人工智能中常用的KL散度是什么?分布p相对于q的KL散度与q相对于p的KL散度是否相等呢?
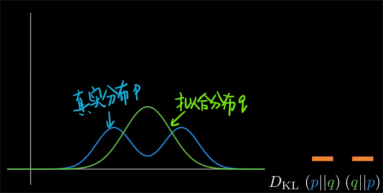
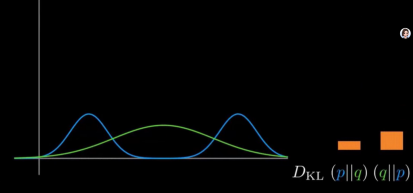
假如蓝色为目标真实分布p,绿色为拟合分布q。分别改变它们的形状,我们可以从右边柱状图看出两种KL散度的变化。二者大多数情况下是不相等的,这是什么原因呢?
先来看KL散度的公式,它是对两个分布间差异的一种衡量,通过先比值后、log、再求期望来实现。
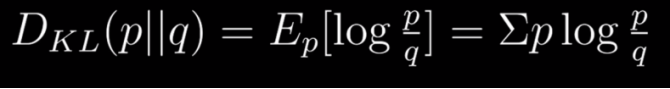
谁在前,谁就是分子。p相对于q称为前向散度 , 在监督学习 中,有大量的应用。q相对于p称为反向散度 ,在强化学习变分推断中广泛使用。
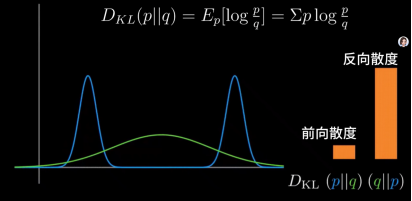
需要特别注意的是,谁在前就对谁求期望,也就是加权平均。
实际应用中真实分布p往往是多峰的。
p和q分布相似时,两种散度都很小。
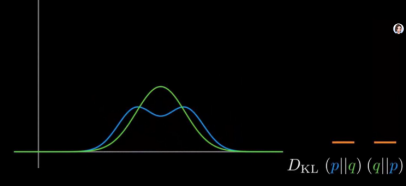
p双峰分开,两种散度均变大。
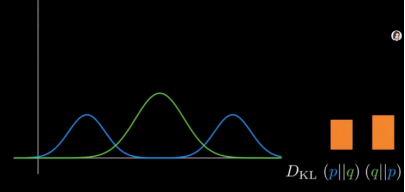
固定p不变,调整近似分布q,对它进行单峰拟合,前向散度变大,反向散度变小。
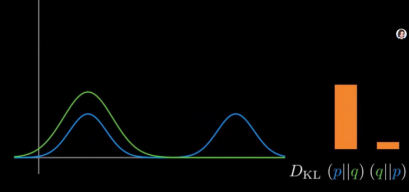
q均值不变,方差变小,前向散度继续增大,反向散度变化不明显。
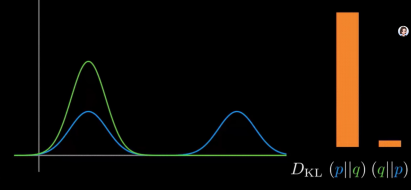
改变均值,移动回来,前向散度减小,反向散度增大。
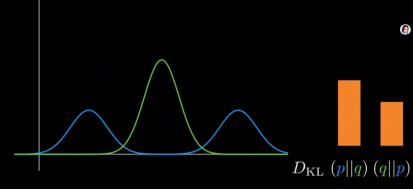
减小峰值,两种散度同时减小。
总结起来啊,其实就是一句话,哪个分布在前,就关注谁的峰值多一点。这就好比生活中的一对,在评价相互关系时,每个人总对自己在意的地方给予更高的权重。结果呢,也常常完全不同,多一点理解,多一点换位思考,更有助于减少彼此之间的分歧,这也许就是KL散度给我们的启示。