首先描述一下ceph数据的存储过程,如下图:
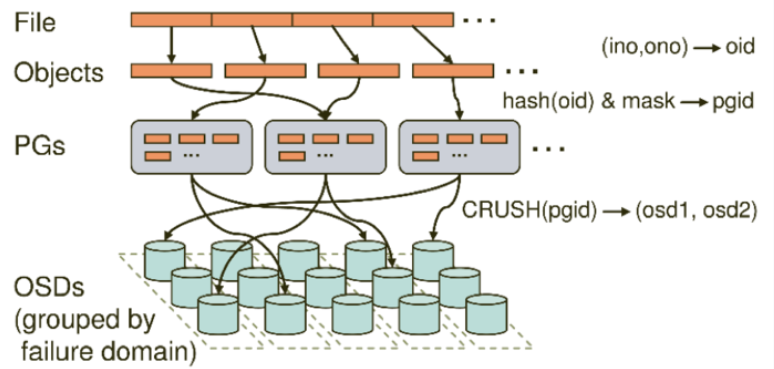
无论使用哪种存储方式(对象、块、挂载),存储的数据都会被切分成对象(Objects)。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino与ono生成,虽然这些名词看上去很复杂,其实相当简单。ino即是文件的File ID,用于在全局唯一标示每一个文件,而ono则是分片的编号。比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。Oid的好处是可以唯一标示每个不同的对象,并且存储了对象与文件的从属关系。由于ceph的所有数据都虚拟成了整齐划一的对象,所以在读写时效率都会比较高
但是对象并不会直接存储进OSD中,因为对象的size很小,在一个大规模的集群中可能有几百到几千万个对象。这么多对象光是遍历寻址,速度都是很缓慢的;并且如果将对象直接通过某种固定映射的哈希算法映射到osd上,当这个osd损坏时,对象无法自动迁移至其他osd上面(因为映射函数不允许)。为了解决这些问题,ceph引入了归置组的概念,即PG。
PG是一个逻辑概念,我们linux系统中可以直接看到对象,但是无法直接看到PG。它在数据寻址时类似于数据库中的索引:每个对象都会固定映射进一个PG中,所以当我们要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG就可以了,无需遍历所有对象。而且在数据迁移时,也是以PG作为基本单位进行迁移,ceph不会直接操作对象。
对象时如何映射进PG的?还记得OID么?首先使用静态hash函数对OID做hash取出特征码,用特征码与PG的数量去模,得到的序号则是PGID。由于这种设计方式,PG的数量多寡直接决定了数据分布的均匀性,所以合理设置的PG数量可以很好的提升CEPH集群的性能并使数据均匀分布。
最后PG会根据管理员设置的副本数量进行复制,然后通过crush算法存储到不同的OSD节点上(其实是把PG中的所有对象存储到节点上),第一个osd节点即为主节点,其余均为从节点。
下面是一段ceph中的伪代码,简要描述了ceph的数据存储流程
locator = object_name
obj_hash = hash(locator)
pg = obj_hash % num_pg
osds_for_pg = crush(pg) # returns a list of osds
primary = osds_for_pg[0]
replicas = osds_for_pg[1:]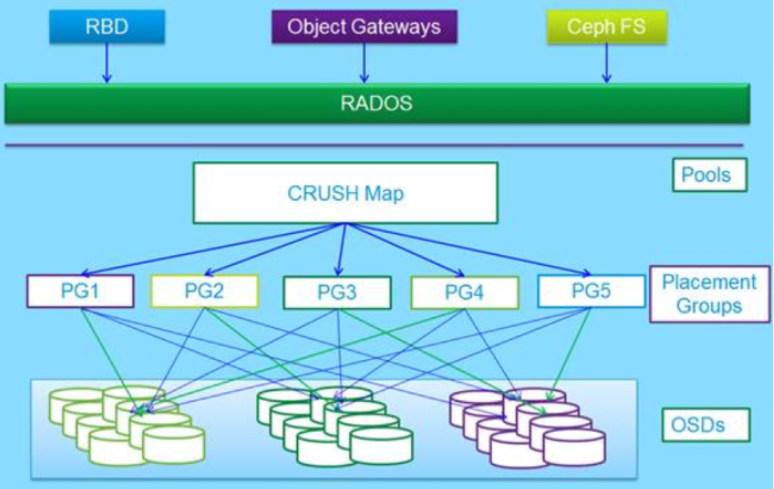
上图中更好的诠释了ceph数据流的存储过程,数据无论是从三中接口哪一种写入的,最终都要切分成对象存储到底层的RADOS中。逻辑上通过算法先映射到PG上,最终存储近OSD节点里。图中除了之前介绍过的概念之外多了一个pools的概念
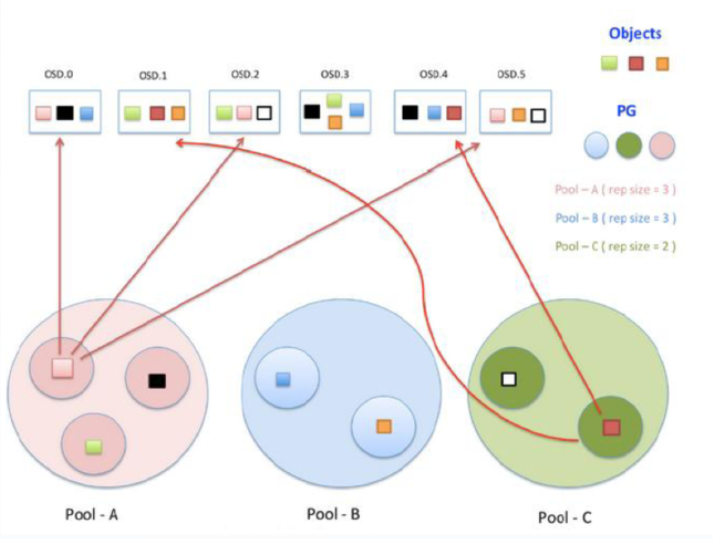
Pool是管理员自定义的命名空间,像其他的命名空间一样,用来隔离对象与PG。我们在调用API存储即使用对象存储时,需要指定对象要存储进哪一个POOL中。除了隔离数据,我们也可以分别对不同的POOL设置不同的优化策略,比如副本数、数据清洗次数、数据块及对象大小等
OSD是强一致性的分布式存储,它的读写流程如下图
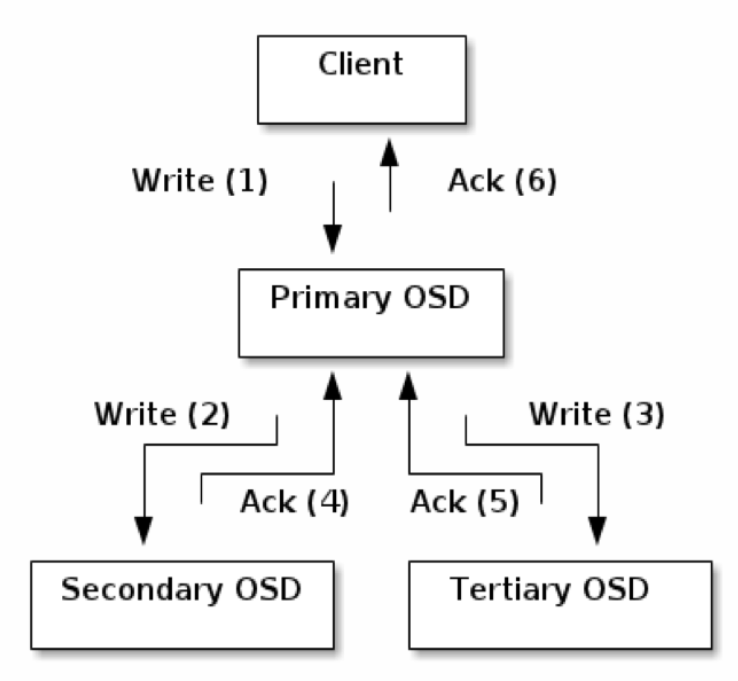
Ceph的读写操作采用主从模型,客户端要读写数据时,只能向对象所对应的主osd节点发起请求。主节点在接受到写请求时,会同步的向从OSD中写入数据。当所有的OSD节点都写入完成后,主节点才会向客户端报告写入完成的信息。因此保证了主从节点数据的高度一致性。而读取的时候,客户端也只会向主osd节点发起读请求,并不会有类似于数据库中的读写分离的情况出现,这也是出于强一致性的考虑。由于所有写操作都要交给主osd节点来处理,所以在数据量很大时,性能可能会比较慢,为了克服这个问题以及让ceph能支持事物,每个osd节点都包含了一个journal文件,稍后介绍。