作者:来自 Elastic Scott Martens 及 Sofia Vasileva

介绍 jina-embeddings-v5-text 模型,包括 jina-embeddings-v5-text-small 和 jina-embeddings-v5-text-nano,并解释如何通过 Elastic Inference Service ( EIS ) 使用这些多语言嵌入模型。
通过 Elasticsearch 进行实操:深入体验 Elasticsearch Labs 仓库中的示例 notebooks,开启免费的 cloud trial,或现在就在你的本地机器上试用 Elastic。
Jina AI 与 Elastic 正在发布 jina-embeddings-v5-text,这是一个全新的高性能、紧凑型文本嵌入模型家族,在所有主要任务类型上,对比同等规模模型都具备最先进的性能。
该模型家族包含两个模型:
- jina-embeddings-v5-text-small
- jina-embeddings-v5-text-nano
这些模型是全新嵌入模型训练方案的成功成果。它们在性能上超越了体量大得多的模型,在节省内存和计算资源的同时,对请求的响应速度也更快。
jina-embeddings-v5-text-small 模型拥有 677M 参数,支持 32768 tokens 的输入上下文窗口,默认生成 1024 维 embeddings。
jina-embeddings-v5-text-nano 的规模约为其兄弟模型的三分之一,拥有 239M 参数和 8192 tokens 的输入上下文窗口,生成更为精简的 768 维 embeddings。
| Model name | Total size | Input context window size | Embedding size |
|---|---|---|---|
| jina-v5-text-small | 677M params | 32768 tokens | 1024 dims |
| jina-v5-text-nano | 239M params | 8192 tokens | 768 dims |
这两个模型在整体 MMTEB (Multilingual MTEB) 基准测试性能中均处于同类最佳水平。在参数量低于 500M 的模型中,jina-embeddings-v5-text-nano 尽管参数少于 250M,仍然是性能最优的模型;而 jina-embeddings-v5-text-small 则是在参数量低于 750M 的多语言嵌入模型中表现领先。
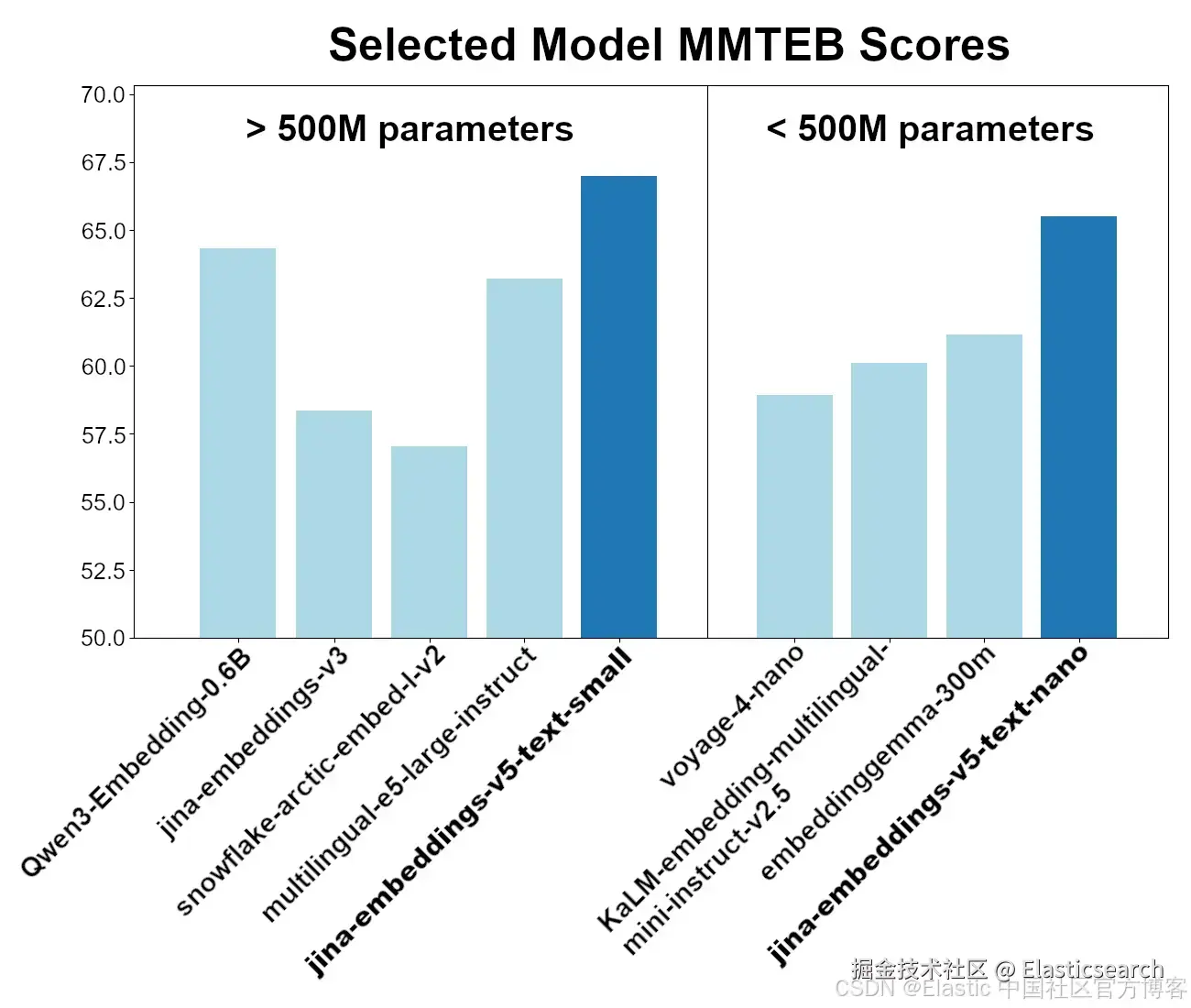
这些模型可通过 Elastic Inference Service ( EIS ) 使用,也可通过在线 API 访问,并支持本地托管。有关如何访问 jina-embeddings-v5-text 模型的说明,请参阅下方的 "Getting started" 部分。
嵌入模型和语义索引能够显著提升搜索算法的准确性,同时在涉及语义相似性和含义提取的多种任务中也有广泛用途,例如:
- 查找重复文本
- 识别改写和翻译
- 主题发现
- 推荐引擎
- 情感和意图分析
- 垃圾信息过滤
- 以及更多其他场景
功能
这个新的模型家族包含多项功能,旨在提升相关性并降低成本。
任务优化
我们针对四大类任务对 jina-embeddings-v5-text 模型进行了优化:
| 任务 | 示例用例 |
|---|---|
| 检索 | 使用自然语言查询进行搜索,并在文档集合中检索最相关的匹配结果。 |
| 文本匹配 | 语义相似度、去重、释义和翻译对齐等。 |
| 聚类 | 主题发现、文档集合的自动组织。 |
| 分类 | 文档分类、情感和意图检测等类似任务。 |
针对某一种任务进行优化通常意味着需要在其他任务上做出妥协,因此大多数嵌入模型只在一种任务上具有有竞争力的性能。但 jina-embeddings-v5-text 模型通过训练针对特定任务的 LoRA 适配器,在不做妥协的情况下同时覆盖这四个领域。
LoRA 适配器是一种 AI 模型的插件,可以在仅略微增加总体大小的情况下显著改变模型行为。与其为每个任务都使用一个包含数亿参数的完整模型,jina-embeddings-v5-text 模型家族允许你只使用一个模型,并为每个任务加载一个紧凑的 LoRA 适配器,从而节省内存、存储空间和推理成本。
嵌入截断
我们使用 Matryoshka Representation Learning 训练了 jina-embeddings-v5-text 模型,使你可以在几乎不影响质量的情况下,将嵌入向量裁剪为更小的尺寸。
默认情况下,jina-embeddings-v5-text-small 会生成 1024 维的嵌入向量,每一维使用 16 位数字表示,因此每个嵌入大小为 2KB。对于大型文档集合来说,这会带来大量需要存储的数据,而且在向量数据库中进行搜索的成本与数据库规模以及每个向量的维度数量都成正比。
但你可以直接将嵌入大小减半(丢弃 1024 维中的 512 维),在占用一半存储空间的同时,将搜索速度提升一倍。这确实会对性能产生影响,因为丢弃信息会降低精度。但如下图所示,即使去掉一半的嵌入维度,性能也只会有轻微下降:
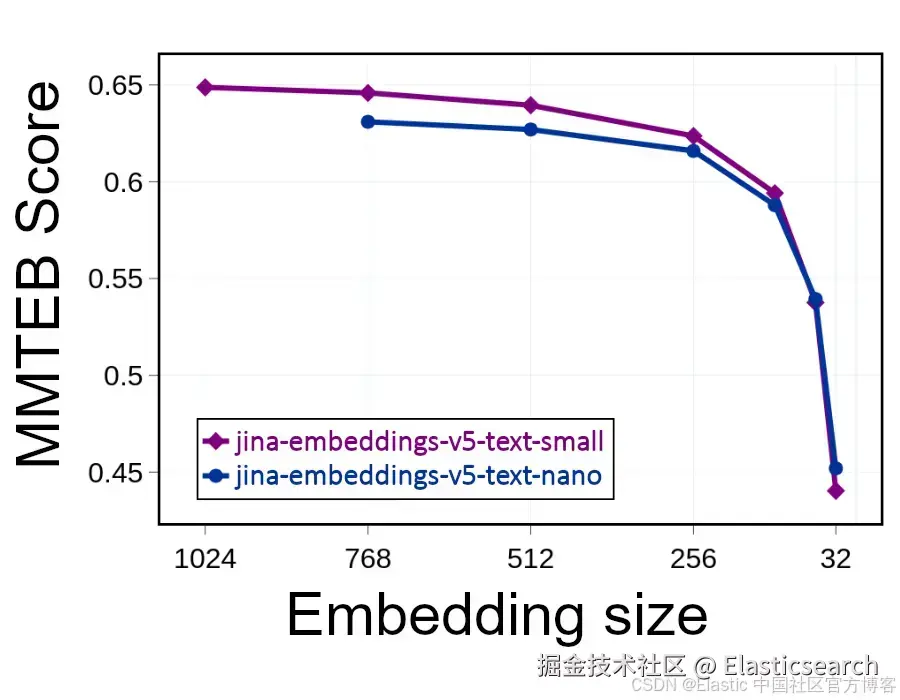
只要你的嵌入维度至少为 256,精度损失应保持在较小范围内。但低于该维度时,相关性和准确性会迅速下降。
像这样截断嵌入使用户能够自行在准确性和计算成本之间做权衡。它为你提供工具,从搜索 AI 中获得高效益和大幅成本节约。
稳健量化
量化是另一种减小嵌入大小的方法。它不是丢弃嵌入的一部分,而是降低嵌入中数字的精度。jina-embeddings-v5-text 模型生成的嵌入使用 16 位数字,但我们可以将这些数字四舍五入,降低其精度以及存储所需的位数。在最极端的情况下,我们可以将每个数字减少到一位(0 或 1),将 jina-embeddings-v5-text 默认的 1024 维嵌入从 2KB 压缩到 128 字节,仅通过二进制量化就减少了 94%。与截断一样,这可大幅节省内存和计算成本。但同样像截断一样,量化会降低嵌入精度。
我们训练 jina-embeddings-v5-text 模型与 Elasticsearch 的 更优二进制量化 配合使用,通过最小化精度损失,并且对这些模型的二值化嵌入进行基准测试,结果显示性能几乎等同于非二值化嵌入。详细的二值化性能消融研究请参考技术报告。
多语言性能
许多嵌入模型是多语言的,因为它们在训练中使用了大量多语言材料。但这并不意味着它们在所有支持的语言上表现都一样。
我们在 MMTEB 多语言基准中识别了 211 种语言,并将它们分开,以便在语言维度上逐一比较我们的模型与同类模型。下图用热力图总结了我们的结果。每个格子代表一种语言(由 ISO-639 代码标识),颜色越绿表示该模型相较于同类模型平均表现越好:

尽管不同语言的准确性有所差异,jina-embeddings-v5-text 模型在世界大多数语言上均处于最先进水平或接近最先进水平。
有关多语言性能的详细信息,请参阅 jina-embeddings-v5-text 技术报告。
Jina 在 Elastic:搜索的最先进原生 AI
借助 EIS 上的 jina-embeddings-v5-text 模型,你可以在 Elasticsearch 中原生运行高性能多语言嵌入模型,享受全托管、GPU 加速推理,无需配置或扩展基础设施。jina-embeddings-v5-text 模型通过最新 AI 技术扩展了不断增长的 EIS 模型目录,提供紧凑、多语言的模型。这些模型在信息检索和标准数据分析基准上性能最先进,并提供无与伦比的全球多语言支持。
凭借两种体量差异巨大的模型,用户可以根据应用需求和预算选择最适合的模型。此外,jina-embeddings-v5-text 模型具有稳健嵌入,即使在截断为更小尺寸或量化为低精度时仍能保持高性能,为存储和计算成本以及处理延迟的进一步节省提供机会。
结合 jina-embeddings-v5-text 系列、Jina Reranker 以及 Elastic 的快速向量和 BM25 搜索,用户现在可以在 Elastic 中访问端到端、最先进的混合搜索。当你需要最相关的结果,无论是用于 RAG 管道、搜索应用还是数据分析,Elastic 与 Jina 搜索 AI 模型都能提供稳定且高性价比的质量。
快速开始
jina-embeddings-v5-text 模型已完全集成到 EIS 中,你可以通过在创建索引时将 type 字段设置为 semantic_text,并在 inference_id 字段中指定模型(jina-embeddings-v5-text-small 或 jina-embeddings-v5-text-nano)来使用,例如:
bash
`
1. PUT multilingual-semantic-index
2. {
3. "mappings": {
4. "properties": {
5. "content": {
6. "type": "semantic_text",
7. "inference_id": ".jina-embeddings-v5-text-small"
8. }
9. }
10. }
11. }
13. # Ingest data about France
14. POST multilingual-semantic-index/_doc
15. {
16. "content": "The capital of France is Paris"}
18. GET multilingual-semantic-index/_search
19. {
20. "query": {
21. "semantic": {
22. "field": "content",
23. "query": "What is the French capital?"
24. }
25. }
26. }
`AI写代码Elasticsearch 会在索引和检索过程中自动选择合适的 LoRA 适配器。嵌入维度(参见上文 "截断嵌入" 部分)可以在创建自定义推理端点时设置。
有关使用 jina-embeddings-v5-text 模型的更多信息,请参阅 Elasticsearch 文档。
更多信息
要了解更多关于 jina-embeddings-v5-text 模型的信息,请阅读 Jina AI 博客上的发布说明和技术报告,其中提供了关于性能和 Jina AI 创新训练方法的详细技术信息。有关在本地下载和运行这些模型的信息,请访问 Hugging Face 上的 jina-embeddings-v5-text 模型集合页面。
Jina AI 模型在 CC-BY-NC-4.0 许可证下提供,你可以自由下载并试用,但商业用途请联系 Elastic 销售。