文章目录
- 前言
- 背景
- 关于模型型号
-
- [AWQ 等量化技术](#AWQ 等量化技术)
- 总结
- 关于部署模型
- [关于function calling](#关于function calling)
- Qwen-Agent源码
-
- 测试demo
- [真实验证调用function calling(curl)](#真实验证调用function calling(curl))
- 推荐类型模型
- 平替部署方案
-
- LocalAI
- [Xorbits Inference量化部署](#Xorbits Inference量化部署)
- 资料获取

前言
博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
CSDN搜索:长路
视频平台:b站-Coder长路
背景
公司内部部署了Qwen3-14B-AWQ模型,应该是xinference自定义去部署启动服务的,发现使用langchain4j中实现的一套基于xinference的chatModel并不能够使用其中的tools功能。
主要的原因就是因为走xinference那套无法兼容qwen3他们自己的协议,所以这块需要特定去研究下qwen3的http接口调用传参,来将参数传对才可以初步实现。
**对于使用哪一类参数才支持适配qwen3呢?**可见该文档:https://dtstack.yuque.com/rd-center/sm6war/slzrlg3ixw1fnvbi
关于模型型号
AWQ 等量化技术
AWQ(Activation-aware Weight Quantization)是一种模型量化技术。它的主要目的是在不显著损失性能的前提下,减小模型体积、降低计算开销,从而让大模型能在消费级显卡等资源受限的设备上运行。它通过将模型权重从高精度(如FP16)转换为低精度(如INT4)来实现这一点。
为什么"原生"的 AWQ 量化模型在 Function Call 上可能表现不佳?
关键在于 "原生" 这个词。问题不出在 AWQ 技术本身,而出在量化过程可能会损害模型完成特定任务所需的精确能力。
-
精度损失带来的脆弱性 :Function Call 是一个对输出格式的精确性要求极高的任务。模型必须一字不差地生成正确的函数名和结构正确的JSON参数。任何偏差(比如少个引号、多个逗号)都会导致整个调用失败。
-
- 基础的语言生成任务(如续写故事)对轻微的词汇替换或语法错误有较高的容错率。
- Function Call 的容错率几乎为零。
-
量化对敏感神经元的影响 :量化过程可以看作是对模型的一种"有损压缩"。虽然大部分语义理解能力得以保留,但那些负责生成精确格式 (如括号、引号)和特定关键词(如函数名)的"敏感"神经元或注意力机制可能会在量化中受到较大影响。这可能导致模型在需要"精雕细琢"的地方出错。
结论:一个未经针对性处理、直接使用 AWQ 等量化技术压缩的模型,其在 Function Call 任务上的可靠性确实可能会下降,表现为更频繁的格式错误或识别意图失败。
解决方案是什么?
业界已经意识到了这个问题,并发展出了相应的解决方案:
- 量化后再微调(Post-Training Quantization + Fine-tuning):
-
- 这是最有效的方法。先对模型进行量化(如使用AWQ),然后使用一个高质量的、包含大量Function Call示例的数据集对这个量化后的模型进行轻量级的微调。
- 这个过程相当于告诉被"压缩"过的模型:"嘿,虽然你变小了,但生成JSON格式、调用函数这个核心技能不能丢,我们再来专门练一下这个。"
- 例如,
**qwen2.5-7b-instruct-awq**这样的模型,很可能就是在完成 AWQ 量化后,又经过了指令数据的微调,以确保其对话和工具调用能力得以保持。
- 更先进的量化策略:
-
- 像 AWQ 这类方法本身就在进化,它们会尝试识别并保护模型中对于任务性能至关重要的"关键权重",在量化时给予它们更高的精度,从而在整体压缩的同时,更好地保留关键能力。
总结
对于大多数Instruct是相当于支持原生就可以返回function calling
| 特性 | Instruct(指令微调) | Function Call(函数调用) | AWQ(量化) |
|---|---|---|---|
| 角色 | 基础训练方法 | 一种特定的高级应用 | 模型压缩技术 |
| 目的 | 让模型学会遵循指令、理解意图、按格式输出。 | 让模型识别工具使用意图并生成严格结构化的调用请求。 | 减小模型体积,提升推理速度。 |
| 关系 | Function Call 强烈依赖于模型的 Instruct 能力。 | 是 Instruct 能力在工具调用场景下的极致体现。 | 是一个独立的、可应用于任何模型的技术,但可能损害Function Call所需的精确性。 |
| 实践 | 生产可用的 Function Call 模型必须先经过高质量的 Instruct 微调。 | 要获得可靠的量化 Function Call 模型,需要在量化后进行针对性的再微调。 |
直接拿一个"原生"的、未经适配的AWQ量化模型来做严肃的Function Call应用,风险很高。在生产环境中,应该选择明确标注支持工具调用、并针对量化版本进行过能力保持训练的模型(如 *-instruct-awq)。
很多开源模型现在都发布了专门针对function calling优化的版本:
- Qwen2.5系列:Qwen2.5发布时特别强调了tool calling能力
- DeepSeek系列:DeepSeek-V2有专门的tool calling版本
- Llama系列:Llama 3.1的8B/70B版本有专门的Instruct-ToolCall变体
"Instruct"和"Thinking"作为两个独立的版本推出,这能让你更直观地理解它们的不同定位。
- Qwen3-Max-Instruct :可以理解为"执行模式 "。它追求低延迟和快速响应,像一个聪明的助手,非常适合日常对话、快速的代码生成和常规问题解答。
- Qwen3-Max-Thinking :可以理解为"思考模式"。它面向更复杂的多步骤推理任务,会花费更多时间进行"深度思考",通过调用代码解释器、搜索引擎等工具来解决复杂问题,像一个团队智囊。
框架的辅助实现:Qwen-Agent这类框架,确实会通过精心设计提示词(Prompt)来引导和增强模型的工具调用行为。但需要注意的是,对于已经具备原生Function Calling能力的模型,框架更多是提供了一套便捷的集成和使用机制。
Function Call介绍:https://www.hiascend.com/document/detail/zh/mindie/21RC1/mindiellm/llmdev/mindie_llm0303.html
关于部署模型
能够提供兼容OpenAI API的推理服务器,并且支持function calling。根据搜索结果,有几种部署方式:
- 使用SGLang部署:SGLang支持复杂的LLM Programs,包括多轮对话、规划、工具调用和结构化输出等。它可以通过Docker部署,并提供了与OpenAI兼容的API。
- 使用vLLM部署:vLLM是大模型加速推理框架,优化内存利用率和吞吐量,适合高并发场景。它也可能支持function calling(但搜索结果中没有明确说明)。
- 使用Ollama部署:Ollama是一个本地运行大模型的集成框架,内置了一系列优化策略,并且与主流大模型应用开发框架高度集成。
- 使用Transformers原生库:你可以直接使用Transformers库加载模型并进行推理,但这需要你自己处理API接口。
在这些方案中,SGLang和Ollama可能更易于使用,因为它们提供了完整的API服务。
关于function calling
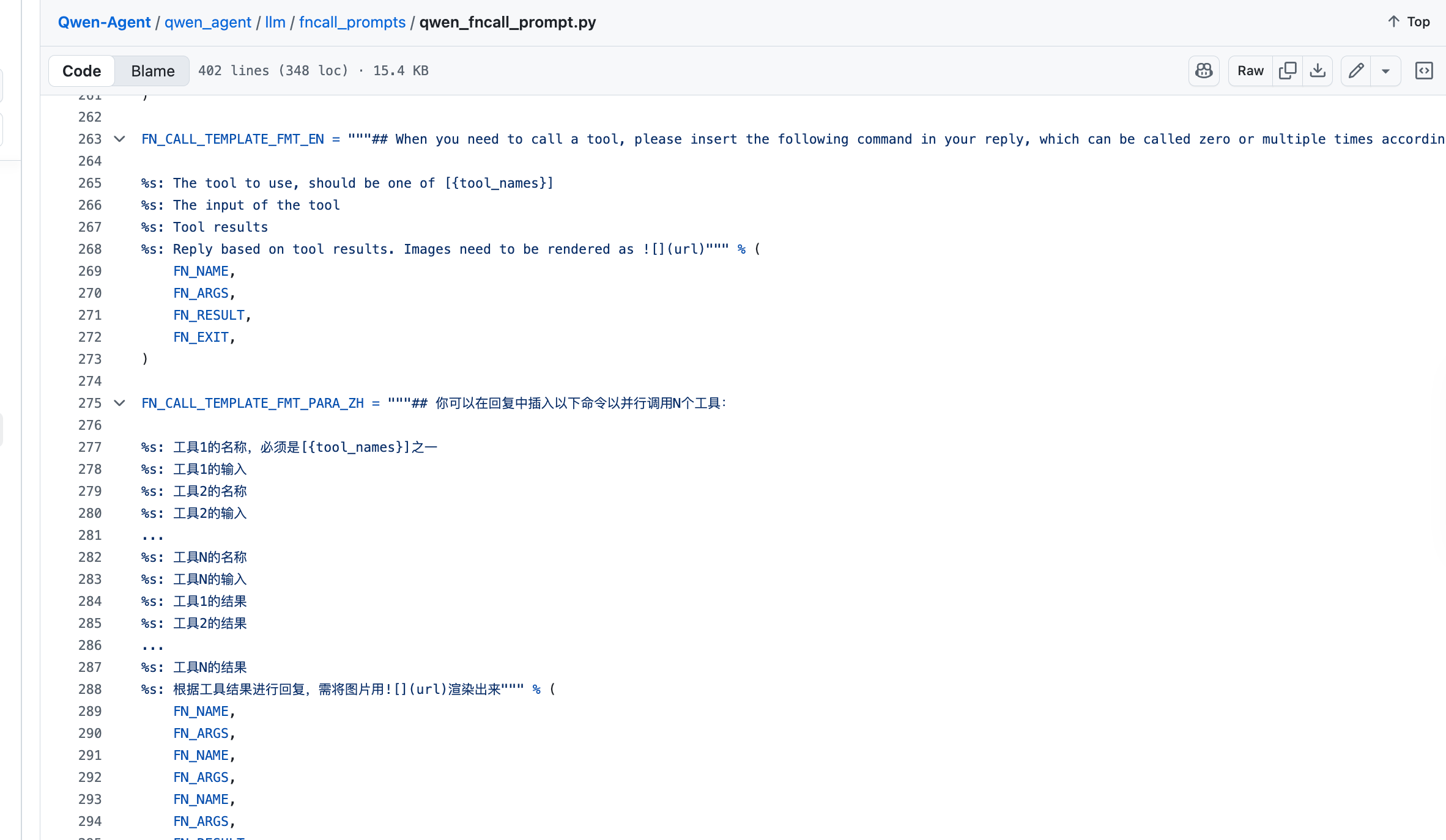
可以参考看对应qwen-agent源码:https://github.com/QwenLM/Qwen-Agent/blob/main/qwen_agent/llm/fncall_prompts/qwen_fncall_prompt.py
大多数大模型(包括很多官方提供的 API)的 function calling 本质上都是通过精心设计的提示词(Prompt)来引导模型输出结构化的函数调用信息,再通过代码解析这些结构化信息来执行实际的函数调用。
这是目前大模型实现工具调用的主流方式,核心逻辑可以理解为 "提示词引导输出格式 + 代码解析执行"。
具体来说,主要有两种实现模式:
1、纯提示词引导(开源模型常用)
就像前面示例中展示的,通过在提示词中明确告知模型:
- 可用的工具列表(名称、参数、功能描述)
- 函数调用的格式要求(例如用<function_call>{...}</function_call>包裹 JSON)
- 何时需要调用工具(例如 "当需要获取实时信息时必须调用工具")
模型会根据这些指令,在需要调用工具时输出符合格式的内容。这种方式完全依赖模型的文本生成能力,所有逻辑都通过提示词控制,没有特殊的模型内部机制。
大部分开源大模型(如 Qwen、Llama、Mistral 等)都采用这种方式,因为它们的核心是文本生成模型,本身并不内置 "函数调用" 的专用逻辑。
例如:https://github.com/QwenLM/Qwen-Agent/blob/main/qwen_agent/llm/fncall_prompts/qwen_fncall_prompt.py
2. 官方 API 封装(闭源模型常用)
像 OpenAI 的 GPT、Anthropic 的 Claude 等闭源模型,虽然底层原理也是基于提示词引导,但官方 API 做了一层封装:
- 你只需要在 API 参数中传入tools列表(工具定义)
- 模型返回的结果会直接包含function_call字段(结构化数据,而非原始文本)
- 不需要你手动解析文本中的函数调用格式
这种方式看起来更 "原生",但本质上是官方在 API 层帮你做了两件事:
- 自动生成更优化的提示词引导模型输出结构化内容
- 自动解析模型的文本输出,转换成结构化的function_call字段
Qwen-Agent源码
官方对接agent仓库:https://github.com/QwenLM/Qwen-Agent/tree/main
测试demo
官方给出的tools测试调用源码为:
python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-14B-AWQ',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://127.16.99.68:9997/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ 介绍qwen最新的进展'}]
for responses in bot.run(messages=messages):
pass
print(responses)真实验证调用function calling(curl)
shell
curl http://172.16.99.68:9997/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer EMPTY" \
-d '{
"model": "Qwen3-14B-AWQ",
"messages": [
{
"role": "system",
"content": "你拥有调用工具的能力。当需要调用工具时,必须使用以下格式:用包裹JSON对象,例如:。"
},
{"role": "user", "content": "我想知道北京的天气"}
],
"functions": [
{
"name": "get_current_weather",
"description": "获取指定城市的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称(如北京、上海)"
}
},
"required": ["location"]
}
}
],
"stream": false
}'
是否带思考,就是问题后面加不加:/no_think,如下:
java
curl http://172.16.99.68:9997/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer EMPTY" \
-d '{
"model": "Qwen3-14B-AWQ",
"messages": [
{
"role": "system",
"content": "你拥有调用工具的能力。当需要调用工具时,必须使用以下格式:用包裹JSON对象,例如:。"
},
{"role": "user", "content": "我想知道北京的天气 /no_think"}
],
"functions": [
{
"name": "get_current_weather",
"description": "获取指定城市的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称(如北京、上海)"
}
},
"required": ["location"]
}
}
],
"stream": false,
"generate_cfg": {"thought_in_content": false}
}'
推荐类型模型
这类模型通常是在指令微调(Instruct)版本的基础上,再通过AWQ量化技术进行优化,以在性能和效率之间取得平衡。
下面这个表格整理了搜索结果中提及的一些Qwen系列的AWQ量化模型,你可以快速了解:
| 模型名称 | 核心特点 |
|---|---|
| Qwen2.5-VL-32B-Instruct-AWQ | - 32B参数的多模态模型 - 支持图像、视频理解 - 在专业领域的视觉分析和数学推理上表现突出 |
| Qwen2.5-Coder-0.5B-Instruct-AWQ | - 0.5B参数的代码专用模型 - 专注于代码生成、推理和修复 - 通过AWQ量化,体积小,推理速度快 |
| Qwen3-4B-Instruct-2507-AWQ | - 4B参数的通用模型 - 在指令遵循、逻辑推理等方面有显著提升 - 支持长上下文和工具调用 |
平替部署方案
LocalAI
官方文档:https://localai.io/docs/overview/
使用LocalAI来替换您现有的vLLM和Xinference方案,并直接通过OpenAI协议进行function calling,在技术上是完全可行的。这实际上正是LocalAI的一个核心设计目标。
为了让您快速了解这两种方案的对比,我准备了一个简单的表格:
| 特性维度 | vLLM + Xinference 方案 | LocalAI 方案 |
|---|---|---|
| 核心优势 | 高吞吐推理、平台化管理 | OpenAI API全兼容、部署简单、数据隐私性好 |
| Function Calling | 依赖Xinference等框架的封装 | 原生支持OpenAI格式的function calling |
| 使用体验 | 可能需要适配不同框架的API | 标准化的OpenAI客户端代码,无缝迁移 |
Xorbits Inference量化部署
参考文章:https://blog.csdn.net/gitblog_01417/article/details/150381057
github地址:https://github.com/xorbitsai/inference
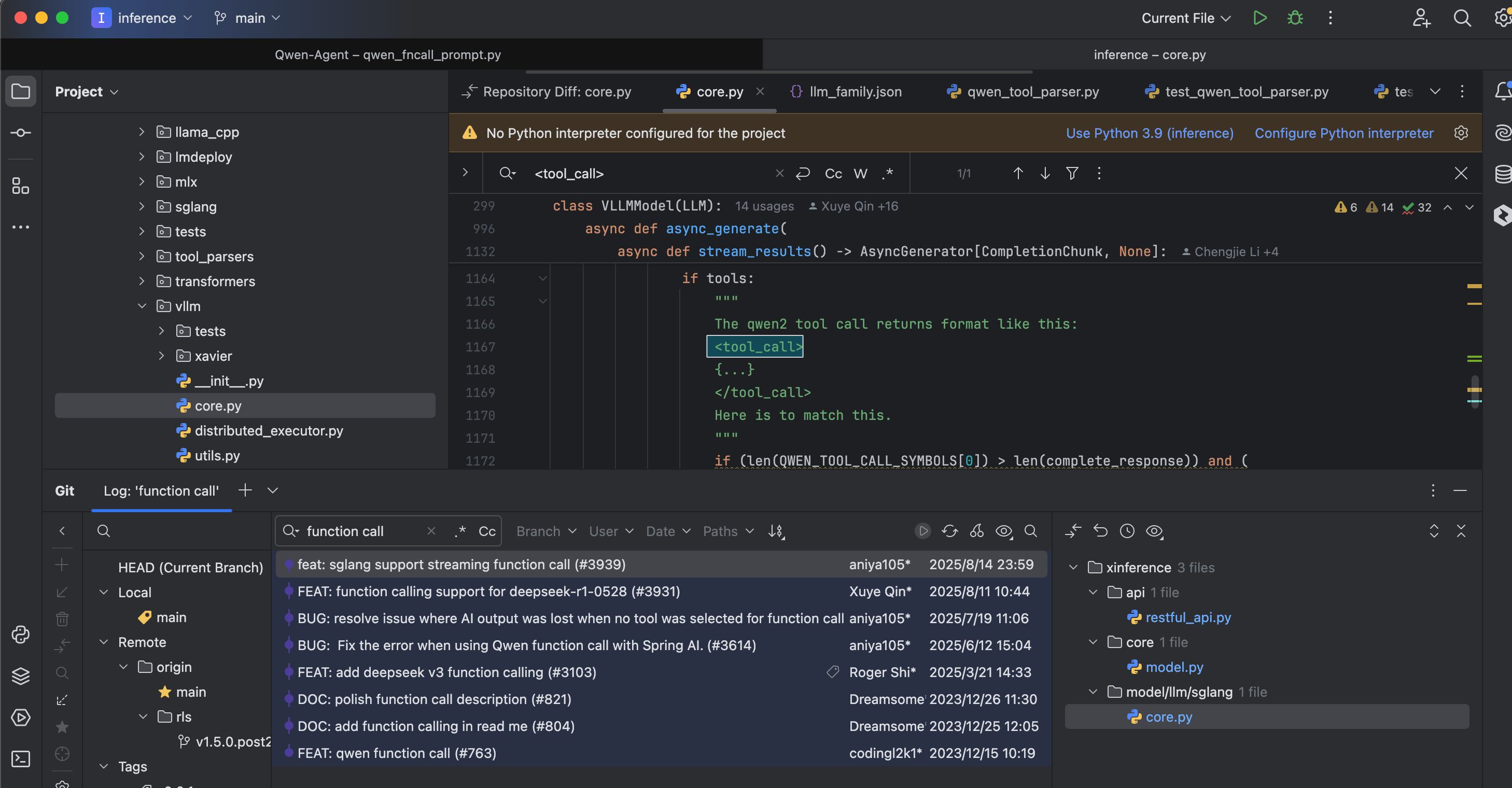
使用Xorbits Inference部署,基本就是对接open ai协议,对应对接工具tools协议:https://inference.readthedocs.io/zh-cn/latest/models/model_abilities/tools.html#tools
关于部署qwen-14b-awq:
- 从GPT到Qwen3:Xorbits Inference实现AWQ量化部署的性能革命(部署命令):https://blog.csdn.net/gitblog_01417/article/details/150381057
- 封了个启动脚本(视频):https://www.bilibili.com/video/BV14t421W7jv/?vd_source=4b290247452adda4e56d84b659b0c8a2
支持function call调用:
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue---校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅