目录
[一、背景:ZooKeeper 需要什么样的一致性?](#一、背景:ZooKeeper 需要什么样的一致性?)
[二、ZAB 的架构基础](#二、ZAB 的架构基础)
[2.1 集群角色](#2.1 集群角色)
[2.2 两种工作模式](#2.2 两种工作模式)
[2.3 核心数据结构:zxid](#2.3 核心数据结构:zxid)
[三、崩溃恢复模式:Leader 选举](#三、崩溃恢复模式:Leader 选举)
[3.1 选举触发条件](#3.1 选举触发条件)
[3.2 FastLeaderElection 算法](#3.2 FastLeaderElection 算法)
[3.3 防止脑裂](#3.3 防止脑裂)
[4.1 同步前的准备:确定提交基线](#4.1 同步前的准备:确定提交基线)
[4.2 三种同步策略](#4.2 三种同步策略)
[4.3 同步完成的标志](#4.3 同步完成的标志)
[5.1 整体流程:简化的两阶段提交](#5.1 整体流程:简化的两阶段提交)
[5.2 Follower/Observer 的写请求转发](#5.2 Follower/Observer 的写请求转发)
[5.3 顺序保证:FIFO 队列](#5.3 顺序保证:FIFO 队列)
[5.4 与标准 2PC 的关键区别](#5.4 与标准 2PC 的关键区别)
[六、ZAB 的两大核心安全属性](#六、ZAB 的两大核心安全属性)
[7.1 默认读行为:本地读](#7.1 默认读行为:本地读)
[7.2 ZooKeeper 的实际一致性级别](#7.2 ZooKeeper 的实际一致性级别)
[7.3 如何实现线性化读?](#7.3 如何实现线性化读?)
[八、ZAB 与 Raft 的深度对比](#八、ZAB 与 Raft 的深度对比)
[九、总结:ZAB 的设计哲学](#九、总结:ZAB 的设计哲学)
前言:ZAB(ZooKeeper Atomic Broadcast)是 Apache ZooKeeper 的核心共识协议,专为主备架构设计。本文系统梳理 ZAB 的两大工作模式------崩溃恢复与消息广播,深入剖析其如何保证"已提交事务永不丢失、未提交事务彻底丢弃"这两大安全属性,并详细说明 ZooKeeper 在 Leader 选举、数据同步、写请求处理、读一致性等环节的具体实现,从协议层面真正理解 ZooKeeper 的一致性模型。
一、背景:ZooKeeper 需要什么样的一致性?
ZooKeeper 是一个分布式协调服务,其核心职责包括配置管理、命名服务、分布式锁和 Leader 选举。这些场景有一个共同的特征:数据量极小,但对一致性要求极高。
具体而言,ZooKeeper 的一致性目标是满足以下四条属性:
- 顺序一致性(Sequential Consistency):来自同一个客户端的操作,必须按照发出顺序被执行
- 原子性(Atomicity):每个操作要么完整成功,要么完整失败,没有中间状态
- 单一系统映像(Single System Image):客户端连接集群中任何一台服务器,看到的数据视图都是一致的
- 持久性(Durability):一旦事务被提交,即使发生节点故障也不会丢失
标准的主从复制(MySQL Binlog 异步复制等)无法满足这些要求,而通用的 Paxos 协议实现复杂、不支持日志严格有序,都不适合直接采用。为此,Yahoo! 的工程师专门设计了 ZAB 协议。
二、ZAB 的架构基础
2.1 集群角色
ZooKeeper 集群中每个节点扮演以下角色之一:
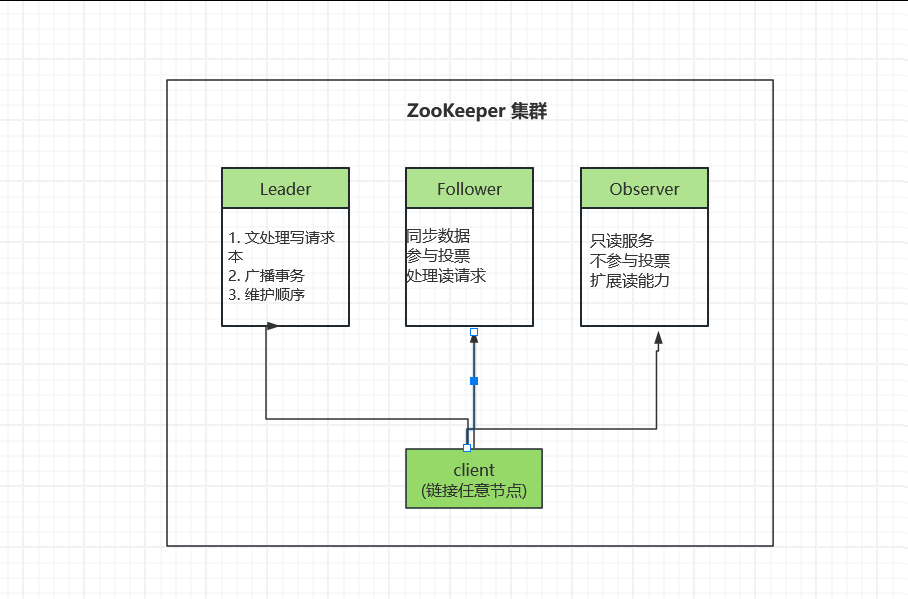
角色说明
| 角色 | 职责 | 特点 |
|---|---|---|
| Leader | 处理写请求、广播事务、维护全局顺序 | 唯一,通过选举产生 |
| Follower | 同步数据、参与投票、处理读请求 | 可参与选举,影响决策 |
| Observer | 只读服务、扩展读能力 | 不参与投票,不影响决策 |
核心特性
-
写操作:所有写请求都路由到 Leader 处理
-
读操作:Client 可连接任意节点(包括 Observer)
-
数据同步:Follower/Observer 与 Leader 保持数据一致
-
故障恢复:Leader 故障时,Follower 通过 ZAB 协议重新选举
Leader 是整个集群的写请求入口和事务广播中心,同一时刻只能有一个合法的 Leader。Follower 参与投票并同步 Leader 的数据,可以直接响应读请求。Observer(3.3.0 引入)不参与投票,专门承担读流量,用于水平扩展读吞吐。
2.2 两种工作模式
ZAB 在两种模式之间动态切换:
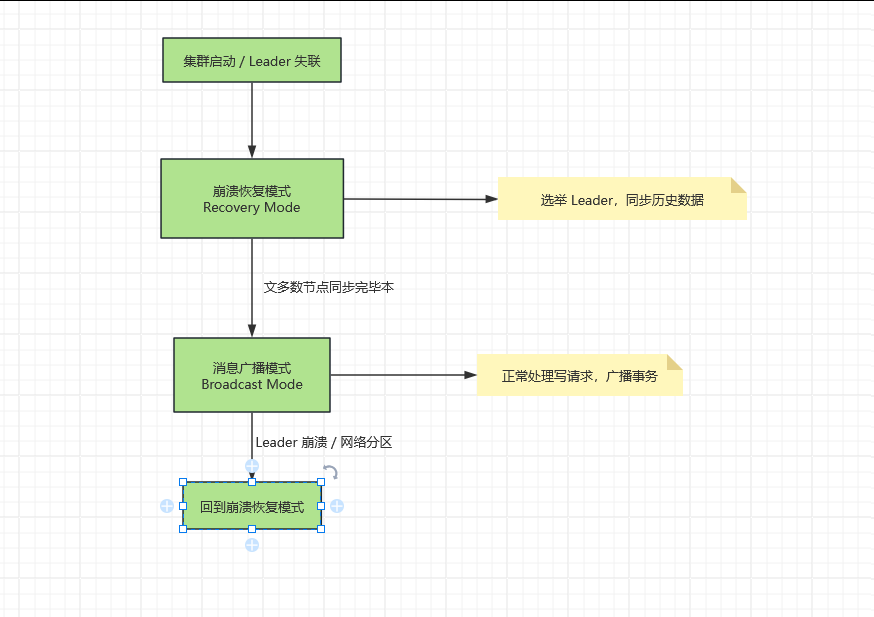
正常运行时,集群处于消息广播模式,高效处理读写请求。一旦 Leader 失联或集群启动,立即切换到崩溃恢复模式,完成新 Leader 的选举和数据同步,再重新进入广播模式。
1. 崩溃恢复模式 (Recovery Mode)
触发条件:
-
集群首次启动
-
Leader 节点失联
-
网络分区导致脑裂
主要工作:
-
Leader 选举:通过 ZAB 协议选举 zxid 最大的节点
-
数据同步:新 Leader 与 Follower 进行数据同步
-
DIFF:增量同步缺失的事务 -
TRUNC:回滚 Follower 上多余的事务 -
SNAP:全量快照同步(差距过大时)
-
**退出条件:** 超过半数 Follower 完成数据同步
2. 消息广播模式 (Broadcast Mode)
正常工作状态:
-
Leader 接收客户端写请求
-
生成
PROPOSAL提案广播给 Follower -
收到多数 Follower
ACK后发送COMMIT -
处理读请求(本地读取)
触发切换:
-
Leader 宕机
-
网络分区导致 Leader 失去多数派联系
关键要点
| 特性 | 崩溃恢复模式 | 消息广播模式 |
|---|---|---|
| Leader | 选举中 → 确定 | 稳定运行中 |
| 写请求 | 暂缓处理 | 正常处理 |
| 数据一致性 | 确保所有节点数据一致 | 维持一致性 |
| 退出条件 | 多数 Follower 同步完成 | Leader 失效触发切换 |
2.3 核心数据结构:zxid
ZAB 中每个写事务都有一个全局唯一的 64 位事务 ID,称为 zxid:
63 32 31 0
┌────────────────────┬─────────────────────┐
│ epoch (32 bit) │ counter (32 bit) │
│ Leader 任期编号 │ 事务序列号 │
└────────────────────┴─────────────────────┘高 32 位 epoch 是 Leader 的任期编号。每次产生新 Leader,epoch 自增 1。这是防止脑裂的关键机制------旧 Leader 的 epoch 过时,Follower 会直接拒绝其消息。
低 32 位 counter 是同一任期内的事务序号,单调递增,保证事务全局有序。
只需比较两个 zxid 的大小,即可立即判断任意两个事务的先后顺序。这是 ZAB 所有顺序保证的数学基础。
三、崩溃恢复模式:Leader 选举
3.1 选举触发条件
以下情况会触发 Leader 选举:
- 集群首次启动,没有 Leader
- Follower 与 Leader 的心跳超时(默认 tickTime × syncLimit)
- Leader 自身检测到失去多数 Follower 的连接
每个节点在选举期间进入 LOOKING 状态,开始广播自己的投票。
3.2 FastLeaderElection 算法
ZooKeeper 默认使用 FastLeaderElection 算法。每张选票包含三个字段:
Vote = (sid, zxid, epoch)
节点ID 最新事务ID 当前任期投票比较规则(优先级从高到低):
① epoch 更大者优先 ── 任期更新,数据更权威
② zxid 更大者优先 ── 数据更新,已提交事务更多
③ sid 更大者优先 ── 打破平局选举流程:
初始:每个节点投票给自己
S1: Vote(sid=1, zxid=100, epoch=2)
S2: Vote(sid=2, zxid=102, epoch=2)
S3: Vote(sid=3, zxid=99, epoch=2)
第一轮广播:所有节点互发选票
S1 收到 S2 的票:zxid(102) > zxid(100) → 更新票为 Vote(2, 102, 2),重新广播
S3 收到 S2 的票:zxid(102) > zxid(99) → 更新票为 Vote(2, 102, 2),重新广播
第二轮:S2 收到来自 S1、S3 的投票均指向自己
S2 获得 3/3 票 > 半数(2) → S2 当选 Leader
各节点状态更新:
S2 → LEADING
S1, S3 → FOLLOWING为何选 zxid 最大的节点?
这是 ZAB 安全性的核心保障。一个已被 Leader 提交的事务,必定存在于多数节点上。新 Leader 必须从多数节点中产生,根据鸽巢原理,获选的节点一定包含了所有已提交事务。选 zxid 最大者,就是选"见过最多已提交事务"的节点,从而确保数据永不丢失。
3.3 防止脑裂
网络分区时,可能出现两个节点同时认为自己是 Leader。ZAB 通过以下机制防止脑裂:
epoch 机制:新 Leader 产生时 epoch 自增,旧 Leader 的 epoch 落后,Follower 会直接拒绝旧 Leader 的所有 PROPOSAL 消息。
多数派限制:Leader 必须在超过半数节点的支持下才能工作。在 2F+1 个节点的集群里,两个分区最多一个拥有多数,另一个分区中的"Leader"无法推进任何写操作,自然失效。
四、崩溃恢复模式:数据同步
Leader 选出后,不能立即接收新的写请求,必须先完成数据同步,让多数 Follower 与 Leader 的数据对齐。
4.1 同步前的准备:确定提交基线
Leader 首先确定自己的事务日志中,哪些事务已被多数节点确认(已提交),哪些只有自己有(孤儿事务,需要丢弃)。
Leader 等待 Follower 发来各自的 zxid,根据差距选择同步策略。
4.2 三种同步策略
Leader 事务日志(lastZxid = 500):
[z1][z2]...[z498][z499][z500]
↑ 已提交边界
Follower A:lastZxid = 490 → 落后10条 → DIFF
Follower B:lastZxid = 501 → 多一条孤儿事务 → TRUNC + DIFF
Follower C:lastZxid = 1 → 远远落后 → SNAPDIFF(增量同步):Follower 只缺少少量事务,Leader 将缺失的事务日志逐条发送。这是最常见、最高效的同步方式。
TRUNC(截断回滚):Follower 拥有超出 Leader 已提交范围的"孤儿事务"(旧 Leader 发出 PROPOSAL 后崩溃,事务未达到多数 ACK),这些事务必须被彻底清除。Leader 发送 TRUNC 命令,指定截断点,Follower 回滚超出部分,再进行 DIFF 同步。
SNAP(快照同步):Follower 落后太多,或者是新加入的节点。Leader 将内存中完整的数据树序列化为快照发送,Follower 用快照重建内存状态,再补全快照之后的增量事务。
4.3 同步完成的标志
Leader Follower
│ │
│──── NEWLEADER(epoch) ─────►│
│ │ 应用同步数据
│◄─── ACK-NEWLEADER ─────────│
│ │
│ (收到多数 Follower 的 ACK)│
│ │
│──── UPTODATE ─────────────►│ 可以开始服务
│ │
进入广播模式 进入广播模式当 Leader 收到超过半数节点的 ACK-NEWLEADER 后,向已同步的 Follower 广播 UPTODATE 消息,集群正式进入消息广播模式,开始对外提供服务。
五、消息广播模式:写请求处理
5.1 整体流程:简化的两阶段提交
消息广播模式本质上是一个无回滚的两阶段提交(2PC)。Leader 充当协调者,Follower 充当参与者。
Client Leader Follower × N
│ │ │
│── write(k,v) ─────►│ │
│ │ │
│ ① 生成事务 txn │
│ 分配 zxid,写本地日志 │
│ │ │
│ │──── PROPOSAL(zxid, k, v) ─►│
│ │ │ ② 写事务日志(持久化)
│ │ │ 不更新内存数据树
│ │◄─── ACK(zxid) ─────────────│
│ │ │
│ ③ 收到多数 ACK │
│ 本地提交(更新内存) │
│ │──── COMMIT(zxid) ──────────►│
│ │ │ ④ 按序应用到内存数据树
│◄─── response ──────│ │
│ │ │第一阶段(Propose):Leader 分配 zxid,将事务持久化到本地日志,然后向所有 Follower 广播 PROPOSAL。
Follower 响应 :将事务写入本地事务日志(WAL 持久化),但不立即应用到内存,回复 ACK。
第二阶段(Commit):Leader 收到超过半数的 ACK 后,先在本地提交(更新内存数据树),再向所有 Follower 广播 COMMIT。
Follower 提交:按 zxid 顺序将事务应用到内存数据树,完成提交。
5.2 Follower/Observer 的写请求转发
客户端可能连接到任意节点。如果连接的是 Follower 或 Observer,写请求会被转发给 Leader处理:
Client ──── write ────► Follower ──── 转发 ────► Leader
│
正常广播流程
│
Client ◄─── response ── Follower ◄──── 通知 ────── Leader5.3 顺序保证:FIFO 队列
ZAB 要求所有事务严格按 zxid 顺序提交,不允许出现日志空洞。实现手段是:
- Leader 到每个 Follower 之间维护一条基于 TCP 的 FIFO 队列
- PROPOSAL 和 COMMIT 消息都通过这条队列顺序发送
- TCP 协议本身保证消息不会乱序
这一点与 Multi-Paxos 不同。Multi-Paxos 允许实例间存在空洞(需要 no-op 填补),ZAB 从设计之初就选择了强顺序,代价是稍高的协调开销,但换来了更简单的实现和更强的语义保证。
5.4 与标准 2PC 的关键区别
| 维度 | 标准 2PC | ZAB 广播 |
|---|---|---|
| 提交条件 | 所有参与者 ACK | 多数参与者 ACK |
| 回滚 | 支持(任意节点 ABORT 触发全局回滚) | 不支持(Follower 不能拒绝 PROPOSAL) |
| 单点阻塞 | 协调者或任意参与者崩溃可能永久阻塞 | Leader 崩溃触发新一轮选举,不永久阻塞 |
| 顺序性 | 无内置顺序保证 | 严格 zxid 顺序 |
ZAB 去掉了回滚,是因为在主备架构中,Leader 拥有绝对权威------Follower 无权拒绝一个合法 Leader 的 PROPOSAL,它们的职责是忠实记录并按序提交。这大幅简化了协议实现,也消除了 2PC 中"参与者投 ABORT 导致全局回滚"的复杂路径。
六、ZAB 的两大核心安全属性
ZAB 协议在任何情况下都保证以下两条属性,这是其线性一致性的基石。
属性一:已提交事务永不丢失
定义:一个已经被 Leader 提交的事务(Leader 已广播 COMMIT,多数节点已 ACK),在任何 Leader 切换后,仍然会被新 Leader 和所有节点提交,永不回退。
证明思路:
事务 T 被提交 ⟹ 至少 ⌊N/2⌋+1 个节点的日志中有 T
新 Leader 当选 ⟹ 至少 ⌊N/2⌋+1 个节点为其投票
两个"多数"集合必然有交集(鸽巢原理)
⟹ 新 Leader 一定包含 T(因为它从有 T 的节点获得了投票支持)
⟹ 数据同步阶段,新 Leader 将 T 同步给所有 Follower
⟹ T 不会丢失属性二:未提交的孤儿事务必须丢弃
定义:一个仅在旧 Leader 上发出过 PROPOSAL、但未达到多数 ACK 就因 Leader 崩溃而"悬空"的事务,在新 Leader 产生后必须被彻底清除,不得提交。
实现机制:
旧 Leader 崩溃前的状态:
旧 Leader: [txn1][txn2][txn3_孤儿] ← 已崩溃
Follower A: [txn1][txn2][txn3_孤儿] ← 极少数情况
Follower B: [txn1][txn2]
Follower C: [txn1][txn2]
选举结果:
新 Leader 从 B 或 C 中产生(zxid = txn2,更具代表性的多数)
数据同步:
新 Leader 发现 A 的 zxid > 自己的 commitZxid
→ 发送 TRUNC 命令:截断到 txn2
→ A 回滚 txn3_孤儿
结果:txn3_孤儿 彻底消失这条属性防止了"幽灵提交"------客户端发出写请求,旧 Leader 部分广播后崩溃,新系统如果提交了这个孤儿事务,客户端却已经因为超时放弃了,会产生语义矛盾。ZAB 选择丢弃孤儿事务,保持语义清晰。
七、读一致性:一个必须理解的细节
7.1 默认读行为:本地读
ZooKeeper 的读请求默认由客户端连接的本地节点直接响应,不经过 Leader:
Client ──── getData("/config") ────► Follower(本地直接返回)这带来了极高的读吞吐(读不占用 Leader 资源),但代价是读操作不保证线性一致性:
时间线:
t1: Leader 提交 txn(key=v2)
t2: Follower-A 应用了 txn,key=v2 ✓
t3: Client 连接 Follower-B(尚未应用 txn)
Client.getData(key) → 读到 v1 ← 读到旧值7.2 ZooKeeper 的实际一致性级别
ZooKeeper 提供的是顺序一致性(Sequential Consistency),而非线性一致性(Linearizability):
- 同一个客户端的操作严格有序(写后读自己的写)
- 不同客户端可能观察到不同的数据版本(读到旧值)
- 保证最终所有节点收敛到相同状态
7.3 如何实现线性化读?
调用 sync() 方法可以将读升级为线性一致:
cpp
// 错误示范:直接读,可能读到旧值
byte[] data = zk.getData("/lock", false, null);
// 正确做法:先 sync,再读
zk.sync("/lock", (rc, path, ctx) -> {
// sync 完成后,再 getData 保证读到最新值
zk.getData("/lock", false, dataCallback, ctx);
}, null);sync() 的内部机制:Follower 向 Leader 发送一个同步请求,Leader 将当前最新的 zxid 作为响应返回,Follower 等待本地应用到该 zxid 后,再响应客户端的读请求。
常见坑 :通过 Watch 收到节点变更通知后,如果不经 sync 直接读,可能仍然读到旧值。在实现分布式锁、Leader 选举等强一致场景时,务必在读前调用 sync()。
八、ZAB 与 Raft 的深度对比
ZAB 和 Raft 是两个独立提出却高度相似的协议,对比理解有助于掌握分布式共识设计的共同规律。
| 维度 | ZAB | Raft |
|---|---|---|
| 提出时间 | 2008(Yahoo!) | 2013(Stanford) |
| 设计目标 | 专为 ZooKeeper | 易于理解与实现 |
| 任期概念 | epoch | term |
| 日志顺序 | 严格有序,不允许空洞 | 严格有序,不允许空洞 |
| 提交条件 | 多数 ACK | 多数 ACK |
| Leader 选举 | 选 zxid 最大者 | 选 log 最新者(term+index) |
| 数据同步 | DIFF/TRUNC/SNAP | 追加缺失 entries |
| 成员变更 | 静态(传统) | Joint Consensus(内置) |
| 读一致性默认 | 本地读(顺序一致) | 强领导读(线性一致) |
| 线性化读 | sync() 后读 | ReadIndex / LeaseRead |
| 实现复杂度 | 中等 | 相对简单 |
两者的核心思想几乎一致:epoch/term 防脑裂,多数派提交,选最新日志节点当 Leader,严格顺序日志。这不是巧合,而是在"可理解的强一致性"这个设计空间里,逻辑收敛的结果。
ZAB 针对 ZooKeeper 的主备架构做了定制优化(三种同步策略、Observer 角色),而 Raft 作为通用协议,内置了更完善的成员变更机制。
九、总结:ZAB 的设计哲学
ZAB 的整个设计可以用一句话概括:用"多数派重叠"保证已提交数据不丢,用"epoch 隔离"防止旧 Leader 干扰,用"严格 zxid 顺序"提供强顺序一致性语义。
| 核心概念 | 说明 |
|---|---|
| 核心数据结构 | zxid= epoch(32bit) + counter(32bit) |
| 崩溃恢复 | - FastLeaderElection :选 zxid最大者 - 数据同步 :DIFF/ TRUNC/ SNAP |
| 消息广播 | - 简化 2PC:PROPOSAL→ 多数 ACK→ COMMIT - FIFO队列:严格 zxid顺序 |
| 安全属性 | - 已提交事务永不丢(多数派重叠) - 孤儿事务必须丢(TRUNC截断) |
| 读一致性 | - 默认:顺序一致(本地读) - 强一致:sync()+ getData() |
| 实际应用 | 分布式锁、Leader 选举、配置同步 |
ZAB 不是最学术的协议,但它是生产环境中经过十余年磨砺的工程选择。理解 ZAB,就是理解分布式系统中一致性、可用性、容错性三者之间真实的取舍与平衡。
