本文译自「The Dawn of Offline AI Agents in Your Pocket」,原文链接medium.com/@denisov.sh...,由Sasha Denisov发布于2025年8月21日。

前言
在我之前的文章使用LoRA微调Gemma实现移动端推理中,我详细介绍了如何使用LoRA对Gemma模型进行微调,以实现设备端推理。我们涵盖了理论基础,并准备好了用于移动部署的模型。现在,激动人心的时刻到了------真正开始构建利用这些强大AI功能的移动或Web应用程序。
经过数月对flutter_gemma插件的开发和完善,我已经了解了在移动应用中实现设备端AI的哪些方法有效(哪些无效)。今天,我将分享我关于如何创建用户真正想要使用的、可用于生产环境的AI功能的全部心得。
我们正在进入移动开发的新时代。有了flutter_gemma,你不再只是构建连接到AI服务的应用程序------你创建的是完全自主、多模态的AI代理,它们完全驻留在用户的设备上。
想想这意味着什么。你的应用现在可以:
-
通过摄像头观察和理解世界,分析图像和文档,无需向云端发送任何数据
-
推理和思考复杂问题,并将思考过程透明地展示给用户
-
执行操作通过调用函数和集成设备功能,成为真正的数字助理
-
随时随地使用------无论是在飞机上、偏远地区,还是仅仅为了保护用户隐私
这不仅仅是为应用添加人工智能功能,而是从根本上重新定义移动应用。教育类应用可以成为理解手写作业的私人辅导老师;辅助功能应用可以成为与视障用户一同观察世界的AI伙伴;效率类应用可以成为不仅理解请求还能执行请求的智能代理。
你将学到什么
读完本文,你将掌握以下技能:
-
flutter_gemma 是什么,以及如何在现有的 Flutter 项目中进行设置
-
为你的特定用例选择合适的模型
-
构建能够理解文本和图像的多模态应用
-
创建可以调用外部函数的 AI 助手
-
实现"思考模式"来展示 AI 的推理过程
-
应对移动 AI 特有的挑战(内存、性能、用户体验)
-
将 AI 应用部署到生产环境
入门:你的第一个 AI 驱动的 Flutter 应用
我的旅程始于一个简单的目标:在 Flutter 应用中直接运行现代 AI 模型,完全离线。我探索了各种方案。有一些强大的工具,例如 llama.cpp,我的朋友 Georgios Soloupis 在他的文章 使用 llama.cpp 在移动设备上运行 Gemma 和 VLM 中出色地演示了它在 Android 上的应用。然而,就我使用 Flutter 的特定需求而言,我发现许多现有的解决方案,包括 llama.cpp 的封装,通常缺乏生产就绪的跨平台应用所需的稳定性和无缝集成。
突破性的进展来自于我发现了Google 的 MediaPipe。它功能强大,并针对设备端任务进行了优化,但有一个主要问题:它实际上并没有对 Flutter 提供官方支持。意识到这一缺陷后,我决定自己来弥补。这就是 flutter_gemma 的由来。
flutter_gemma 是一个 Flutter 插件,它通过 MediaPipe 将 Google 的 Gemma 系列和其他小型语言模型 (SLM) 的强大功能引入到你的应用中,使你能够在 iOS、Android 和 Web 上本地运行它们。自创建以来,它已被许多寻求稳定高效的方式来构建设备端 AI 功能的开发者所采用。
第一次运行它时,你会感觉像魔法一样,但这需要对细节的仔细关注。
完整的最新安装说明始终位于项目的 README.md 中。务必严格按照 iOS、Android 和 Web 平台的具体步骤进行操作。 iOS 的 Podfile 文件中哪怕出现一个小小的错误,或者缺少授权,都可能导致应用无法运行。
如果你遇到任何问题,仓库中包含一个完整的 示例应用,保证可以正常运行。你可以将其作为参考,与自己的配置进行比较。

模型分发挑战
在深入代码之前,我们先来解决一个显而易见的问题:如何将 1~6GB 的 AI 模型部署到用户的设备上?
我最初接触 flutter_gemma 时,以为这很简单。但我错了。每个人在看完演示后都会问的第一个问题是:"这很酷,但我该如何将模型交付给生产环境的用户呢?"
手动部署方法
从技术上讲,你可以手动将模型部署到设备上进行测试:
-
Android :使用 ADB 推送模型文件:
adb push model.task /sdcard/Android/data/your.app.id/files/ -
iOS:使用 Xcode 的设备窗口或 iTunes 文件共享将模型复制到应用的文档目录
-
Web:托管模型文件并提供直接下载链接
但是,让用户在使用你的应用之前手动下载并安装 AI 模型,这难道不是一件好事吗?这可不是我心目中可以投入生产使用的用户体验。想象一下,你跟别人说:"嘿,下载我们的聊天应用!哦,对了,请手动下载这个 3GB 的文件,然后把它放到手机上正确的文件夹里。" :)
嗯,这肯定不会发生。
引入 ModelManager:解决方案
幸运的是,flutter_gemma 插件包含一个强大的 ModelManager 类,它抽象化了模型分发的所有复杂性。它可以自动处理平台特定的文件操作、进度跟踪和错误恢复。
模型管理器提供了三种将模型部署到设备上的主要方法:
-
资源打包 --- 用于小型模型和开发
-
网络下载 --- 用于生产环境应用(推荐)
-
自定义路径 --- 用于高级集成场景
下面我将逐一介绍每种方法及其适用场景:
资源打包方法(仅限有限使用)
Flutter 允许你将资源与应用打包在一起,最初,我认为这就是解决方案:
dart
// Don't do this for large models
await modelManager.installModelFromAsset('assets/models/gemma_1b.task');这种方法对于不太大的模型非常有效,但存在平台限制:iOS 和 Android 对资源包大小都有严格的限制。 iOS 应用如果大于 4GB,在 App Store 提交时将无法正常处理。Android 也有自己的限制:应用包总大小上限为 4GB,但任何单一设备配置的压缩下载大小限制为 200MB,而传统 APK 的大小上限仅为 100MB。
其实有"正确"的方法!
生产环境方案:智能模型加载
我经过数十个应用的实践,最终完善的解决方案就是我所说的"渐进式模型加载"。工作原理如下:
dart
class ProductionModelManager {
static const String MODEL_URL = 'https://your-cdn.com/models/qwen25_1_5b.task';
static const String MODEL_FILENAME = 'qwen25_1_5b.task';
Future<void> ensureModelReady() async {
final modelManager = FlutterGemmaPlugin.instance.modelManager;
// Check if model is already downloaded
if (await modelManager.isModelInstalled) {
return; // We're good to go
}
// Show download UI to user
await _downloadModelWithProgress();
}
Future<void> _downloadModelWithProgress() async {
final modelManager = FlutterGemmaPlugin.instance.modelManager;
// This is where the magic happens - with real-time progress updates
await modelManager.downloadModelFromNetwork(
MODEL_URL,
onProgress: (progress) {
// progress is a double from 0.0 to 1.0
final percentage = (progress * 100).toStringAsFixed(1);
print('Download progress: $percentage%');
// Update UI with download progress
setState(() {
_downloadProgress = progress;
_downloadStatus = 'Downloading AI model... $percentage%';
});
},
);
}
// UI method to show download progress
void _updateDownloadProgress(double progress) {
setState(() {
_downloadProgress = progress;
if (progress >= 1.0) {
_downloadStatus = 'AI model ready!';
} else {
final percentage = (progress * 100).toStringAsFixed(1);
_downloadStatus = 'Downloading AI model... $percentage%';
}
});
}
}为什么网络下载是生产标准
这种方法的主要优势如下:
-
应用体积小:你的应用只需几秒即可下载,无需几分钟
-
模型更新:无需在应用商店发布即可更新 AI 模型
-
基于 LoRA 的动态个性化:通过动态下载小型 LoRA 适配器文件(几兆字节),即可将不同的微调行为立即应用到基础模型
-
设备特定优化:根据设备功能提供不同的模型变体
-
成本控制:用户只需在需要时下载所需内容
-
A/B 测试:针对不同的用户群体测试不同的模型
为确保下载快速可靠,该插件使用了 background_downloader 包以优化性能。
首次运行体验
以下是我发现效果最佳的用户流程:
-
用户下载你的应用(体积小,下载速度快)
-
应用打开后显示引导页面,介绍 AI 功能
-
用户点击"启用 AI 功能"
-
应用下载模型并显示进度指示器
-
用户下载完成后即可立即开始使用 AI 功能
我总结的关键用户体验洞察:始终显示进度 --- 用户需要知道正在发生什么,显示文件大小信息 --- "1.2GB 中的 3.2MB" 可以帮助用户理解等待时间,妥善处理错误 --- 提供重试选项,而不仅仅是错误消息
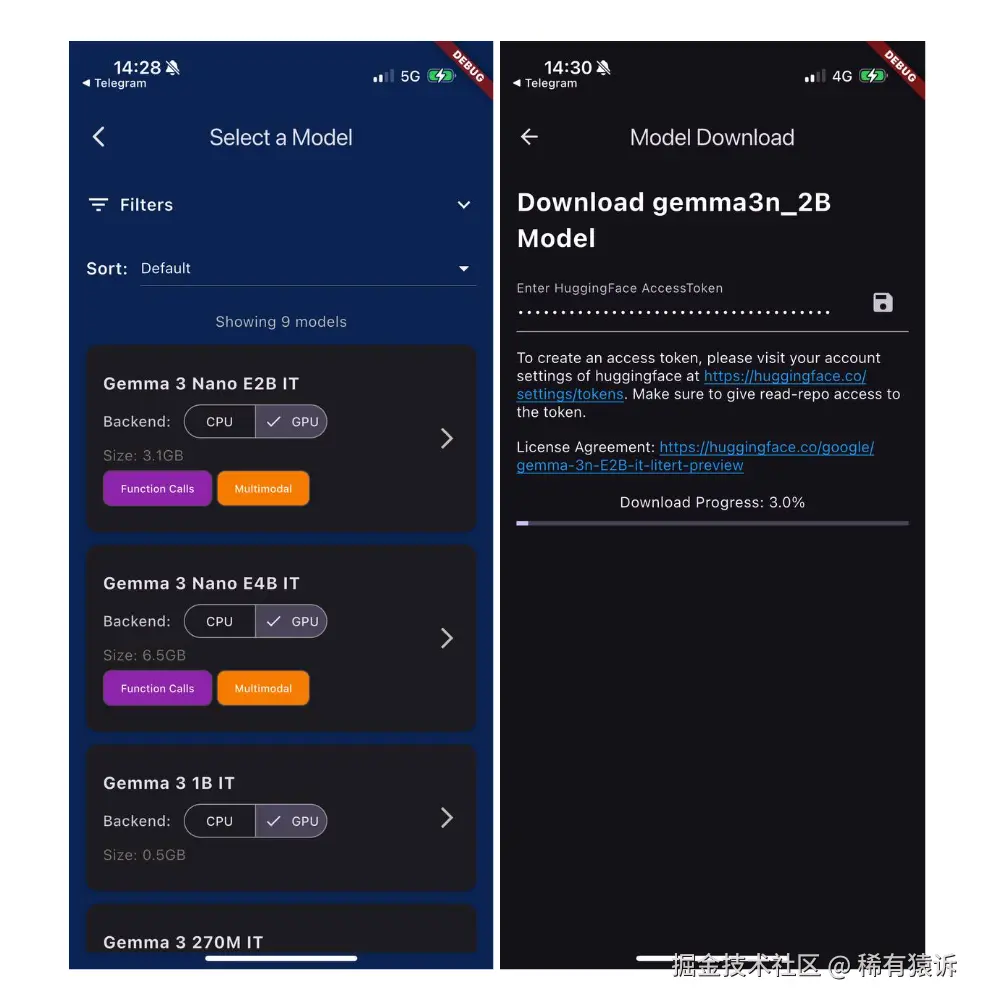
好了,我们已经找到了将模型交付到设备的方法。接下来我们来讨论推理。
理解推理类型:聊天模式 vs. 单次响应模式
flutter_gemma 插件提供了两种不同的 AI 交互模式,每种模式都针对不同的用途进行了优化。选择合适的模式是构建高效应用的关键:单次推理 适用于一次性、无状态的请求,而聊天界面适用于有状态的、持续的对话。
单次推理:适用于无状态的单次任务
可以将单次推理理解为每次都向模型的一个全新实例提出问题。模型不会记住过去的交互。这种模式非常适合事务性任务,因为在事务性任务中,不需要从一次请求到下一次请求的上下文信息。
用途:
-
文本摘要: 向模型提供一篇长文章,并请求其生成简洁的摘要。
-
数据提取: 分析一段文本,提取特定信息,例如姓名、日期或情感倾向。
-
简单问答: 回答一个独立的问题,例如"法国的首都是哪里?"
-
图像分析: 使用具备视觉能力的模型描述单张图像的内容。
以下是如何使用它来概括一段文本:
dart
// 1. Create a model instance
final model = await gemma.createModel(modelType: ModelType.general);
// 2. Create a stateless session
final session = await model.createSession();
// 3. Generate a single, streaming response
final article = "Your long article text goes here...";
final prompt = "Summarize the following article in three sentences: $article";
String summary = '';
await for (final token in session.generateResponseAsync(prompt)) {
summary += token;
// Update your UI with the streaming summary in real-time
}
print(summary);
// 4. Clean up the session
await session.close();聊天界面:用于有状态的对话式 AI
聊天界面旨在构建对话体验。它会自动管理对话历史记录,因此每条新消息都能在之前所有对话的上下文中被理解。你可以使用此模式来构建聊天机器人、助手以及任何需要来回对话的功能。
用途:
-
客户支持聊天机器人: 在多个回合中协助用户解决问题。
-
AI 导师: 通过持续的、不断发展的对话来帮助用户学习。
-
多步骤任务执行: 引导用户完成一个流程,其中 AI 需要记住之前的回答。
以下是一个简单的多轮对话示例:
dart
// 1. Create a model and a stateful chat instance
final model = await gemma.createModel(modelType: ModelType.general);
final chat = await model.createChat();
// 2. Send the first user message
await chat.addQuery(Message.text(text: "I'm planning a trip to Japan. What's a good city for a first-time visitor?", isUser: true));
// 3. Stream the AI's response
String aiResponse1 = '';
await for (final response in chat.generateChatResponseAsync()) {
if (response is TextResponse) {
aiResponse1 += response.token;
}
}
print("AI: $aiResponse1"); // e.g., "Tokyo is a great choice..."
// 4. Ask a follow-up question. The AI remembers the context (Japan, Tokyo).
await chat.addQuery(Message.text(text: "What's the best way to get around there?", isUser: true));
// 5. Stream the second response
String aiResponse2 = '';
await for (final response in chat.generateChatResponseAsync()) {
if (response is TextResponse) {
aiResponse2 += response.token;
}
}
print("AI: $aiResponse2"); // e.g., "The subway system in Tokyo is fantastic..."关键区别很简单:单次推理 用于无记忆的事务性请求,而聊天界面用于随着时间的推移构建上下文和关系。
你的第一个 AI 聊天
既然我们已经了解了核心概念,那么了解它们实际应用的最佳方法是查看一个完整的、可运行的示例。这里只提供一个简单的代码片段,我鼓励你探索代码库中包含的示例应用程序。
它包含一个完全实现的简单聊天界面,演示了如何管理模型状态、处理用户输入以及显示来自离线 AI 机器人的流式响应。它是完美的起点和可靠的参考资料。
你可以在示例应用程序文件夹中找到完整的实现。
我学到的关键经验:始终显示加载状态。模型初始化在移动设备上可能需要 10~30 秒,用户需要知道正在发生什么。
现在你已经了解如何实现聊天功能,接下来需要做出一个关键决定:为你的应用程序选择合适的 AI 模型。
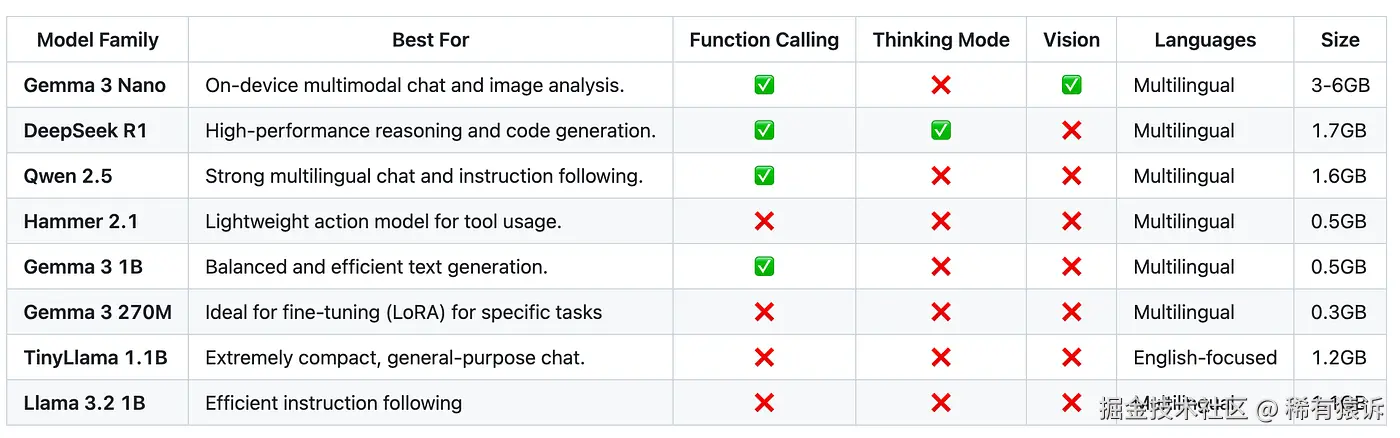
了解模型功能:选择你的 AI 合作伙伴
并非所有模型都一样。经过数十种组合的测试,以下是我对不同应用场景下最佳模型的真实评估:
实际模型选择示例
当我们构建 LiveCaptionsXR(一个用于实时字幕的 AI 辅助功能平台)时,我需要快速推理、具备处理屏幕内容的视觉能力以及合理的内存占用。我选择了 Gemma 3n 2B,因为它是满足所有标准(尤其是视觉支持)的最小模型。
关键不在于是否存在单一的"最佳"模型,而在于根据你的主要应用场景进行选择。以下是简要指南:
-
纯函数调用: 如果你的应用的主要目标是将用户命令转换为操作(例如智能助手),Hammer 2.1 正是为此而设计的。它以极低的开销出色地使用各种工具。
-
包含函数调用的通用聊天: 如果你需要一个优秀的对话者,并且能够可靠地使用各种工具,Qwen 2.5 或 Gemma 2 都是绝佳的选择。
-
简单轻量级聊天: 如果你只需要一个功能强大的对话式 AI,而不需要高级功能,Gemma 3 1B 是我的首选。它只有 500MB,下载和初始化速度都非常快。
-
查看 AI 的推理过程: 如果你想了解模型的思考过程,DeepSeek R1 是唯一支持"思考模式"的选项。
-
针对高度特定、精细化的任务: 当你的任务非常具体且需要最高效率时,超紧凑的 Gemma 3 270M 是使用 LoRA 进行精细化调整的理想选择。你可以利用其极小的资源占用,创建高度专业化的专家模型。
稍后我会详细讲解一些具体示例的实现。但在那之前,我们需要了解 flutter_gemma 的一些核心概念,这些概念将在每个实现中用到。
核心概念:消息、响应和流式传输
flutter_gemma API 构建于几个核心概念之上,在构建 UI 之前,理解这些概念至关重要。从简单的文本字符串过渡到结构化数据,是解锁插件最强大功能的关键。
消息类型:不仅仅是文本
首先,你发送给模型的每一条信息都会被封装在一个 Message 对象中。这是对话历史记录的基本构建模块。你不再直接发送原始字符串,而是创建一个 Message 对象来描述输入的性质。这种面向对象的方法支持多模态输入和函数调用等高级功能。
以下代码展示了你可以构建的不同类型的消息:
dart
// Text-only message - the most common type
final textMsg = Message.text(text: "Hello AI!", isUser: true);
// Image + text (multimodal) - for vision-capable models
final imageMsg = Message.withImage(
text: "What's in this image?",
imageBytes: await getImageBytes(),
isUser: true,
);
// Tool response - to feed the result of a function call back to the model
final toolMsg = Message.toolResponse(
toolName: 'get_weather',
response: {'temperature': 72, 'condition': 'sunny'},
);
// System information - for displaying info in the UI that isn't sent to the model
final systemMsg = Message.systemInfo(text: "Function completed");
// Thinking content - for displaying the model's reasoning process (DeepSeek only)
final thinkingMsg = Message.thinking(text: "Let me analyze this...");响应类型:理解 AI 输出
正如你的输入是结构化的一样,模型的输出也是结构化的。模型不会仅仅返回一个最终的文本块。相反,它会返回一个 ModelResponse 对象流,其中每个对象代表一种不同的输出类型。模型可能生成纯文本,也可能决定调用你的某个函数。你的应用程序逻辑必须准备好处理来自模型的这些不同的"意图"。
这通常在响应流的 listen 代码块中处理,你可以在其中检查每个传入响应对象的类型并采取相应的操作:
dart
chat.generateChatResponseAsync().listen((response) {
if (response is TextResponse) {
// This is a regular text token. Append it to your chat bubble.
_updateChatBubble(response.token);
} else if (response is FunctionCallResponse) {
// The AI wants to call a function. Execute it now.
await _handleFunctionCall(response);
} else if (response is ThinkingResponse) {
// The AI is "thinking" (DeepSeek only). Show this in the UI.
_updateThinkingBubble(response.content);
}
});流式处理 vs. 批处理:用户体验差异
这是构建优秀 AI 应用最重要的概念之一。你应该始终流式处理模型的响应,而不是等待生成完整的文本(批处理)。
原因完全在于用户体验。等待完整的响应可能需要几秒钟,这会让应用感觉缓慢、卡顿或"冻结"。相比之下,逐个 token 地流式处理响应会让应用感觉非常快速且交互性强,因为用户可以实时看到 AI 的"输入"。即使总生成时间相同,流式版本的"感知性能"也明显更好。
以下是标准实现方式,你需要累积流式令牌,并在每个新事件发生时更新 UI:
dart
String _accumulatedText = '';void _processStreamingResponse() async {
await for (final response in chat!.generateChatResponseAsync()) {
if (response is TextResponse) {
setState(() {
_accumulatedText += response.token;
// Update the last message in your message list with the new accumulated text
_messages.last = Message.text(text: _accumulatedText);
});
}
}
}现在我们已经了解了基本概念,接下来让我们通过详细示例来学习如何处理除文本之外的其他数据。
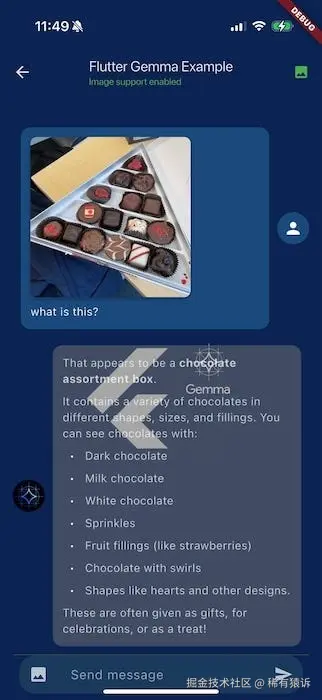
高级功能 #1:多模态 AI(让你的应用拥有视觉能力)
当我的 Flutter 应用实现图像理解功能时,我就知道移动 AI 已经跨越了一个门槛。以下是如何构建能够真正"看"和理解图像的应用。
设置支持视觉的模型
目前只有 Gemma 3 Nano 模型支持视觉功能。设置略有不同:
dart
final model = await _gemma.createModel(
modelType: ModelType.gemmaIt,
supportImage: true,
// Enable vision
maxNumImages: 1,
// How many images per message
maxTokens: 4096,
// Vision models need more tokens
);
final chat = await model.createChat(
supportImage: true,
tokenBuffer: 512,
// Larger buffer for image processing
);构建图像分析功能
以下是我用于分析图像的完整实现:
dart
class ImageAnalyzer extends StatefulWidget {
@override
_ImageAnalyzerState createState() => _ImageAnalyzerState();
}
class _ImageAnalyzerState extends State<ImageAnalyzer> {
Uint8List? _selectedImage;
String _analysis = '';
bool _analyzing = false;
Future<void> _pickAndAnalyzeImage() async {
final picker = ImagePicker();
final image = await picker.pickImage(source: ImageSource.gallery);
if (image != null) {
final bytes = await image.readAsBytes();
setState(() {
_selectedImage = bytes;
_analyzing = true;
});
await _analyzeImage(bytes);
}
}
Future<void> _analyzeImage(Uint8List imageBytes) async {
final message = Message.withImage(
text: "Analyze this image in detail. What do you see?",
imageBytes: imageBytes,
isUser: true,
);
await chat!.addQuery(message);
String analysis = '';
await for (final response in chat!.generateChatResponseAsync()) {
if (response is TextResponse) {
setState(() {
analysis += response.token;
_analysis = analysis;
});
}
}
setState(() => _analyzing = false);
}
// ... UI implementation
}
高级功能 #2:函数调用(当 AI 接触现实世界)
函数调用是设备端 AI 真正强大的地方。AI 不仅可以生成文本,还可以执行实际操作------调用 API、更新数据库、控制设备功能。
理解工具和函数
可以将工具视为你向 AI 公开的 API。 AI 会根据用户请求决定何时调用函数:
dart
final List<Tool> appTools = [
Tool(
name: 'get_weather',
description: 'Get current weather for a location',
parameters: {
'type': 'object',
'properties': {
'location': {
'type': 'string',
'description': 'City name or address'
}
},
'required': ['location']
}
),
Tool(
name: 'set_reminder',
description: 'Create a reminder for the user',
parameters: {
'type': 'object',
'properties': {
'title': {'type': 'string'},
'datetime': {'type': 'string', 'format': 'datetime'},
'priority': {'type': 'string', 'enum': ['low', 'medium', 'high']}
},
'required': ['title', 'datetime']
}
)
];实现函数执行
当 AI 需要调用函数时,你需要执行该函数并返回结果:
dart
Future<Map<String, dynamic>> _executeTool(FunctionCallResponse functionCall) async {
switch (functionCall.name) {
case 'get_weather':
final location = functionCall.args['location'] as String;
return await _getWeatherData(location);
case 'set_reminder':
final title = functionCall.args['title'] as String;
final datetime = DateTime.parse(functionCall.args['datetime']);
await _createReminder(title, datetime);
return {'status': 'success', 'reminder_id': '12345'};
default:
return {'error': 'Unknown function: ${functionCall.name}'};
}
}
Future<Map<String, dynamic>> _getWeatherData(String location) async {
// Call actual weather API
final response = await http.get(
Uri.parse('https://api.weather.com/v1/current?location=$location')
);
if (response.statusCode == 200) {
final data = jsonDecode(response.body);
return {
'temperature': data['temperature'],
'condition': data['condition'],
'humidity': data['humidity']
};
} else {
return {'error': 'Failed to get weather data'};
}
}
高级功能 #3:思考模式(观察 AI 的推理过程)
某些模型型号提供的"思考模式"非常吸引人------你可以亲眼目睹 AI 一步步解决问题的过程。这就像拥有一个透明的 AI,可以清晰地展示它的工作原理。
理解思考模式
启用思考模式后,AI 的推理过程与其最终结果将分开记录:
dart
final chat = await model.createChat(
isThinking: true,
modelType: ModelType.deepSeek,
temperature: 0.7,
);
chat.generateChatResponseAsync().listen((response) {
if (response is ThinkingResponse) {
// AI is thinking - show reasoning process
_showThinkingBubble(response.content);
} else if (response is TextResponse) {
// Final answer - show normal response
_showChatMessage(response.token);
}
});构建思考模式 UI 组件
我创建了可展开的"Thinking气泡",让用户可以窥探 AI 的推理过程:
dart
class ThinkingBubble extends StatefulWidget {
final String thinkingContent;
final bool isComplete;
@override
_ThinkingBubbleState createState() => _ThinkingBubbleState();
}
class _ThinkingBubbleState extends State<ThinkingBubble> {
bool _isExpanded = false;
@override
Widget build(BuildContext context) {
return Container(
margin: EdgeInsets.symmetric(vertical: 4),
decoration: BoxDecoration(
color: Colors.blue.withOpacity(0.1),
borderRadius: BorderRadius.circular(12),
border: Border.all(color: Colors.blue.withOpacity(0.3)),
),
child: Column(
children: [
ListTile(
leading: Icon(Icons.psychology, color: Colors.blue),
title: Text(
'AI is thinking...',
style: TextStyle(color: Colors.blue, fontWeight: FontWeight.w500),
),
trailing: widget.isComplete
? IconButton(
icon: Icon(_isExpanded ? Icons.expand_less : Icons.expand_more),
onPressed: () => setState(() => _isExpanded = !_isExpanded),
)
: SizedBox(
width: 16,
height: 16,
child: CircularProgressIndicator(strokeWidth: 2),
),
),
if (_isExpanded && widget.thinkingContent.isNotEmpty)
Container(
padding: EdgeInsets.all(16),
child: Text(
widget.thinkingContent,
style: TextStyle(
fontFamily: 'monospace',
fontSize: 12,
color: Colors.grey[700],
),
),
),
],
),
);
}
}
何时使用思考模式
Thinking模式非常适合:
-
教育类应用 --- 学生可以了解 AI 如何解决问题
-
调试工具 --- 开发者可以了解 AI 的问题解决方法
-
复杂推理任务 --- 用户可以在信任结果之前验证 AI 的逻辑
但它也带来了一些问题延迟较高且会消耗更多Token,因此请谨慎使用。
实际应用案例
LiveCaptionsXR:AI 无障碍平台
LiveCaptionsXR 就是一个强大的实际应用案例,它是一个基于 AI 的无障碍平台。该项目源于加州聋人开发者 Craig Merry 的一个想法,我们合作开发了该项目,并参加了 Gemma 3n Challenge。我们的目标是解决听力障碍人士面临的一个关键问题:不仅转录语音,还能通过在 3D 空间渲染字幕来显示说话者的身份和位置。该项目目前正处于积极开发阶段,初始 MVP 版本现已发布。
该应用程序完全在设备端运行,以保护隐私并支持离线使用,它使用多模态 Gemma 模型来处理音频和视觉数据。它还利用 flutter_gemma 的函数调用功能,使用户能够通过自然语言语音命令控制辅助功能,例如字幕大小。你可以在 YouTube 上观看我们的宣传视频。

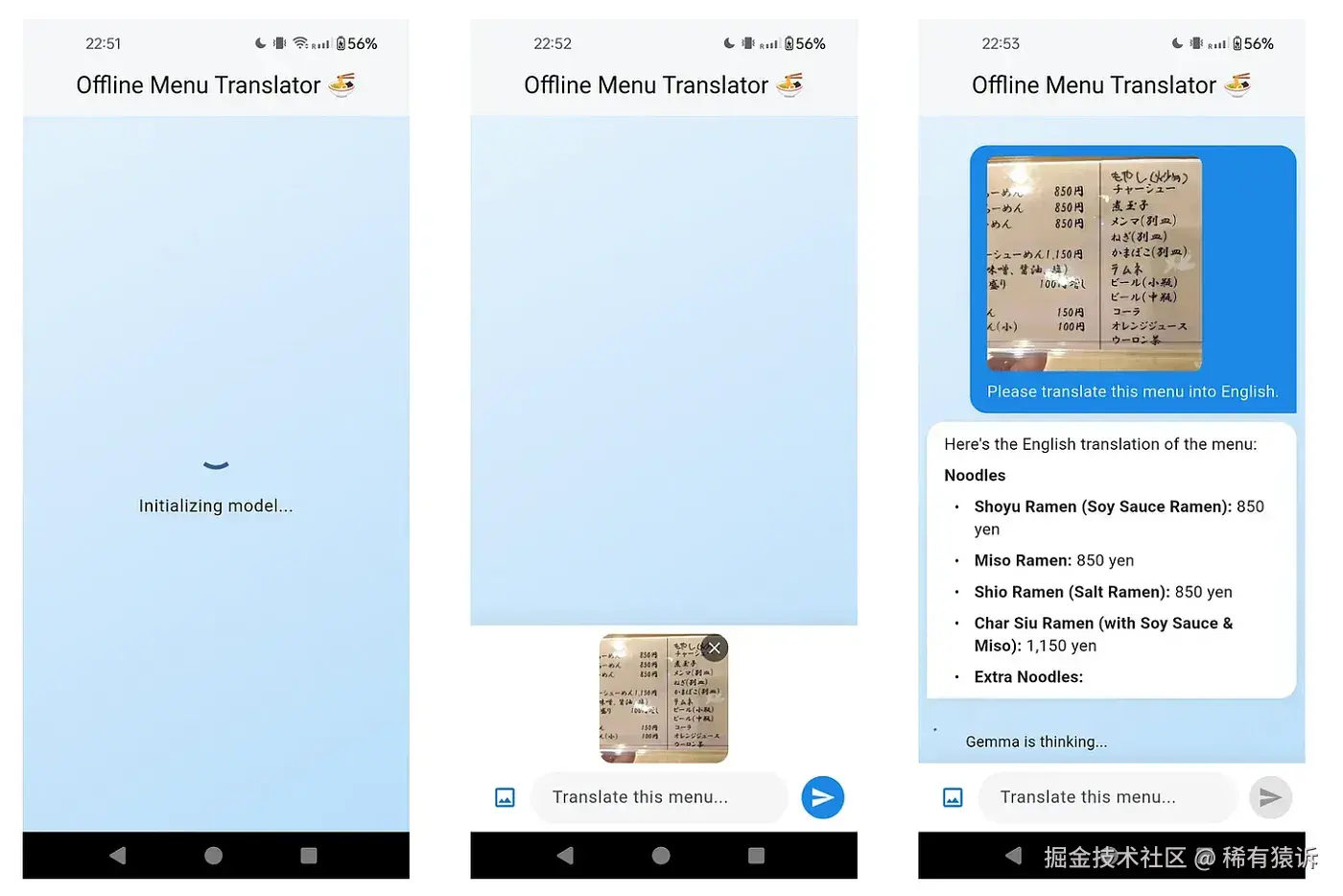
离线菜单翻译器
我们都遇到过这样的挑战:身处异国他乡,渴望品尝当地美食,却发现餐厅菜单上的语言你看不懂,而且没有 Wi-Fi。这正是设备端多模态人工智能的完美应用场景,正如 Csongor Vogel 在一篇精彩的文章 Using Gemma for Flutter apps 中展示的那样。
借助 flutter_gemma,你可以构建一个使用视觉模型作为个人翻译器的应用。用户只需将摄像头对准菜单即可。模型会处理图像,识别外语文本(例如日语),并将其翻译成用户的语言。关键在于,所有操作都在设备端即时完成,确保应用在任何地方都能正常运行,并且图像始终保存在用户的手机中。
其核心逻辑是将图像连同翻译请求一起发送给模型,如下方简化示例所示。
MenuMind:你的智能营养指南
MenuMind 也诞生于 Gemma 3n 挑战赛,它是开发者 Mohamed Abdo 的项目。这款应用将菜单分析的概念更进一步。它不仅提供翻译功能,还能作为智能营养和过敏原指南。
用户可以拍摄菜单照片,多模态人工智能不仅会翻译菜品名称,还会识别潜在的过敏原或提供营养信息。这完美地展现了如何利用模型的推理能力,为有饮食限制的用户提供真正的价值。你可以在 YouTube 上观看该应用的演示视频。

紧急助手:离线急救助手
另一个令人振奋的项目是紧急助手,这是一款可靠的离线急救助手应用。这款应用由 Siddharth Joshi、Vera Austermann 和 Jakub Niemiec 共同开发,旨在为各种紧急情况提供分步指导,涵盖从割伤、烧伤到更严重的伤情。
正如他们在 YouTube 上的演示视频所示,该应用的关键特性在于其可在设备本地运行,即使没有网络连接也能可靠使用。为了确保指导的安全性和准确性,团队利用 LoRA 技术对 Gemma 模型进行了微调,使其能够更好地识别医学术语。

未来路线图和社区
flutter_gemma 插件正在积极发展。以下是即将推出的功能以及你如何参与其中:
即将推出的功能
接下来:
-
完整的多模态 Web 支持: 在 Web 平台上实现与实体平台相同的图像输入功能。
-
文本嵌入支持: 添加生成文本嵌入的功能,这是实现设备端搜索的关键第一步。
-
设备端 RAG 管道: 实现辅助类和示例,用于构建完整的检索增强生成系统,该系统可以查询本地向量数据库。
更远的未来:
-
桌面支持(macOS、Windows、Linux): 将设备端推理功能引入桌面平台。
-
音频和视频输入: 扩展多模态功能,使其能够处理音频和视频流。
-
音频输出(文本转语音): 集成设备端文本转语音功能,使 AI 能够以语音方式响应。
为项目做贡献
我创建 flutter_gemma 是因为我相信设备端 AI 是移动应用的未来。社区的反响非常热烈,我非常希望得到你的帮助,让它变得更好:
贡献方式:
-
报告问题 --- 发现 bug?请在 GitHub 上提交 issue。
-
修复 bug --- 发现你可以解决的未解决问题?欢迎提交 pull request。
-
实现功能 --- 受到路线图的启发?欢迎为新功能做出贡献。
-
分享示例 --- 开发了一些很棒的作品?与社区分享
-
改进文档 --- 帮助新手更轻松地上手
-
测试新模型 --- 试用新模型版本并分享性能数据
GitHub 代码库 github.com/DenisovAV/f...
特别感谢所有为改进本项目做出贡献的开发者,包括 Jhin Lee、Zemlianikin Max、Ahmet TOK、Csongor Vogel、Alex Vegner 和 Vinayak Amirtharajand。
想了解更多人工智能驱动的 Flutter 内容?关注我,深入探讨移动人工智能、性能优化和实际应用策略。让我们携手共建智能移动应用的未来!
未来比你想象的更近,离线代理是其中的重要组成部分!

本文是我关于移动应用中人工智能实际应用系列文章的一部分。接下来是:"使用 FunctionGemma 进行设备端函数调用"------订阅即可获取最新资讯。
联系作者: GitHub, LinkedIn, Medium, X
欢迎搜索并关注 公众号「稀有猿诉」 获取更多的优质文章!
保护原创,请勿转载!