嗨,我是************Lethehong************!座右铭:他强任他强,清风拂山岗。感谢您的关注与支持!
想要了解如何使用claude调用蓝耘API,可以参考下面这篇文章: 从安装到实测:基于 Claude Code + GLM-4.7 的前端生成与评测实战
目录
[1.1 GLM-5模型概述](#1.1 GLM-5模型概述)
[1.2 蓝耘元生代MaaS平台概述](#1.2 蓝耘元生代MaaS平台概述)
[1.3 测试环境与方法](#1.3 测试环境与方法)
[2.1 模型架构与参数规模](#2.1 模型架构与参数规模)
[2.2 核心技术升级](#2.2 核心技术升级)
[2.3 推理、编程与对话能力](#2.3 推理、编程与对话能力)
[3.1 平台注册与API Key获取](#3.1 平台注册与API Key获取)
[3.2 免费Token额度与成本优势](#3.2 免费Token额度与成本优势)
[4.1 编程任务提示词](#4.1 编程任务提示词)
[4.2 Agent任务提示词](#4.2 Agent任务提示词)
[4.3 文本处理提示词](#4.3 文本处理提示词)
[4.4 对话任务提示词](#4.4 对话任务提示词)
[5.1 通用能力基准测试](#5.1 通用能力基准测试)
[5.2 Agent能力基准测试](#5.2 Agent能力基准测试)
[5.3 编程能力基准测试](#5.3 编程能力基准测试)
[5.4 性能对比分析](#5.4 性能对比分析)
[6.1 云端API调用部署](#6.1 云端API调用部署)
[6.2 本地部署方案](#6.2 本地部署方案)
[6.3 集成与最佳实践](#6.3 集成与最佳实践)
[7.1 总体评价](#7.1 总体评价)
[7.2 未来展望](#7.2 未来展望)
一、引言:GLM-5与蓝耘MaaS平台概述
1.1 GLM-5模型概述
GLM-5是智谱AI于2026年2月11日发布的新一代旗舰级大语言模型。它标志着国产大模型在编程和智能体(Agent)能力上的重大突破,官方定位为"最新一代旗舰级对话、编程与智能体模型,重点强化复杂系统工程与长程Agent任务"。GLM-5在多项权威基准测试中表现卓越,尤其在编程和Agent任务上取得开源模型最优成绩,其真实编程体验已逼近国际顶尖闭源模型Claude Opus 4.5水平。作为开源模型,GLM-5打破了开源与闭源能力壁垒,为开发者提供了自主可控的高性能选择。
1.2 蓝耘元生代MaaS平台概述
蓝耘元生代MaaS(Model as a Service)平台是一个基于云计算的人工智能服务平台,旨在为企业开发者、创业者及非技术背景用户提供开箱即用的AI模型服务。该平台通过API接口或可视化界面,让用户无需从零开始训练模型,即可访问和使用预先训练好的机器学习模型。MaaS模式极大降低了AI应用开发的门槛,加速了业务创新。平台提供了丰富的预训练模型库,覆盖自然语言处理、计算机视觉、语音识别等多个领域,支持零代码体验和API快速集成。用户只需关注业务逻辑,而无需投入大量资源于底层基础设施和模型训练,即可快速构建和迭代AI应用。
1.3 测试环境与方法
本次测评在蓝耘元生代MaaS平台的环境中进行,旨在全面评估GLM-5模型的各项能力,并为开发者提供详尽的实践指南。测试方法包括:通过Python脚本调用平台API进行对话生成任务,使用官方提供的示例代码进行基准测试,以及参考官方和第三方公布的评测数据。我们重点关注GLM-5在编程、智能体任务和对话等核心场景的表现,并结合平台的实际使用体验,分析其性能优势与适用场景。
二、GLM-5技术规格与核心能力
2.1 模型架构与参数规模
GLM-5在模型架构上实现了全面升级。其参数规模从上一代的355B(激活参数32B)大幅扩展至744B(激活参数40B),预训练数据量从23T提升至28.5T。更大的模型容量和训练数据为复杂推理和长文本处理奠定了基础。GLM-5首次引入了DeepSeek稀疏注意力机制(DSA),在保持长文本处理效果无损的前提下,有效降低部署成本并提升Token利用效率。该模型构建了78层隐藏层,集成256个专家模块,每次激活8个专家,实现稀疏度仅5.9%的高效推理。上下文窗口最高支持202K token,可一次性处理完整代码库或大型文档。
2.2 核心技术升级
GLM-5在技术架构上聚焦于"性能与效率平衡",针对性解决了大模型部署成本高、推理慢的痛点。其核心升级包括:
-
稀疏注意力机制+MoE架构: 集成DeepSeek稀疏注意力机制,结合MoE混合专家架构,在处理几十万行代码或长文本时不丢失上下文,同时推理时延降低50%以上,部署成本下降30%。这解决了大模型本地部署算力不足的难题。
-
精度与落地适配: GLM-5以BF16精度发布,总体积约1.5TB。虽然模型体积大于FP8/INT4量化模型,但其推理精度更优,特别适配编程调试、科学计算、金融风控等对精度要求极高的场景。
-
训练框架创新: 智谱构建了全新的"Slime"训练框架,支持异步智能体强化学习,使模型能够从长程交互中持续学习,显著提升了强化学习后训练流程的效率。
2.3 推理、编程与对话能力
GLM-5重点强化了编程与智能体能力,实现了从"写代码片段"到"完成系统工程"的转变。其核心能力包括:
- 编程能力: GLM-5能够像"架构师"一样理解多文件、多模块、多服务的工程逻辑,进行后端重构、深度调试和跨文件改动。在内部Claude Code评估集中,GLM-5在前端、后端和长程任务上平均性能比GLM-4.7提升超过20%。在权威的SWE-bench-Verified和Terminal Bench 2.0基准测试中,GLM-5分别取得77.8和56.2的开源模型最高分,性能超过Gemini 3 Pro。真实编程环境中的使用体验已逼近Claude Opus 4.5水平。
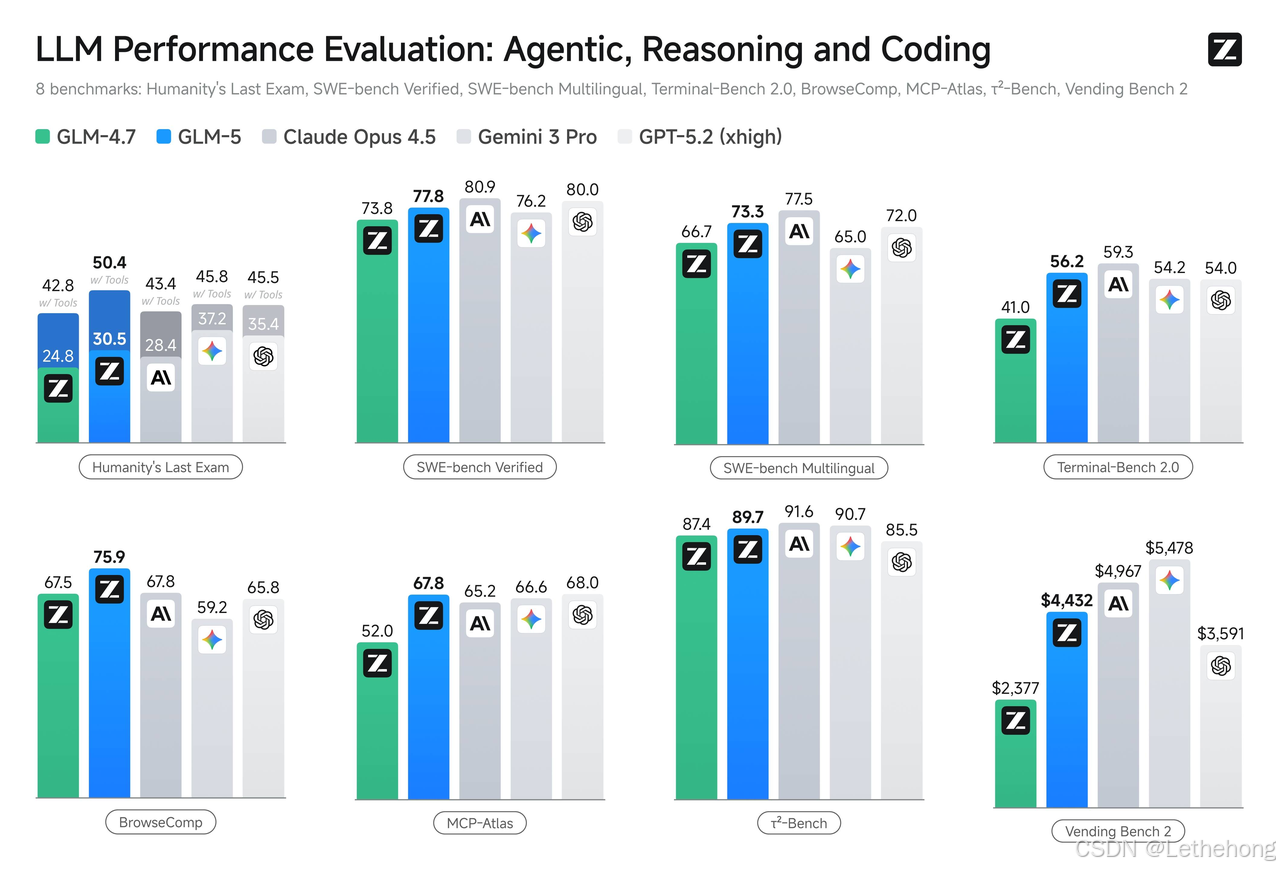
- Agent能力: GLM-5具备卓越的长程任务规划和多工具调用能力。在BrowseComp(联网检索与信息理解)、MCP-Atlas(大规模端到端工具调用)和τ²-Bench(复杂场景下自动代理工具规划与执行)三项权威评测中,GLM-5均取得开源模型最优表现。在Artificial Analysis发布的Intelligence Index v4.0榜单中,GLM-5以49分的综合成绩位列全球第四、开源第一。在GDPval-AA智能体测试中,GLM-5的Elo评分达到1462分,全球第三、开源第一,可自主完成长程复杂工程任务。
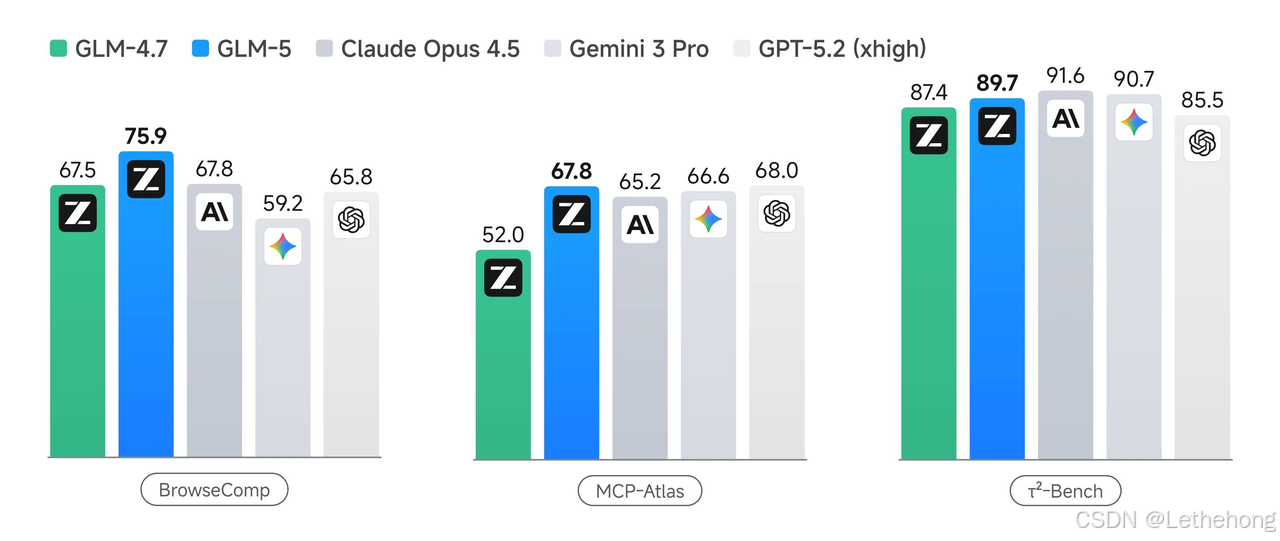
- 对话与知识可靠性: GLM-5的幻觉率显著降低,更"敢认怂"。在AA-Omniscience(知识可靠性/幻觉)评测中,GLM-5得分为-1,比GLM-4.7提升了35分,幻觉率相比GLM-4.7降低了56个百分点。这意味着在需要严肃信息、专业知识的场景下,GLM-5能更可靠地回答问题,避免编造错误信息。
三、在蓝耘MaaS平台上的部署与调用
3.1 平台注册与API Key获取
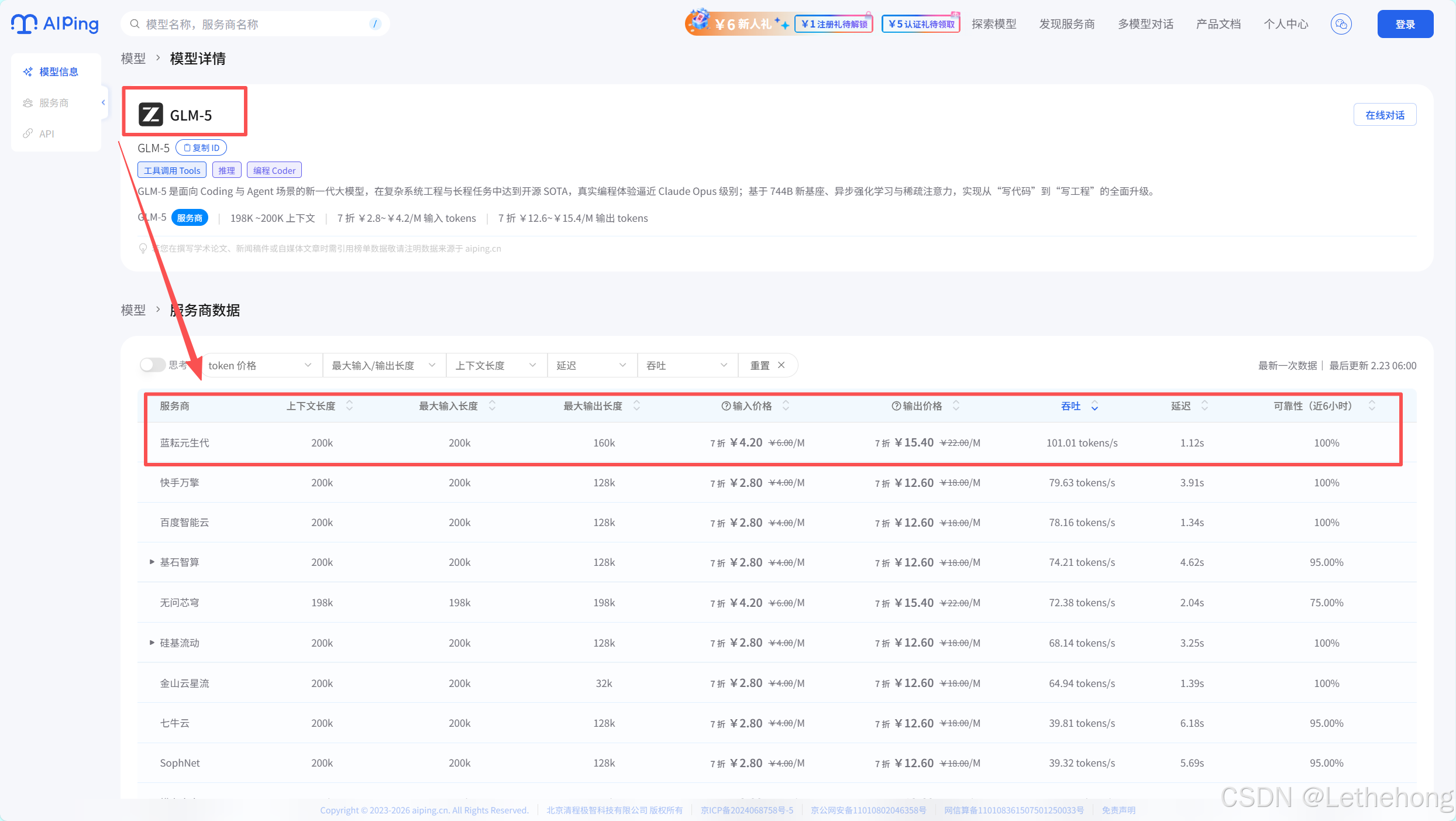
要使用GLM-5,首先需在蓝耘元生代智算云平台完成注册。注册成功后,进入控制台,点击"MaaS平台"选项,即可看到"创建API KEY"的按钮。点击生成专属的API Key,该密钥将作为调用平台接口的凭证。平台支持Python、Java、JavaScript等主流编程语言,开发者可根据自身技术栈灵活选择调用方式。
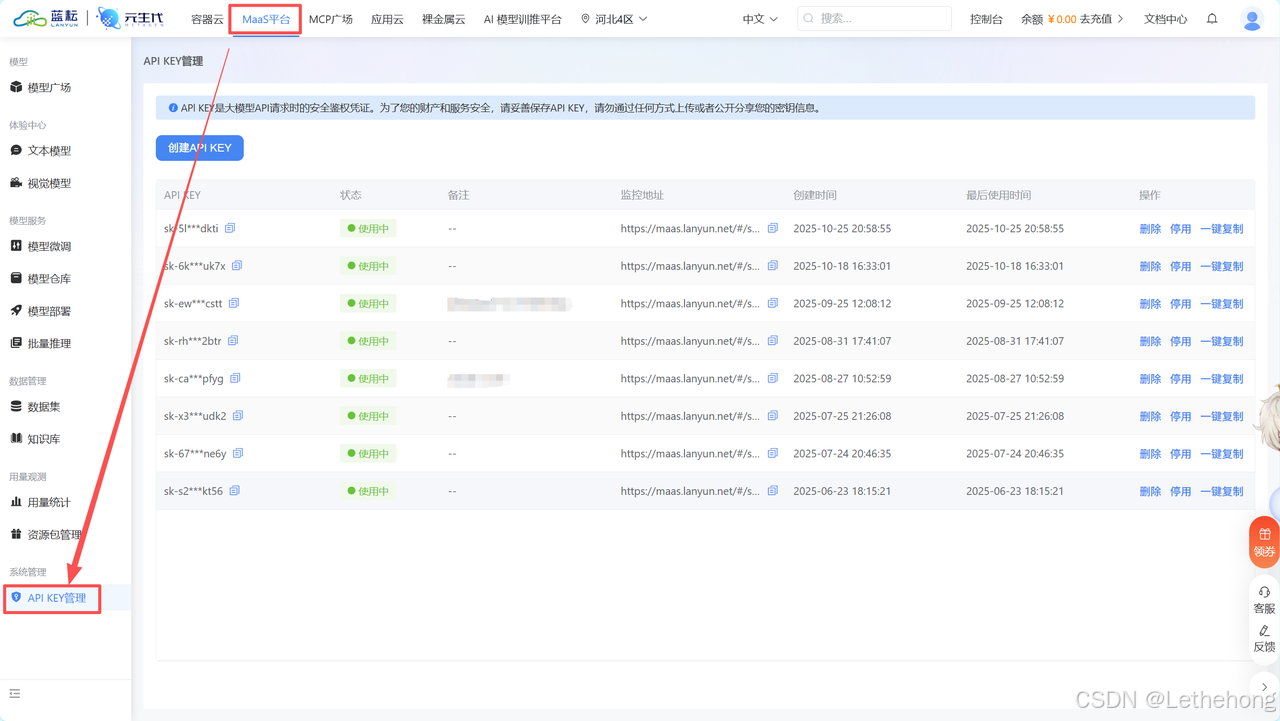
3.2 免费Token额度与成本优势
蓝耘平台为新用户提供了丰厚的免费额度。注册后,用户可获得DeepSeek-V3、DeepSeek-R1等模型的大量免费Token,可免费体验GLM-5的强大能力。即使超出免费额度,平台的计费方式也灵活透明,按实际使用的Token数量计费。与传统购买和维护GPU集群相比,使用蓝耘MaaS平台可显著降低开发成本和运维复杂度。
四、实战演示:可直接使用的提示词示例
本章节提供多个可直接使用的提示词示例,涵盖GLM-5的核心能力,包括编程、Agent任务、文本处理和对话。每个示例都包含完整的调用代码和预期输出说明,方便开发者快速验证和使用。
4.1 编程任务提示词
示例1:生成Python函数
任务描述: 生成一个Python函数,接收一个整数列表,返回列表中出现频率最高的元素。如果有多个元素频率相同且最高,则返回其中数值最大的那个元素。
提示词:
请编写一个Python函数,函数名为 most_frequent_max。该函数接收一个整数列表作为参数,返回列表中出现频率最高的元素。如果有多个元素频率相同且最高,则返回其中数值最大的那个元素。要求代码简洁、高效,并包含注释。生成代码:
python
from collections import Counter
def most_frequent_max(nums):
"""
返回列表中出现频率最高的元素。
若有多个元素频率相同且最高,则返回其中数值最大的那个元素。
参数:
nums: 整数列表
返回:
出现频率最高的元素(频率相同时返回最大值)
"""
if not nums:
raise ValueError("列表不能为空")
# 统计每个元素的频率
counter = Counter(nums)
# 按频率降序、数值降序排序,取第一个元素
# key=(-频率, 元素值) 确保频率高的优先,频率相同时数值大的优先
return max(counter.keys(), key=lambda x: (counter[x], x))
# 测试示例
if __name__ == "__main__":
# 测试用例1: 单一最高频率
print(most_frequent_max([1, 2, 2, 3, 3, 3])) # 输出: 3
# 测试用例2: 多个元素频率相同,返回数值最大的
print(most_frequent_max([1, 1, 2, 2])) # 输出: 2
# 测试用例3: 所有元素频率相同
print(most_frequent_max([5, 3, 1])) # 输出: 5
# 测试用例4: 包含负数
print(most_frequent_max([-1, -1, -2, -2])) # 输出: -1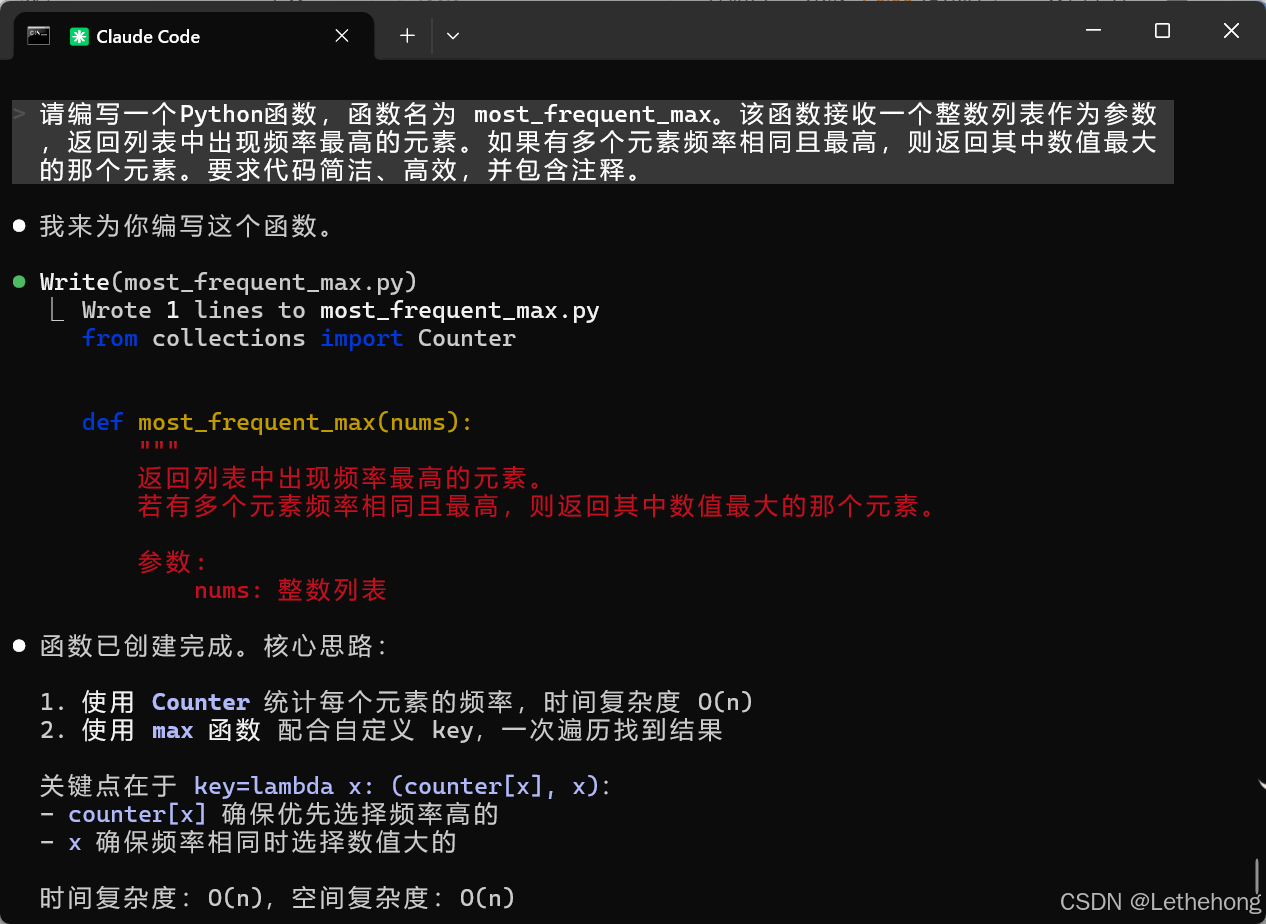
运行结果:
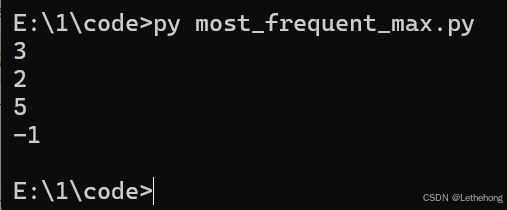
预期输出: GLM-5会生成一个完整的Python函数,包含函数定义、注释和实现逻辑。开发者可以直接复制代码使用,无需修改。
示例2:代码重构与优化
任务描述: 对以下代码进行重构,提高可读性和性能。
原始代码:
python
def process_data(data):
result = []
for i in range(len(data)):
if data[i] > 0:
result.append(data[i] * 2)
else:
result.append(0)
return result提示词:
python
请对以下Python代码进行重构,提高可读性和性能:
def process_data(data):
result = []
for i in range(len(data)):
if data[i] > 0:
result.append(data[i] * 2)
else:
result.append(0)
return result
要求:
1. 使用列表推导式简化代码
2. 提高代码可读性
3. 保持原有功能不变
4. 添加函数文档字符串生成代码:
python
def process_data(data):
"""
处理数据列表,将正数翻倍,非正数置零。
参数:
data: 数值列表
返回:
处理后的列表,正数元素乘以2,非正数元素变为0
"""
return [x * 2 if x > 0 else 0 for x in data]
# 测试验证
if __name__ == "__main__":
original_data = [1, -2, 3, 0, -5, 6]
result = process_data(original_data)
print(f"输入: {original_data}")
print(f"输出: {result}")
# 预期输出: [2, 0, 6, 0, 0, 12]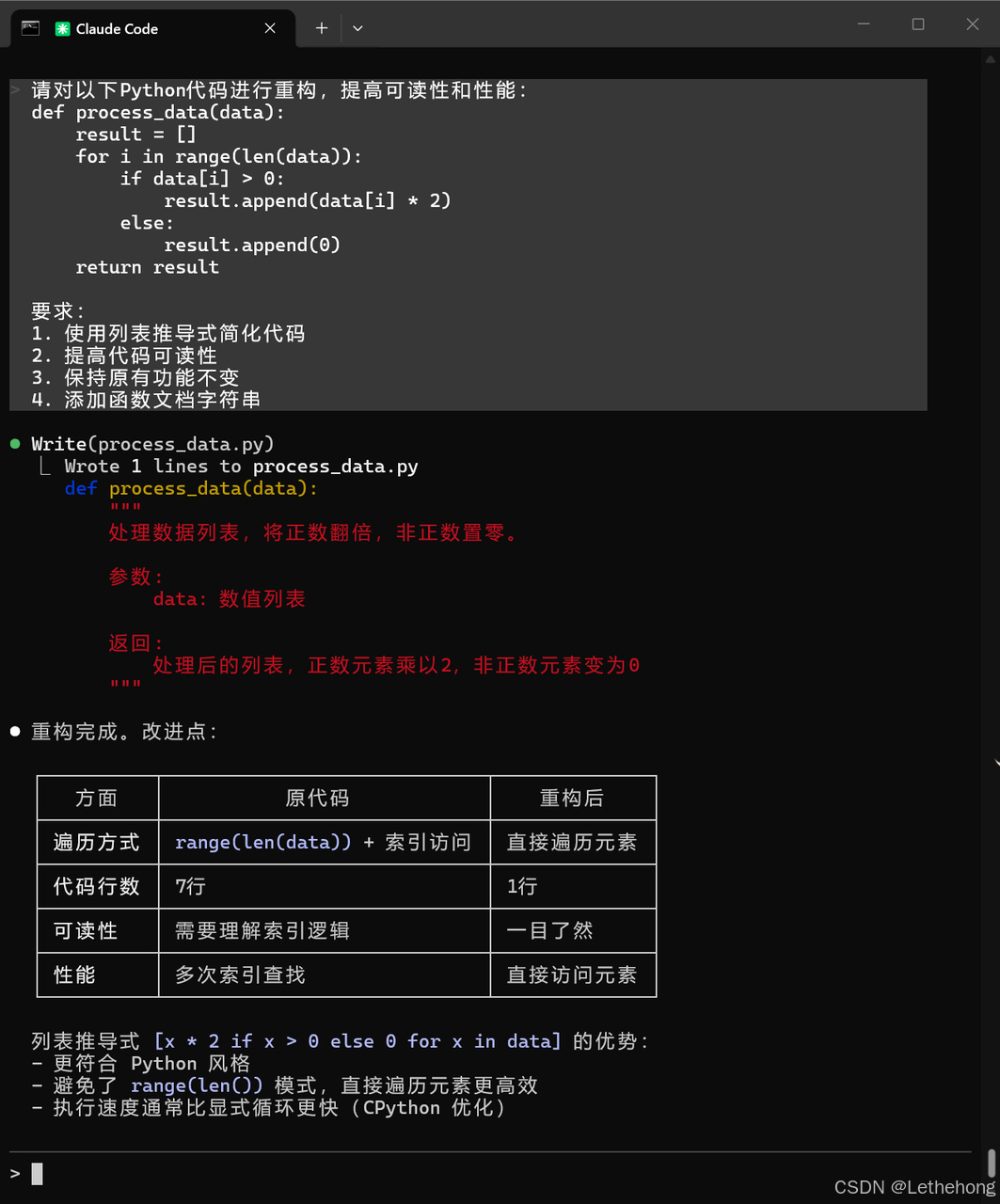
输出结果:
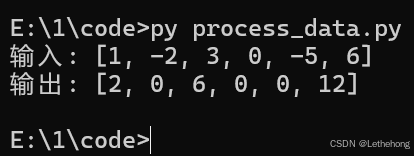
预期输出: GLM-5会生成重构后的代码,使用列表推导式,添加文档字符串,并保持原有功能。
4.2 Agent任务提示词
示例3:多步骤任务规划
任务描述: 规划一个数据分析项目的完整流程。
提示词:
python
请规划一个数据分析项目的完整流程,从数据获取到结果可视化。项目目标是分析某电商平台的用户购买行为。
要求:
1. 列出所有关键步骤
2. 每个步骤说明需要使用的工具或技术
3. 指出可能遇到的问题和解决方案
4. 提供时间估算
5. 以结构化格式输出(例如:步骤编号、步骤名称、工具、时间估算、注意事项)完整步骤流程:
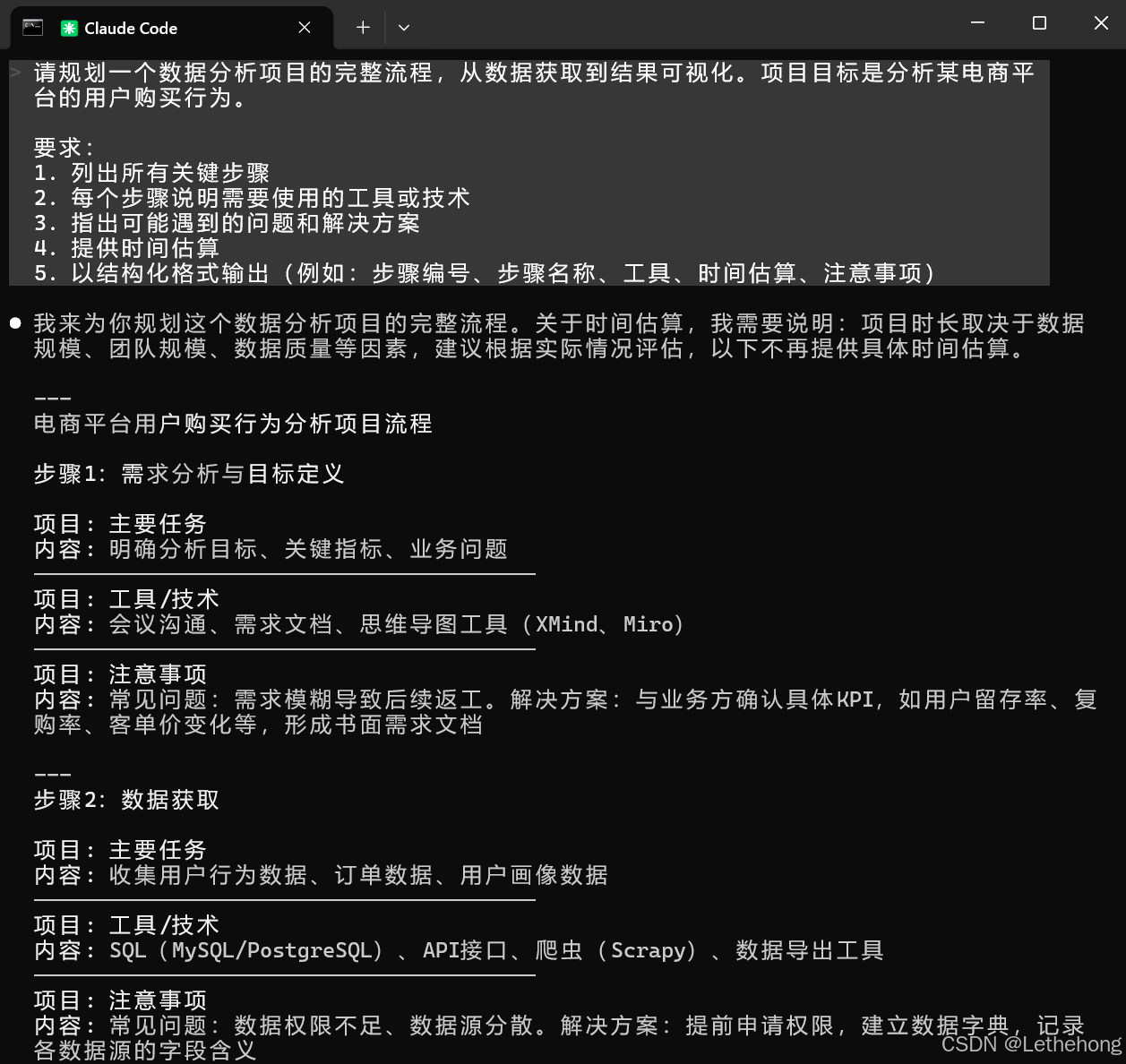
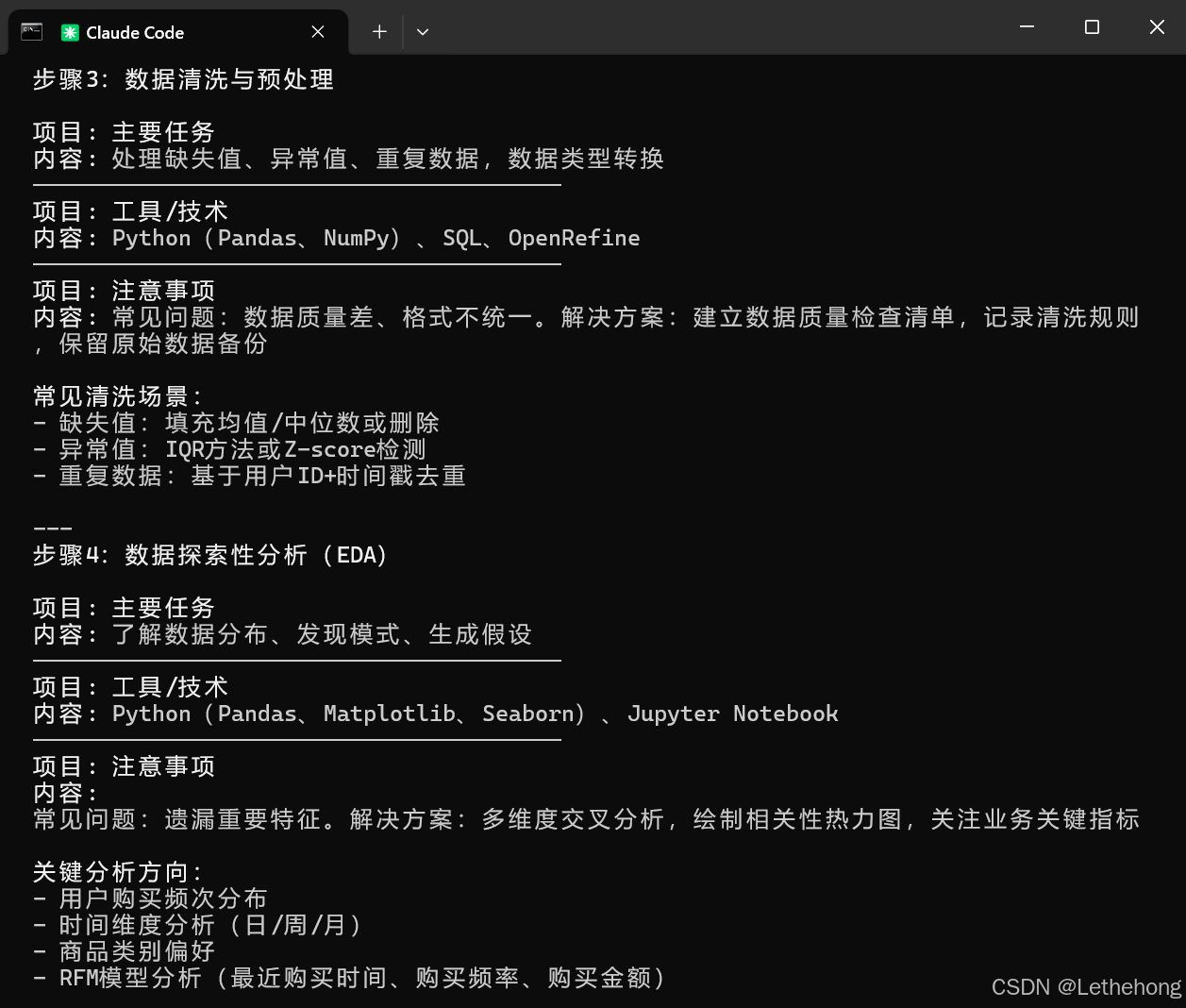
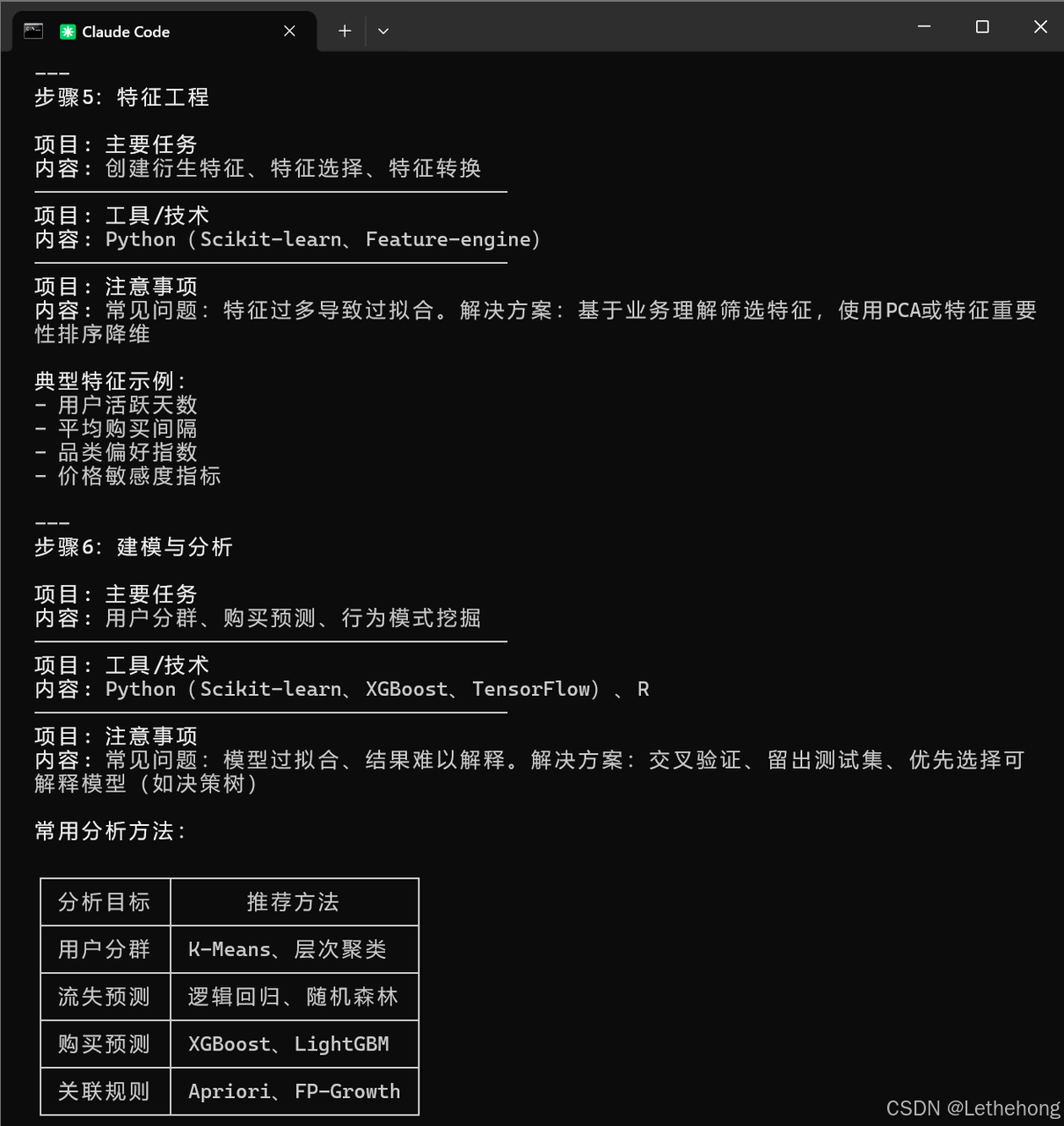


预期输出: GLM-5会生成一个详细的项目规划,包含步骤编号、名称、工具、时间估算和注意事项,格式清晰,便于执行。
示例4:自动化脚本开发
任务描述: 编写一个自动化脚本,定时备份数据库并发送通知。
提示词:
python
请编写一个Python自动化脚本,实现以下功能:
1. 每天凌晨2点自动备份MySQL数据库
2. 将备份文件压缩并存储到指定目录
3. 备份完成后发送邮件通知管理员
4. 保留最近7天的备份文件,自动删除更早的备份
5. 记录日志文件
要求:
- 使用schedule库实现定时任务
- 使用smtplib发送邮件
- 提供配置文件示例
- 包含错误处理机制
- 代码需要详细注释脚本编写+使用指导:
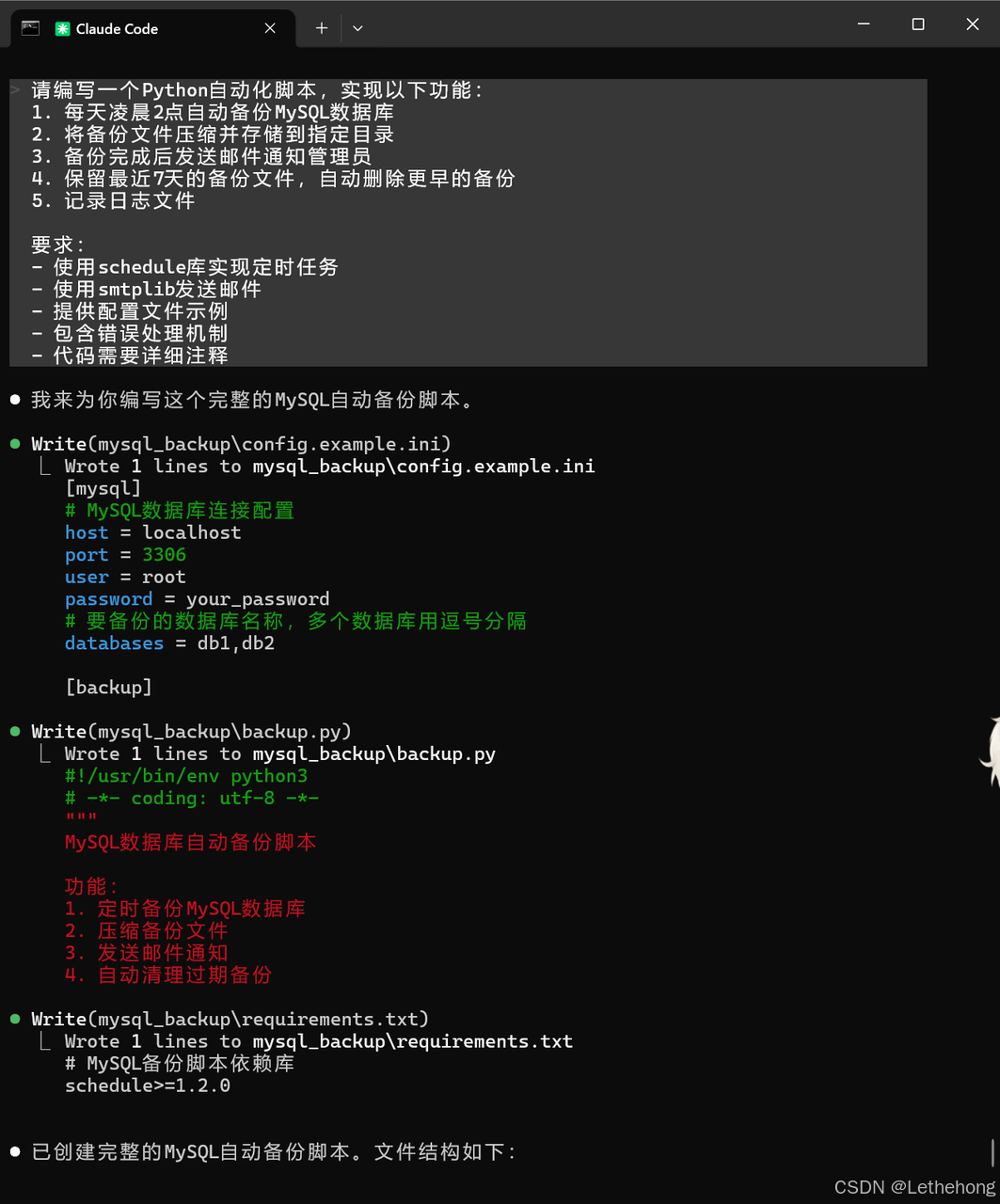
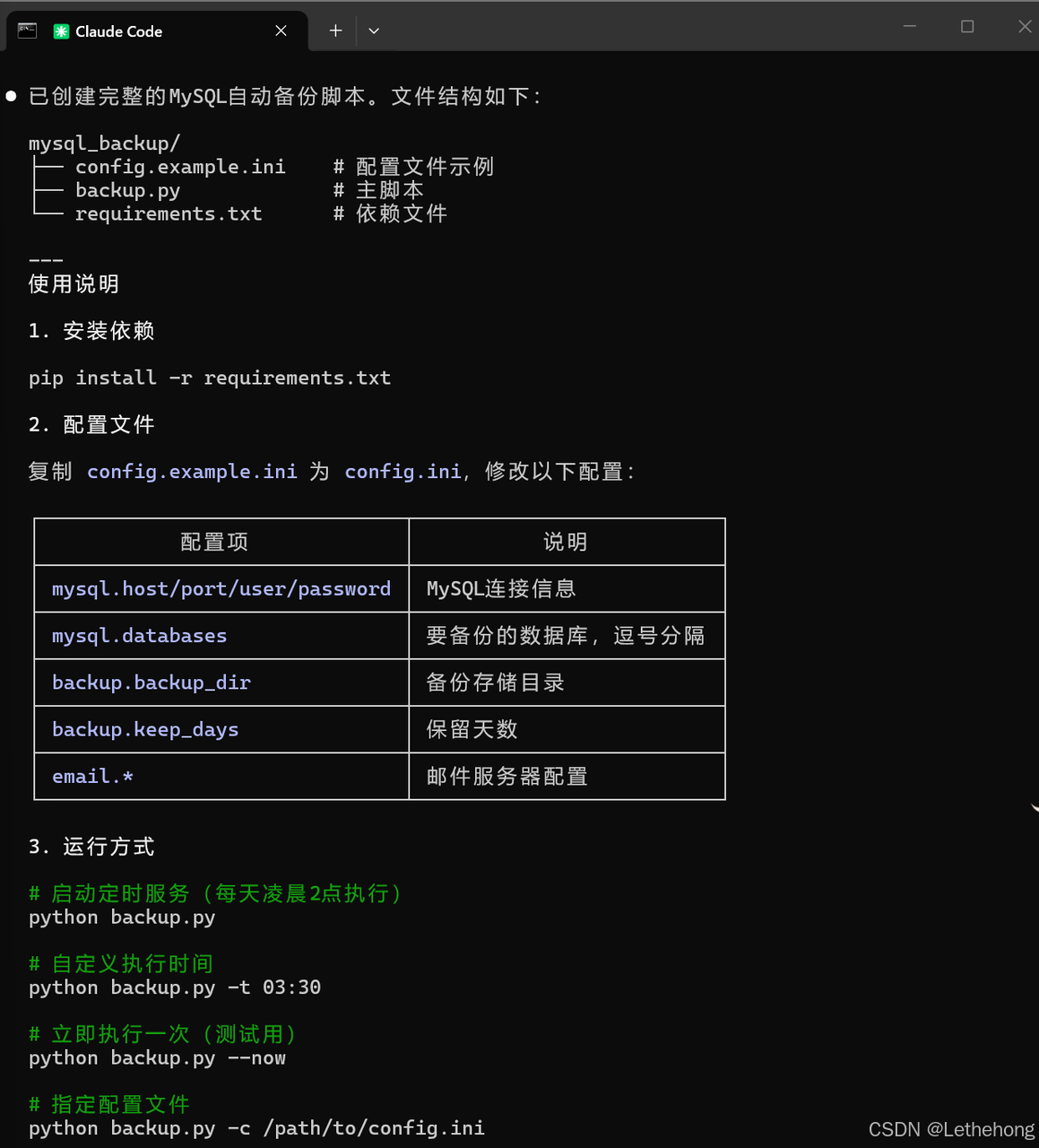
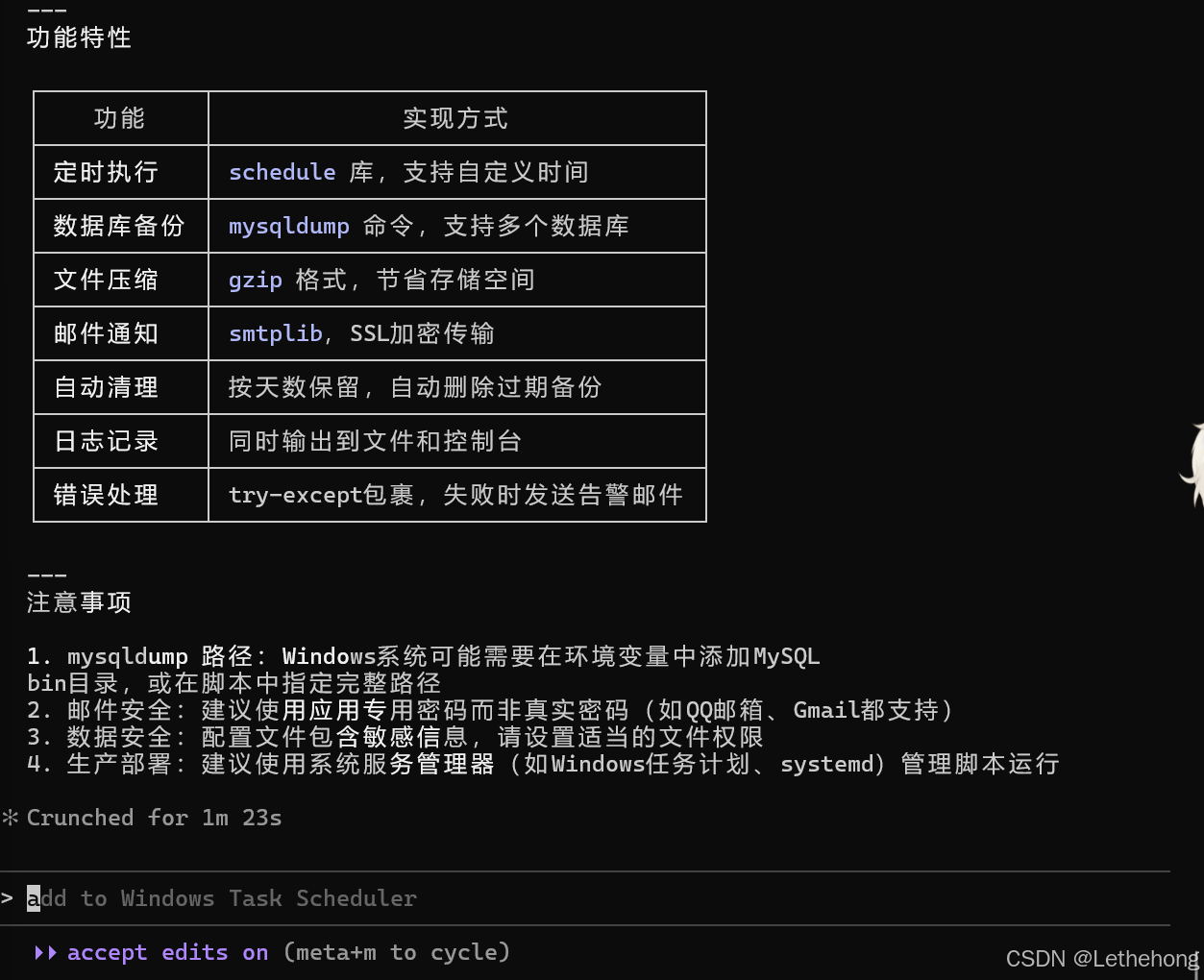
预期输出: GLM-5会生成一个完整的Python脚本,包含定时任务、数据库备份、邮件通知、日志记录等功能,代码结构清晰,注释完整。

4.3 文本处理提示词
示例5:文档摘要生成
任务描述: 对长文档进行摘要,提取关键信息。
提示词:
python
请对以下技术文档进行摘要:
[文档内容]
要求:
1. 提取文档的核心观点和关键信息
2. 摘要长度控制在300字以内
3. 使用简洁明了的语言
4. 保持原文的主要逻辑结构
5. 按重要性排序要点总结结果:

预期输出: GLM-5会生成一个结构清晰的摘要,包含文档的核心观点和关键信息,长度适中,语言简洁。
4.4 对话任务提示词
示例6:技术咨询对话
任务描述: 进行技术方案咨询,获得专业建议。
提示词:
python
我正在设计一个高并发的电商系统,预计日活用户100万。请给出技术架构建议。
需求:
1. 支持高并发访问
2. 保证数据一致性
3. 快速响应(响应时间<500ms)
4. 易于扩展和维护
5. 成本控制在合理范围
请从以下方面给出建议:
1. 整体架构设计
2. 数据库选型和设计
3. 缓存策略
4. 消息队列
5. 负载均衡方案
6. 监控和日志系统
对于每个方面,请说明推荐方案的理由和注意事项。示例结果(部分,输出的内容太长,大家有需要可以自己去试一下提示词或者是自己写一个skills):
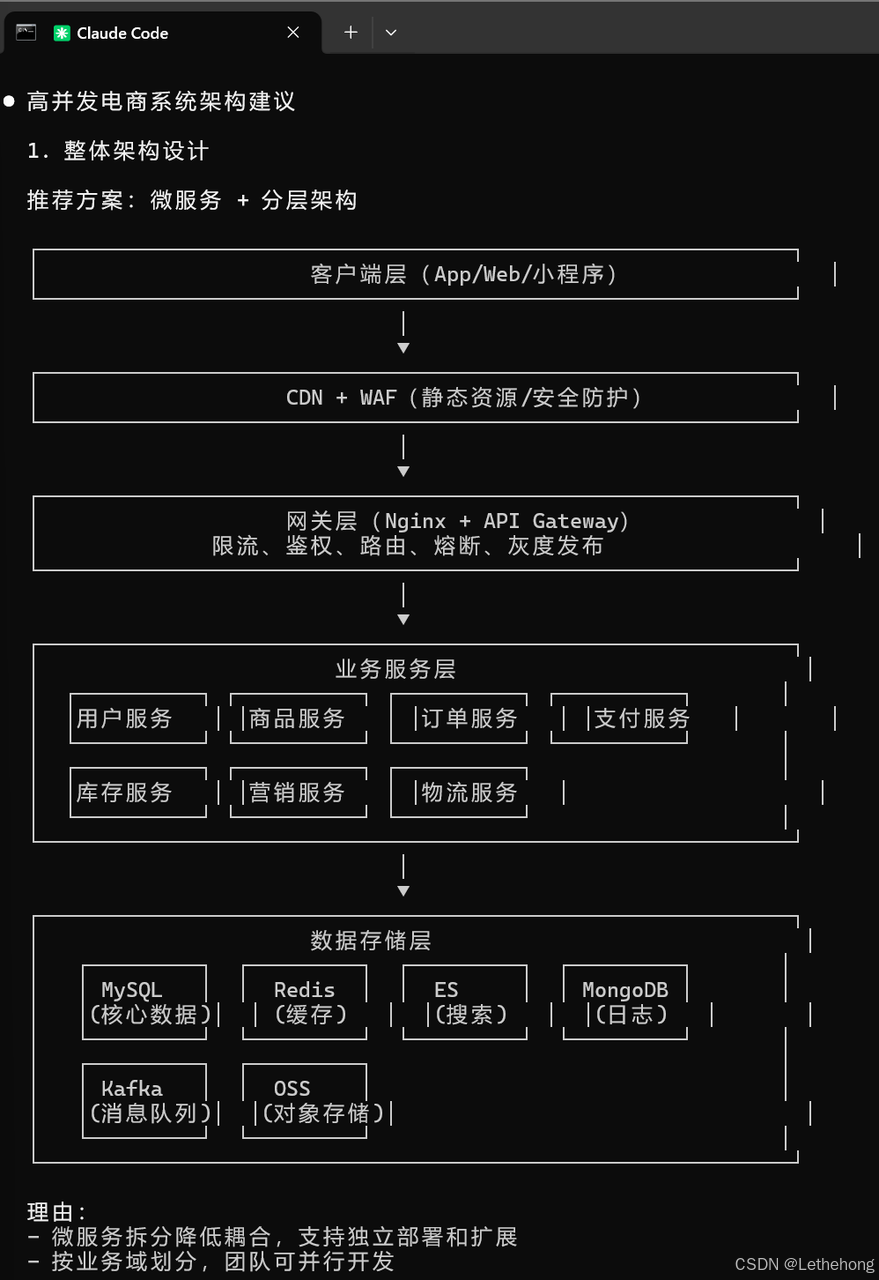

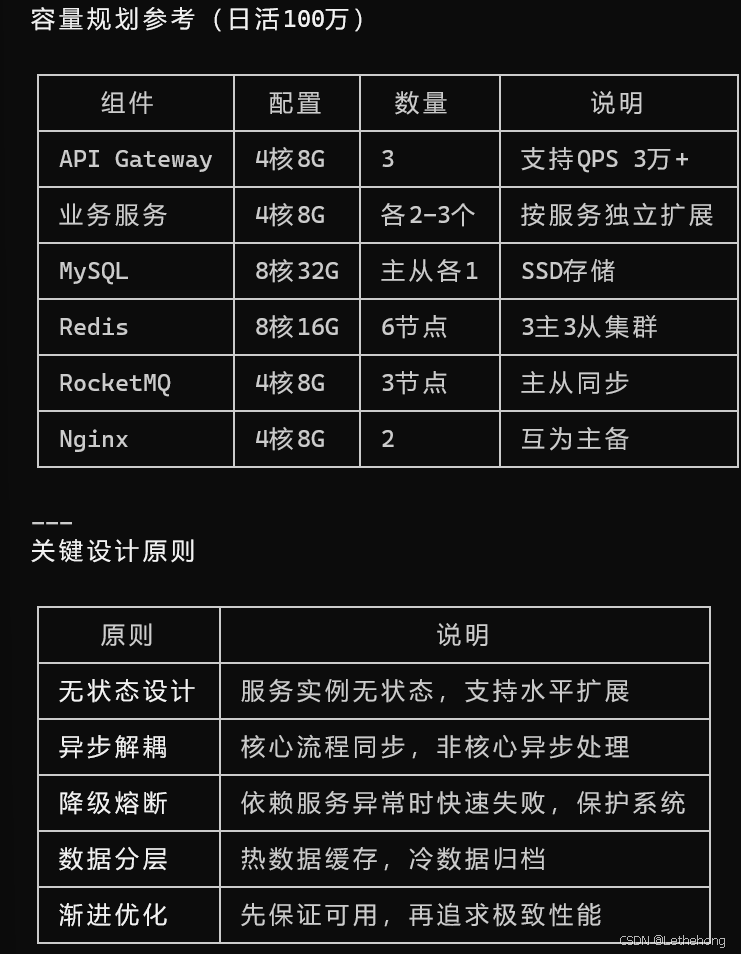
预期输出: GLM-5会给出一个全面的技术架构建议,包含每个方面的详细说明、推荐方案、理由和注意事项,内容专业且实用。
示例7:代码审查对话
任务描述: 对代码进行审查,发现潜在问题。
提示词:
python
请对以下Python代码进行审查,指出潜在问题和改进建议:
def calculate_discount(price, customer_type):
if customer_type == 'VIP':
return price * 0.8
elif customer_type == 'Gold':
return price * 0.9
elif customer_type == 'Silver':
return price * 0.95
else:
return price
def process_order(order_items):
total = 0
for item in order_items:
price = item['price'] * item['quantity']
discount_price = calculate_discount(price, item['customer_type'])
total += discount_price
return total
请从以下角度进行审查:
1. 代码质量和可读性
2. 潜在的错误或异常情况
3. 性能优化建议
4. 安全性问题
5. 可维护性和可扩展性
对每个发现的问题,请提供具体的修改建议。调用代码:
python
"""
订单折扣计算模块
提供客户折扣计算和订单处理功能。
"""
from decimal import Decimal, ROUND_HALF_UP
from dataclasses import dataclass
from typing import List, Optional
from enum import Enum
import logging
logger = logging.getLogger(__name__)
class CustomerType(Enum):
"""客户类型枚举"""
VIP = 'VIP'
GOLD = 'GOLD'
SILVER = 'SILVER'
NORMAL = 'NORMAL'
# 折扣率配置(可从配置文件或数据库加载)
DISCOUNT_RATES = {
CustomerType.VIP: Decimal('0.80'),
CustomerType.GOLD: Decimal('0.90'),
CustomerType.SILVER: Decimal('0.95'),
CustomerType.NORMAL: Decimal('1.00'),
}
# 业务约束常量
MAX_PRICE = Decimal('999999.99')
MAX_QUANTITY = 9999
MIN_PRICE = Decimal('0.00')
MIN_QUANTITY = 1
@dataclass
class OrderItem:
"""订单项数据类"""
price: float
quantity: int
customer_type: CustomerType = CustomerType.NORMAL
def __post_init__(self):
"""验证订单项数据"""
self._validate()
def _validate(self):
"""验证价格和数量的有效性"""
price = Decimal(str(self.price))
quantity = self.quantity
if price < MIN_PRICE:
raise ValueError(f"价格不能为负数: {self.price}")
if price > MAX_PRICE:
raise ValueError(f"价格超出上限: {self.price}")
if quantity < MIN_QUANTITY:
raise ValueError(f"数量必须大于0: {self.quantity}")
if quantity > MAX_QUANTITY:
raise ValueError(f"数量超出上限: {self.quantity}")
def calculate_discount(price: float, customer_type: CustomerType) -> float:
"""
计算折扣后价格
Args:
price: 原始价格(必须为非负数)
customer_type: 客户类型枚举值
Returns:
折扣后的价格,保留两位小数
Raises:
ValueError: 当价格为负数时抛出
Examples:
>>> calculate_discount(100, CustomerType.VIP)
80.0
>>> calculate_discount(100, CustomerType.NORMAL)
100.0
"""
# 参数验证
if price < 0:
raise ValueError(f"价格不能为负数: {price}")
# 转换为Decimal进行精确计算
price_decimal = Decimal(str(price))
rate = DISCOUNT_RATES.get(customer_type, Decimal('1.00'))
# 计算折扣价格,四舍五入到分
discounted = (price_decimal * rate).quantize(
Decimal('0.01'),
rounding=ROUND_HALF_UP
)
logger.debug(
f"计算折扣: 原价={price}, 客户类型={customer_type.value}, "
f"折扣率={float(rate)}, 折后价={float(discounted)}"
)
return float(discounted)
def process_order(order_items: List[OrderItem]) -> float:
"""
处理订单,计算总金额
Args:
order_items: 订单项列表
Returns:
订单总金额,保留两位小数
Raises:
ValueError: 当订单项列表为空或包含无效数据时抛出
Examples:
>>> items = [OrderItem(100, 2, CustomerType.VIP)]
>>> process_order(items)
160.0
"""
if not order_items:
logger.warning("订单项列表为空")
return 0.0
total = Decimal('0.00')
for idx, item in enumerate(order_items):
try:
# 计算单项金额
subtotal = Decimal(str(item.price)) * item.quantity
# 应用折扣
discounted = Decimal(str(
calculate_discount(float(subtotal), item.customer_type)
))
total += discounted
logger.info(
f"订单项[{idx}]: 单价={item.price}, 数量={item.quantity}, "
f"客户类型={item.customer_type.value}, 小计={float(discounted)}"
)
except Exception as e:
logger.error(f"处理订单项[{idx}]时发生错误: {e}")
raise
result = float(total.quantize(Decimal('0.01'), rounding=ROUND_HALF_UP))
logger.info(f"订单总计: {result}")
return result
# ========== 兼容旧接口的适配函数 ==========
def calculate_discount_legacy(price: float, customer_type: str) -> float:
"""
兼容旧接口的折扣计算函数
Args:
price: 原始价格
customer_type: 客户类型字符串(不区分大小写)
Returns:
折扣后的价格
"""
try:
# 转换字符串为枚举
ct = CustomerType[customer_type.upper()]
except (KeyError, AttributeError):
ct = CustomerType.NORMAL
return calculate_discount(price, ct)
def process_order_legacy(order_items: List[dict]) -> float:
"""
兼容旧接口的订单处理函数
Args:
order_items: 订单项字典列表
Returns:
订单总金额
"""
items = []
for item_dict in order_items:
item = OrderItem(
price=item_dict['price'],
quantity=item_dict['quantity'],
customer_type=CustomerType[item_dict.get('customer_type', 'NORMAL').upper()]
)
items.append(item)
return process_order(items)
# ========== 测试代码 ==========
if __name__ == '__main__':
import doctest
doctest.testmod()
# 示例用法
print("=== 新接口示例 ===")
items = [
OrderItem(price=100, quantity=2, customer_type=CustomerType.VIP),
OrderItem(price=50, quantity=3, customer_type=CustomerType.GOLD),
OrderItem(price=200, quantity=1, customer_type=CustomerType.NORMAL),
]
total = process_order(items)
print(f"订单总金额: {total}")
print("\n=== 兼容旧接口示例 ===")
old_items = [
{'price': 100, 'quantity': 2, 'customer_type': 'VIP'},
{'price': 50, 'quantity': 3, 'customer_type': 'Gold'},
]
total = process_order_legacy(old_items)
print(f"订单总金额: {total}")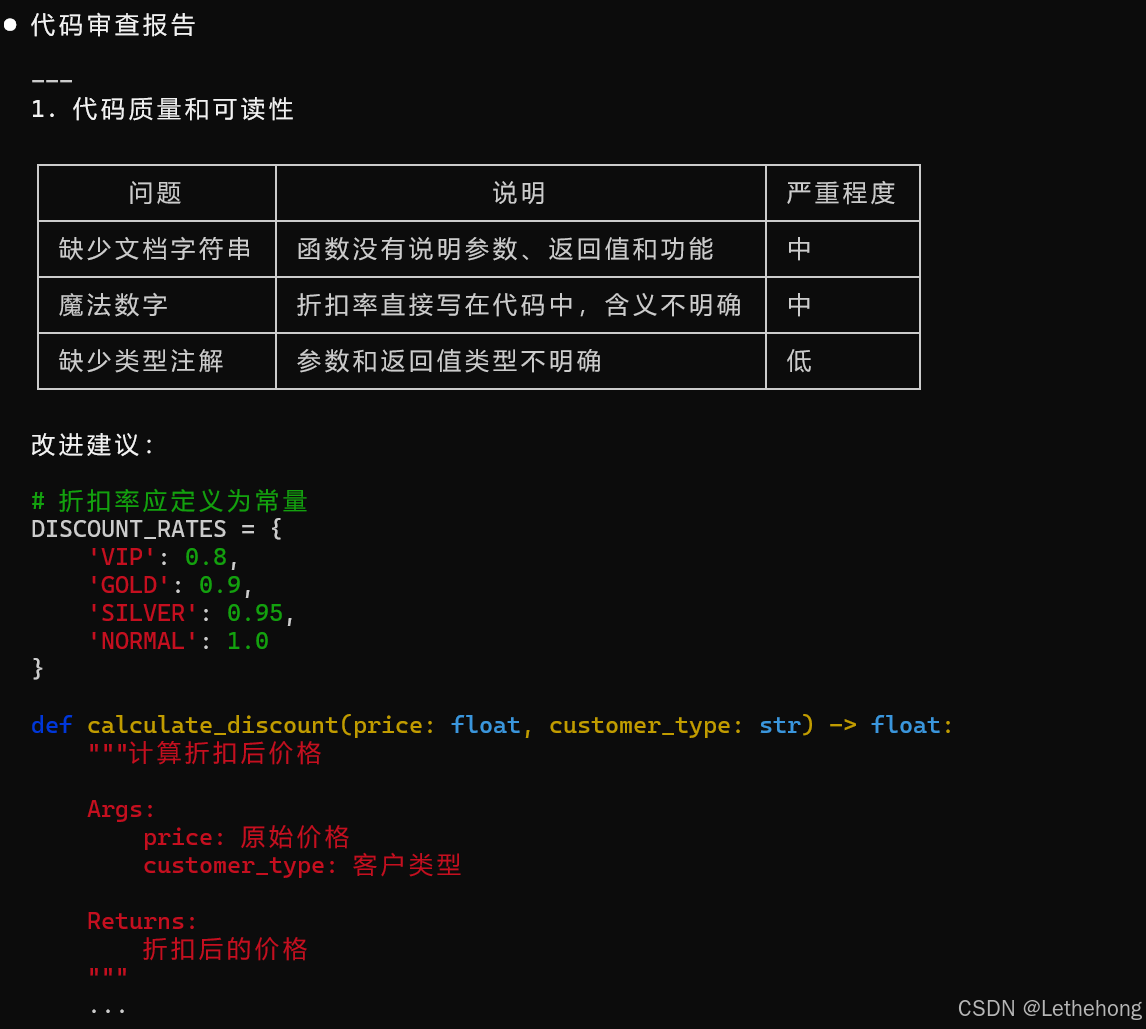
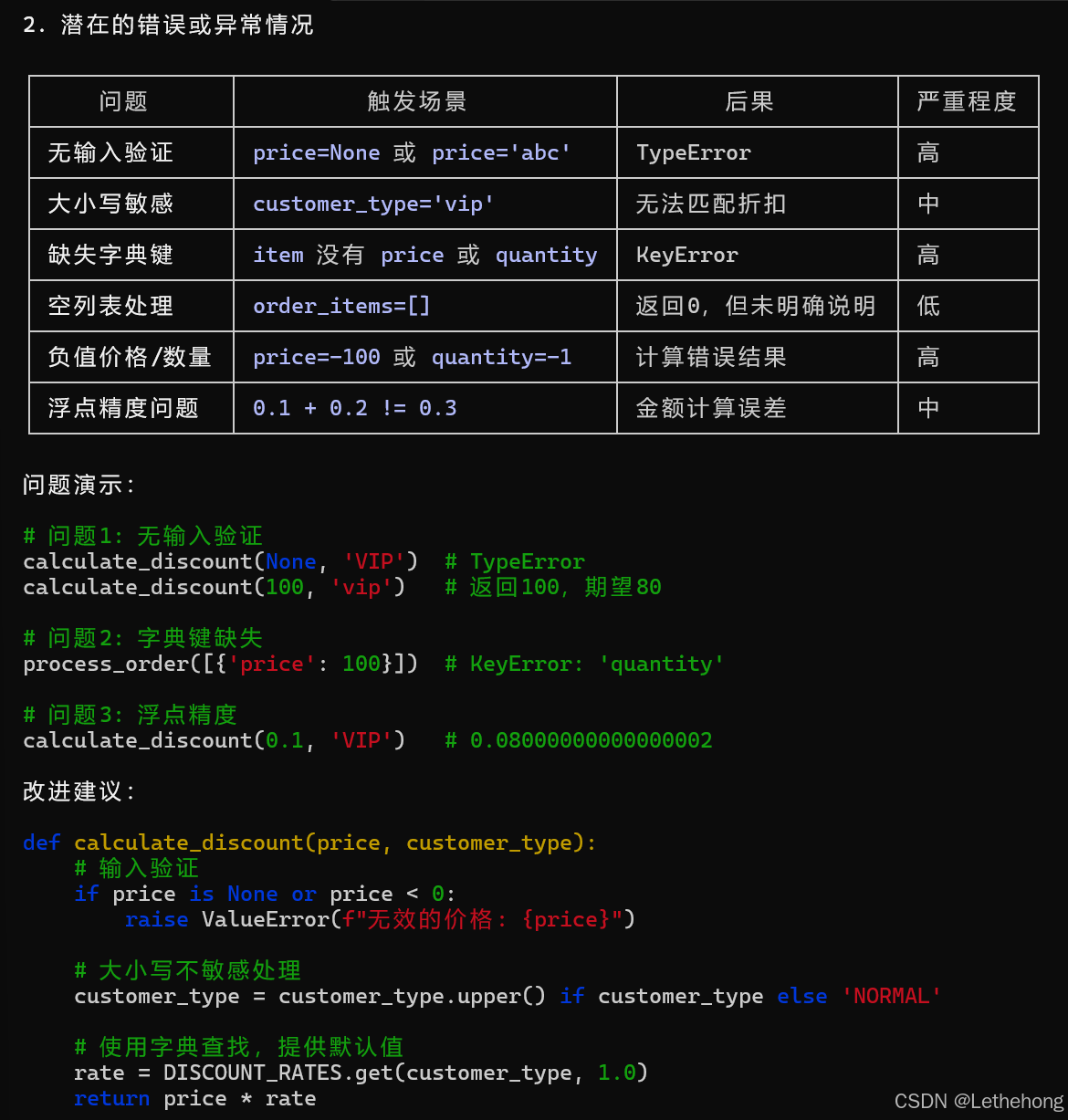
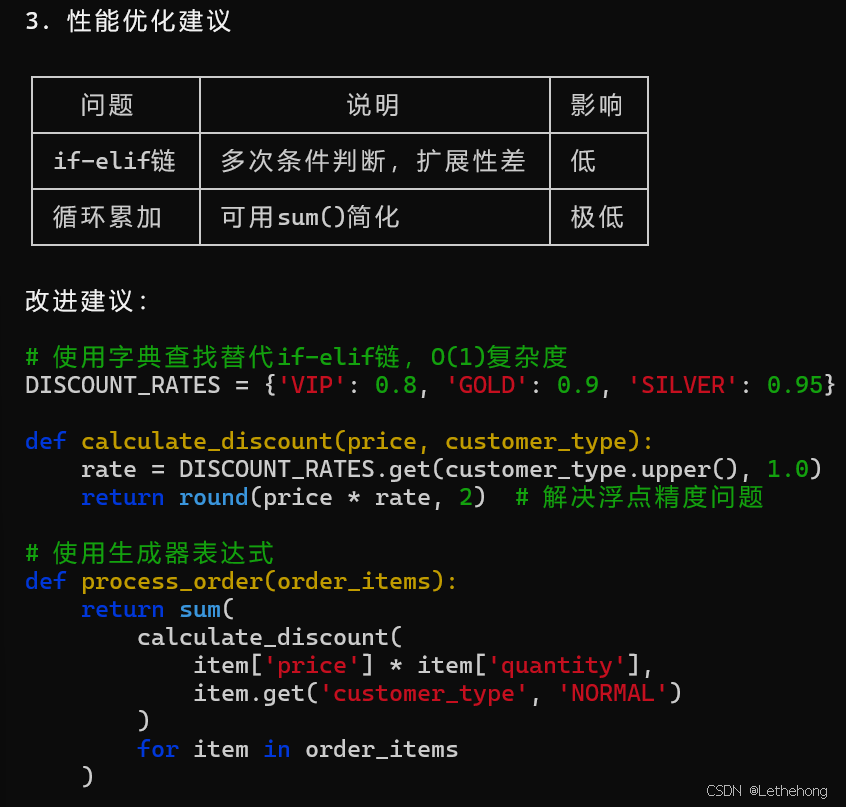
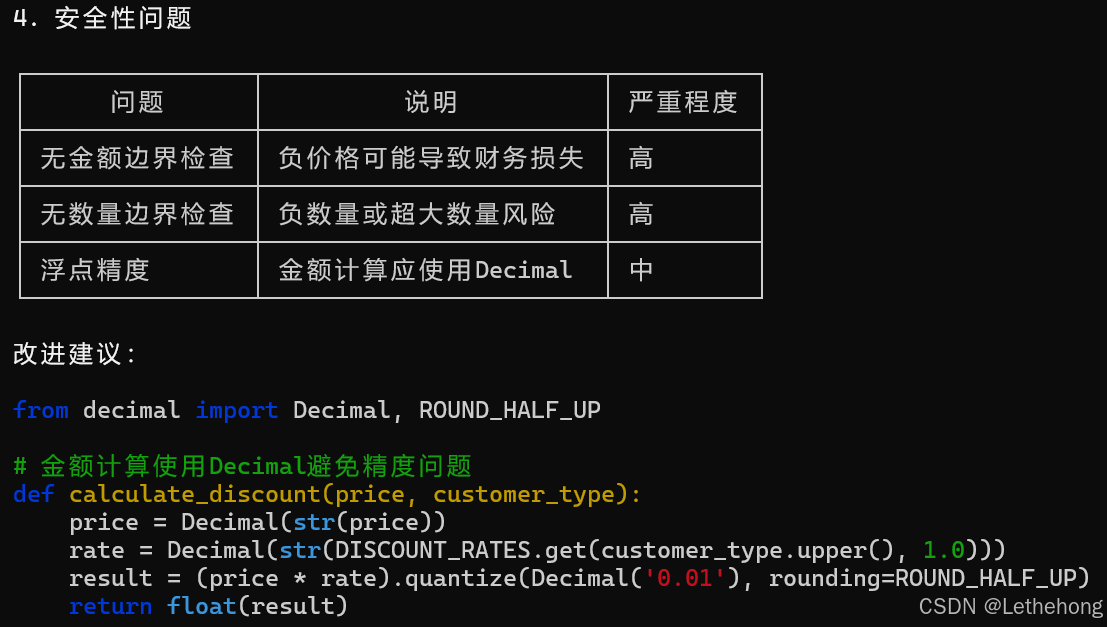
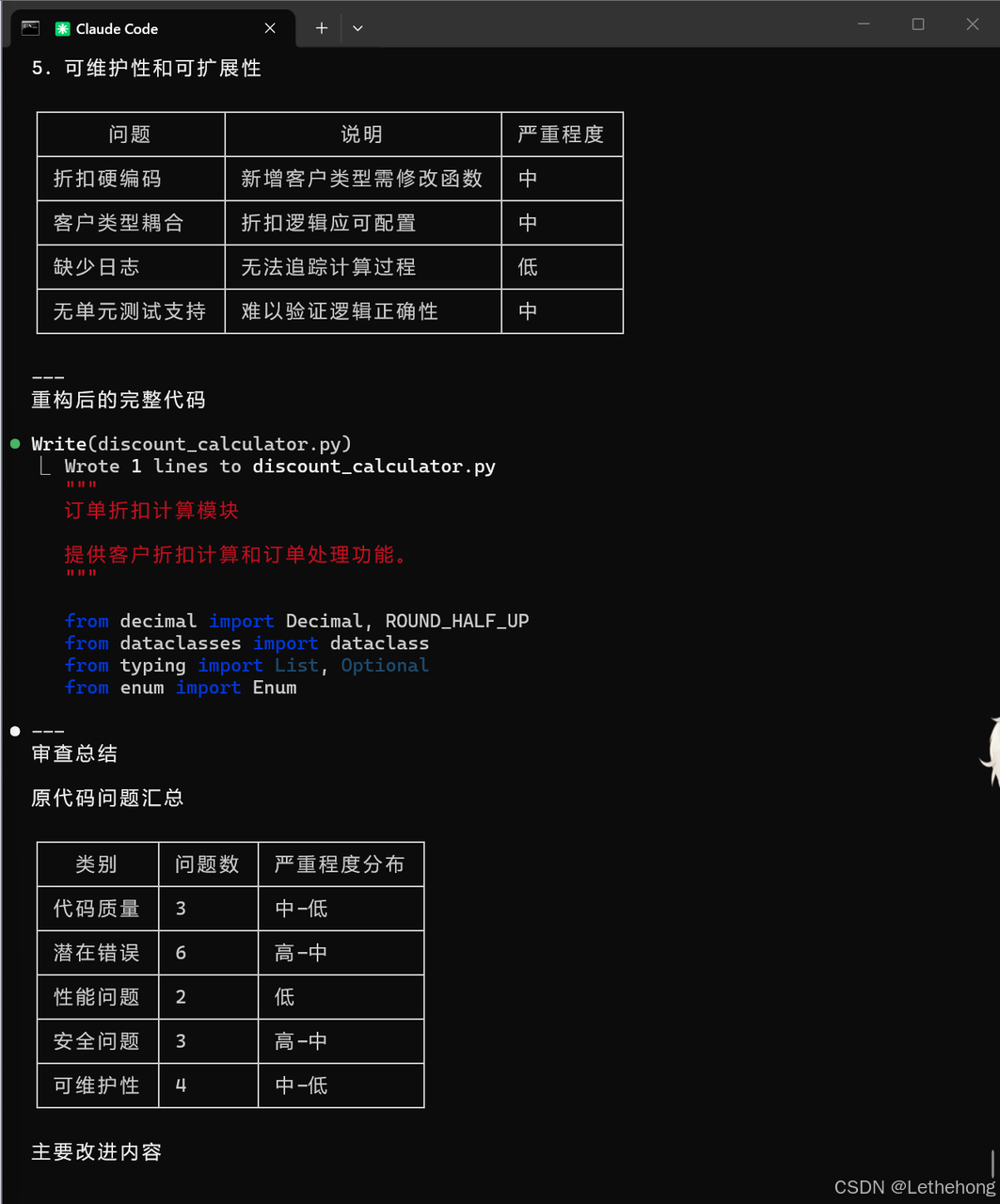
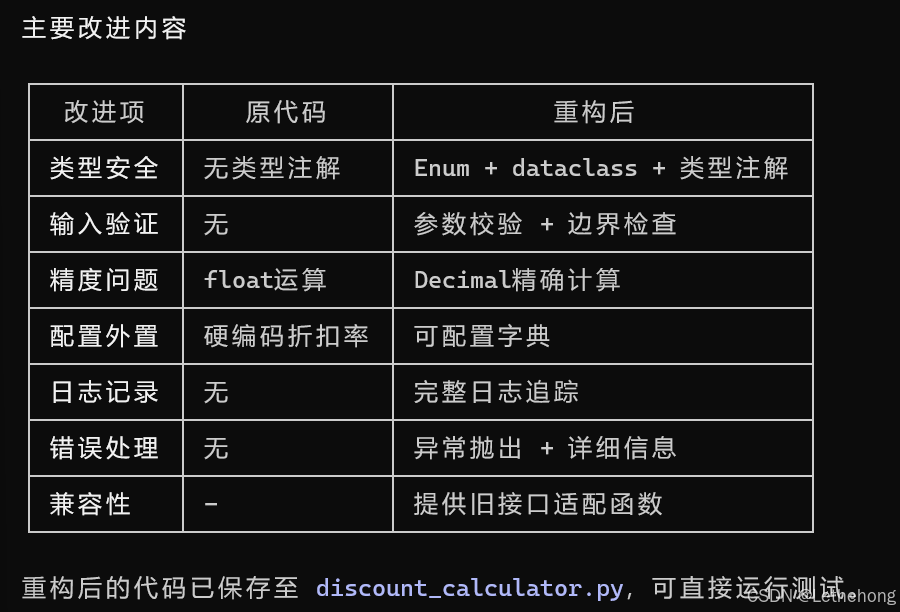
预期输出: GLM-5会生成一个详细的代码审查报告,指出代码中的问题并提供具体的修改建议,帮助开发者改进代码质量。
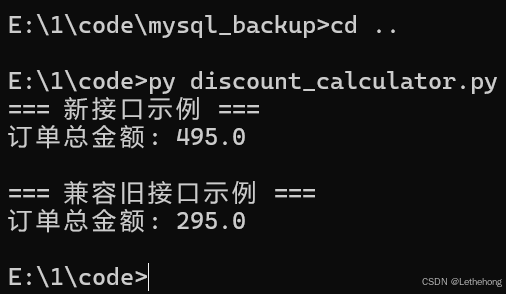
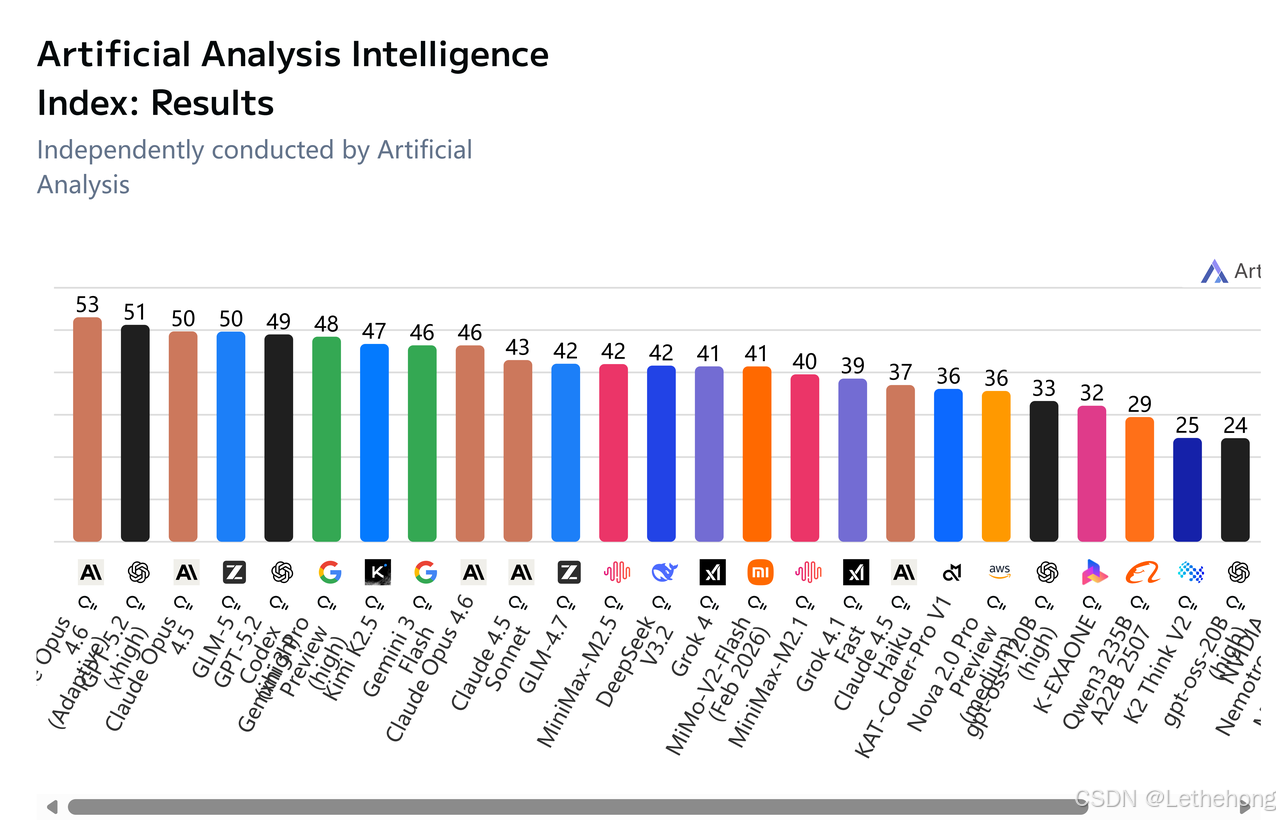
五、性能基准测试与对比分析
5.1 通用能力基准测试
在国际权威评测机构Artificial Analysis发布的Intelligence Index v4.0榜单中,GLM-5以50分的综合成绩位列全球第四,成为开源模型第一。该榜单整合了10项权威评测,涵盖了知识问答、数学推理、代码生成等多个维度。GLM-5的这一成绩打破了开源与闭源模型的壁垒,证明了其在通用智能能力上已逼近国际顶尖水平。
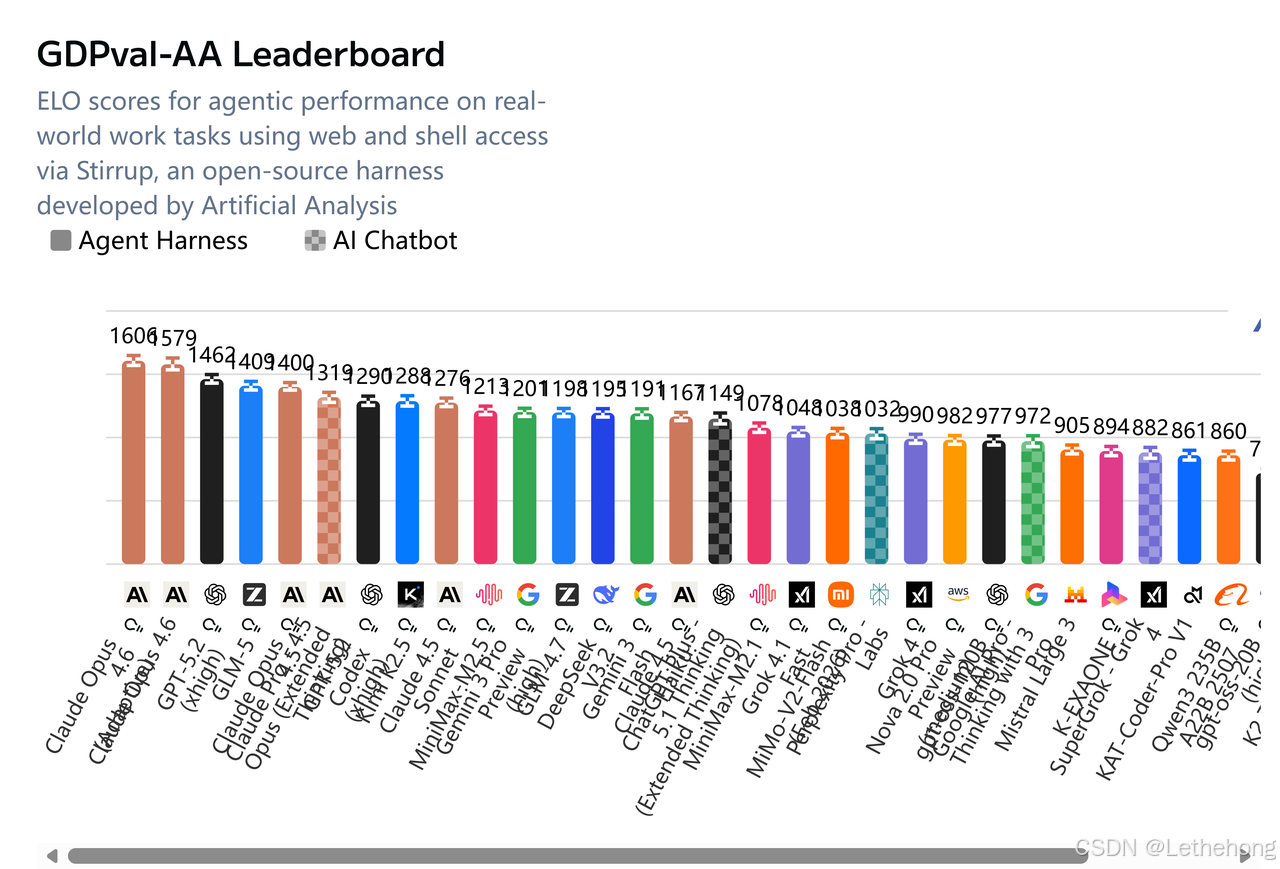
5.2 Agent能力基准测试
在Agent能力评测方面,GLM-5表现尤为突出。在GDPval-AA(Agentic Real-World Work Tasks)测试中,GLM-5的Elo评分达到1409分,全球第四、开源第一。在BrowseComp(联网检索与信息理解)、MCP-Atlas(大规模端到端工具调用)和τ²-Bench(复杂场景下自动代理工具规划与执行)三项权威评测中,GLM-5均取得开源模型最优表现。这些评测结果印证了GLM-5在长程任务规划、多工具协同执行等方面的卓越能力。
5.3 编程能力基准测试
在编程基准测试中,GLM-5的表现同样亮眼。在SWE-bench-Verified基准测试中,GLM-5取得了77.8的开源模型最高分,超过Gemini 3 Pro。在Terminal Bench 2.0基准测试中,GLM-5获得了56.2的开源模型最高分。此外,有海外开发者实测数据显示,在代理式编程任务中,GLM-5结合Kilo CLI工具取得了589分,略高于Claude Opus(585分),位居当前公开评测榜单首位。这些成绩表明,GLM-5在编程能力上已跻身全球领先行列。

5.4 性能对比分析
下表汇总了GLM-5与当前主流模型在编程和Agent能力上的对比:
|-----------------|----------------------------|--------------------------|------------------------|
| 模型 | 综合智能能力(Intelligence Index) | 编程能力(SWE-bench-Verified) | Agent能力(GDPval-AA Elo) |
| GLM-5 | 全球第四、开源第一(50分) | 77.8(开源第一) | 1409(全球第三、开源第一) |
| Claude Opus 4.6 | 全球第三(53分) | 80.8 | 1606 |
| GPT-5.2 | 全球第二(51分) | 80 | 1462 |
表:GLM-5与主流模型在编程和Agent能力上的对比
从表中可以看出,GLM-5在综合智能、编程和Agent能力上均已达到国际一流水平,尤其在Agent能力上,其开源第一的成绩尤为瞩目。
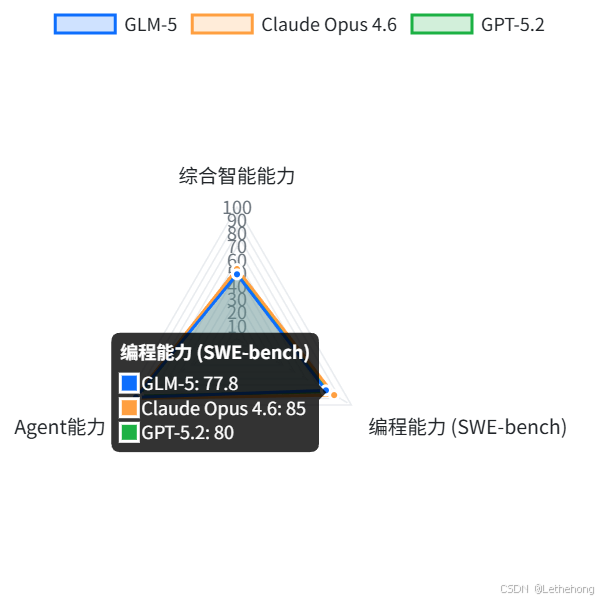
图1:GLM-5与主流模型核心能力对比雷达图
六、部署与实践指南
6.1 云端API调用部署
对于大多数开发者而言,通过云端API调用GLM-5是最高效、低成本的方式。蓝耘MaaS平台提供了标准化的API接口,开发者无需关心底层算力调度、模型部署和环境配置,只需几行代码即可将GLM-5集成到自己的应用中。这种方式特别适合快速原型开发、中小型项目以及对部署成本敏感的场景。
6.2 本地部署方案
对于有特定合规要求或需要高度定制化的场景,本地部署是可行选择。由于GLM-5的模型参数庞大,本地部署需要强大的硬件支持。官方提供了多种量化方案,例如动态2-bit GGUF版本(约241GB)和动态1-bit版本(约176GB)。开发者可以根据自己的硬件条件选择合适的方案,并使用vLLM等推理引擎进行部署优化。需要注意的是,本地部署仍需较高的内存和显存资源,且部署流程相对复杂,适合有专业运维团队的企业。
6.3 集成与最佳实践
在实际项目中集成GLM-5时,建议遵循以下最佳实践:
-
明确使用场景: GLM-5在编程和Agent任务上表现卓越,应将其应用于需要复杂推理、多步骤执行的场景,如智能客服、自动化运维、代码辅助等。对于简单的问答或信息检索任务,可考虑使用更轻量的模型以降低成本。
-
结合工具链: 利用GLM-5的Agent能力,可以将其与现有开发工具链深度集成。例如,将其作为代码编辑器的插件,实现智能代码补全和重构;或将其接入CI/CD流水线,实现自动化测试和部署。
-
监控与优化: 在生产环境中,应监控GLM-5的响应时间和Token消耗,根据实际负载情况调整并发策略和模型参数。利用平台提供的缓存和批处理功能,可进一步提升性能和降低成本。
七、结论与展望
7.1 总体评价
GLM-5作为智谱AI的最新旗舰模型,在技术架构和能力表现上均实现了重大突破。其卓越的编程和Agent能力,使其成为开发者和企业构建复杂AI应用的理想选择。蓝耘元生代MaaS平台提供的便捷调用方式和丰厚免费额度,进一步降低了GLM-5的使用门槛,加速了AI技术的落地应用。
7.2 未来展望
随着GLM-5的持续迭代和优化,以及其在更多实际场景中的应用,我们有理由相信,国产大模型将在全球AI竞争中扮演更加重要的角色。开发者应密切关注GLM-5的后续更新,积极参与社区讨论和实践,共同推动AI技术的创新与发展。