
背景需求
制作下学期的班级文本资料,继续用以前的代码修改
"后续补代码"
代码复制一下,修改日期


从参考资料里找到原来的育儿知识的内容,复制到指定文件夹。
'''
00 周次变成2位数变docx
deepseek 阿夏
20260228
'''
# 设置路径
import os
import time
import shutil
classroom='小2班'
# 设置路径
path = r'D:\test\02办公类\20260228周计划4份_小2班表格合并表\03 育儿知识'
oldpath = path + r'\01doc' # 原文件doc地址
newpath = path + r'\02docx' # docx地址
# 创建目标文件夹(如果不存在)
os.makedirs(newpath, exist_ok=True)
# 检查源文件夹是否存在
if not os.path.exists(oldpath):
print(f"错误:路径 '{oldpath}' 不存在!")
exit()
# 第一步:复制所有DOC文件到02docx文件夹
print("正在复制文件到02docx文件夹...")
fileList = os.listdir(oldpath)
doc_files = [f for f in fileList if f.endswith('.doc') and not f.startswith('~$')]
if not doc_files:
print("没有找到DOC文件")
exit()
for file in doc_files:
src_path = os.path.join(oldpath, file)
dst_path = os.path.join(newpath, file)
# 如果目标文件已存在,先删除
if os.path.exists(dst_path):
os.remove(dst_path)
try:
shutil.copy2(src_path, dst_path)
print(f"✓ 复制成功: {file}")
except Exception as e:
print(f"✗ 复制失败 {file}: {e}")
print("\n文件复制完成!")
time.sleep(1)
# 第二步:在02docx文件夹中重命名文件
print("\n开始重命名文件...")
fileList = os.listdir(newpath)
for file in fileList:
if file.endswith('.doc') and not file.startswith('~$'):
# 提取月份数字
month_num = ''.join(filter(str.isdigit, file))
if month_num: # 确保找到了数字
# 如果月份是单数字,前面补0(1月变成01月,9月变成09月)
if len(month_num) == 1:
month_num = f"0{month_num}"
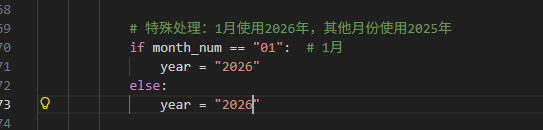
# 特殊处理:1月使用2026年,其他月份使用2025年
if month_num == "01": # 1月
year = "2026"
else:
year = "2026"
newname = f'{classroom} {year}年{month_num}月 家园小报.doc'
oldname_path = os.path.join(newpath, file)
newname_path = os.path.join(newpath, newname)
# 检查目标文件是否已存在
if os.path.exists(newname_path):
print(f"文件已存在,跳过重命名: {newname}")
continue
try:
os.rename(oldname_path, newname_path)
print(f"✓ 重命名成功: {file} -> {newname}")
except Exception as e:
print(f"✗ 重命名失败 {file}: {e}")
else:
print(f"跳过文件(无法提取月份): {file}")
print("\n" + "="*50)
print("文件重命名完成!")
time.sleep(1)
# 第三步:转换DOC到DOCX(在同一文件夹中)
print("\n开始转换DOC到DOCX格式...")
try:
from win32com import client as wc
# 获取重命名后的文件列表
final_files = os.listdir(newpath)
doc_files = [f for f in final_files if f.endswith('.doc') and not f.startswith('~$')]
if not doc_files:
print("没有找到DOC文件进行转换")
else:
word = None
try:
word = wc.Dispatch("Word.Application")
word.Visible = False
for file in doc_files:
doc_path = os.path.join(newpath, file)
# 生成DOCX文件名(保持相同的命名格式)
docx_filename = os.path.splitext(file)[0] + '.docx'
docx_path = os.path.join(newpath, docx_filename)
print(f"正在转换: {file} -> {docx_filename}")
try:
doc = word.Documents.Open(doc_path)
doc.SaveAs2(docx_path, FileFormat=16) # 16表示docx格式
doc.Close()
print(f" ✓ 转换成功")
# 可选:删除原始DOC文件
os.remove(doc_path)
print(f" ✓ 已删除原文件: {file}")
except Exception as e:
print(f" ✗ 转换失败: {e}")
time.sleep(0.5) # 短暂延迟
print(f"\n✓ 所有文件转换完成!保存在: {newpath}")
except Exception as e:
print(f"初始化Word应用程序时出错: {e}")
finally:
if word:
word.Quit()
except ImportError:
print("警告: 未找到win32com库,无法进行DOC到DOCX的转换")
print("请安装: pip install pywin32")
# 显示最终结果
print("\n" + "="*50)
print("处理完成!最终文件列表:")
print("源文件夹 (01doc):")
for f in os.listdir(oldpath):
if f.endswith('.doc'):
print(f" 📄 {f}")
print("\n目标文件夹 (02docx):")
if os.path.exists(newpath):
docx_files = [f for f in os.listdir(newpath) if f.endswith('.docx')]
if docx_files:
for f in docx_files:
print(f" 📄 {f}")
else:
print(" 没有DOCX文件")
else:
print(" 文件夹不存在")
文件名改成:班级+年月+家园小报+docx
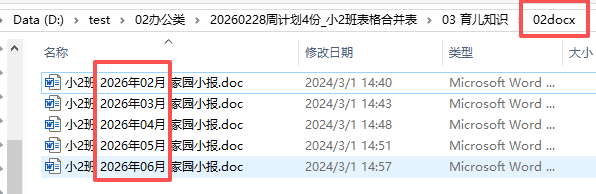

需要修改两个形式,家长名字,原来模版还缺少 班级

'''
01 修改形式、日期、班级
这次的原始资料里面没有班级,所以把家园小报,改成小2班家园小报
deepseek 阿夏
20260228
'''
import os
import win32com.client as win32
from win32com.client import constants
import re
# 配置参数 - 针对您的需求定制
g = '小' # 年级前缀
n1 = '3' # 原班级号
n2 = '2' # 新班级号
n3 = '三' # 原班级号(中文)
n4 = '二' # 新班级号(中文)
T1 = '吴老师' # 原教师姓名
T2 = '顾老师' # 原教师称呼
T3 = '张老师' # 新教师姓名
T4 = '夏老师' # 新教师称呼
# 定义替换规则 - 针对小1班→小2班,吴老师→夏老师
replacements = [
# 班级替换规则
(f"2024", f"2026"),
(f"2020年1月", f"2026年1月"),
(f"2020", f"2025"),
(f"{g}({n1})班", f"{g}({n2})班"),
(f"{g}({n1})班", f"{g}({n2})班"),
(f"{g}{n3}班", f"{g}{n4}班"),
(f"{g}{n1}班", f"{g}{n2}班"),
(f"{g}({n3})班", f"{g}({n4})班"),
(f"{g}({n3})班", f"{g}({n4})班"),
(f"小{n1}班", f"小{n2}班"),
(f"小{n3}班", f"小{n4}班"),
# 教师姓名替换规则
(T1, T3),
(T2, T4),
("周", "夏"), # 更广泛的替换,但需谨慎使用
# 可能的其他变体
(f"{T1}老师", f"{T3}老师"),
(f"{T2}老师", f"{T4}老师"),
]
def replace_in_all_story_ranges(doc, find_text, replace_text):
"""在文档的所有故事范围(包括页眉、页脚、文本框等)中执行替换,保持格式"""
for story_range in doc.StoryRanges:
while story_range:
try:
# 使用Word内置的查找替换功能,保持格式
story_range.Find.Execute(
FindText=find_text,
ReplaceWith=replace_text,
Replace=constants.wdReplaceAll,
MatchCase=False,
MatchWholeWord=False,
MatchWildcards=False
)
# 处理链接的故事范围(如连续的页眉页脚)
story_range = story_range.NextStoryRange
except Exception as e:
print(f"替换时出错: {e}")
break
def replace_content_comprehensive():
# 设置路径
path = r'D:\test\02办公类\20260228周计划4份_小2班表格合并表\03 育儿知识'
source_folder = path + r'\02docx' # 源文件夹
target_folder = path + r'\03替换后' # 目标文件夹
# 创建目标文件夹
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# 初始化Word应用程序
word = win32.gencache.EnsureDispatch('Word.Application')
word.Visible = False
word.DisplayAlerts = False
try:
# 获取所有DOCX文件
docx_files = [f for f in os.listdir(source_folder) if f.endswith('.docx') and not f.startswith('~$')]
if not docx_files:
print(f"在 {source_folder} 中没有找到DOCX文件")
return
print(f"找到 {len(docx_files)} 个DOCX文件")
# 处理每个文件
for i, filename in enumerate(docx_files, 1):
source_file = os.path.join(source_folder, filename)
target_file = os.path.join(target_folder, filename)
print(f"正在处理 ({i}/{len(docx_files)}): {filename}")
# 打开文档
doc = word.Documents.Open(source_file)
# 按顺序执行所有替换规则
for find_text, replace_text in replacements:
replace_in_all_story_ranges(doc, find_text, replace_text)
# 保存并关闭文档
doc.SaveAs(target_file)
doc.Close()
print(f" 已完成: {filename}")
except Exception as e:
print(f"处理过程中出错: {e}")
finally:
# 确保Word应用程序关闭
word.Quit()
def test_replacements():
"""测试替换规则"""
print("将应用的替换规则:")
print("-" * 50)
for i, (find_text, replace_text) in enumerate(replacements, 1):
print(f"{i:2d}. {find_text} → {replace_text}")
print("-" * 50)
if __name__ == "__main__":
# 显示替换规则
test_replacements()
# # 确认是否继续
# confirm = input("\n确认要应用这些替换规则吗? (y/n): ")
# if confirm.lower() != 'y':
# print("操作已取消")
# exit()
# 处理文档
print("\n开始处理文档...")
replace_content_comprehensive()
print("\n所有文档处理完成!")
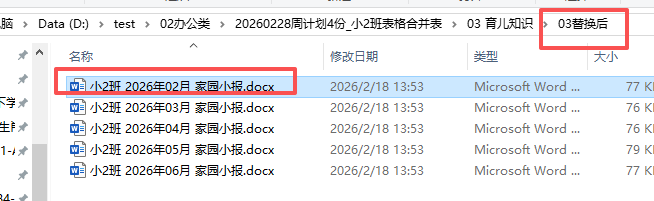
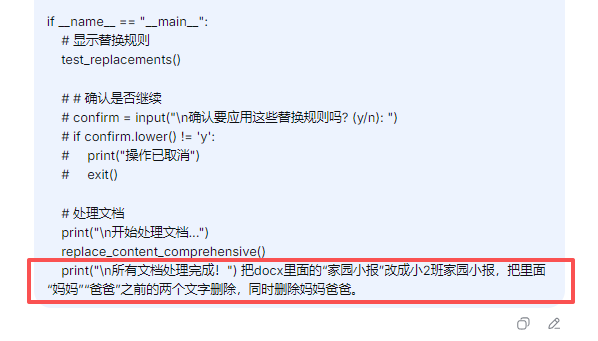
姓名修改了,年月也修改了。我还需要添加班级


'''
01 修改形式、日期、班级
这次的原始资料里面没有班级,所以把家园小报,改成小2班家园小报
XX妈妈、XX爸爸文字删除(全部删除,留一个空格)
deepseek 阿夏
20260228
'''
import os
import win32com.client as win32
from win32com.client import constants
import re
# 配置参数 - 针对您的需求定制
g = '小' # 年级前缀
n1 = '3' # 原班级号
n2 = '2' # 新班级号
n3 = '三' # 原班级号(中文)
n4 = '二' # 新班级号(中文)
T1 = 'W老师' # 原教师姓名
T2 = 'G老师' # 原教师称呼
T3 = 'Z老师' # 新教师姓名
T4 = 'X老师' # 新教师称呼
# 定义替换规则 - 针对小1班→小2班,吴老师→夏老师
replacements = [
# 班级替换规则
(f"2024", f"2026"),
(f"2020年1月", f"2026年1月"),
(f"2020", f"2025"),
(f"{g}({n1})班", f"{g}({n2})班"),
(f"{g}({n1})班", f"{g}({n2})班"),
(f"{g}{n3}班", f"{g}{n4}班"),
(f"{g}{n1}班", f"{g}{n2}班"),
(f"{g}({n3})班", f"{g}({n4})班"),
(f"{g}({n3})班", f"{g}({n4})班"),
(f"小{n1}班", f"小{n2}班"),
(f"小{n3}班", f"小{n4}班"),
# 教师姓名替换规则
(T1, T3),
(T2, T4),
("周", "夏"), # 更广泛的替换,但需谨慎使用
# 可能的其他变体
(f"{T1}老师", f"{T3}老师"),
(f"{T2}老师", f"{T4}老师"),
# 家园小报替换为小2班家园小报
("家园小报", f"{g}{n2}班家园小报"),
# 老师顿号改成老师空格
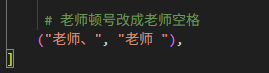
("老师、", "老师 "),
]
def delete_xx_mama_baba_completely(doc):
"""
完全删除"XX妈妈"和"XX爸爸"(包括妈妈和爸爸本身),并在原位置留一个空格
例如:"小明妈妈" -> " "(一个空格),"小刚爸爸" -> " "(一个空格)
"""
try:
# 遍历所有故事范围
for story_range in doc.StoryRanges:
while story_range:
try:
# 处理"妈妈"
current_range = story_range.Duplicate
# 查找所有"妈妈"并删除前面的两个字符加上"妈妈"本身
while True:
# 在当前范围内查找"妈妈"
current_range.Find.Execute(
FindText="妈妈",
MatchCase=False,
MatchWholeWord=False,
Forward=True,
Wrap=constants.wdFindStop
)
if current_range.Find.Found:
# 获取"妈妈"的位置
mama_start = current_range.Start
# 如果前面至少有2个字符(存在XX)
if mama_start >= story_range.Start + 2:
# 删除前面的两个字符加上"妈妈"(共4个字符)
delete_range = doc.Range(
mama_start - 2,
mama_start + 2 # "妈妈"是两个字符
)
# 替换为一个空格
delete_range.Text = " "
else:
# 如果前面字符不足2个,只删除"妈妈"本身
delete_range = doc.Range(
mama_start,
mama_start + 2
)
delete_range.Text = " "
# 继续查找,从当前位置之后开始
current_range.SetRange(
delete_range.Start + 1, # +1跳过空格
story_range.End
)
else:
break
# 重新设置范围,处理"爸爸"
text = story_range.Text
current_range = story_range.Duplicate
# 查找所有"爸爸"
while True:
current_range.Find.Execute(
FindText="爸爸",
MatchCase=False,
MatchWholeWord=False,
Forward=True,
Wrap=constants.wdFindStop
)
if current_range.Find.Found:
baba_start = current_range.Start
if baba_start >= story_range.Start + 2:
# 删除前面的两个字符加上"爸爸"
delete_range = doc.Range(
baba_start - 2,
baba_start + 2
)
delete_range.Text = " "
else:
# 只删除"爸爸"本身
delete_range = doc.Range(
baba_start,
baba_start + 2
)
delete_range.Text = " "
# 继续查找
current_range.SetRange(
delete_range.Start + 1,
story_range.End
)
else:
break
# 处理链接的故事范围
story_range = story_range.NextStoryRange
except Exception as e:
print(f"处理范围时出错: {e}")
story_range = story_range.NextStoryRange
except Exception as e:
print(f"删除XX妈妈爸爸时出错: {e}")
def delete_xx_mama_baba_with_pattern(doc):
"""
使用通配符模式查找并删除"XX妈妈"和"XX爸爸"(全部删除),留一个空格
"""
try:
# 遍历所有故事范围
for story_range in doc.StoryRanges:
while story_range:
try:
# 设置查找范围
current_range = story_range.Duplicate
# 使用通配符查找"??妈妈"(任意两个字符后跟妈妈)
current_range.Find.ClearFormatting()
current_range.Find.Execute(
FindText="??妈妈",
MatchWildcards=True,
Forward=True,
Wrap=constants.wdFindStop
)
# 处理所有找到的"??妈妈"
while current_range.Find.Found:
found_range = current_range.Duplicate
# 替换为一个空格
found_range.Text = " "
# 继续查找
current_range.Find.Execute(
FindText="??妈妈",
MatchWildcards=True,
Forward=True,
Wrap=constants.wdFindStop
)
# 重新设置范围,查找"??爸爸"
current_range = story_range.Duplicate
current_range.Find.ClearFormatting()
current_range.Find.Execute(
FindText="??爸爸",
MatchWildcards=True,
Forward=True,
Wrap=constants.wdFindStop
)
while current_range.Find.Found:
found_range = current_range.Duplicate
found_range.Text = " "
current_range.Find.Execute(
FindText="??爸爸",
MatchWildcards=True,
Forward=True,
Wrap=constants.wdFindStop
)
story_range = story_range.NextStoryRange
except Exception as e:
print(f"处理范围时出错: {e}")
story_range = story_range.NextStoryRange
except Exception as e:
print(f"删除XX妈妈爸爸时出错: {e}")
def replace_in_all_story_ranges(doc, find_text, replace_text):
"""在文档的所有故事范围(包括页眉、页脚、文本框等)中执行替换,保持格式"""
try:
for story_range in doc.StoryRanges:
while story_range:
try:
# 使用Word内置的查找替换功能,保持格式
story_range.Find.ClearFormatting()
story_range.Find.Replacement.ClearFormatting()
story_range.Find.Execute(
FindText=find_text,
ReplaceWith=replace_text,
Replace=constants.wdReplaceAll,
MatchCase=False,
MatchWholeWord=False,
MatchWildcards=False,
Forward=True,
Wrap=constants.wdFindContinue
)
# 处理链接的故事范围(如连续的页眉页脚)
story_range = story_range.NextStoryRange
except Exception as e:
print(f"替换 '{find_text}' 时出错: {e}")
break
except Exception as e:
print(f"在替换函数中出错: {e}")
def replace_content_comprehensive():
# 设置路径
path = r'D:\test\02办公类\20260228周计划4份_小2班表格合并表\03 育儿知识'
source_folder = path + r'\02docx' # 源文件夹
target_folder = path + r'\03替换后' # 目标文件夹
# 创建目标文件夹
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# 初始化Word应用程序
word = win32.gencache.EnsureDispatch('Word.Application')
word.Visible = False
word.DisplayAlerts = False
try:
# 获取所有DOCX文件
docx_files = [f for f in os.listdir(source_folder) if f.endswith('.docx') and not f.startswith('~$')]
if not docx_files:
print(f"在 {source_folder} 中没有找到DOCX文件")
return
print(f"找到 {len(docx_files)} 个DOCX文件")
# 处理每个文件
for i, filename in enumerate(docx_files, 1):
source_file = os.path.join(source_folder, filename)
target_file = os.path.join(target_folder, filename)
print(f"正在处理 ({i}/{len(docx_files)}): {filename}")
# 打开文档
doc = word.Documents.Open(source_file)
# 先执行常规替换规则
for find_text, replace_text in replacements:
replace_in_all_story_ranges(doc, find_text, replace_text)
# 删除"XX妈妈"和"XX爸爸"(全部删除,留一个空格)
print(f" 正在删除XX妈妈、XX爸爸(全部删除,留空格)...")
# 使用方法1:直接删除并留空格
delete_xx_mama_baba_completely(doc)
# 或者使用方法2:使用通配符模式(更简洁)
# delete_xx_mama_baba_with_pattern(doc)
# 保存并关闭文档
doc.SaveAs(target_file)
doc.Close()
print(f" 已完成: {filename}")
except Exception as e:
print(f"处理过程中出错: {e}")
finally:
# 确保Word应用程序关闭
try:
word.Quit()
except:
pass
def test_replacements():
"""测试替换规则"""
print("将应用的替换规则:")
print("-" * 50)
for i, (find_text, replace_text) in enumerate(replacements, 1):
print(f"{i:2d}. {find_text} → {replace_text}")
print("\n特殊处理:")
print(" 删除'XX妈妈'、'XX爸爸'(全部删除,包括妈妈和爸爸本身)")
print(" 在原位置留一个空格")
print(" 例如:'小明妈妈' → ' '(一个空格),'小刚爸爸' → ' '(一个空格)")
print("-" * 50)
if __name__ == "__main__":
# 显示替换规则
test_replacements()
# 确认是否继续
confirm = 'y'
# input("\n确认要应用这些替换规则吗? (y/n): ")
if confirm.lower() != 'y':
print("操作已取消")
exit()
# 处理文档
print("\n开始处理文档...")
replace_content_comprehensive()
print("\n所有文档处理完成!")
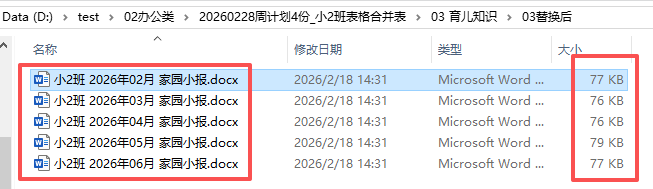



把docx转PDF
'''
育儿知识docx转PDF合并
deepseek 阿夏
20260228
'''
import os
import time
from docx2pdf import convert
from PyPDF2 import PdfMerger # 使用 PdfMerger 替代 PdfFileMerger
import shutil
def docx_to_pdf_merge():
path = r'D:\test\02办公类\20260228周计划4份_小2班表格合并表\03 育儿知识'
source_folder = path + r'\03替换后' # 源文件夹(已经替换好的docx文件)
print("=" * 50)
print("开始处理docx转PDF合并...")
print("=" * 50)
# 检查源文件夹是否存在
if not os.path.exists(source_folder):
print(f"错误:源文件夹不存在 - {source_folder}")
return
# 获取所有docx文件
docx_files = [f for f in os.listdir(source_folder) if f.endswith('.docx') and not f.startswith('~$')]
if not docx_files:
print(f"在 {source_folder} 中没有找到DOCX文件")
return
print(f"找到 {len(docx_files)} 个DOCX文件:")
for f in docx_files:
print(f" - {f}")
# 创建PDF文件夹(可选,用于存放单个PDF)
pdf_folder = os.path.join(source_folder, 'pdf_files')
if not os.path.exists(pdf_folder):
os.makedirs(pdf_folder)
print("\n开始转换DOCX到PDF...")
# 将每个docx文件转换为PDF
pdf_paths = []
for i, docx_file in enumerate(docx_files, 1):
try:
doc_path = os.path.join(source_folder, docx_file)
# 将PDF保存到pdf_folder中
pdf_name = docx_file.replace('.docx', '.pdf')
pdf_path = os.path.join(pdf_folder, pdf_name)
print(f" 正在转换 ({i}/{len(docx_files)}): {docx_file} -> {pdf_name}")
# 转换docx到pdf
convert(doc_path, pdf_path)
# 等待一下确保文件保存完成
time.sleep(1)
# 检查PDF是否生成成功
if os.path.exists(pdf_path):
pdf_paths.append(pdf_path)
print(f" ✓ 转换成功")
else:
print(f" ✗ 转换失败")
except Exception as e:
print(f" ✗ 转换出错: {e}")
if not pdf_paths:
print("没有成功转换的PDF文件,退出")
return
print(f"\n成功转换 {len(pdf_paths)} 个PDF文件")
# 合并所有的PDF文件
print("\n开始合并PDF文件...")
try:
# 创建PdfMerger对象(新版本使用PdfMerger)
merger = PdfMerger()
# 将所有PDF文件添加到合并器中
for pdf_path in pdf_paths:
try:
print(f" 添加: {os.path.basename(pdf_path)}")
merger.append(pdf_path)
except Exception as e:
print(f" 添加失败: {e}")
# 输出合并后的PDF文件
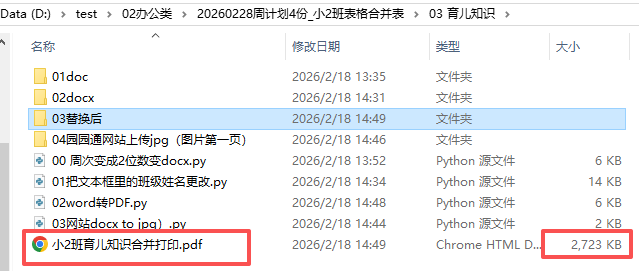
output_pdf_name = f'小2班育儿知识合并打印.pdf'
output_pdf_path = os.path.join(path, output_pdf_name)
print(f"\n正在写入合并文件: {output_pdf_name}")
merger.write(output_pdf_path)
merger.close()
print(f"\n✓ 所有PDF文件已合并到: {output_pdf_path}")
# 显示文件大小
if os.path.exists(output_pdf_path):
size = os.path.getsize(output_pdf_path) / 1024 # KB
print(f" 文件大小: {size:.2f} KB")
except Exception as e:
print(f"合并PDF时出错: {e}")
return
# 询问是否删除临时文件
print("\n" + "=" * 50)
delete_temp = input("是否删除临时PDF文件?(y/n): ").lower()
if delete_temp == 'y':
try:
# 删除pdf_folder及其所有内容
shutil.rmtree(pdf_folder)
print(f"已删除临时文件夹: {pdf_folder}")
except Exception as e:
print(f"删除临时文件时出错: {e}")
print("\n所有处理完成!")
def check_pypdf2_version():
"""检查PyPDF2版本"""
try:
import PyPDF2
print(f"PyPDF2版本: {PyPDF2.__version__}")
# 检查可用的类
print("可用的合并类:")
if hasattr(PyPDF2, 'PdfMerger'):
print(" - PdfMerger (推荐)")
if hasattr(PyPDF2, 'PdfFileMerger'):
print(" - PdfFileMerger (已弃用)")
except ImportError:
print("未安装PyPDF2")
except Exception as e:
print(f"检查版本时出错: {e}")
if __name__ == "__main__":
# 检查PyPDF2版本
print("检查PyPDF2版本...")
check_pypdf2_version()
print()
# 确认是否继续
confirm = 'y'
# input("确认要开始转换并合并PDF吗?(y/n): ")
if confirm.lower() != 'y':
print("操作已取消")
exit()
# 执行转换合并
docx_to_pdf_merge()
print("\n程序运行完成!")
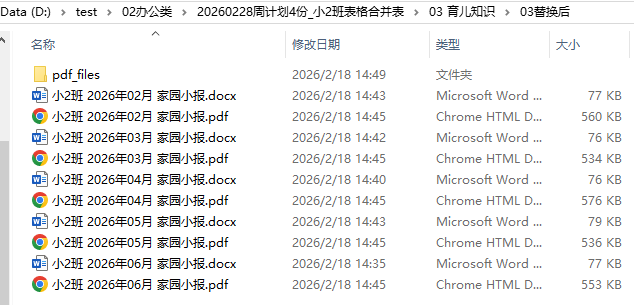

传网页的图片
'''
育儿知识docx转jpg
deepseek 阿夏
20260228
'''
import os
import time
import fitz # PyMuPDF
from PIL import Image
path=r'D:\test\02办公类\20260228周计划4份_小2班表格合并表\03 育儿知识'
old = path + r'\03替换后'
new = path + r'\04园园通网站上传jpg(图片第一页)'
os.makedirs(new, exist_ok=True)
print('--------使用PyMuPDF将PDF转换为JPG图片(仅第一页)---------')
# 遍历03替换后文件夹中的所有PDF文件
for file_name in os.listdir(old):
if file_name.endswith('.pdf'):
pdf_path = os.path.join(old, file_name)
try:
# 打开PDF文件
pdf_document = fitz.open(pdf_path)
# 只转换第一页(索引0)
if pdf_document.page_count > 0:
page = pdf_document[0] # 第一页
# 获取高质量图片(设置缩放系数提高清晰度)
zoom = 2 # 缩放系数,2表示200%质量
mat = fitz.Matrix(zoom, zoom)
pix = page.get_pixmap(matrix=mat)
# 生成输出文件名
output_filename = os.path.splitext(file_name)[0] + '.jpg'
output_path = os.path.join(new, output_filename)
# 保存为JPG图片
pix.save(output_path)
print(f"已转换: {file_name} -> {output_filename}")
else:
print(f"无法转换: {file_name} (PDF没有页面)")
pdf_document.close()
except Exception as e:
print(f"转换失败: {file_name}, 错误: {str(e)}")
time.sleep(0.1) # 短暂延迟
print('--------转换完成---------')


把内容复制到桌面的"园园通上传"的文件夹里
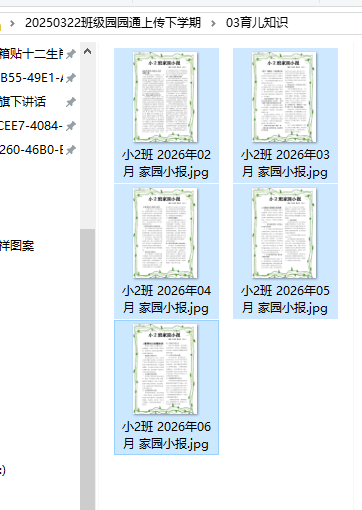
育儿知识是最简单的