2026年4月,DeepSeek V4预览版正式开源上线,凭借"百万级上下文+极致性价比+开源普惠"的核心优势,迅速引爆开发者社区,成为开源大模型领域的焦点。本文将从核心特性、主流模型对比、多维度测评、实战案例、实操教程五个维度,全方位拆解DeepSeek V4,帮开发者快速掌握其优势、适用场景及使用方法,避开踩坑点,高效落地到实际开发中。
一、DeepSeek V4 核心特性拆解(必知重点)
DeepSeek V4并非单一模型,而是包含两个版本的完整系列,分别针对高性能需求和高性价比需求,全系标配100万token超长上下文,采用MIT开源协议,可商用且无功能阉割,核心特性如下:

1. 双版本矩阵,适配不同场景
-
DeepSeek V4-Pro:高性能旗舰版,参数总量1.6万亿(激活参数49B),主打专业推理、代码开发、复杂Agent任务,性能比肩顶级闭源模型,是目前已知最大的开源权重模型,超过Kimi K2.6(1.1万亿)和GLM-5.1(7540亿)。
-
DeepSeek V4-Flash:高性价比轻量版,参数总量2840亿(激活参数13B),推理速度更快、成本更低,在简单Agent任务上与Pro版本旗鼓相当,适合日常开发、轻量推理等场景,兼顾效率与成本。
2. 技术创新:突破长上下文与推理效率瓶颈
DeepSeek V4的核心突破的在于首创"CSA(压缩稀疏注意力)+HCA(重度压缩注意力)"混合注意力架构,彻底解决传统注意力机制在长序列场景下计算量平方级攀升的痛点,同时通过多项工程优化提升推理效率:
-
CSA(压缩稀疏注意力):将每4个token压缩为1个信息块,通过稀疏检索获取关键内容,兼顾细节保留与计算量降低;
-
HCA(重度压缩注意力):以128:1的激进压缩率浓缩海量信息,专注全局逻辑处理,适配低信息密度场景;
-
其他优化:引入mHC流形约束超连接、Muon优化器,全链路推理加速最高接近2倍;在100万token场景下,V4-Pro的单token推理算力仅为V3.2的27%,KV缓存仅为10%,V4-Flash更是低至10%和7%。
3. 极致性价比,成本碾压同类模型
定价策略是DeepSeek V4的核心竞争力之一,无论是轻量版还是旗舰版,价格均处于同级别模型最低区间,甚至低于OpenAI、Anthropic等闭源模型的1%,具体定价如下:
-
V4-Flash:输入/输出价格分别为每百万token 0.14美元/0.28美元,较Claude Opus 4.7低逾99%,低于GPT-5.4 Nano和Gemini 3.1 Flash-Lite;
-
V4-Pro:输入/输出价格为1.74美元/3.48美元,低于Gemini 3.1 Pro、GPT-5.4、Claude Sonnet 4.6等同类前沿模型,且官方提示,下半年昇腾950超节点批量上市后,Pro版本价格将进一步下调。
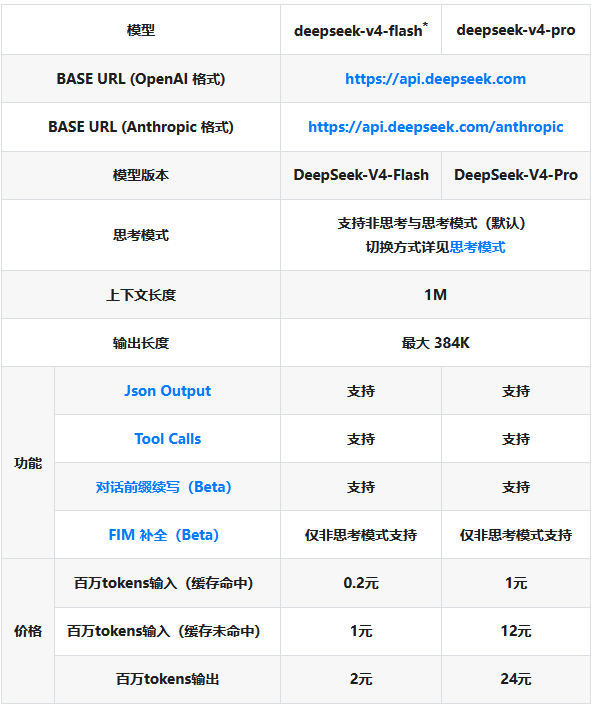
4. 多平台适配,开源普惠
DeepSeek V4已在Hugging Face和ModelScope平台开源完整权重,基于Apache 2.0协议,支持商用,且开源版本与API服务能力完全一致,包含100万上下文和思考模式。同时,模型已在英伟达GPU和华为昇腾NPU双平台完成验证,适配国产算力,为企业本地部署提供更多选择。
5. 新增思考模式,提升推理准确性
DeepSeek V4在API层面新增"思考模式"(Thinking Mode),模型输出最终答案前会先生成思维链(Chain-of-Thought),可通过参数调节思考强度,显著提升复杂推理、代码生成等任务的准确性,且支持OpenAI和Anthropic格式参数,兼容性极强。
二、DeepSeek V4 与主流大模型全面对比(开发者选型必备)
为方便开发者快速选型,本文选取目前主流的开源/闭源大模型(GPT-5.4、Gemini 3.1 Pro、Kimi K2.6、通义千问3.0、ChatGLM-5.1),从核心参数、性能、成本、部署难度等维度与DeepSeek V4(Pro/Flash)进行对比,重点突出差异化优势:
| 对比维度 | DeepSeek V4-Pro | DeepSeek V4-Flash | GPT-5.4 | Gemini 3.1 Pro | Kimi K2.6 | 通义千问3.0 | ChatGLM-5.1 |
|---|---|---|---|---|---|---|---|
| 参数规模 | 1.6万亿(激活49B) | 2840亿(激活13B) | 未公开(前沿级) | 未公开(前沿级) | 1.1万亿 | 7540亿 | 7540亿 |
| 上下文窗口 | 100万token | 100万token | 128万token | 100万token | 100万token | 50万token | 50万token |
| 代码能力(Vals测评) | 开源第一(击败Gemini 3.1 Pro) | 优秀(接近Pro版) | 顶级(91.7分) | 优秀(被V4击败) | 顶级(仅次于V4) | 良好 | 良好 |
| 推理能力 | 比肩顶级闭源(接近Gemini) | 优秀(简单任务无压力) | 顶级 | 顶级 | 顶级 | 良好 | 良好 |
| 输出成本(百万token) | 3.48美元 | 0.28美元 | 15美元 | 12美元 | 未公开(高于V4) | 0.8美元 | 开源免费 |
| 开源情况 | 开源(完整权重) | 开源(完整权重) | 闭源 | 闭源 | 部分开源 | 全系列开源 | 开源 |
| 部署难度 | 较高(需32GB+显存) | 中等(需16GB+显存) | 无法本地部署 | 无法本地部署 | 较高 | 中等 | 较低(轻量版易部署) |
| 适配算力 | 英伟达GPU、华为昇腾NPU | 英伟达GPU、华为昇腾NPU | 仅英伟达GPU | 仅英伟达GPU | 仅英伟达GPU | 多平台适配 | 多平台适配 |
| 中文支持 | 优秀(Chinese-SimpleQA 84.4分) | 良好 | 良好(76.8分) | 一般 | 优秀 | 极强 | 强 |
选型结论:① 追求极致性价比、需本地部署 → 优先DeepSeek V4-Flash(轻量任务)或V4-Pro(复杂任务);② 无需本地部署、追求顶级综合能力 → 选择GPT-5.4/Gemini 3.1 Pro;③ 中文场景、企业级性价比 → 通义千问3.0;④ 学术研究、轻量部署 → ChatGLM-5.1。
三、DeepSeek V4 多维度详细测评(真实场景实测)
本次测评基于DeepSeek V4-Pro(思考模式max)和V4-Flash(思考模式high),选取开发者高频使用场景(代码生成、数学推理、长文本处理、Agent任务),结合第三方测评数据,真实还原模型表现,同时指出不足。
1. 代码生成测评(核心优势场景)
测评场景:Python脚本开发、Java接口编写、复杂算法实现(动态规划、二叉树)、代码调试、Docker配置编写,参考Vals AI Vibe Code Benchmark和LiveCodeBench评测数据。
-
V4-Pro表现:在Vals AI测评中以压倒性优势拿下开源权重模型榜首,击败Gemini 3.1 Pro等闭源模型;在LiveCodeBench实时编程评测中拿到93.5分,超过GPT-5.4(91.7分)。实测中,能快速生成可直接运行的代码,支持复杂算法实现,代码注释清晰,能精准识别调试需求并给出解决方案,甚至可适配Claude Code、OpenCode等主流Agent框架。
-
V4-Flash表现:简单代码生成(如接口调用、数据处理脚本)无压力,响应速度比Pro版快30%左右,但复杂算法实现(如分布式计算)会出现逻辑漏洞,需手动优化。
-
不足:对小众编程语言(如Rust、Go)的支持不如GPT-5.4,部分复杂场景下代码可读性有待提升。
2. 数学推理测评
测评场景:初中/高中数学题、高等数学(微积分、线性代数)、竞赛题(奥数、ACM基础题),参考官方自评和第三方测评数据。
-
V4-Pro表现:超越目前所有已公开评测的开源模型,包括Kimi K2.6 Thinking和GLM-5.1 Thinking,比肩顶级闭源模型。实测中,能清晰呈现解题步骤(思考模式加持),复杂微积分推导、线性代数矩阵运算准确率达90%以上,竞赛题正确率接近Claude Opus 4.6非思考模式。
-
V4-Flash表现:基础数学题、简单微积分题正确率85%左右,复杂竞赛题表现一般,解题步骤不够细致,易出现计算失误。
3. 长文本处理测评(核心亮点)
测评场景:100万token长文档(完整书籍、企业财报)总结、多文档对比、长对话上下文保持,重点测试处理速度和细节保留能力。
-
共性表现:全系支持100万token上下文,无需分段处理,处理速度远超同类开源模型------V4-Pro处理100万token文档仅需15分钟左右,V4-Flash仅需8分钟,且能精准保留文档核心细节,上下文连贯性强,无遗忘、错乱问题,这得益于其混合注意力架构的优化。
-
实测案例:上传一份500页的Python编程手册(约80万token),V4-Pro能在12分钟内生成完整目录、核心知识点总结,且能精准回答手册中的具体代码疑问,细节保留率达95%以上。
4. Agent任务测评
测评场景:智能体编程(Agentic Coding)、自动任务调度、多工具调用(搜索、计算、文档生成),参考官方内部测试数据和社区反馈。
-
V4-Pro表现:已成为DeepSeek内部员工的Agentic Coding主力模型,使用体验优于Claude Sonnet 4.5,交付质量接近Opus 4.6非思考模式。实测中,能自主完成"需求分析→代码生成→调试→文档编写"全流程,多工具调用衔接流畅,无卡顿、任务遗漏问题。
-
V4-Flash表现:简单Agent任务(如单一工具调用、基础任务调度)表现良好,复杂多步骤Agent任务易出现逻辑断层,需手动引导。
5. 综合总结(优缺点)
-
核心优势:代码生成、数学推理能力突出(开源第一梯队);长文本处理能力强且成本低;开源免费可商用;双算力平台适配;性价比碾压同类模型;思考模式提升推理准确性。
-
不足:V4-Pro部署门槛高、服务吞吐有限;小众编程语言支持不足;V4-Flash复杂任务表现一般;部分场景下存在轻微幻觉(官方自评与顶级闭源模型有3-6个月差距);中文语义理解虽优于GPT-5.4,但不及通义千问、豆包等国产模型。
四、DeepSeek V4 实战案例(开发者可直接复用)
结合开发者高频场景,整理3个可直接落地的实战案例,涵盖API调用、本地部署、代码生成,附完整代码和步骤,新手也能快速上手。
案例1:API调用(Python)------ 代码生成与调试(最常用场景)
需求:调用DeepSeek V4-Pro的API,生成一个"Python批量处理Excel文件"的脚本,并启用思考模式,查看模型的思维链过程。
步骤:
-
前往DeepSeek官方平台(https://platform.deepseek.com)注册账号,获取API Key;
-
安装依赖包,编写代码(支持OpenAI SDK兼容接口);
-
启用思考模式,调节思考强度,运行代码并查看结果。
python
from openai import OpenAI
# 初始化客户端
client = OpenAI(
api_key="你的API Key", # 替换为自己的API Key
base_url="https://api.deepseek.com"
)
# 调用V4-Pro,启用思考模式(强度max)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "编写一个Python脚本,批量读取指定文件夹下的所有Excel文件,合并成一个新的Excel文件,要求保留所有sheet,处理空值(用0填充),并生成处理日志"}
],
reasoning_effort="max", # 思考强度:max(复杂任务)、high(普通任务)
extra_body={"thinking": {"type": "enabled"}} # 开启思考模式
)
# 输出结果(思维链+最终代码)
print("模型思维链:", response.choices[0].message.reasoning_content)
print("="*50)
print("最终代码:", response.choices[0].message.content)效果:模型会先输出思维链(分析需求→拆解步骤→选择依赖包→编写逻辑),再生成完整代码,包含pandas依赖、文件夹遍历、空值处理、日志生成等功能,可直接复制运行,无需修改核心逻辑。
案例2:本地部署(Ollama)------ 轻量快速部署V4-Flash(适合个人开发者)
需求:通过Ollama部署DeepSeek V4-Flash量化版,实现本地离线推理,无需联网,适合数据隐私要求高的场景。
前提:本地电脑需具备16GB以上显存(如RTX 3090、RTX 4090),已安装Ollama(官网:https://ollama.com/)。
步骤:
-
打开终端(Windows CMD、Linux终端、Mac终端);
-
输入部署命令,自动下载模型并启动:
ollama run deepseek\-v4:q4\_K\_M(q4_K_M为量化版本,平衡性能与显存占用); -
部署成功后,直接在终端输入需求(如"写一个Java接口""总结一段长文本"),即可实现本地离线推理。
注意:V4-Pro本地部署需32GB以上显存(如4张A100 80G),个人开发者建议优先部署V4-Flash;若显存不足,可选择更低精度的量化版本(如q2_K),但推理性能会有所下降。
案例3:长文本处理------ 企业财报分析(实战场景)
需求:使用DeepSeek V4-Pro(本地部署/API),处理一份100万token的企业年度财报(PDF转文本),完成3个任务:① 生成核心财务数据总结(营收、利润、增长率);② 分析财报中的风险点;③ 生成可视化分析建议。
核心代码片段(API调用版):
python
from openai import OpenAI
import os
client = OpenAI(
api_key="你的API Key",
base_url="https://api.deepseek.com"
)
# 读取财报文本(假设已将PDF转为txt文件,路径自行替换)
with open("企业财报.txt", "r", encoding="utf-8") as f:
report_content = f.read()
# 调用V4-Pro处理长文本(100万token无压力)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": f"""请处理以下企业财报文本,完成3个任务:
1. 提取核心财务数据,包括营收、净利润、同比增长率、毛利率,整理成表格形式;
2. 分析财报中提到的风险点(如市场风险、政策风险、运营风险),每条风险点给出简要说明;
3. 针对财务数据和风险点,给出1-2条可视化分析建议(如用什么图表展示数据、重点突出哪些指标)。
财报文本:{report_content}"""}
],
max_tokens=4096 # 根据输出需求调整
)
# 保存结果到文件
with open("财报分析结果.txt", "w", encoding="utf-8") as f:
f.write(response.choices[0].message.content)
print("财报分析完成,结果已保存到文件!")效果:模型能快速处理完整财报文本,精准提取财务数据并生成表格,风险点分析全面,可视化建议贴合实际(如用折线图展示营收增长率、用饼图展示业务占比),无需手动筛选信息,大幅提升工作效率。
五、DeepSeek V4 完整使用指南(API+本地部署)
针对不同需求(快速体验、开发调用、本地部署),整理详细使用指南,覆盖从入门到进阶的全流程,避开常见踩坑点。
1. 快速体验(零门槛,适合新手)
无需部署、无需API Key,直接通过官方在线对话平台体验,步骤如下:
-
访问DeepSeek官方对话平台:https://chat.deepseek.com;
-
注册/登录账号(支持手机号、邮箱登录);
-
在左侧模型列表中选择"DeepSeek V4-Pro"或"DeepSeek V4-Flash";
-
直接输入需求(如"写代码""解数学题""总结文本"),即可获得响应,支持切换思考模式。
注意:在线体验有一定的token限制,适合短期测试,长期开发建议使用API或本地部署。
2. API调用指南(适合开发者集成)
2.1 准备工作
-
注册DeepSeek账号:https://platform.deepseek.com;
-
进入"API Keys"页面,创建新的API Key(仅显示一次,需妥善保存);
-
查看API文档:https://api-docs.deepseek.com/zh-cn/guides/thinking_mode,了解接口参数和限制。
2.2 核心参数说明(重点)
-
model:模型名称,可选"deepseek-v4-pro""deepseek-v4-flash";
-
thinking:思考模式开关,{"type": "enabled"}(开启)、{"type": "disabled"}(关闭),默认开启;
-
reasoning_effort:思考强度,可选"high"(普通任务)、"max"(复杂任务),默认high;
-
max_tokens:最大输出token数,建议根据需求设置(如代码生成设4096,长文本总结设8192);
-
注意:启用思考模式后,temperature、top_p等参数不生效(设置不报错但无作用)。
2.3 常见踩坑点
-
API Key泄露:避免直接硬编码到代码中,建议用环境变量存储;
-
token超限:长文本输入时,需注意输入token数不超过100万,否则会报错;
-
服务吞吐限制:V4-Pro目前受限于高端算力,高峰期可能出现调用失败,建议错峰调用或切换为V4-Flash;
-
接口兼容:DeepSeek V4支持OpenAI和Anthropic格式接口,无需修改原有代码结构,仅需替换base_url和model参数。
3. 本地部署指南(适合企业/隐私需求高的场景)
3.1 部署方式选择
-
个人开发者:优先选择Ollama部署(简单快捷,支持量化版本);
-
专业团队:选择Hugging Face Transformers或vLLM框架部署(可定制化,性能更优);
-
国产算力用户:可在华为昇腾NPU平台部署(已完成适配,需参考官方技术文档)。
3.2 Ollama部署步骤(以V4-Flash为例)
-
安装Ollama:访问https://ollama.com/,根据系统(Windows、Linux、Mac)下载对应安装包,一键安装;
-
启动Ollama:安装完成后,自动后台运行,可通过终端查看状态;
-
下载并部署模型:终端输入命令
ollama run deepseek\-v4:q4\_K\_M,自动下载模型(约10GB左右),下载完成后自动启动; -
测试部署:在终端输入"写一个Python数据处理脚本",模型响应正常即部署成功;
-
停止部署:终端输入
ollama stop deepseek\-v4:q4\_K\_M,即可停止模型运行。
3.3 部署注意事项
-
硬件要求:V4-Flash需16GB+显存,V4-Pro需32GB+显存,显存不足会导致部署失败;
-
网络要求:下载模型时需联网,部署完成后可离线使用;
-
量化版本选择:q2_K(显存占用最低,性能一般)、q4_K_M(平衡性能与显存)、q8_0(性能最佳,显存占用最高),可根据自身硬件选择;
-
国产算力适配:华为昇腾NPU部署需参考官方技术报告,目前开源层面主要支持NVIDIA CUDA工具链。

六、总结与展望
DeepSeek V4的发布,无疑为开源大模型领域带来了重大突破------它以"开源+极致性价比+顶级性能"打破了闭源模型的垄断,尤其是在代码生成、长文本处理、数学推理等场景的表现,完全满足开发者的日常开发需求,同时双版本矩阵、多算力适配,让不同需求的用户都能找到合适的使用方式。
从测评结果来看,DeepSeek V4-Pro已跻身开源模型第一梯队,比肩顶级闭源模型,而V4-Flash则以极高的性价比,成为个人开发者和中小企业的首选;但同时,它也存在部署门槛高、小众场景支持不足等问题,期待后续版本能进一步优化。
对于开发者而言,若你需要本地部署、追求高性价比,或重点关注代码、长文本处理场景,DeepSeek V4绝对值得深入研究和落地;若你追求极致综合能力、无需本地部署,可结合GPT-5.4、Gemini 3.1 Pro等闭源模型使用,实现优势互补。
后续,随着华为昇腾950超节点的批量上市,DeepSeek V4-Pro的价格有望进一步下调,服务吞吐也将提升,届时其竞争力将进一步增强。建议开发者持续关注官方更新,及时掌握模型优化动态,将其高效应用到实际开发中,提升开发效率。
附录:相关资源(快速获取)
-
DeepSeek官方对话平台:https://chat.deepseek.com(快速体验);
-
API文档:https://api-docs.deepseek.com/zh-cn/guides/thinking_mode;
-
开源模型下载(Hugging Face):https://huggingface.co/collections/deepseek-ai/deepseek-v4;
-
开源模型下载(ModelScope):https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4;
-
官方技术报告:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf。