5 个连续空位",CPU 还是得去扫描这 512 个位,虽然比扫描整个内存快,但还是不够快(需要几十个时钟周期)。所以需要进一步PallocSum
(3)父子关系
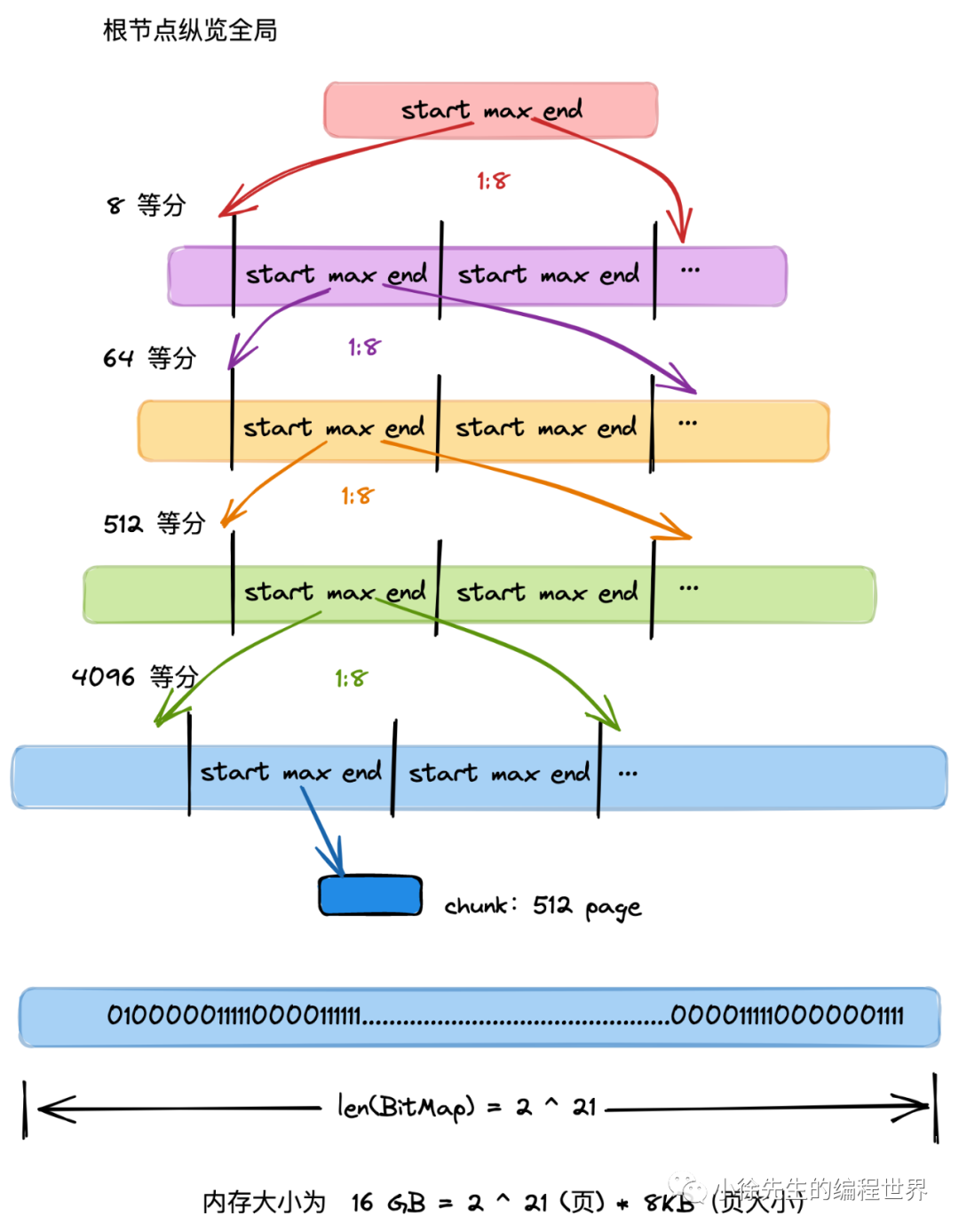
- 每个父 pallocSum 有 8 个子 pallocSum
- 根 pallocSum 总览全局,映射的 bitMap 范围为全局的 16 GB 空间(其 max 最大值为 2^21,因此总空间大小为 2^21*8KB=16GB);
- 从首层向下是一个依次八等分的过程,每一个 pallocSum 映射其父节点 bitMap 范围的八分之一,因此第二层 pallocSum 的 bitMap 范围为 16GB/8 = 2GB,以此类推,第五层节点的范围为 16GB / (8^4) = 4 MB,已经很小
- 聚合信息时,自底向上. 每个父 pallocSum 聚合 8 个子 pallocSum 的 start、max、end 信息,形成自己的信息,直到根 pallocSum,坐拥全局 16 GB 的 start、max、end 信息
- mheap 寻页时,自顶向下. 对于遍历到的每个 pallocSum,先看起 start 是否符合,是则寻页成功;再看 max 是否符合,是则进入其下层孩子 pallocSum 中进一步寻访;最后看 end 和下一个同辈 pallocSum 的 start 聚合后是否满足,是则寻页成功.
-
Go 选择了 8 作为基数(Radix)。
-
这意味着一个父节点的
start/max/end 摘要信息,是由底下 8 个 子节点的摘要信息汇总而来的。 -
这种设计可以让树变得很扁(只有 5 层)。如果用二叉树(1:2),树会变得非常高,查找就要跳很多次内存,速度就慢了。
-
计算验证:
- L4 (Root): 1 个节点
- L3: 1×8=81 \times 8 = 81×8=8
- L2: 8×8=648 \times 8 = 648×8=64
- L1: 64×8=51264 \times 8 = 51264×8=512
- L0: 512×8=4096512 \times 8 = 4096512×8=4096
这 4096 个 L0 节点,正好对应最底下的 4096 个 Chunk。
查找流程
寻找内存的过程,就是一个 "从上帝视角逐层放大,最终锁定目标" 的过程,非常像你在 Google 地图中找一家餐馆:从"市" -> "区" -> "街道" -> "门牌号"。
假设我们需要申请 N 个连续的页(比如 N=10)。
整个流程可以分为三个阶段:宏观过滤(快速跳过) -> 定位区域(逐层下钻) -> 微观锁定(位图扫描)。
第一阶段:宏观过滤(上帝视角)
分配器先看一眼金字塔最顶端(Root, L4)的那一个 pallocSum。
-
问: "老大,整个堆内存里,最大的连续空地(Root.max)有 10 个位吗?"
-
判断:
- 如果
Root.max < 10:直接返回失败 (OOM) 。不用往下找了,全公司都没这么大的地儿。 - 如果
Root.max >= 10:有戏! 肯定在下面某个地方,准备下钻。
- 如果
第二阶段:定位区域(雷达扫描与下钻)
这是最精彩的"剪枝"过程。我们不需要遍历所有内存,我们利用 Radix Tree 的特性来走捷径。
算法逻辑(从上往下,L4 -> L3 -> ... -> L1):
假设我们现在在 L4 层,手里有 8 个子节点(L3 的摘要)。我们要找这 8 个孩子里,谁能接下这个"10 页的大单"。
-
扫描子节点: 从左到右(或者从上次扫描的位置开始)检查这 8 个子节点的
pallocSum。 -
核心判断(剪枝):
- 看一眼
Child[0].max。 - 如果
Child[0].max < 10:直接跳过! 哪怕 Child0 里面有很多零散空位,但它凑不出连续的 10 个,进去也是白费功夫。 - 如果
Child[1].max >= 10:找到了! 目标就在 Child1 管辖的区域里。
- 看一眼
-
下钻: 锁定 Child1,我们要进入下一层(L3),去 Child1 的地盘里继续找。
重复这个过程:
- 在 L3 层,看它的 8 个 L2 孩子,找到
max >= 10的那个,跳进去。 - 在 L2 层,看它的 8 个 L1 孩子,找到
max >= 10的那个,跳进去。 - 在 L1 层,看它的 8 个 L0 孩子(也就是指向 Chunk 的那一层),找到
max >= 10的那个。
这一步的威力:
想象一下,如果没有这个树,你需要扫描内存。有了这个树,如果内存前面的 100GB 都是碎的(max 都很小),CPU 只要看几个数字就能把这 100GB 瞬间跳过,直接降落在后面有空地的地方。
第三阶段:微观锁定(巷战)
现在我们已经"降落"到了最底层:L0 层 。
我们要面对真正的 Chunk(位图) 了。
我们知道这个 Chunk 的 pallocSum.max >= 10,说明这里面一定 有 10 个连续的 0。现在的任务是找到它们具体在第几位。
-
加载位图: 把这个 Chunk 的 512 bit(64 字节)读进 CPU。
-
位运算搜索:
- 利用 CPU 的硬件指令(如
CTZ- Count Trailing Zeros 或专门的位操作算法),快速扫描这 512 个位。 - 寻找连续 10 个
0的起始位置。
- 利用 CPU 的硬件指令(如
-
最终操作:
- 找到位置(比如从第 100 位开始)。
- 修改位图: 把第 100 到 109 位,从
0改成1(标记为已占用)。 - 更新摘要: 这一步极其重要!因为你改了底层位图,所以这个 Chunk 的
pallocSum变了(max 可能变小了)。你需要把这个变化一层层向上传递(Re-summarize) ,更新 L1, L2... 直到 Root,保证地图的准确性。
一个特殊的疑问:如果空地"跨界"了怎么办?
你可能会问: "如果我要 10 个页,Chunk A 的尾巴有 5 个空位,Chunk B 的头有 5 个空位,它俩连在一起正好 10 个。但我单独查 A 的 max 是 5,查 B 的 max 也是 5,会不会被跳过?"
答案是:不会错过!
这就是上一轮对话中 "合并逻辑" 的功劳。
当 L1 层(Chunk A 和 B 的父节点)在计算自己的 pallocSum 时,它会执行:
L1.max = max(A.max, B.max, A.end + B.start)
因为 A.end=5, B.start=5,所以 A.end + B.start = 10。
L1 的 max 会变成 10。
搜索流程如下:
- 搜索算法来到 L1 层。
- 它看到
L1.max = 10,满足条件,于是决定进入这个 L1 节点。 - 进入后,它会发现没有任何一个单个子节点满足 10。
- 这时候算法会检查 "边界跨越" 的情况(Go 的代码里有专门处理 straddle 的逻辑,或者通过 search 索引定位)。
- 它会发现 Child A 的尾巴和 Child B 的头正好凑齐,从而锁定这个跨界的位置。
总结全流程
- Root 问诊: 有没有足够大的空地?(没有直接挂)。
- 树上跑酷: 沿着
max >= N的路径,一路狂奔下楼,无视所有空间不足的分支。 - 落地巷战: 找到 Chunk,通过位运算精确定位。
- 修改汇报: 占坑,修改位图,并通知上级更新"地图"。
2.7 heapArena
heapArena 就是 Go 堆内存管理的"物业档案室" 。在 Go 的内存架构里,它解决了两个极其重要的问题: "这块内存归谁管?" 和 "垃圾回收(GC)怎么扫它?"
在 64 位系统(Linux/Windows)下,一个 heapArena 通常管理 64MB 的连续内存空间。
Go 的堆(Heap)并不是一开始就申请一大整块内存,而是按需向操作系统申请。每申请一块大的(通常是 64MB),就会创建一个 heapArena 结构体来管理这块地。每个 heapArena 包含 8192 个页,大小为 8192 * 8KB = 64 MB
heapArena 结构体里最关键的两个字段,分别对应了 内存映射 和 垃圾回收:
A. spans 数组(最重要的索引)
-
作用: "给定一个内存地址,告诉我它属于哪个对象(mspan)?"
-
场景: 当你在代码里
free 一个指针,或者 GC 扫描到一个指针时,Go 只有这个指针的内存地址(比如0xc000010080)。Go 怎么知道这个地址是 8 字节的小对象,还是 32KB 的大对象? -
原理: Go 会拿着地址找到对应的
heapArena,然后查里面的spans 数组。- 这是一个巨大的指针数组。
- 它建立了 Page(页) -> mspan(跨度类) 的映射。
- 就像查户口本一样: "第 5 页属于 mspan A,第 6 页也属于 mspan A..."
B. bitmap (GC 的藏宝图)
-
作用: "这块内存里,哪里是指针,哪里是纯数字?"
-
场景: 垃圾回收器(GC)在扫描内存时,必须知道内存里的数据到底是"指向另一个对象的指针"(需要继续扫描),还是仅仅是一个"数值 12345"(不需要扫描)。
-
原理:
heapArena 里有一块bitmap 区域。- 每 8 字节(一个字)的内存,对应 bitmap 里的几个 bit。
- 如果 bit 是 1,说明这里存的是指针;如果是 0,说明是标量。
在 64 位系统下,Go 的堆内存可以非常大,而且不一定是连续的。
Go 维护了一个 二维数组 来管理所有的 heapArena:mheap_.arenas [L1][L2]*heapArena
- 这就像一个巨大的 世界地图网格。
- 整个虚拟内存空间被切成无数个 64MB 的方块。
- 如果我们用到了某个 64MB 的空间,就分配一个
heapArena结构体填进去。 - 如果没用到,那个格子里就是
nil。
2.8 整个流程
1. 启动阶段 (Setup)
- Go 程序启动,向操作系统申请一大块虚拟内存。
- 初始化
mheap全局堆。
2. 申请阶段 (Allocation)
-
你写了代码:
p := new(int64) // 需要 8 字节 -
计算规格: 8 字节对应
size class 1。 -
L1 mcache: 当前 P(处理器)看看自己本地缓存的
mspan 有没有空位?- 有 →\rightarrow→ 标记位图,直接返回地址。(无锁,最快)
- 没有 →\rightarrow→ 去找 L2。
-
L2 mcentral: 找到管理 8 字节规格的中心缓存。
- 加锁,从链表里拿一个有空位的
mspan给 mcache。 - 没有 →\rightarrow→ 去找 L3。
- 加锁,从链表里拿一个有空位的
-
L3 mheap: 需要申请新的物理页。
- Radix Tree & pallocSum: 快速在基数树里找到连续的空闲页(Chunk)。
- 将这些页包装成一个新的
mspan,写入heapArena的元数据映射。 - 一路返回给 mcentral -> mcache -> 用户。
3. 回收阶段 (GC & Free)
- GC 扫描: 拿到一个指针。
- 反查 Arena: 通过地址计算出 Arena 索引,查表找到所属的
mspan。 - 标记: 确认对象存活。
- 清扫: GC 结束后,没被标记的对象对应的位图置为 0。
- 归还: 如果
mspan全空了,还给mheap。mheap尝试把空闲页合并,留给下次分配大对象使用。
Go 内存分配器的设计哲学是计算机科学中 "空间换时间" 与 "分层解耦" 的极致体现:
- TCMalloc 思想 :通过 mcache 消除锁竞争,实现极致的高并发分配性能。
- 隔离 (Segregation) :通过 Size Class 让大小相似的对象聚在一起,消灭了外部碎片。
- 多级缓存:从线程私有,到全局分类,再到全局大堆,层层递进。
- 位图与树 :用 Bitmap 管理微观状态,用 Radix Tree 管理宏观索引。
3 对象分配流程
下面来串联 Golang 中分配对象的流程,不论是以下哪种方式,最终都会殊途同归步入 mallocgc 方法中,并且根据 3.1 小节中的策略执行分配流程:
- new(T)
- &T{}
- make(xxxx)
3.1 分配流程总览
Golang 中,依据 object 的大小,会将其分为下述三类:
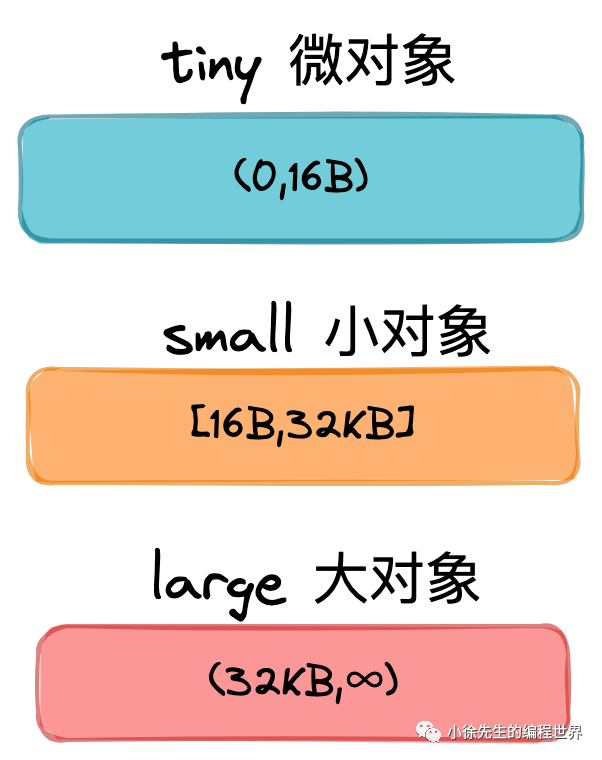
不同类型的对象,会有着不同的分配策略,这些内容在 mallocgc 方法中都有体现.
核心流程类似于读多级缓存的过程,由上而下,每一步只要成功则直接返回. 若失败,则由下层方法兜底.
对于微对象的分配流程:
(1)从 P 专属 mcache 的 tiny 分配器取内存(无锁)
(2)根据所属的 spanClass,从 P 专属 mcache 缓存的 mspan 中取内存(无锁)
(3)根据所属的 spanClass 从对应的 mcentral 中取 mspan 填充到 mcache,然后从 mspan 中取内存(spanClass 粒度锁)
(4)根据所属的 spanClass,从 mheap 的页分配器 pageAlloc 取得足够数量空闲页组装成 mspan 填充到 mcache,然后从 mspan 中取内存(全局锁)
(5)mheap 向操作系统申请内存,更新页分配器的索引信息,然后重复(4).
对于小对象的分配流程是跳过(1)步,执行上述流程的(2)-(5)步;
对于大对象的分配流程是跳过(1)-(3)步,执行上述流程的(4)-(5)步.
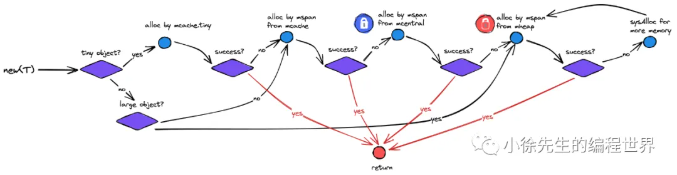
3.2 主干方法 mallocgc
先上道硬菜,malloc 方法主干全流程展示.
如果觉得理解曲线太陡峭,可以先跳到后续小节,把拆解的各部分模块都熟悉后,再回过头来总览一遍.
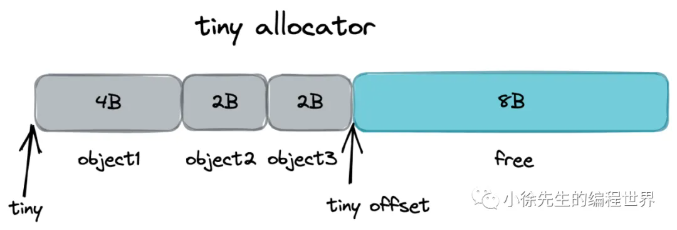
3.3 步骤(1):tiny 分配
每个 P 独有的 mache 会有个微对象分配器,基于 offset 线性移动的方式对微对象进行分配,每 16B 成块,对象依据其大小,会向上取整为 2 的整数次幂进行空间补齐,然后进入分配流程.
4 参考
https://mp.weixin.qq.com/s/2TBwpQT5-zU4Gy7-i0LZmQ 小徐先生