Linux进程概念及周边知识
1. 冯·诺依曼体系结构
我们常见的计算机、服务器等,大部分都遵循冯·诺依曼体系结构。
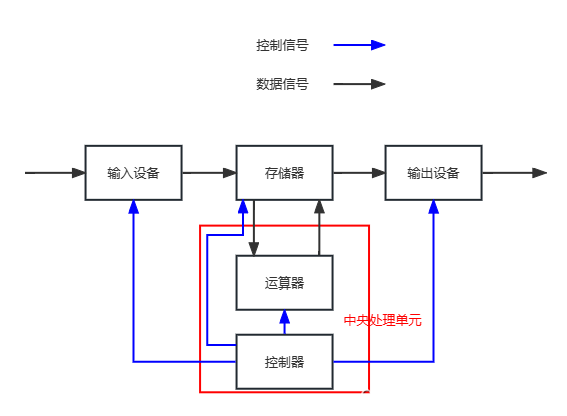
上图就是冯·诺依曼体系结构示意图,截至目前我们所认识的计算机, 就是由一个一个的硬件组成,其中,我们的硬件都可以分为下面的几类:
- 输入设备:键盘、鼠标、摄像头、麦克风、磁盘、网卡......
- 输出设备:显示器、声卡、磁盘、网卡......
- CPU(中央处理单元):运算器、控制器
- 存储器:内存
对于计算机来说,我们使用计算机,就是通过输入设备输入信息,然后从输出设备拿到我们需要的信息。
对于计算机中的硬件,都是互相连接的,数据是要在计算机体系结构中进行流动的,在数据的流动中进行数据的加工处理,从一个设备到另一个设备本质上就是一种拷贝。
在我们目前的计算机中,CPU的计算速率是非常快的,所以数据设备间的拷贝效率决定了计算机整机的基本效率。
下图是存储金字塔:
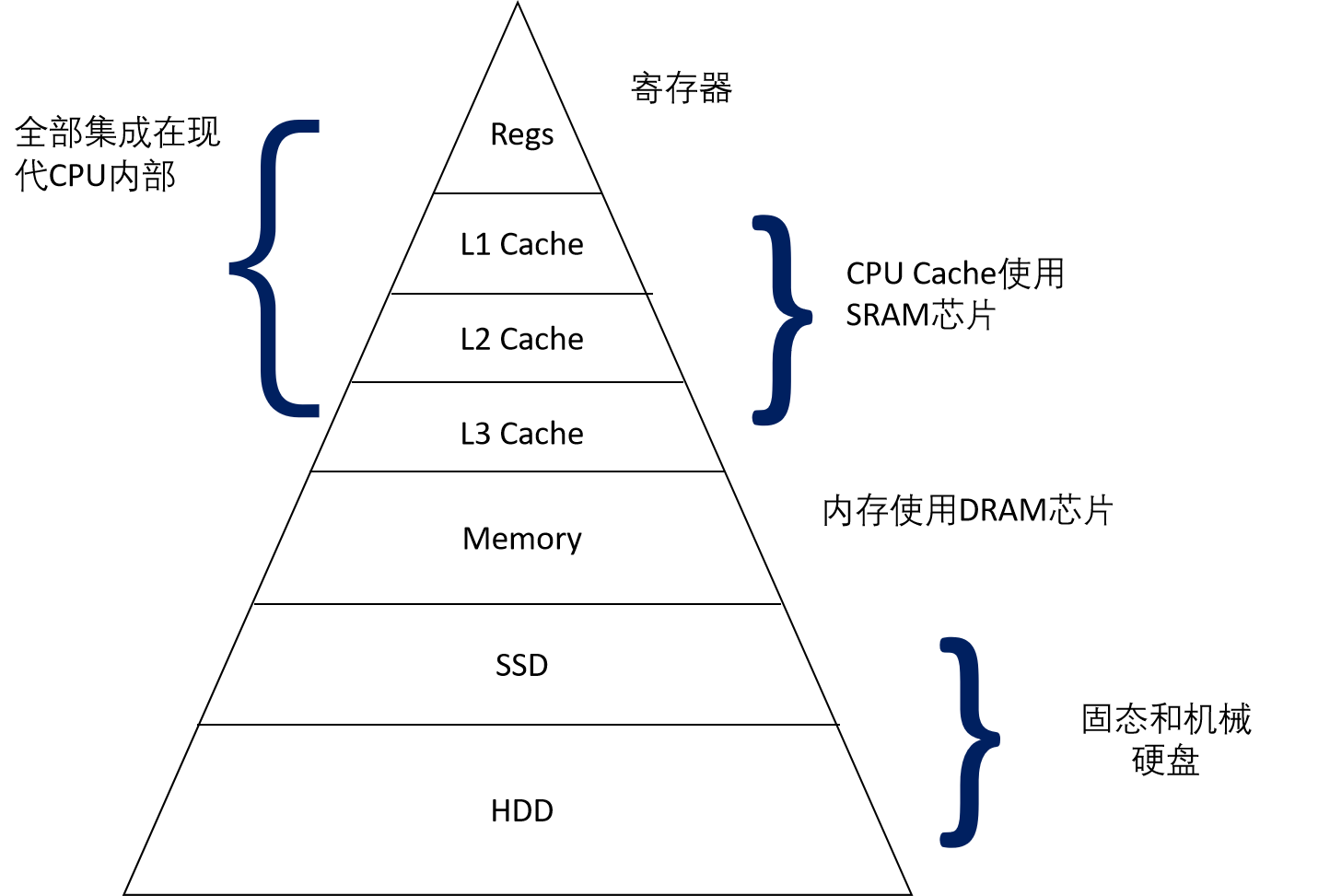
对于存储来说,拷贝效率越高的存储,成本也越高,为了提高计算机的运行效率,如果整台计算机都使用效率最高的存储,成本将会及其昂贵,为了平衡效率和成本,我们使用了多级的存储,在计算机运行时,将会预先加载需要使用到的大量数据到内存中,而CPU直接从内存中读取数据进行计算,在CPU计算的同时,输入输出设也在内存中读写数据,此时效率就得到了一定的提高,我们可以将存储器看作输入输出设备与CPU之间的巨大缓存。
在硬件数据流动角度出发,数据层面上:
- CPU不和外设直接打交道,只和内存打交道
- 输入设备和输出设备的数据不直接给CPU,而是先放进内存中
得出结论:
- 我们写的程序实际上就是代码+数据
- 程序在没有运行的时候就是存储在磁盘中的二进制文件
- CPU只和内存打交道,磁盘(外设)之和内存打交道
- 综上所述,我们的程序在运行时,都是要把程序先加载在内存中,然后交给CPU运行
2. 操作系统(Operator System,OS)
2.1 概念
OS是一款进行软硬件资源管理的软件。
广义的认识:OS=OS内核+OS外壳及周边程序(外壳及周边程序就是给用户提供使用操作系统的方式,如Windows系统的图形化界面)
狭义的认识:只考虑OS的内核
2.2 结构
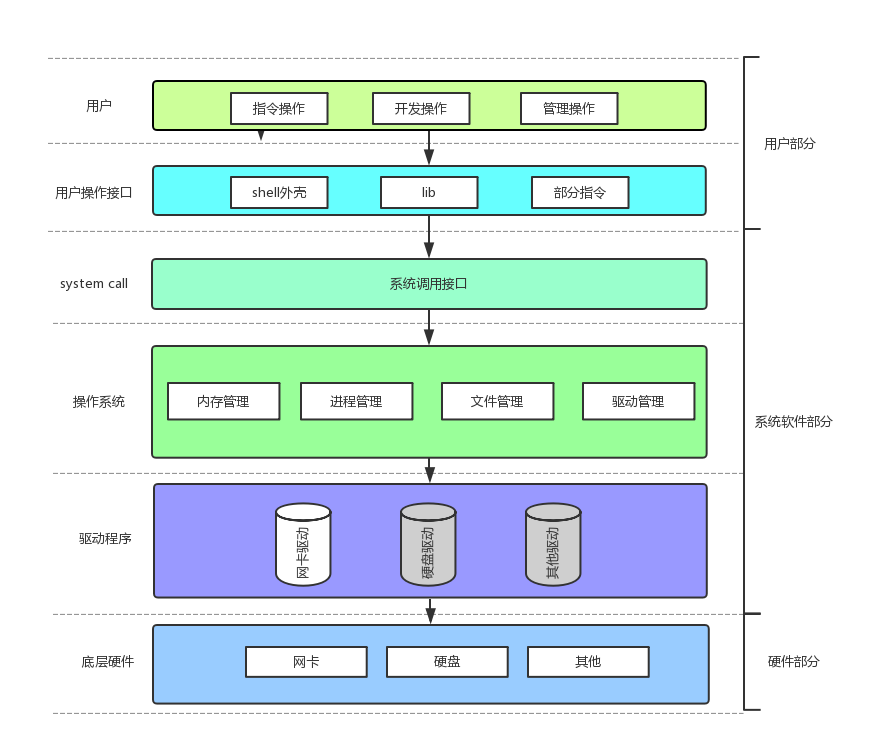
这里先谈下面的三层:
- 首先,我们的计算机都是由各种各样的硬件组成的,这些硬件组成了硬件层。
- 而我们的OS内核,就是上面的OS层。
- OS需要用来管理硬件,但是OS和硬件随着发展都会不断的更新迭代,如果OS进行了升级,即使硬件没有升级也需要对OS进行适配,反过来也是一样,这样就非常麻烦,为了解决这个问题,就有了驱动层,驱动层就是提供了管理硬件的接口,当OS升级时只需要调整调用的接口,而硬件升级时,只需要调整相对应的驱动。
OS存在的意义:对软硬件资源进行管理(手段),为用户提供一个良好(稳定、安全、高效)的运行环境(目的)。
就像我们使用C语言的printf时,我们非常容易就可以在屏幕上打印一些内容,实际上这也是我们访问了硬件设备,而底层的工作就是由操作系统来完成的。
2.3 尝试理解操作系统
再来看上面那结构图:
OS管理下层硬件
对于管理任何事物:先描述,再组织。
OS需要管理各种各样的硬件,我们都可以使用一个结构体,这个结构体中包含各种各样的属性,然后对于每个硬件,用一个结构体描述起来,这样一来,管理每个硬件,就是对这个硬件对应的结构体管理。
OS服务上层用户
一般来说,OS是不允许用户直接访问下层的硬件的,OS不相信任何用户,为了底层硬件的安全等问题的考虑,用户访问底层的硬件,必须要经过OS,因此OS向上提供了一个系统调用层,用户可以通过系统调用来访问,用户访问任何硬件,都需要直接或间接调用系统调用。
但是并不是所有用户都了解操作系统,对于通过系统调用来使用计算机的方式还是比较复杂的,为了降低人们对计算机的使用成本,又在系统调用上层又封装了一层软件层(用户操作接口层),如shell外壳(如命令行)、lib(如C语言库)等。同时,对于不同的OS,提供的系统调用也是不同的,但是有了这层软件层,我们就无需在意系统调用是什么样的,比如在Windows环境下写C语言时,使用printf函数需要包含stdio.h头文件,在Linux下同样也是包含stdio.h头文件,并且语法也是一摸一样的。
【总结】为什么要有OS?OS对下进行软硬件管理工作(手段),对上层提供良好(高效、稳定、安全)的运行环境(目的)。
3. 进程概念
在Windows中,我们可以在任务管理器看到我们的电脑中存在着非常多的进程。
对于这么多的进程,我们的OS肯定是要将这些进程管理起来的,怎么管理?先描述,再组织。
3.1 基本概念
- 课本概念:程序的一个执行实例、正在执行的进程......
- 内核观点:担当分配系统资源(CPU时间、内存)的实体。
对于我们的程序,没有在加载时,它是被存放在磁盘中的。我们执行一个程序,首先需要将这个程序的代码和数据加载到内存当中,如果同时有非常多的程序同时被加载到内存中,OS肯定是需要将这些程序管理起来的,怎么管理?先描述,再组织。
对于所有被加载到内存里的程序来说,他们都有各种各样的属性:在内存中的地址,是否正在被执行,处于什么状态......而OS需要将这些程序管理起来,就是需要将每一个程序的信息管理起来:创建一个结构体,在结构体中存放着各种属性和信息,对于每个程序都对应着一个这样的结构体,OS管理这些程序,就是对一个个结构体进行管理。
而这个描述进程的结构体就是:PCB。
对于每个进程都有一个这样的PCB,在OS管理进程的时候,只需要使用链表将这些PCB串起来,如果新增进程,就将该程序的代码和数据加载到内存中,创建一个PCB将其管理起来,然后加入到链表中,中止进程,就将那个程序在内存中的代码和数据释放掉,然后把PCB释放掉。
为什么要有PCB?因为OS需要管理进程,而PCB就是用来描述每个进程的结构体,有了PCB,OS就可以通过PCB来管理计算机中的这些进程。
而进程,就是它的PCB+它在内存中的代码和数据。
3.2 描述进程-PCB
PCB是所有OS中对于进程控制块的统称,而我们这里学习的是Linux中的PCB。而在Linux下的PCB是:task_struct。
对于OS来说,对于进程的管理,也就是管理task_struct。在计算机中,OS是需要调度进程给CPU来运行的,而OS调度进程,并不是在调度这个进程的代码和数据,而是在调度这个进程的task_struct。
在Linux中,进程=task_struct+程序的代码和数据。
如何理解进程动态运行?只要让进程的task_struct将来放在不同的队列中,就可以访问不同的资源。
task_struct内容分类
- 标识符:描述本进程的唯一标识符,用来区别其他进程。
- 状态:任务状态,退出信号等。
- 优先级:相对于其他进程的优先级。
- 程序计数器:程序中即将被执行下一条指令的地址。
- 内存指针:包括程序代码和进程相关数据的指针,还有其他进程共享的内存块的指针。
- 上下文数据:进程执行时处理器的寄存器中的数据。
- I/O状态信息;包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息:可能包括处理器时间总和,使用的时钟种数总和,时间限制,记帐号等。
- 其他信息。
4. 对于进程的操作
4.1 创建进程
- ./xxxx,本质导航就是让系统创建进程并运行,我们自己的代码生成的可执行程序 == 系统命令 == 可执行文件,在Linux中的大部分执行操作,本质都是运行进程
查看进程
-
每一个进程都有自己的唯一标识符,叫做进程pid
-
在系统中,可以通过/proc文件夹查看其中每个pid对应着一个文件夹,可以在文件夹中看到对应信息
-
在程序外,我们可以通过ps axj命令来查看当前系统中的进程
-
在程序中,我们可以通过系统调用getpid来获取自己的pid
以下面这段代码进行演示:
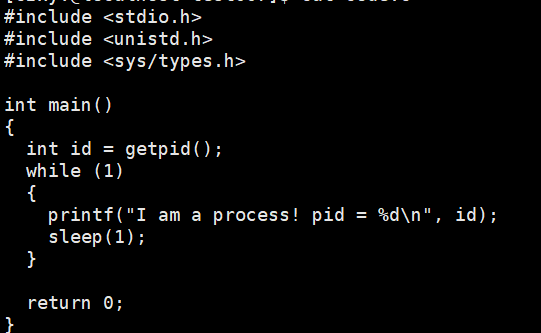
运行:
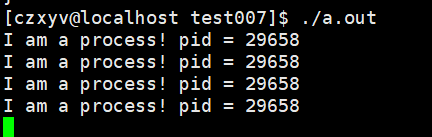
查看pid:

【补充】我们想要同时执行两条指令,可以使用&&将两条指令穿起来。

4.2 中止进程
-
在Linux下我们可以在程序运行时使用ctrl+C中止进程
-
也可以使用kill -9 pid命令来杀死指定进程
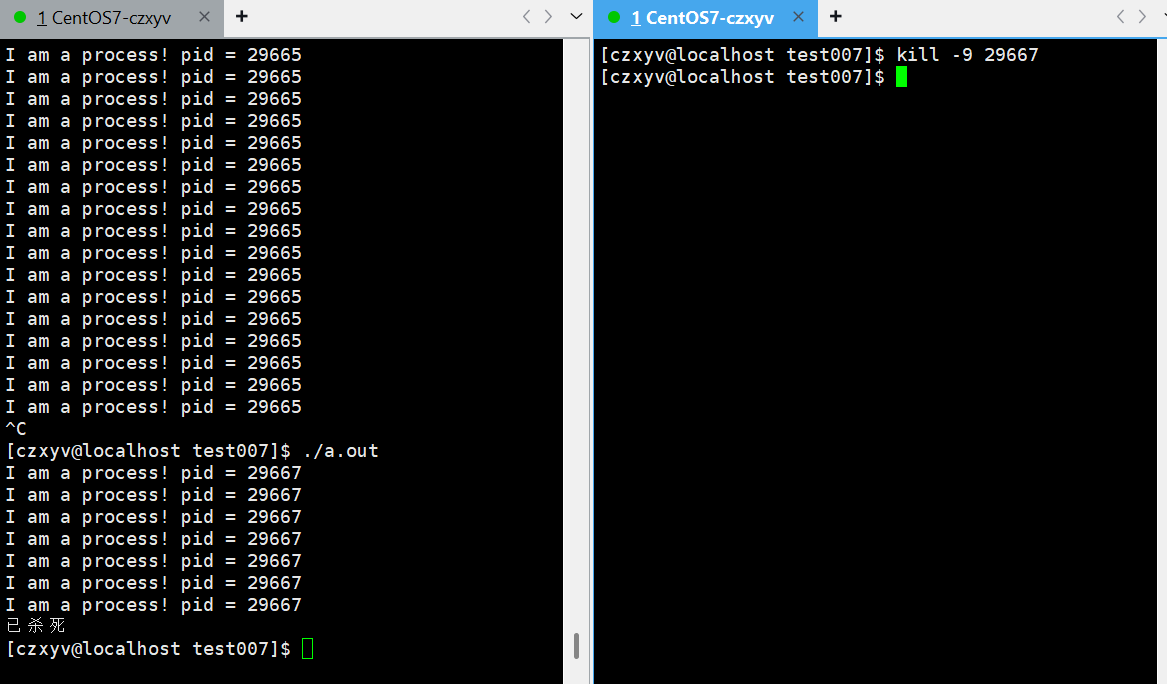
4.3 创建进程
在上面的man getpid查到的页面中,还有一个getppid,这个getppid代表的时查询父进程的pid。
我们运行的所有进程都有自己的父进程。
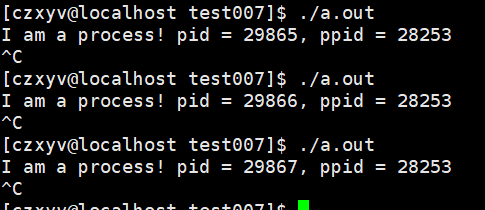
我们发现对于我们同一个进程,每次启动的pid都不一样,但是每次的父进程的pid都是一样的。

我们查找这个pid,发现这是一个叫做bash的程序,而这个bash就是命令行解释器,我们运行所有程序都是在bash下运行的,而这些程序对应的进程也就是bash创建的。
我们自己可以在程序中创建自己的子进程,这就需要系统调用fork:
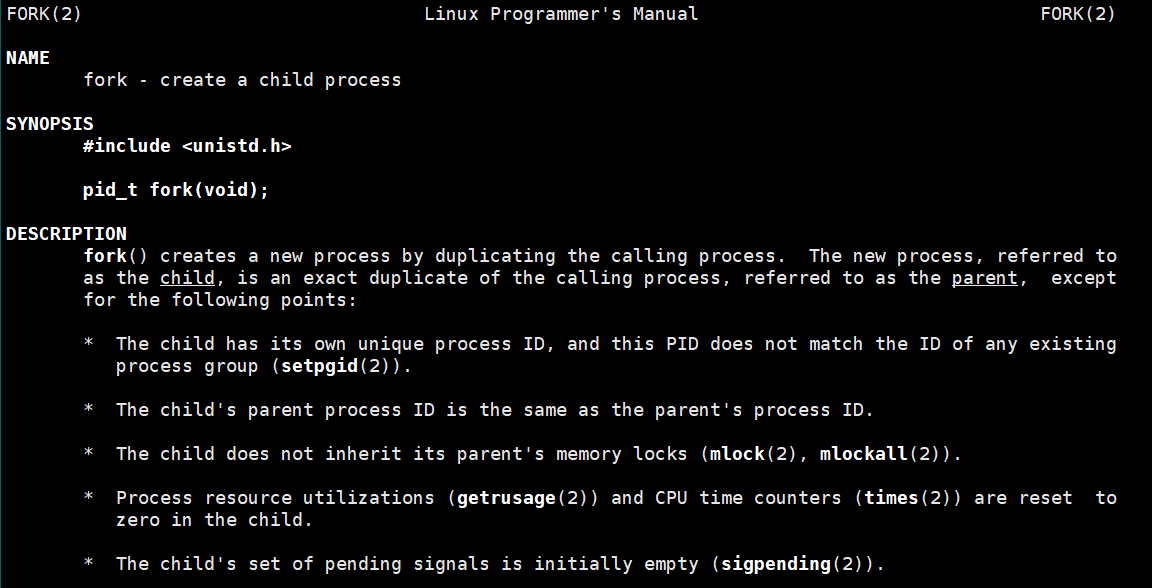
测试代码:
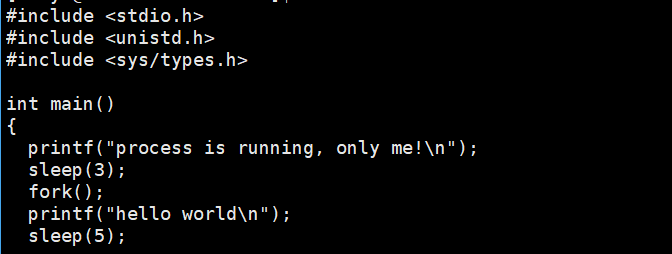
运行结构&&查询结构:
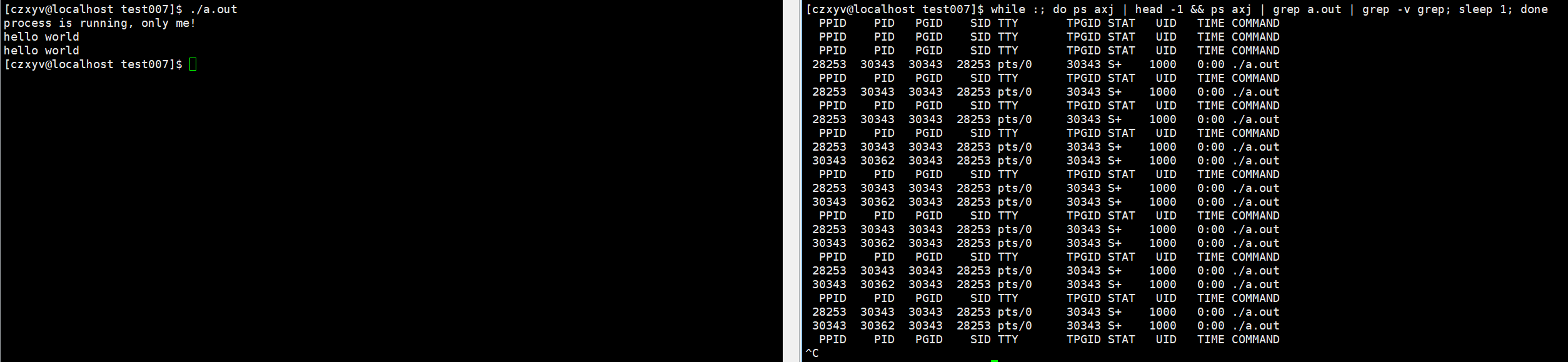
我们发现,结果中printf运行了两次,原因是在fork创建子进程后,父子进程代码共享。
我们创建一个进程,本质时系统中多了一个进程,每个进程都有自己的task_struct、代码和数据,子进程task_struct是由父进程创建的,而子进程代码和数据继承自父进程的代码和数据。
但是这并不是我们想要的效果,我们创建子进程,当然是想要子进程来执行和父进程不一样的代码。
此时我们就要关注到fork的返回值,文档里的描述:子进程被创建成功后,fork在父进程中返回子进程的pid,在子进程中返回0,如果创建失败,返回值为-1,错误码被设置。
有了这一层,我们就可以进行下面的操作:
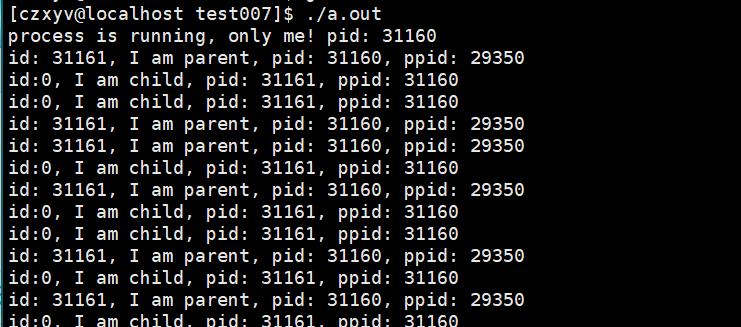
这样我们就可以实现父子进程运行不同的代码。
但是这又引出一个问题,对于一个进程来说,每个进程都是要具有独立性的,进程=task_struct+代码和数据,task_struct是被新创建出来的,这个毫无疑问父子进程都是独立的,但是子进程继承了父进程的代码和数据,其中代码是只读的,父子共同读一份代码,不做修改,这也没有问题,但是数据是不能共享的,原则上数据是要分开的,但是实际上在子进程刚被创建出来时,为了提高运行效率,刚开始并不进行拷贝,子进程和父进程是指向同一份数据的,而是在后面的运行中进行写时拷贝。
4.4 关于/proc下进程的信息
使用一份简单的代码进行测试
运行后,我们可以通过ps指令查到该进程的pid:

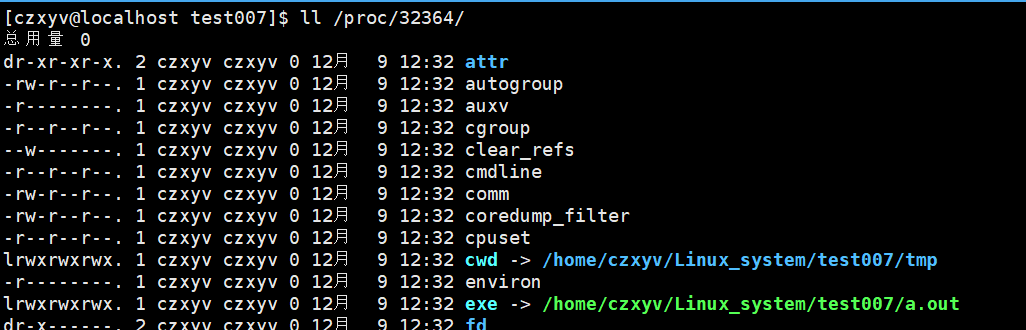
然后可以在/proc目录下找到对应的进程:
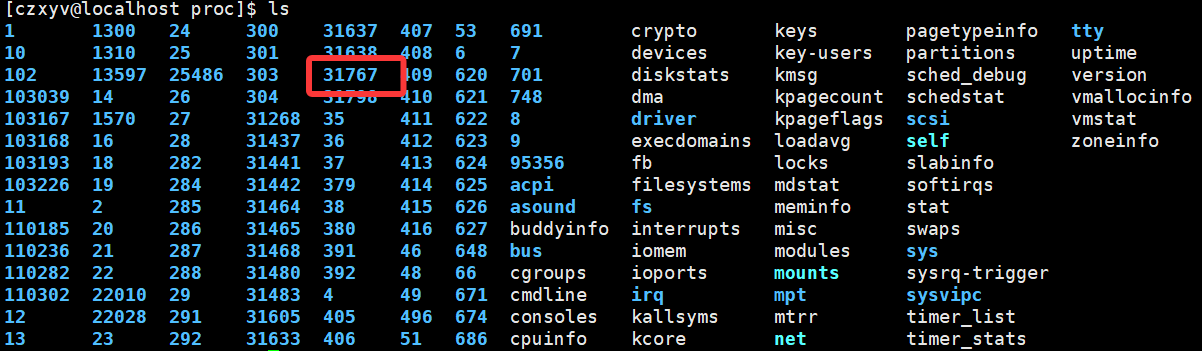
进入这个目录,可以看到该进程task_struct包含的一些信息:
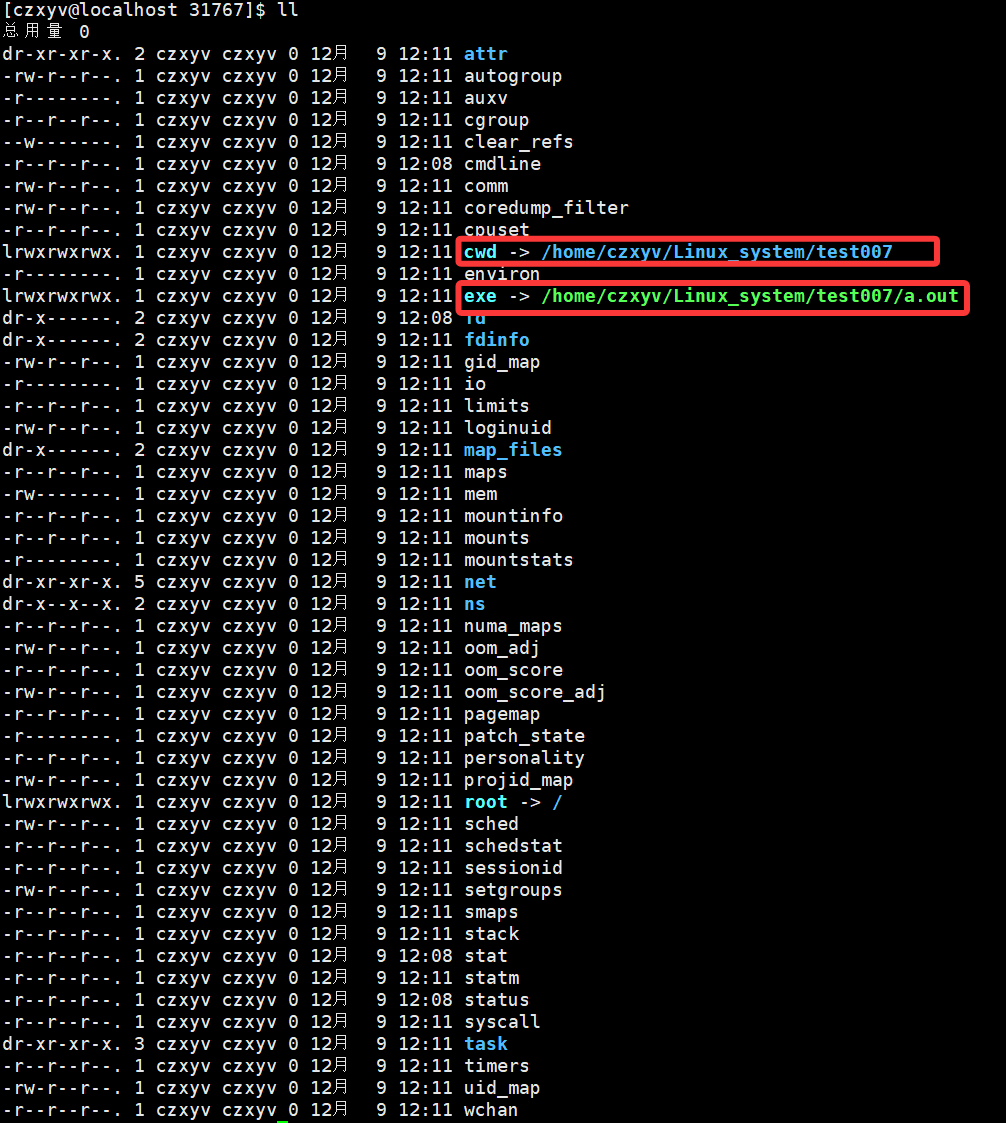
其中,cwd代表的是当前进程所处的路径,exe代表的是当前进程所对应的可执行程序。
如果我们在其还在运行的时候,就将该可执行程序删除,就会变成下面这样,提示已经被删除:

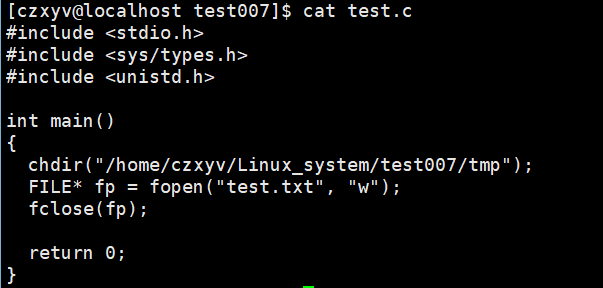
而cwd存在的意义:当我们使用C语言进行一些文件操作时,比如fopen("log.txt", "w")以写方式打开当前目录的log.txt,而当前目录指的就是cwd,它打开的文件实际上就时cwd/log.txt。
怎么证明呢?这里我们可以使用一个系统调用,来改变当前进程所处的路径(改变cwd):
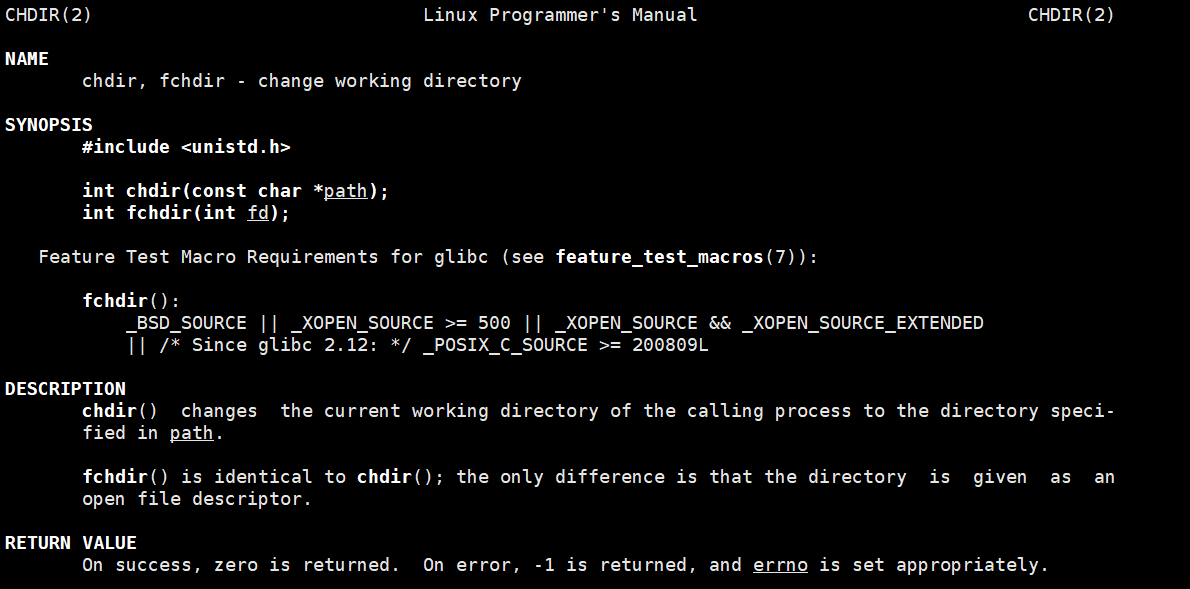
chdir用于修改当前进程的cwd,传入参数为目标路径。
测试代码:
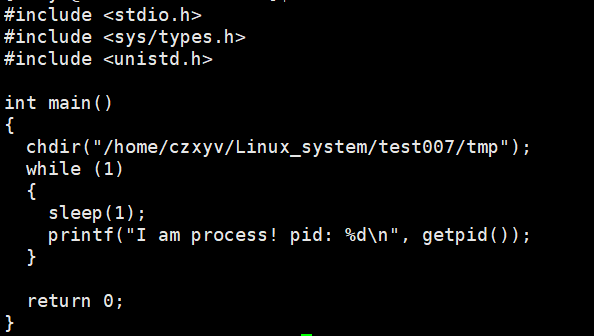
我们在/home/czxyv/Linux_system/test007路径下启动该进程:
此时我们可以查到,当前进程的cwd已被修改:
我们再使用下面这个程序来创建一个文件:
执行后我们会发现,生成的文件并不是在当前可执行文件所在的目录下,而是在我们修改后的cwd目录下。
5. 进程状态
5.1 Linux进程状态
前面说过,每个进程都会有自己的task_struct,进程的状态本质上就是task_struct中的一个属性,OS在管理进程状态时,也就是修改task_struct中代表进程的属性。
在Linux内核中,源代码对于状态的定义:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
}- R:运行状态:并不意味着在运行中,这表明进程要么在运行、要么在运行队列中。
- S:睡眠状态:意味着进程正在等待某事件完成(也称为可中断睡眠,即使在这个状态下,也可以被外部的指定进行控制,如kill)。
- D:磁盘休眠状态:Linux系统中特有的一种状态,也叫不可中断睡眠状态,比如此时一个进程向磁盘发送了I/O需求,然后这个进程就会进入D状态,等待磁盘返回结果,在这个状态下,进程无法被杀,通常需要等待IO结束。
- T/t:暂停状态:可以使用
kill -19 pid给指定进程发送SIGSTOP信号(19号信号)来停止进程,我们可以通过发送SIGCONT信号(18号信号)来让暂停的进程继续运行。(实际上我们在调试代码的时候,让程序运行到某个位置,就是在让进程暂停,此时就是t状态,t暂停状态表示当前进程是因为被追踪而暂停的) - X:死亡状态:这是一个返回状态,我们几乎无法在任务列表中查看到这个状态,因为这个状态是在进程死亡的一瞬间返回的状态,也就是说这个状态只在那一瞬间存在。
- Z:僵尸状态:当进程退出且父进程没有读取子进程退出的返回代码(使用wait()系统调用,后面的章节会介绍)时就会产生僵尸状态。
我们可以使用ps指令查看一个进程处于何种状态,其中,状态后带+意味着这个进程处于前台运行,如果想要让一个进程在后台运行,可以执行可执行文件的时候,加上&,如:./a.out &。
5.2 僵尸进程
僵尸进程概念
当一个进程退出时,会有一个退出代码需要返回到它的父进程中,而父进程获取这个代码需要使用到一个系统调用进行等待(wait()),如果父进程一直没有等待子进程,那么子进程就会一直存在于进程表中,并且会一直等待父进程读取退出代码,此时这个子进程就是僵尸状态(Z状态),这样的子进程就是僵尸进程。
僵尸进程危害
-
进程退出状态必须被维持下去,因为他要告诉它的父进程,父进程交给它的任务执行的怎么样了(退出代码),如果父进程一直不等待这个进程,那么子进程就会一直处于Z状态并维持在进程列表中。
-
维护退出状态本身就是要维护它的数据,而它的数据在task_struct(PCB)中,换句话说,如果Z状态不退出,task_struct将一直要被维护。
-
如果创建了很多子进程,当这些子进程运行完后都不进行回收,那么这些进程的数据就会一直被维护,占用系统资源,也就是占用内存资源,造成内存泄漏。
为什么我们之前启动的进程没有出现僵尸进程
我们使用命令行执行的进程,它们的父进程都是bash进程,也是由bash进程进行回收的,而bash进程接就是OS,我们就也就不需要关心这些问题。
5.3 孤儿进程
孤儿进程概念
如果父进程比子进程先退出,此时子进程就没有父进程了,这时的进程就是孤儿进程。
解决
孤儿进程会被1号进程领养,1号进程也就是系统第一个启动的进程,也就是bash进程。
5.4 进程的运行、阻塞、挂起
运行状态
在操作系统中,每个CPU都有一个需要维护的运行队列,我们需要运行一个进程就需要先将这个进程放到CPU的运行队列中去,CPU运行进程时,就会从运行队列中拿出一个进程来运行,此时只要处于运行队列中的进程,都是R状态(运行状态)。
也就是说,在Linux中,R状态下进程意味着:已经准备好,随时准备被调度。
引出:并发和并行
在一些操作系统的教材中,可能会有类似于下面这种内容的介绍:
一个进程一旦被CPU运行后,是不会一直运行到这个进程结束的。CPU是基于时间片来进行运行的,所谓时间片,就是执行这个进程的时间,当这个进程被CPU运行后,经过了指定的时间片后,哪怕这个进程没有运行完,也会被剥离下来,重新放到运行队列中,等待下次的运行。这种基于时间片,让多个进程以切换的方式进行调度,在一个时间内同时得以推进代码,就叫做并发。
如果一台计算机,有两个CPU,那么也就会有两个运行队列,此时,在任何时候,都会有两个进程在同时运行,这种运行的方式,就叫做并行。
阻塞状态
在Linux中S状态和D状态对应的就是阻塞状态,当我们使用scanf函数时,如果一直没有输入信息,这个进程将会停在那里一直等待我们的输入,实际上也就是进入了阻塞状态等待键盘输入的资源。
在阻塞状态下,进程并没有在调度,也就是并没有在CPU的运行队列中,那么它在哪呢?
对于所有的硬件来说,OS需要将它们管理起来,也同样是先描述再组织,用一个结构体管理起来,结构体中有代表这个外设的各种各样的信息,其中有一个就是外设的等待队列,这个等待队列里面存放的就是等待获取该外设的资源的进程。
进程刚开始运行时肯定是在运行队列中的,但是当运行到需要获取硬件的资源的时候,比如运行到scanf时,需要获取键盘资源,此时CPU检测键盘资源是否就绪,如果就绪就读取键盘资源继续运行,如果没有就绪,就将这个进程从运行队列中剥离出来,放入到键盘的等待队列中去。
并不是只有CPU有运行队列,与电脑连接的各种设备也有自己的等待队列。
总结:进程进入阻塞状态,本质上就是将进程从CPU运行队列剥离,放入到相应设备的等待队列中。(进程的运行和阻塞的状态变化往往意味着进程PCB被放入到不同的队列中)
挂起
计算机中的内存是有限的,有一些情况下,当电脑的内存严重不足时,但是现在又需要使用一些内存,这个时候OS会把一些处于S状态的进程的代码和数据唤出(拷贝)到磁盘中一个叫做swap分区的一块空间中,此时就能再内存中腾出一些空间来供其他急需内存的进程来使用,当需要使用这个进程的代码和数据时候,再将这个进程的代码和数据唤入(拷贝)回到内存中。
当进程的代码和数据被唤出到swap分区中的时候,此时的进程就是挂起状态。
换入唤出是一个用效率换空间的做法,如果频繁的唤入唤出就意味着增加了I/O操作,必然会带来计算机运行效率的下降
6. 进程切换
在我们计算机的CPU中,有很多的寄存器,这些寄存器中会保存进程中的临时数据,当进程在切换时,这些临时的数据需要保存起来,然后在进程下一次被CPU调度的时候,再将这些临时的数据拷贝回CPU的寄存器中,然后接着上次的进度继续运行。
而CPU内部的寄存器中的临时数据,就叫做进程的上下文。进程在切换时最重要的事情是:上下文数据的保护和恢复。
关于寄存器:寄存器本身时硬件,具有存储数据的能力,CPU的寄存器只有一套,但是CPU内存内部的数据可以有多套,有几个进程,就有几套和该进程对应的上下文数据,所以寄存器!=寄存器的内容。
7. 进程优先级
7.1 优先级的概念
指定进程获取某种资源的先后顺序,如在CPU队列中,排队时排名靠前的,优先级高,排名靠后的优先级低。
在task_struct中有一个属性,代表了这个进程的优先级,而优先级的本质就时一个数字,数字小的优先级高,反之优先级低。
优先级 VS 权限
优先级:已经能获得某种资源,代表获取资源的顺序
权限:能不能获取某种资源
7.2 优先级存在的意义
进程所访问的资源(CPU)始终都是有限的,一般来说OS中的进程都是由较多的,多数的进程竞争少数的资源,所以就必定存在先后获取资源的问题。
OS关于调度和优先级的原则:目前的大部分OS都是分时OS,也就是基于时间片来进行调度,这样OS的调度都需要维护基本的公平。如果进程因为长时间不被调度,就会造成饥饿问题(长时间得不到资源)。
7.3 查看/调整优先级
7.3.1 查看优先级
一段简单的代码:
使用ps -l可以查看当前终端下的进程,而ps -al则可以查看当卡你系统下的进程。
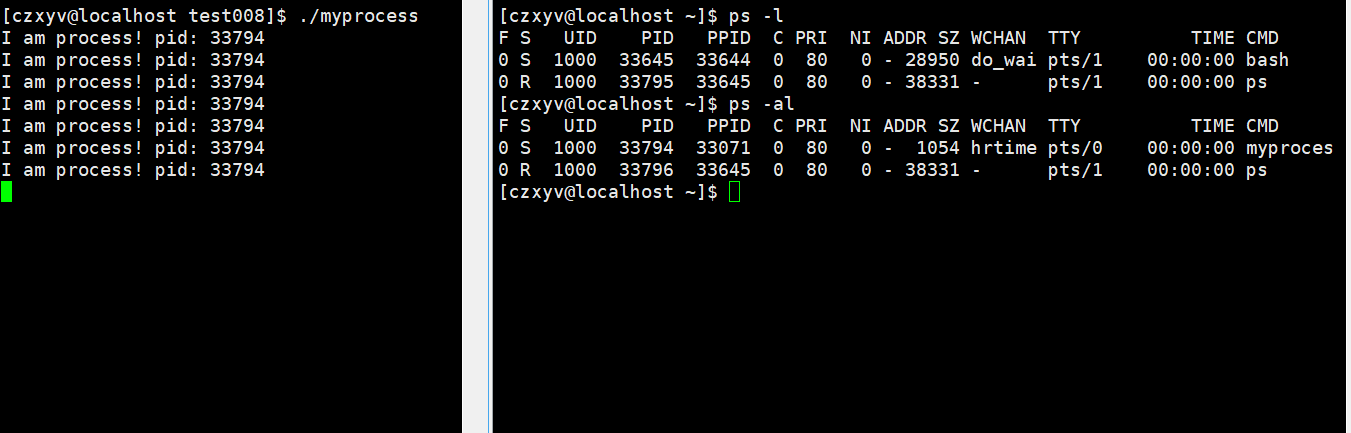
其中的PRI和NI这两栏的数据中:
- PRI:进程优先级
- NI:进程优先级的修正数据,也叫nice值,新优先级=默认优先级(80)+nice
7.3.2 调整优先级
**方法一:**nice/renice
nice用于启用命令时赋予进程NI值:
nice -n NI值 命令
renice用于运行时修改该进程的NI值
renice NI值 pid
**方法二:**top
-
在启动进程后可以使用命令top进入调整界面。
-
输入r进入调整。
-
输入pid回车。
-
输入NI值回车,通过查询可以发现NI值发生改变。

【注意】NI值是有范围的,无法任意调整,范围是-20~19,一共40个优先级,调整的NI值过大(超过19)或过小(低于-20)都只会变成它的最大值(19)或最小值(-20)。