(以下内容全部出自上述课程)
目录
- 选择排序
-
- [1. 简单选择排序](#1. 简单选择排序)
-
- [1.1 算法思想](#1.1 算法思想)
- [1.2 算法实现](#1.2 算法实现)
- [1.3 算法性能分析](#1.3 算法性能分析)
- [1.4 小结](#1.4 小结)
- [2. 堆排序](#2. 堆排序)
-
- [2.1 什么是堆?](#2.1 什么是堆?)
- [2.2 如何基于堆进行排序?](#2.2 如何基于堆进行排序?)
-
- [2.2.1 建立大根堆](#2.2.1 建立大根堆)
- [2.2.2 建立大根堆(代码)](#2.2.2 建立大根堆(代码))
- [2.2.3 基于大根堆进行排序](#2.2.3 基于大根堆进行排序)
- [2.2.4 基于大根堆排序(代码)](#2.2.4 基于大根堆排序(代码))
- [2.3 算法效率分析](#2.3 算法效率分析)
- [2.4 小结](#2.4 小结)
- [2.5 基本操作](#2.5 基本操作)
-
- [2.5.1 插入操作](#2.5.1 插入操作)
- [2.5.2 删除操作](#2.5.2 删除操作)
- [2.5.3 小结](#2.5.3 小结)
- 归并排序
-
- [1. 什么是归并?](#1. 什么是归并?)
- [2. 算法思想](#2. 算法思想)
-
- [2.1 4路归并](#2.1 4路归并)
- [2.2 归并排序(手算模拟)](#2.2 归并排序(手算模拟))
- [3. 代码实现](#3. 代码实现)
-
- [3.1 例1-分别有序](#3.1 例1-分别有序)
- [3.2 例2-完全乱序](#3.2 例2-完全乱序)
- [4. 算法效率分析](#4. 算法效率分析)
- [5. 小结](#5. 小结)
- 基数排序
-
- [1. 算法思想](#1. 算法思想)
-
- [1.1 第一趟](#1.1 第一趟)
- [1.2 第二趟](#1.2 第二趟)
- [1.3 第三趟](#1.3 第三趟)
- [1.4 小总结](#1.4 小总结)
- [2. 算法效率分析](#2. 算法效率分析)
- [3. 基数排序的应用](#3. 基数排序的应用)
- [4. 小结](#4. 小结)
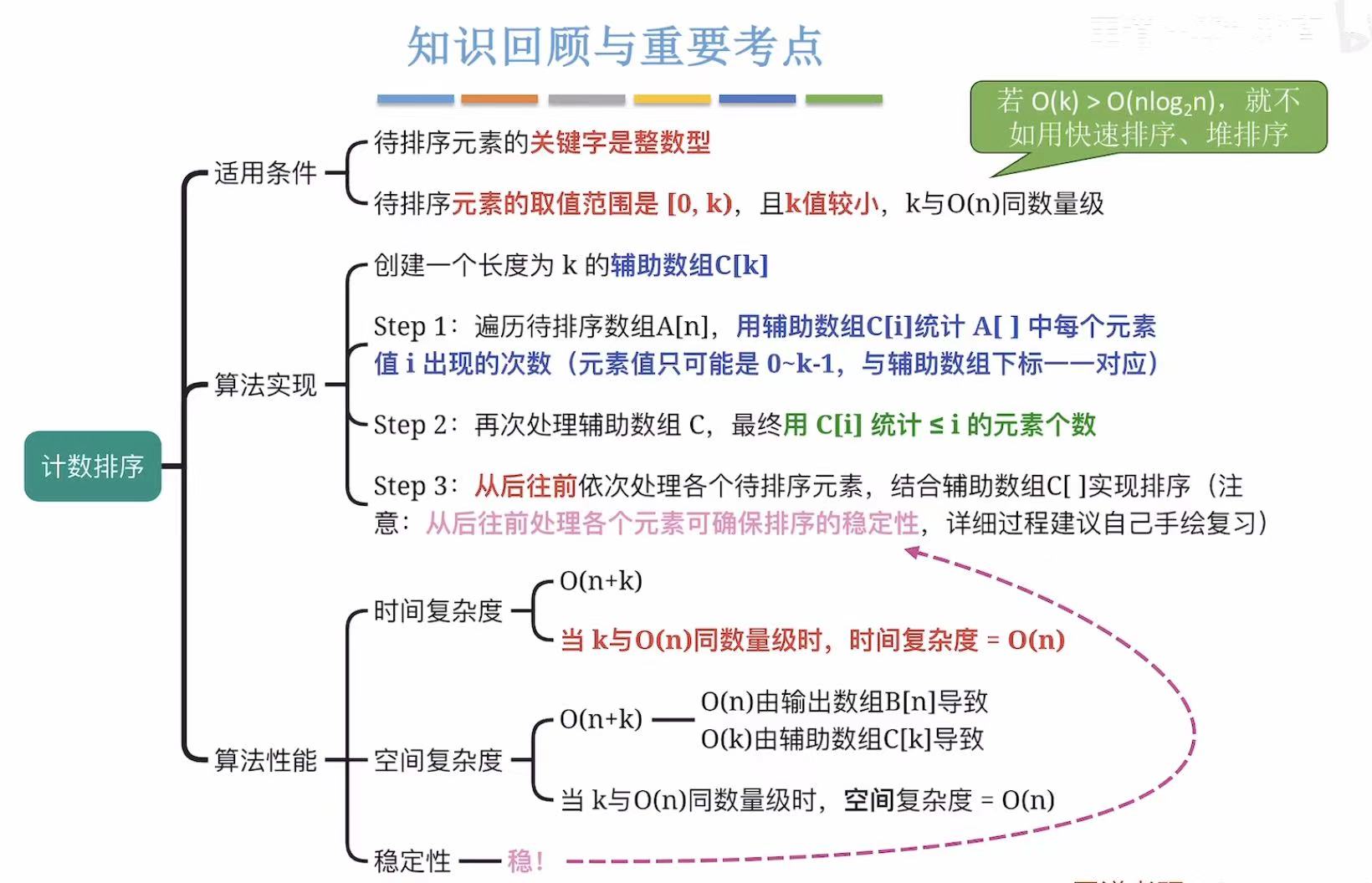
- 计数排序
-
- [1. 引入](#1. 引入)
- [2. 计数排序的实现](#2. 计数排序的实现)
- [3. 计数排序的复杂度分析](#3. 计数排序的复杂度分析)
- [4. 在考试中的应用](#4. 在考试中的应用)
- [5. 小结](#5. 小结)
选择排序
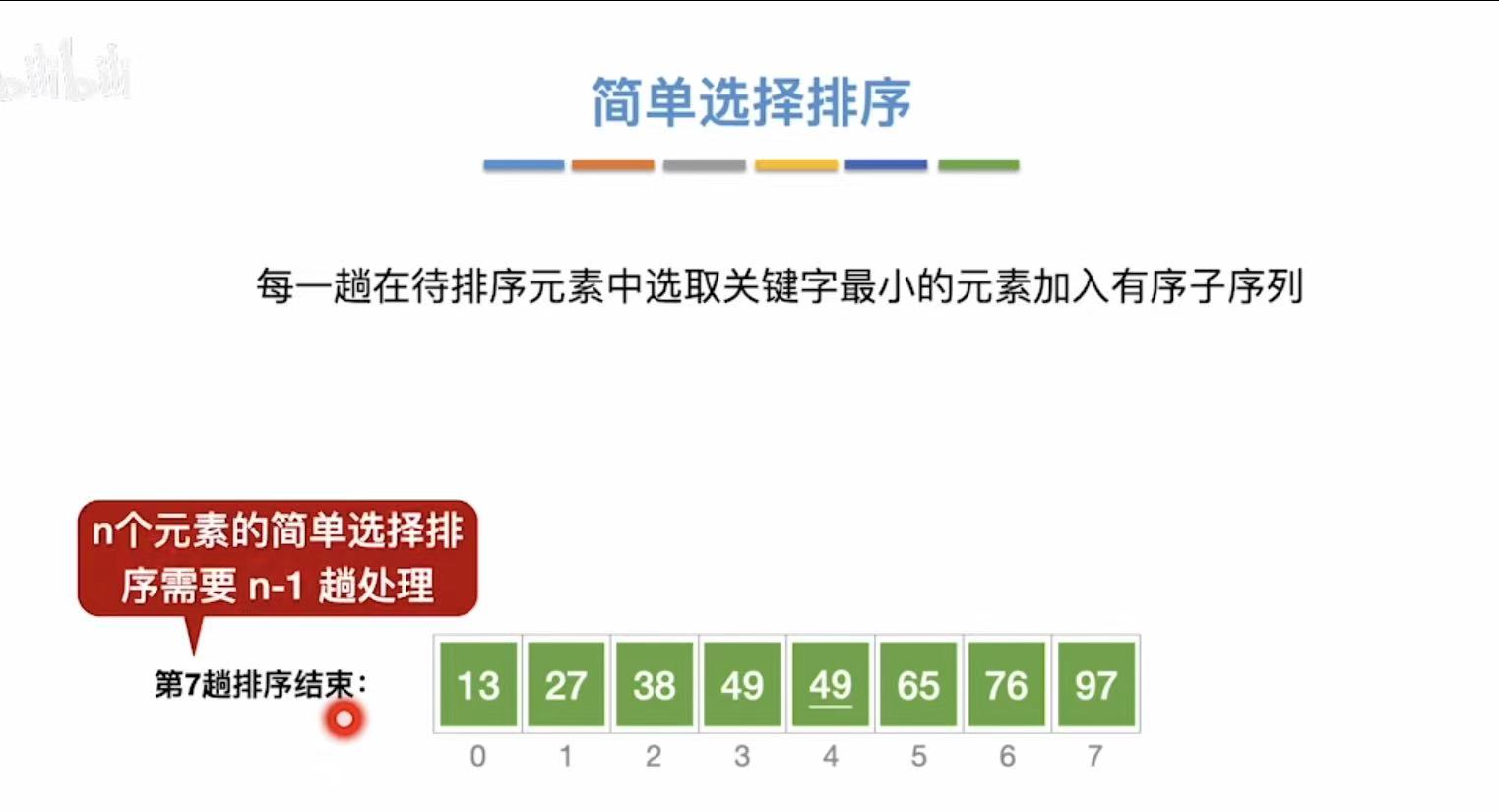
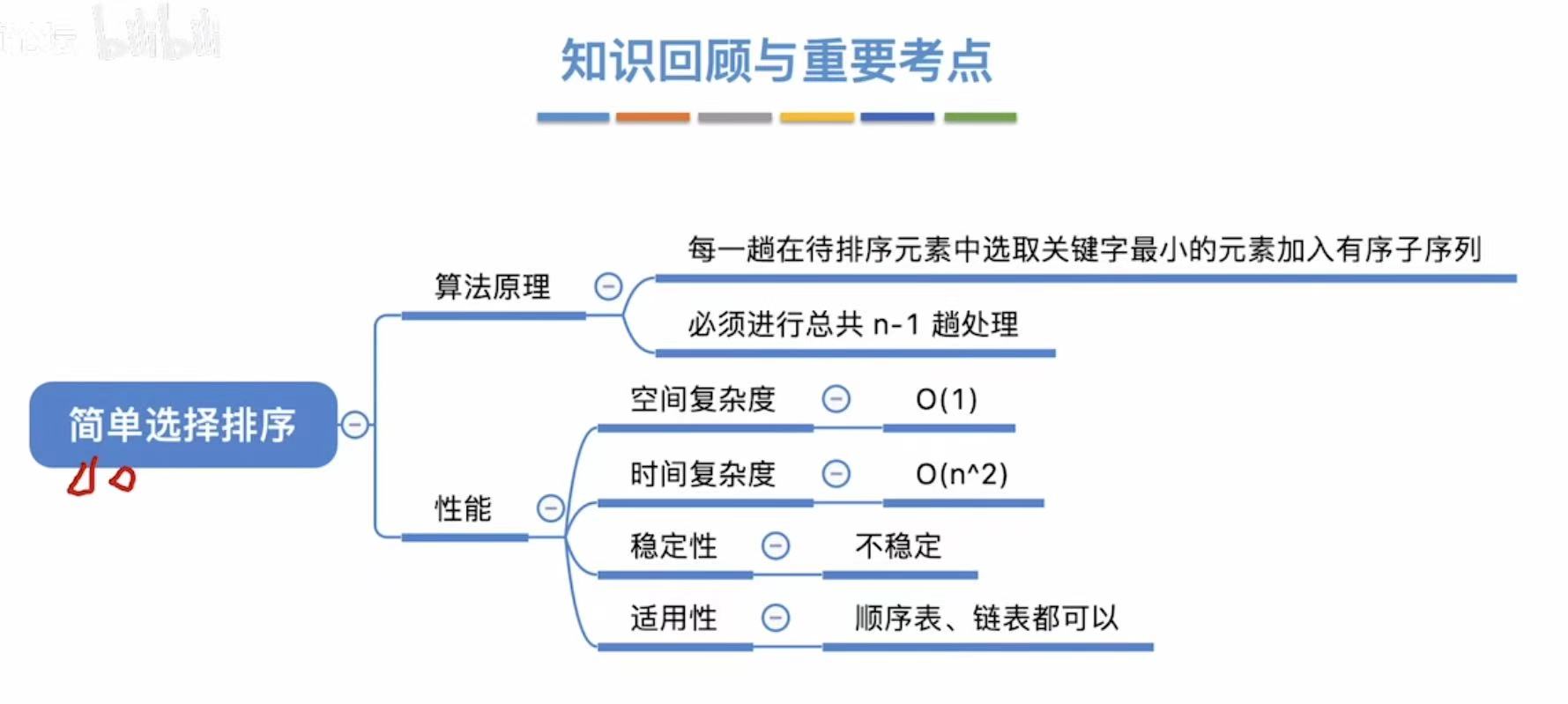
1. 简单选择排序
扫描-->找到最小-->提到前面(重复n-1轮)
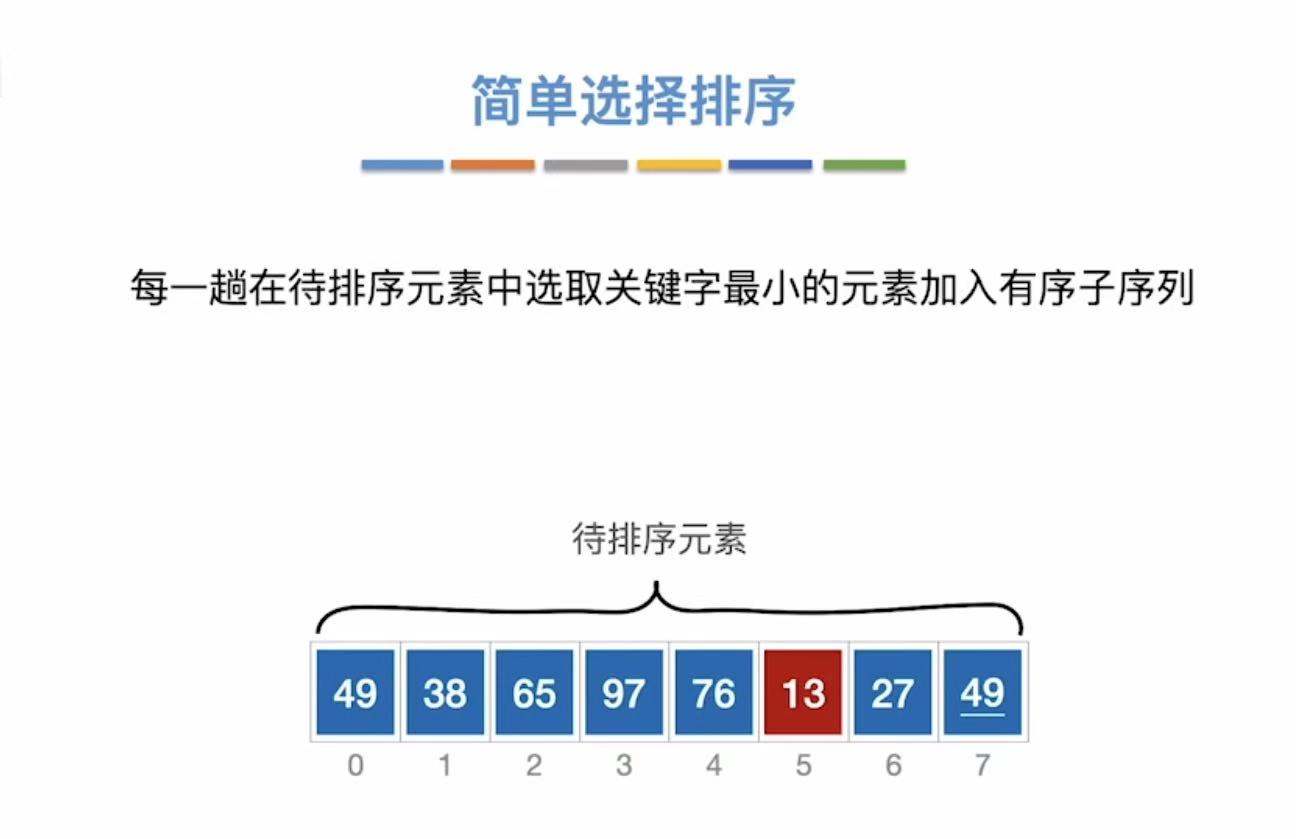
1.1 算法思想
| 轮次 (i) | 查找范围 | 最小值 | 最小值位置 | 交换操作 | 排序后数组状态(前 i+1 个已有序) |
|---|---|---|---|---|---|
| 0 | A0 ~ A7 | 13 | 5 | A0 ↔ A5 | 13, 38, 65, 97, 76, 49, 27, 49 |
| 1 | A1 ~ A7 | 27 | 6 | A1 ↔ A6 | 13, 27, 65, 97, 76, 49, 38, 49 |
| 2 | A2 ~ A7 | 38 | 6 | A2 ↔ A6 | 13, 27, 38, 97, 76, 49, 65, 49 |
| 3 | A3 ~ A7 | 49 | 5 | A3 ↔ A5 | 13, 27, 38, 49, 76, 97, 65, 49 |
| 4 | A4 ~ A7 | 49 | 7 | A4 ↔ A7 | 13, 27, 38, 49, 49, 97, 65, 76 |
| 5 | A5 ~ A7 | 65 | 6 | A5 ↔ A6 | 13, 27, 38, 49, 49, 65, 97, 76 |
| 6 | A6 ~ A7 | 76 | 7 | A6 ↔ A7 | 13, 27, 38, 49, 49, 65, 76, 97 |
| --- | --- | --- | --- | --- | 最终结果:13, 27, 38, 49, 49, 65, 76, 97 |
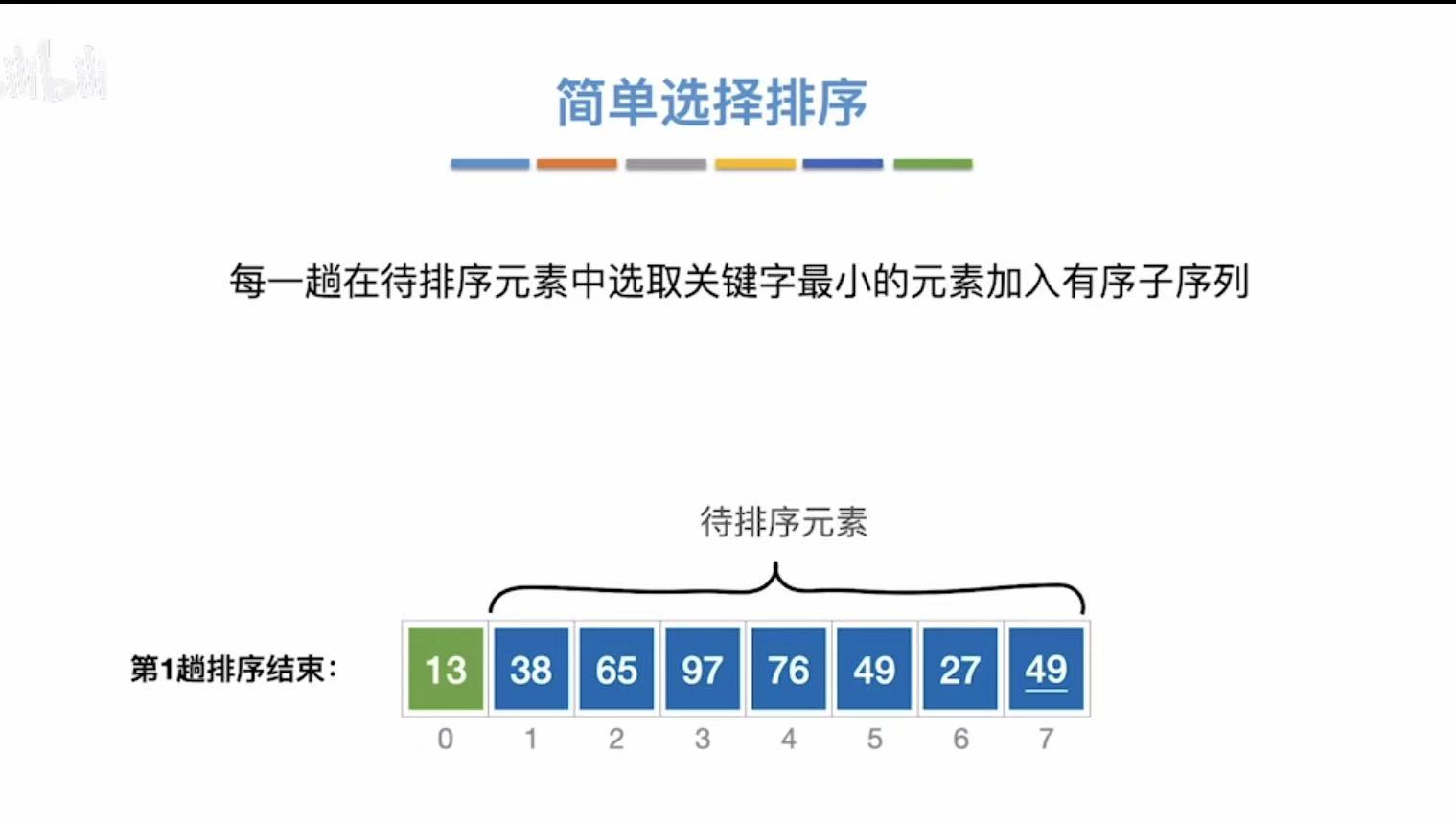
剩下最后一个就不需要处理了:
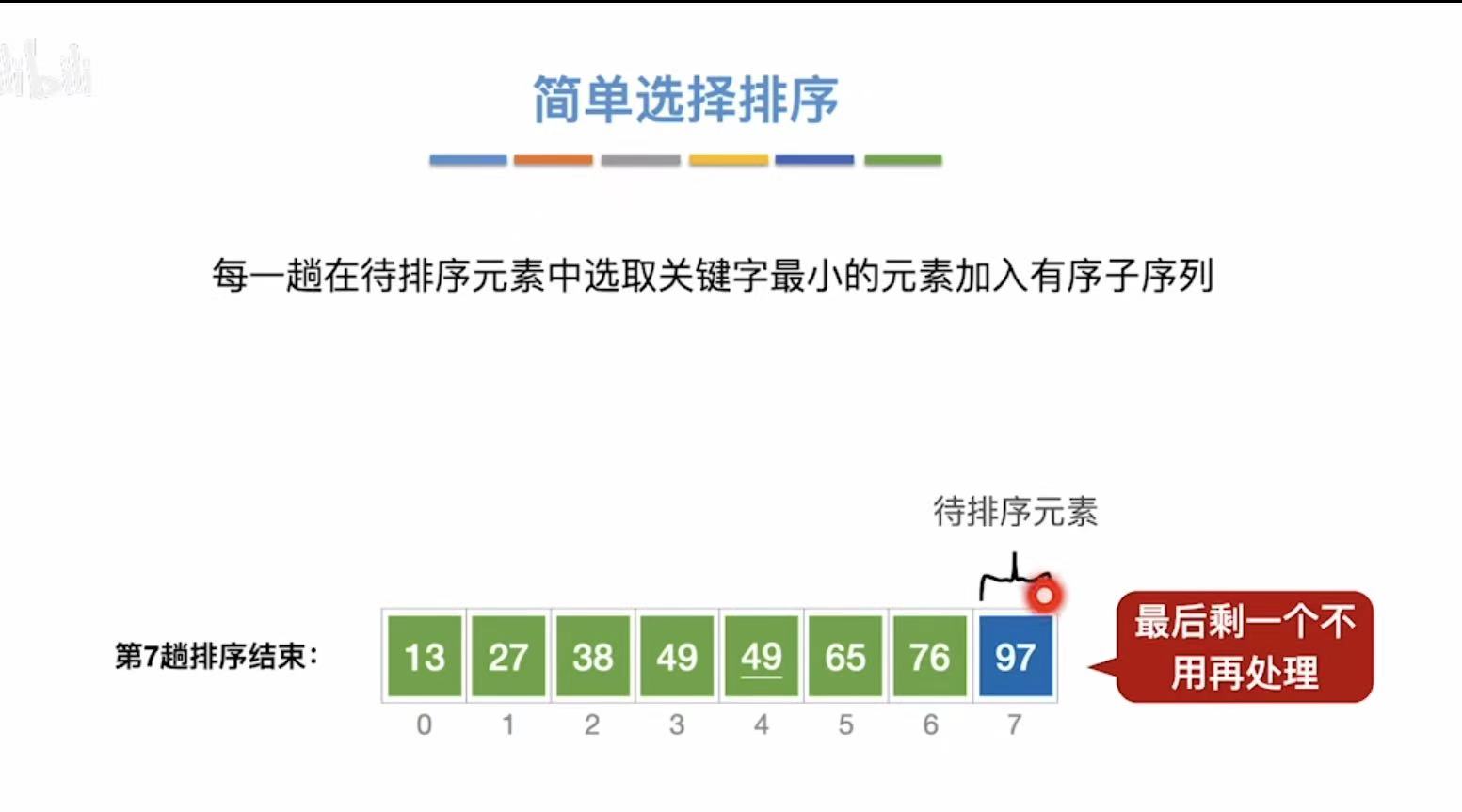
最终结果:
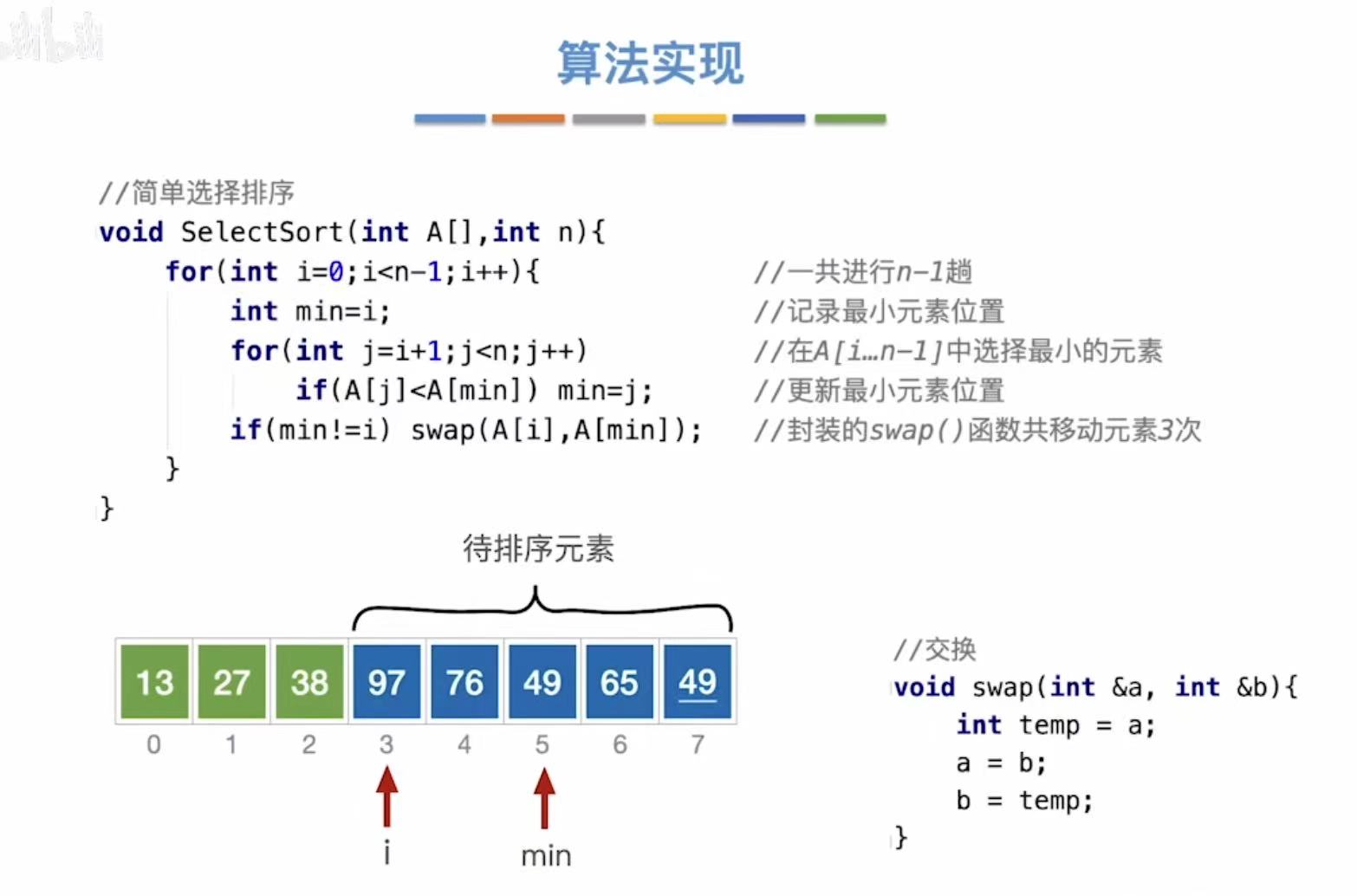
1.2 算法实现
简单选择排序:
java
// 简单选择排序:每次从未排序部分中选出最小元素,放到已排序部分末尾
void SelectSort(int A[], int n) {
// 外层循环:共进行 n-1 轮,每轮确定一个位置 i 的最小值
for (int i = 0; i < n - 1; i++) { // 一共进行 n-1 趟
// min 记录当前未排序部分中最小元素的下标(初始为 i)
int min = i;
// 内层循环:在 A[i+1] 到 A[n-1] 中寻找比 A[min] 更小的元素
for (int j = i + 1; j < n; j++) {
// 如果发现更小的元素,则更新 min 的位置
if (A[j] < A[min])
min = j;
}
// 如果最小元素不在当前位置 i,则交换 A[i] 和 A[min]
// 注意:只有当 min != i 时才需要交换(避免自交换)
if (min != i)
swap(A[i], A[min]); // 封装的 swap() 函数移动元素3次
}
}交换:
java
// 交换两个整数的值(通过引用传递)
void swap(int &a, int &b) {
int temp = a; // 用临时变量保存 a 的值
a = b; // 将 b 的值赋给 a
b = temp; // 将原 a 的值赋给 b
}
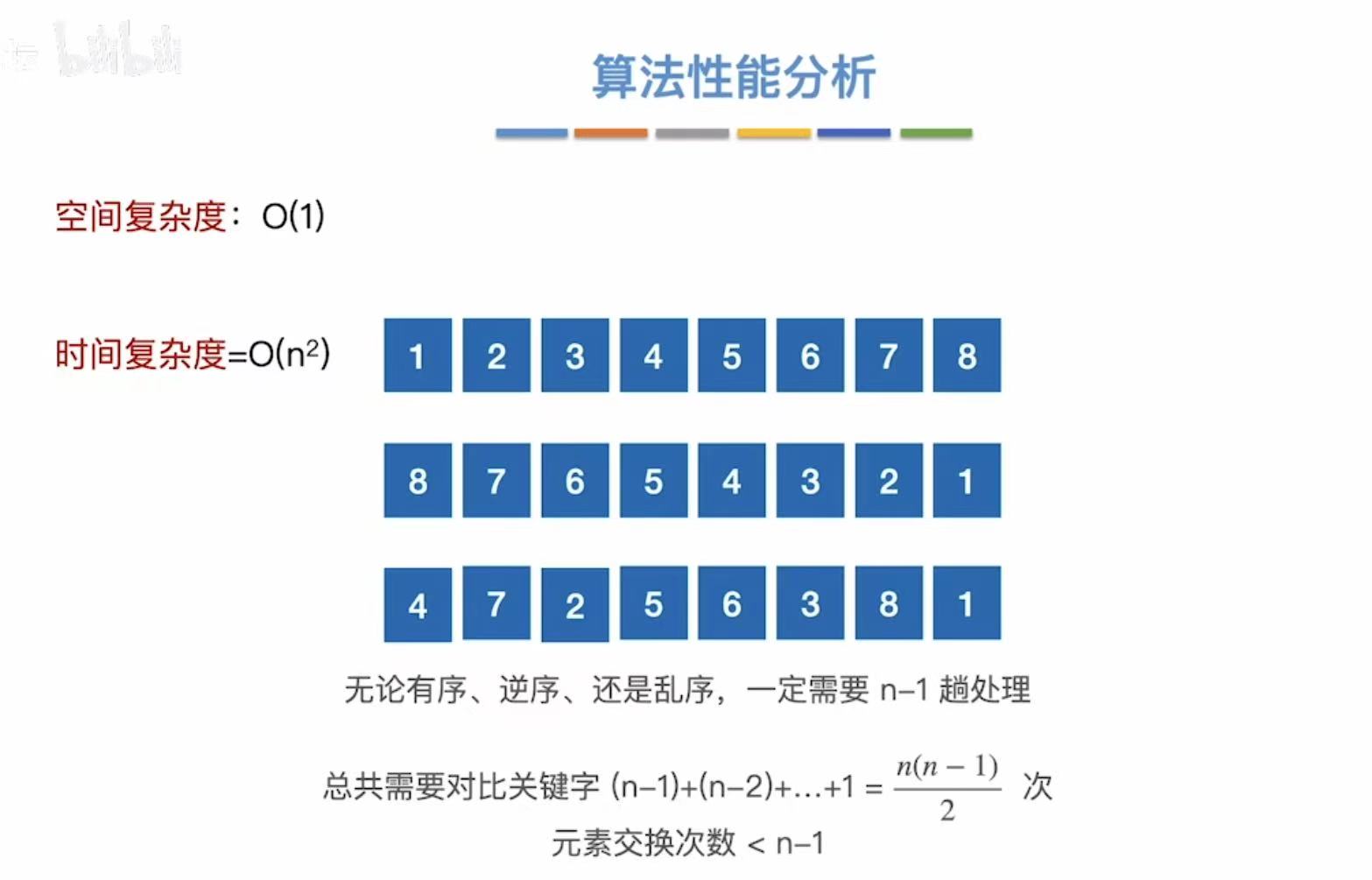
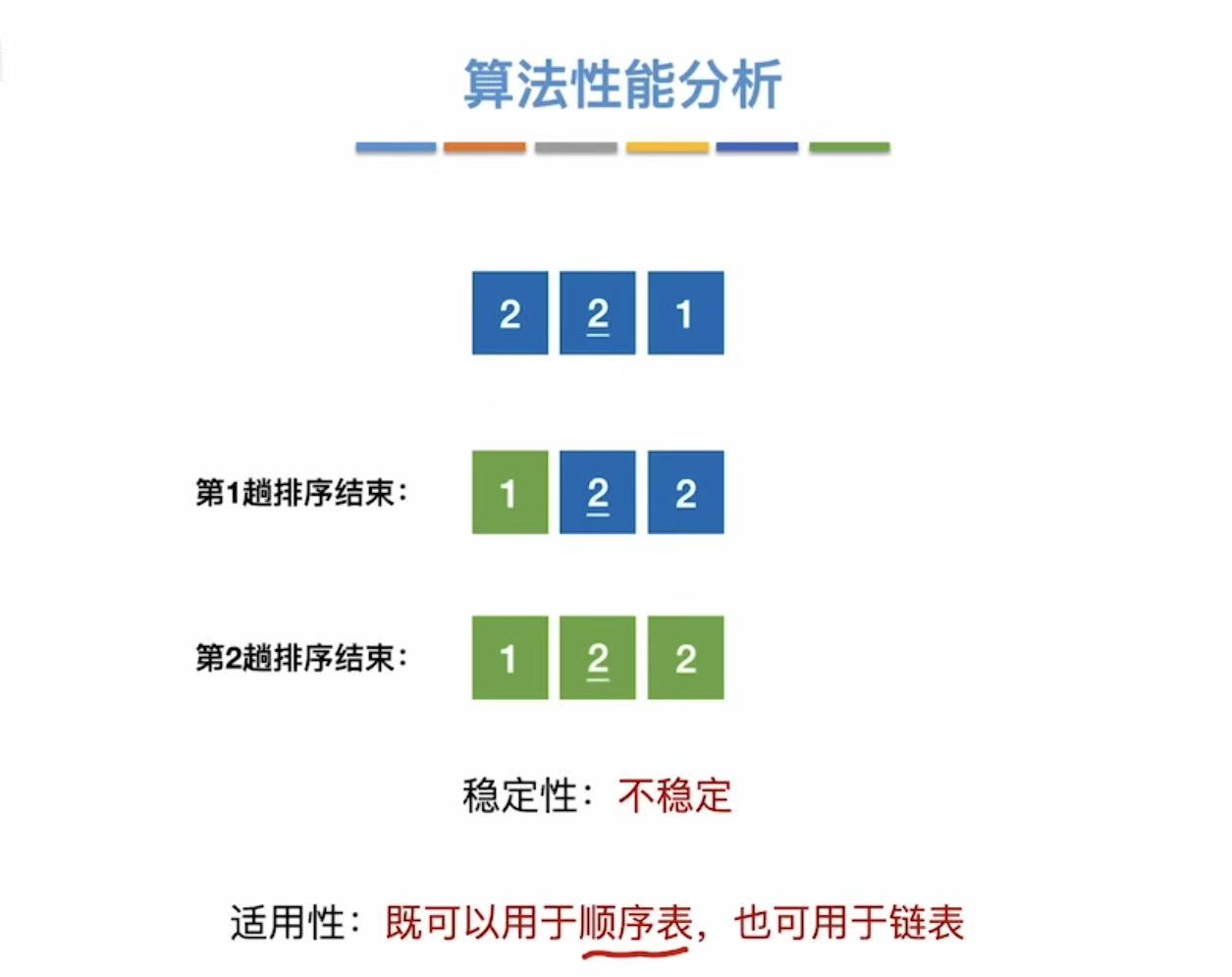
1.3 算法性能分析
结论:
- 空间复杂度:O(1)
- 时间复杂度:O(n2)
- 不稳定
1.4 小结
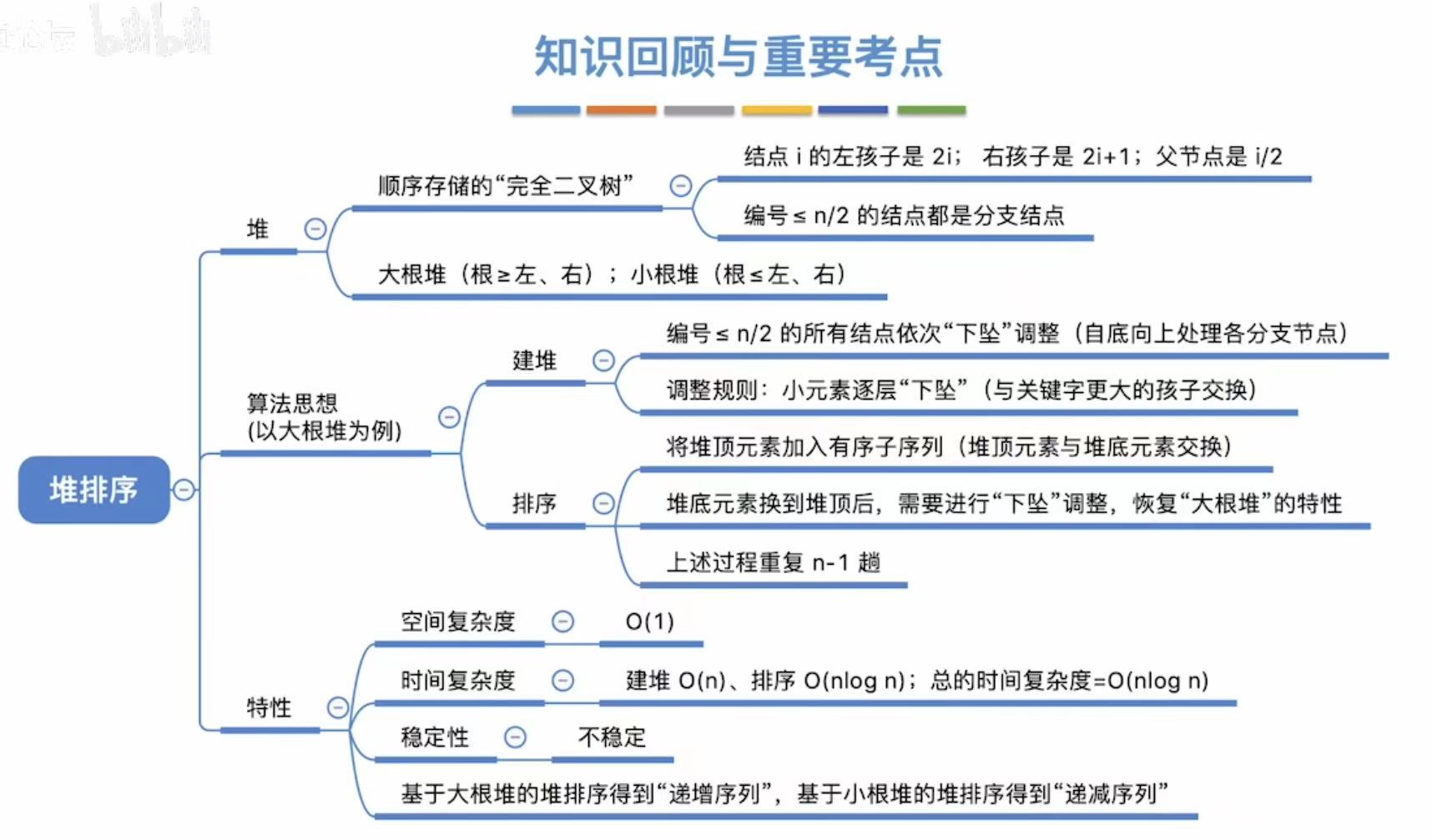
2. 堆排序
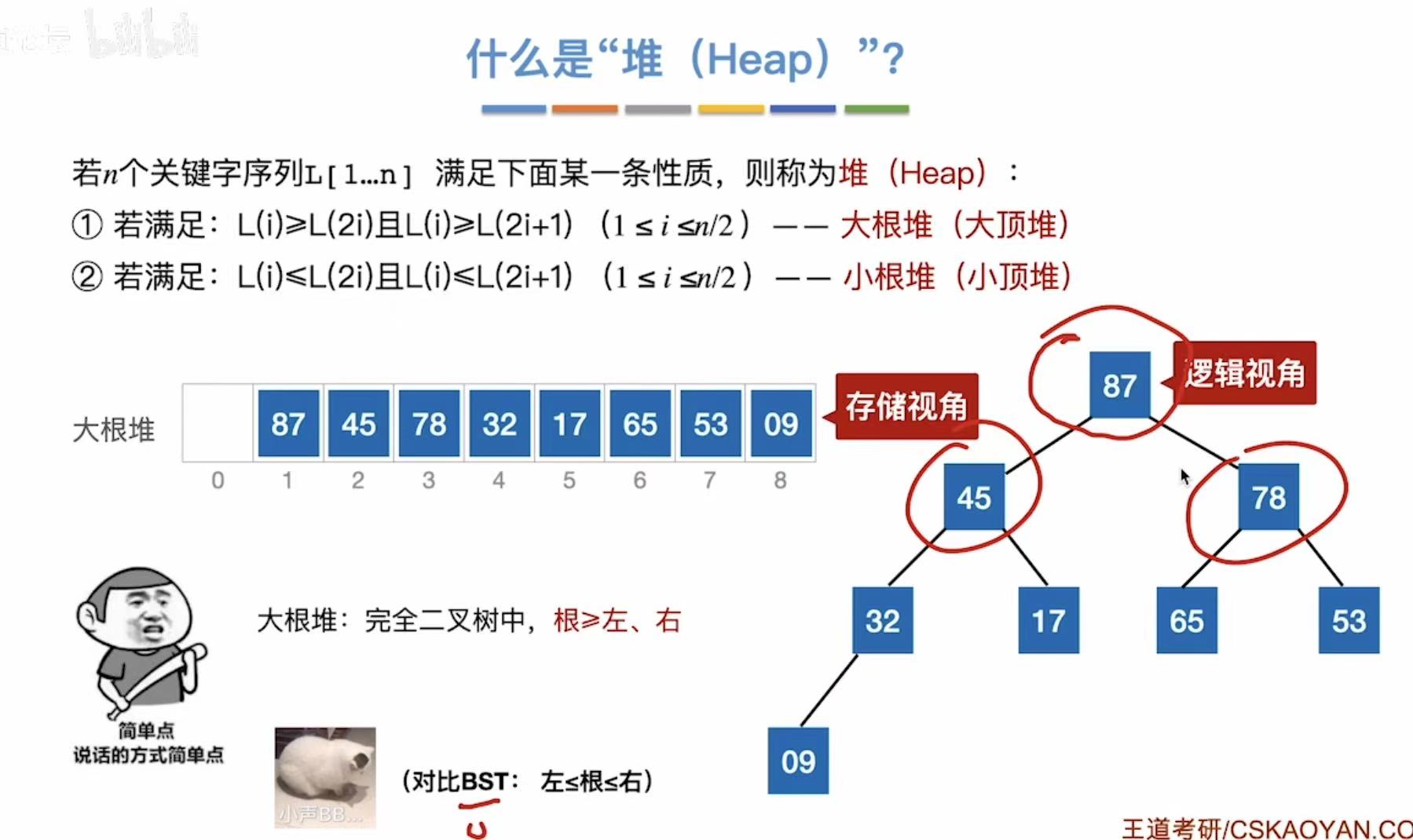
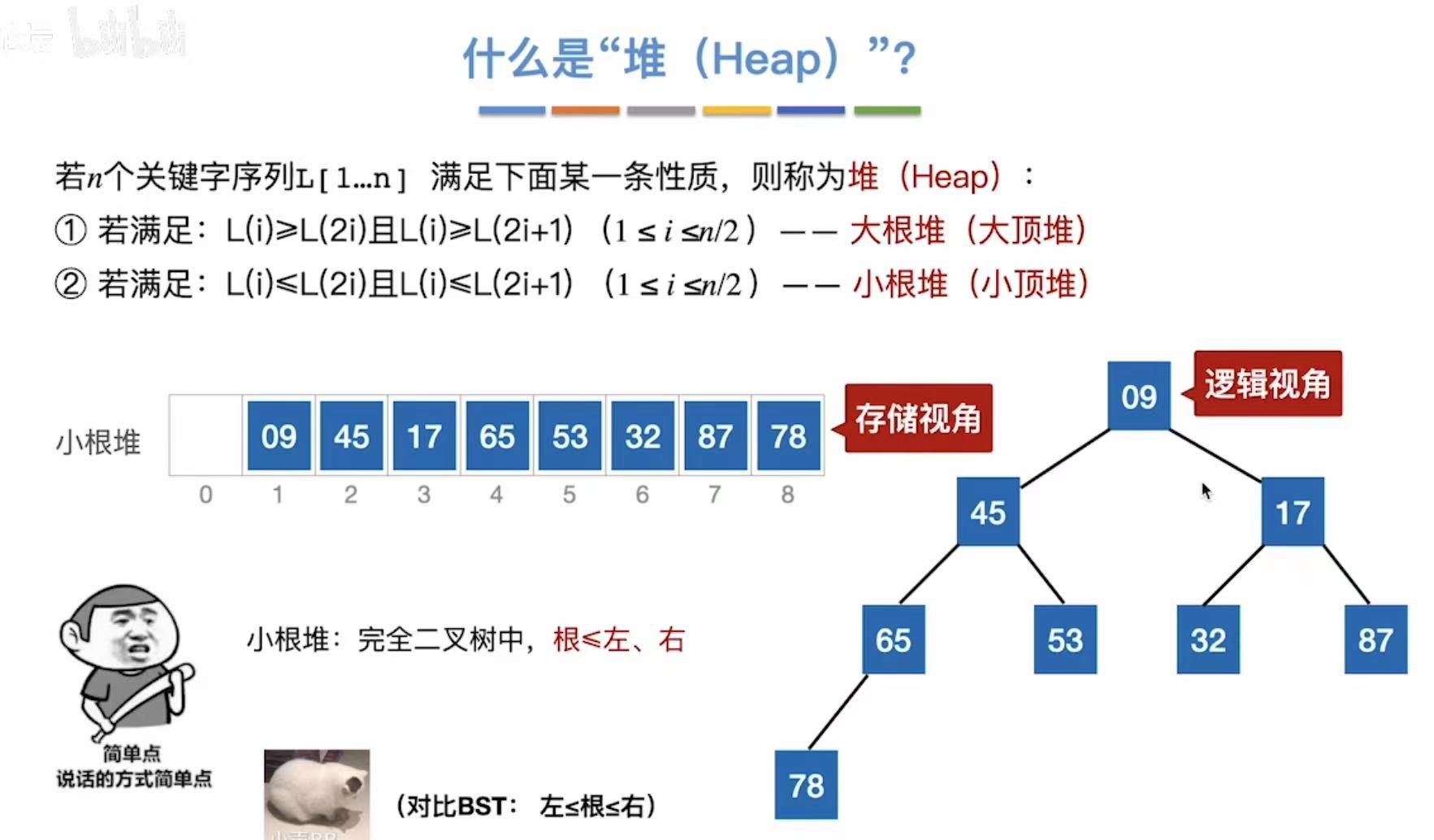
2.1 什么是堆?
堆分为大根堆和小根堆。
- 大根堆:根>左、右
- 小根堆 :根<左、右

大根堆如图所示: - 87>45、78
- 45>32、17;78>65、53;
- 32>09
小根堆如图所示: - 09<45、12
- 45<65、53;17<32、87;
- 65<78
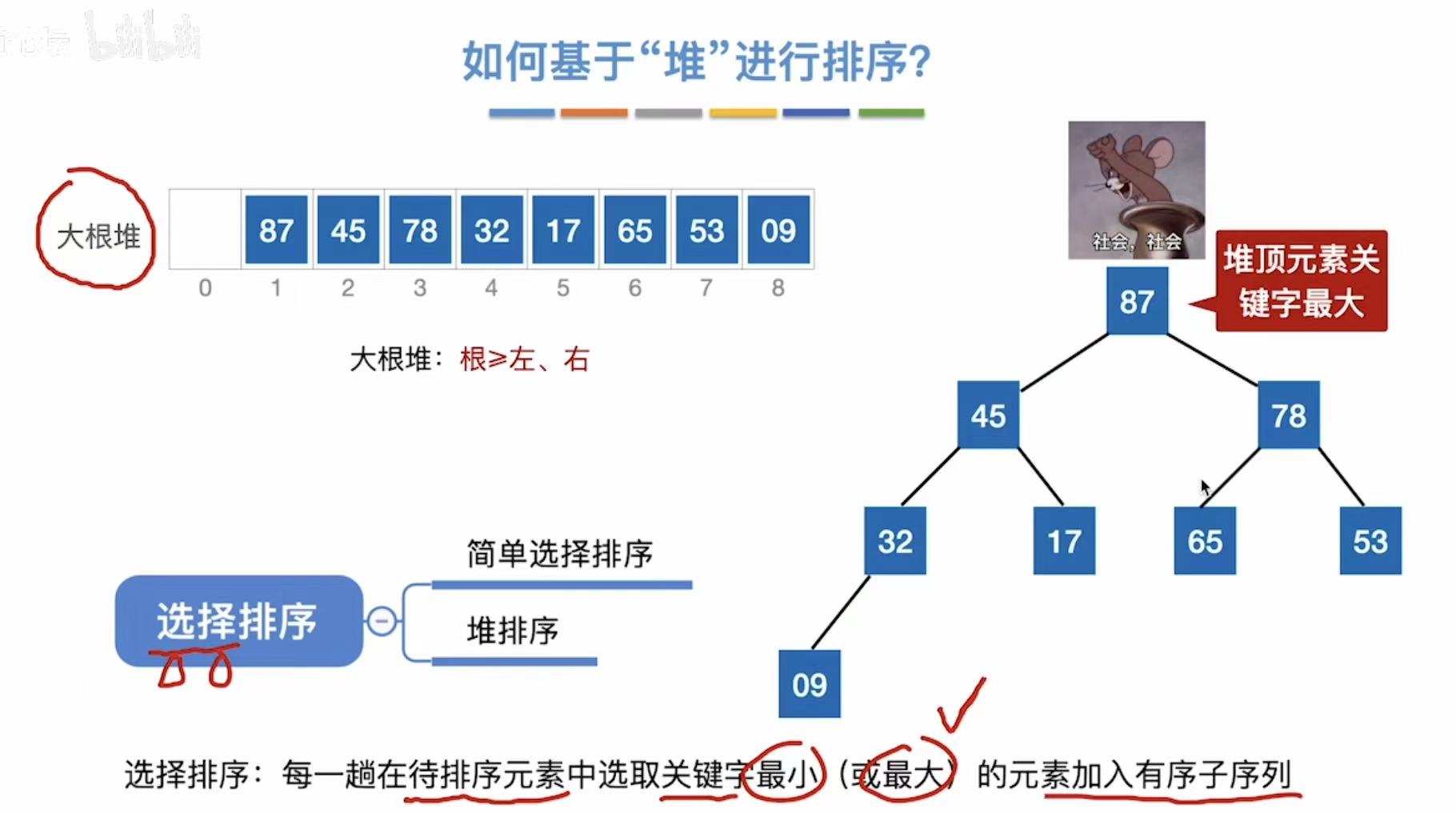
2.2 如何基于堆进行排序?
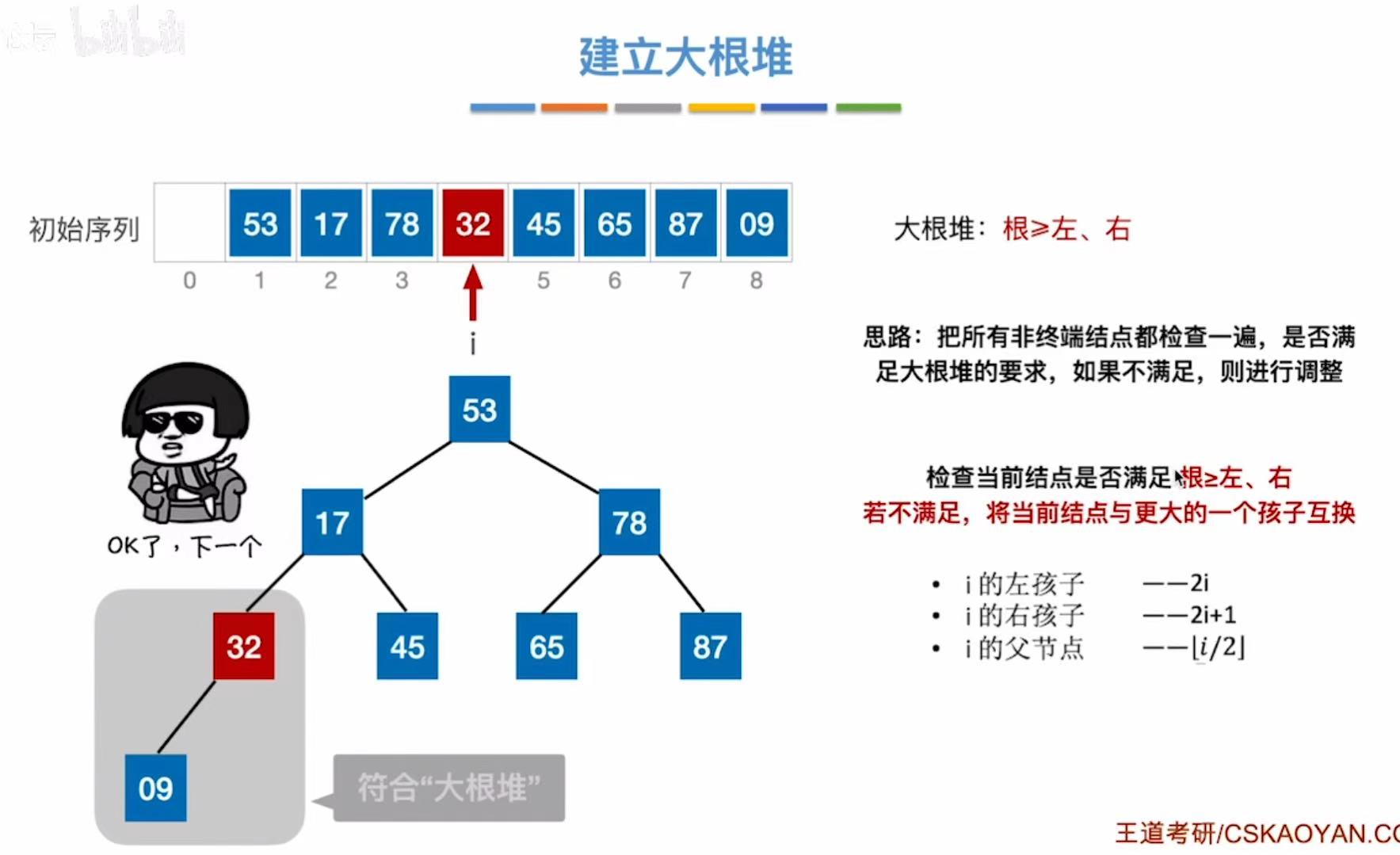
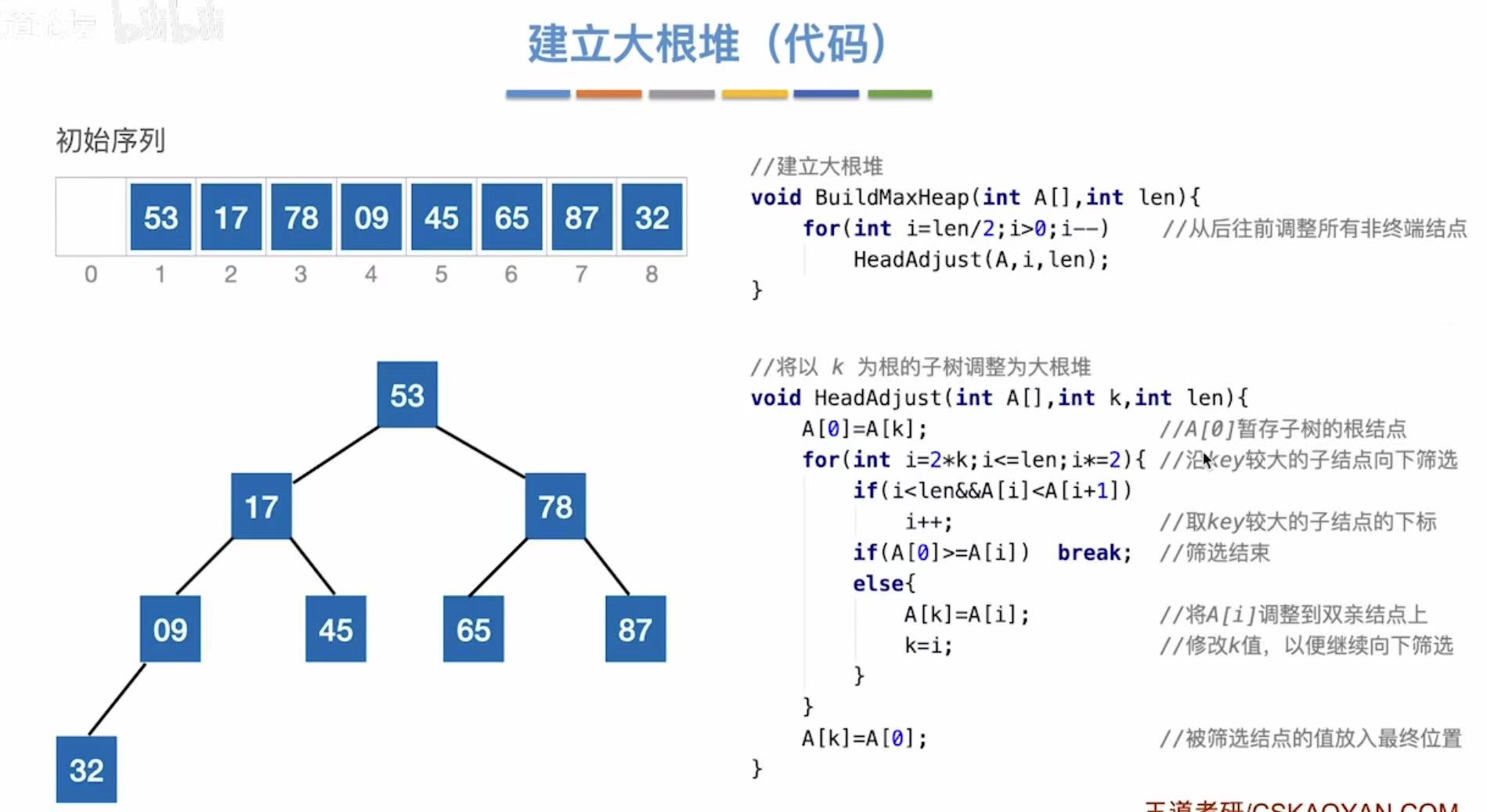
2.2.1 建立大根堆
未排序的序列-->二叉树的形式:
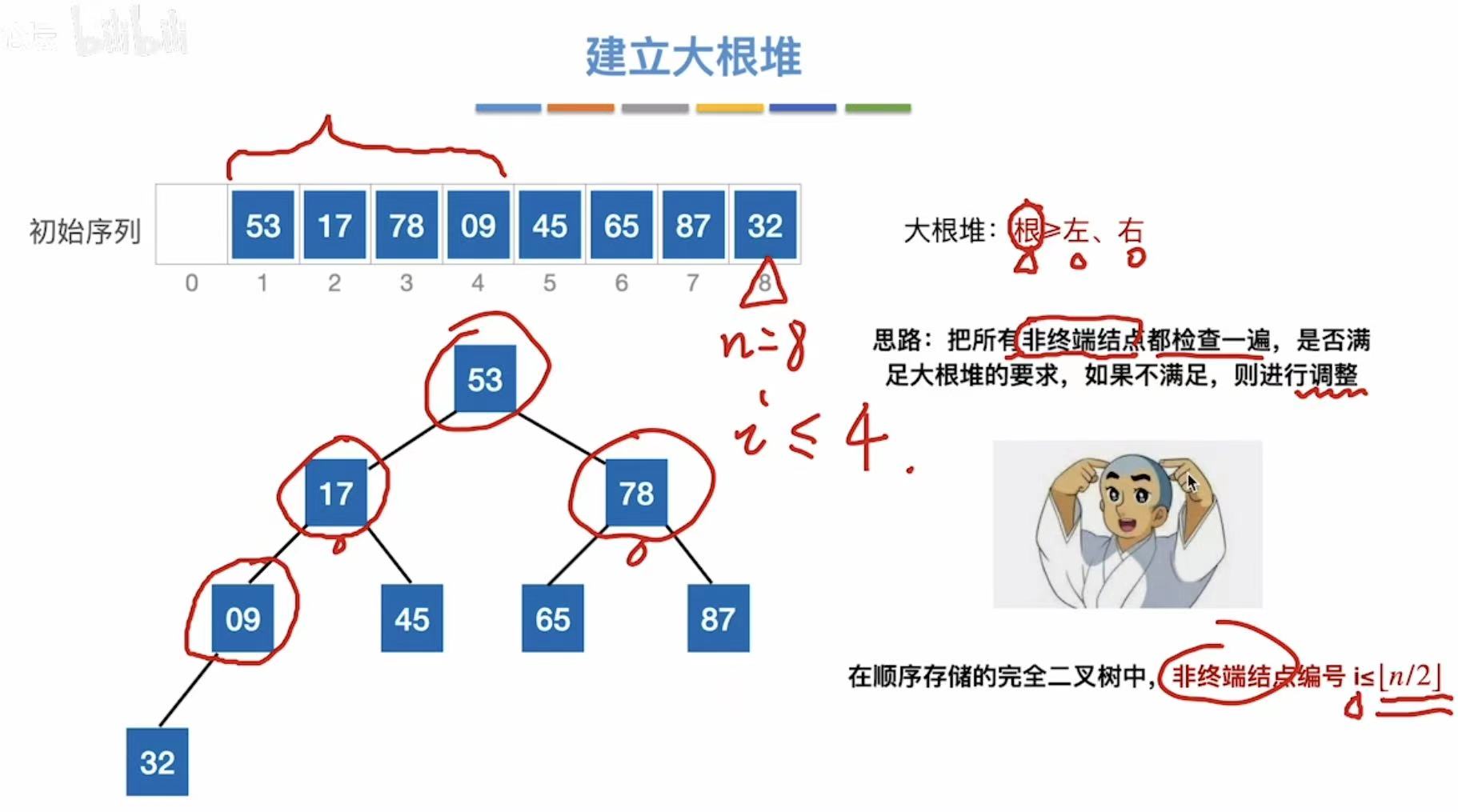
普通二叉树-->大根堆:
初始序列从后往前:
- 32、87、65、45都是终端结点,不用检查
- i指向09,检查09是否满足根>左、右-->09<32、不满足
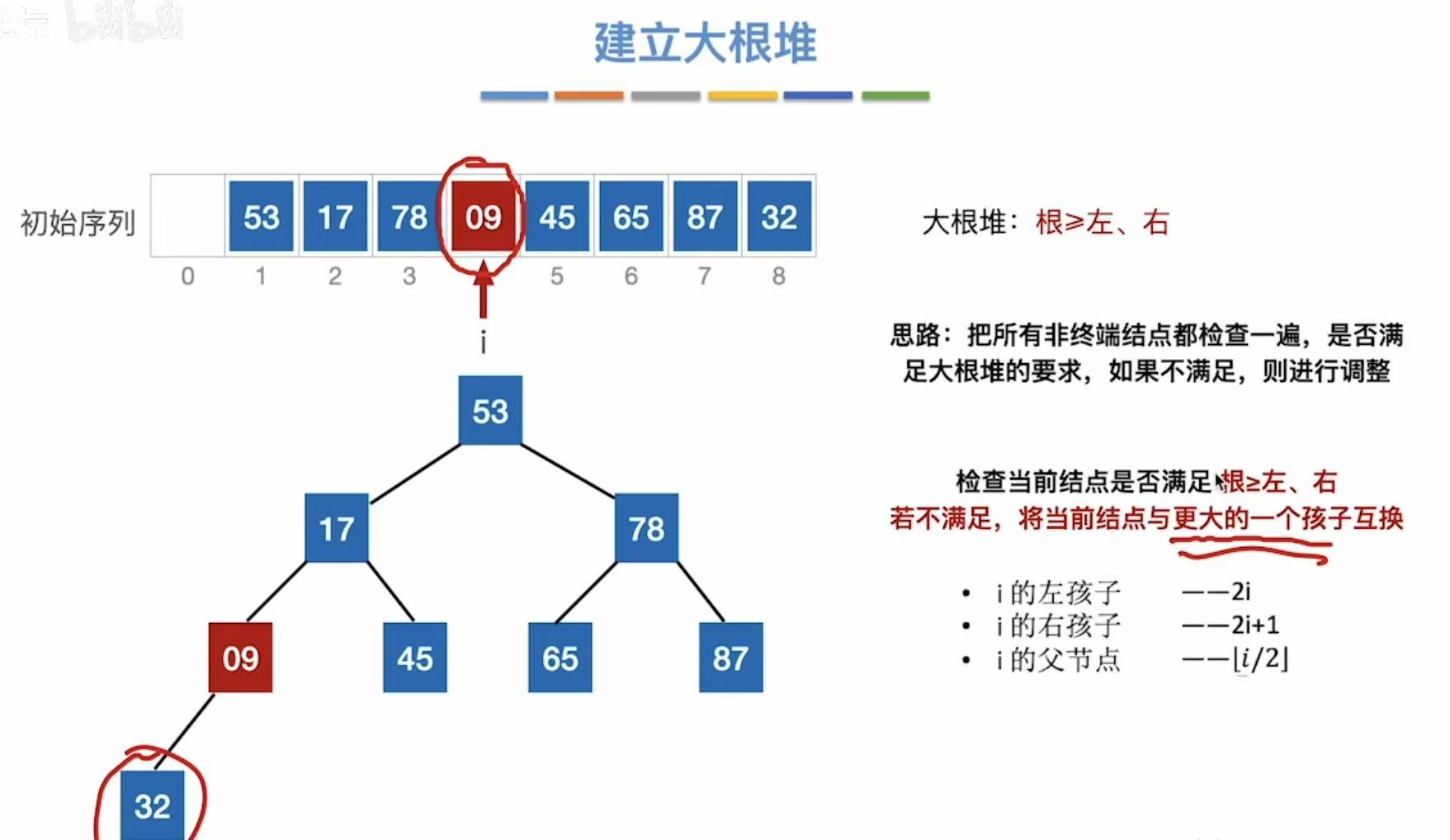
- 不满足,互换
- 所以现在i指向32,i--,指向78
- 78<87,不满足,互换(换为根左右三个数中最大的那个)
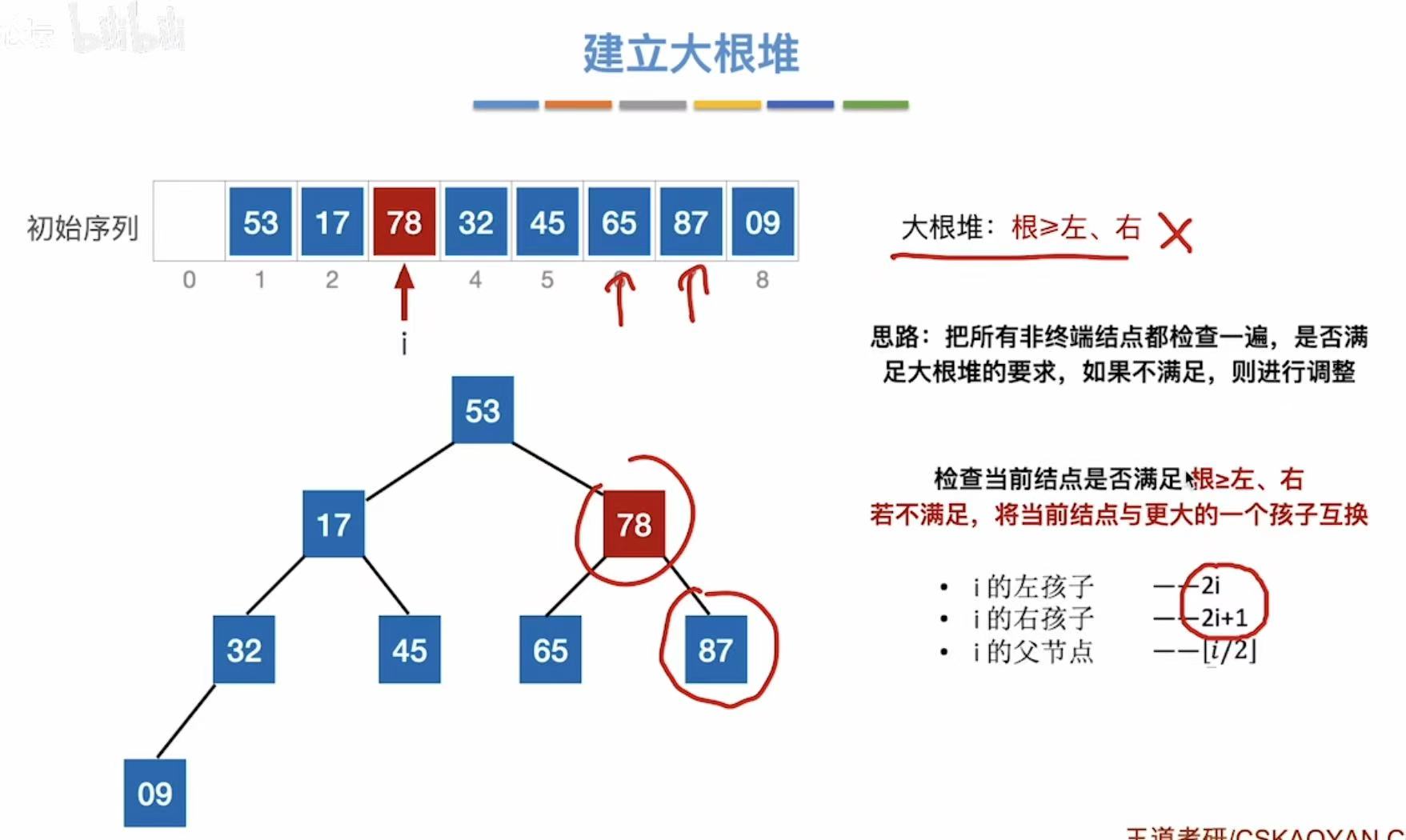
图略的两个阶段: - 所以现在i指向87,i--,指向17
- 17<45,不满足,互换(换为根左右三个数中最大的那个)
- 所以现在i指向45,i--,指向53
- 53<87,不满足,互换(换为根左右三个数中最大的那个)
- 所以现在i指向87,i--,指向位置0
这个时候如图,我们就能看出来53和87互换之后,53的分支又不满足大根堆的特性了:
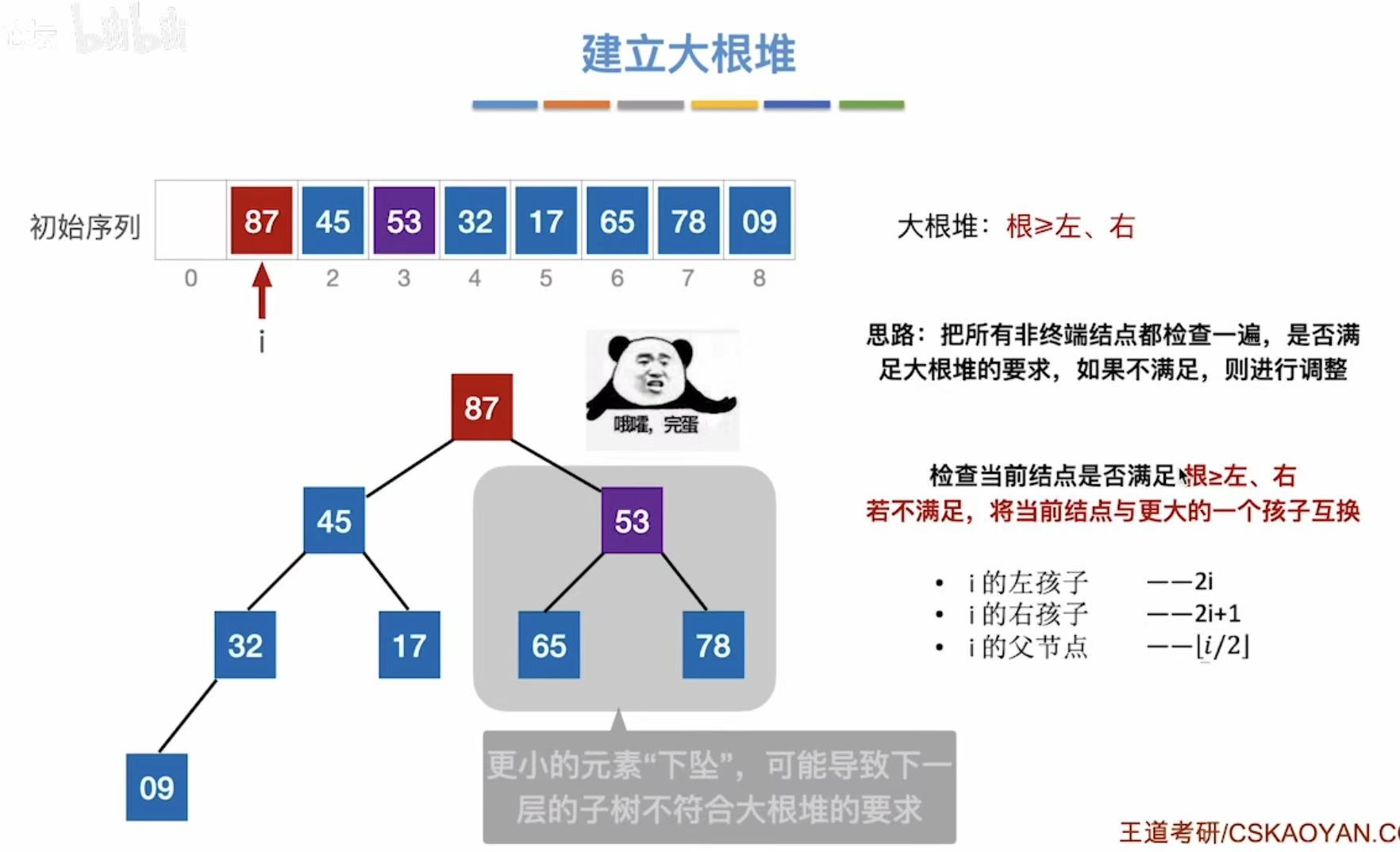
我们就需要将53下坠,以符合大根堆的要求:
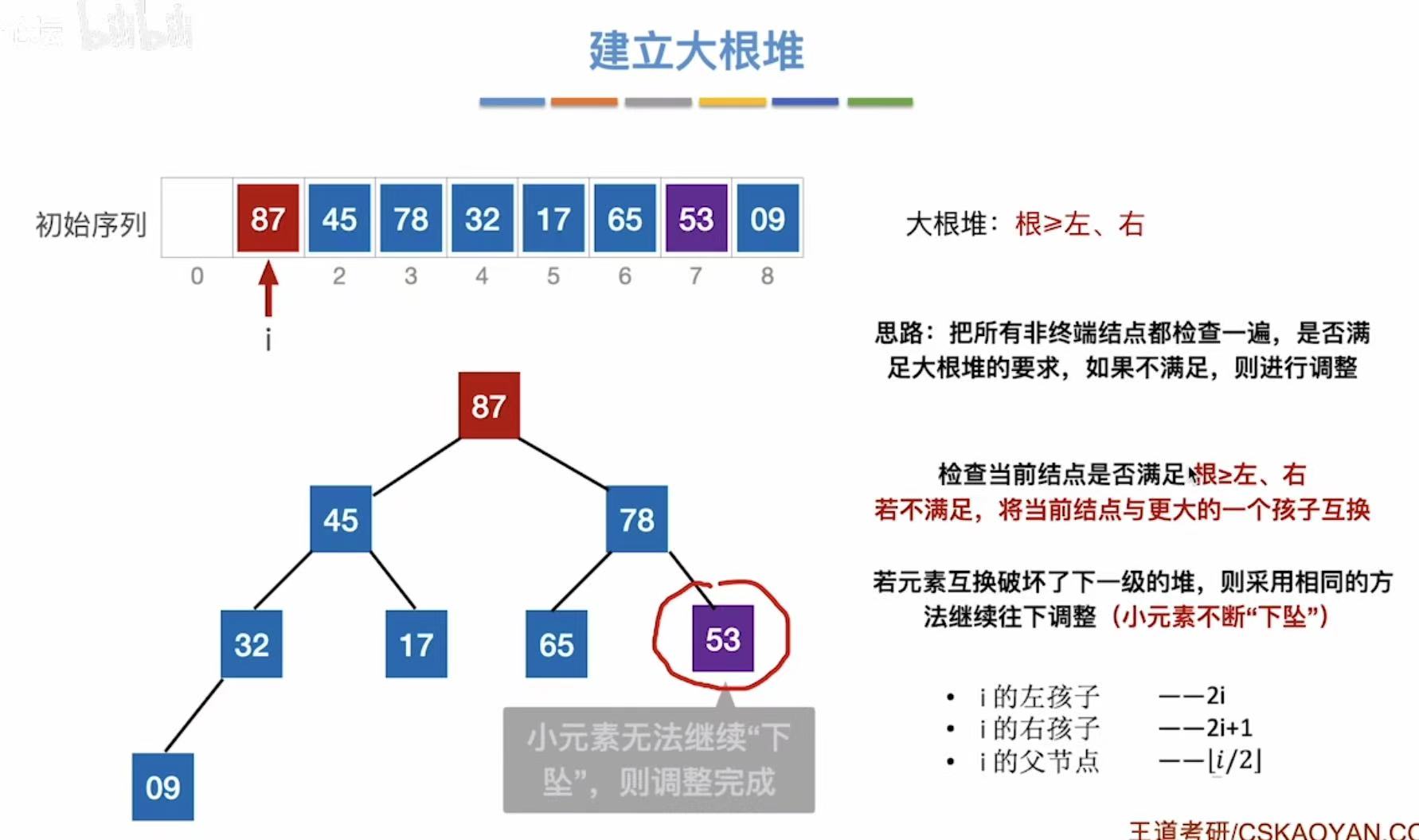
整体过程:
| 调整节点 (i) | 节点值 | 操作 | 数组状态 |
|---|---|---|---|
| 3 | 09 | 与 32 交换 | [53, 17, 78, 32, 45, 65, 87, 09] |
| 2 | 78 | 与 87 交换 | [53, 17, 87, 32, 45, 65, 78, 09] |
| 1 | 17 | 与 45 交换 | [53, 45, 87, 32, 17, 65, 78, 09] |
| 0 | 53 | 与 87 交换 → 再与 78 交换 | [87, 45, 78, 32, 17, 65, 53, 09] |
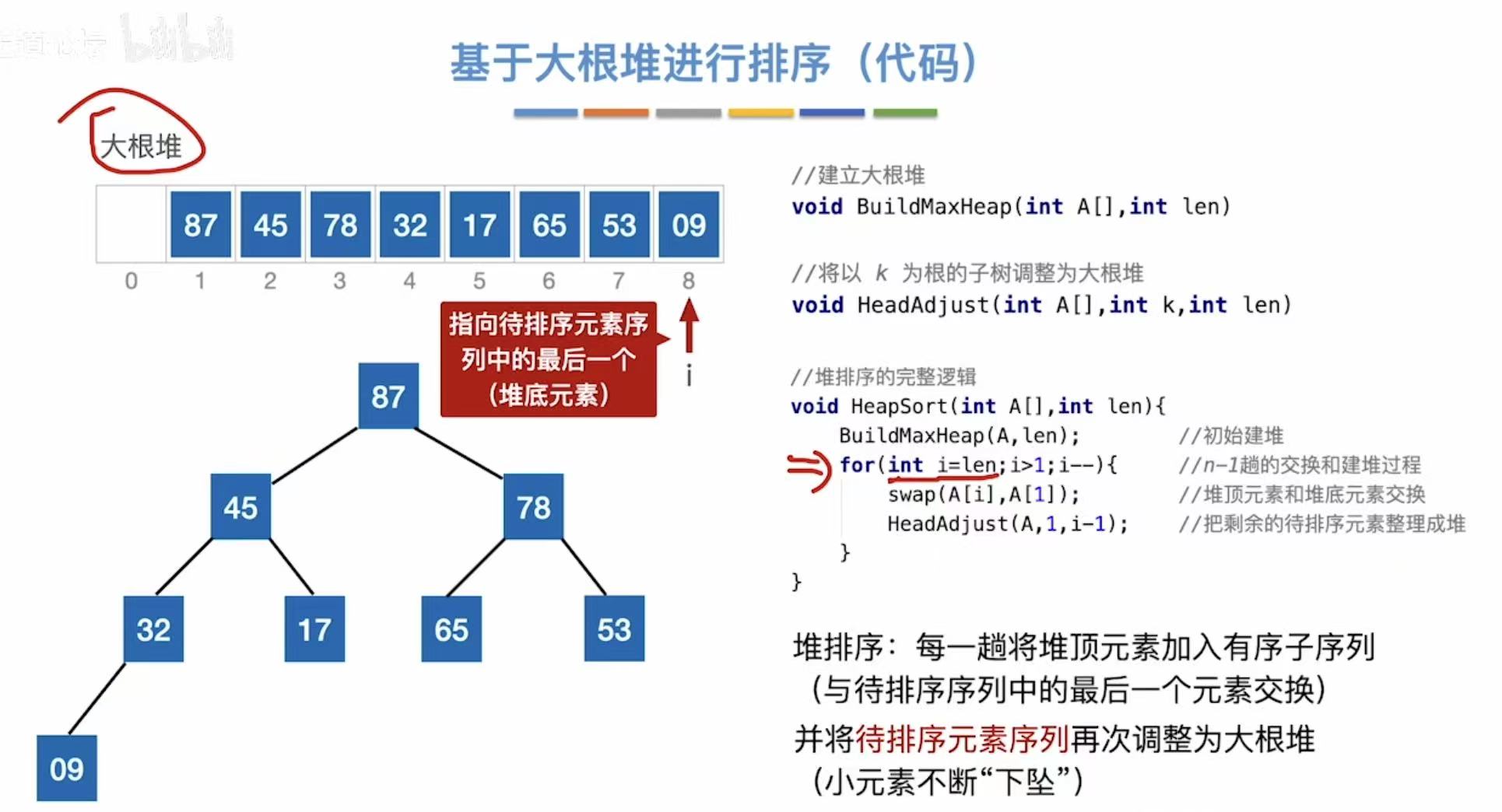
2.2.2 建立大根堆(代码)
建立大根堆:
java
// 建立大根堆:将数组 A[0..len-1] 构造成一个最大堆
void BuildMaxHeap(int A[], int len) {
// 从最后一个非叶子节点开始,倒序遍历到根节点(索引 0)
// 非叶子节点的下标范围是 [len/2 - 1, 0]
for (int i = len / 2; i >= 0; i--) {
// 对以 A[i] 为根的子树进行向下调整(heapify),使其成为大根堆
HeadAdjust(A, i, len);
}
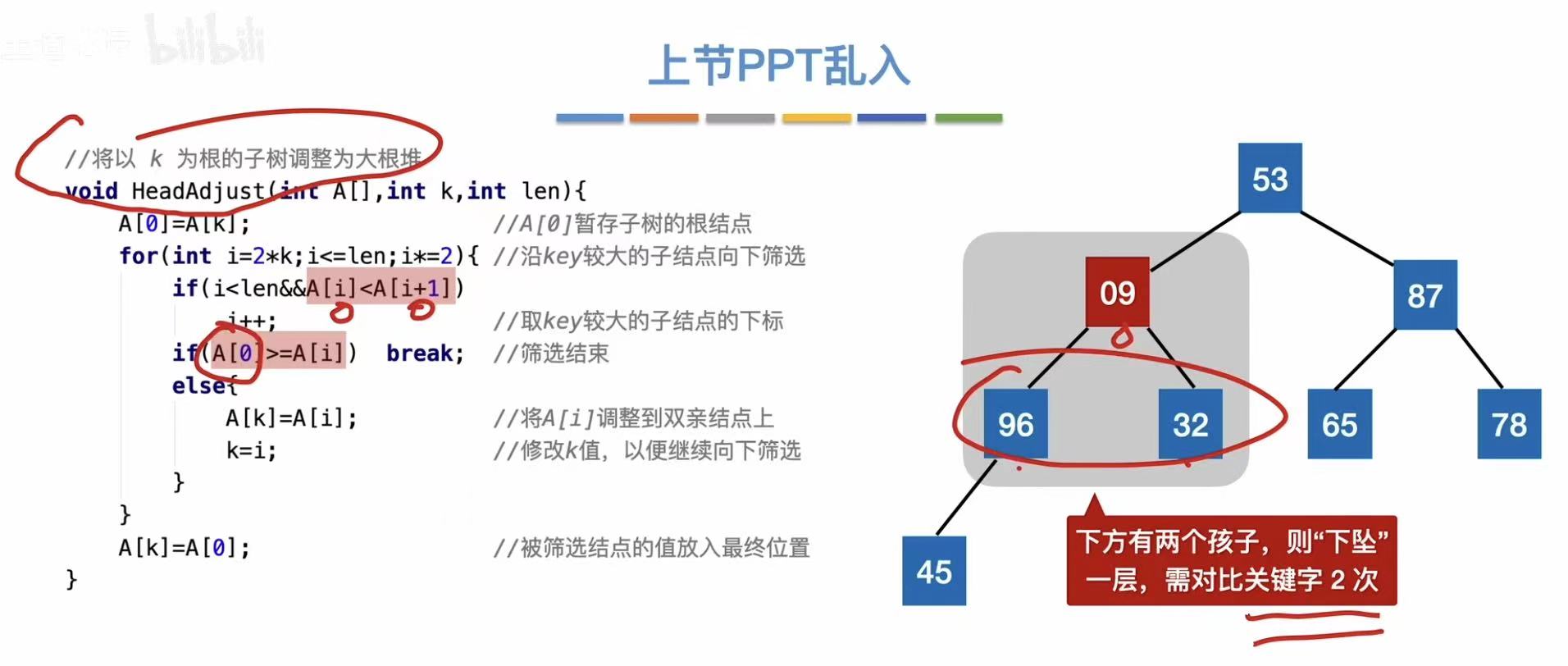
}调整大根堆:
java
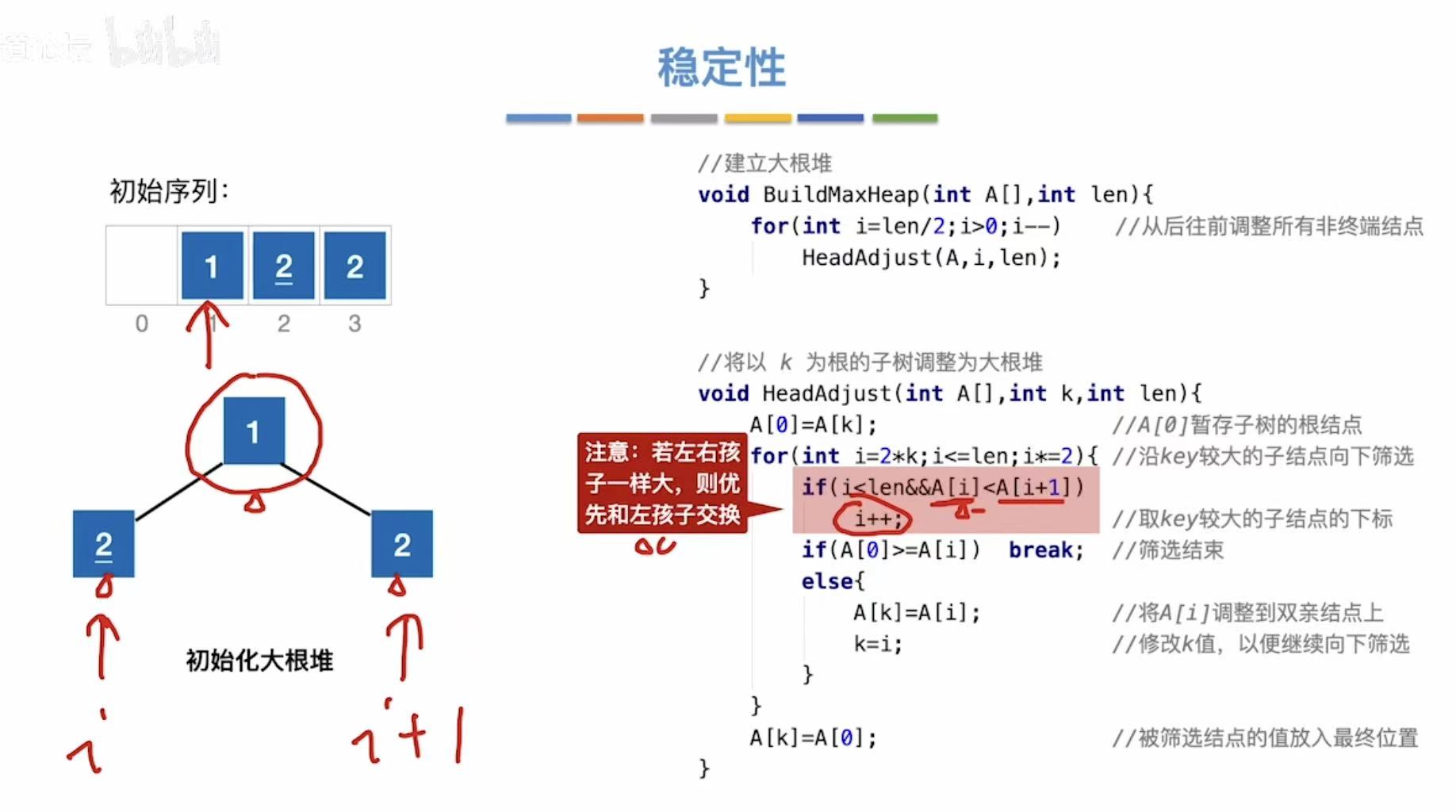
// 向下调整函数:将以 k 为根的子树调整为大根堆
void HeadAdjust(int A[], int k, int len) {
// 将当前根节点的值暂存到 A[0],便于后续比较和交换
A[0] = A[k]; // A[0] 是临时存储单元,不是哨兵
// 循环条件:i <= len-1 且 A[i] < A[i+1],即找到较大的孩子
// 从左孩子开始(2*k+1),每次取较大的孩子
for (int i = 2 * k + 1; i <= len - 1; i += 2) {
// 如果右孩子存在且比左孩子大,则指向右孩子
if (i < len - 1 && A[i] < A[i + 1]) {
i++; // 指向较大的孩子
}
// 如果当前较大的孩子大于 A[0](即原根节点),则继续向下筛选
if (A[i] > A[0]) {
A[k] = A[i]; // 将较大孩子上移
k = i; // 更新 k 为较大孩子的下标,继续向下筛选
} else {
// 如果没有更大的孩子,说明已找到最终位置,结束循环
break;
}
}
// 将原来保存在 A[0] 的值放到正确的位置(即 k 所指位置)
A[k] = A[0];
}
2.2.3 基于大根堆进行排序
逻辑:根节点最大-->移到最后-->其余保持大根堆性质-->根节点最大-->...(重复)
因为大根堆的特质,我们知道根节点是整个树中最大的数,所以直接把他移动到最后(位置8)
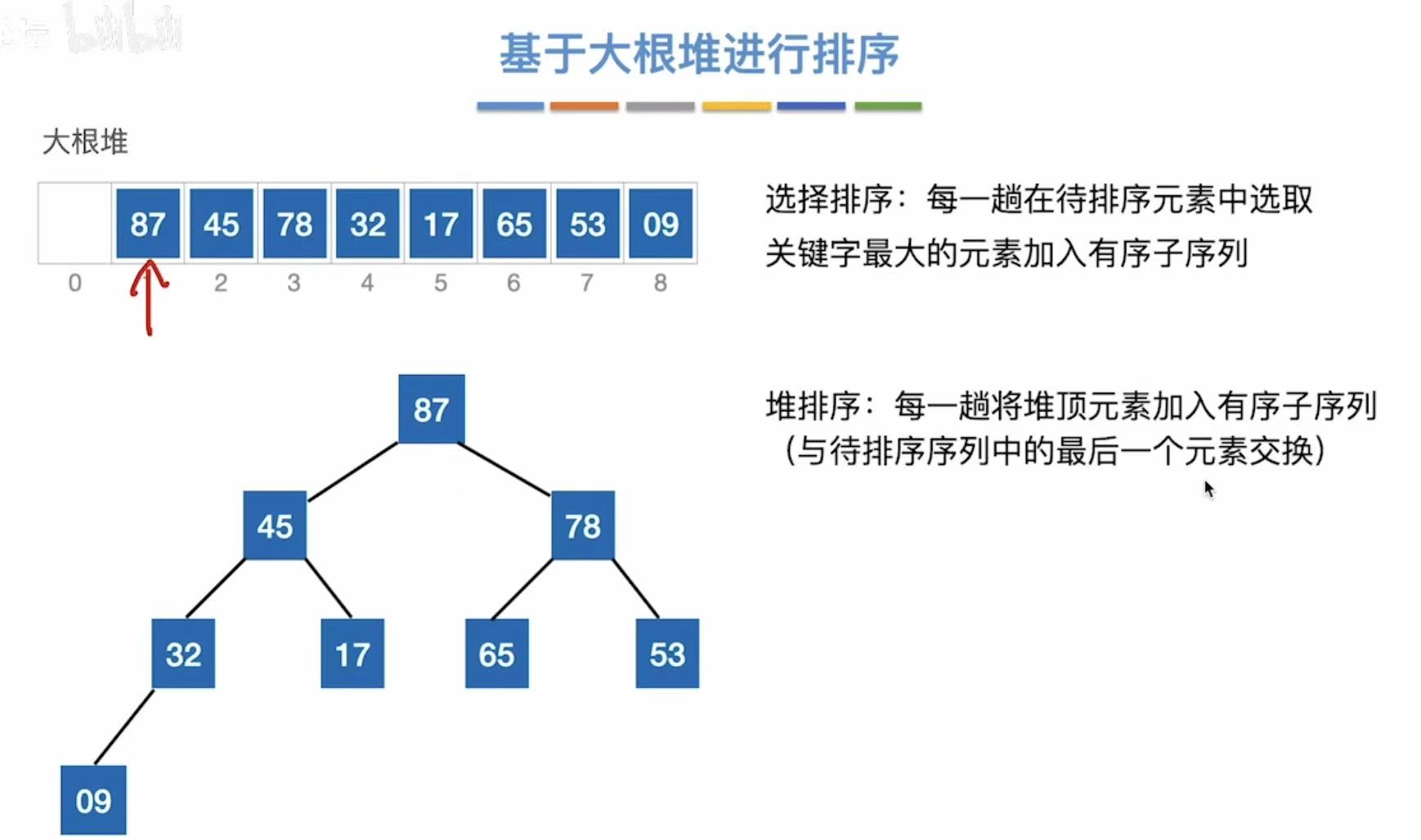
就算把最大的数移走了,整个数还是必须保持大根堆的特性,所以就算小数成为了根结点,也必须不断下坠,把位置让出来给当前最大的数:如图,09又不断下坠,将位置让给了78
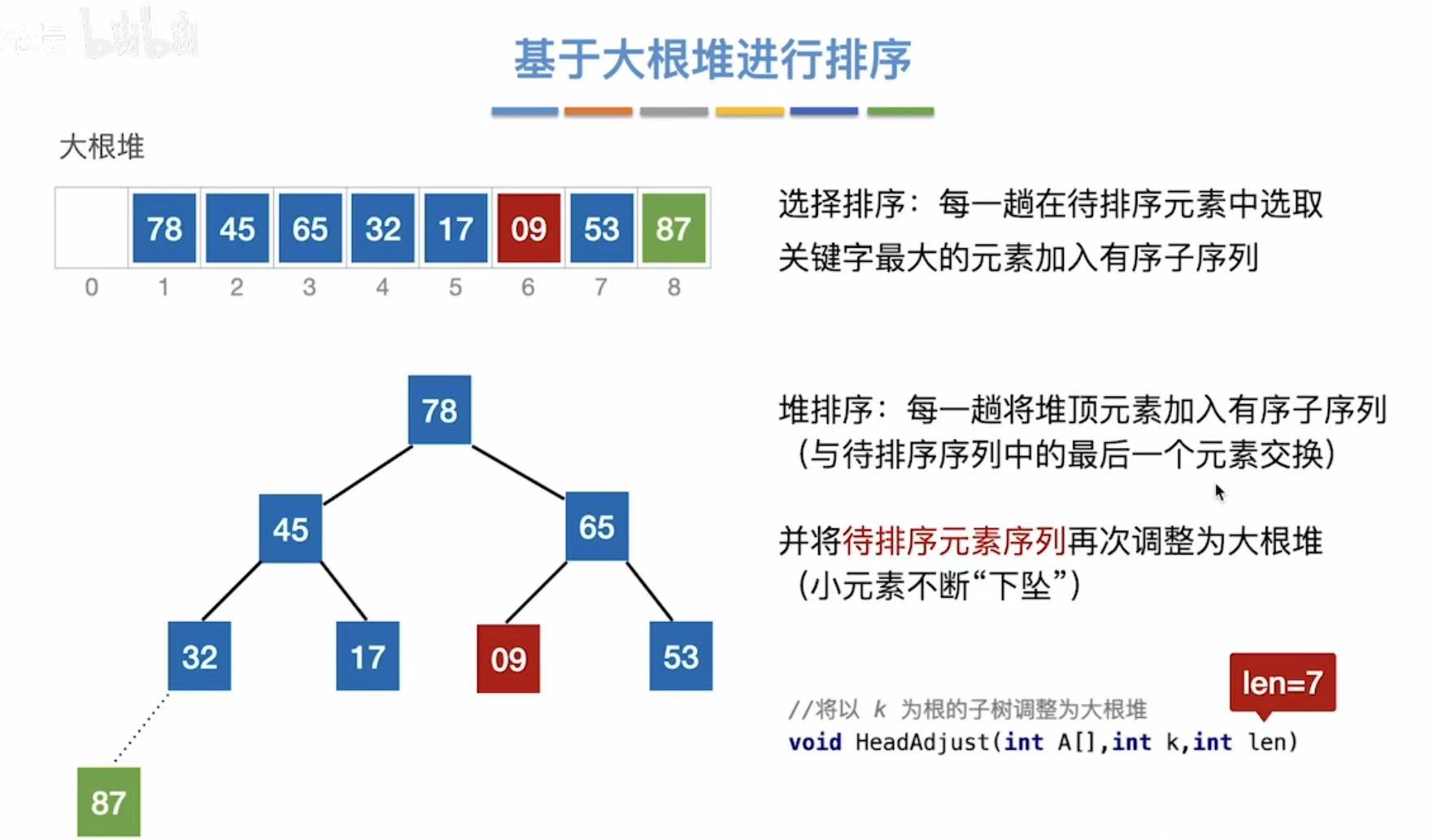
重蹈覆辙,根节点就是最大的,所以78也移到最后面:
虚线就证明完成排列了,以后不用考虑这个数了
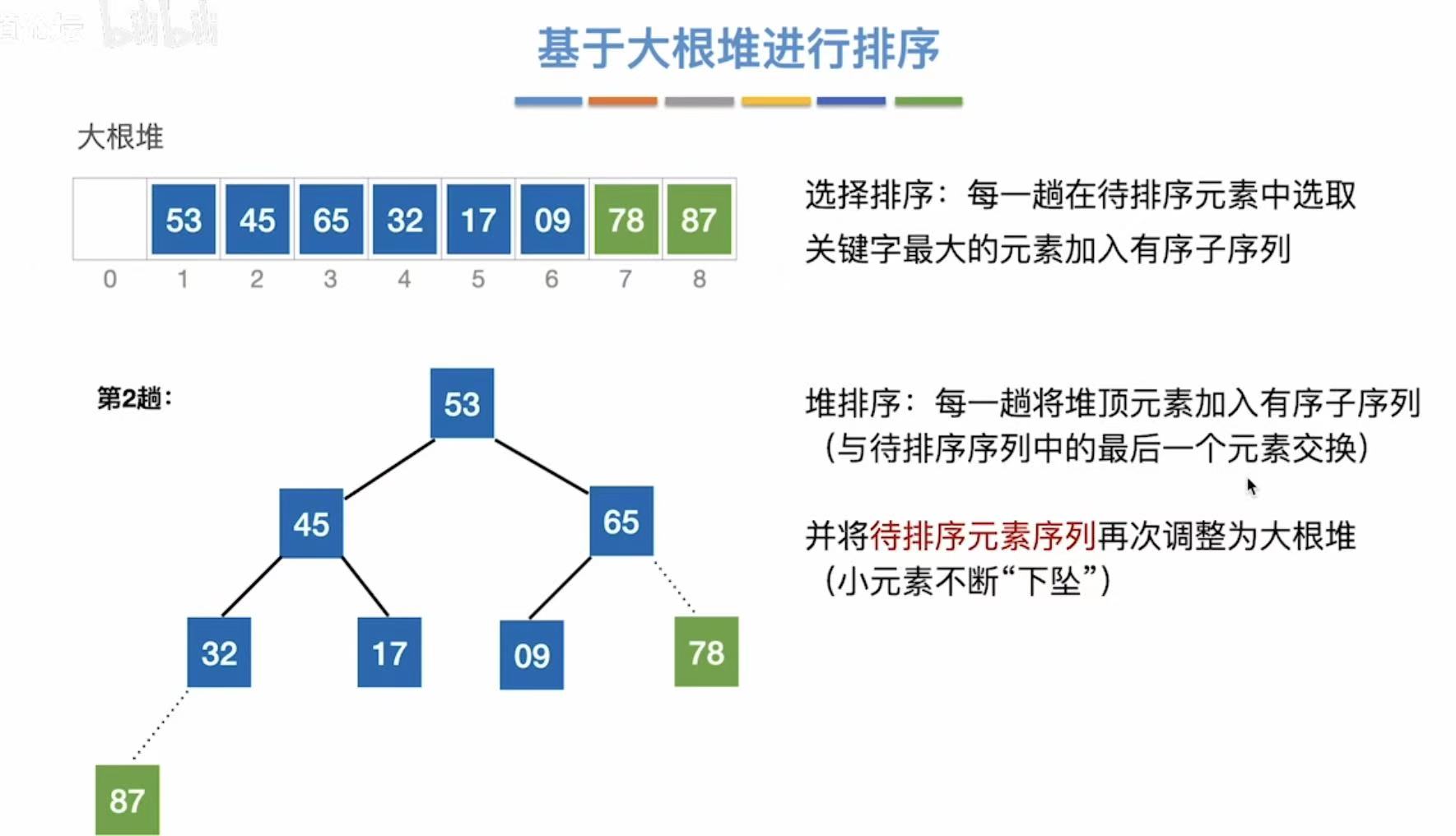
53登顶变为根结点,但是又必须下坠把位置让给当前最大的数:65
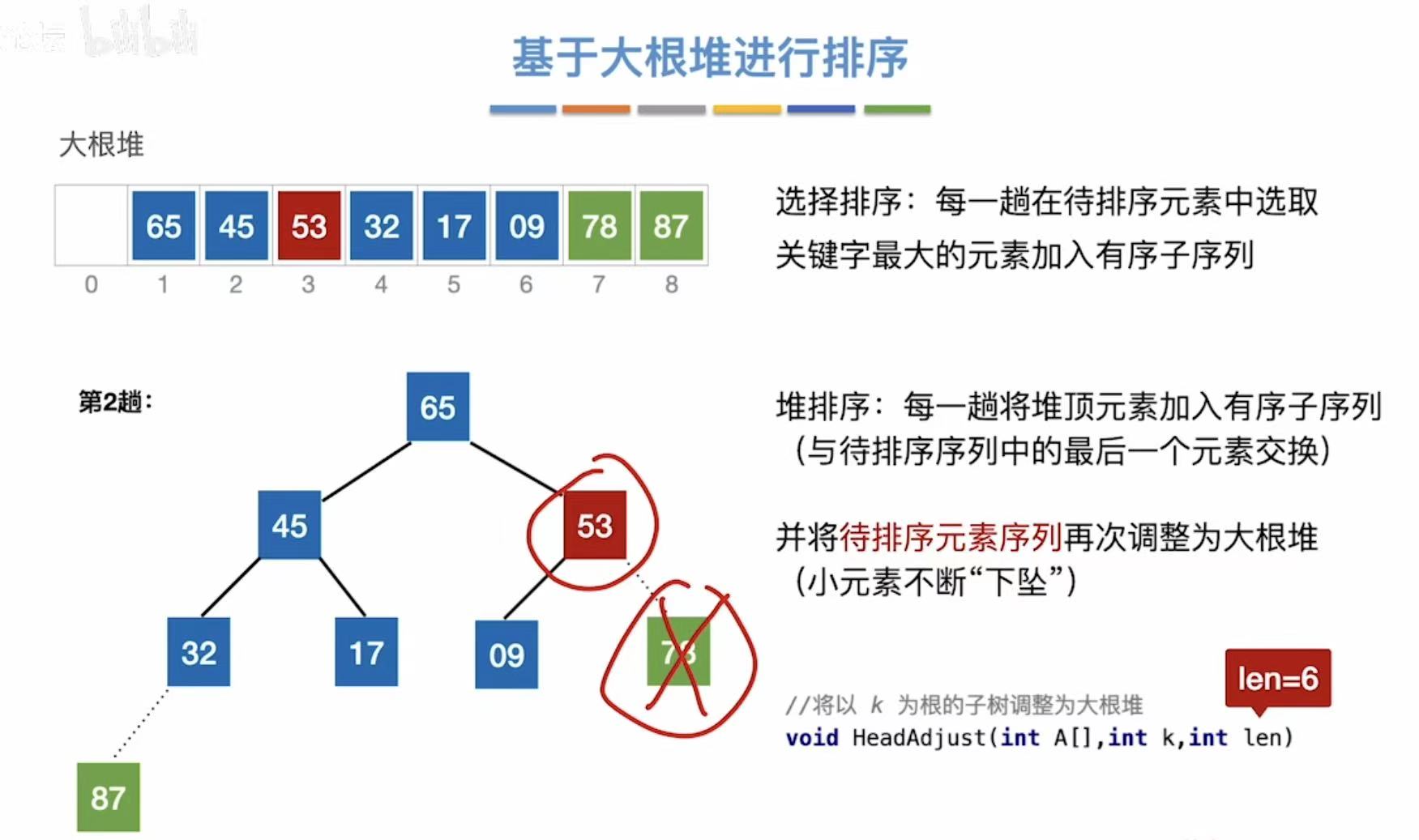
也就是除去排序结束的数字,其余必须仍旧保持大根堆的性质:
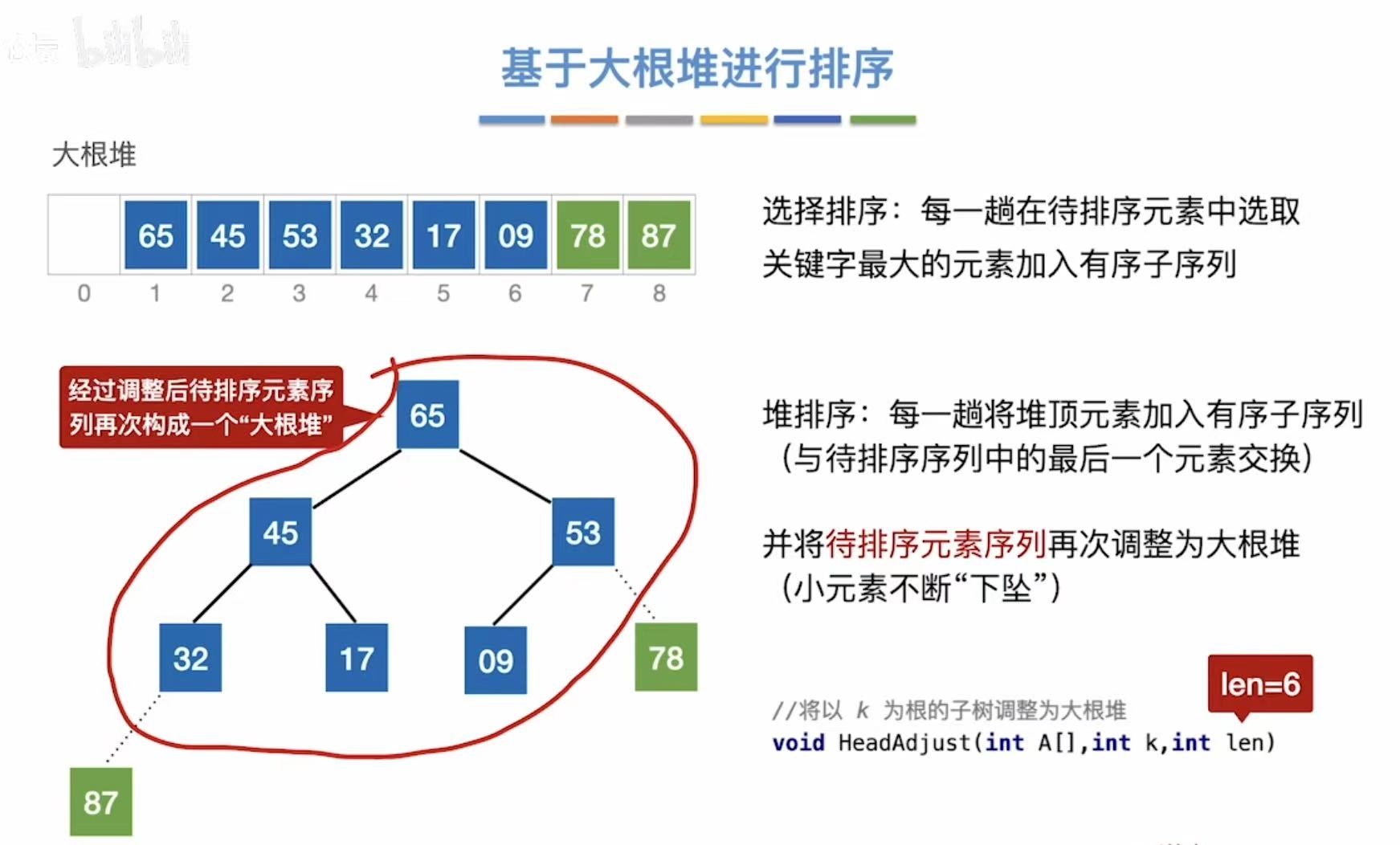
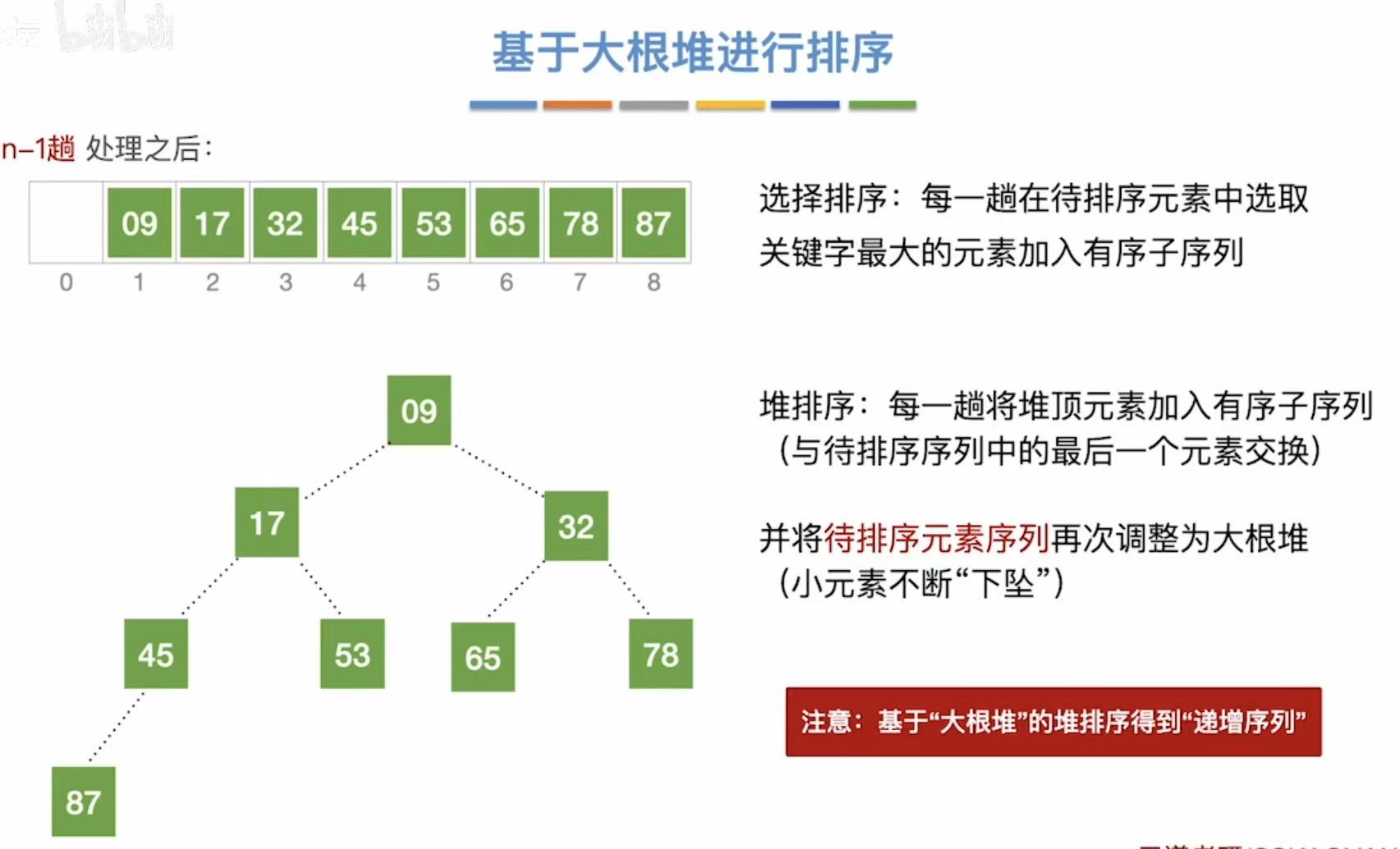
最终结果:
2.2.4 基于大根堆排序(代码)
java
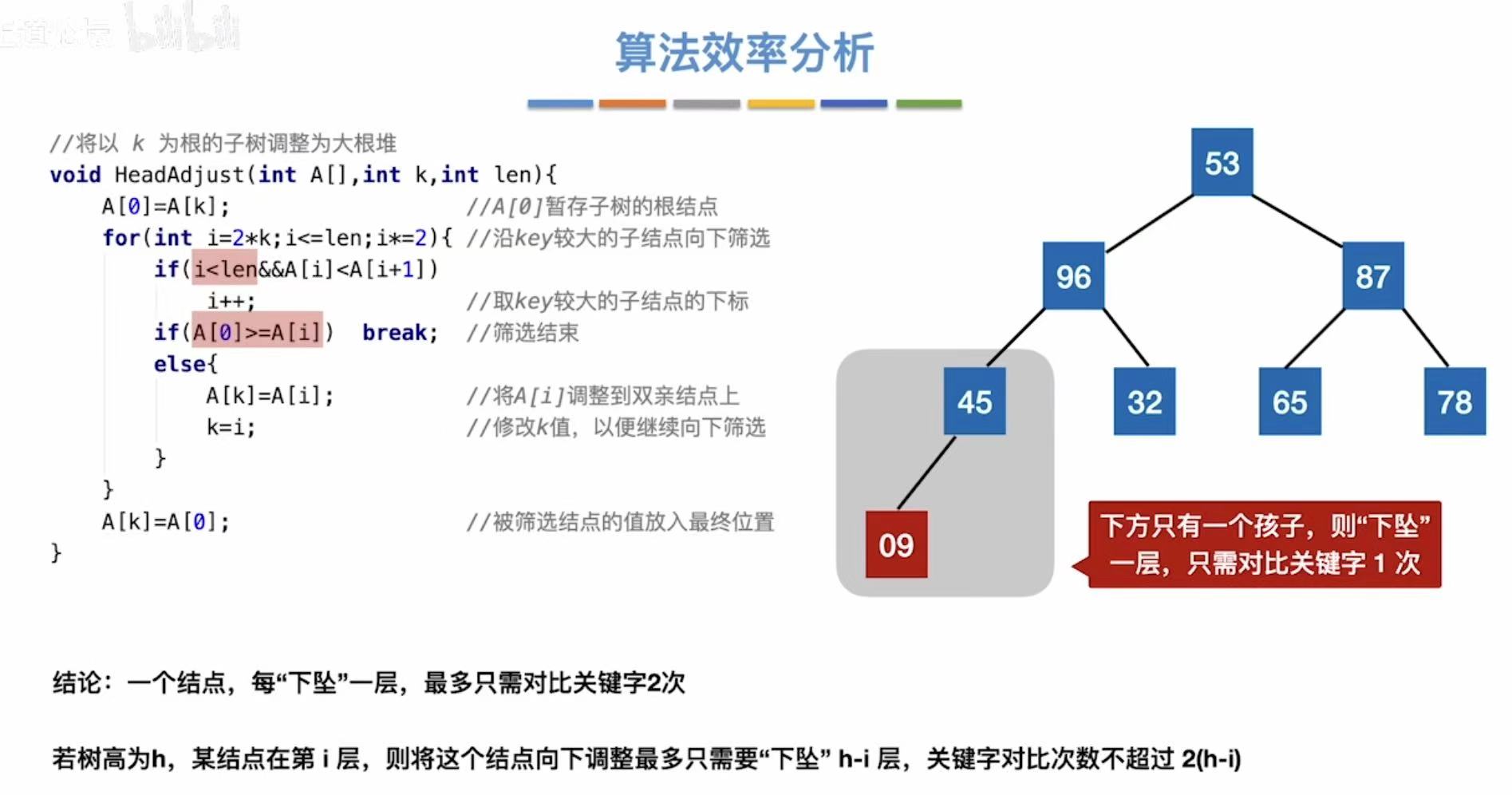
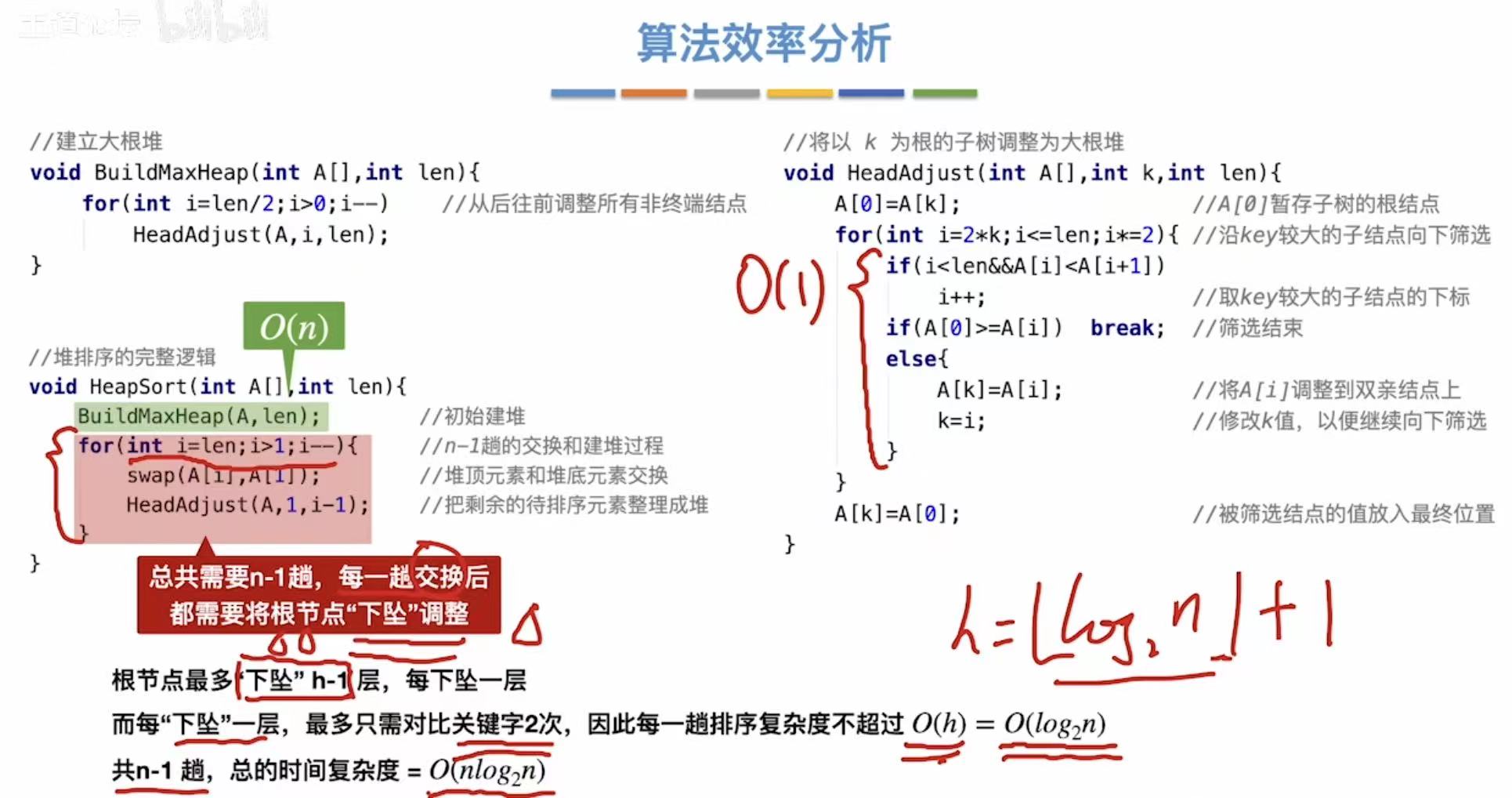
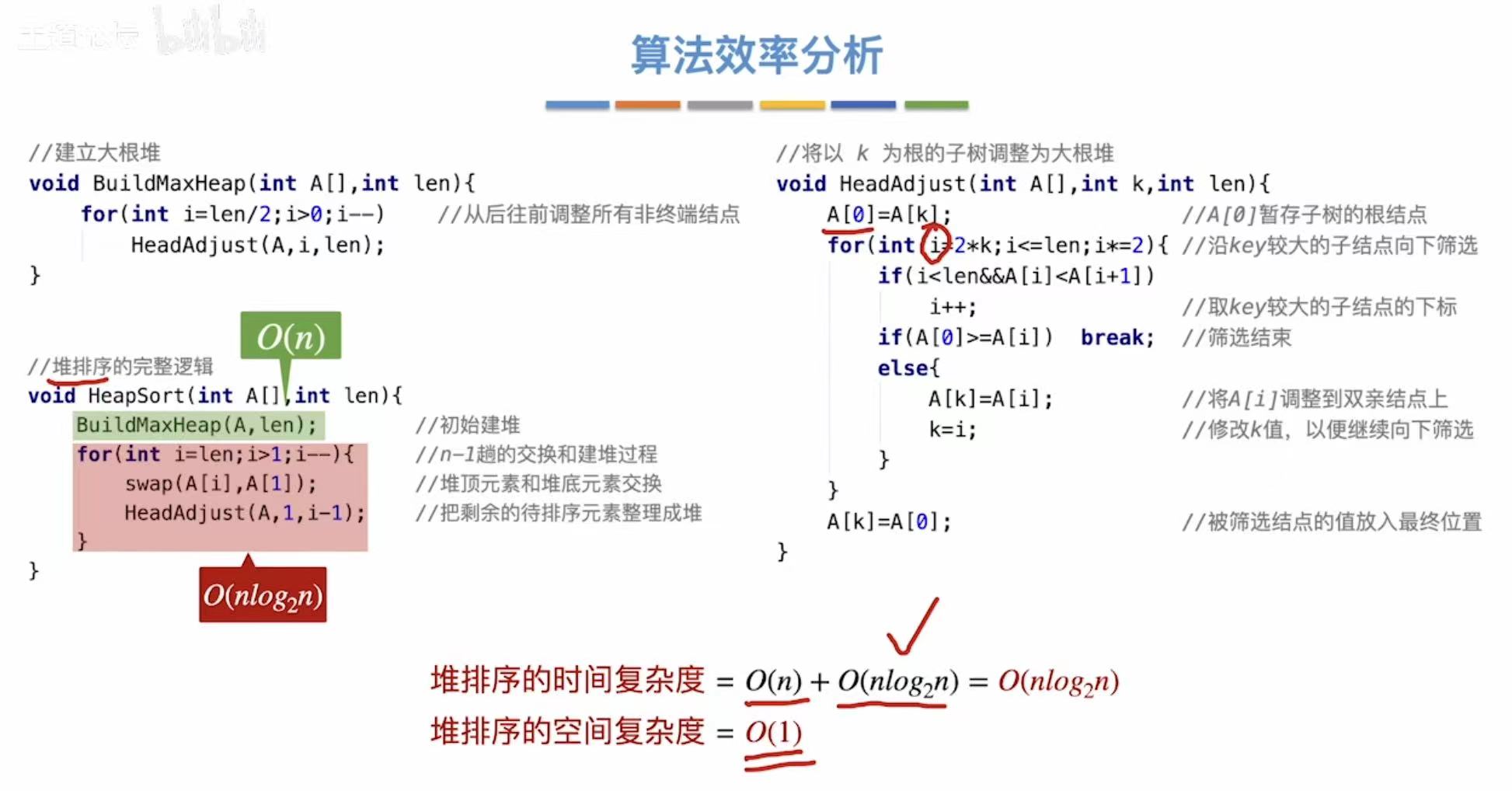
2.3 算法效率分析
结论:
- 空间复杂度:O(1)
- 时间复杂度:O(nlog2n)(2是下标)
- 不稳定



2.4 小结
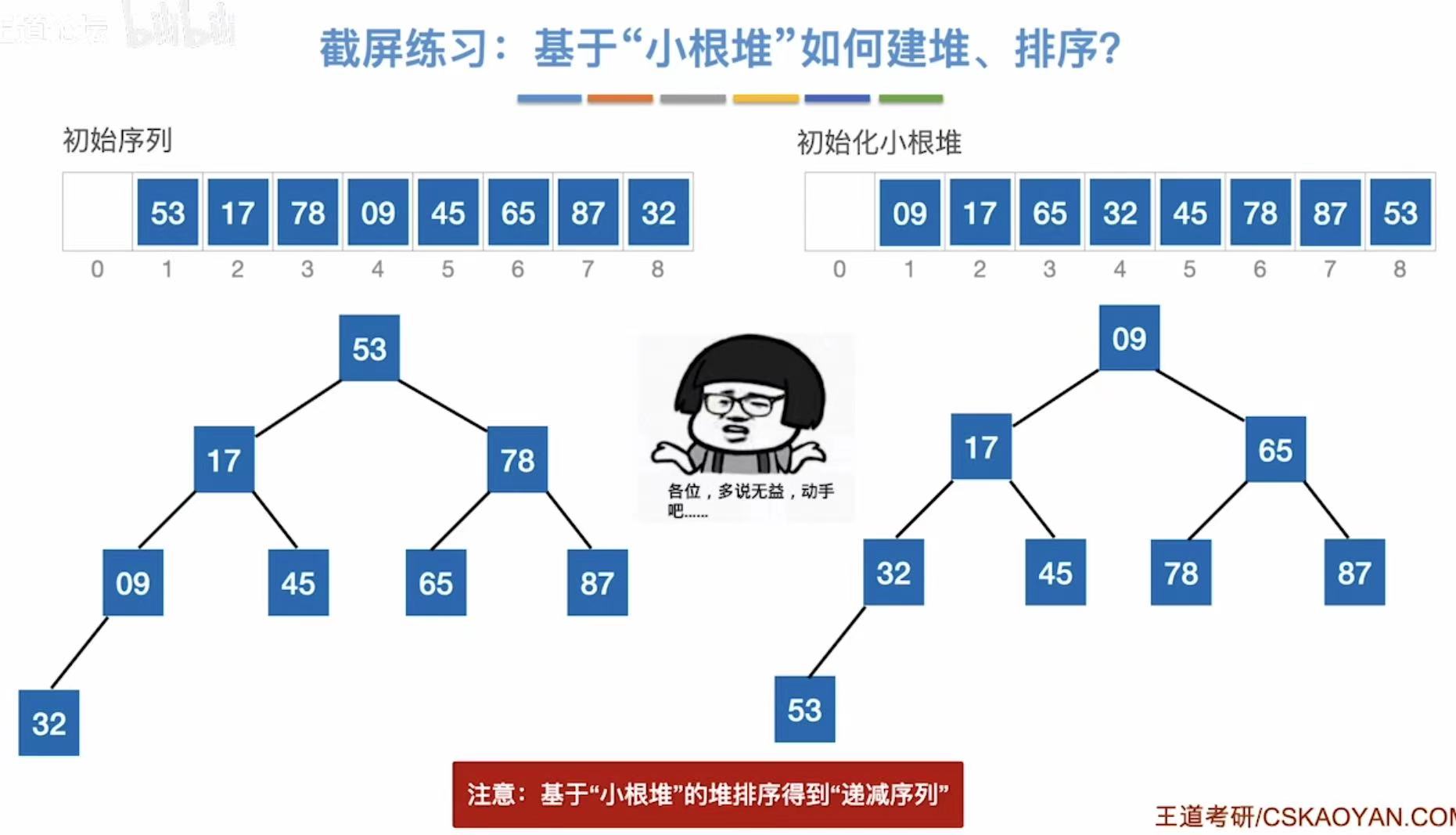
2.5 基本操作
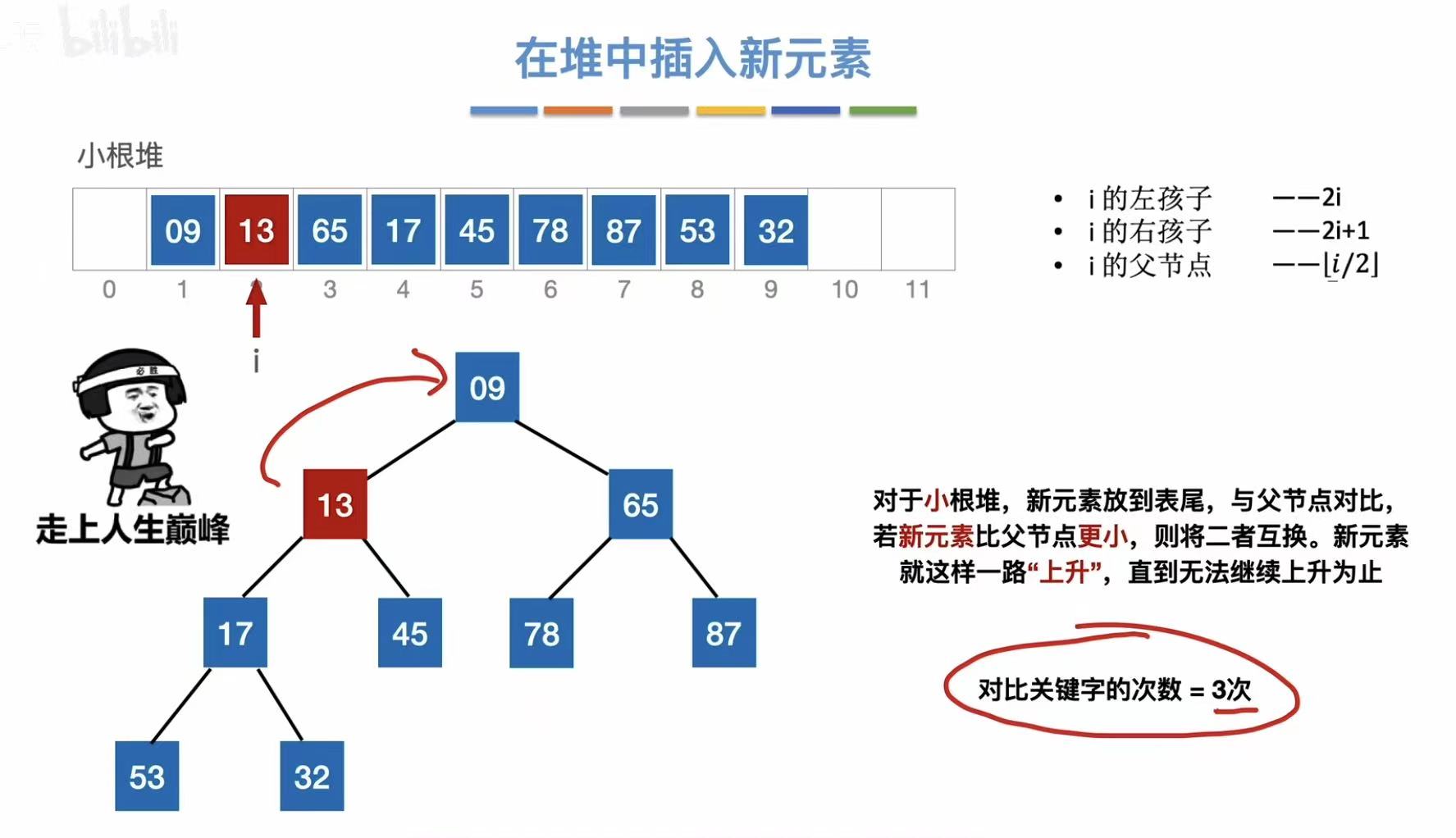
2.5.1 插入操作
逻辑:直接插入到数组后面,对应插入二叉树的位置-->保持大/小根堆的性质
插入13:
- 插入到最后
- 对应插入二叉树的位置
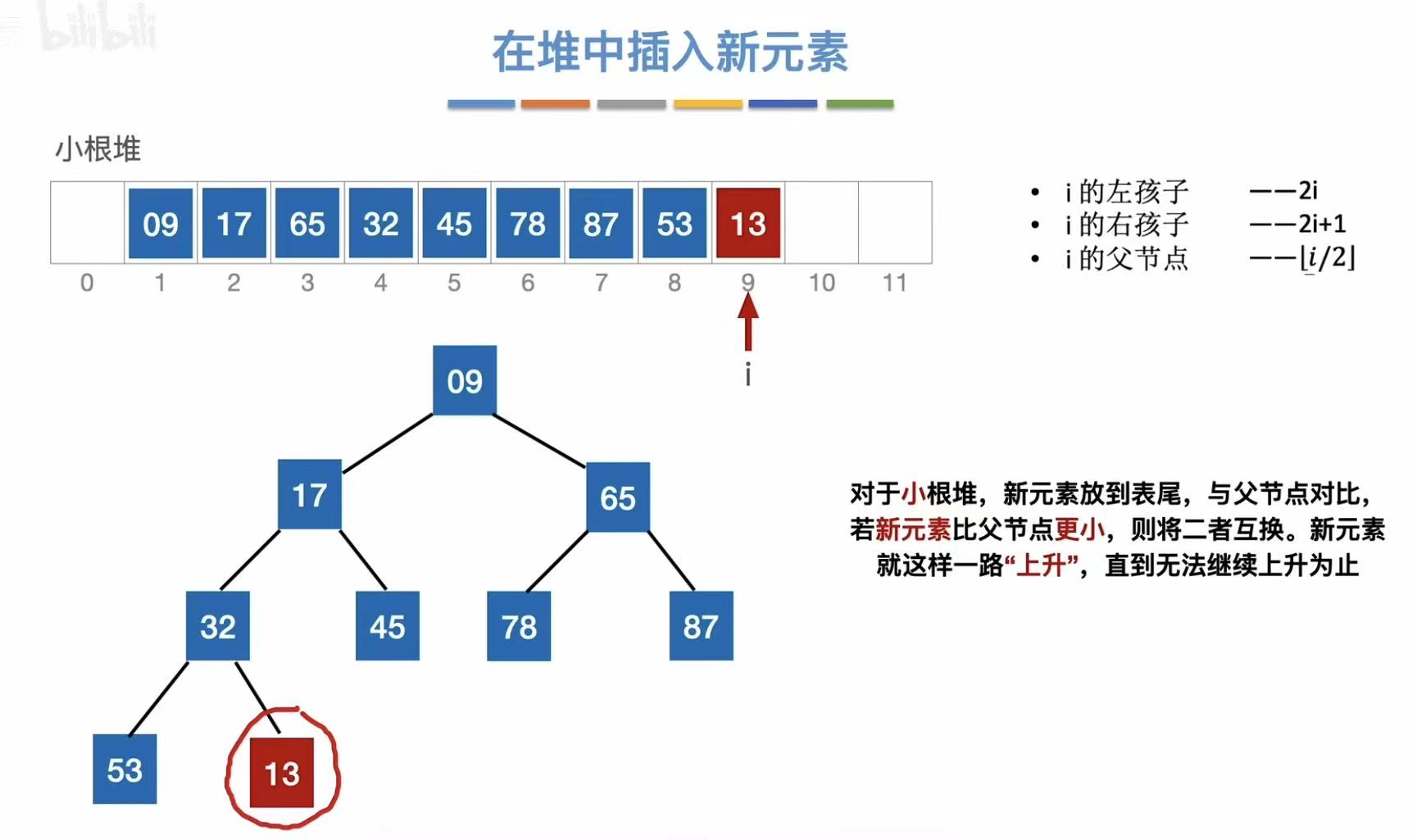
- 保持小根堆的性质,越小越上升
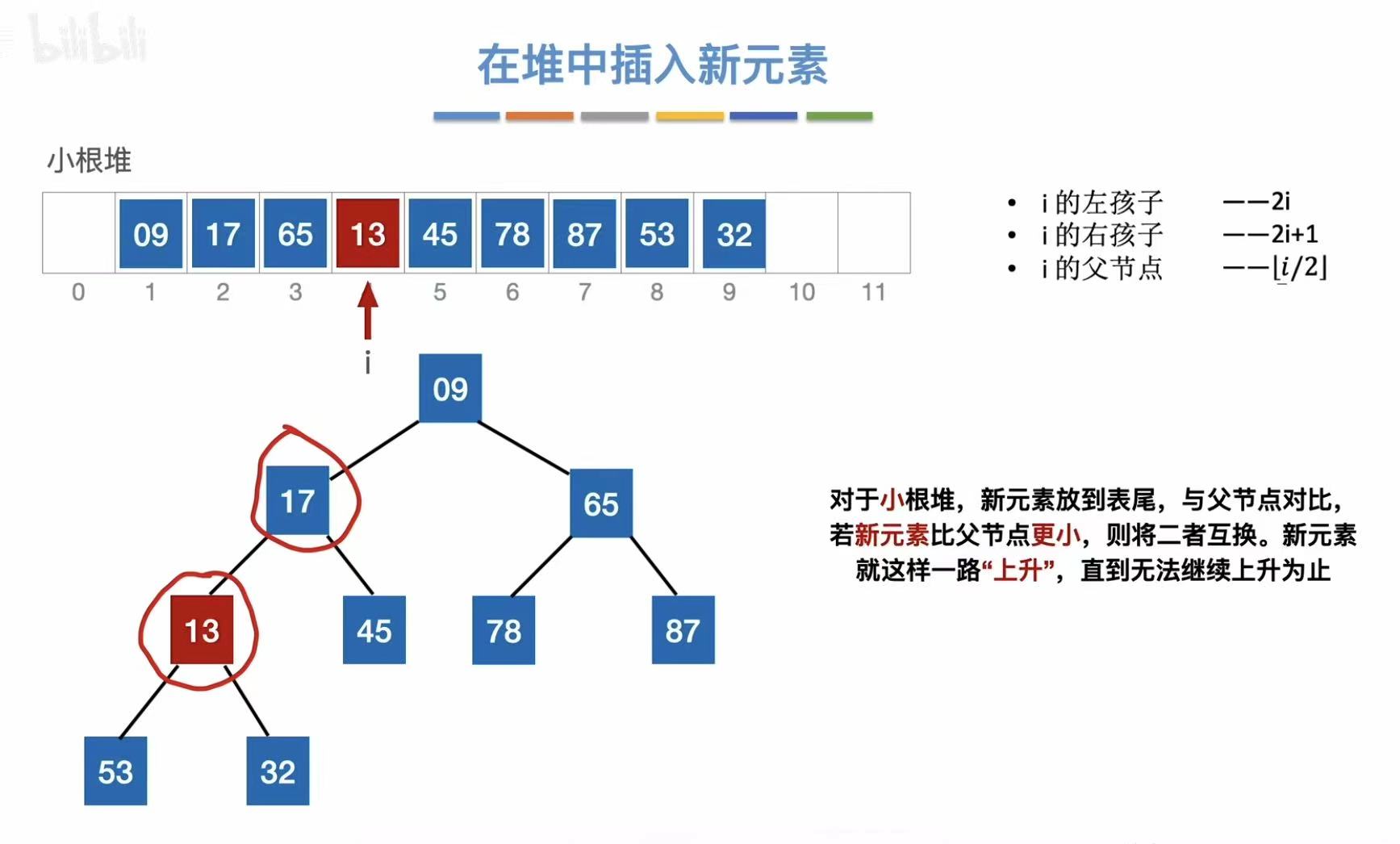
- 上升结束:
插入46: - 插入到最后
- 对应插入到二叉树的位置上
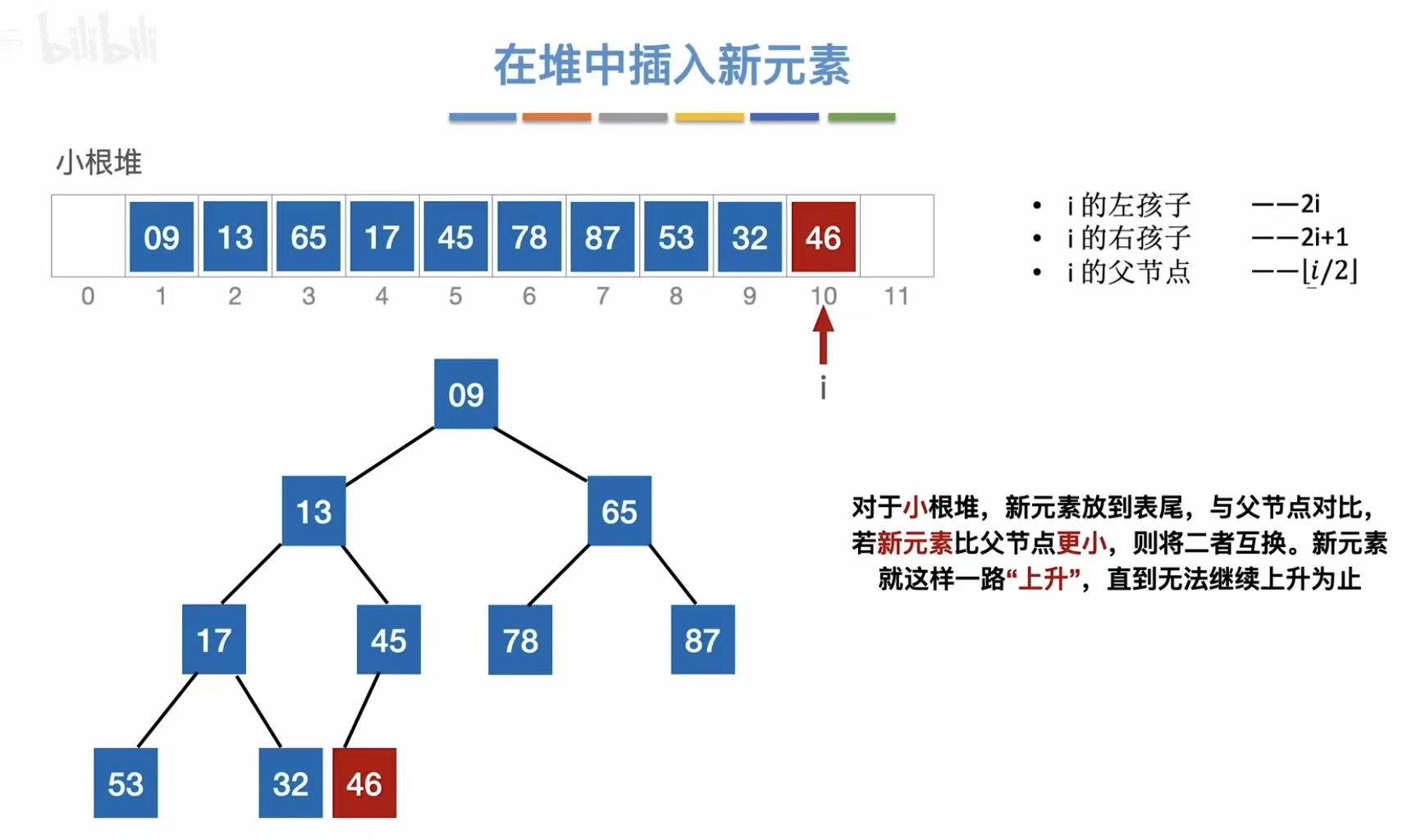
- 数这么大,根本没必要上升
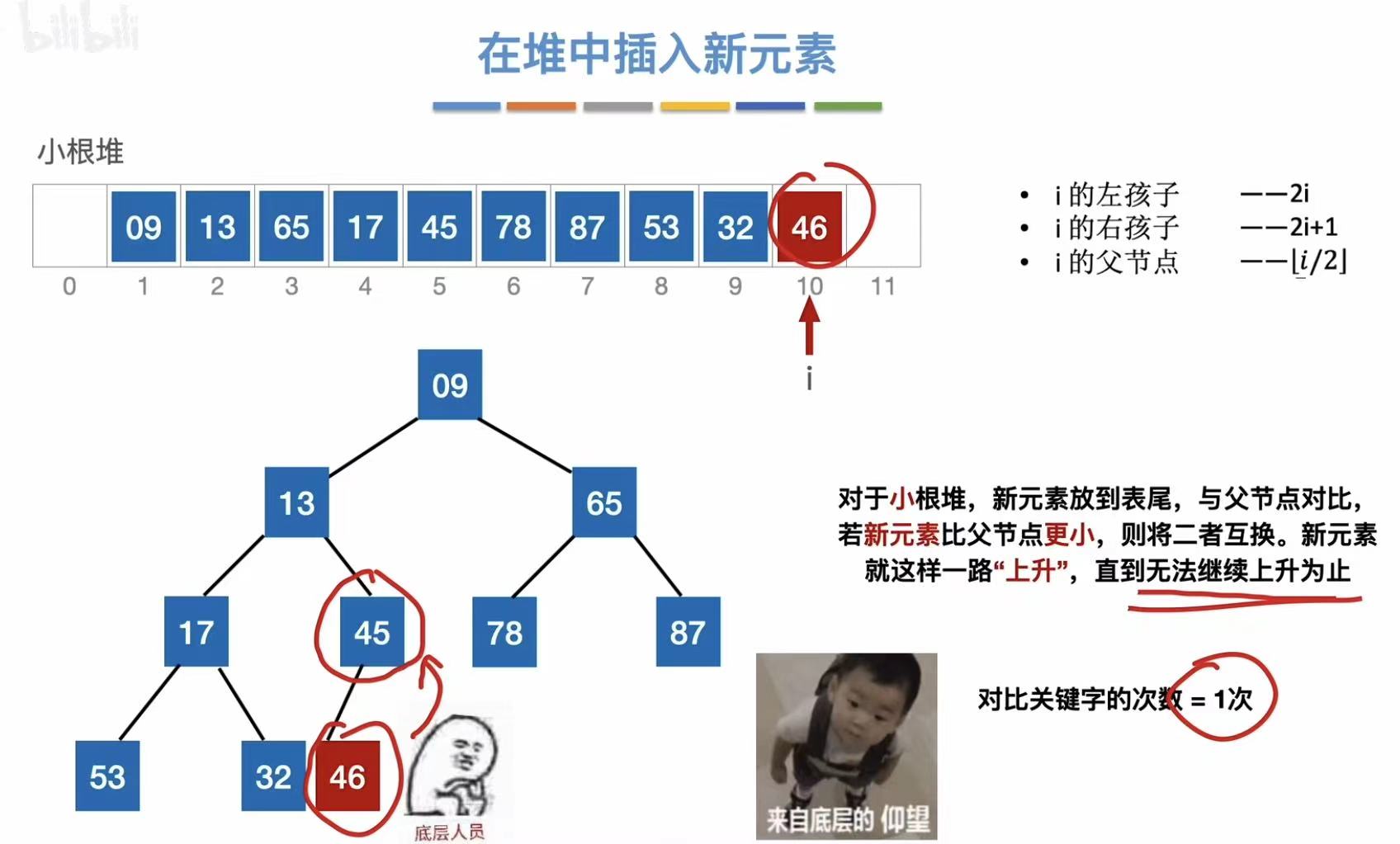
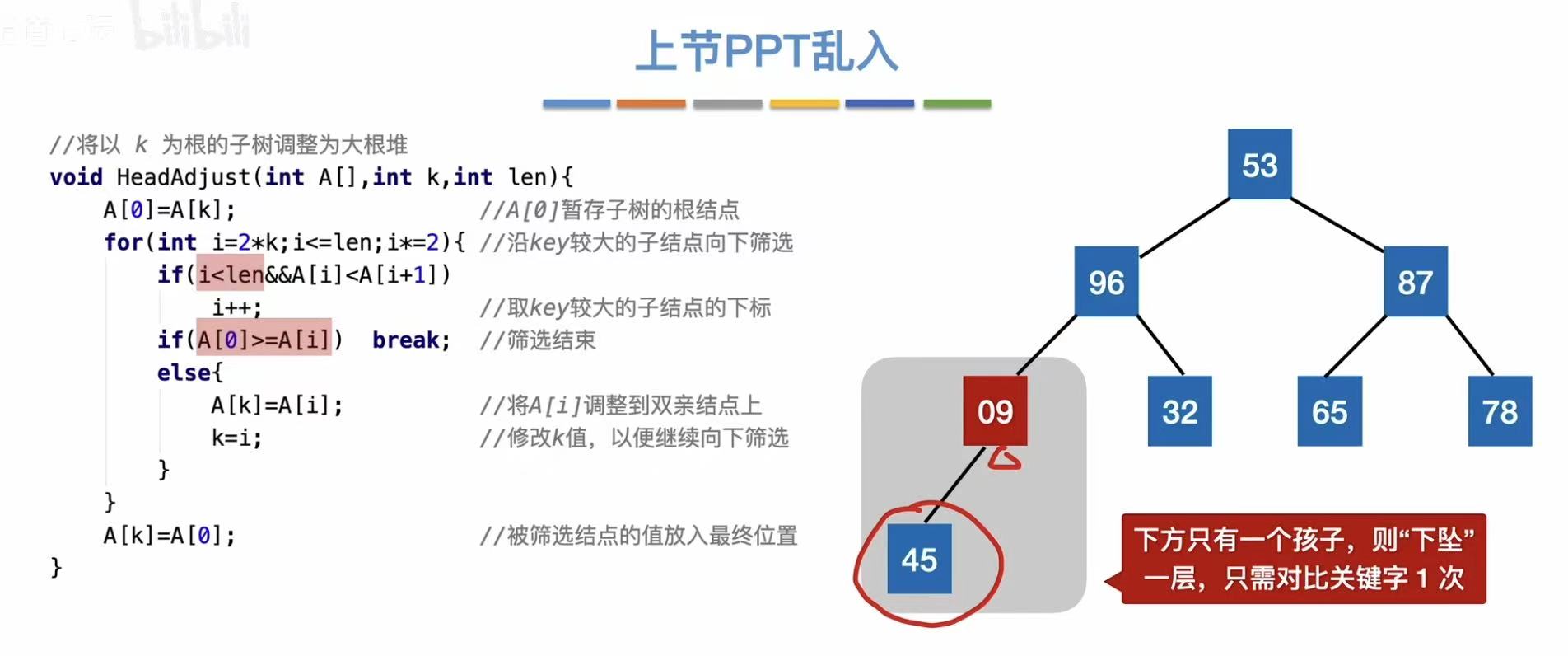
2.5.2 删除操作
逻辑:因为删除而空出来的位置由最后面的数补位-->依旧保持小根堆的性质
删除13:
- 空位由最后的46补上
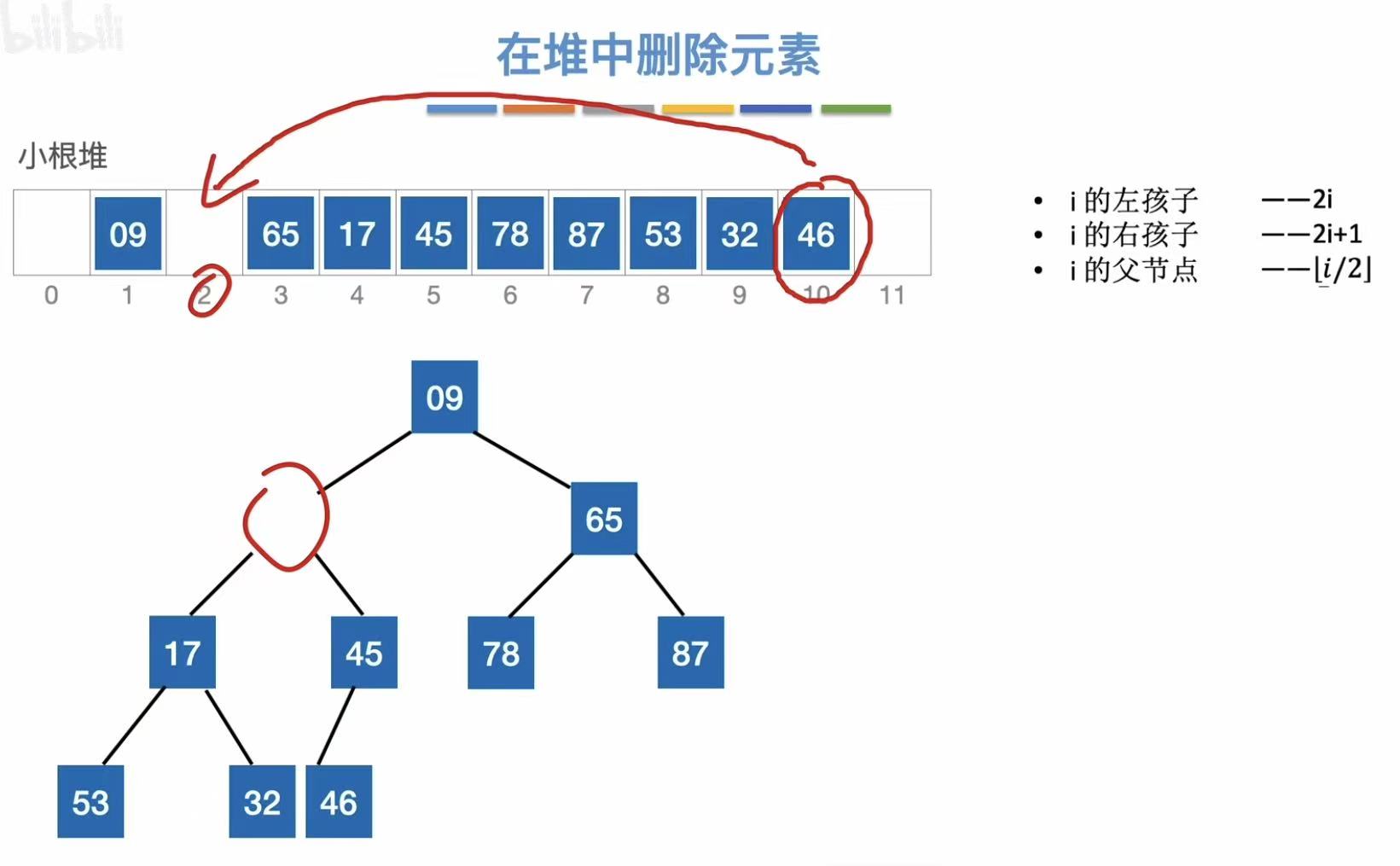
- 大的数在小根堆中需要下坠
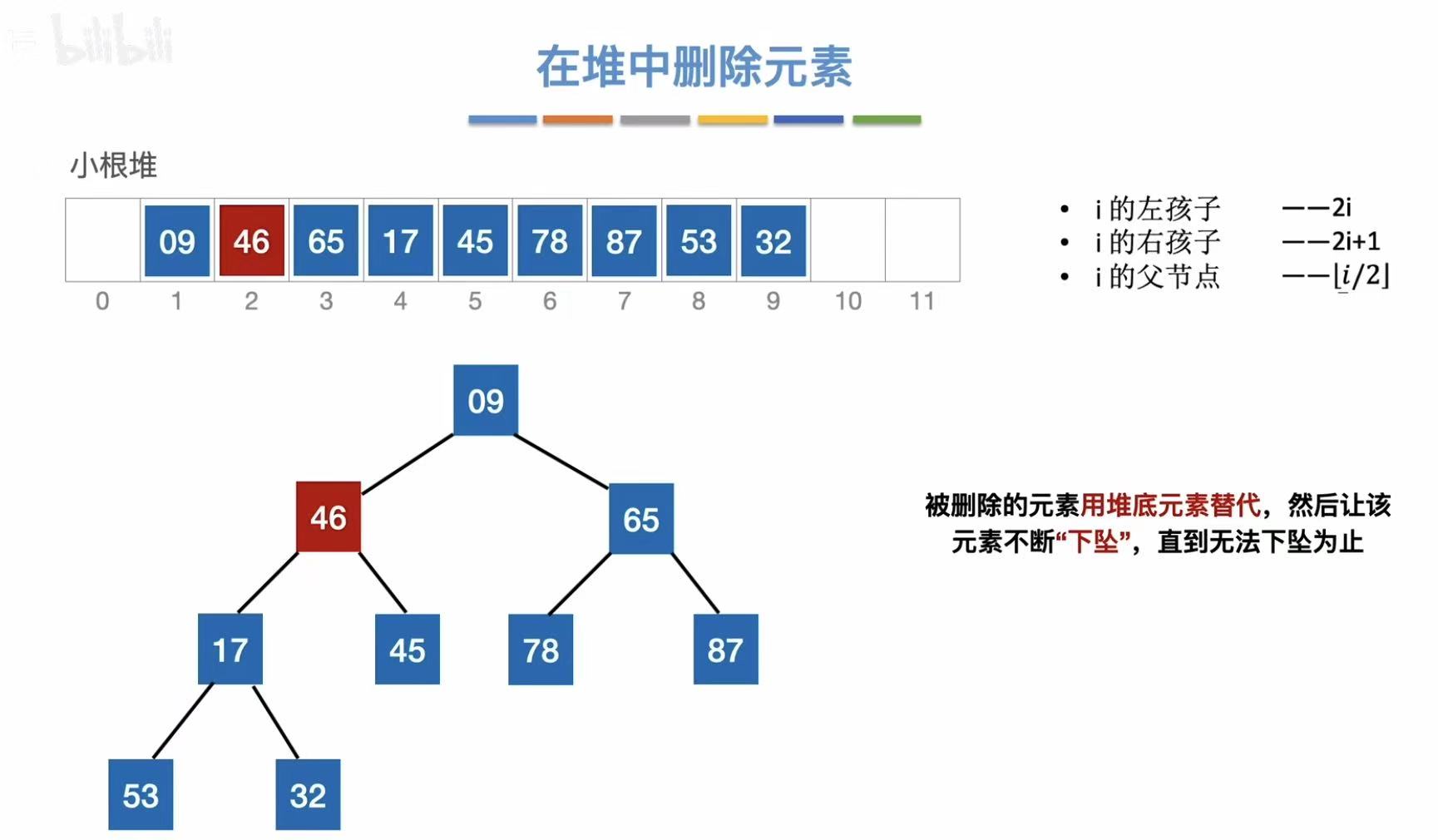
- 继续下坠
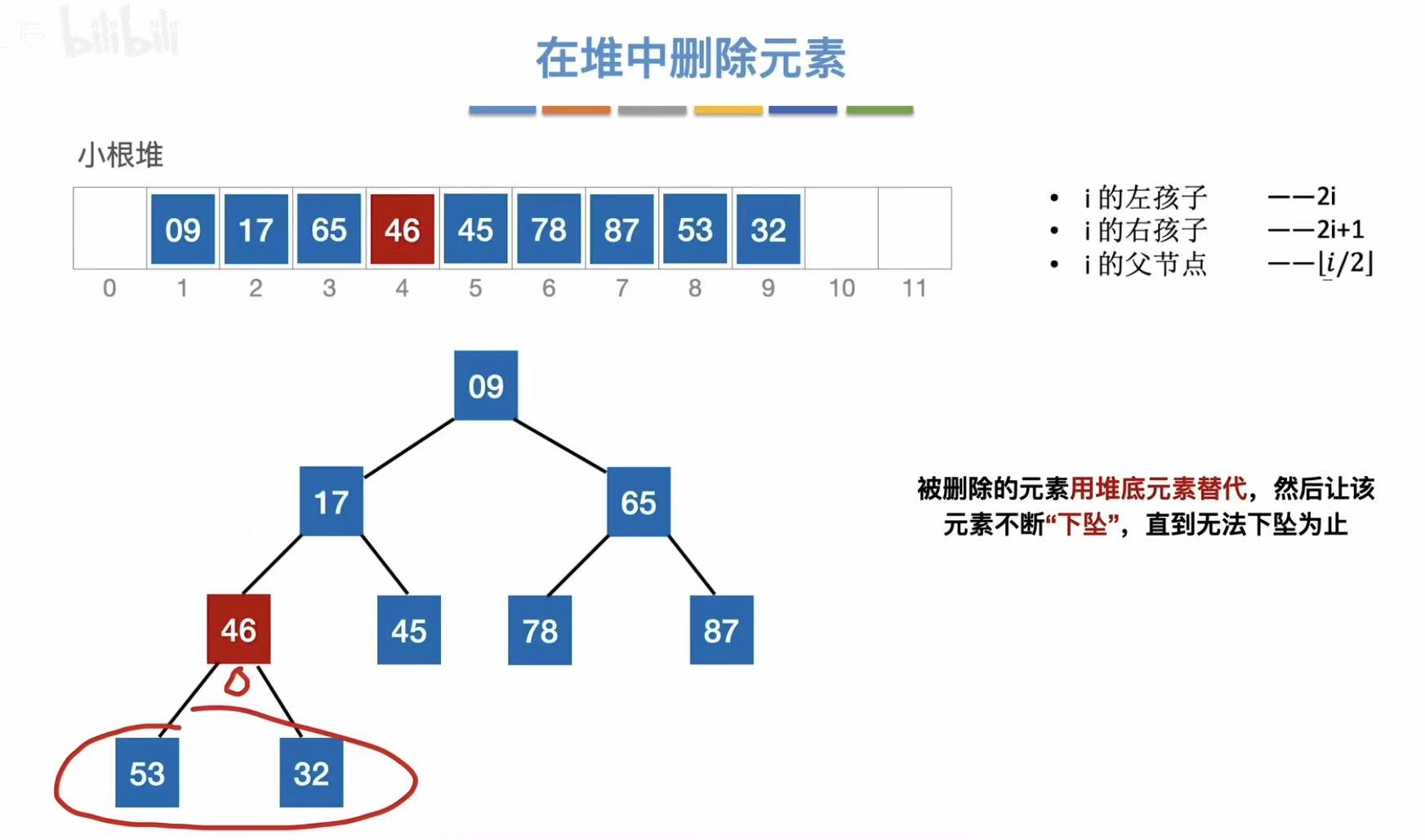
- 下坠结束
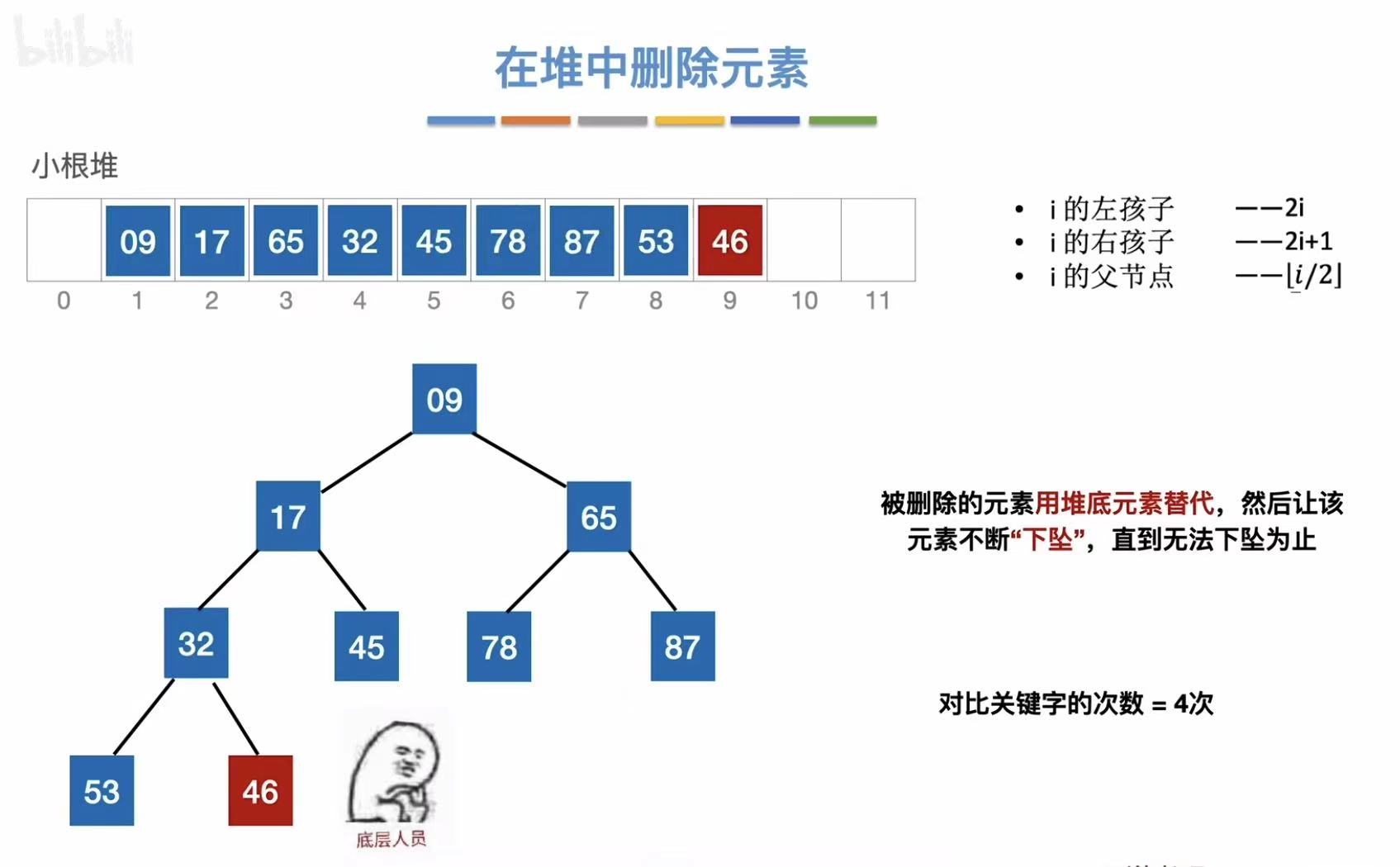
下坠次数:
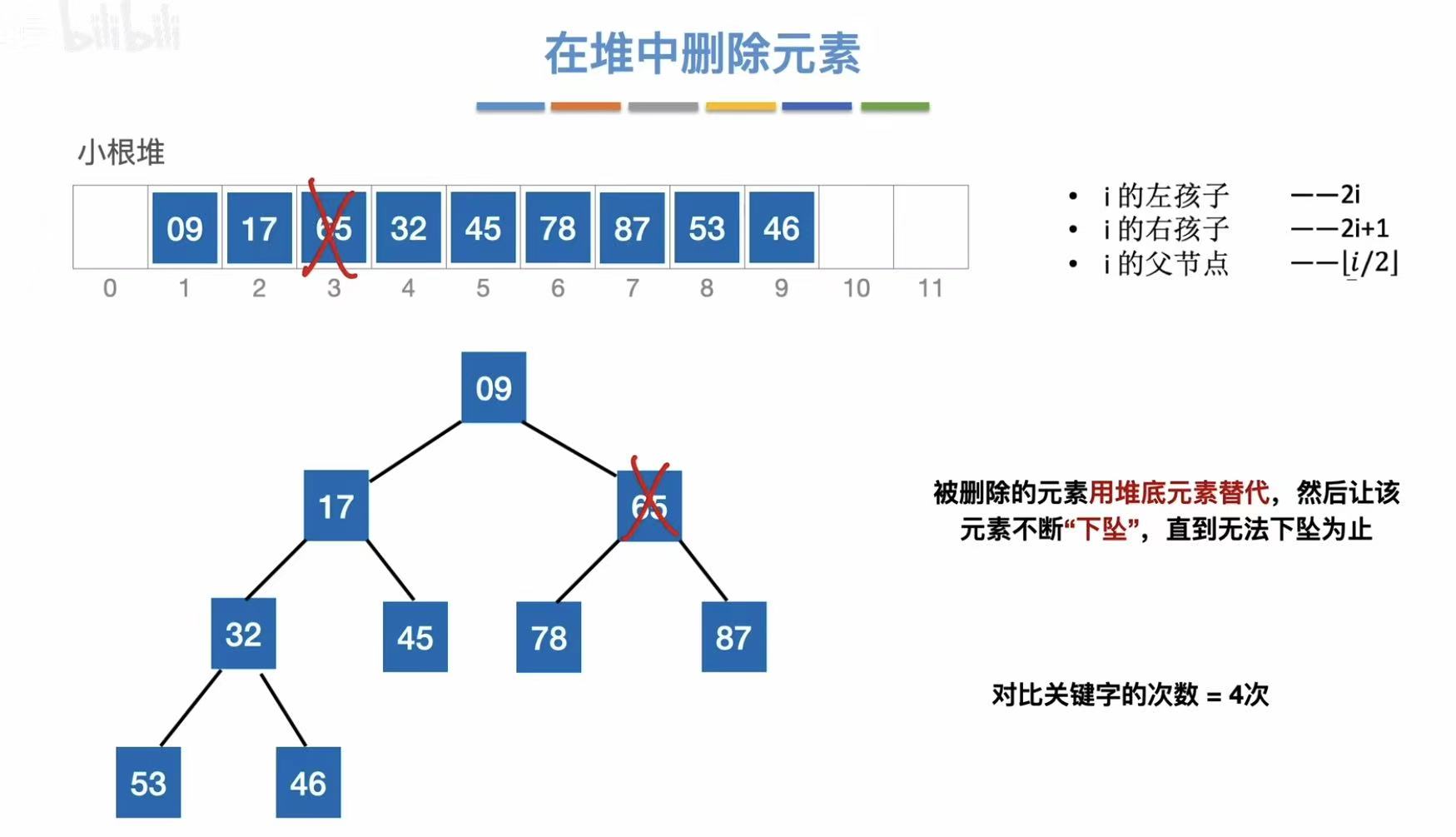
删除65:
- 依旧末尾的46过来补位
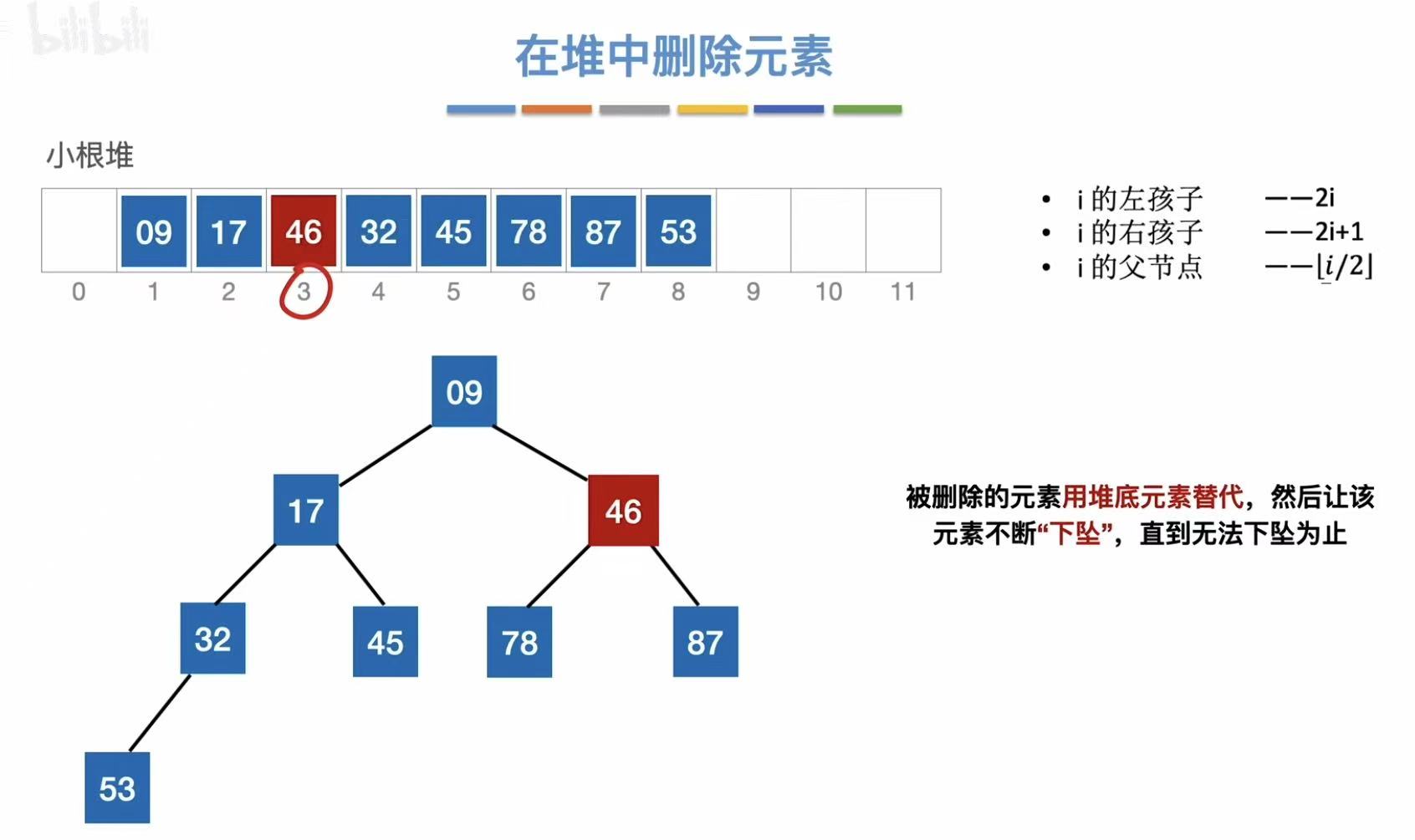
- 对比查看自己是否需要下坠
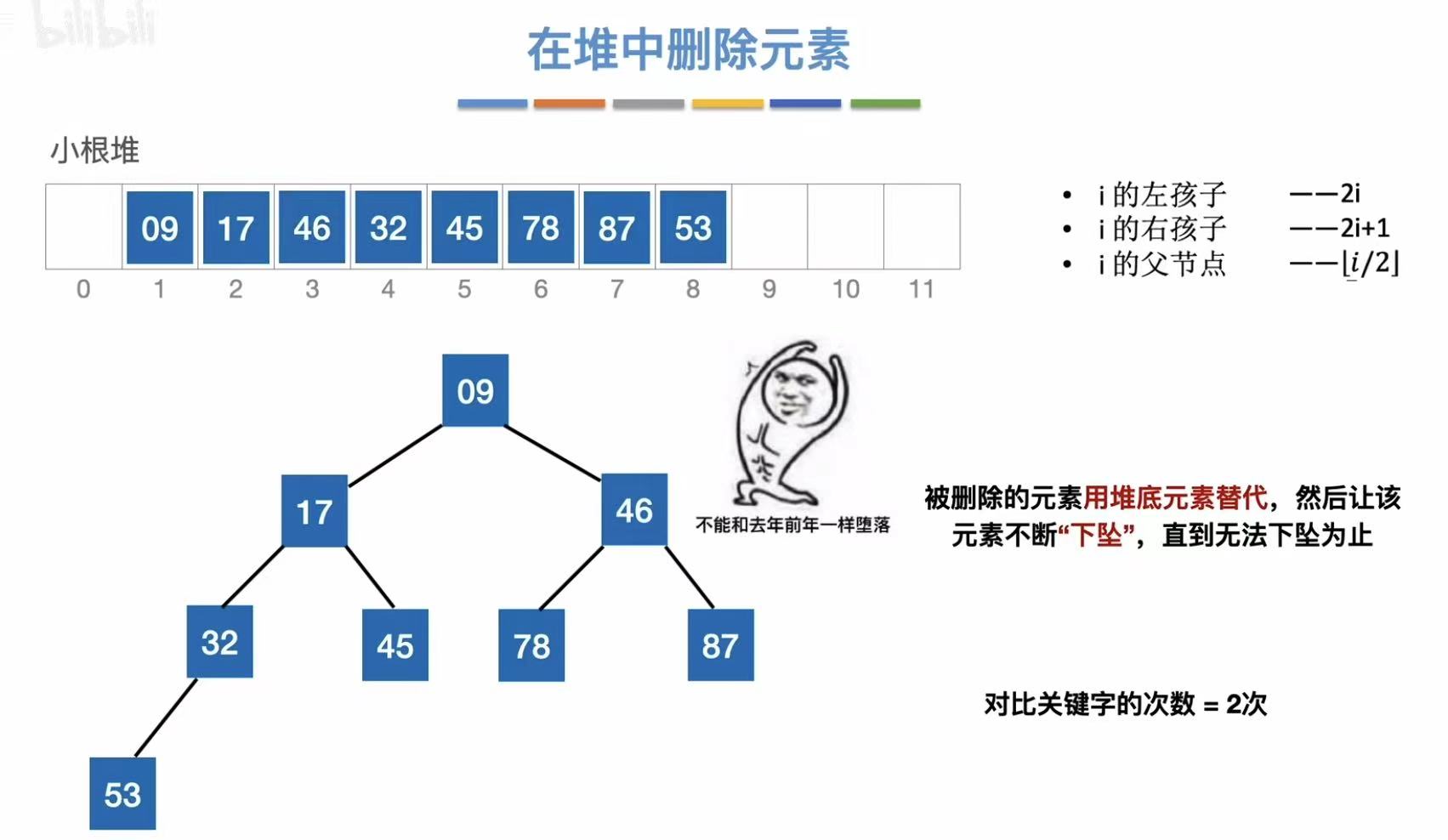
- 结果发现自己不用下坠
2.5.3 小结
归并排序
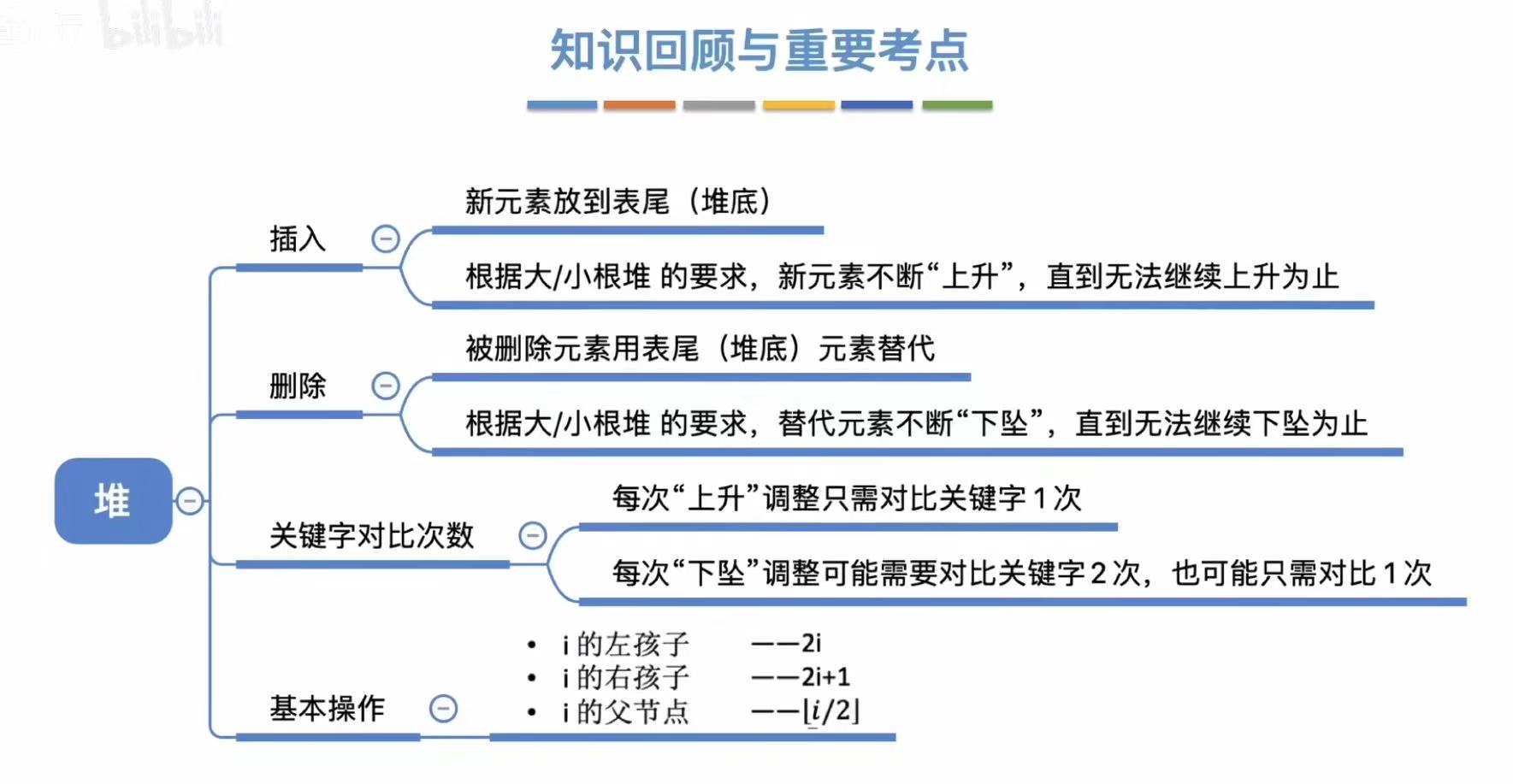
1. 什么是归并?
- i指向一组有序数据,j指向一组有序数据
- i和j比大小,谁小谁先进最终的位置
- 这样就把两组数据归并成一组数据了
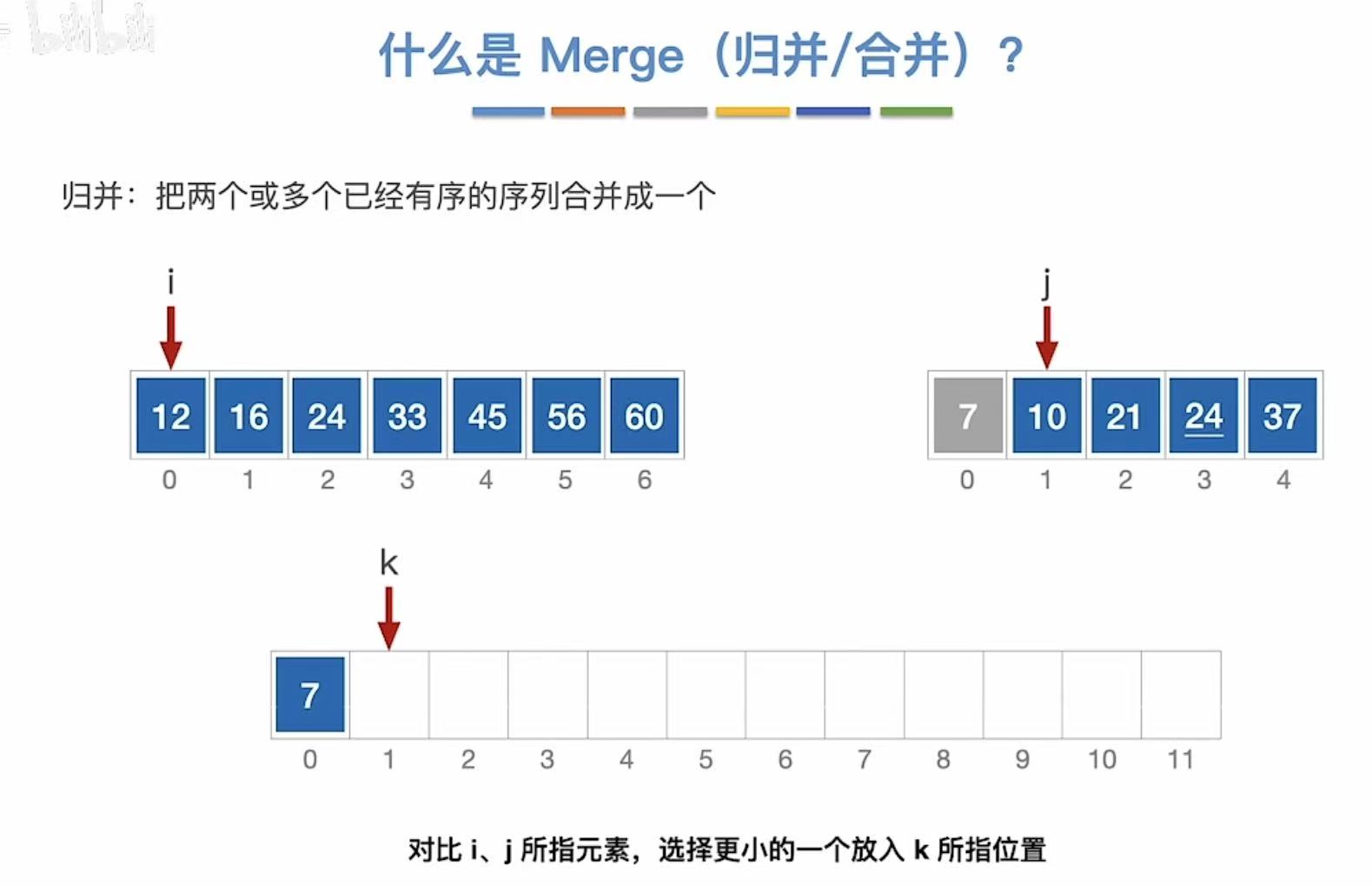
右侧全部进入-->j没有指向元素了-->i所指的数据可以全部进入最终位置
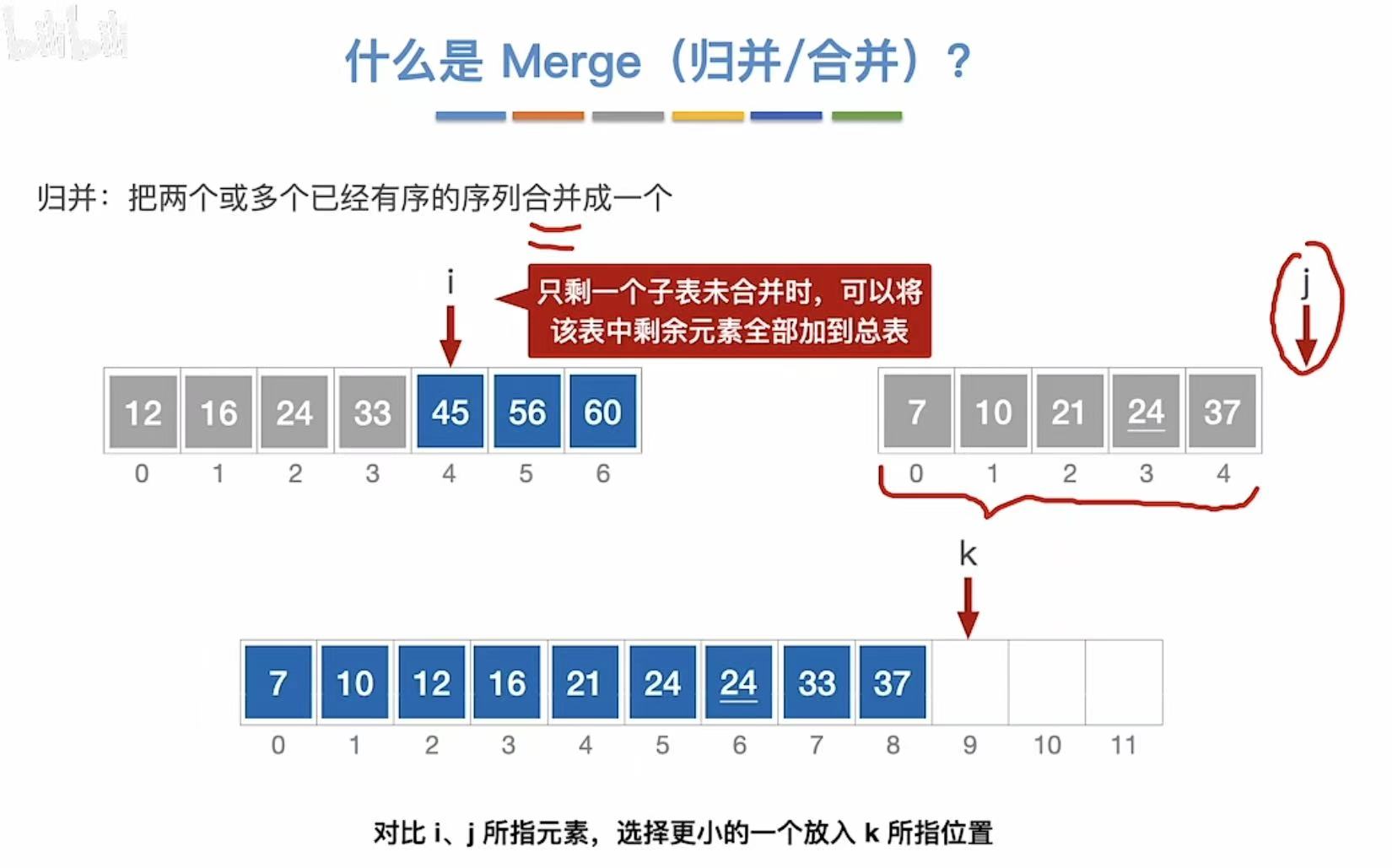
这样就成功把两组数据合并成一组数据
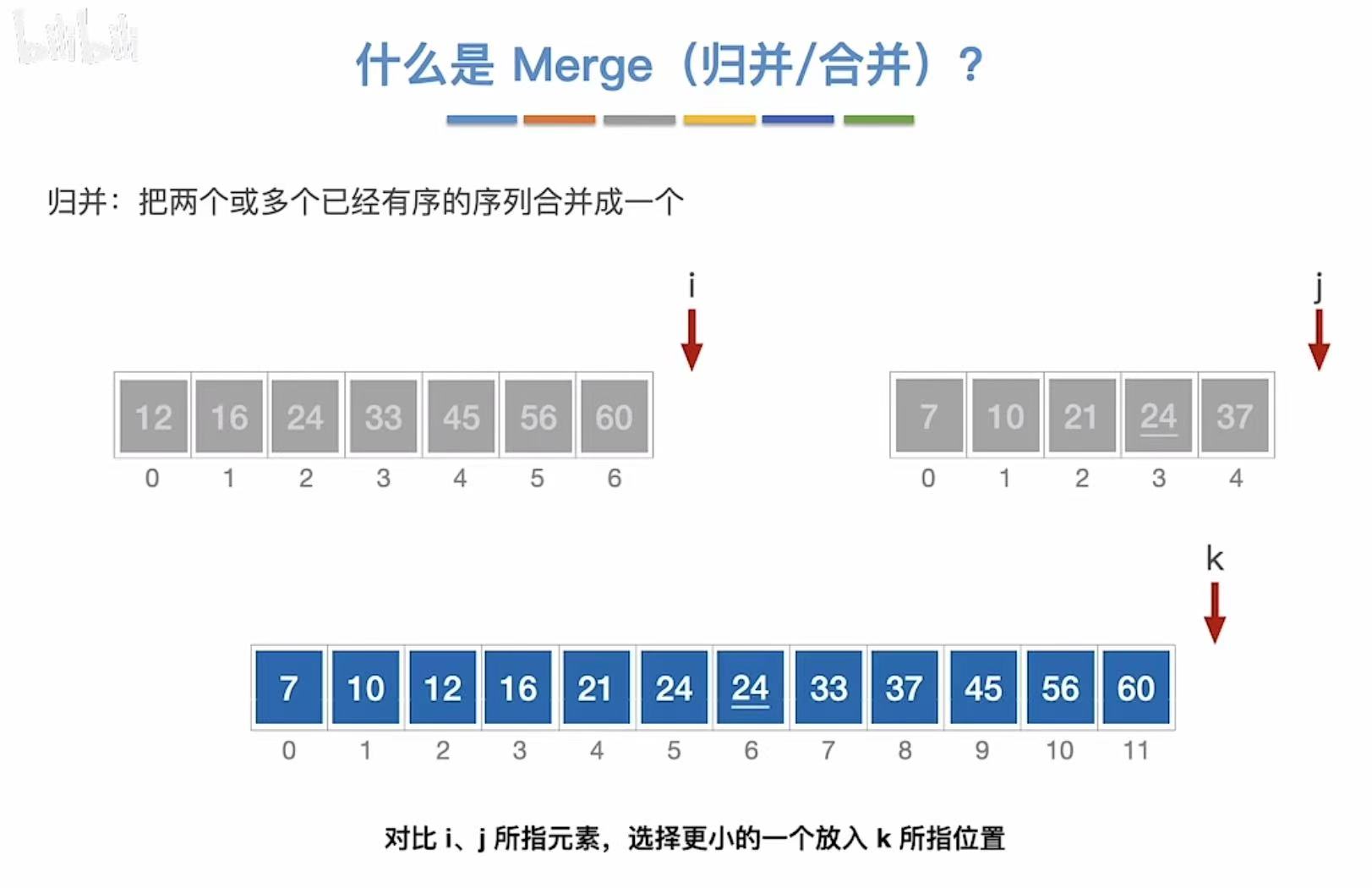
2. 算法思想
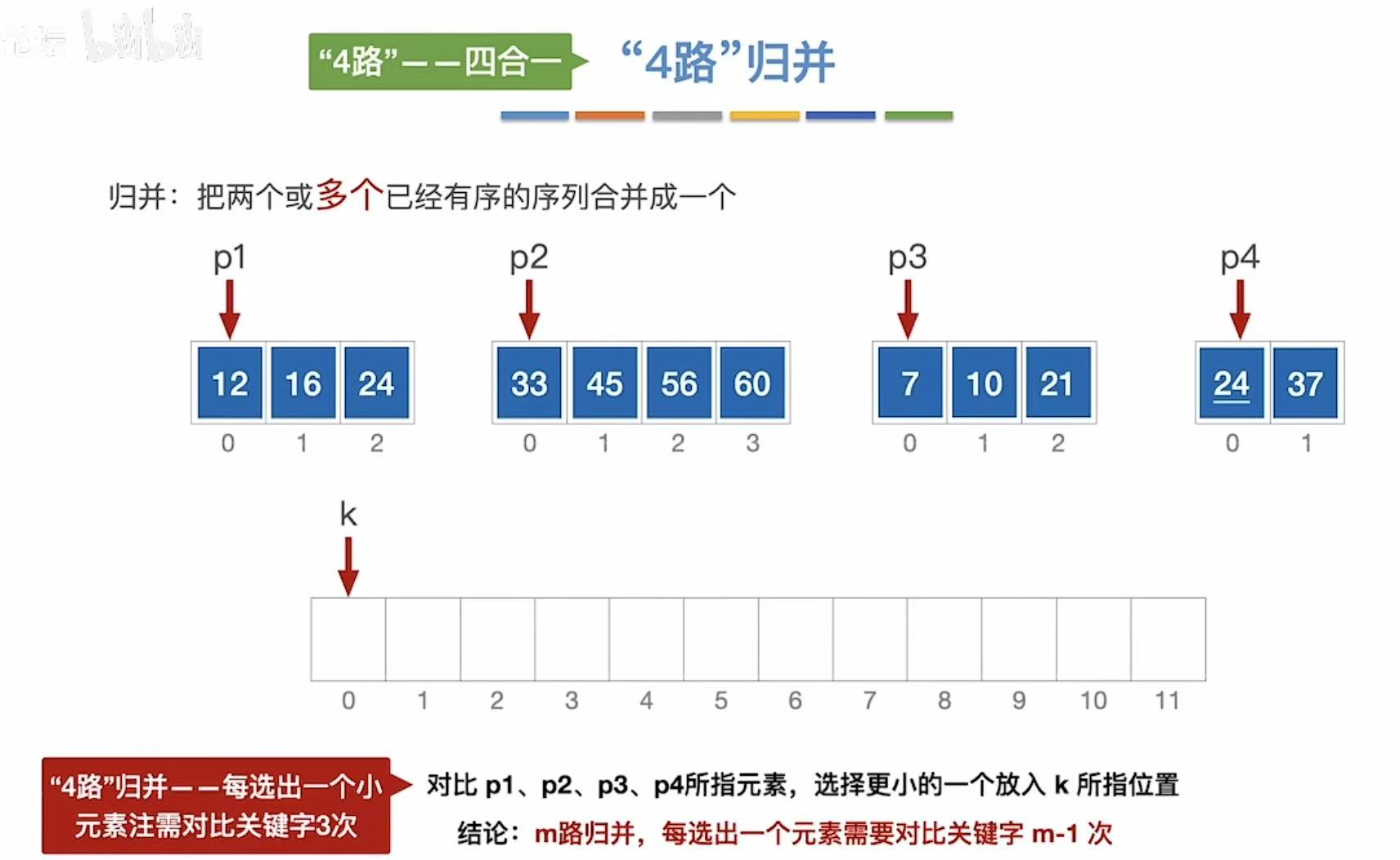
2.1 4路归并
上文提到过2路归并,可以多加几个指向数据的指针,如图就是4路归并。
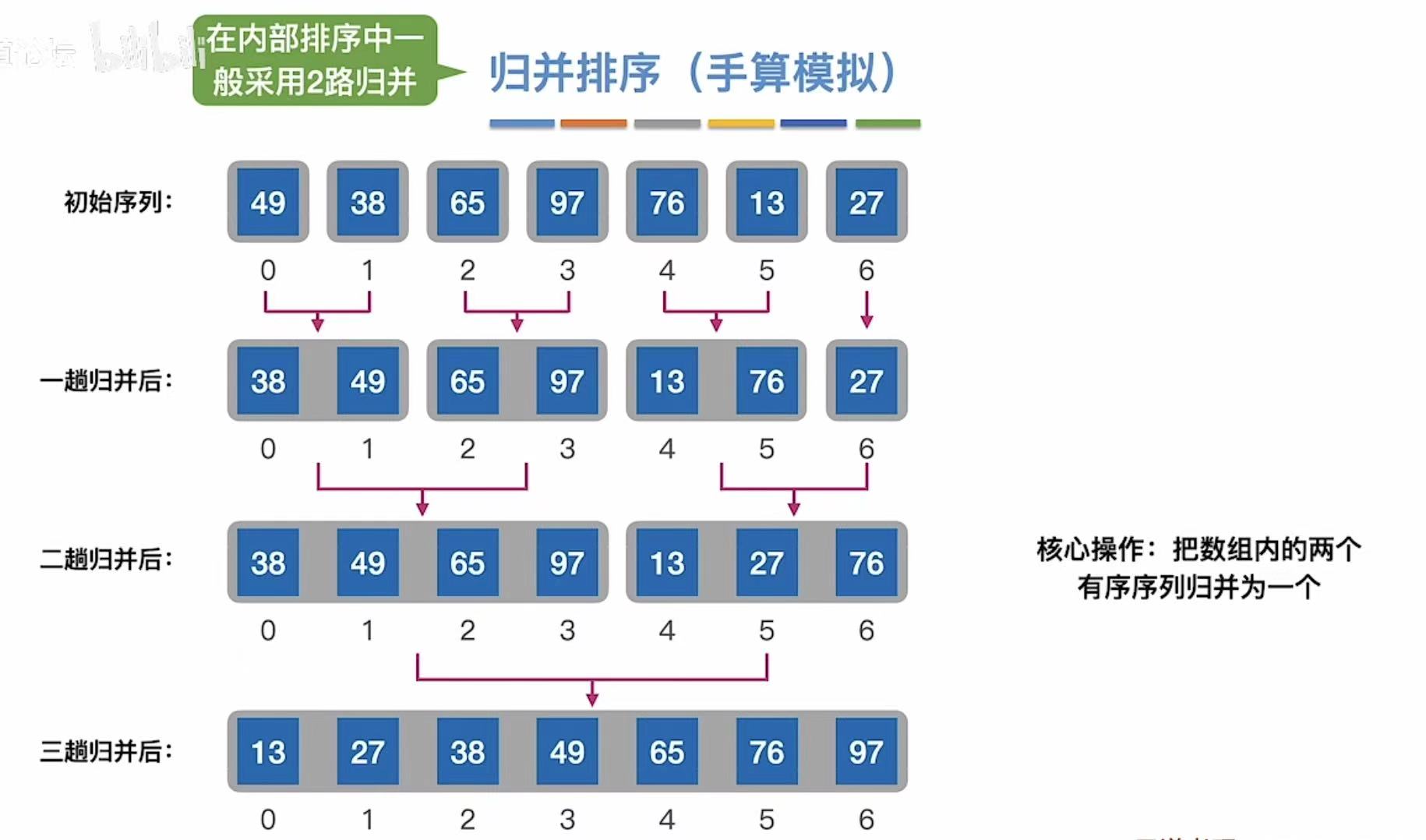
2.2 归并排序(手算模拟)
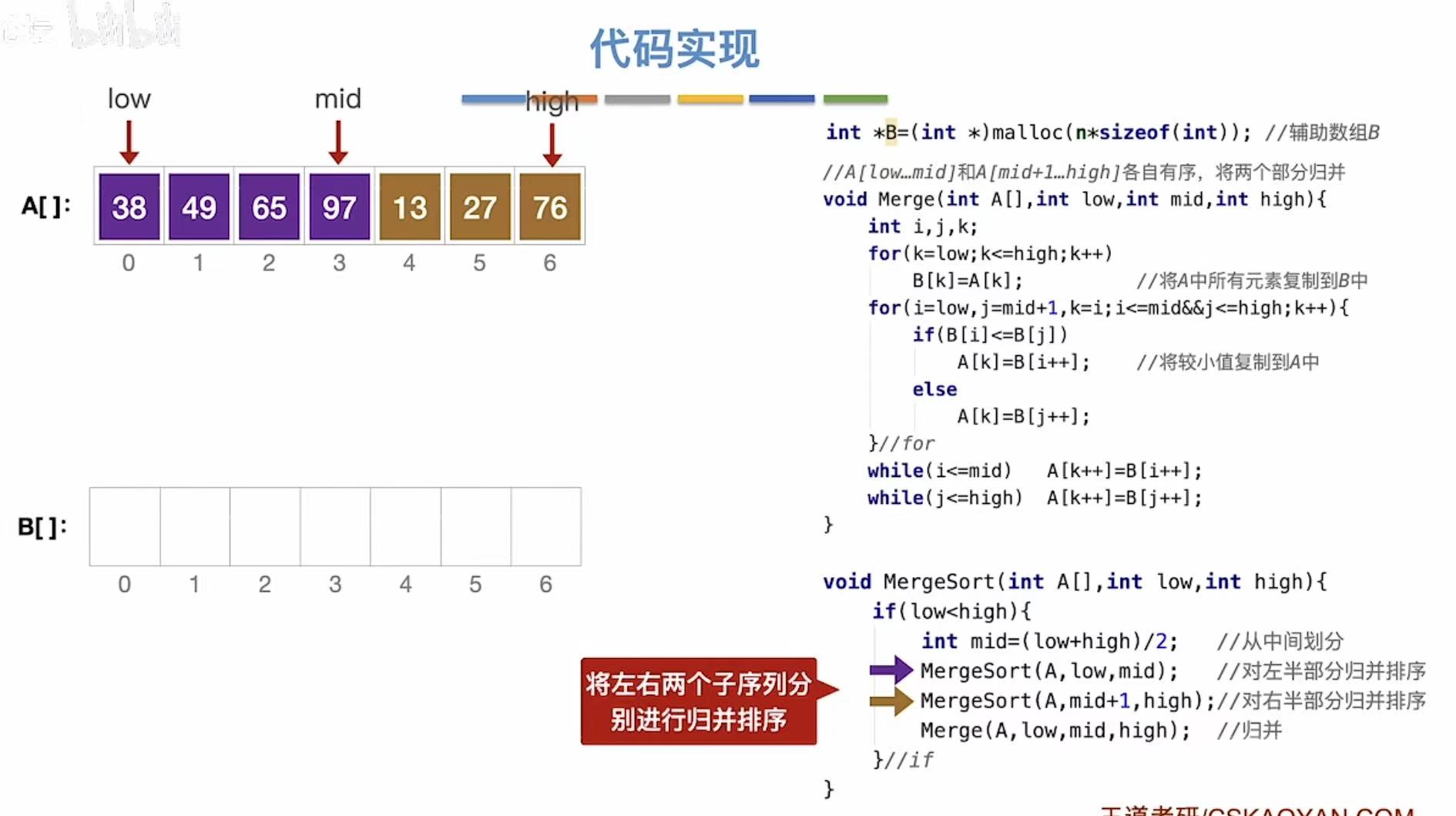
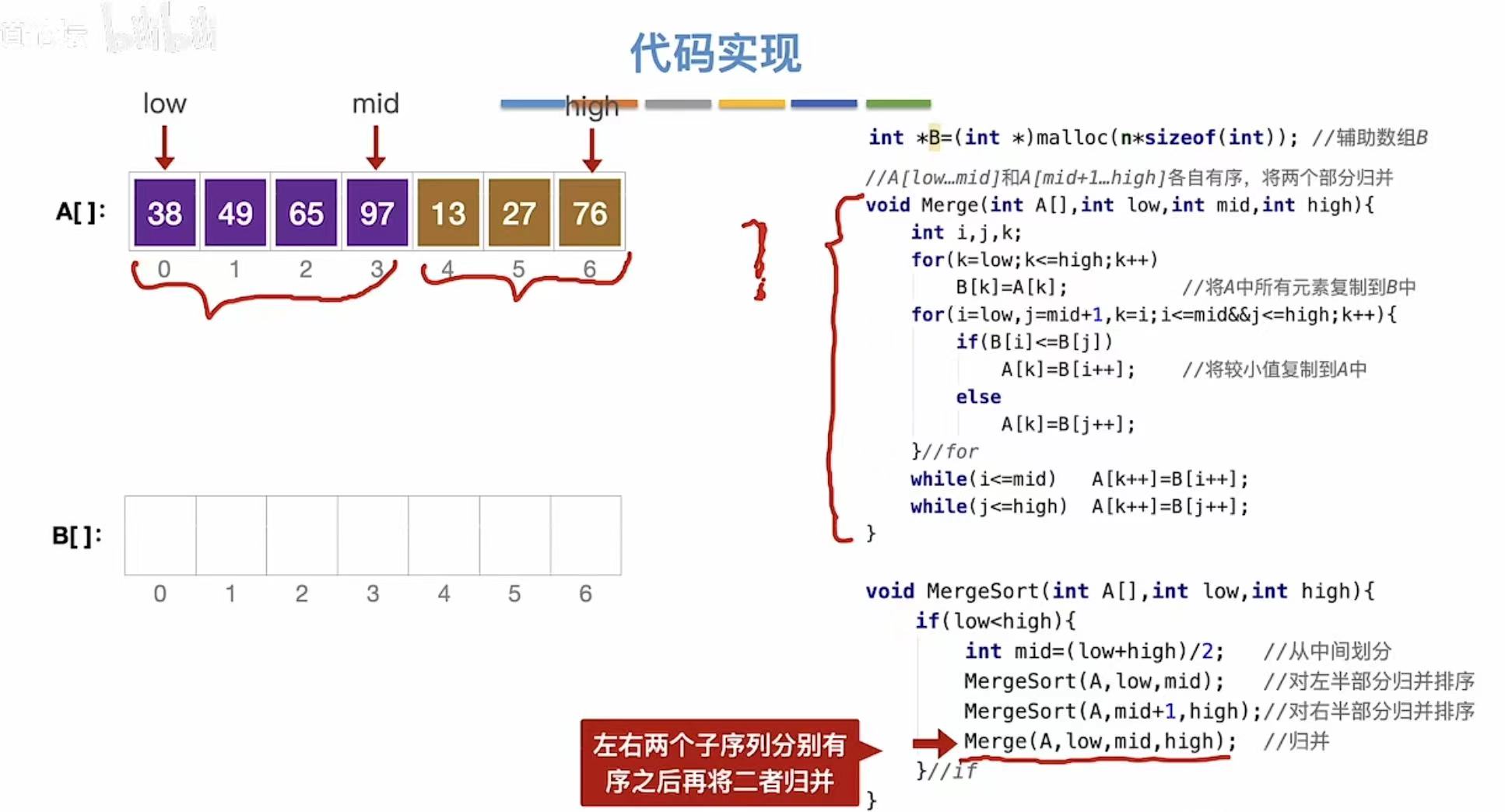
3. 代码实现
3.1 例1-分别有序
设置一个辅助队列,将未排序的数据全部复制进去(A---->B)
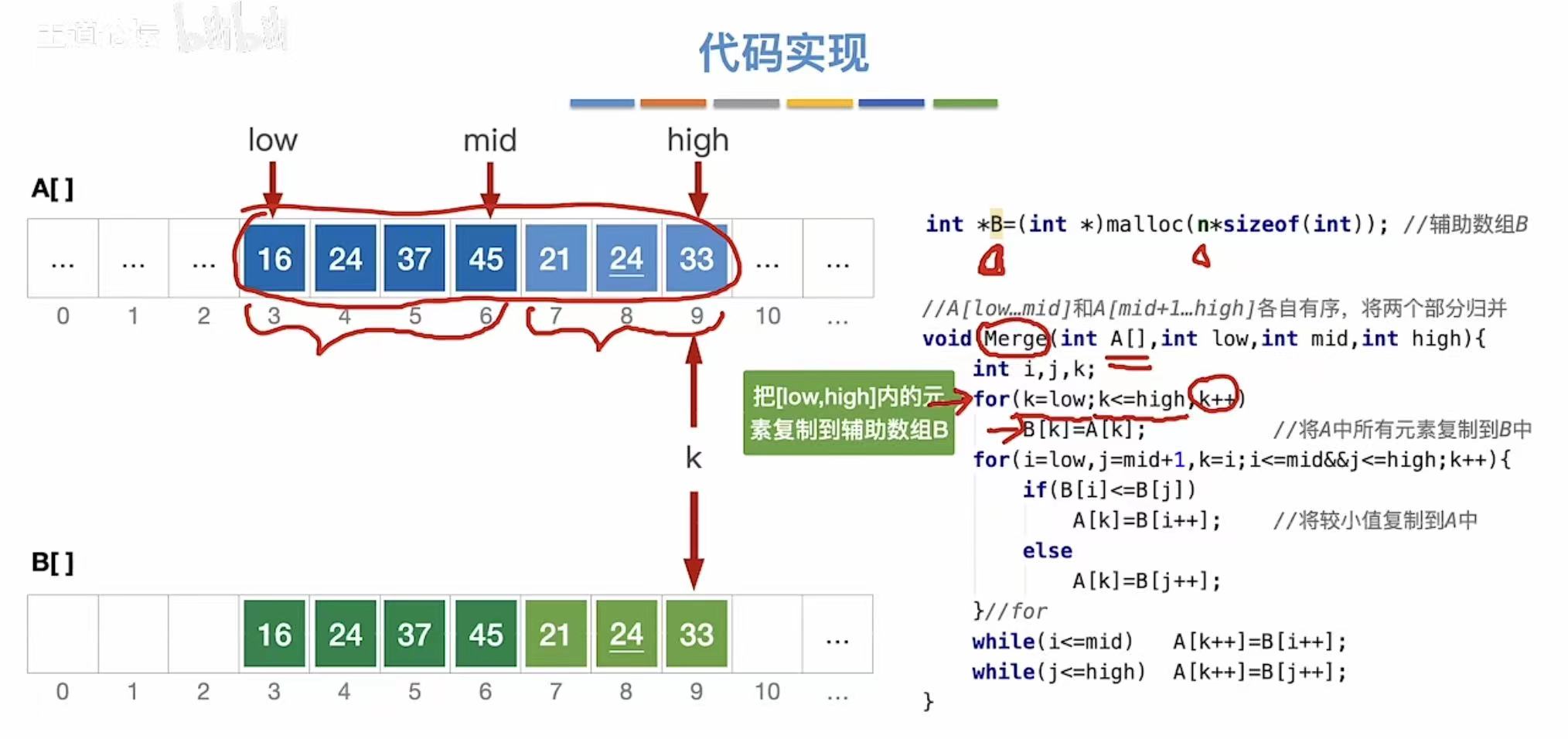
原数组:折半分出两个部分
辅助数组:得到两个数组
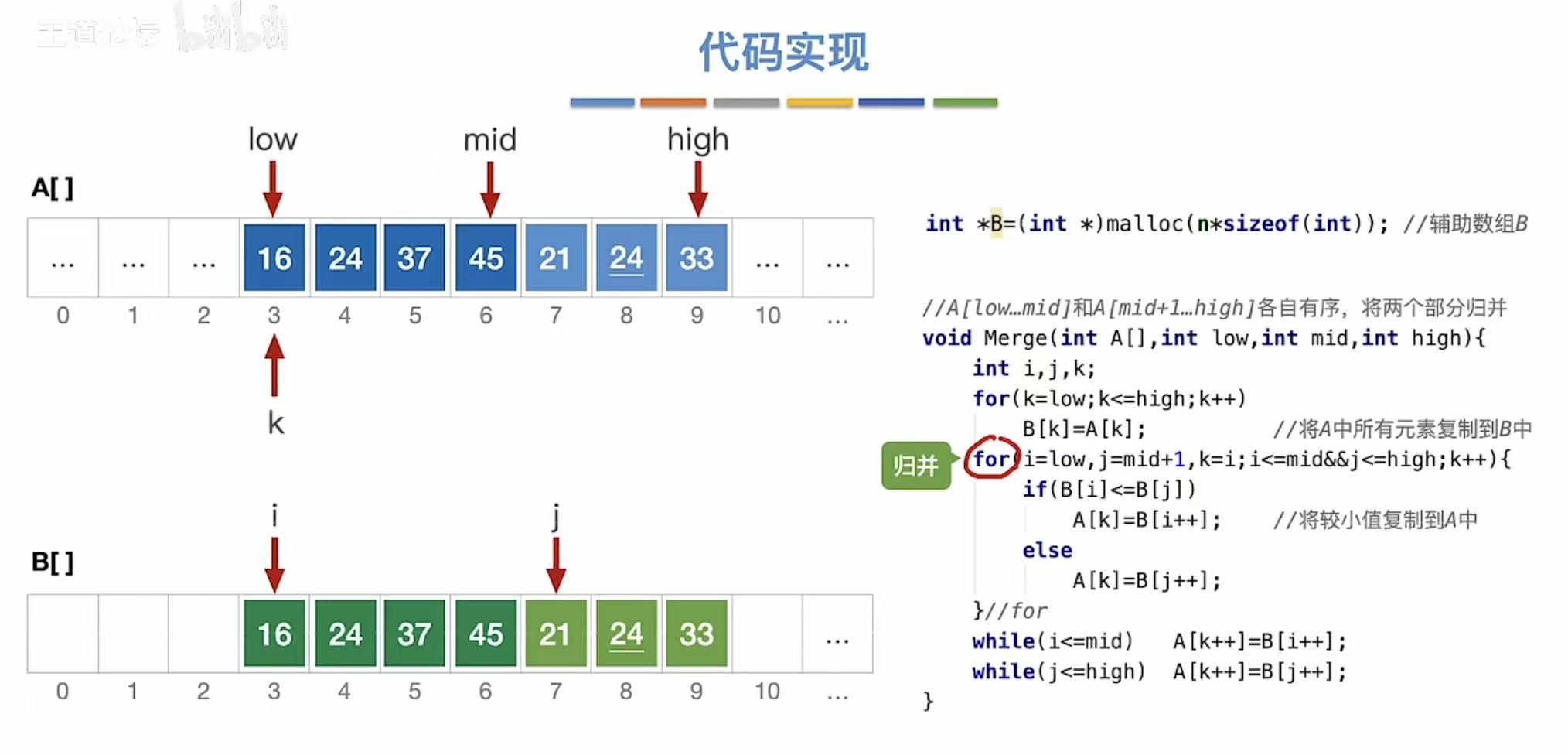
接下来就可以通过将辅助数组中的两个部分进行归并排序,将排序后的数组依次复制到原数组
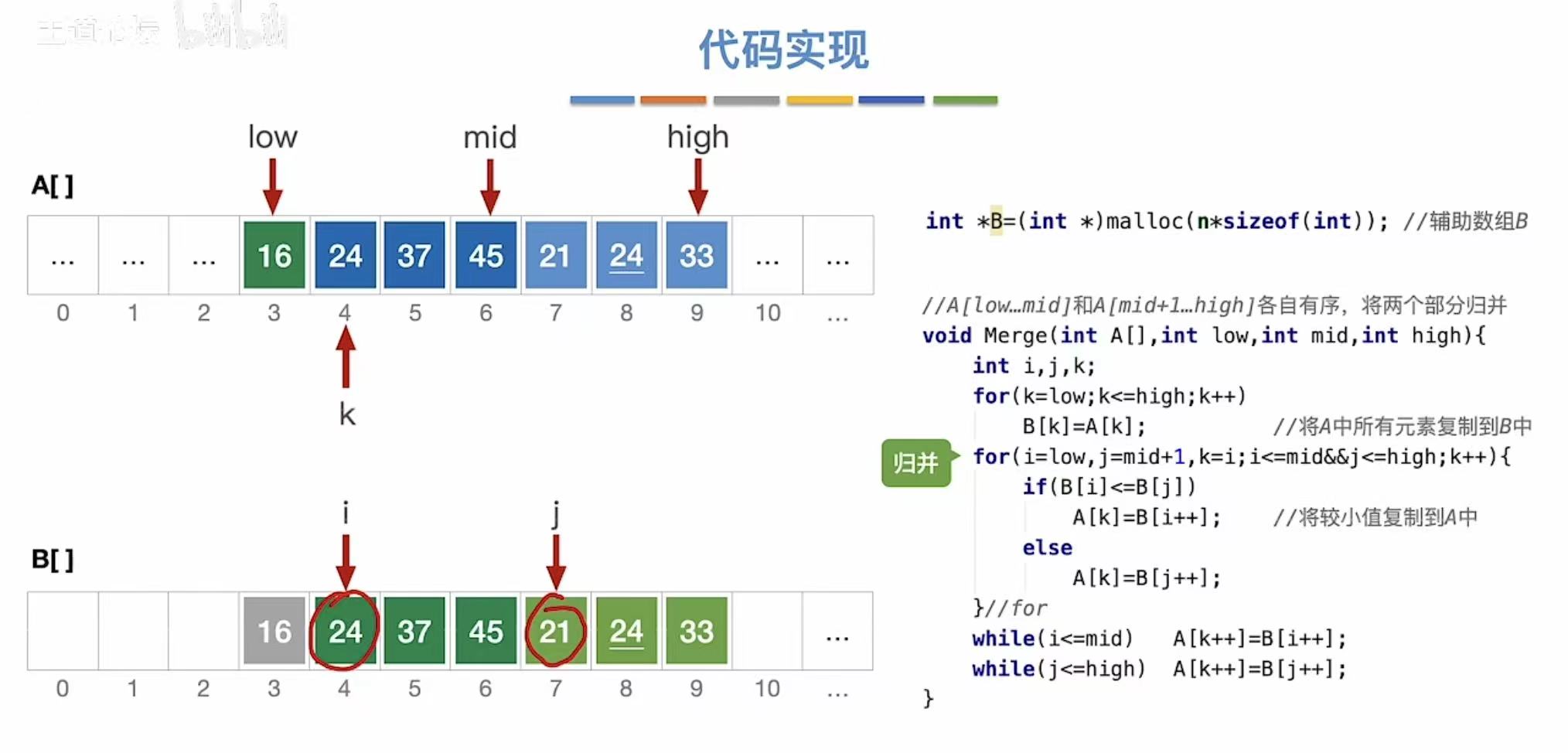
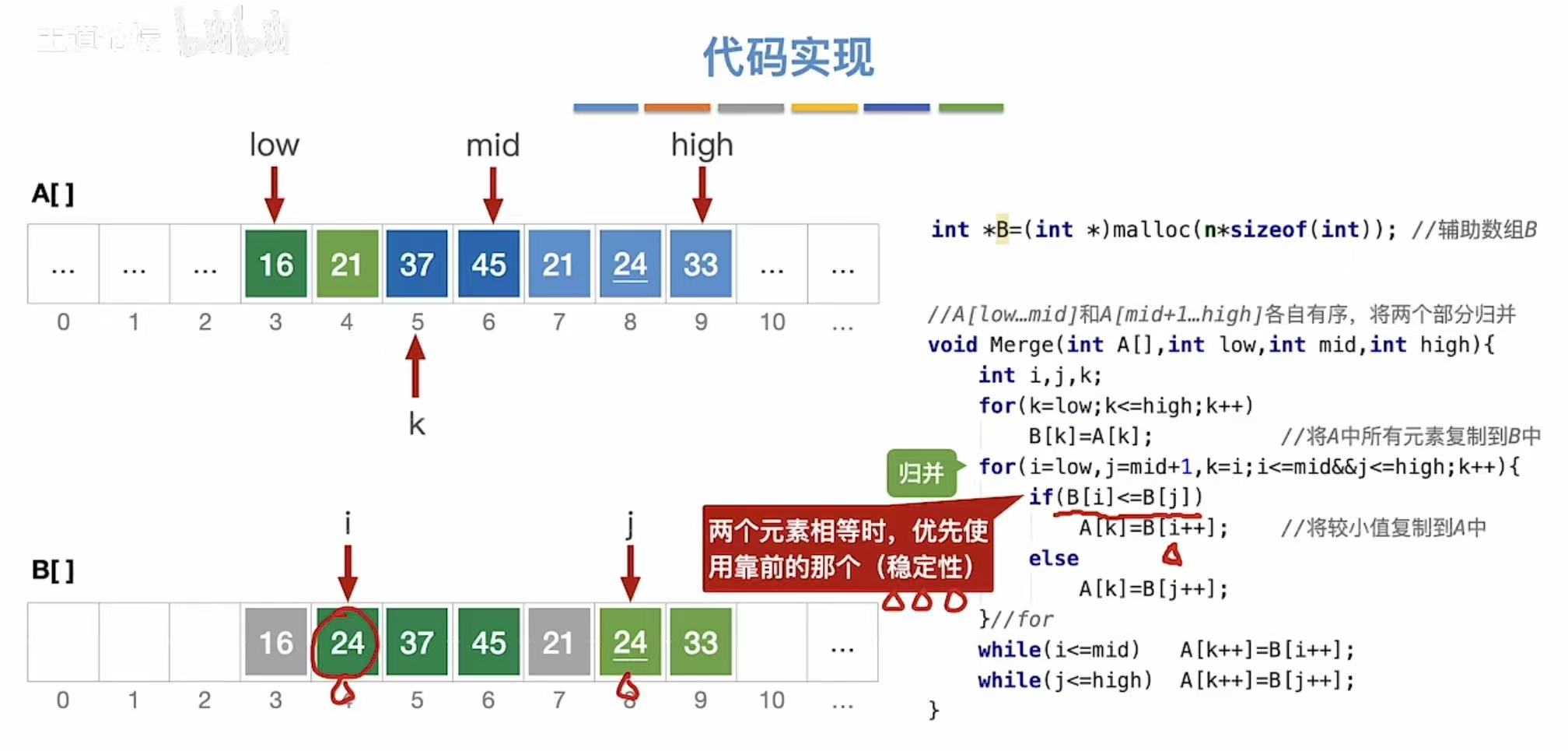
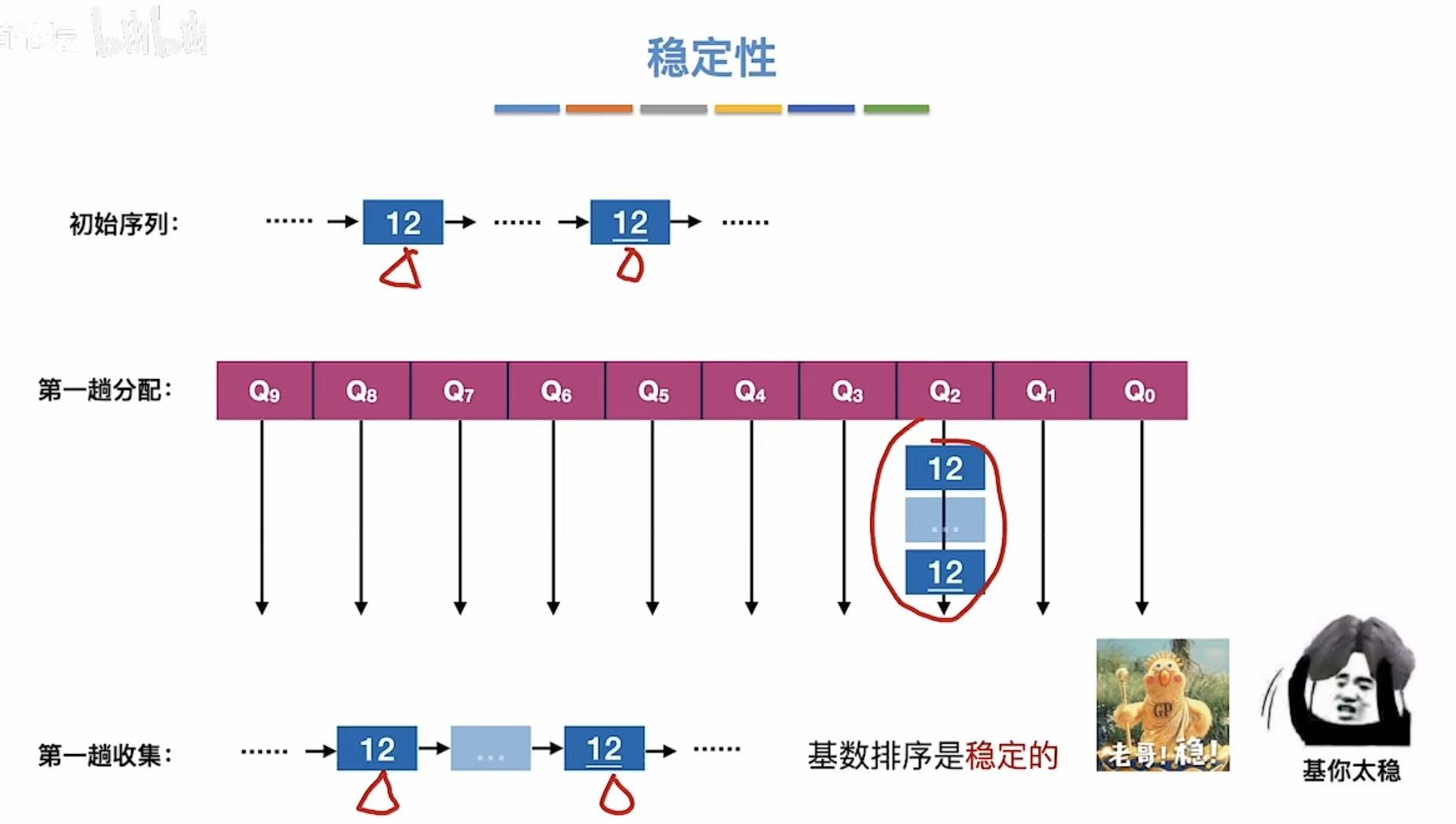
两个元素相等时,优先适用靠前的那个(由此可见归并排序是稳定的)
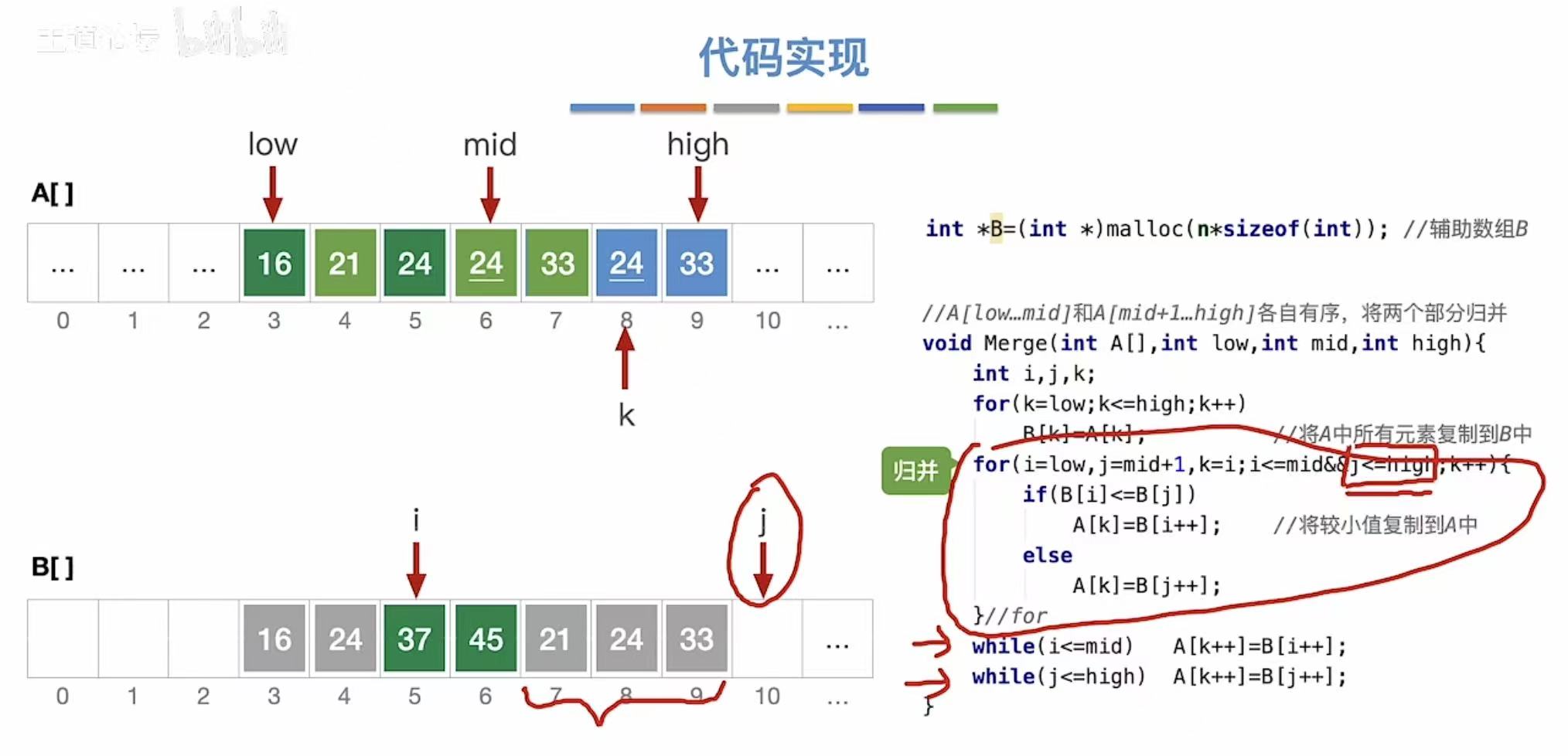
此时,辅助数组中第二个部分的已经全部排完序,所以另一组没处理完的就可以直接放回原数组
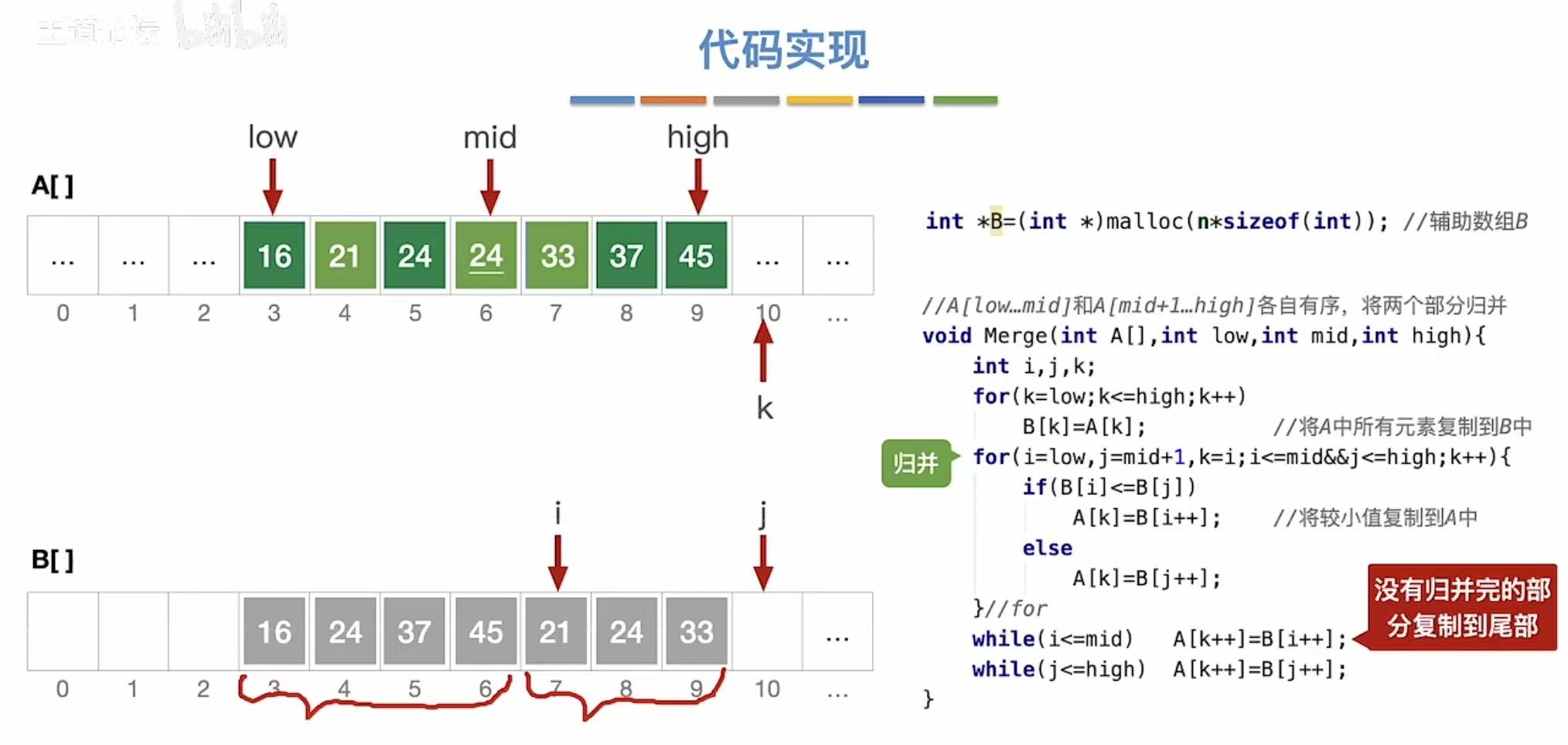
排序后:
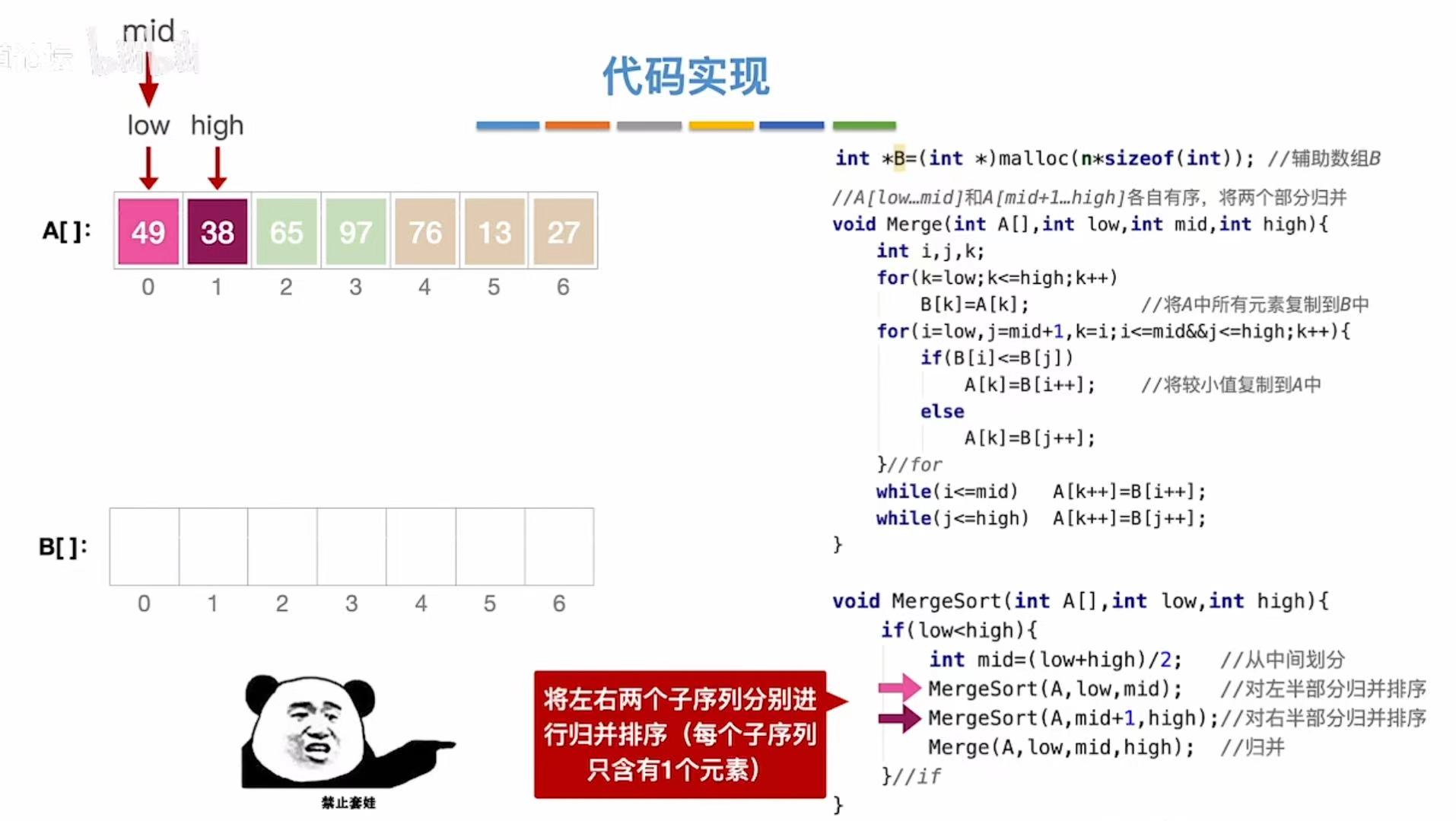
3.2 例2-完全乱序
逻辑:将原数组不断地分成两份然后进行排序
分为:4+3
4+3:分别有序之后再进行例1的归并排序
4:2+2 -->将左部分分成两份

2:1+1 将左部分的左部分分成两份

经历过递归套娃之后,终于可以排序了
正着递归分开,逆着递归回去就又合在一起了

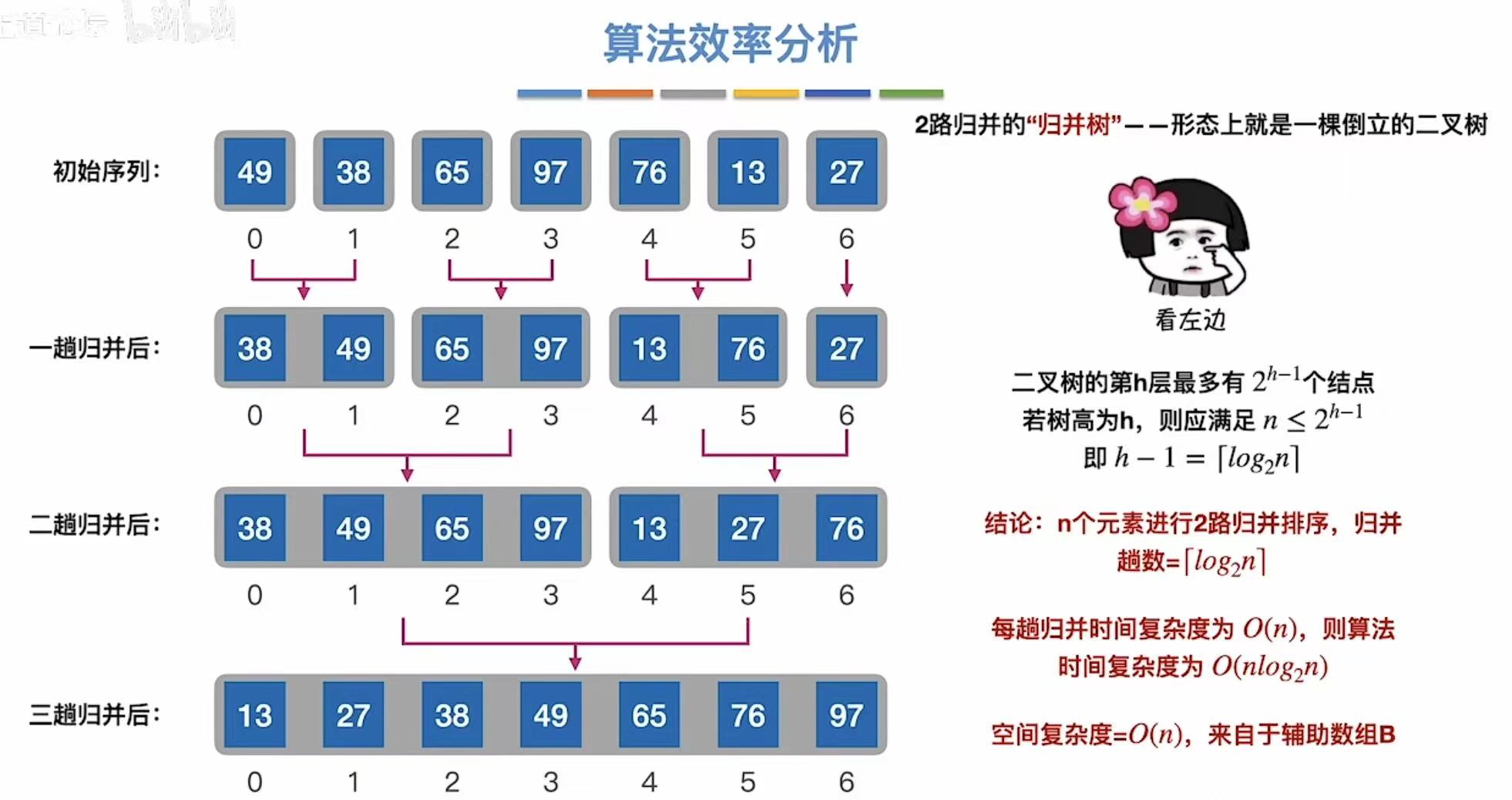
4. 算法效率分析
另:稳定
5. 小结
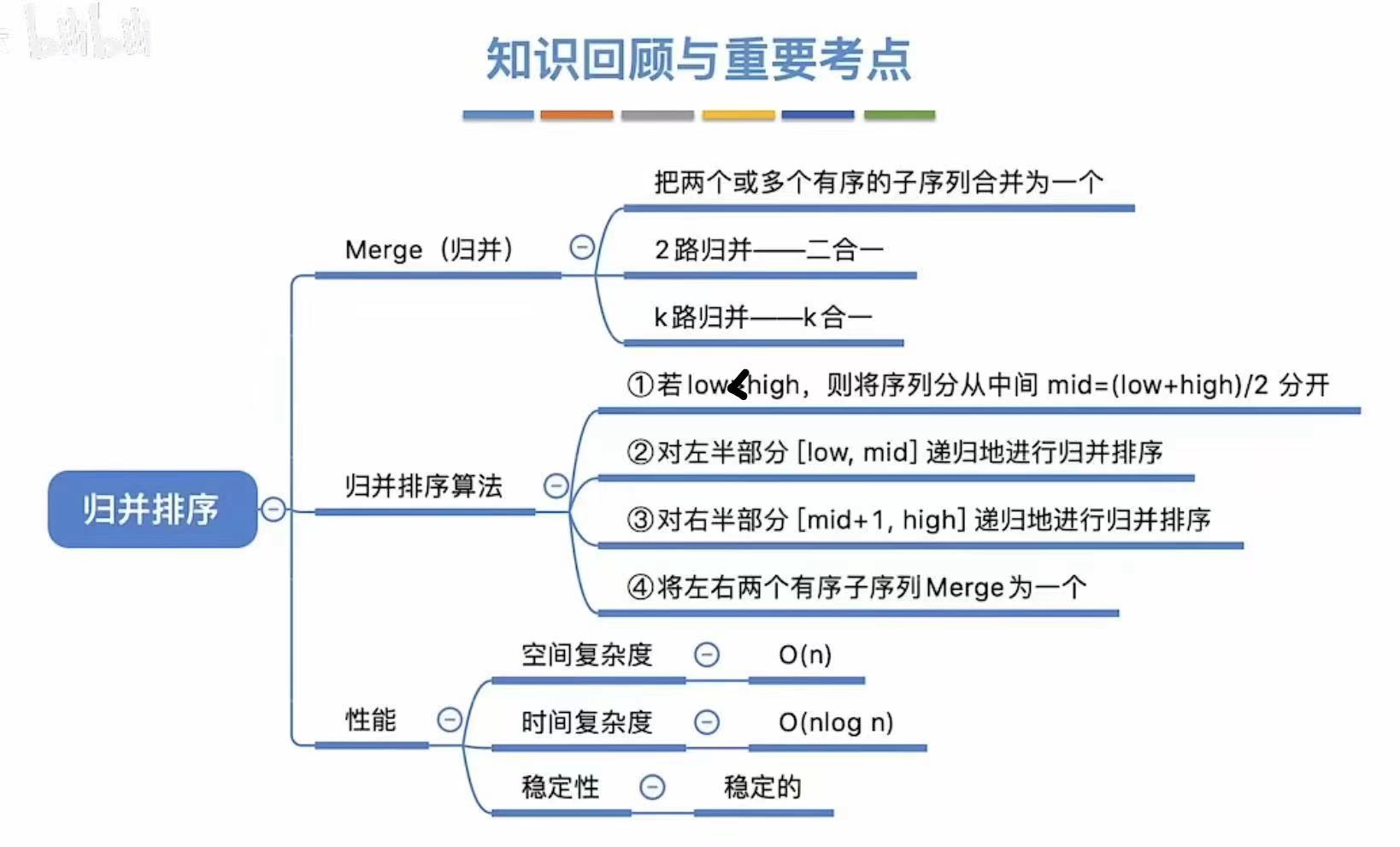
基数排序
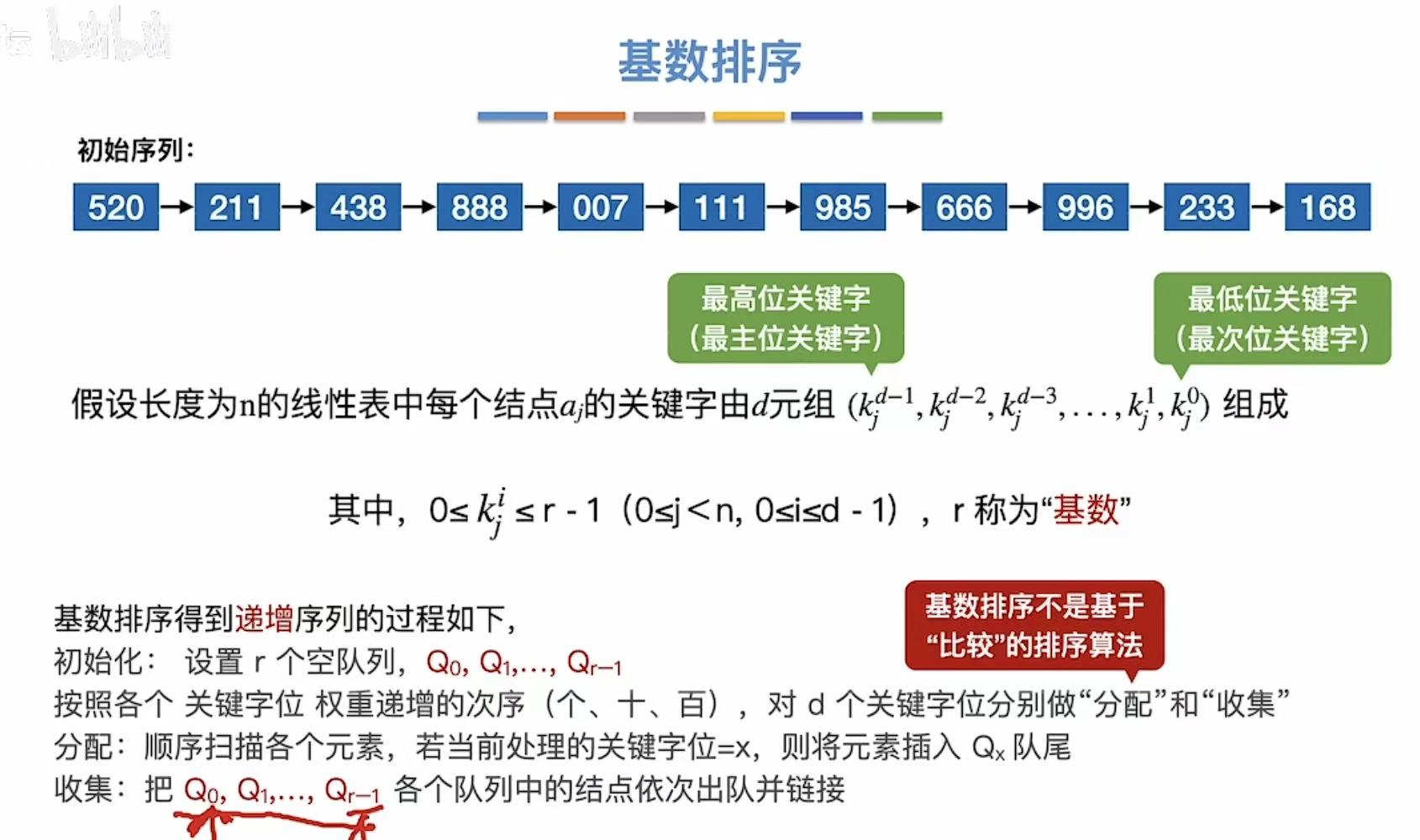
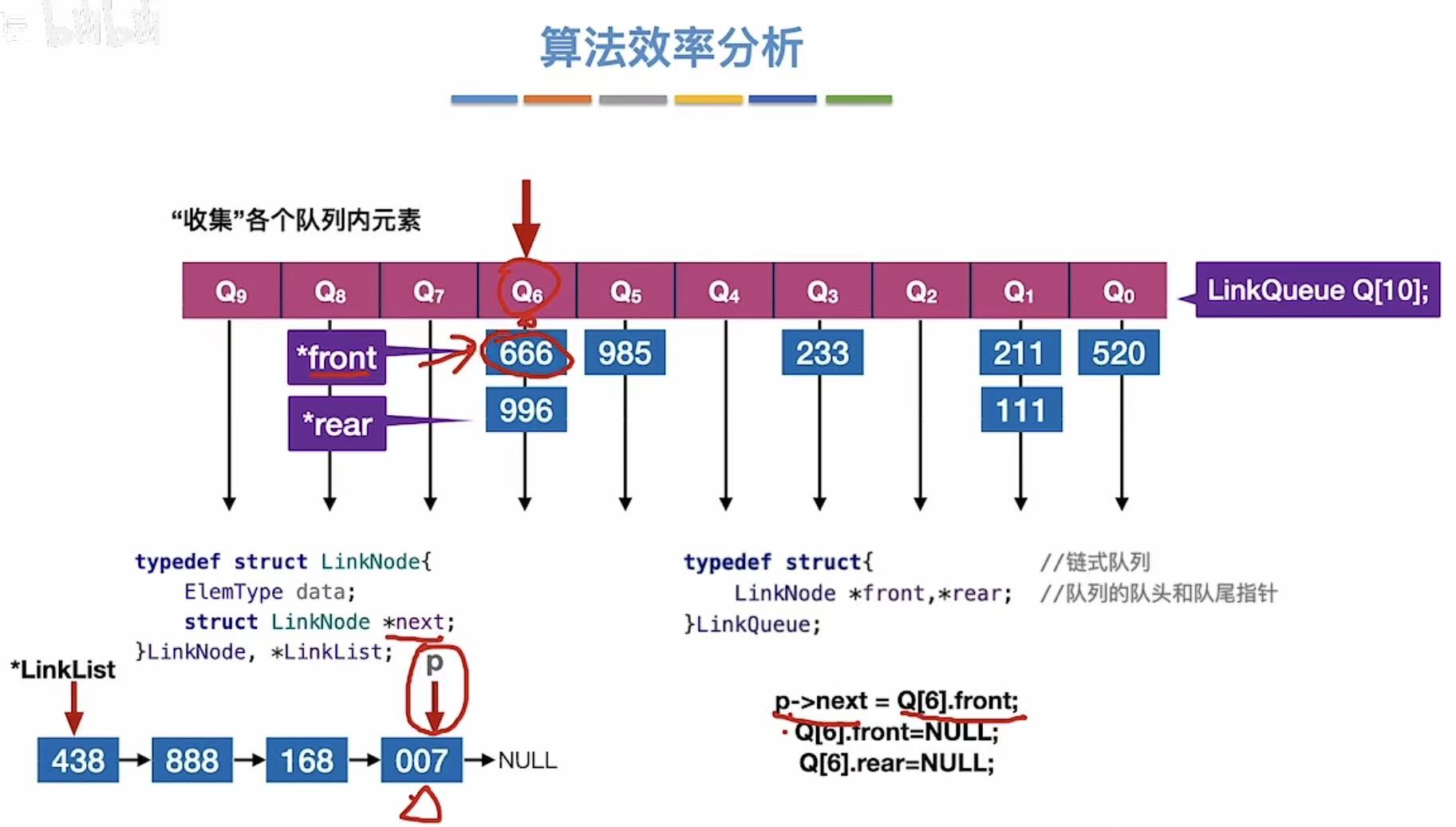
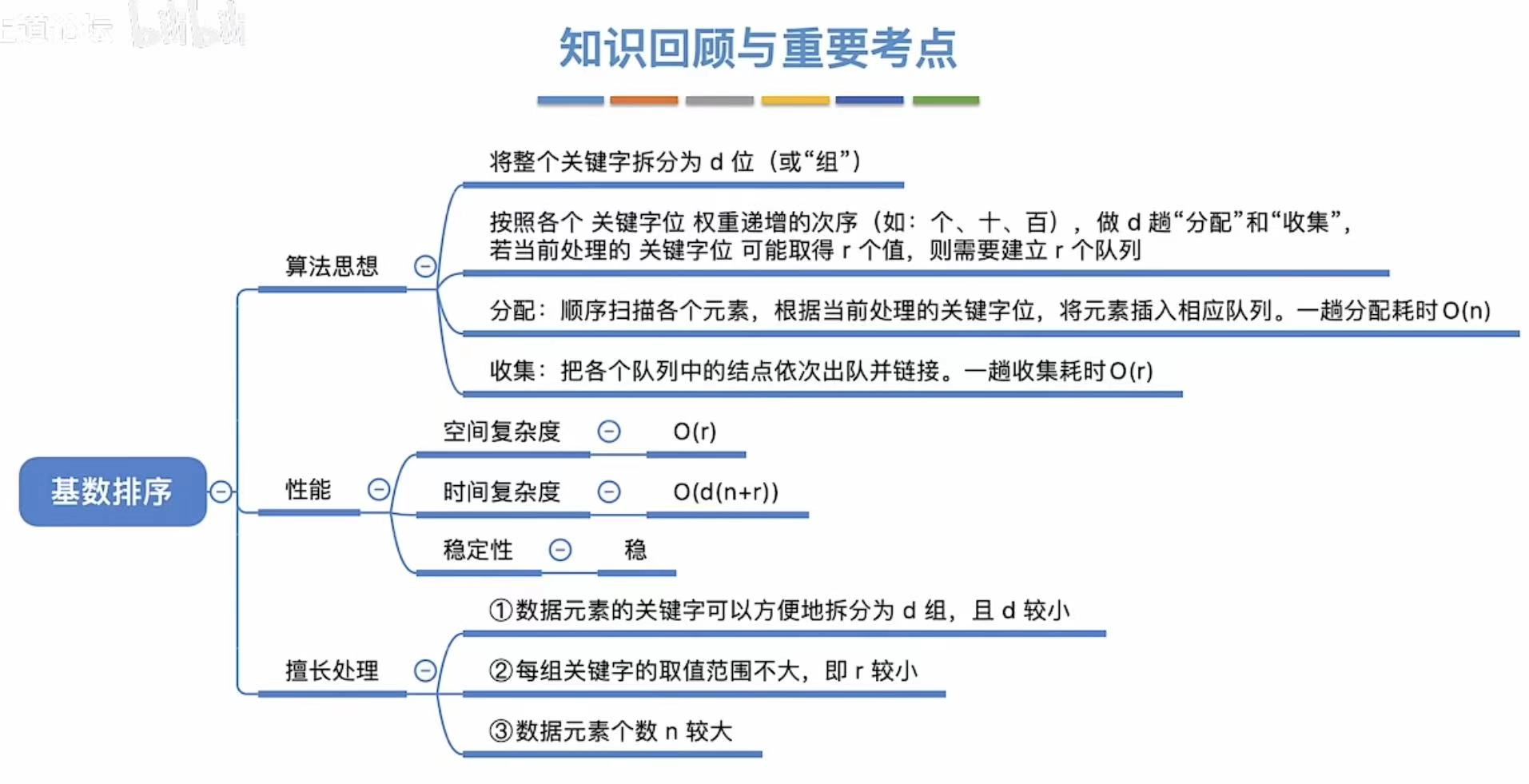
1. 算法思想
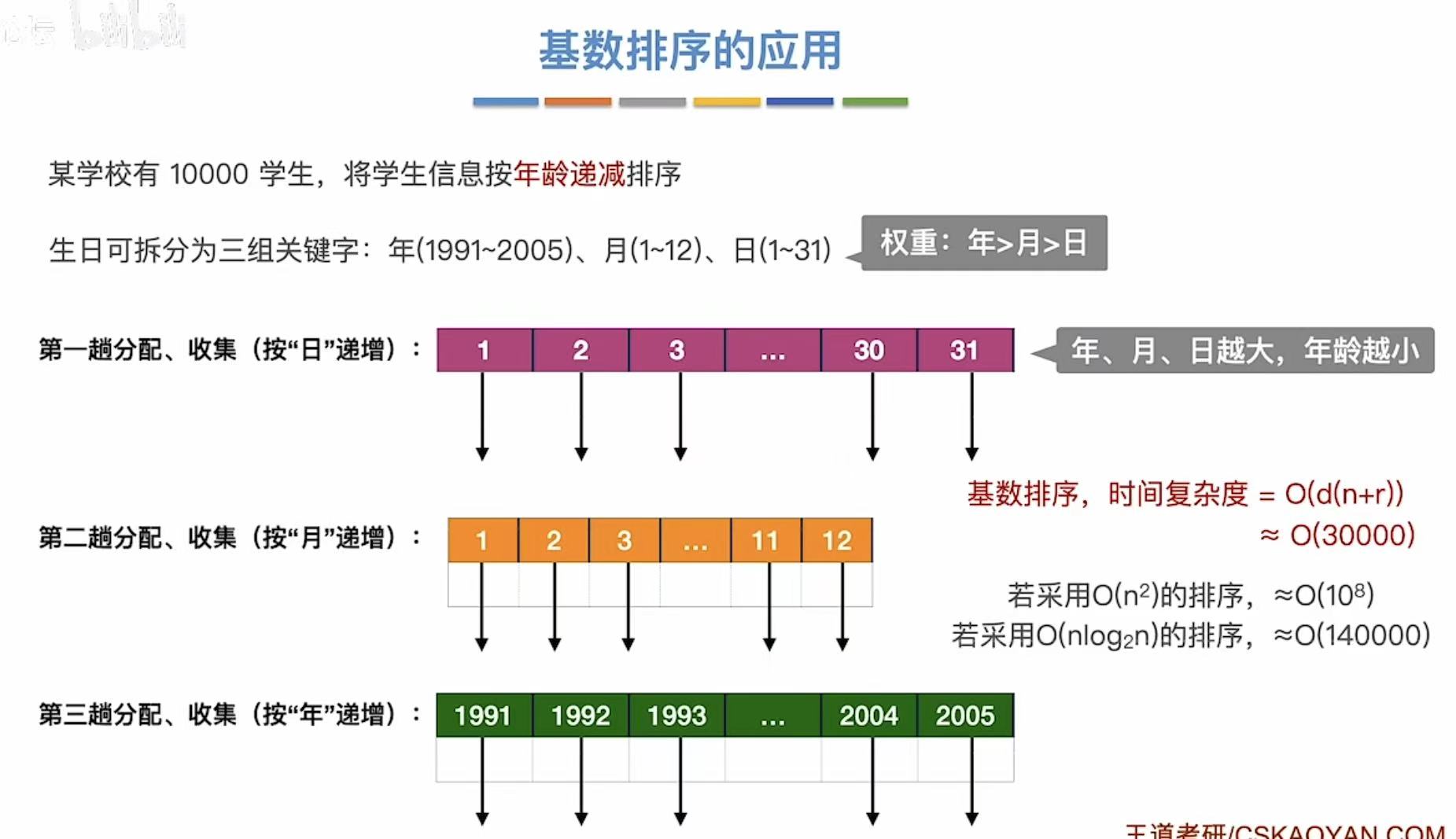
按照不同的指标分为一位一位地排列,比如:个十百、年月日
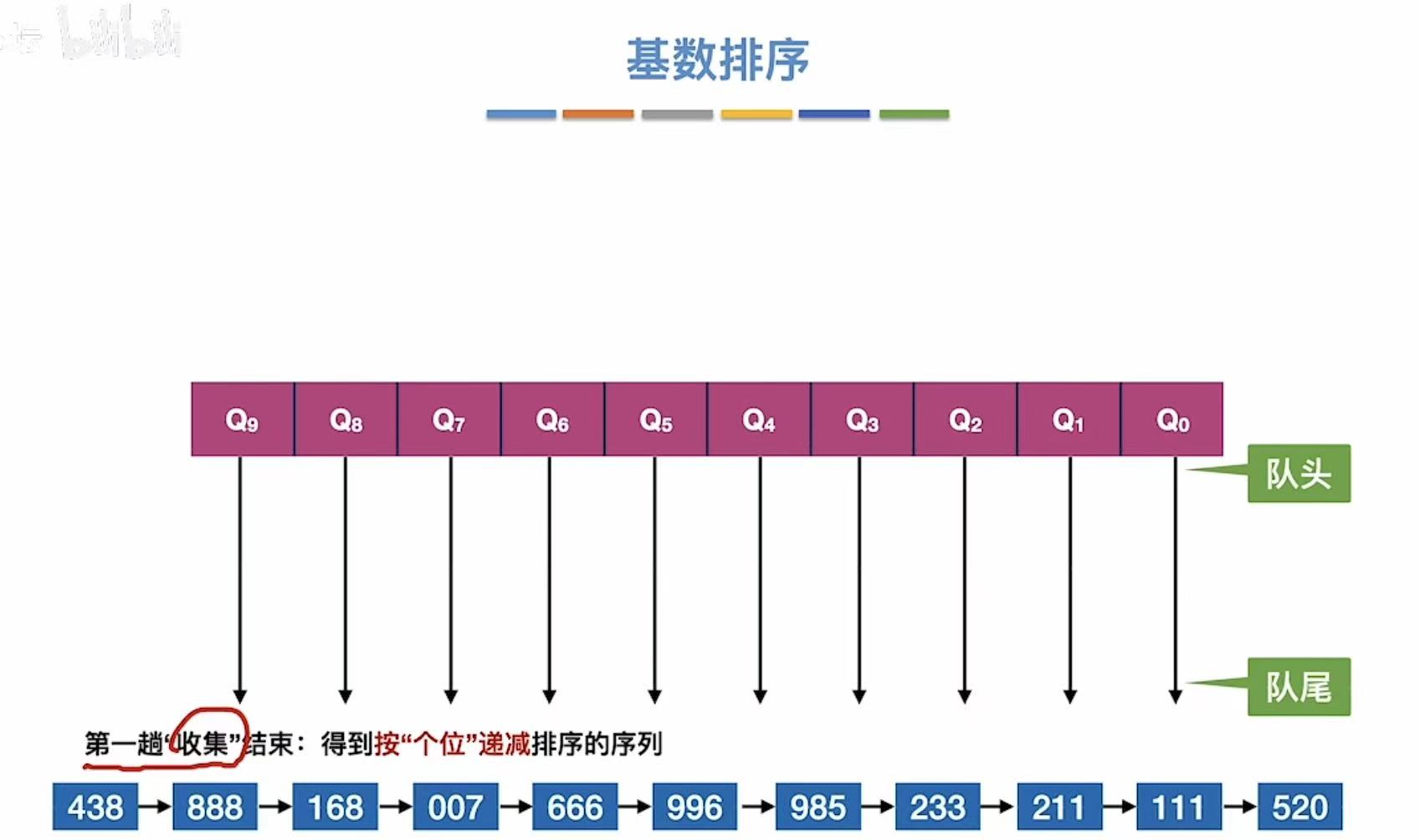
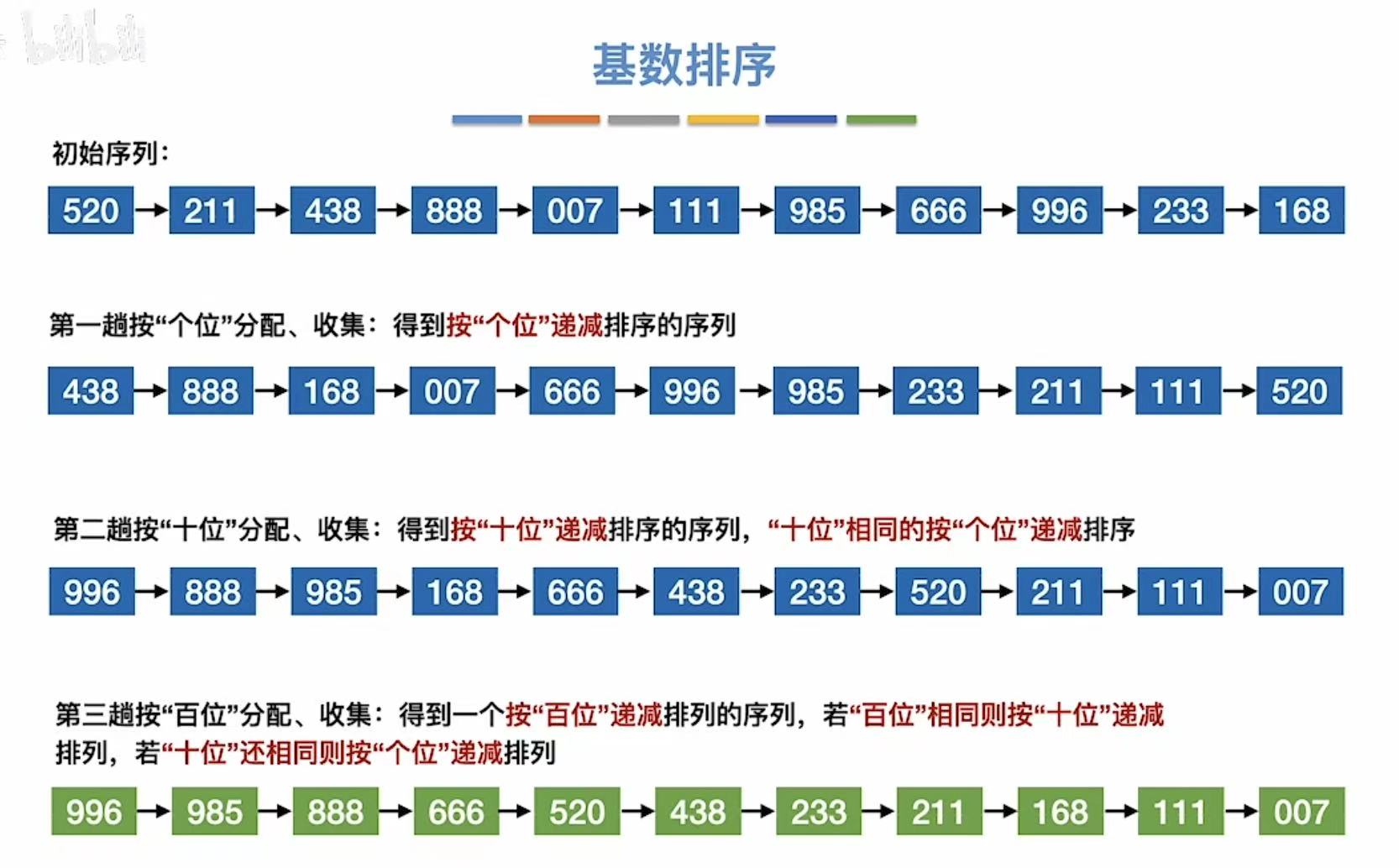
1.1 第一趟
首先将标准分为9~0
然后按照个位,单纯看数字的个位,把数字串到对应的位置
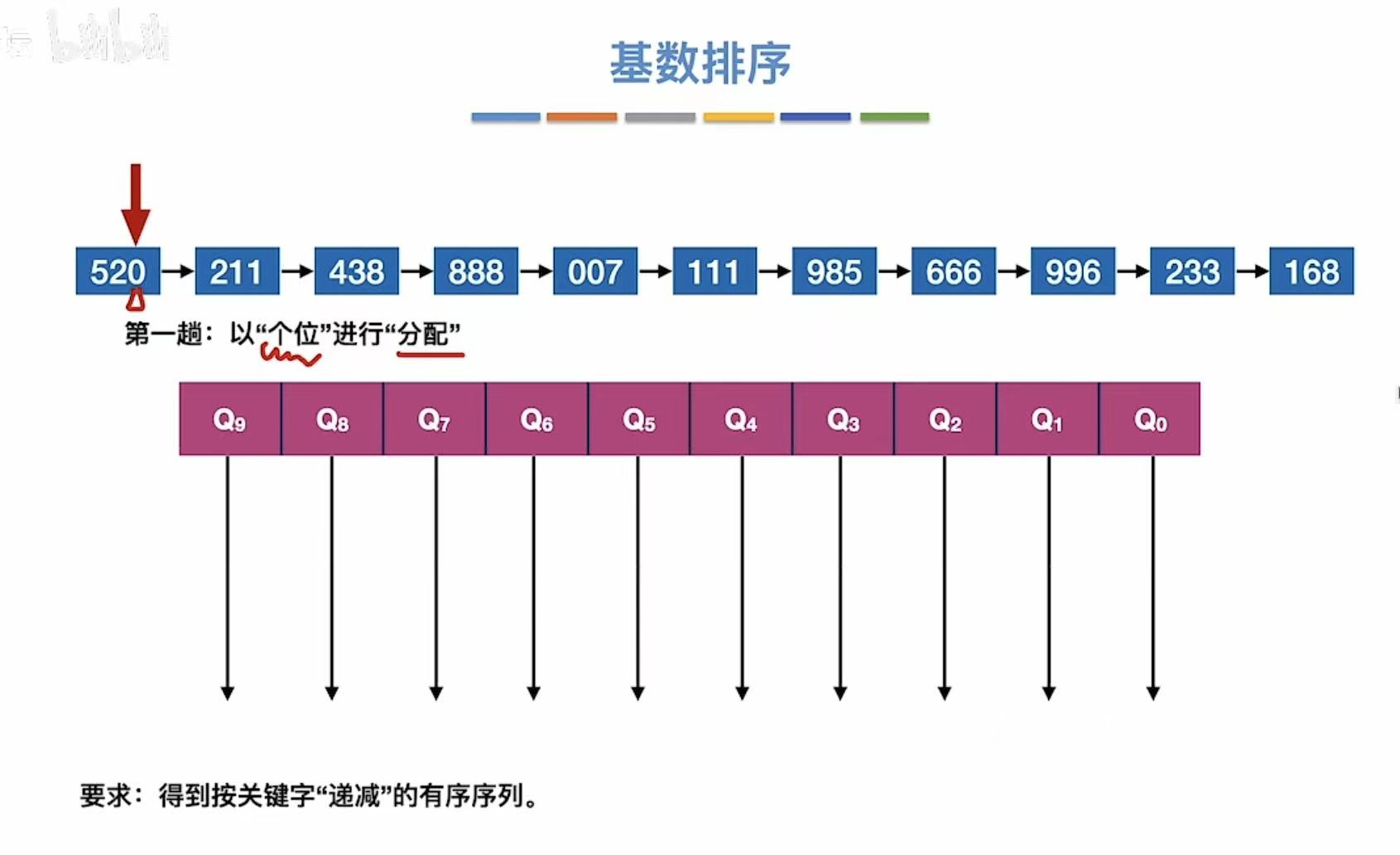
比如:520的个位是0,就把他串到Q0的位置上
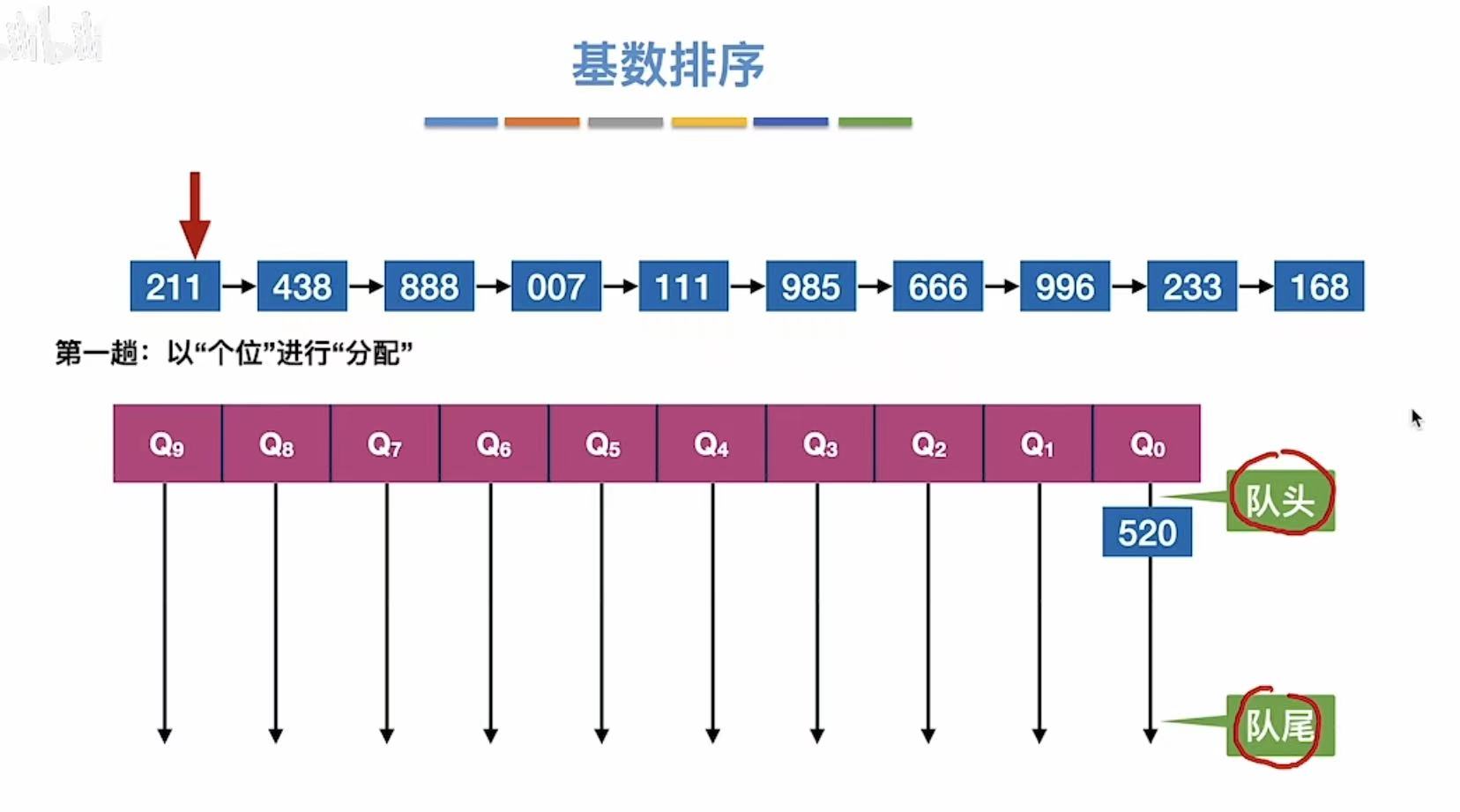
所有数字都串完后:
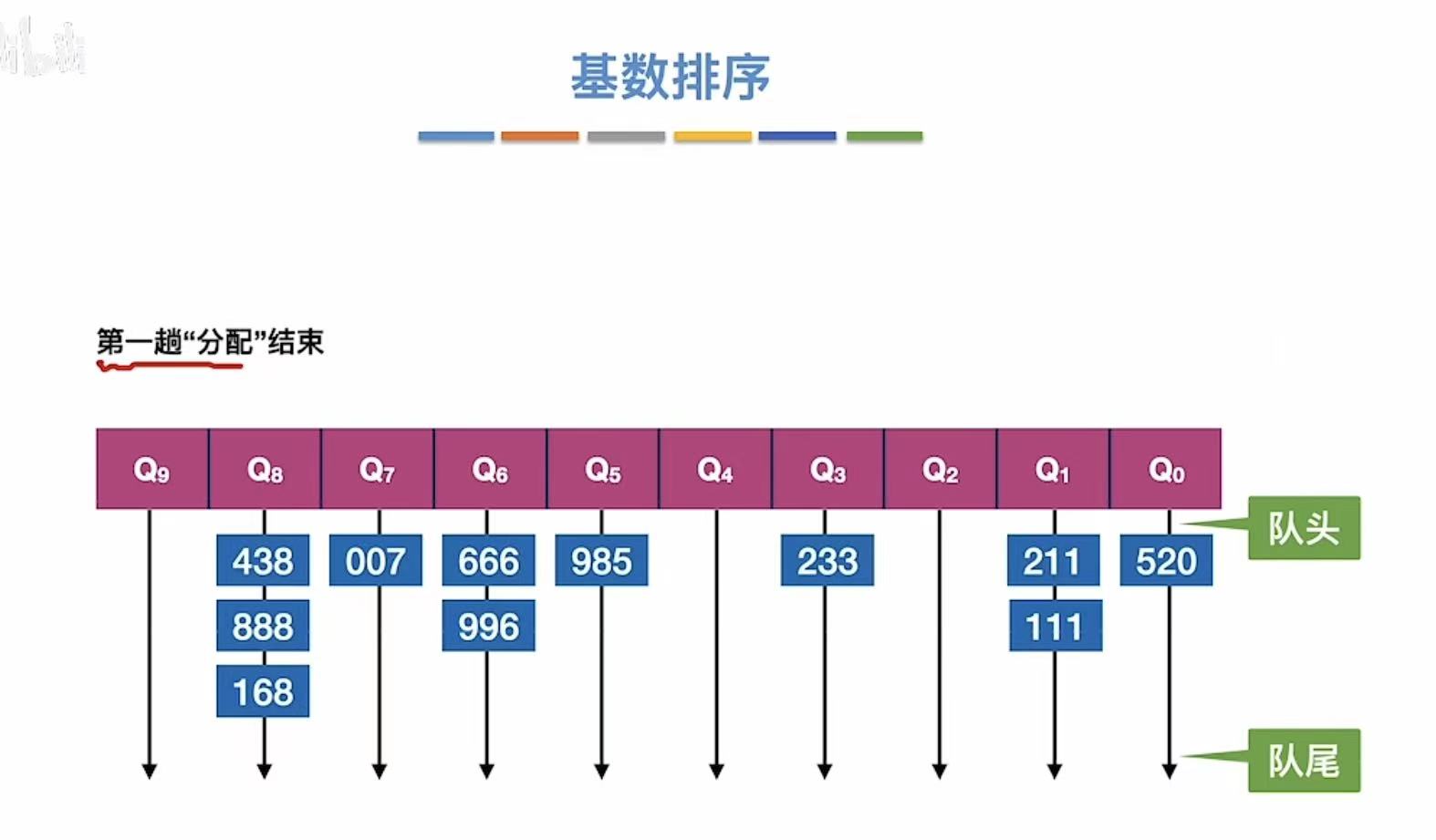
按照队头队尾把数字都拿下来,串成一个长串
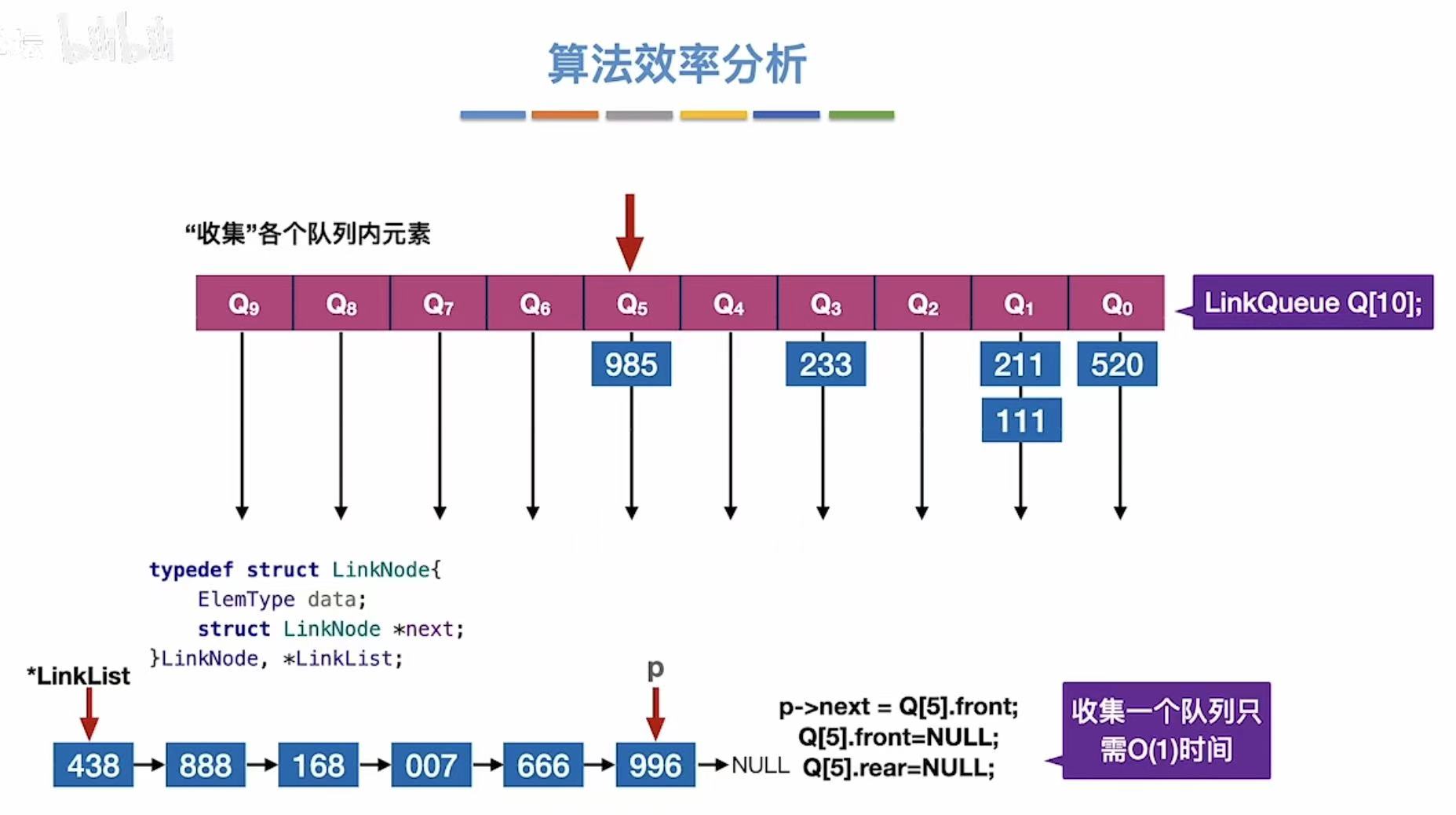
1.2 第二趟
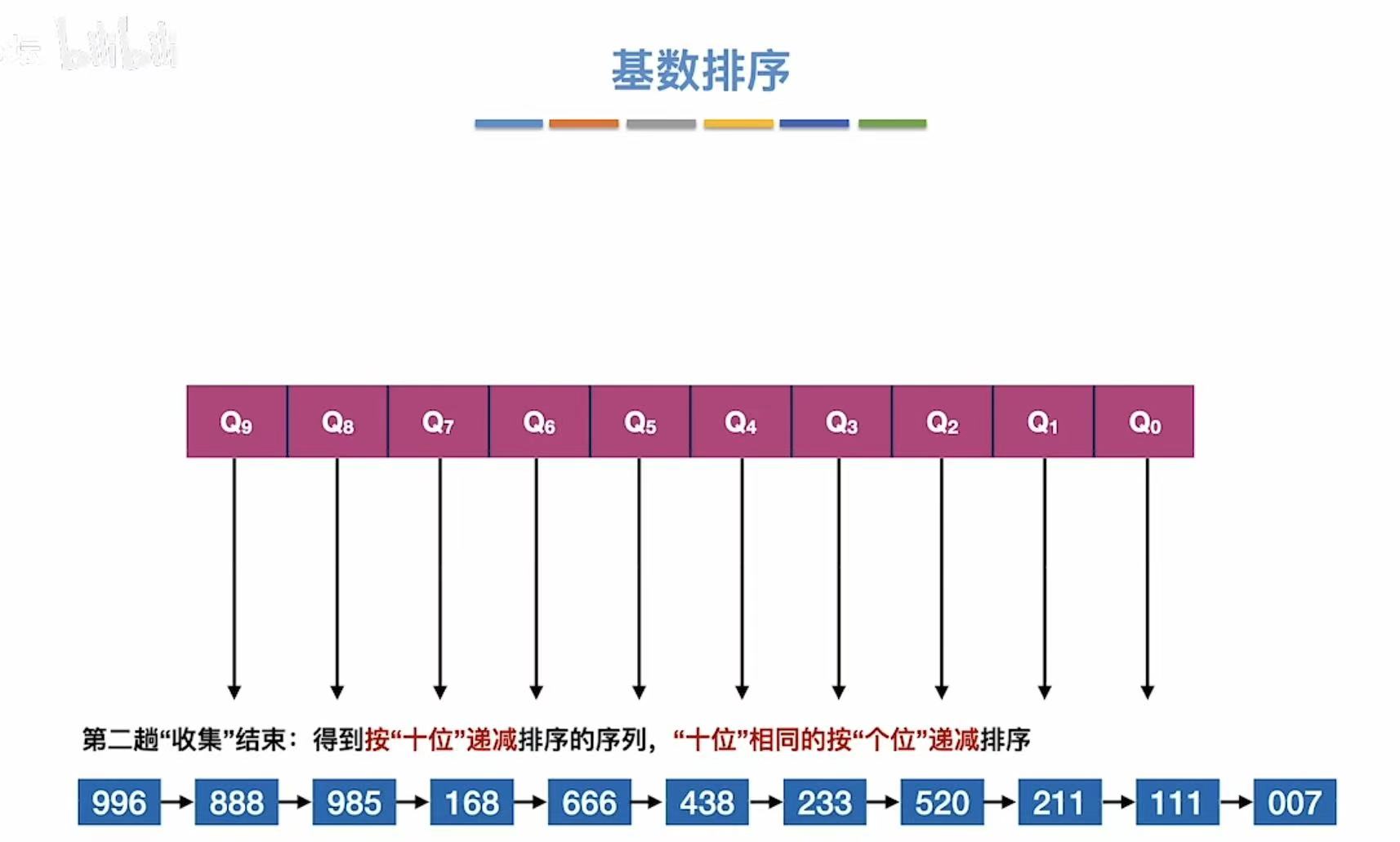
按照十位:
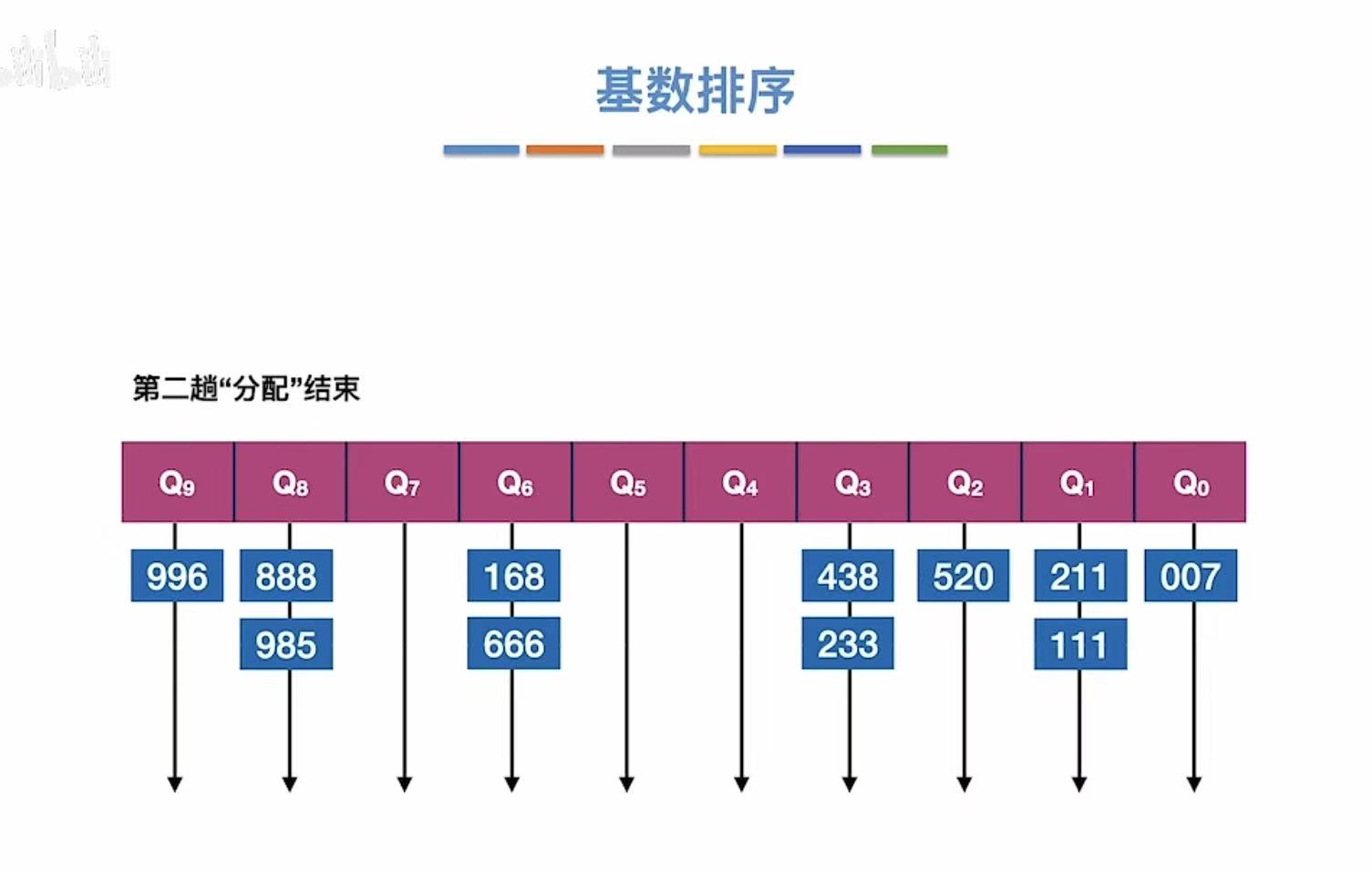
结束后:
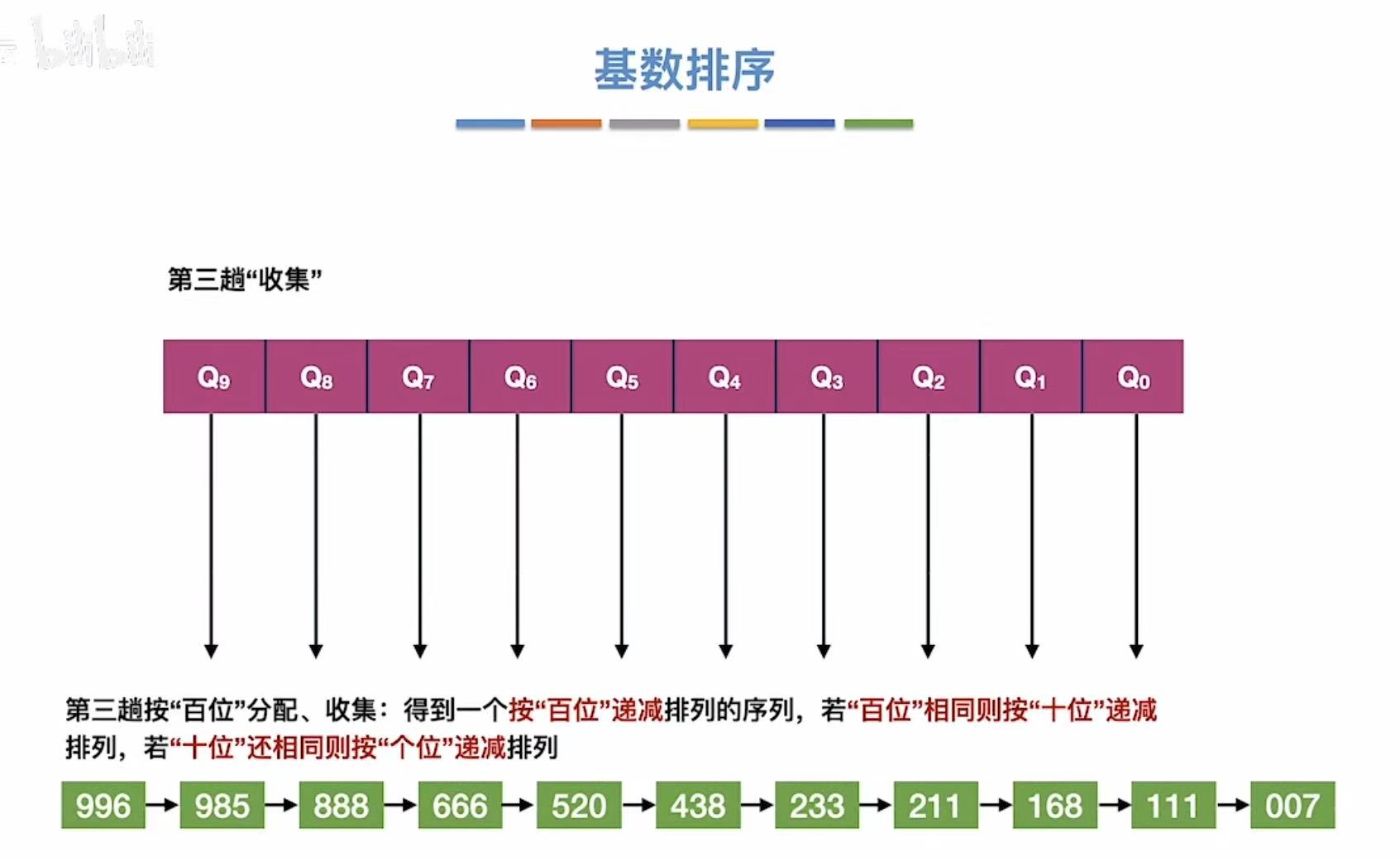
1.3 第三趟
按照百位:
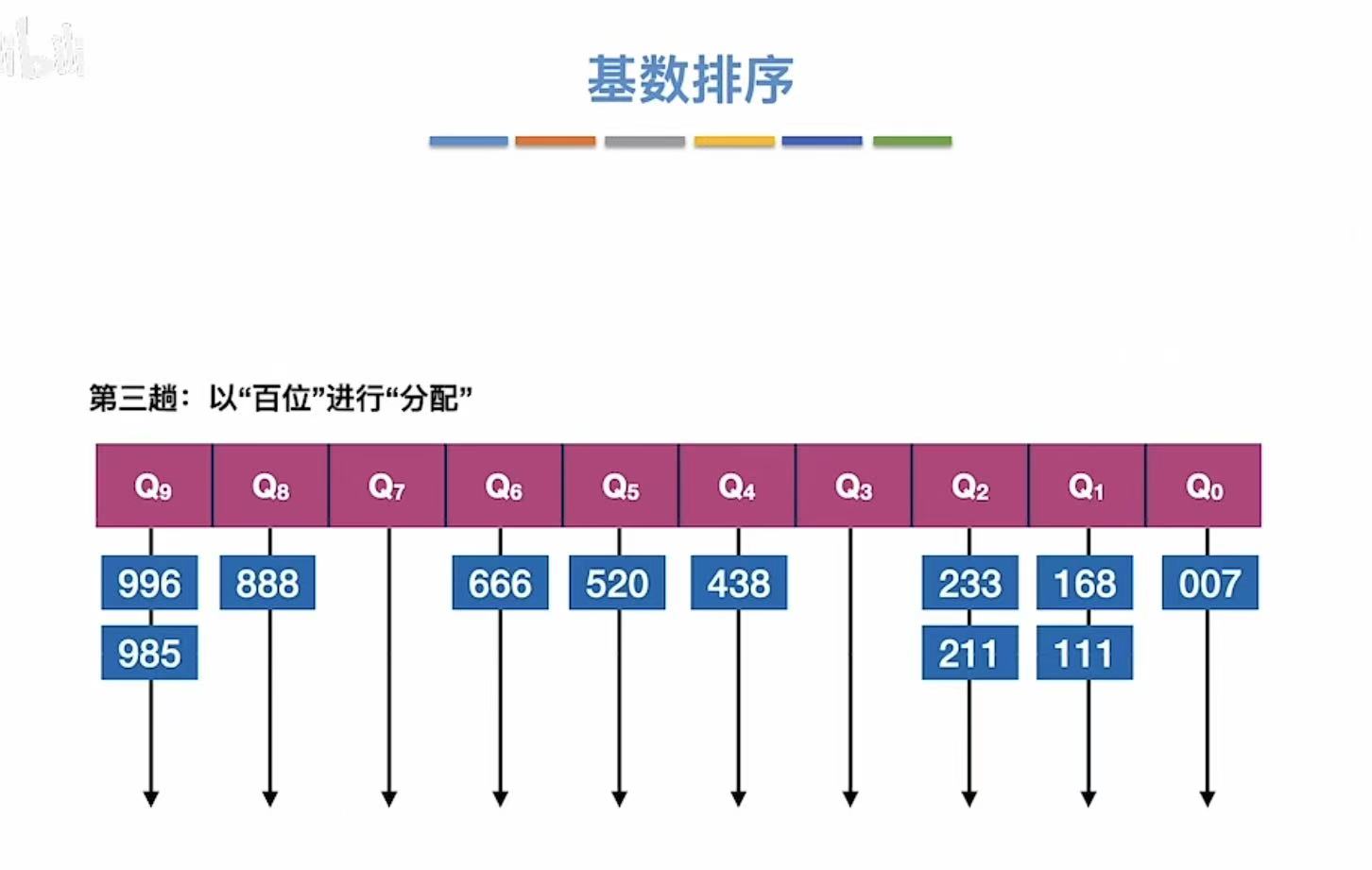
结束后:
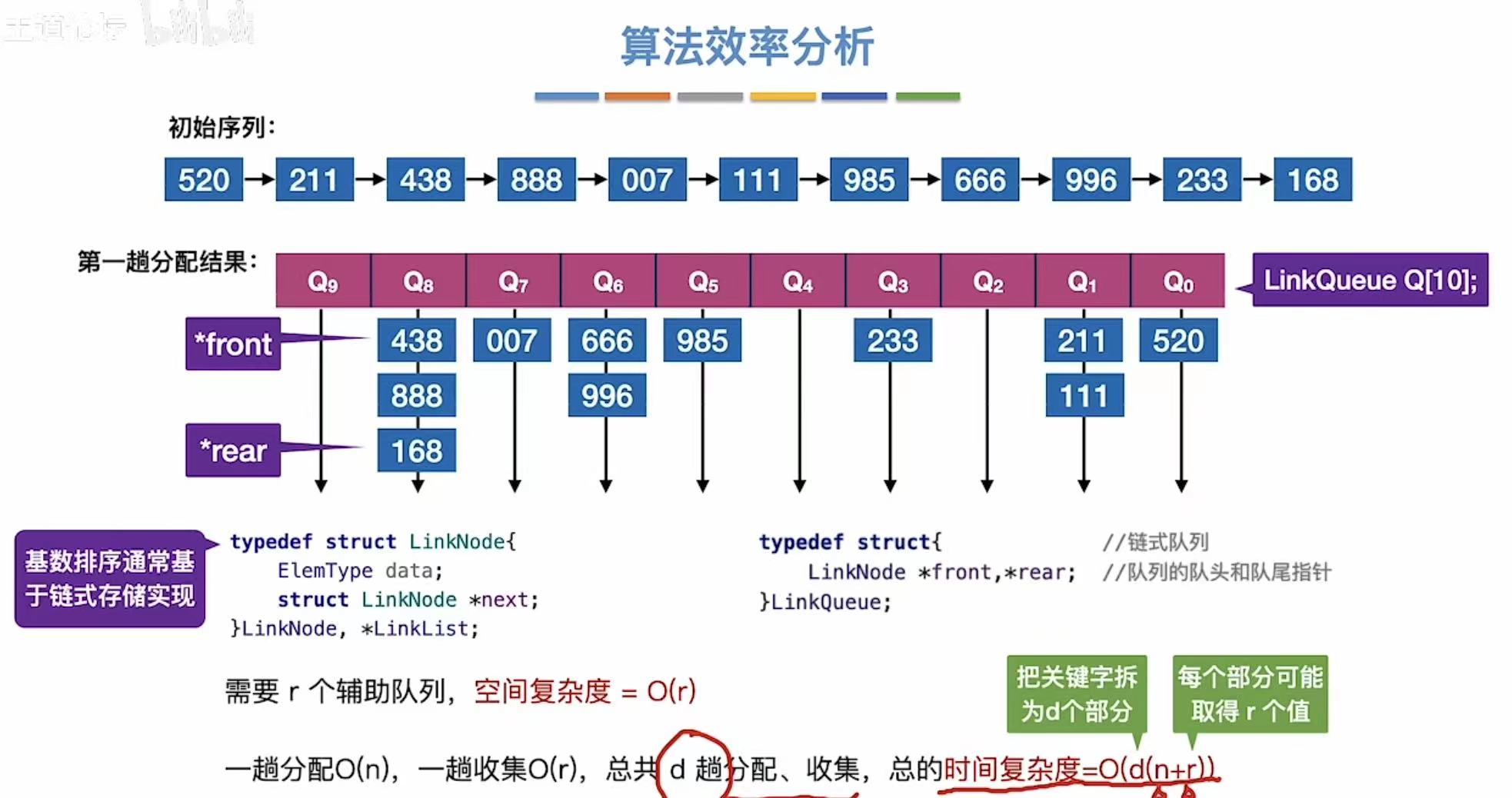
1.4 小总结
- 最高位关键字:百位
- 最低位关键字:个位
- 基数r:0~9,就是10个数字
2. 算法效率分析
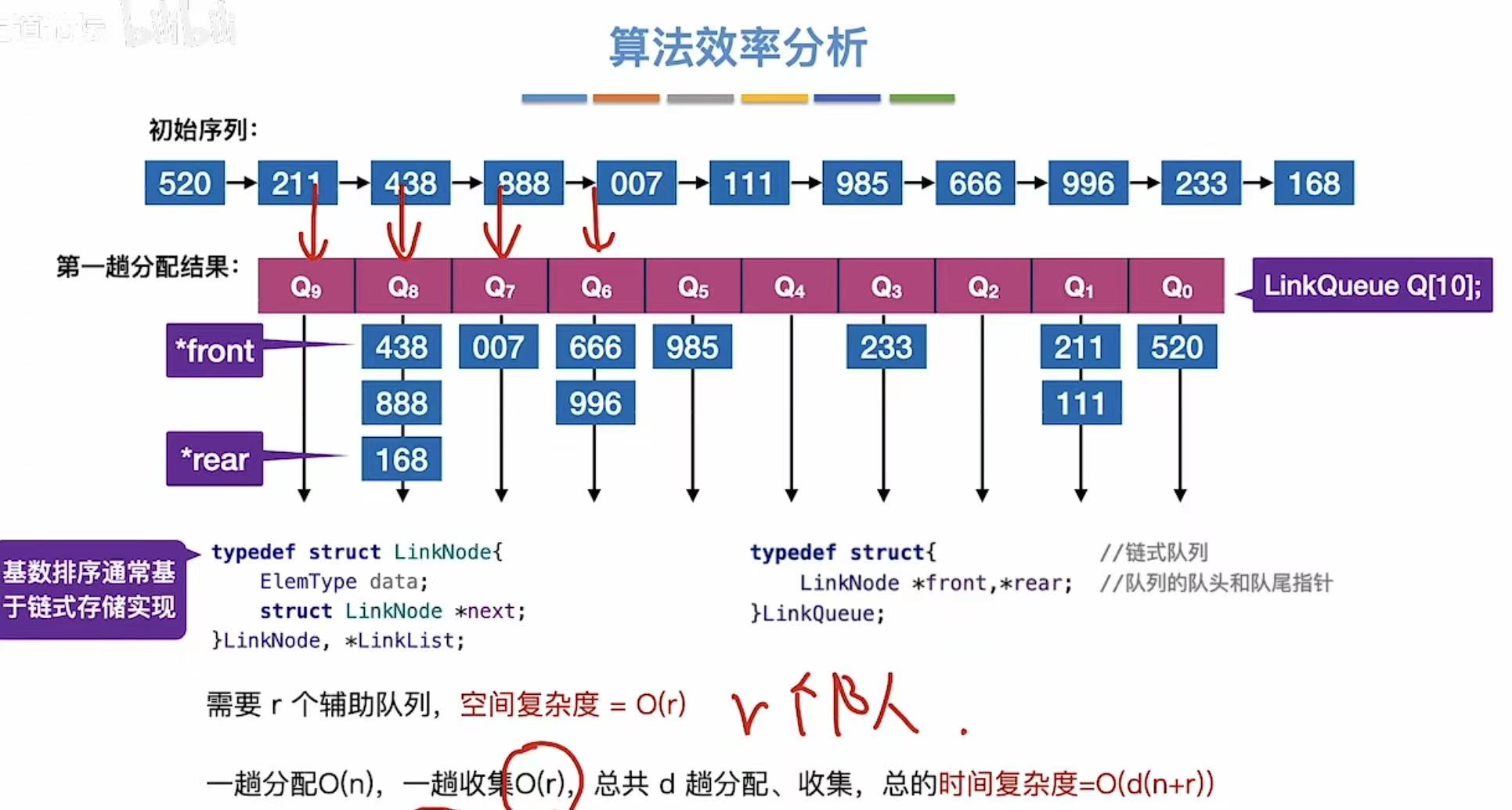
结论:
- 空间复杂度:O®
- 时间复杂度:O(d(n+r))
- 稳定
3. 基数排序的应用
如图,可以通过年月日的划分进行排序:
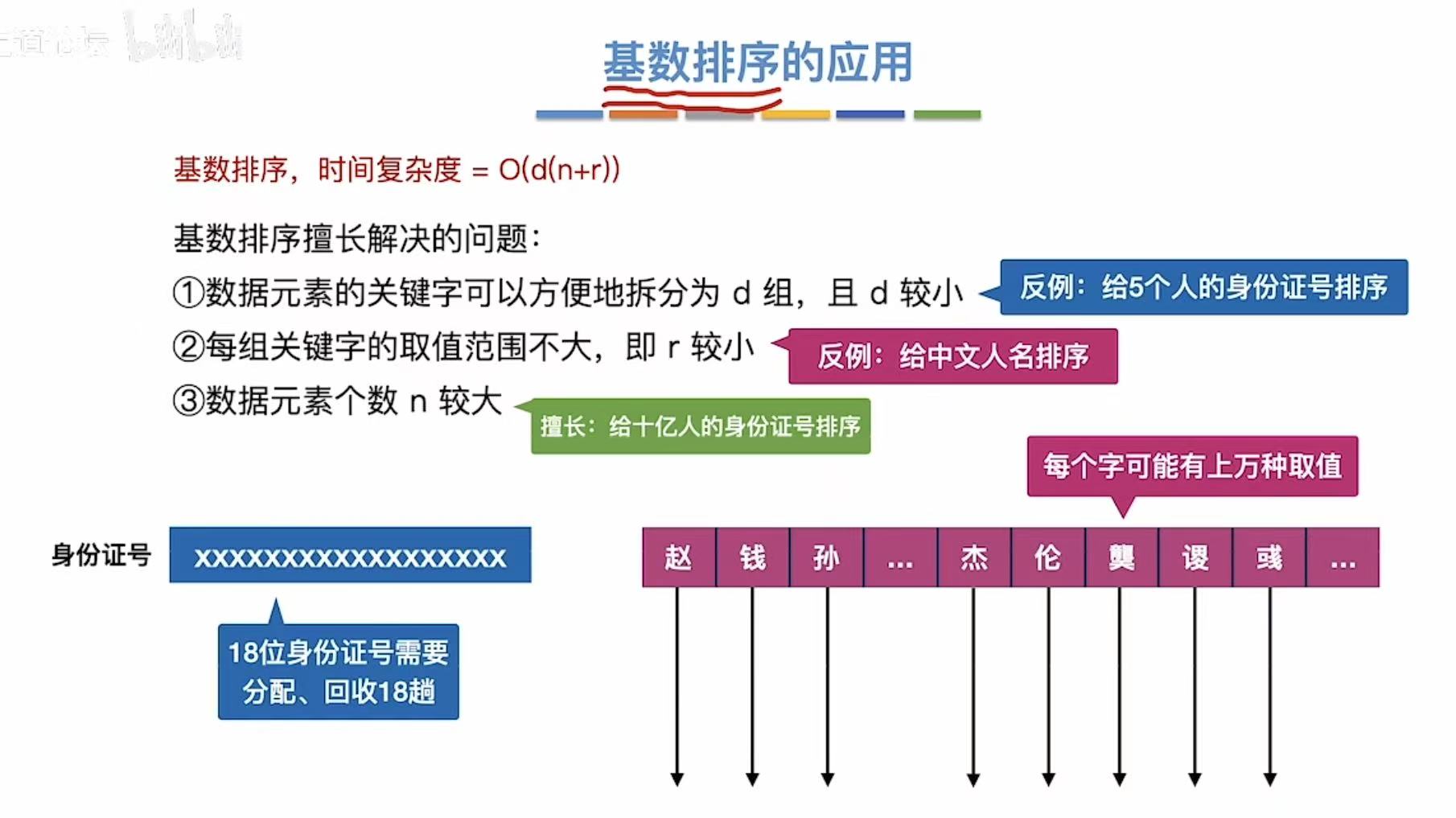
基数排序擅长解决的问题:

- 给5个人的身份证号排序:5<身份证号的位数,没必要
- 给中文人名排序:人的个数<浩如烟海的文字,没必要
- 给十亿人的身份证号排序:十亿>身份证号的位数,太好用了!!!
4. 小结
计数排序
大纲虽然没要求,但是默认我们会

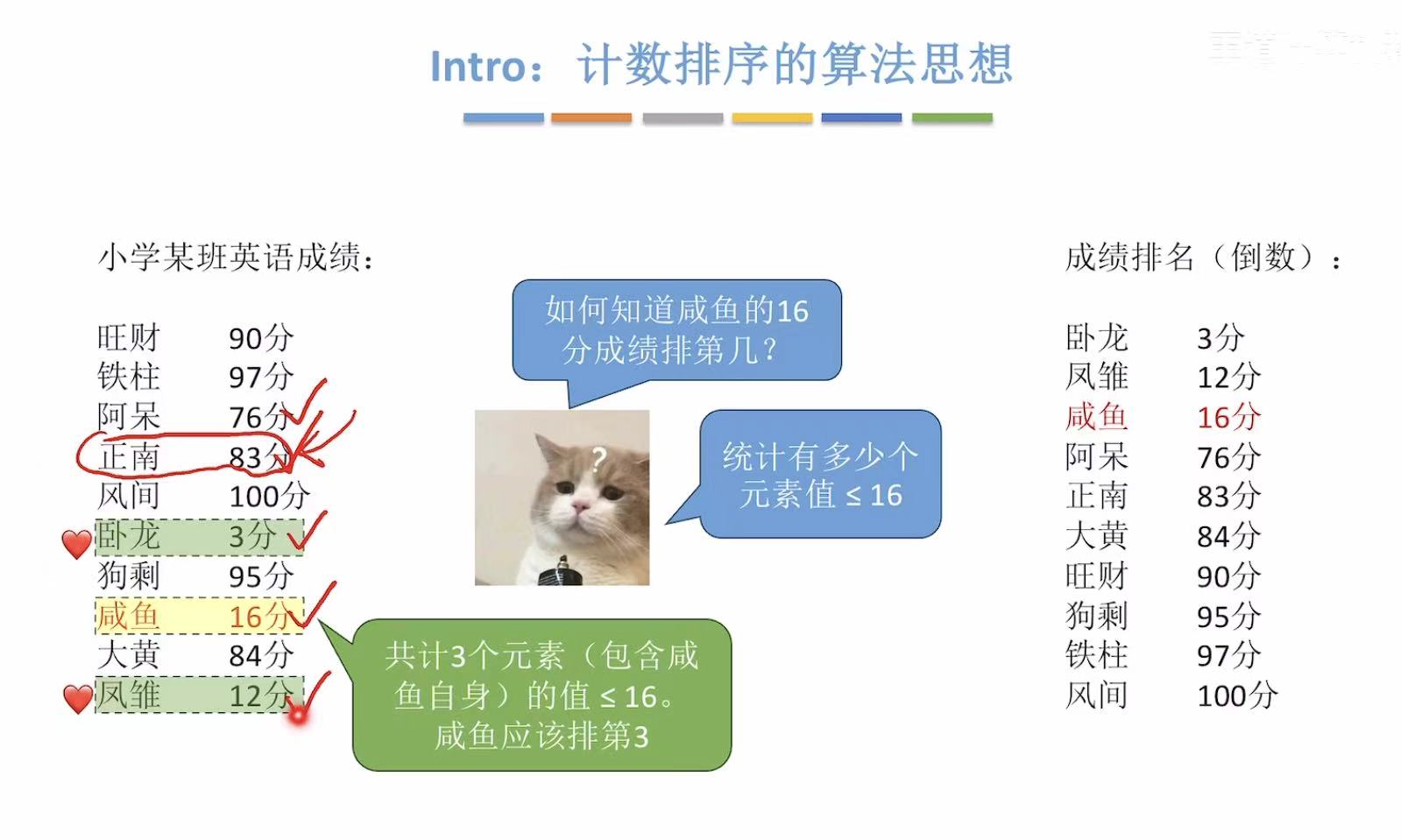
1. 引入
比如我们想知道咸鱼考了第几,就可以直接查比咸鱼分数低 的有几个人:
找到两个,一个卧龙一个凤雏,所以就可以推断咸鱼排第三(倒数的)
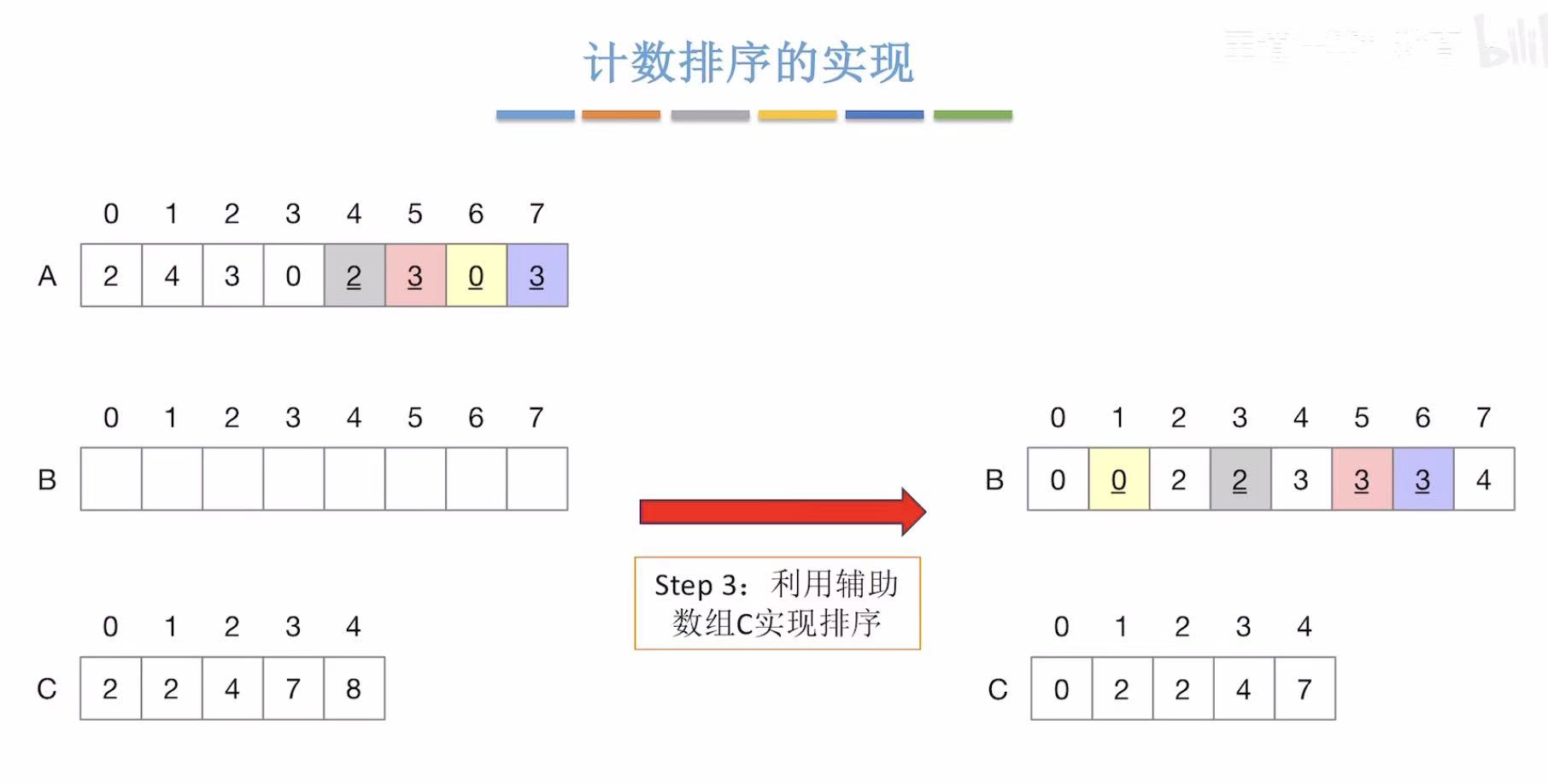
2. 计数排序的实现
创建1个数组:
-
先统计元素出现次数
-
后统计小于等于某个元素的出现次数
-
(根据出现的不同元素的个数决定这个数组多大)
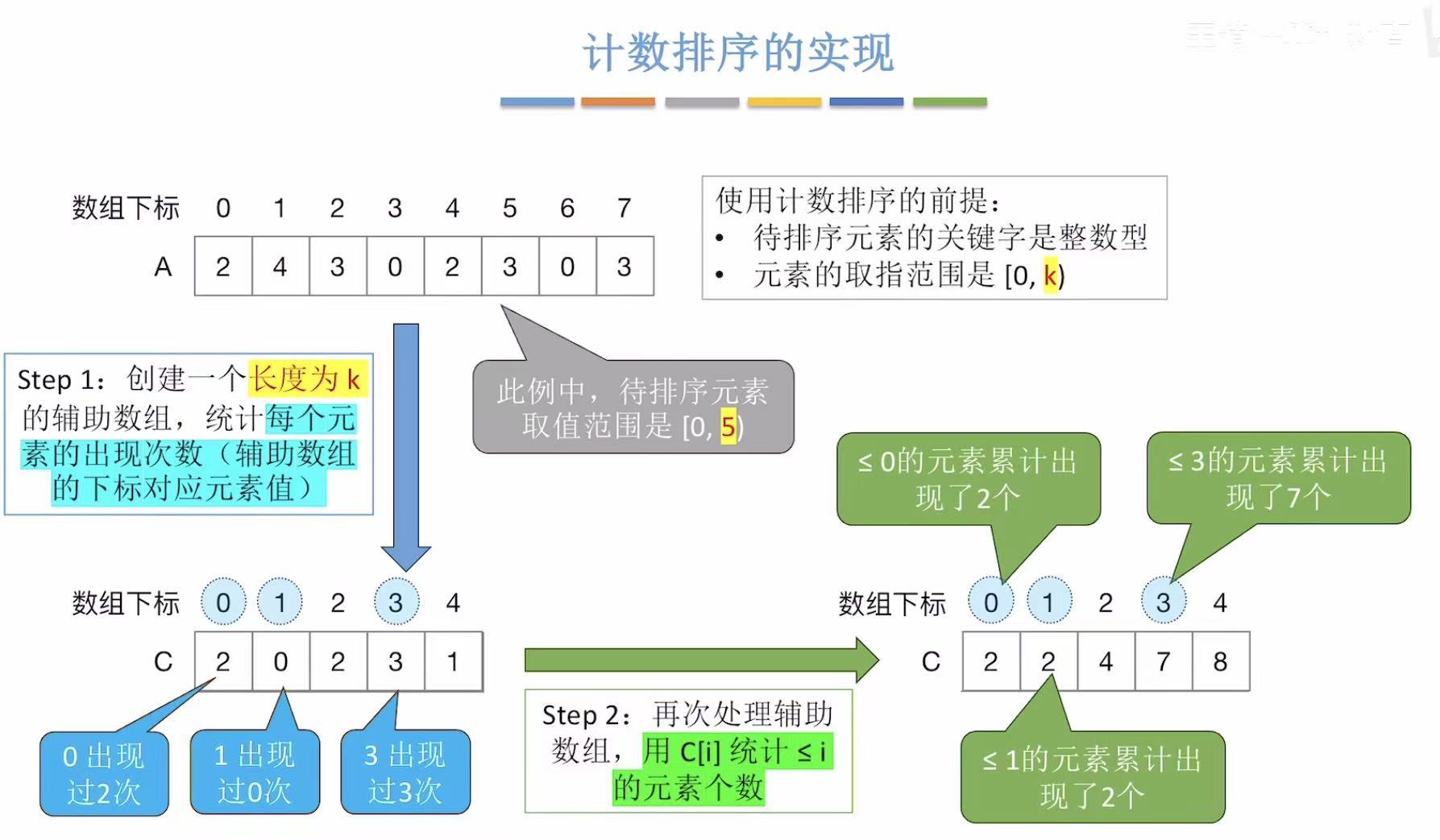
经过上面两部,我们得到:<=某个元素的个数的辅助数组
-
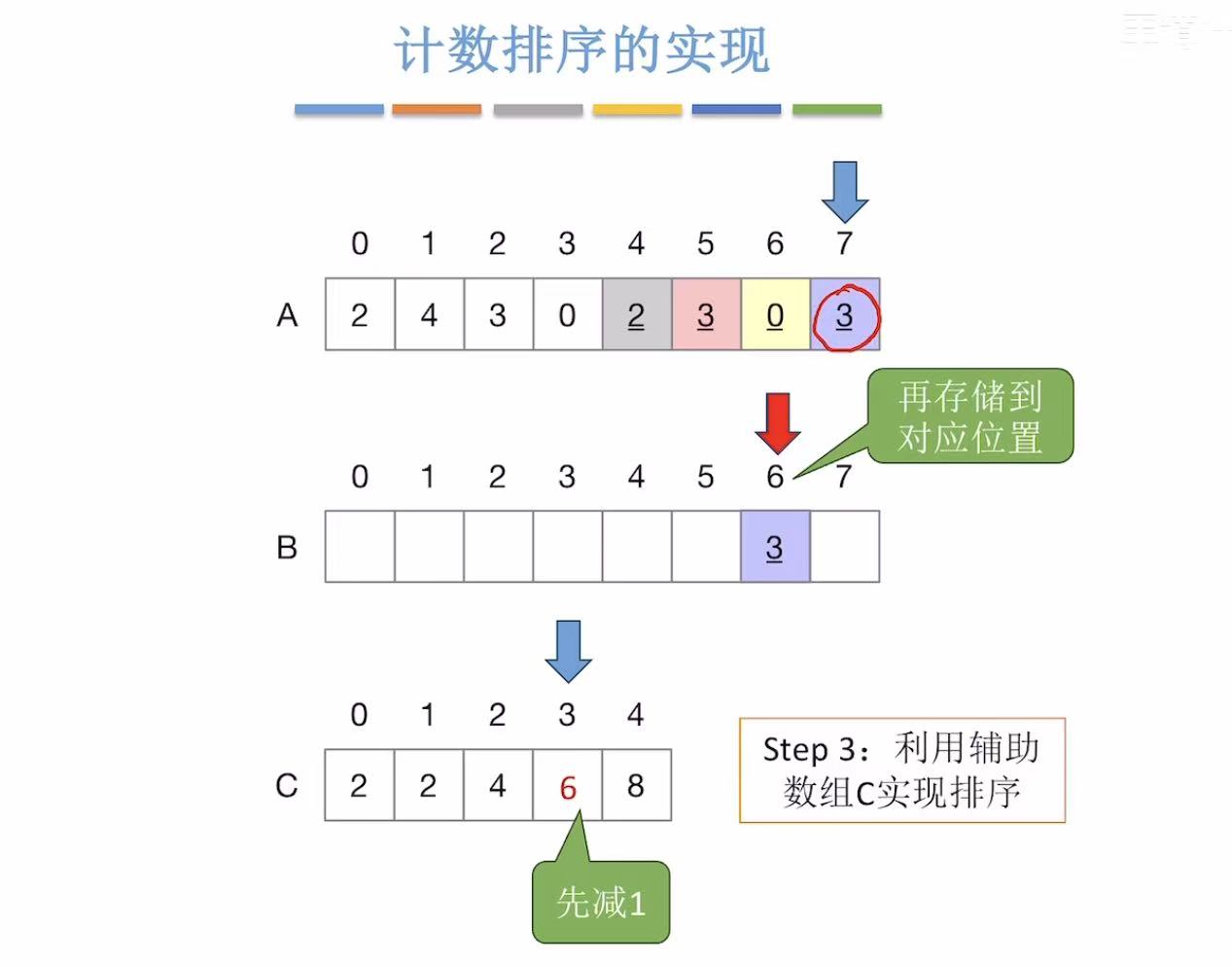
未排序的数组:从后往前排序
-
辅助数组:使用时自动-1
-
未排序的数组:指到3
-
辅助数组:使用时自动-1,所以存入最终排序数组的位置6
-
未排序的数组:指到0
-
辅助数组:使用时自动-1,所以存入最终排序数组的位置1
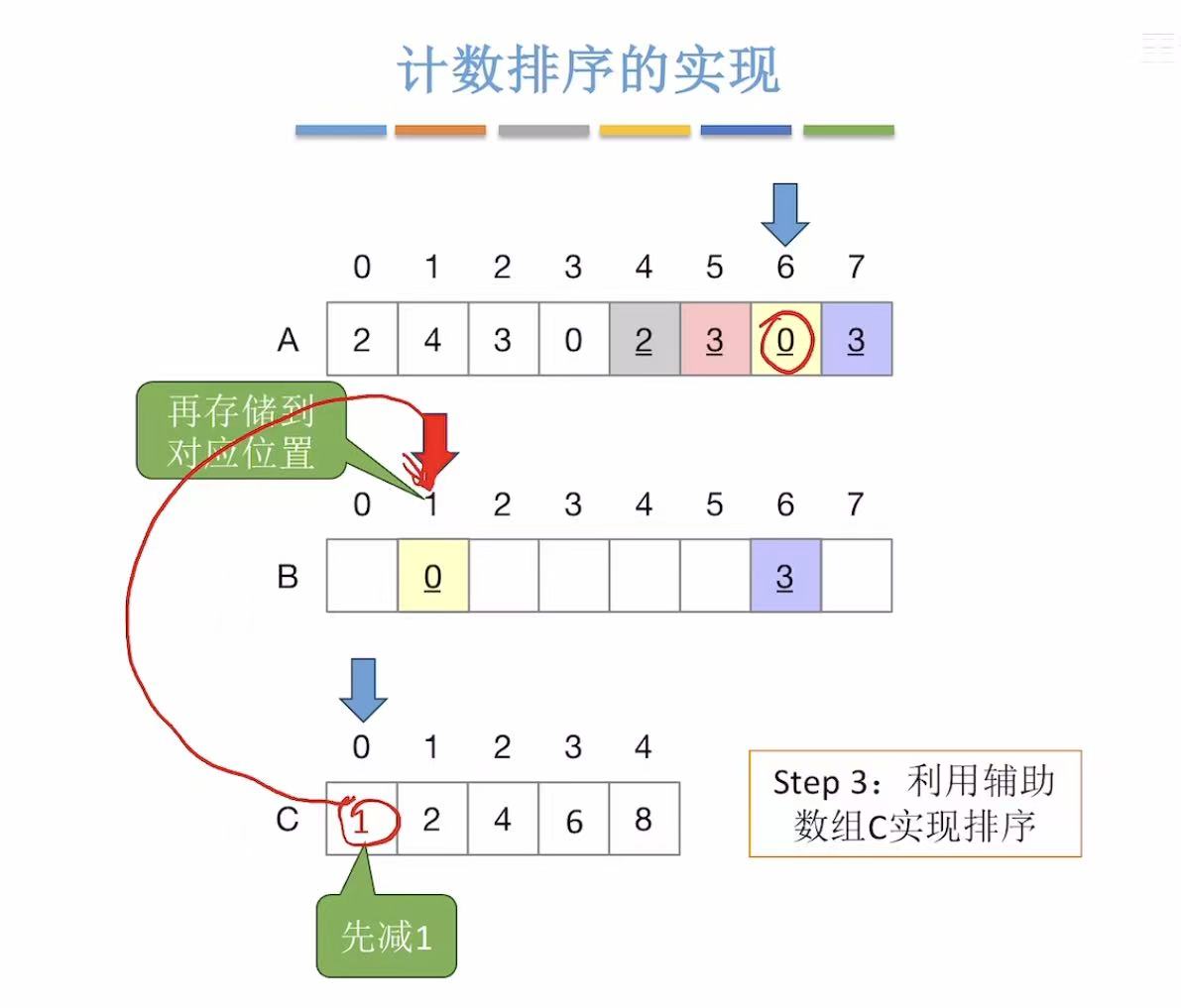
最终处理结果:
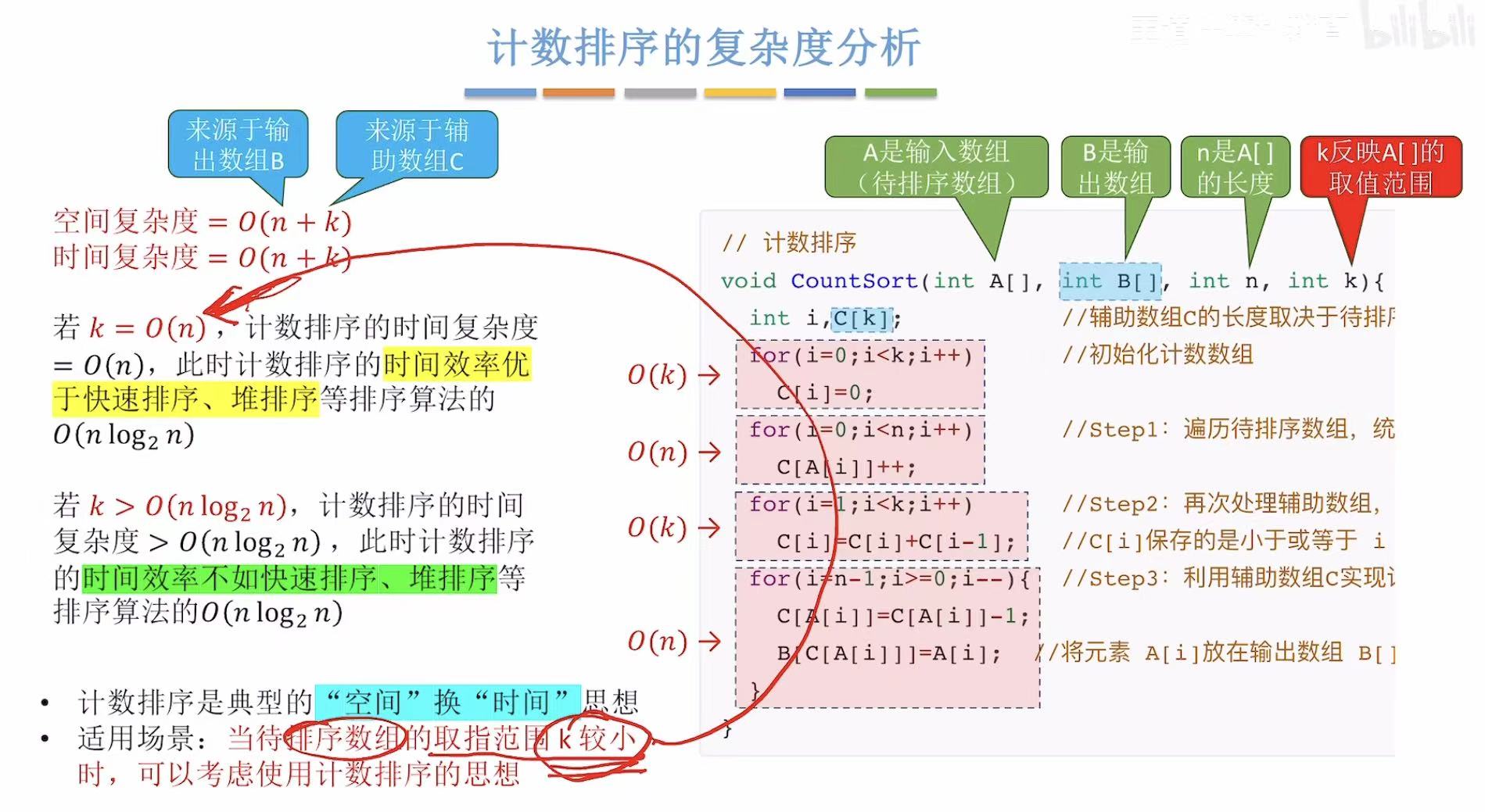
3. 计数排序的复杂度分析
适用于k<<=n的场景(最好还是<<,=勉强可以用)
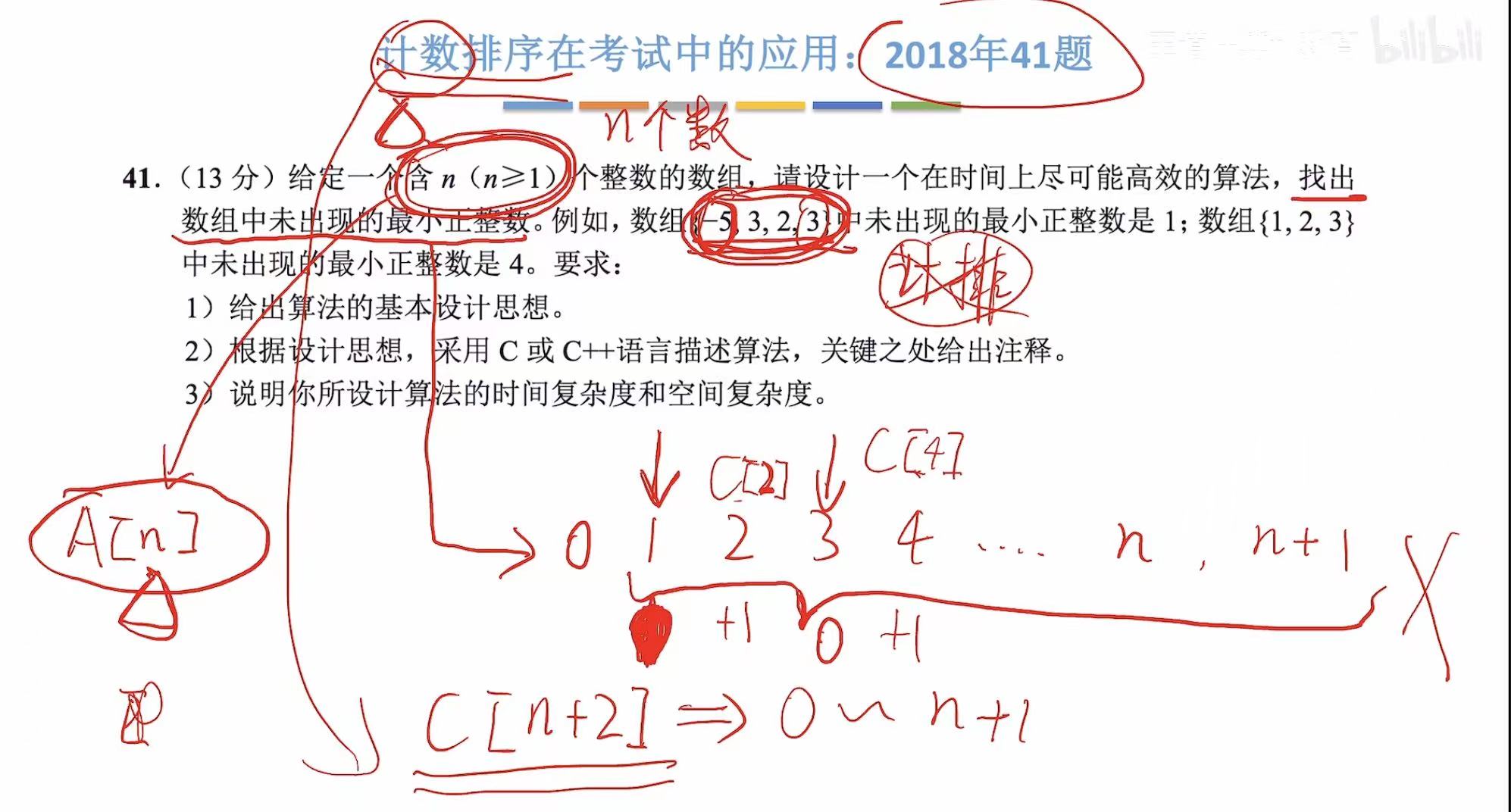
4. 在考试中的应用

5. 小结