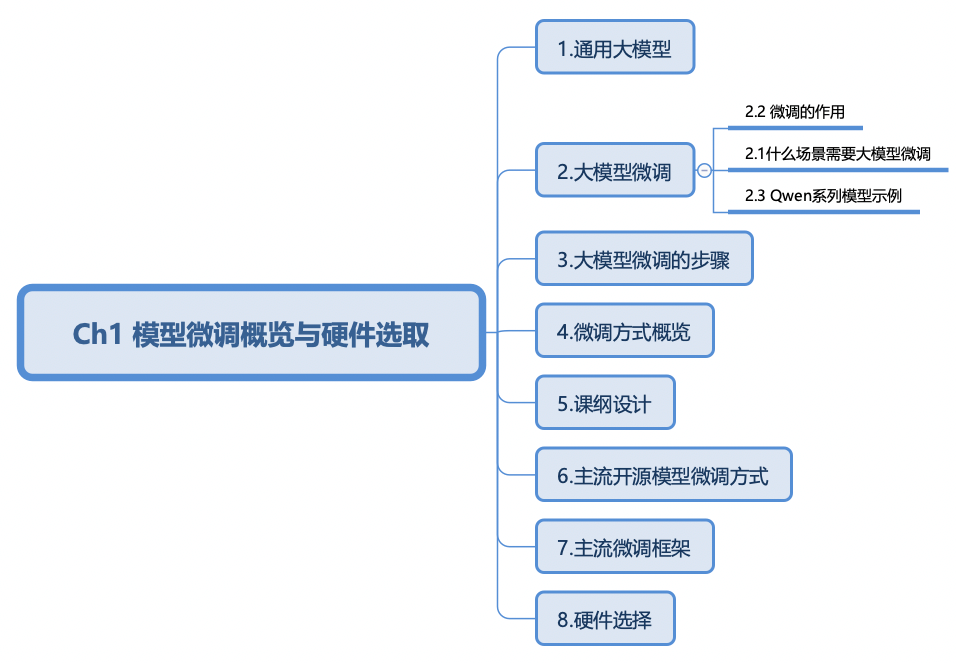
模型微调概览与硬件选取(笔记)
来源:1. 模型微调概览与硬件选取.ipynb
备注:以下为课堂/文档笔记整理,模型归属与细节以官方资料为准。
1. 通用大模型
定义:基于深度学习的大规模通用模型,能处理多任务与多场景,具备通用性与强泛化能力。
核心特点:
- 大规模参数:常见数十亿到万亿级;通过海量数据训练捕获复杂模式。
- 多任务统一处理:文本生成、翻译、问答、代码、推理等。
- 预训练 + 微调范式:先学通用知识,再用少量标注数据适配任务。
- 跨模态能力:部分模型支持文本、图像、音频等。
1.1 大模型的分类
按功能特点:
| 类型 | 特点 | 代表 |
|---|---|---|
| 文本生成与理解模型 | NLP 任务为主:生成、翻译、问答、摘要 | GPT 系列 |
| 多模态模型 | 支持文本/图像/音频/视频 | Gemini、GPT‑4 |
| 代码生成与理解模型 | 代码生成、调试、补全 | Claude、DeepSeek‑Coder |
按应用领域:
| 类型 | 特点 | 代表 |
|---|---|---|
| 通用领域模型 | 日常对话、写作、翻译 | ChatGPT |
| 垂直领域模型 | 医疗、法律、金融等 | Med‑PaLM |
按技术架构:
| 类型 | 说明 |
|---|---|
| Transformer | 自注意力机制,处理长序列 |
| MoE(混合专家) | 动态选择专家,提升效率 |
| 开源/闭源 | 开源模型 vs 闭源模型(GPT、PaLM、Claude 等) |
按规模:
| 类型 | 说明 |
|---|---|
| 超大规模 | 千亿级参数,训练成本高 |
| 中等规模 | 数十亿到百亿级,适配资源受限场景 |
2. 大模型微调
定义:在预训练大模型基础上,用特定任务数据继续训练,使模型适配特定任务或领域。
核心概念:
- 预训练模型:海量通用数据学习语言表示与知识。
- 微调:少量任务数据进一步训练,提高特定任务性能。
2.1 什么场景需要微调
图示:
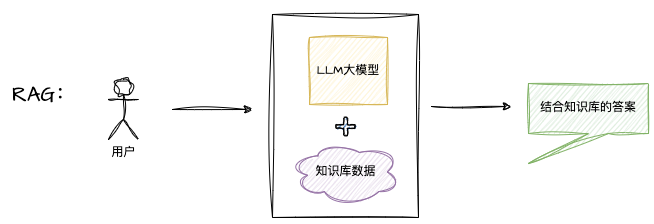
RAG 与微调的差异:
- RAG:主要对知识库内容整合、汇总后输出。
- 微调:模型学习到的定制化内容,形成稳定能力。
图示:
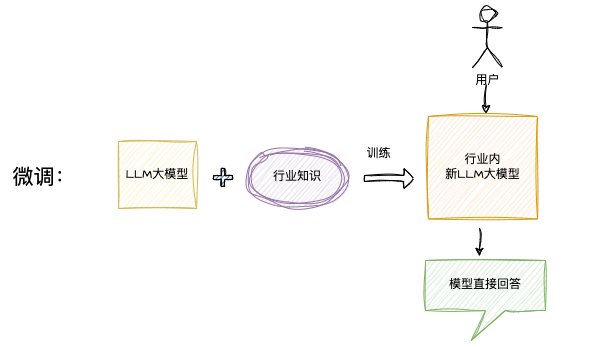
选择对比:
| 场景 | RAG | 微调 |
|---|---|---|
| 动态数据 | ✅ | |
| 成本 | ✅ | |
| 可解释性 | ✅ | |
| 场景需要通用能力 | ✅ | |
| 特色能力 | ✅ | |
| 延迟 | ✅ | |
| 微智能设备 | ✅ | |
| 模型幻觉 | ✅ | ✅ |
示例场景:
- 医学论文整理:领域知识与整理能力依赖微调。
- 智慧库房:清单经常更新与对话能力更适合 RAG。
- 智慧销售:产品数据常更新用 RAG,销售语气与风格用微调。
2.2 微调的作用
- 任务适配:通用模型变为专用模型。
- 性能提升:用任务数据优化参数。
- 数据效率:少量标注数据即可显著提升。
2.3 Qwen 系列模型示例
Base 与 Instruct:
- Base:大规模预训练得到的通用模型。
- Instruct:在 Base 上做指令微调,适配对话/问答等任务。
微调流程(示例):
- 预训练:得到 Qwen‑Base。
- 指令微调:用指令‑响应对得到 Qwen‑Instruct。
- 领域微调(可选):医疗/法律等领域专用 Instruct。
微调意义:提升任务性能、降低开发成本、快速适配新任务。
3. 微调步骤
核心步骤:任务目标 → 数据 → 模型 → 环境 → 参数 → 训练 → 评估 → 部署。
详细链路:
- 确定任务目标:明确任务类型与领域,输出任务定义文档。
- 准备数据:收集、清洗、划分、格式化,输出高质量训练数据。
- 选择预训练模型:综合模型规模、架构、预训练数据,输出模型文件。
- 设置微调环境:硬件、框架、依赖配置完成。
- 配置微调参数:学习率、batch size、epoch、优化器等。
- 训练模型:加载模型与数据,训练循环,保存权重。
- 评估与验证:验证集/测试集评估,错误分析与调参。
- 部署与应用:导出模型、部署、接口开发、监控维护。
4. 微调方式概览
4.1 全量微调(Full Fine‑tuning)
要点:更新全模型参数,适配任务输出层。
优点:充分利用通用知识,数据较小仍能提升。
缺点:算力与时间成本高,小数据易过拟合。
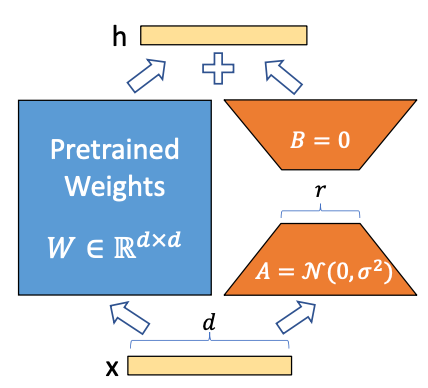
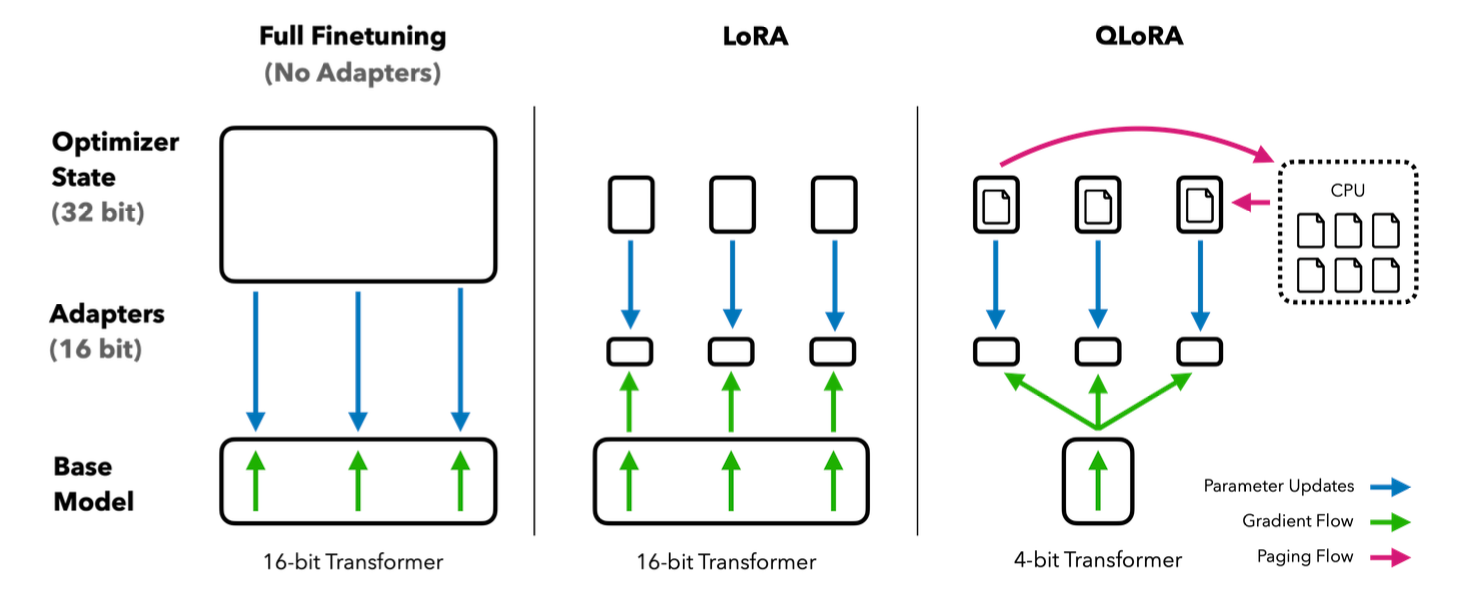
4.2 LoRA(Low‑Rank Adaptation)
原理:冻结原权重,加入低秩矩阵 A、B 进行适配。
优点:训练参数少,显存与计算成本低。
缺点:需要一定工程与调参经验。
图示:
4.3 QLoRA
原理:LoRA + 量化,将 FP32/FP16 转为 INT8/INT4 等降低存储与计算。
优点:更省显存,适合大模型微调。
图示:
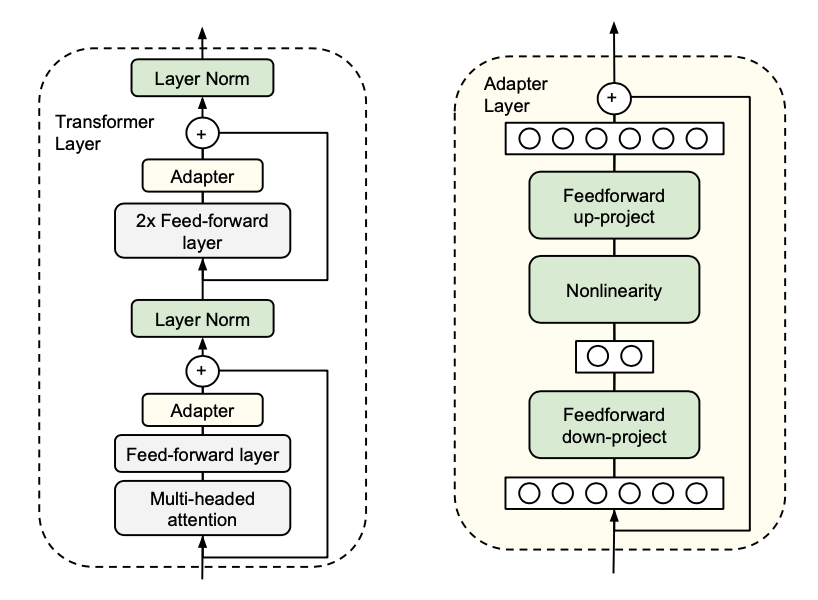
4.4 Adapter Tuning
原理:在模型各层插入少量参数的适配器模块,保持原模型冻结。
优点:多任务可插不同 Adapter,参数量小。
缺点:工程设计复杂,可能过拟合。
图示:
4.5 其他微调方式
- 冻结微调:仅更新顶层或少数层,性能可能受限。
- 逐层微调:从顶层逐步向下,调参成本高。
- 动态微调:动态调整超参数,效果好但实现复杂。
5. 强化学习与偏好对齐
5.1 RLHF(人类反馈强化学习)
流程要点:
- 监督微调:用标注答案训练初始策略。
- 奖励模型:人类排序多输出,训练奖励模型。
- PPO 优化:使用奖励模型反馈优化策略。
图示:
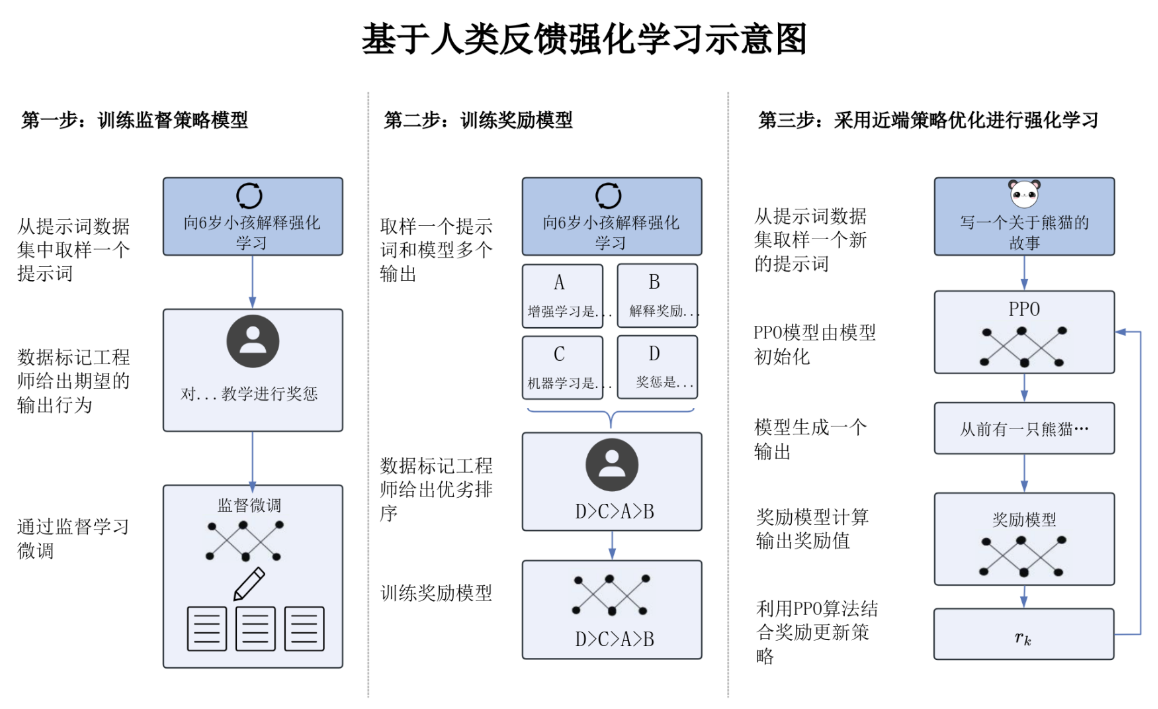
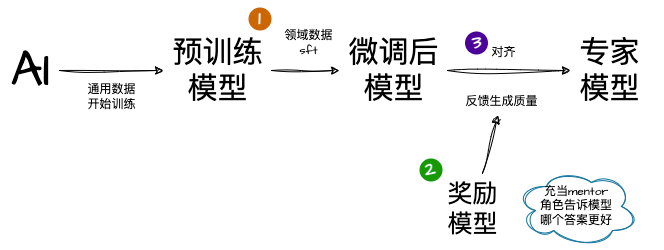
补充:人工标注成本高 → 可用 AI 反馈强化学习(RLAIF)。
5.2 PPO(近端策略优化)
要点:策略网络 + 价值网络;限制更新幅度提升稳定性;适合复杂决策任务。
5.3 DPO(直接偏好优化)
要点:用偏好对直接优化,无需奖励模型;最大化首选输出概率、最小化不受欢迎输出概率。
5.4 GRPO(组相对策略优化)
核心:分组优化 + 组内相对奖励 + 稳定性控制。
5.5 SFT(监督式微调)
定义:用标注数据在预训练模型上继续训练。
优势:简单高效、少量数据见效、可解释性强。
挑战:标注成本高、小数据过拟合、领域迁移可能下降。
6. 课纲设计(摘要)
第一部分:微调基础理论
模块1:微调范式与硬件基础
模块2:LoRA/QLoRA 核心方法
模块3:SFT
模块4:强化学习框架
模块5:模型轻量化与加速
第二部分:数据工程体系
模块1:数据工程总览
模块2:SFT 数据完整链路
模块3:偏好数据完整链路
模块4:CoT 数据完整链路
第三部分:微调实战
模块1:工具链
模块2:强化学习微调实战
模块3:高效微调技术
模块4:多模型架构适配
模块5:vllm/ollama 应用
模块6:模型评估验证
第四部分:企业项目实战
行业项目实战
7. 主流开源模型微调方式
图示:



要点概览:
| 模型 | 核心优势方向 | 主要微调方法 |
|---|---|---|
| LLaMA | 多语言对话与代码生成;长上下文推理 | LoRA/QLoRA、DPO、全参微调 |
| Qwen | 中文长文本、多模态与数学推理 | 全参 SFT、LoRA、QLoRA |
| ChatGLM | 中文对话与抽取;轻量部署 | Freeze、P‑Tuning v2、SFT+PPO |
| DeepSeek | 复杂逻辑推理;合规与效率 | GRPO、多源数据增强 |
8. 主流框架
| 框架 | 核心定位 | 典型场景 |
|---|---|---|
| LLaMA‑Factory | 全流程微调工具链 | 多模型、多方法训练 |
| Unsloth | 轻量级训练加速库 | 消费级 GPU 快速微调 |
| DeepSpeed | 分布式训练框架 | 超大规模训练、企业级部署 |
| TRL | RLHF 强化学习库 | 对话系统对齐与偏好优化 |
| OpenRLHF | 开源 RLHF 框架 | 定制化奖励与多阶段训练 |
9. 硬件选择
9.1 硬件平台
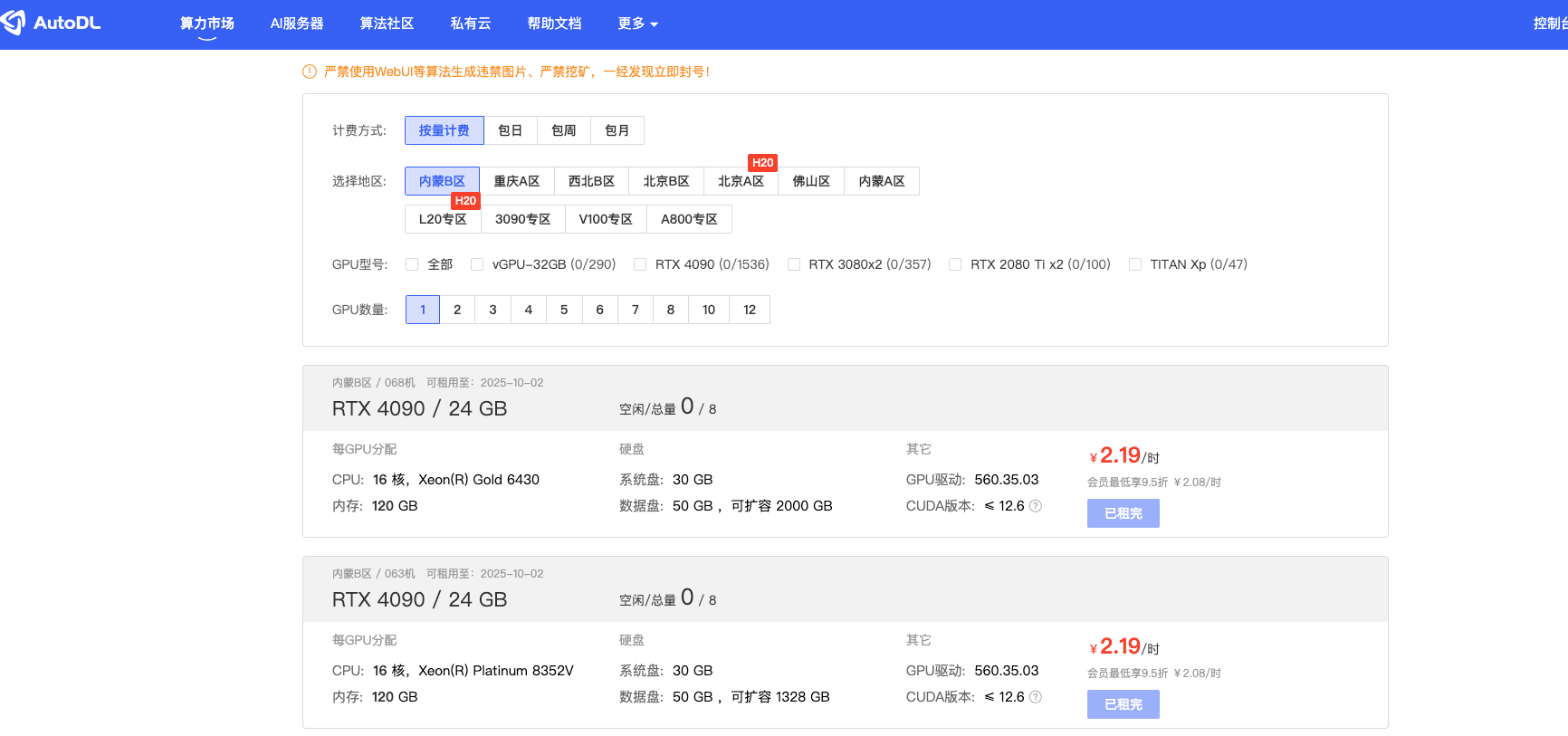
- AutoDL:
https://www.autodl.com/login - 优云智算:
https://www.compshare.cn/
图示:

9.2 资源选择
常见显卡系列:
| 系列 | 主要特点 | 典型用户 |
|---|---|---|
| RTX | 消费级,兼顾游戏/渲染/轻量 AI | 游戏玩家、AI 初学者 |
| A 系列 | 数据中心训练/推理 | 研究团队 |
| A800 | A 系列特供版 | 中国市场训练/推理 |
| H 系列 | 超大规模训练 | 超大项目/HPC |
| H800 | H 系列特供版 | 中国市场训练/推理 |
| L 系列 | 图形/推理 | 数据分析、工作站 |
| T 系列 | 入门级、低功耗 | 云服务、推理 |
推理模型显存需求:
| 模型尺寸 | 精度 | 显存需求 (GB) | 推荐显卡 |
|---|---|---|---|
| 7B | FP16 | 12 | RTX 4080 / 4090 |
| 7B | INT8 | 8 | RTX 4080 / T4 |
| 7B | INT4 | 6 | RTX 4080 / 3060 |
| 7B | INT2 | 4 | RTX 3060 / 4080 |
| 13B | FP16 | 24 | RTX 4090 |
| 13B | INT8 | 16 | RTX 4090 |
| 13B | INT4 | 12 | RTX 4090 / 4080 |
| 13B | INT2 | 8 | RTX 4080 / 4090 |
| 30B | FP16 | 60 | A100 (40GB) * 2 |
| 30B | INT8 | 40 | L40 (48GB) |
| 30B | INT4 | 24 | RTX 4090 |
| 30B | INT2 | 16 | T4 (16GB) |
| 70B | FP16 | 120 | A100 (80GB) * 2 |
| 70B | INT8 | 80 | L40 (48GB) * 2 |
| 70B | INT4 | 48 | L40 (48GB) |
| 70B | INT2 | 32 | RTX 4090 |
| 110B | FP16 | 200 | H100 (80GB) * 3 |
| 110B | INT8 | 140 | H100 (80GB) * 2 |
| 110B | INT4 | 72 | A10 (24GB) * 3 |
| 110B | INT2 | 48 | A10 (24GB) * 2 |
训练显存需求(全量训练):
| 模型尺寸 | 精度 | 显存需求 (GB) | 推荐硬件配置 |
|---|---|---|---|
| 7B | AMP | 120 | A100 (40GB) * 3 |
| 7B | FP16 | 60 | A100 (40GB) * 2 |
| 13B | AMP | 240 | A100 (80GB) * 3 |
| 13B | FP16 | 120 | A100 (80GB) * 2 |
| 30B | AMP | 600 | H100 (80GB) * 8 |
| 30B | FP16 | 300 | H100 (80GB) * 4 |
| 70B | AMP | 1200 | H100 (80GB) * 16 |
| 70B | FP16 | 600 | H100 (80GB) * 8 |
| 110B | AMP | 2000 | H100 (80GB) * 25 |
| 110B | FP16 | 900 | H100 (80GB) * 12 |
高效微调显存需求:
| 模型尺寸 | 精度 | 显存需求 (GB) | 推荐硬件配置 |
|---|---|---|---|
| 7B | Freeze (FP16) | 20 | RTX 4090 |
| 7B | LoRA (FP16) | 16 | RTX 4090 |
| 7B | QLoRA (INT8) | 10 | RTX 4080 |
| 7B | QLoRA (INT4) | 6 | RTX 3060 |
| 13B | Freeze (FP16) | 40 | RTX 4090 / A100 (40GB) |
| 13B | LoRA (FP16) | 32 | A100 (40GB) |
| 13B | QLoRA (INT8) | 20 | L40 (48GB) |
| 13B | QLoRA (INT4) | 12 | RTX 4090 |
| 30B | Freeze (FP16) | 80 | A100 (80GB) |
| 30B | LoRA (FP16) | 64 | A100 (80GB) |
| 30B | QLoRA (INT8) | 40 | L40 (48GB) |
| 30B | QLoRA (INT4) | 24 | RTX 4090 |
| 70B | Freeze (FP16) | 200 | H100 (80GB) * 3 |
| 70B | LoRA (FP16) | 160 | H100 (80GB) * 2 |
| 70B | QLoRA (INT8) | 80 | H100 (80GB) |
| 70B | QLoRA (INT4) | 48 | L40 (48GB) |
| 110B | Freeze (FP16) | 360 | H100 (80GB) * 5 |
| 110B | LoRA (FP16) | 240 | H100 (80GB) * 3 |
| 110B | QLoRA (INT8) | 140 | H100 (80GB) * 2 |
| 110B | QLoRA (INT4) | 72 | A10 (24GB) * 3 |
10. 总结要点
- 通用大模型基于大规模预训练,微调是落地关键。
- RAG 适合动态与可解释场景,微调适合特色能力与低延迟。
- 资源受限时优先考虑 LoRA/QLoRA 等高效微调。
- 硬件选型需结合模型规模、精度与训练方式。
图示(总结页):