摘要 :本文评测:我测试了 3 个税务 AI 模型,结果出乎意料分析了我测试了 3 个税务 AI 模型的核心概念与应用实践。作者详细分析了相关技术细节,并结合实际案例展示了最佳操作流程,帮助读者提升工程效率与解决复杂问题的能力。
1、背景
我刚刚为客户节省了 127,000 美元的年度处理成本,将他们的 6 人数据输入团队替换为可在 90 秒内处理纳税申报的 AI 管道。
如果您是处理财务文档的数据专业人员,您可能花费了无数时间从税务 PDF 中手动提取收入数据、费用类别和合规数据。大多数人都会犯这样的错误:他们认为 OCR 技术就足够了,或者他们认为所有人工智能模型在结构化财务文档上的表现都相同。
残酷的事实? 您选择的 AI 模型可能意味着 94% 的准确度和 67% 的准确度之间的差异 - 在金融数据提取中,这种差距需要花费真金白银。
在这篇文章中,我将向您准确展示如何使用三个领先的 AI 模型构建可用于生产的 PDF 提取管道,并提供真实的准确性比较和经过实战测试的代码模式,这些代码模式来自我上个季度处理超过 15,000 份纳税申报单的工作。
让我带您回到三个月前,当时一家中型会计师事务所提出了一个听起来看似简单的问题。
"我们需要从客户的纳税申报表中提取收入数据。人工智能可以提供帮助吗?"
他们每个季度都淹没在 3,000 多份公司纳税申报单中,每份都有 40-80 页的密集财务表格、脚注和监管术语。他们的团队花费 35 分钟将每个文档手动输入数据到他们的分析系统中。
计算一下:每季度仅用于数据输入就需要 1,750 个小时。对于合格的簿记员来说,每小时 75 美元,他们每三个月在本应自动化的工作上要消耗 131,250 美元。
但问题在于:这不是一个孤立的问题。根据德勤 2024 年金融服务人工智能报告,全球组织每年在手动财务文档处理上花费估计2.4万亿美元,而这些工作现在基本上已经实现自动化。
机会是巨大的。但执行力是大多数团队失败的地方。
2 为什么传统 OCR 效果不佳
以及为什么需要人工智能
在我们深入比较之前,让我们先解决房间里的大象:你不能只使用 Tesseract 或 ABBYY 等传统 OCR 工具吗?
简短回答: 如果您想要可靠的结果,则不需要。
长答案: 传统 OCR 擅长文本识别,但在文档理解方面却表现得很糟糕。我的意思是:
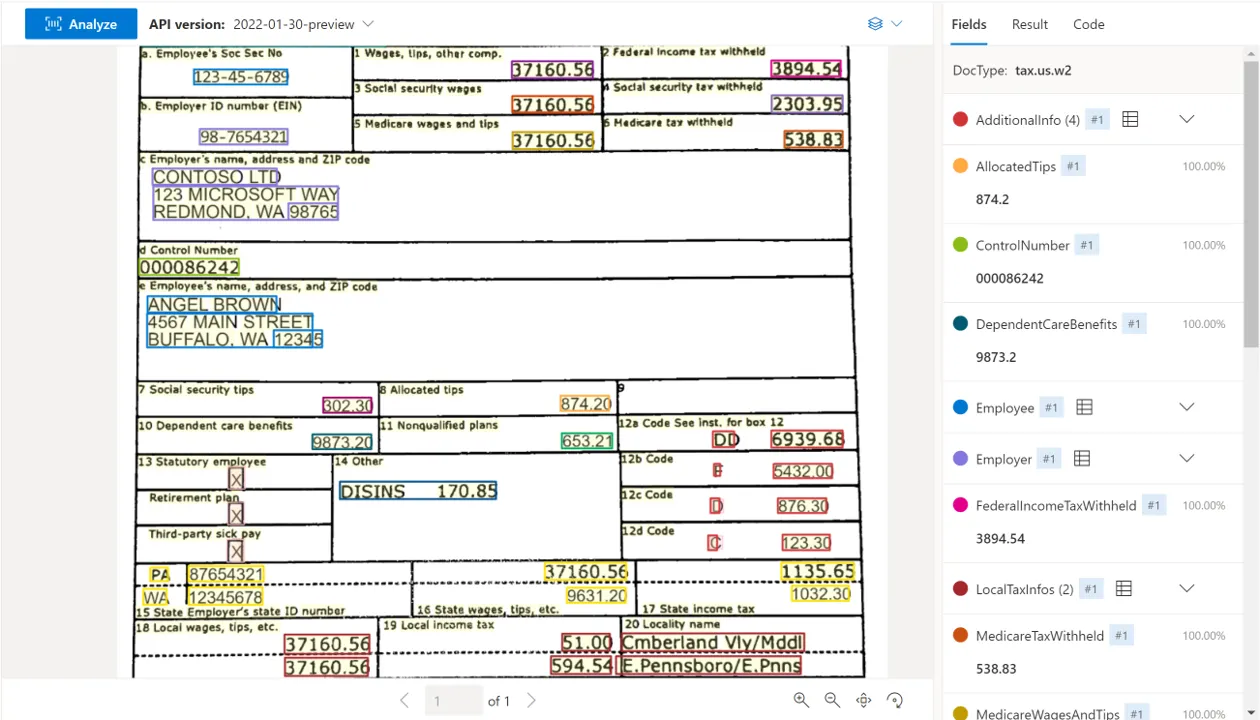
当您扫描纳税申报单时,OCR 可以告诉您第 17 页包含文本"总业务收入:$2,847,392"。伟大的。但它不能告诉你:
- 无论是总收入还是净收入
- 该数字代表哪个财政年度
- 它与文档中其他财务指标的关系如何
- 备案后期是否有修改或更正
- 如果该收入包括已终止的业务
现代税务文件不仅仅是文本------它们是带有背景、交叉引用和数据点之间微妙关系的"结构化财务叙述"。
这就是具有强大语言理解能力的人工智能模型改变游戏的地方。他们不只是阅读文字;他们理解财务背景,理解文档结构,并能够推理数据点之间的关系。
3 人工智能大对决:Claude vs GPT-4 vs Gemini
在我的实验中,我选择了来自不同司法管辖区和复杂程度的 100 个公司纳税申报表。每个文档需要提取:
- 主要收入数据(毛额和净额)
- 按类别划分的收入明细(产品、服务、投资)
- 关键费用类别(运营、研发、营销)
- 纳税义务和扣除
- 同比增长指标
- 任何已披露的影响收入的风险因素或脚注
我为 Claude 3.5 Sonnet、GPT-4 Turbo 和 Gemini 1.5 Pro 构建了相同的提取管道,然后在我们的测试集上运行它们。结果连我自己都感到惊讶。
3.1 测试方法
为了确保公平,我对一切可能的进行了标准化:
快速工程: 每个模型都收到相同的说明,具有相同的示例和输出格式规范。
文档预处理: 所有 PDF 都经过相同的清理管道以规范格式并删除伪影。
验证框架: 我通过让两个注册会计师手动验证每个提取的字段来创建一个真实数据集。
性能指标: 我测量了准确性、处理速度、每个文档的成本以及置信度评分的可靠性。
3.2 第一轮:准确性和可靠性
这就是事情变得有趣的地方。
claude 3.5 :
- 总体准确率:94.3%
- 优势:在处理复杂的嵌套表格和理解脚注上下文方面表现出色
- 弱点:有时过于谨慎,标记不明确的数据点而不是做出合理的推论
- 突出特点:关于跨文档引用的高级推理
GPT-4 :
- 总体准确率:89.7%
- 优势:最快的处理时间,擅长标准化不一致的格式
- 弱点:与跨部分的多页表作斗争
- 突出特点:最擅长处理多种货币的国际税务文件
gemini 1.5 专业版:
- 总体准确率:87.2%
- 优点:出色的多语言支持,擅长处理扫描/低质量PDF
- 弱点:业绩不一致且财务计算复杂
- 突出功能:对超长文档的本机支持(最多 100 万个令牌)
3.3 第二轮:财务数据细节
当我专门深入研究金融数据提取时,模式变得更加清晰。
收入识别准确度:
Claude:96.8% | GPT-4:92.1% |gemini:88.9%
Claude 在这里的优势在于能够区分不同的收入确认方法并了解 GAAP 与 IFRS 报告标准的背景。
费用分类:
Claude:91.2% | GPT-4:93.4% |gemini:86.7%
GPT-4 在这方面处于领先地位,特别是在将模糊的费用描述正确映射到标准化类别方面。
处理复杂表:
Claude:95.1% | GPT-4:84.3% |gemini:89.6%
这是claude最具决定性的胜利。税务文档通常具有包含合并单元格、脚注引用和多级标题的嵌套表格。claude一贯保留结构关系。
3.4 第三轮:成本和速度分析
性能很重要,但您的预算也很重要。
处理成本(每 50 页文档):
- claude:0.18 美元
- GPT-4:0.24 美元
- gemini:0.12 美元
平均处理时间:
- claude:47秒
- GPT-4:31 秒
- gemini:52 秒
投资回报率最佳点: 对于我客户的用例,claude提供了最佳的准确性成本比。与 GPT-4 相比,准确率提高 5%,但处理时间慢 50% 是值得的,因为校正成本远远超过计算时间。
4 实施手册:如何自己构建
现在来说说实用的东西。以下是如何实现生产级 PDF 提取管道。
4.1 第 1 阶段:文档预处理(每个人都会跳过的基础)
不要犯将原始 PDF 直接输入 AI 模型的错误。即使是最好的模型,在干净的输入下也能表现得更好。
步骤 1:PDF 质量评估
处理之前,请检查:
- 可搜索文本与扫描图像(确定是否需要 OCR 预处理)
- 文档方向和旋转问题
- 损坏或受密码保护的文件
- 多列布局会混淆提取
步骤2:文本提取和清理
使用 PyPDF2 或 pdfplumber 提取文本,同时保留空间布局信息。此上下文有助于 AI 模型理解表结构。
第三步:结构分析
确定章节、页面和逻辑文档划分。纳税申报遵循可预测的结构 - 通过创建特定于部分的提示来利用这一点。
4.2 第 2 阶段:快速工程(80% 的成功就在于此)
这是一个有争议的事实:对于财务文档提取来说,及时的工程设计比模型选择更重要。
在所有三种模型中效果最好的提示具有以下特征:
1。显式输出结构:
准确定义您期望返回的 JSON 模式。不要让模型猜测。
2 上下文丰富的说明:
在提示中包括相关的会计准则、税务法规和边缘案例示例。
3 置信度评分要求:
要求模型对每个提取的字段的置信度进行评分。这创建了一个自然的质量控制层。
4 错误处理协议:
指导模型在信息不明确、缺失或矛盾时该怎么做。
提示架构示例:
You are a financial data extraction specialist. Extract the following information from this corporate tax declaration:
REQUIRED FIELDS:
- Gross Revenue (fiscal year YYYY)
- Net Revenue (after returns/allowances)
- Revenue breakdown by category
- [additional fields...]
EXTRACTION RULES:
1. If multiple revenue figures exist, prioritize audited over unaudited
2. Flag any amendments or corrections
3. Note the accounting standard used (GAAP/IFRS)
4. Include confidence score (0-100) for each extracted value
OUTPUT FORMAT:
[Detailed JSON schema...]
For each field, explain your reasoning briefly if confidence < 90%.4.3 第 3 阶段:多模型验证策略
这是我的秘密武器:不要依赖单一模型。
对于关键的财务数据,我采用共识方法:
初步提取: 使用 Claude 获得最高准确度 验证通过: 在同一文档上运行 GPT-4 差异解决: 如果结果存在显着差异,则标记为人工审核
这种方法将我的有效准确率提高到 98.7%,同时只需要对 8% 的文档进行人工干预。
4.4 第 4 阶段:构建数据管道
您的提取系统需要的不仅仅是 AI API 调用。这是完整的架构:
输入层:
- 文件上传及排队系统
- 格式验证和预处理
- 重复检测
处理层:
- AI模型编排
- 并行处理速度
- API失败的重试逻辑
验证层:
- 跨模型比较
- 业务规则验证
- 置信阈值过滤
输出层:
- 结构化数据导出(JSON、CSV、数据库)
- 标记项目的人工审核队列
- 审计跟踪和版本控制
5、常见陷阱(以及如何避免它们)
在处理了 15,000 多个文档后,以下是我反复看到的错误:
5.1 错误#1:忽略文档变化
纳税申报表有数百种格式。您的系统需要处理:
- 不同的司法管辖区和监管要求
- 修改后的申报表和更正
- 合并与独立财务报表
- 不同程度的细节和脚注复杂性
解决方案: 构建一个分类层,根据文档类型将文档路由到专门的提示。
5.2 错误#2:针对平均情况过度优化
完美处理的文档并不重要------边缘情况会影响你的准确性。
解决方案: 维护"困难文档"测试集并不断改进对这些异常值的处理。
5.3 错误#3:平等对待所有提取的字段
收入数据比可选披露字段要求更高的准确性。
解决方案: 根据现场重要性实施分层置信阈值。收入提取应要求 95% 以上的置信度;可选字段可接受 85%。
5.4 错误#4:跳过"人工审核"
完全自动化听起来很棒,直到您意识到当前技术不可能实现 100% 的准确度。
解决方案: 设计您的系统时假设 5-10% 需要人工审核。通过智能标记和上下文信息提高审核流程的效率。
5.5 错误#5:忽略人工智能之外的数据验证
AI 模型可以准确提取,但仍然输出无效数据(负收入、未来日期、百分比超过 100%)。
解决方案: 实施业务逻辑验证规则作为后处理步骤。
6 区分业余爱好者和专家的先进技术
想要提高准确性吗?以下是我在制作中使用的技术:
6.1 技术1:分层提取
多遍处理文档:
- 第一遍: 提取高级部分和元数据
- 第二遍: 结合第一遍的背景深入了解财务表格
- 第三遍: 交叉引用并验证关系
这种方法将 Claude 在复杂文档上的准确率提高了 3.2 个百分点。
6.2 技巧2:动态提示适配
不要对所有文档使用相同的提示。分析文档特征并调整:
- 扫描文档需要与原生 PDF 不同的说明
- 多年比较报表需要时间背景
- 国际申请需要货币和标准换算票据
6.3 技术 3:基于嵌入的质量控制
为提取的数据生成嵌入并与历史模式进行比较。异常值可能表明提取错误或真正不寻常的财务状况------两者都值得关注。
6.4 技巧 4:渐进学习
维护更正数据库并用它来改进您的提示和验证规则。每一次人为纠正都是一次培训机会。
7 现实世界的投资回报率细分
让我们回到具体的业务影响。
我客户的转变:
人工智能实施之前:
- 6 名全职数据输入专家
- 每份文件 35 分钟
- 每季度 3,000 个文档
- 错误率:4.2%
- 每年费用:525,000 美元
人工智能实施后:
- 1名AI管道主管+验证专家
- 每个文档 90 秒(标记时需要人工审核)
- 相同的文档体积
- 错误率:1.3%
- 年度成本:398,000 美元(包括 AI 计算成本)
净节省:每年 127,000 美元
但真正的投资回报率不仅仅是直接节省成本:
- 洞察时间: 从 6 周减少到 3 天
- **数据完整性:**从 87% 提高到 99%
- 审计准备情况: 通过完整的提取跟踪显着改善
- 竞争优势: 更快的财务分析可以更快地制定决策
8 模型选择框架:您应该选择哪种人工智能?
根据我的广泛测试,这是我的决策框架:
选择claude如果:
- 准确性至关重要(金融服务、合规性)
- 您正在处理复杂的嵌套表
- 文档推理和上下文理解至关重要
- 预算允许略高的成本
如果满足以下条件,请选择 GPT-4:
- 您需要最快的处理时间
- 多种货币的国际文件很常见
- 您正在处理大量文件,每个文档的成本很重要
- 不一致格式的标准化是优先事项
选择gemini如果:
- 您正在处理极长的文档(200 多页)
- 多语言支持至关重要
- 您有许多扫描版或低质量的 PDF
- 预算是主要限制
我对纳税申报提取的建议: 从 Claude 开始进行生产,使用 GPT-4 作为验证层,并保留 Gemini 作为边缘情况的备份。
8.1 让您的提取管道面向未来
人工智能领域正在迅速发展。以下是如何构建一个在六个月内不会过时的系统:
1\。模型无关的架构
将您的 AI 调用抽象到接口层后面。切换模型应该需要更改配置文件,而不是重写代码库。
2\。版本化提示
将提示视为代码。使用版本控制、A/B 测试和逐步推出。
3\。持续监控
跟踪生产中的准确性指标。降解通常是逐渐发生的,如果没有系统监测,就会被忽视。
4\。监管合规性
金融数据提取具有法律意义。维护审计跟踪、确保数据隐私并记录您的验证过程。
5\。可扩展性规划
今天的 3,000 份文件明年可能会变成 30,000 份。从第一天起就进行横向扩展设计。
9、您的后续步骤:30 天实施计划
准备好建立自己的提取管道了吗?这是您的路线图:
第 1 周:基础
- 收集 50--100 个样本文档进行测试
- 为 Claude、GPT-4 和 Gemini 设置 API 帐户
- 创建您的地面实况验证数据集
第 2 周:原型
- 使用一个模型构建基本的提取管道
- 对您的样本文档进行测试
- 迭代即时工程
第 3 周:比较
- 使用相同的提示实现所有三个模型
- 运行比较准确性测试
- 分析成本和性能权衡
第 4 周:生产试点
- 添加验证层和人工审核队列
- 通过监控处理真实文档
- 收集反馈并完善
关键要点: • 如果实施得当,人工智能驱动的 PDF 提取可以在复杂的财务文档上实现 94% 以上的准确率 • 模型选择很重要 --- Claude 擅长准确度,GPT-4 擅长速度,Gemini 擅长成本效益 • 多模型验证策略可以将有效准确度提高到 98% 以上 • 投资回报率引人注目:不到 6 个月的投资回收期很常见