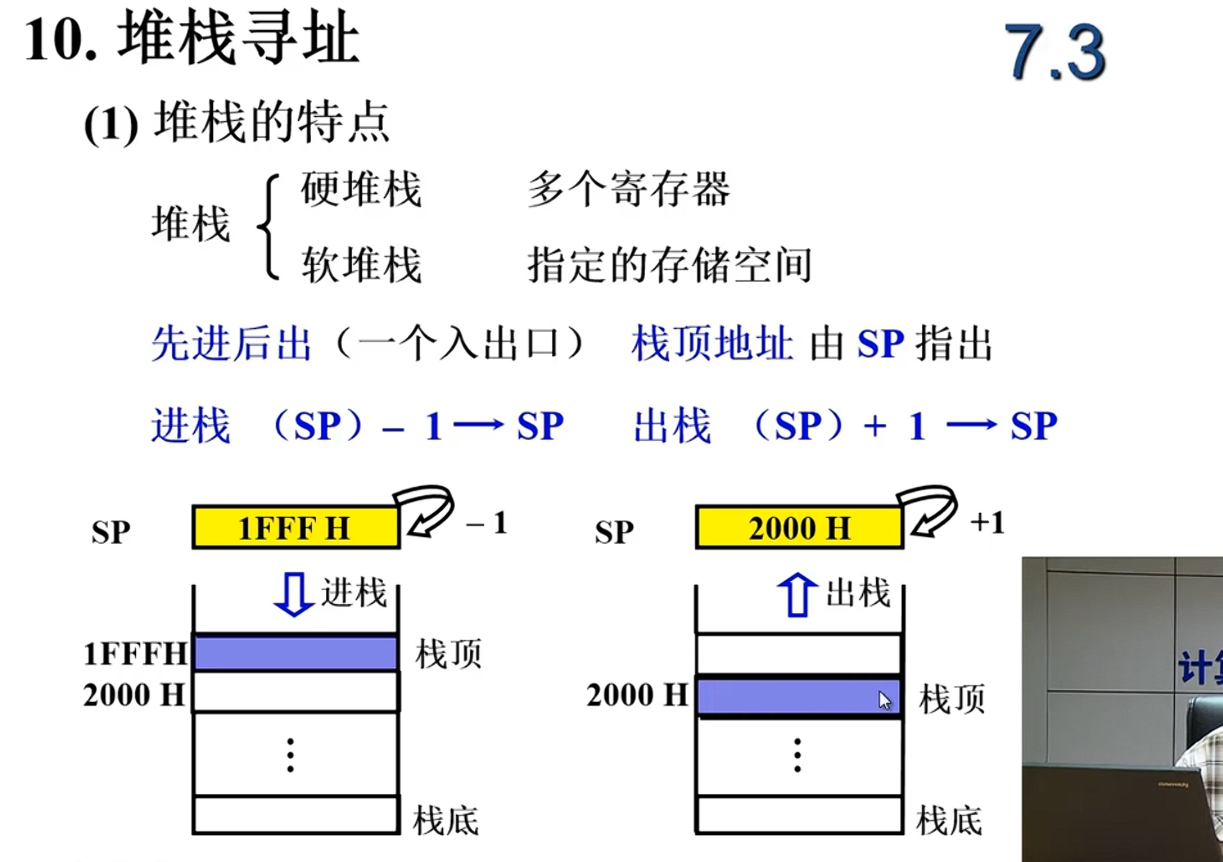
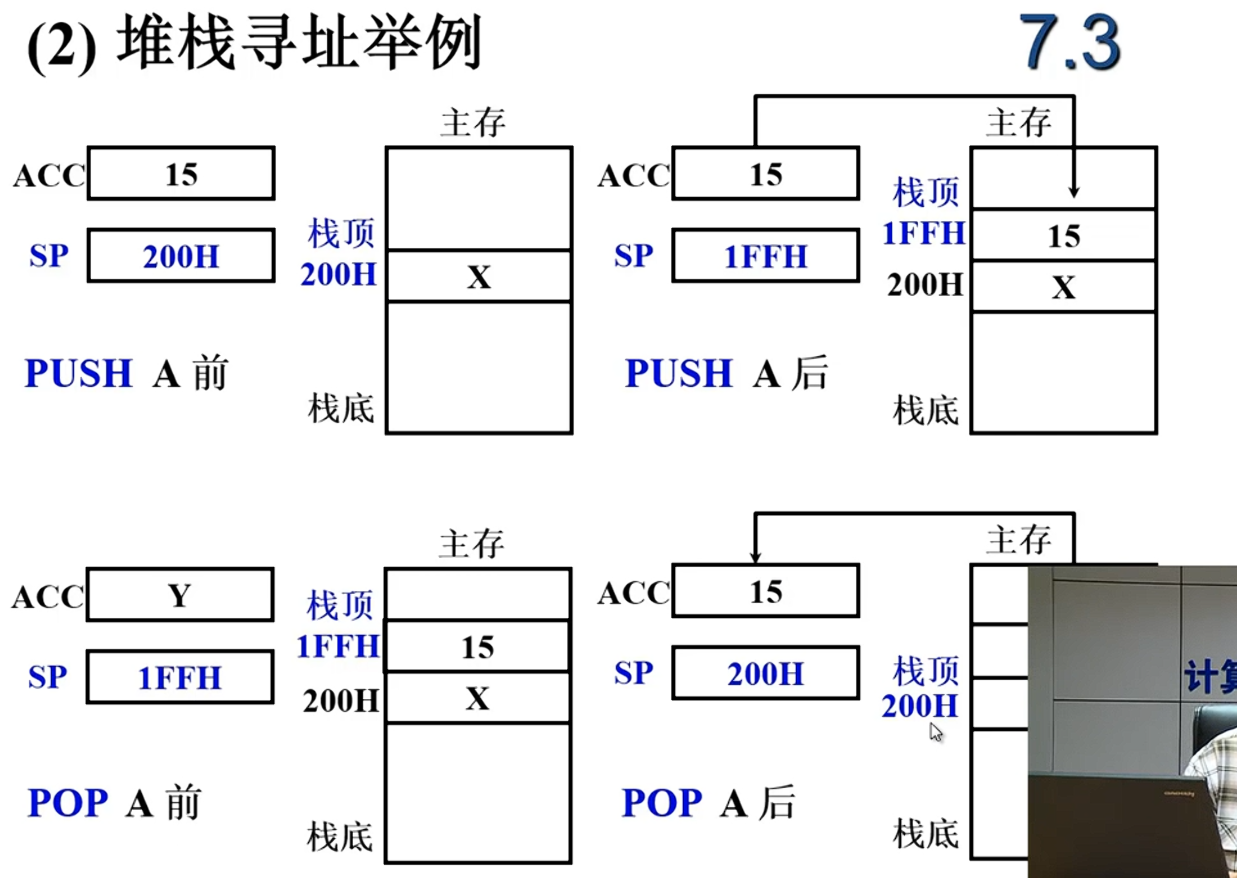
开始

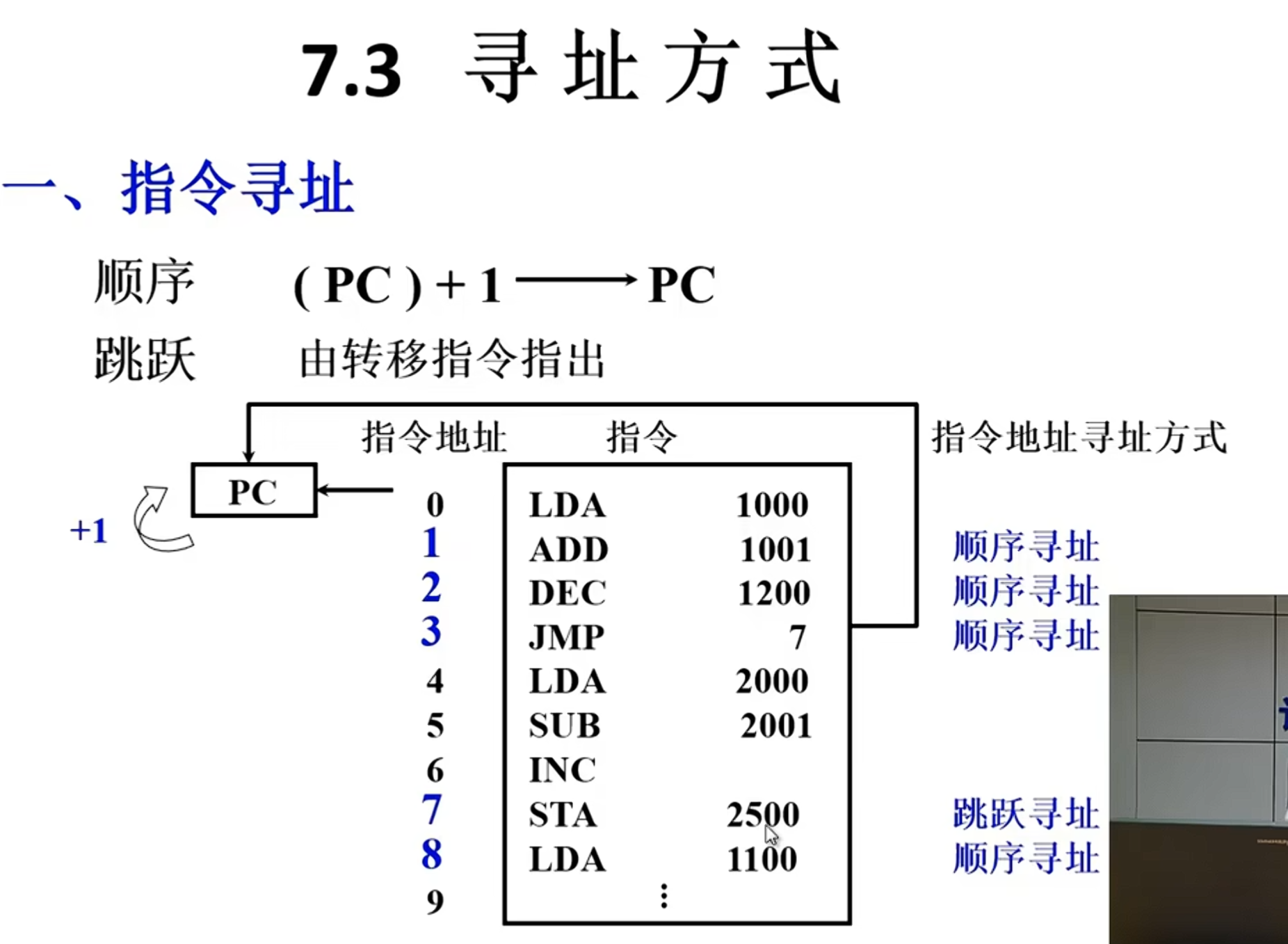

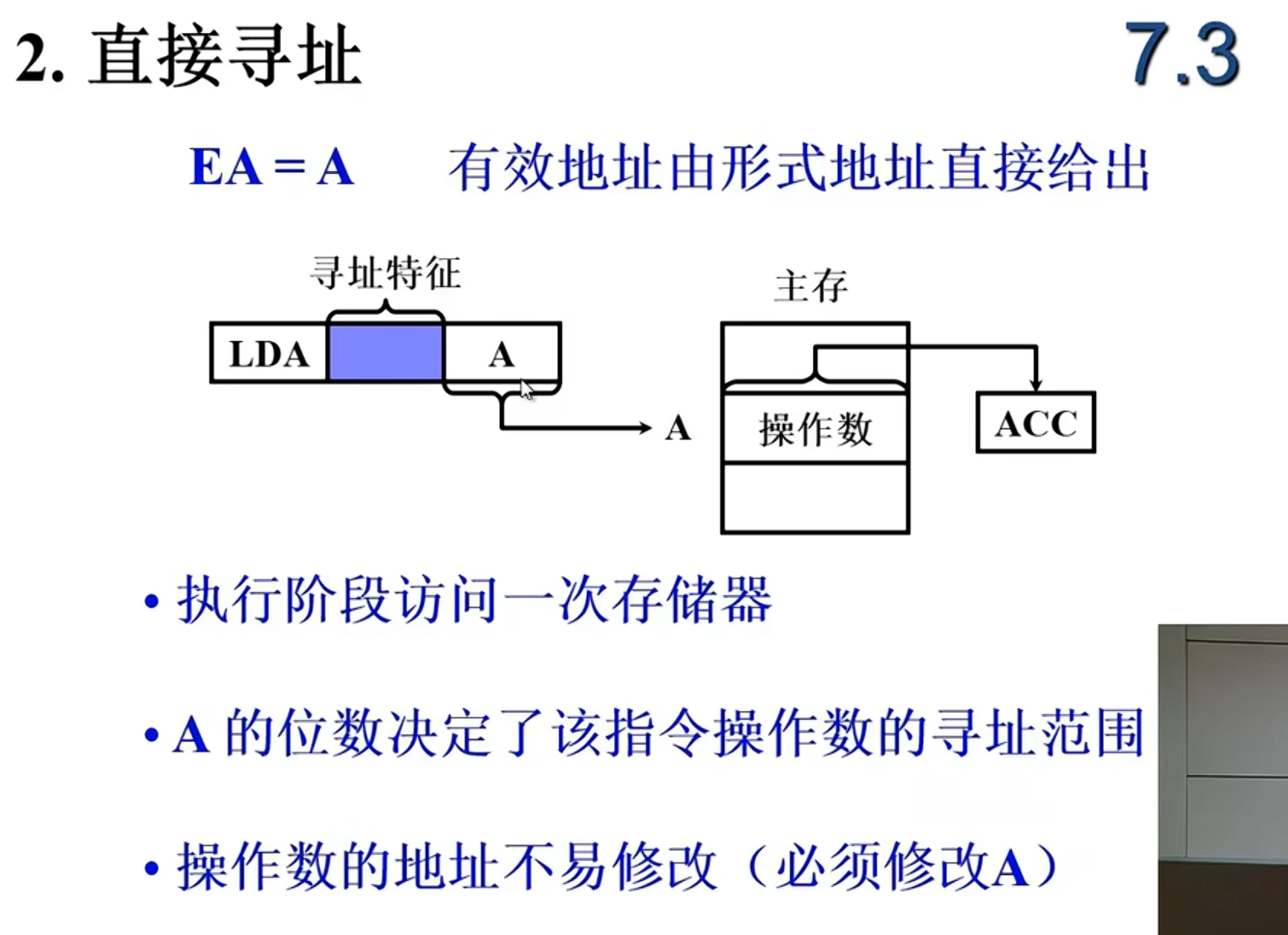
LDA 2000H ; 把内存地址 2000H 处的数据加载到累加器 ACC。
不易修改是什么意思?
你问的这句话:
"操作数的地址不易修改(必须修改A)"
是直接寻址方式的一个缺点,我们来逐句解释它的含义。
📌 一、什么是"操作数的地址"?
在指令中,"操作数的地址"指的是:数据实际存放在内存中的哪个位置。
比如这条指令:
assembly
LDA 2000H ; 把内存地址 2000H 处的数据加载到累加器 ACC这里的 2000H 就是操作数的地址。
📌 二、"不易修改"是什么意思?
意思是:
如果你想让程序去访问另一个内存地址的数据 ,你就必须改写指令本身 ------ 也就是改指令里的形式地址 A。
✅ 举个例子:
假设你有这样一段代码:
assembly
LDA 1000H ; 加载地址 1000H 的数据 → ACC
...
LDA 2000H ; 加载地址 2000H 的数据 → ACC如果你后来发现,原来存在 1000H 的数据现在移到了 3000H,那你必须手动把第一条指令改成:
assembly
LDA 3000H ; 修改了形式地址 A否则程序还是会去读旧的 1000H,导致错误!
📌 三、为什么说"必须修改A"?
因为在直接寻址中:
- 指令格式是:
[操作码] [形式地址 A] - 有效地址 EA = A (即:形式地址就是真实地址)
- 所以,要改变访问的内存位置 → 只能改 A
👉 这就是"必须修改A"的意思。
📌 四、对比其他寻址方式(为什么它们"易修改"?)
| 寻址方式 | 是否容易修改操作数地址? | 原因 |
|---|---|---|
| 直接寻址 | ❌ 不易 | 必须改指令中的 A |
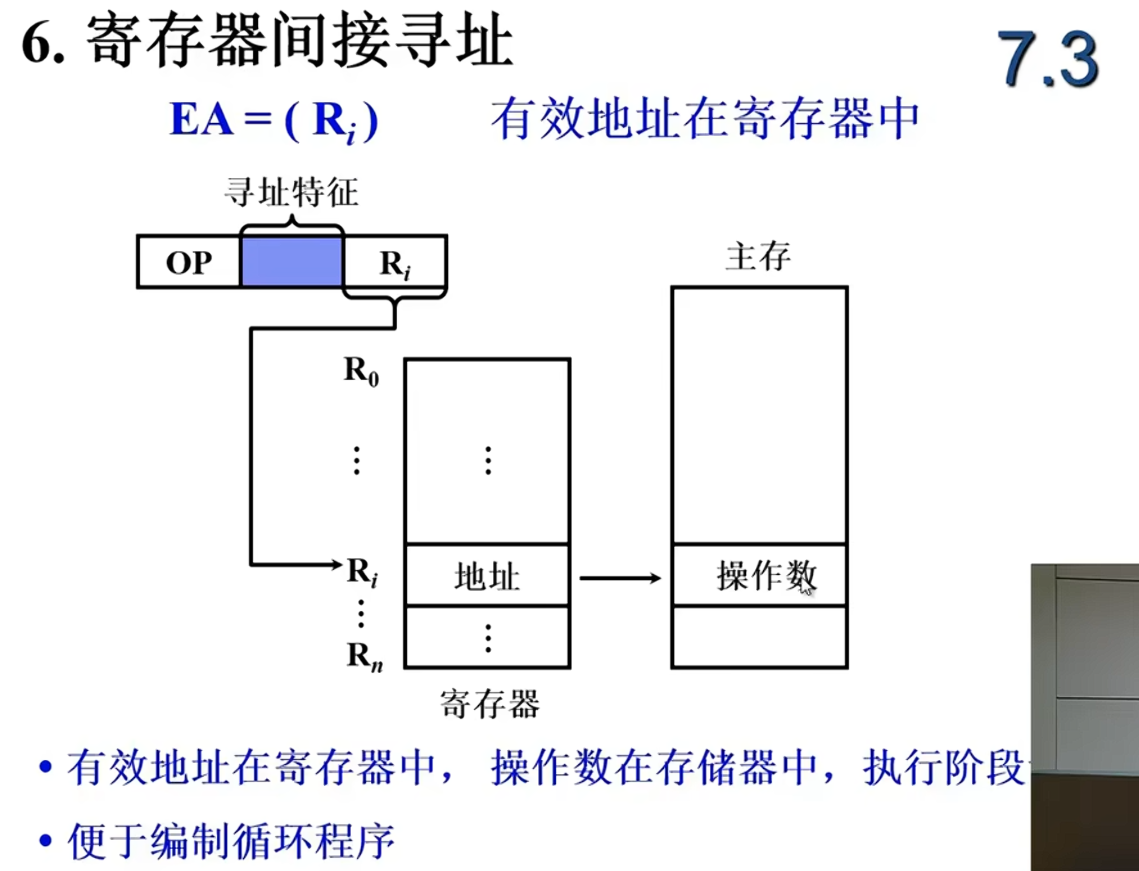
| 寄存器间接寻址 | ✅ 易 | 只需改寄存器内容,不用改指令 |
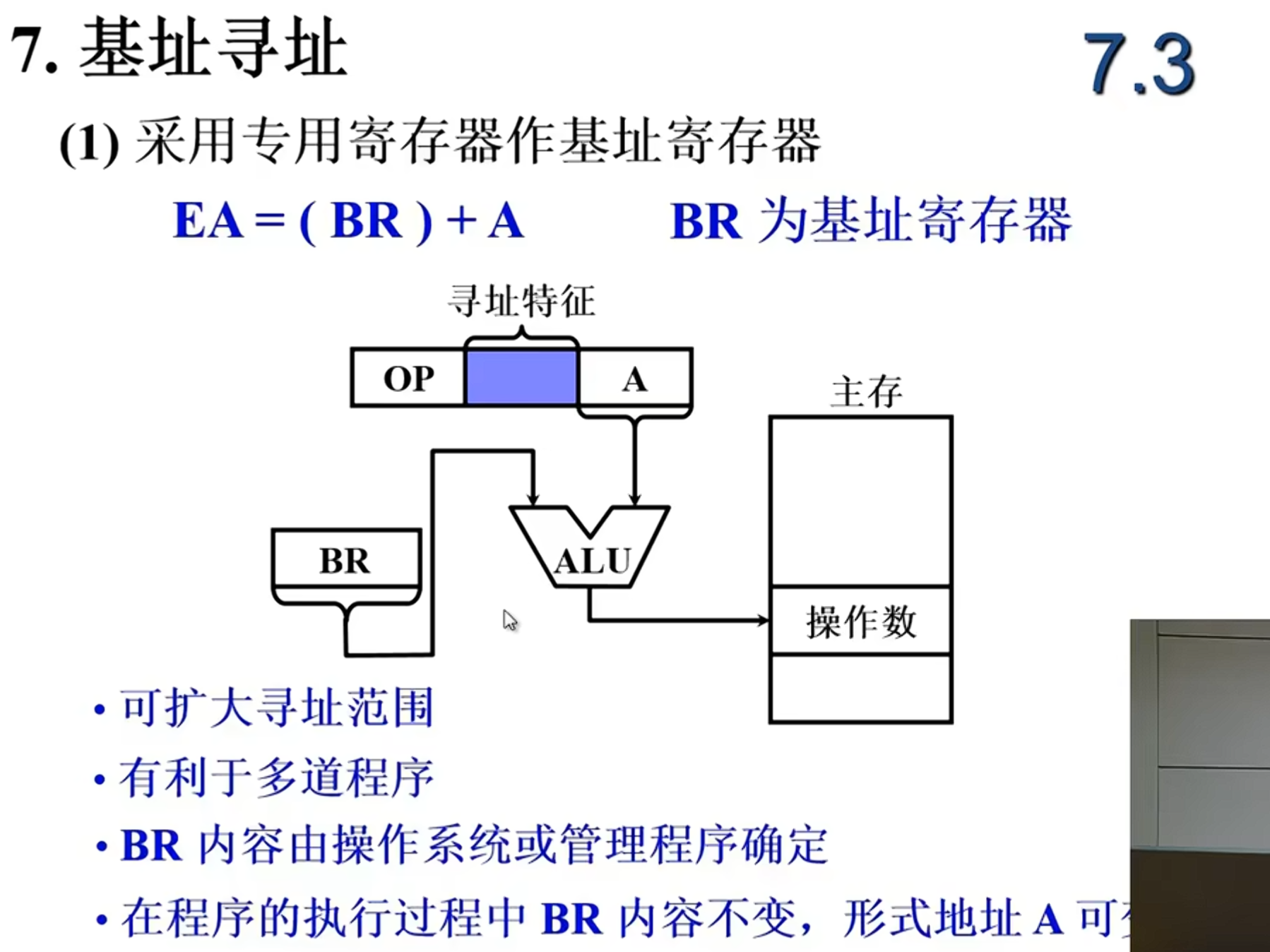
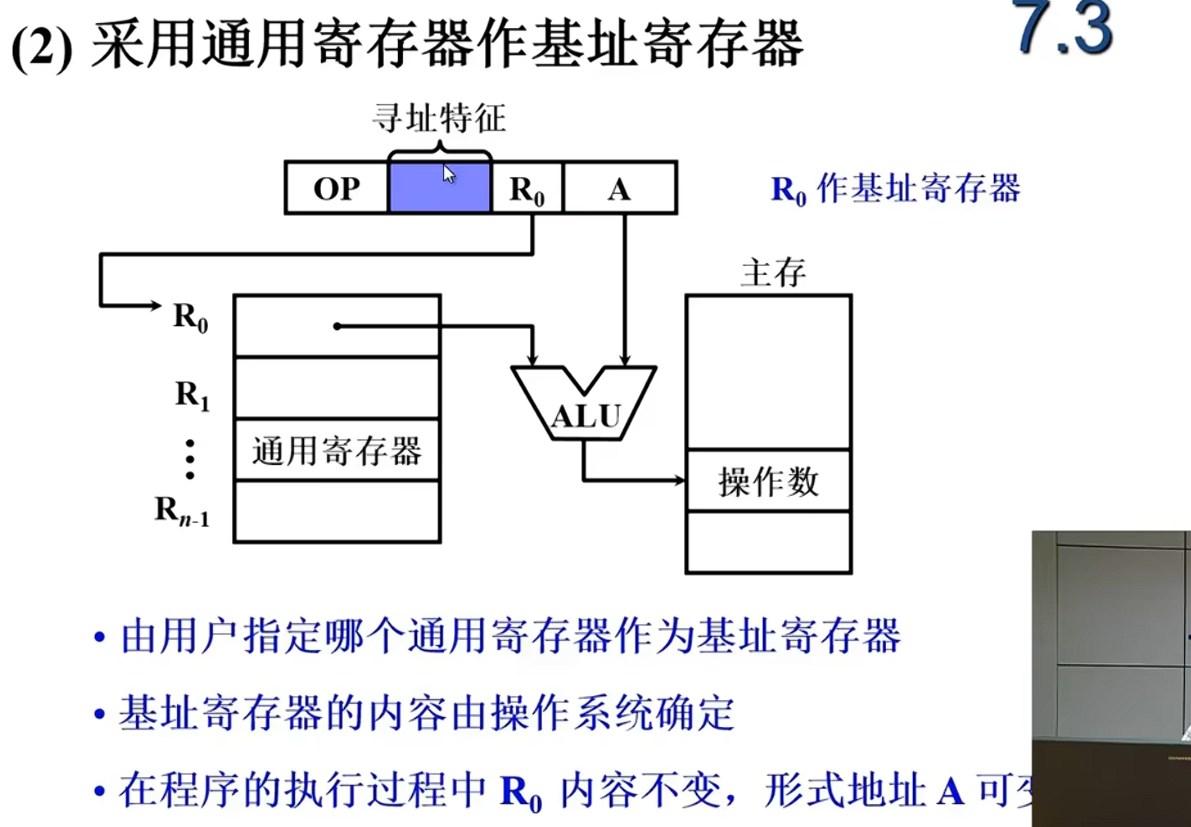
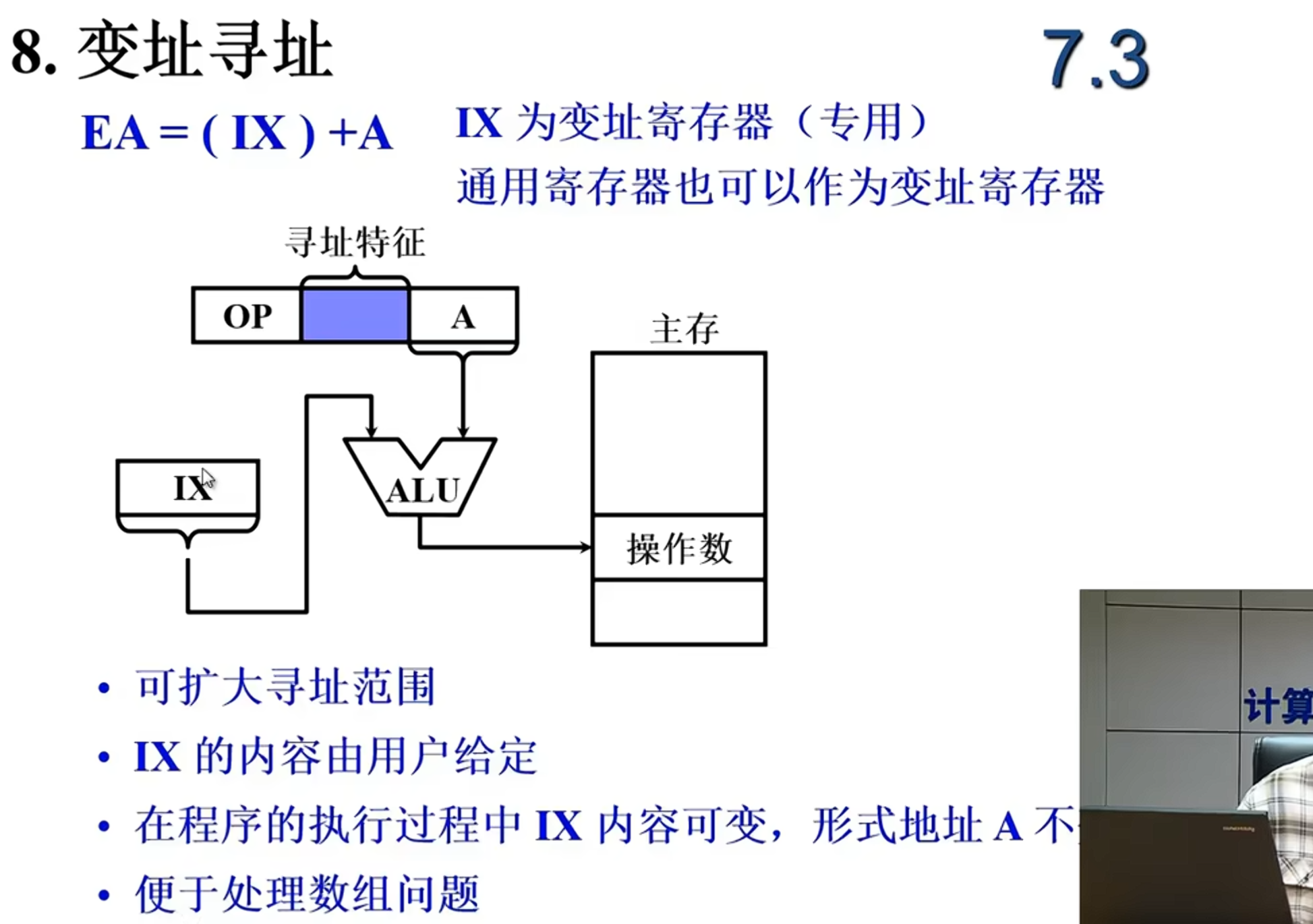
| 基址/变址寻址 | ✅ 易 | 改基址寄存器或变址寄存器即可 |
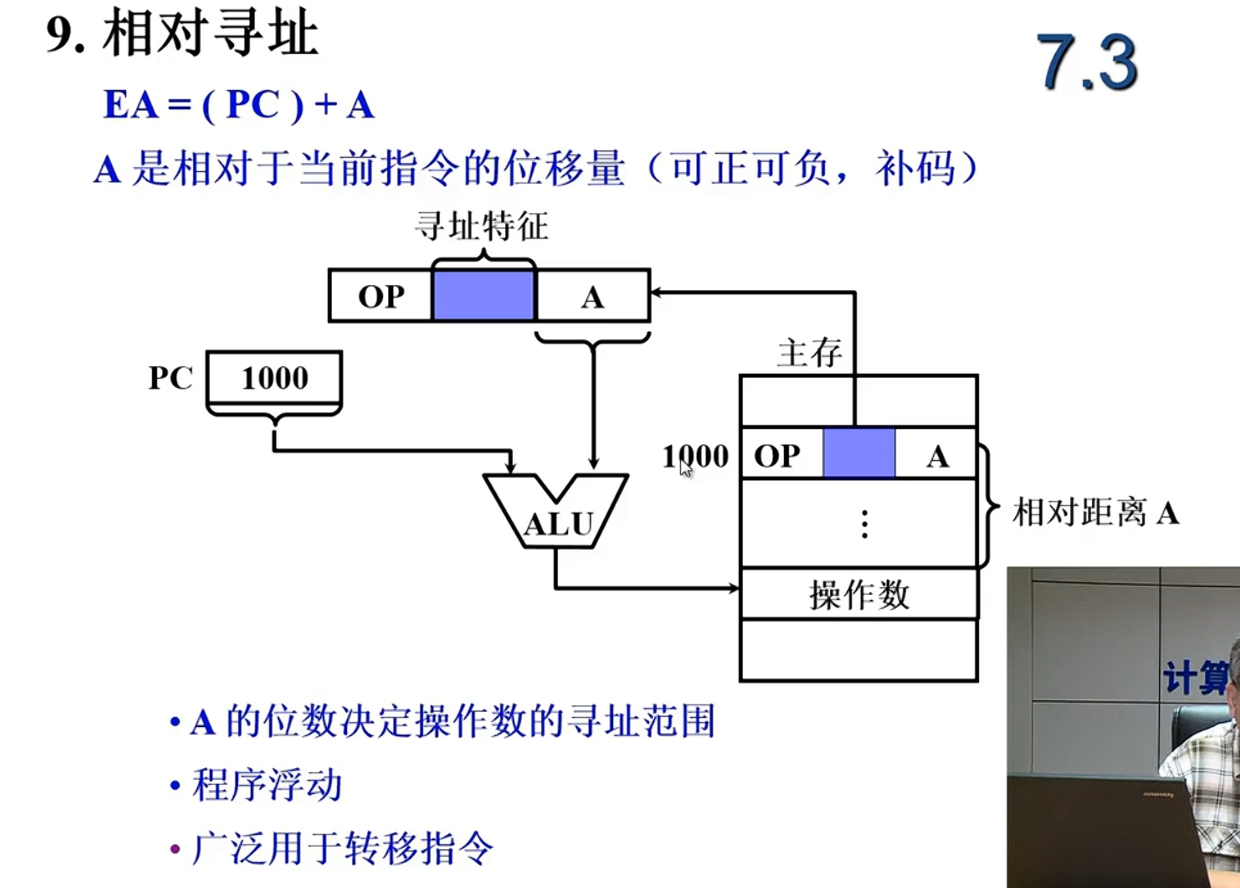
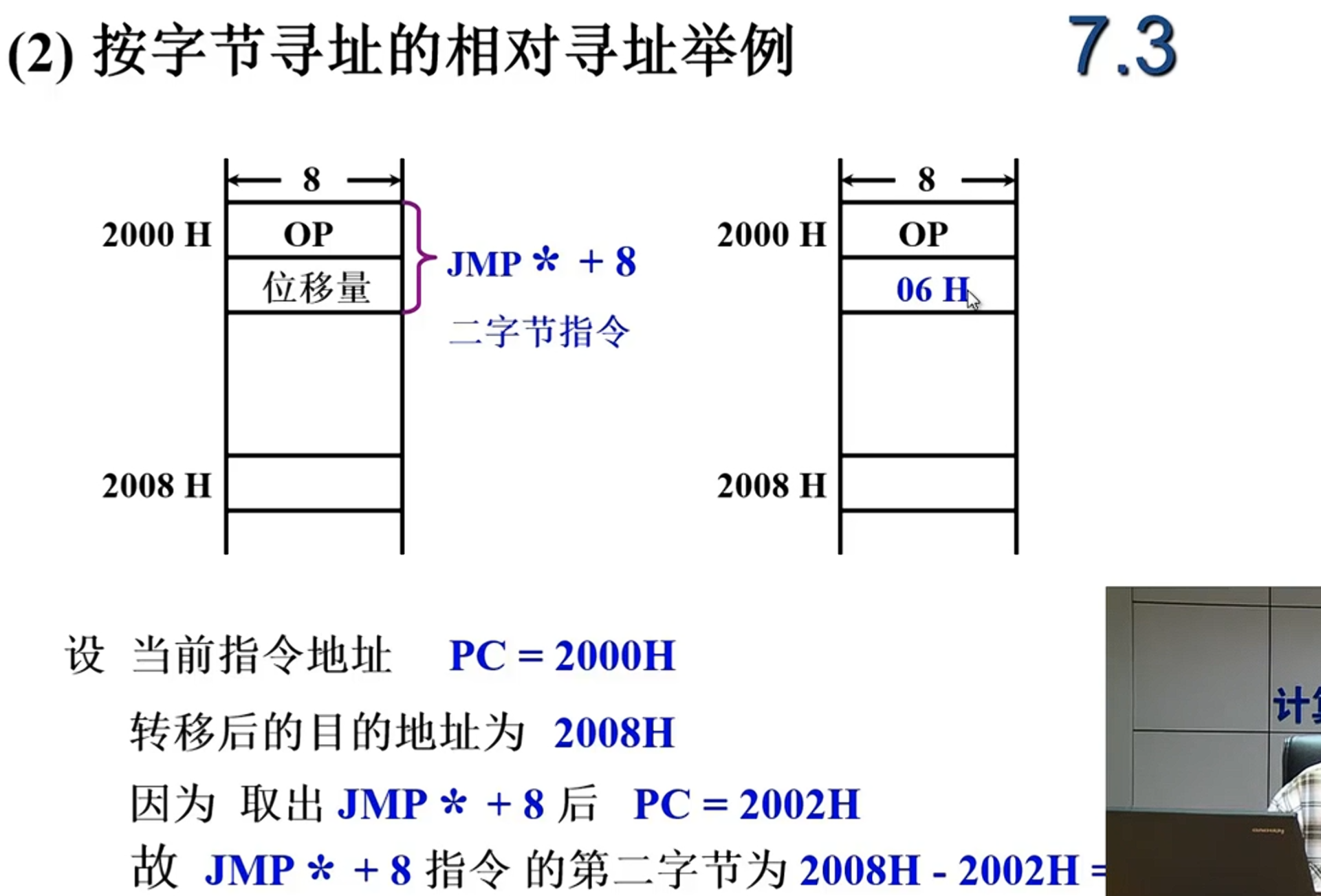
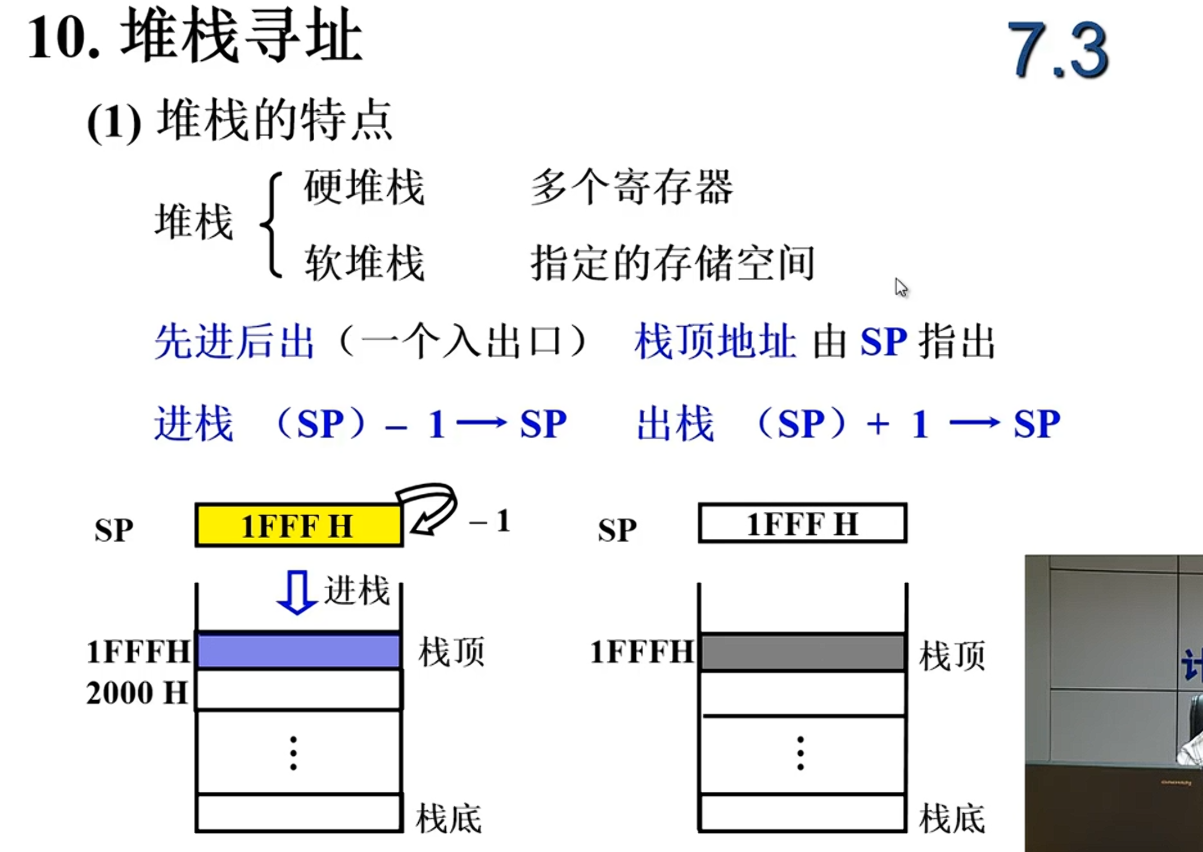
| 相对寻址 | ✅ 易 | 改偏移量或PC值 |
✅ 举例:用寄存器间接寻址
assembly
MOV R0, #1000H ; R0 指向 1000H
LDA (R0) ; 加载 R0 指向的地址的数据
; 后来想改地址?
MOV R0, #3000H ; 只需改寄存器!指令 LDA (R0) 不用动!→ 这种方式更灵活,适合循环、数组等场景。
📌 五、总结一句话:
"操作数的地址不易修改(必须修改A)"
→ 在直接寻址中,若要访问不同内存地址的数据,必须重新编写或修改指令中的地址字段 A,不能通过运行时动态调整实现,因此灵活性差。
💡 实际应用影响:
- 直接寻址适合固定地址访问(如常量、配置项)
- 不适合需要频繁切换数据源的场景(如数组遍历、函数参数传递)
- 现代计算机多用间接寻址、基址寻址、变址寻址来提高灵活性
让我来帮你理清这个逻辑,你的直觉是对的,但这里的"修改"对象不同:
1. 你的直觉(完全正确)
你是这样想的:
"如果数据从地址
1000H搬到了3000H,那程序里写的1000H确实就是旧地址了,如果不改,程序就会去读空的地方或者错误的数据。"
✅ 结论:是的,你说得对! 在直接寻址中,如果数据搬家了,而指令里的地址没改,程序一定会出错。
2. 这里的"不易修改"到底指什么?
这句话的重点不在于"会不会出错",而在于**"想要修正这个错误,有多麻烦"**。
❌ 情况 A:直接寻址(硬编码)
指令长这样:
assembly
LDA 1000H ; 指令里直接写死了地址 1000H- 现状 :数据搬到了
3000H。 - 问题 :指令里的
1000H是写死在代码里的(Hard-coded)。 - 如何修改 :
- 你必须找到源代码。
- 把
LDA 1000H这行代码删掉或改写。 - 重新编译/汇编整个程序。
- 重新加载到内存运行。
- 为什么叫"不易修改" :因为你要改动指令本身(即修改代码逻辑)。如果程序已经发布给用户了,你没法让用户自己去改代码里的数字。
✅ 情况 B:间接寻址(灵活指针)
指令长这样:
assembly
MOV R0, #1000H ; 第一步:把地址 1000H 放入寄存器 R0(这一步可以做成配置项)
LDA (R0) ; 第二步:去 R0 指向的地方取数据- 现状 :数据搬到了
3000H。 - 如何修改 :
- 不需要改指令
LDA (R0)! 这条指令永远不用动。 - 你只需要在程序运行时,让
R0的值变成3000H即可。 - 甚至可以让用户输入一个数字,程序自动把这个数字放进
R0。
- 不需要改指令
- 为什么叫"易修改" :因为指令本身不需要变 ,只需要改变寄存器里的值(数据)就能适应新的地址。
3. 一个生活中的比喻
想象你要去朋友家(数据)拿东西。
-
直接寻址(不易修改):
- 你的脑子里刻着一句话:"去幸福路1000号拿东西"。
- 朋友搬家了(搬到幸福路3000号)。
- 后果:你还是只会去1000号,扑个空。
- 怎么改:你必须**"洗脑"**(修改指令),把自己脑子里的那句话强行改成"去幸福路3000号"。这很难,相当于重写程序。
-
间接寻址(易修改):
- 你手里拿着一张纸条 (寄存器 R0),上面写着地址。你的原则是:"去纸条上写的地址拿东西"。
- 朋友搬家了。
- 怎么改 :你不需要改变你的原则 (指令
LDA (R0)不变)。你只需要拿出笔,把纸条上的数字从 1000 改成 3000 就行了。 - 甚至朋友可以打电话告诉你新地址,你直接改纸条,马上就能去新家。
总结
你之前的理解:
"否则程序还是会去读旧的 1000H,导致错误!"
完全正确! 这正是直接寻址的缺点。
而课本上说"不易修改",是指:
为了纠正这个错误,在直接寻址模式下,你必须去修改指令代码本身 (把 1000H 改成 3000H),这在软件工程和维护中是非常不灵活、成本高的操作。
相比之下,间接寻址只需要改一下数据(寄存器内容),指令代码一行都不用动,所以叫"易修改"。
为什么不直接修改原地址处的值?
这是一个非常棒的问题!你提出了一个很自然的想法:"既然数据搬家了,那我直接把新数据填回旧地址(1000H)不就行了吗?为什么要改地址去找新地方呢?"
答案是:在很多时候,你确实可以这样做(这叫"原地更新"),但在计算机系统的很多核心场景中,你"不能"或者"不想"这样做。
这就涉及到了**"数据"和"地址"**解耦的核心思想。以下是必须修改地址(从1000H改为3000H)而不是修改数据的几个关键原因:
1. 内存空间不够了(最常见的原因)
想象 1000H 这个房间原本是用来放一个小箱子的(比如一个整数,占2个字节)。
后来业务变了,你需要放一个大沙发(比如一个大数组或结构体,占100个字节)。
- 如果原地修改 :
1000H隔壁的房间(1002H, 1004H...)可能已经住了别的"数据住户"。如果你强行把大沙发塞进1000H开始的空间,就会覆盖掉隔壁邻居的数据,导致系统崩溃。 - 解决方案 :你必须去内存空闲的地方找一个能容纳大沙发的大房间(比如
3000H),把沙发放进去。 - 结果 :数据的位置变了(1000 -> 3000),原来的
1000H位置空出来了(或者放了别的东西)。这时候,程序必须 知道新地址是3000H才能找到沙发。
2. 多程序共享数据(指针的力量)
假设有两个程序 A 和 B,它们都要处理同一份数据。
- 程序 A 认为数据在
1000H。 - 程序 B 也认为数据在
1000H。
现在,操作系统为了优化内存,决定把这份数据搬到 3000H。
- 如果原地修改 :你没法"原地"修改,因为
1000H可能被分配给另一个完全不同的程序 C 使用了。你不能为了程序 A 和 B 去覆盖程序 C 的地盘。 - 解决方案 :数据必须搬到空闲的
3000H。然后,操作系统只需要告诉程序 A 和 B:"嘿,数据的新地址是3000H,你们更新一下手里的纸条(指针/寄存器)吧。" - 优势:数据可以在内存中任意移动(比如内存整理、碎片整理),只要所有持有"纸条"(指针)的程序更新一下地址即可,而不需要把数据搬来搬去填补空缺。
3. 动态数据结构(链表、树、堆)
这是计算机科学中最核心的概念。
想象你在写一个聊天软件,用户的消息是一条一条动态增加的。
- 第一条消息存在
1000H。 - 第二条消息来了,
1000H后面没地儿了,只能存在5000H。 - 第三条消息存在
2000H。
这些消息在内存里是散乱分布的。
- 程序通过一个"链表"把它们串起来:
1000H里面存着"下一条在 5000H",5000H里存着"下一条在 2000H"。 - 如果你想"原地修改",逻辑就全乱了。你必须接受数据分散在不同地址的事实。
- 这时候,程序里的变量(指针)存储的就是这些动态变化的地址。如果数据被重新分配了,指针里的地址值(1000H -> 3000H)必须随之改变。
4. 效率问题(写 vs 读)
- 修改数据:意味着你要把整个庞大的数据块(比如一张高清图片,几兆字节)从新位置复制回旧位置。这需要大量的时间(IO开销)。
- 修改地址 :只需要修改寄存器里的一个数字(比如从
1000H变3000H),这只需要 1个时钟周期,几乎瞬间完成。
结论:当数据很大时,移动数据本身(拷贝回原址)的代价太高了,不如直接改一下"指向它的地址"来得快。
总结对比
| 场景 | 策略:原地修改数据 (保持地址1000H不变) | 策略:修改地址 (1000H -> 3000H) |
|---|---|---|
| 数据变大 | ❌ 不可能 (会覆盖邻居数据) | ✅ 必须这样做 (找新地盘) |
| 内存碎片整理 | ❌ 极慢 (需要搬运大量数据填补空洞) | ✅ 极快 (只需更新指针) |
| 动态分配 | ❌ 无法实现 (数据本身就是散乱的) | ✅ 核心机制 (靠地址链接) |
| 适用情况 | 简单的变量更新 (如 score = 100 变 score = 90) |
复杂系统、大型数据、动态内存 |
回到你的课本
课本讲"直接寻址"的缺点时,隐含的背景是通用的、复杂的软件系统 。
在这种系统中,数据的位置往往是动态变化的(由操作系统或内存管理器决定)。
- 直接寻址 :把地址写死在指令里 (
LDA 1000H)。一旦数据被迫搬家(因为上述原因),你就不得不修改指令代码,这在运行时是不可能的(代码段通常是只读的)。 - 间接寻址 :地址存在寄存器或内存变量里 (
LDA (R0))。一旦数据搬家,只需要在运行时修改那个变量的值,程序就能自动适应,无需改动代码。
所以,"把1000H改成3000H"代表的是适应数据位置的动态变化,这是现代计算机灵活性的基石。
继续文章
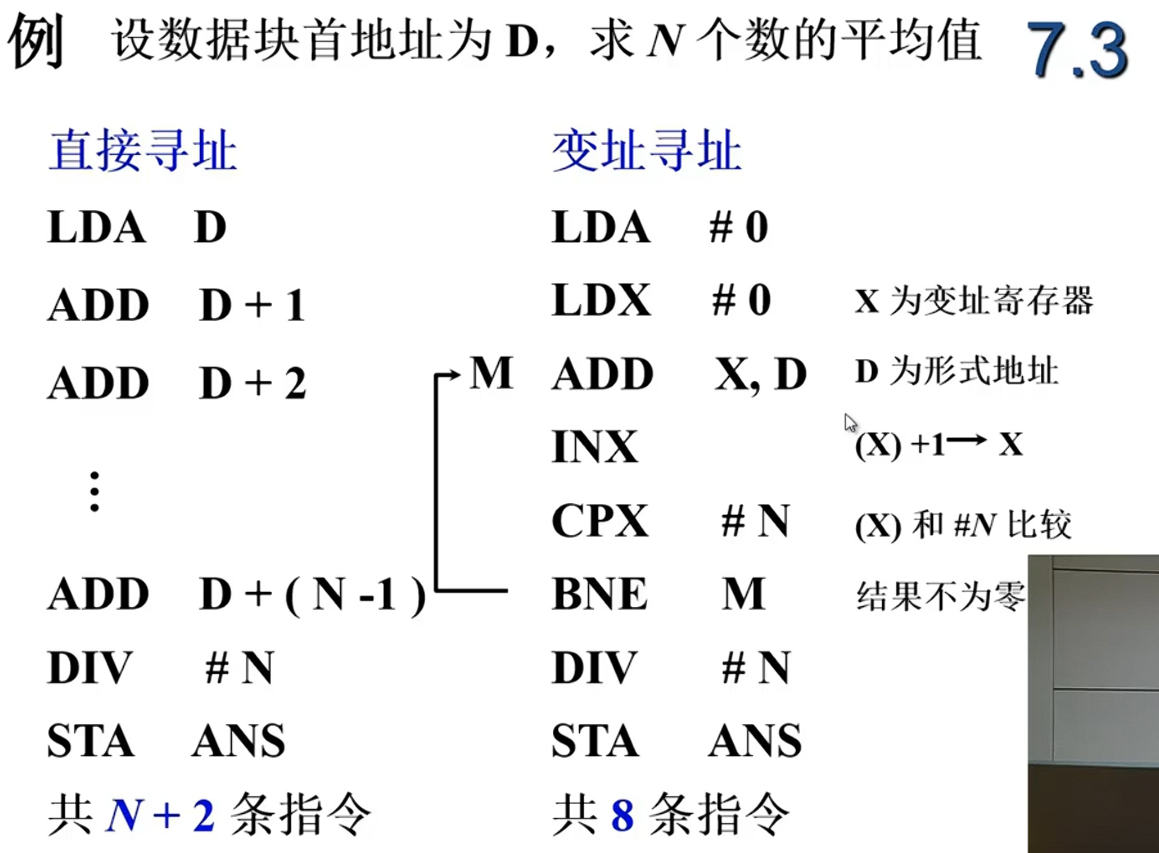
例题
如何使用变址寻址?
assembly
LDA #5 ; Load Accumulator with 5 (将5加载到累加器A)
STA ANS ; Store Accumulator to ANS (将A的值存入名为ANS的内存地址)
...
ANS: .byte 0 ; 定义一个名为 ANS 的字节变量,初始值为0