前提:这些业务和钱的关系不大,并不需要重视并发的问题,所以我就不加锁了。
1.博客点赞限制,同一个用户只能点赞一次。我感觉没必要。
需求:
* 同一个用户只能点赞一次,再次点击则取消点赞
* 如果当前用户已经点赞,则点赞按钮高亮显示(前端已实现,判断字段Blog类的isLike属性)
实现步骤:
* 给Blog类中添加一个isLike字段,标示是否被当前用户点赞(用户查询博客的时候返回给前端的),如果当前用户已经点赞,则点赞按钮高亮显示。
* 修改点赞功能,利用Redis的set集合判断是否点赞过,未点赞过则点赞数+1,已点赞过则点赞数-1(给每一个博客一个redis的set集合)
* 所有根据id查询Blog的业务,判断当前登录用户是否点赞过,赋值给isLike字段。
java
@Override
public Result likeBlog(Long id){
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是否已经点赞
String key = BLOG_LIKED_KEY + id;
Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
if(BooleanUtil.isFalse(isMember)){
//3.如果未点赞,可以点赞
//3.1 数据库点赞数+1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
//3.2 保存用户到Redis的set集合
if(isSuccess){
stringRedisTemplate.opsForSet().add(key,userId.toString());
}
}else{
//4.如果已点赞,取消点赞
//4.1 数据库点赞数-1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
//4.2 把用户从Redis的set集合移除
if(isSuccess){
stringRedisTemplate.opsForSet().remove(key,userId.toString());
}
}BooleanUtil.isFalse(isMember)还是那个问题,只要是redis查出来的,可能是null(发生问题),所以不能写成if(isMember)可能会出现空指针异常,这个要习惯并且记住
2.达人探店-点赞排行榜,看的是谁点赞的时间,而不是那个博客点赞多,笑死了
之前的点赞是放到set集合,但是set集合是不能排序的,所以这个时候,可以采用一个可以排序的set集合,就是咱们的sortedSet,以时间搓作为得分值。
改进之前的代码即可:
java
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是否已经点赞
String key = BLOG_LIKED_KEY + id;
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if (score == null) {
// 3.如果未点赞,可以点赞
// 3.1.数据库点赞数 + 1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2.保存用户到Redis的set集合 zadd key value score
if (isSuccess) {
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {
// 4.如果已点赞,取消点赞
// 4.1.数据库点赞数 -1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
// 4.2.把用户从Redis的set集合移除
if (isSuccess) {
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}然后就是实现这个查询功能:
java
public List<UserDTO> queryBlogLikes(Long id) {
String key = BLOG_LIKED_KEY + id;
//1.查询top5的点赞用户,根据Redis的zset数据结构 zrange key 0 4
Set<String> range = stringRedisTemplate.opsForZSet().range(key, 0, 4);
if (range == null || range.isEmpty()){
return Collections.emptyList();
}
//2.查出来的是string类型,需要转换成long类型
List<Long> collect = range.stream().map(Long::valueOf).collect(Collectors.toList());
//3.根据id列表查询用户信息 where id in ()
List<User> users = userMapper.selectBatchIds1(collect);
//4.转换成UserDTO列表
List<UserDTO> collect1 = users.stream()
.map(user -> {
UserDTO userDTO = new UserDTO();
BeanUtil.copyProperties(user, userDTO);
return userDTO;
}).collect(Collectors.toList());
//5.返回
return collect1;
}if (range == null || range.isEmpty()){
return Collections.emptyList();
}这是不一样的前面是判断有没有,后面是判断是不是空集合,因为可能啥用查不出来。 Collections.emptyList()就是生成一个空的集合。
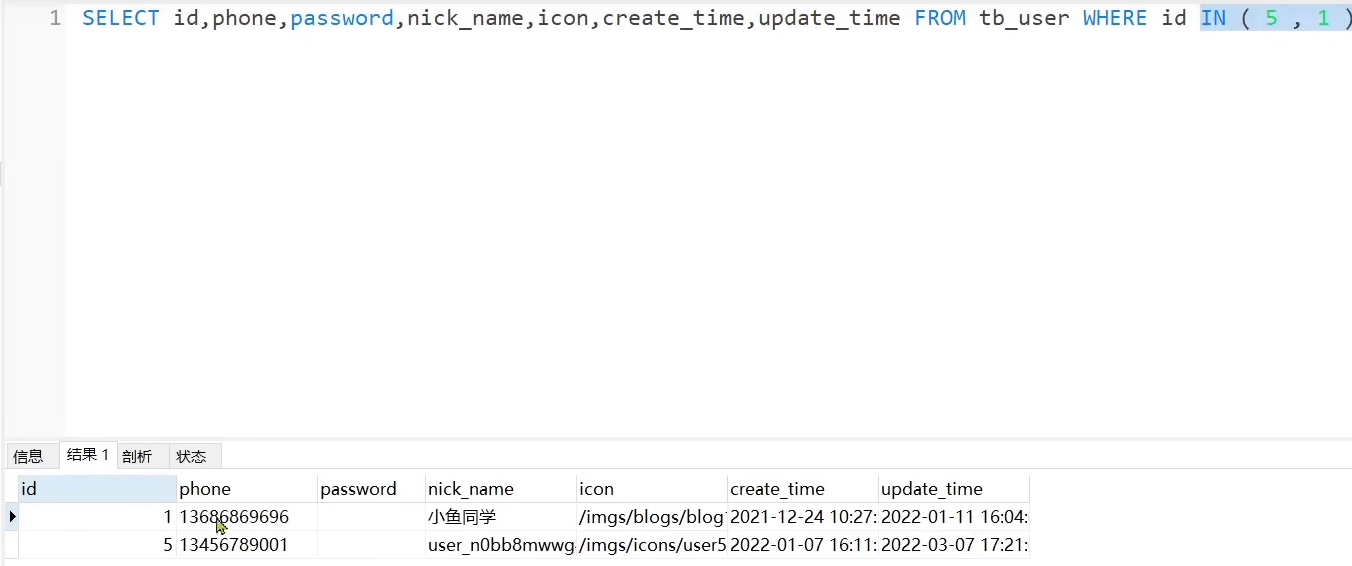
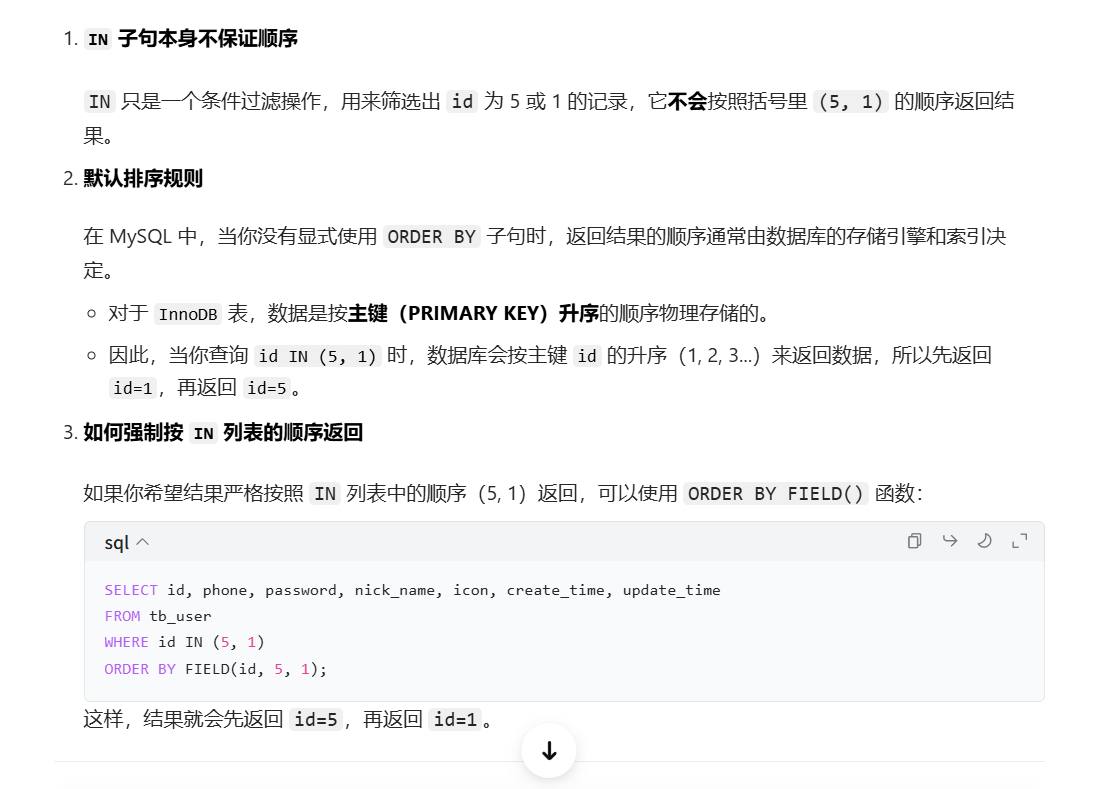
但是会出现一个问题:就是我们给数据库的集合是从前到后,执行的也是从前到后,
为什么返回的是从后到前呢?这是因为id in (),给的是从前到后,但是实际查询的其实是按照主键排序的,in只是起到一个升序的作用
最后xml文件里应该这样写:
XML<select id="selectBatchIds1" resultType="com.hmdp.entity.User"> select * from tb_user where id in <foreach item="id" collection="collect" separator="," open="(" close=")"> #{id} </foreach> order by field(id, <foreach item="id" collection="collect" separator="," open="(" close=")"> #{id} </foreach> ) </select>
3.共同关注啥的我就不写了,很简单,用redis的set集合的交集即可。
java
public Result followCommons(Long id) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
String key = "follows:" + userId;
// 2.求交集
String key2 = "follows:" + id;
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
if (intersect == null || intersect.isEmpty()) {
// 无交集
return Result.ok(Collections.emptyList());
}
// 3.解析id集合
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
// 4.查询用户
List<UserDTO> users = userService.listByIds(ids)
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(users);
}我们重点看一下,feed流实现方案:
当我们关注了用户后,这个用户发了动态,那么我们应该把这些数据推送给用户,这个需求,其实我们又把他叫做Feed流,关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。
Feed流产品有两种常见模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
* 优点:信息全面,不会有缺失。并且实现也相对简单
* 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
* 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
* 缺点:如果算法不精准,可能起到反作用
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:
我们本次针对好友的操作,采用的就是Timeline的方式,只需要拿到我们关注用户的信息,然后按照时间排序即可,因此采用Timeline的模式。该模式的实现方案有三种:
* 拉模式:也叫做读扩散
该模式的核心含义就是:当张三和李四和王五发了消息后,都会保存在自己的邮箱中,假设赵六要读取信息,那么他会读取他自己的收件箱,此时系统会从他关注的人群中,把他关注人的信息全部都进行拉取,然后在进行排序
优点:比较节约空间,因为赵六在读信息时,并没有重复读取,而且读取完之后可以把他的收件箱进行清楚。
缺点:比较延迟,当用户读取数据时才去关注的人里边去读取数据,假设用户关注了大量的用户,那么此时就会拉取海量的内容,对服务器压力巨大。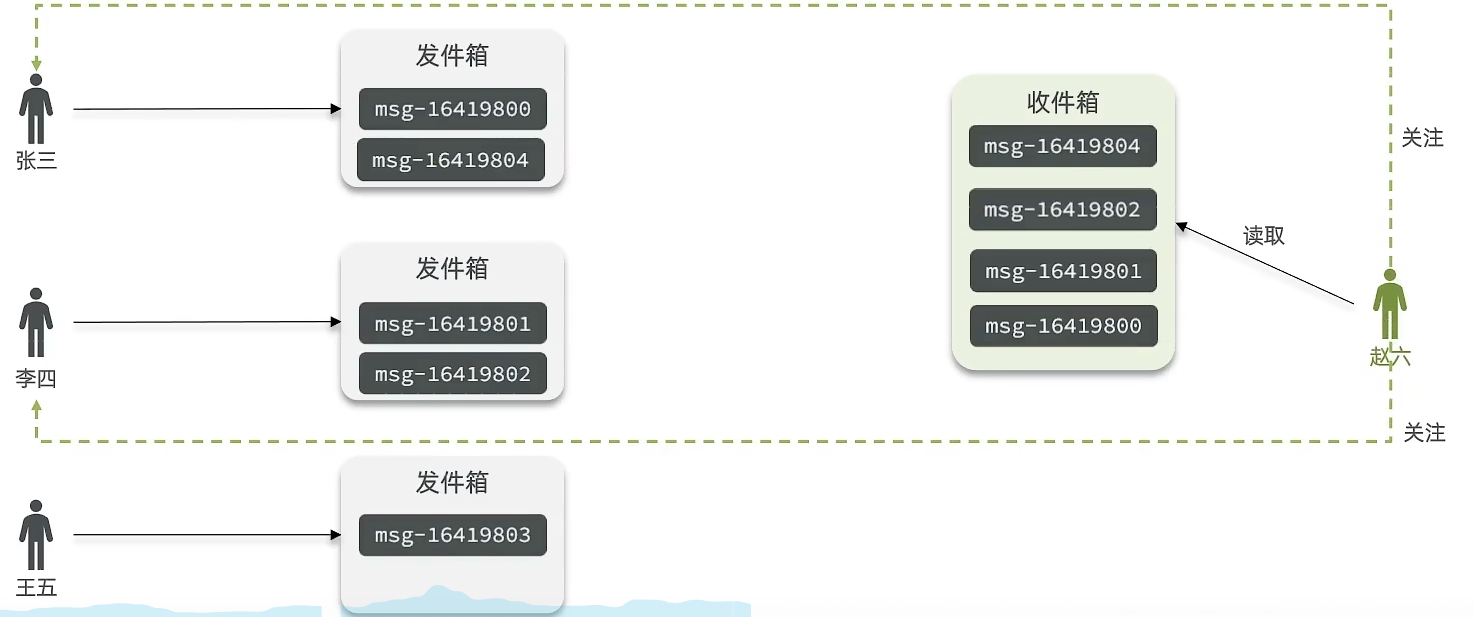
* 推模式:也叫做写扩散。
推模式是没有写邮箱的,当张三写了一个内容,此时会主动的把张三写的内容发送到他的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了
优点:时效快,不用临时拉取
缺点:内存压力大,假设一个大V写信息,很多人关注他, 就会写很多分数据到粉丝那边去* 推拉结合:也叫做读写混合,兼具推和拉两种模式的优点。
推拉模式是一个折中的方案,站在发件人这一段,如果是个普通的人,那么我们采用写扩散的方式,直接把数据写入到他的粉丝中去,因为普通的人他的粉丝关注量比较小,所以这样做没有压力。
如果是大V,那么他是直接将数据先写入到一份到发件箱里边去,然后再直接写一份到活跃粉丝收件箱里边去(不是只写入自己的),现在站在收件人这端来看,如果是活跃粉丝,那么大V和普通的人发的都会直接写入到自己收件箱里边来,而如果是普通的粉丝,由于他们上线不是很频繁,所以等他们上线时,再从发件箱里边去拉信息。所以业务的需求应该是(人不多采取推模式):
* 修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱。
* 收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现,可以采用zset做。
核心的意思:就是我们在保存完探店笔记后,获得到当前笔记的粉丝,然后把数据推送到粉丝的redis中去。
java
@Override
public Result saveBlog(Blog blog) {
// 1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2.保存探店笔记
boolean isSuccess = save(blog);
if(!isSuccess){
return Result.fail("新增笔记失败!");
}
// 3.查询笔记作者的所有粉丝 select * from tb_follow where follow_user_id = ?
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 4.推送笔记id给所有粉丝
for (Follow follow : follows) {
// 4.1.获取粉丝id
Long userId = follow.getUserId();
// 4.2.推送
String key = FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5.返回id
return Result.ok(blog.getId());
}* 查询收件箱数据时,可以实现分页查询要注意的是:传统了分页在feed流是不适用的,因为我们的数据会随时发生变化,t2的时间搓更大,所以11在最上边,如果按传统的查。如图会发现6重复查询了。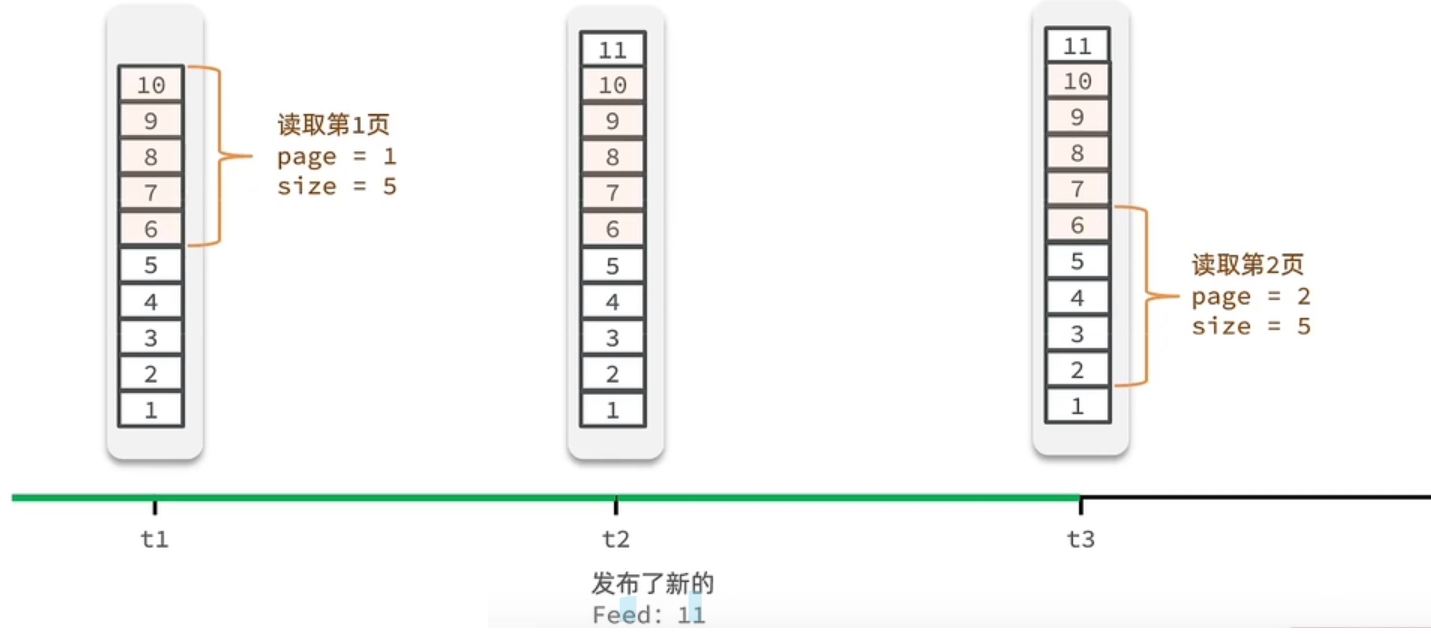
模拟:
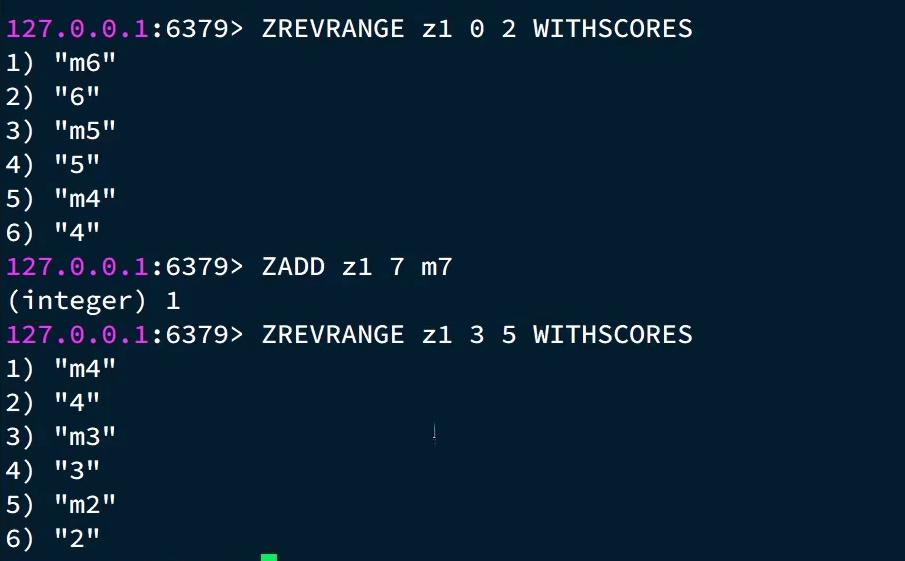
比如在redis里如果按角标查询(zrange key a b是升序查,这里我们要倒叙查所以加一个rev):第一次是排名第一二三的,然后进来一个m7在最上边,因为第一页查的是0-2,下一次就是3-5了,因为数据的变动所以又查出来一个m4.
所以应该采取feed流滚动分页查询:
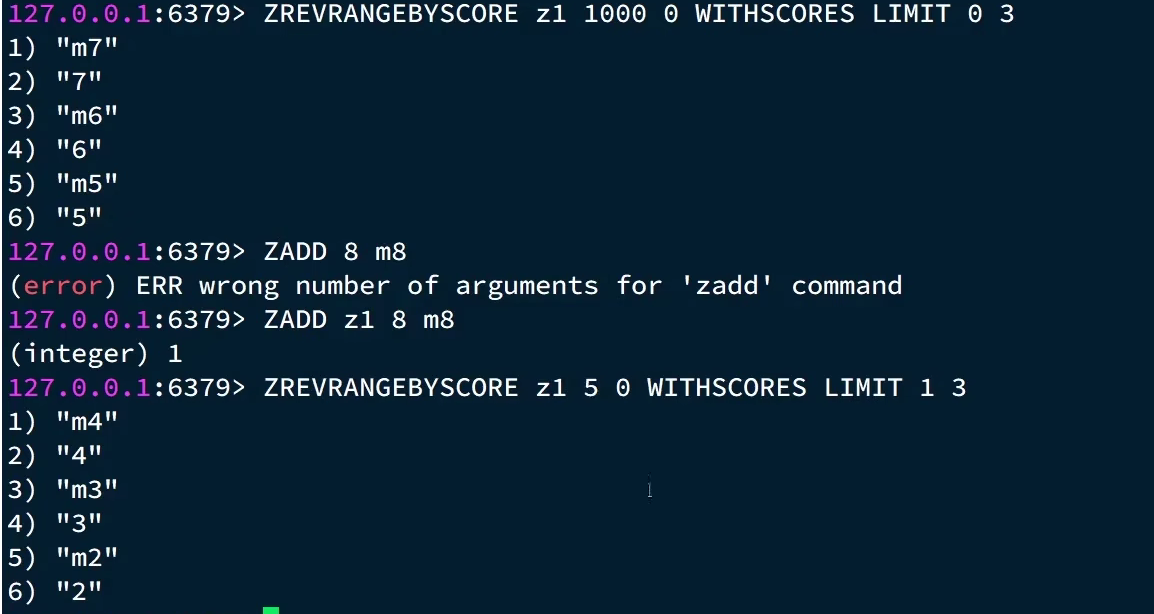
不使用排名进行查询,使用分数进行查询:先讲一下这个命令zrevrangebyscore key 最大值 最小值 (withscore)limit 偏移量 查多少:加上byscore说明用分数查,同样加上rev是降序了,然后最大值和最小值是限定从这个范围查,withscore表示结果你带不带分数,limit 偏移量 查多少:偏移量表示从最大值偏移几个,0就是不偏移,查多少很好理解不说了。这就是模拟:刚开始最大值随便给的大一点,最小值是0就行。第一次查完后,记录这一次的最小值m5作为下一次的最大值,然后偏移量肯定得是1了,因为不能包括这个m5。这样就完成了滚动分页
总结一下:实现滚动分页需要四个参数,首先最大值,最小值,偏移量,查多少,当然在这个业务里查多少是固定的,写死就行了,那个最小值因为存的是时间错我们写死是0即可,最大值需要给,要的是上一次的最小分数(除了第一次,第一次可以令最大值是当前时间戳),然后偏移量第一次是0,其他是1,但是这里还有一种特殊情况:某一页最后分数有一样的,
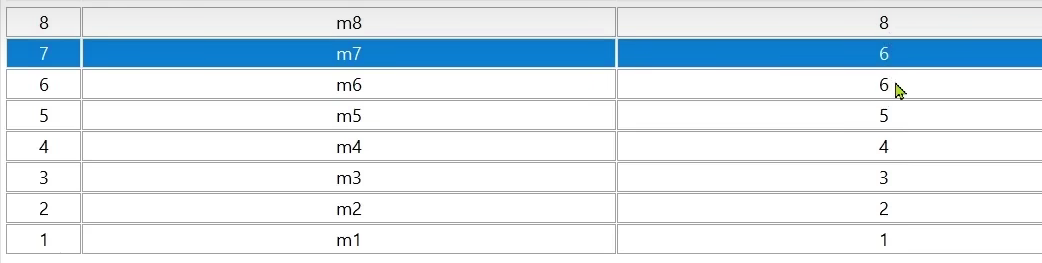 比如这个第一页是m8,m7,m6,然后你就去写zrevrangebyscore z1 6 0 limit 1 3是不对的
比如这个第一页是m8,m7,m6,然后你就去写zrevrangebyscore z1 6 0 limit 1 3是不对的
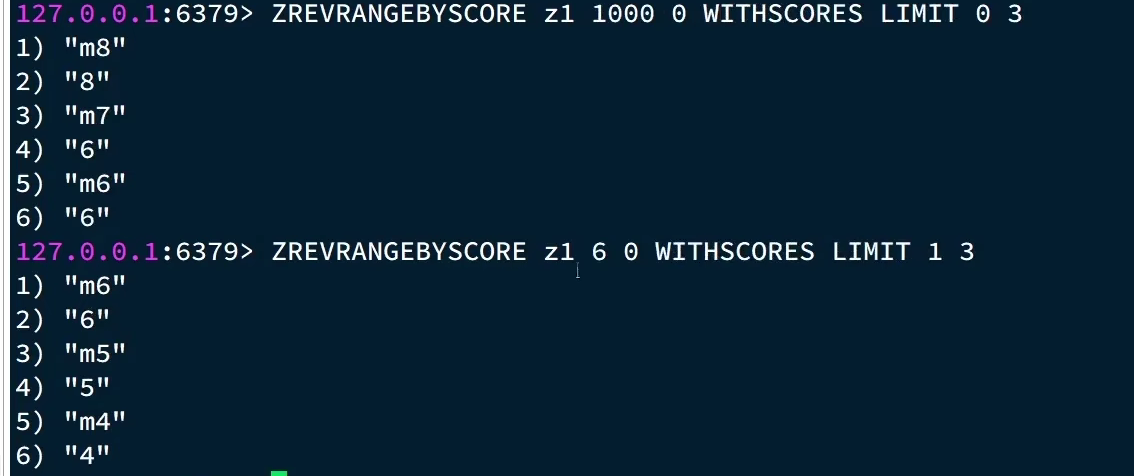
这是因为m7和m6分数一样,第二次你只跳过了一个,所以还查到了6,所以我们应该偏移量应该是上一次最小值大小一样的元素个数,至此现在就可以实现了。

所以每次查询返回值就需要包括最小时间搓和偏移量,然后每次请求携带这俩个。第一次呢只需要给当前时间戳,然后默认我们让偏移量是0就行。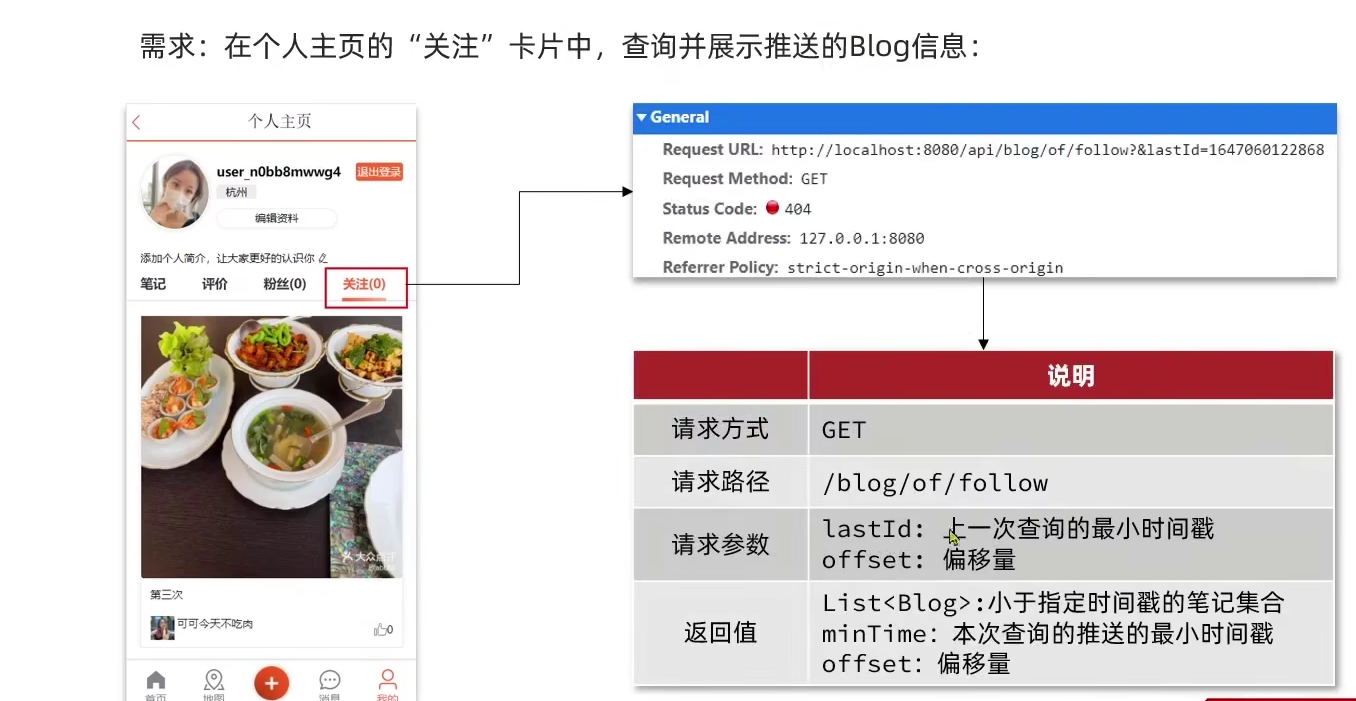
实现:
1.创建一个实体dto类,用于传递,这里泛型我们用?,因为可能这个滚动分页还要用于其他业务,不能简简单单写成Blog
java
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}2.定义controller
java
@GetMapping("/of/follow")
public Result queryBlogOfFollow(
@RequestParam("lastId") Long max, @RequestParam(value = "offset", defaultValue = "0") Integer offset){
return blogService.queryBlogOfFollow(max, offset);
}注意因为第一次前端没有给偏移量,我们默认给0,用defaultValue参数表面默认值即可。
3.写业务层
java
public Result queryBlogOfFollow(Long max, Integer offset) {
//1.获取当前用户
Long userId = UserHolder.getUser().getId();
//2.查询收件箱 zrevrangebyscore key max 0 limit offset 2
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 2);
//3.如果收件箱啥也没有,或者是空集合直接返回
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
//4.有的话就去得到ids,偏移量和最小分数
//4.1准备一个数组存放博客的id
ArrayList<Long> ids = new ArrayList<>(typedTuples.size());
//4.2准备变量存放偏移量和最小得分
long minTime = 0;
int os = 1;
//5循环set集合
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
//5.1得到id并且放入数组
ids.add(Long.valueOf(typedTuple.getValue()));
//5.2为了得到最小分数,和偏移量,遍历时间搓
long time = typedTuple.getScore().longValue();
if (time == minTime){
os++;
} else {
minTime = time;
os = 1;
}
}
//6.根据ids查询blog
List<Blog> blogs = blogMapper.selectByIds1(ids);
//7.封装成分页查询对象
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}细节一:
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 2);我们带了分数,所以返回的应该也带有分数,函数返回的是ZSetOperations.TypedTuple<String>,很复杂,其实就是一个元组,里面就是有值和那个分数,你看源码:得到直接调用这两个方法即可。
细节二:
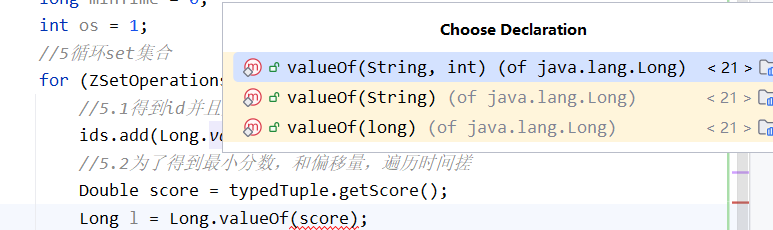
取出来的时间是double类型,我要变成long类型的,不能和上别一样用Long.Valueof,因为这个要求传入string类型的参数,所以用这个方法.longValue()转化成long类型
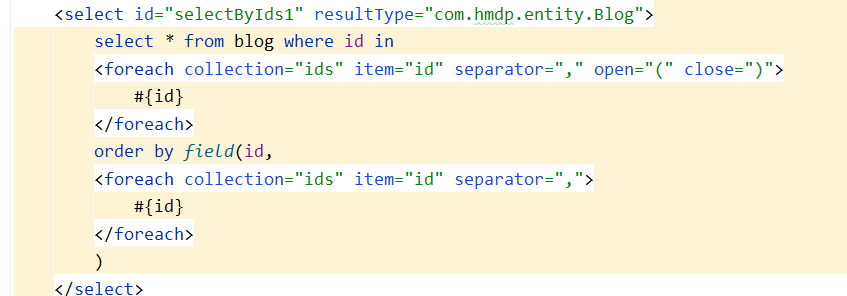
细节三:还是和前面一样,你where id in 是无法保证顺序的,想保证顺序必须使用order by field
细节四:比较巧妙的就是那个遍历集合获取id和偏移量以及最小分数,可以多看一下,其实就是先假设一个,然后去遍历时间搓,如果遍历出来更小的那么就更换,并且让那个计数器重置为一。
4.附近商户,这里不用redis来实现,我们采取es的方法。接下来会学习docker,es,然后回过头来把这个写完了