A. 跑酷设计
数学
今天,Alex想为Steve设计一个跑酷训练场。一个跑酷训练场是平面上整数坐标的序列 \(p_0→p_1→...→p_k\)。其中,相邻的一对坐标称为一次移动,记作 \(p_{i-1}→p_i\)。
Alex知道Steve只能执行以下类型的移动:
- \((x_i,y_i)→(x_i+2,y_i+1)\);
- \((x_i,y_i)→(x_i+3,y_i)\);
- \((x_i,y_i)→(x_i+4,y_i-1)\)。
注意Steve不会执行任何其他类型的移动。例如,Steve可以执行 \((0,0)→(2,1)\) 和 \((2,1)→(5,1)\),但绝不会执行诸如 \((2,1)→(3,2)\)、\((3,0)→(5,-1)\) 或 \((4,-1)→(6,-1)\) 的移动(即使它们看起来可能很简单)。
你被给定了平面上的一个整数坐标 \((x,y)\)。
请判断是否存在一个跑酷训练场 \(q_0,q_1,...,q_k\) 满足以下条件:
- \(q_0=(0,0)\);
- \(q_k=(x,y)\);
- 该跑酷训练场仅由Steve能够执行的移动构成。
思路
2.png]]
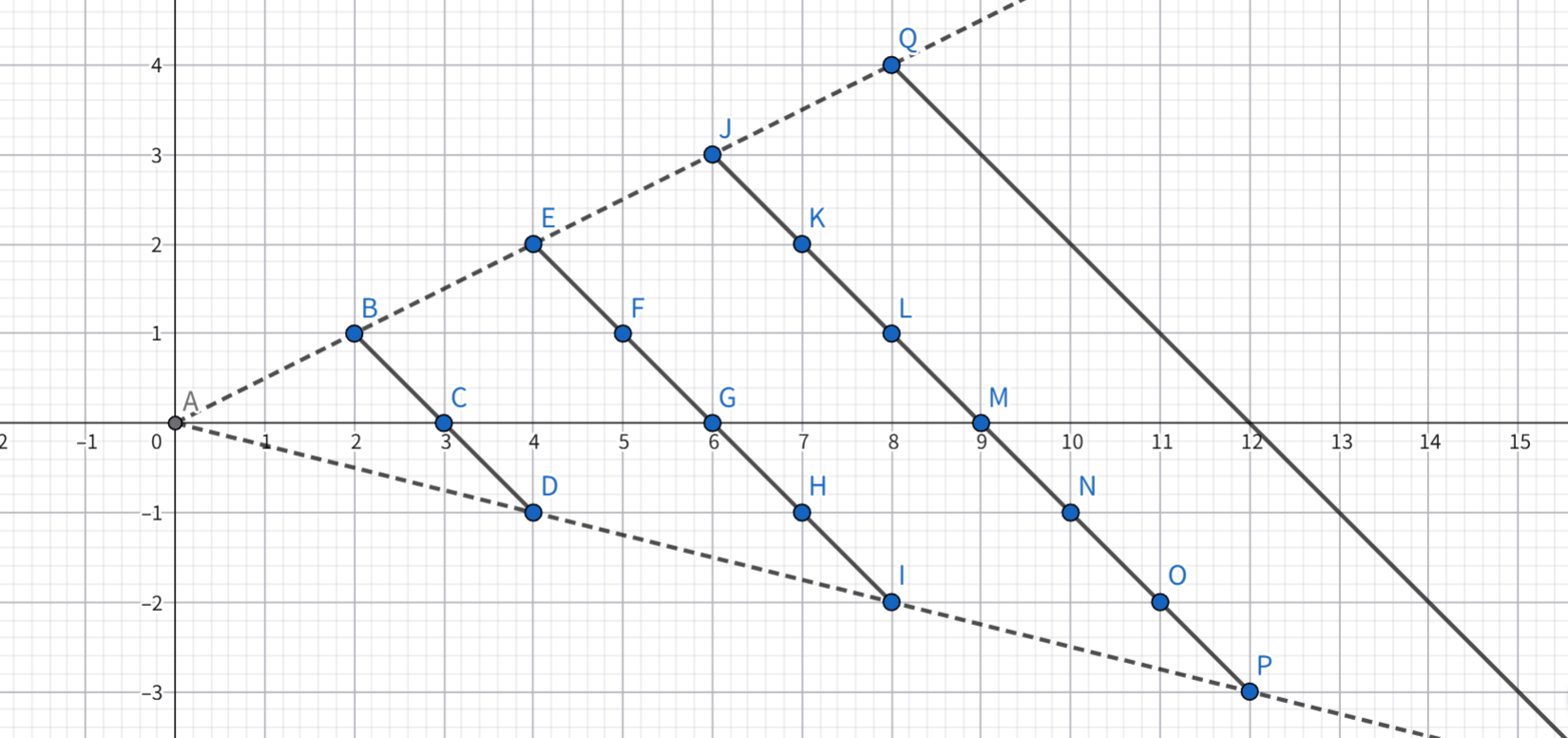
在草稿纸上画一下图,就可以发现非常明显的规律:
所有点都坐落在一些斜率为-1的平行线段上,这些线段所对应的直线可以表示为:
\y=-x+k\\ ,\\ k\\%3==0\\ ,\\ k\\in Z \\
为了将直线限制为线段,再对\(x\)加以限制:
\x\\in\[2k,4k \]
直接判断即可
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
void solve() {
int x, y;cin >> x >> y;
if ((x + y) % 3 != 0)cout << "NO\n";
else {
int k = (x + y) / 3;
if (x >= 2 * k && x <= 4 * k)cout << "YES\n";
else cout << "NO\n";
}
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}B. ABAB 构造
字符串 #dp #贪心
每个测试时间限制1秒
每个测试内存限制256 MB
有一个长度为 \(n\) 的字符串 \(T\),满足对于所有奇数 \(i\),\(T_i =\) 'a';对于所有偶数 \(i\),\(T_i =\) 'b'。
有一天,Bob 用以下算法生成了一个字符串 \(S\)。
初始化 \(S\) 为空字符串。
从 \(T\) 中移除第一个字母或最后一个字母,并将其附加到 \(S\) 的末尾。
如果 \(T\) 为空,则终止并返回字符串 \(S\)。否则,回到第二步。
然后,Bob 将生成的字符串 \(S\) 写在一张纸条上,并将其遗忘几年。当 Bob 找到这张纸条时,它已经磨损了,并且可能有人偷偷更改了一些字母。当然,Bob 想知道是否有人真的更改了这个字符串!
你被给定一个长度为 \(n\) 的字符串 \(X\),它由 'a'、'b' 和 '?' 组成。
请判断是否存在一个字符串 \(A\),满足以下条件:
\(|A|=n\);
对于所有 \(1 \le i \le n\),\(A_i\) 是 'a' 或 'b';
对于所有满足 \(X_i\) 不是 '?' 的 \(1 \le i \le n\),有 \(A_i = X_i\);
字符串 \(A\) 可以通过上述算法生成。
思路
本题在赛时把我给吓住了,想了特别久,最后拼尽全力写了个dp才过。。
本文先讲解一种我队友phaethon90想到很巧妙的贪心方法,再提供一种我个人的dp方法
法一:贪心
- 当 \(n\) 为偶数时,\(T = abab\dots ab\)。无论取左还是取右,取出的字符顺序必定是 \(a, b, a, b \dots\)。因此,如果 \(X\) 中存在相邻位置 \(X_i = X_{i+1}\)(且不是 '?'),直接
NO。 - 当 \(n\) 为奇数时,\(T = abab\dots a\)。首项和末项都是 'a'。
- 因此 \(S0\) 必须是 'a'。如果 \(S0 = 'b'\),直接
NO。 - 处理完 \(S0\) 后,剩下的 \(T\) 长度为偶数,回到了上述偶数的情况。
- 因此 \(S0\) 必须是 'a'。如果 \(S0 = 'b'\),直接
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
void solve() {
int n;cin >> n;
string s;cin >> s;
if ((n & 1) && s[0] == 'b')cout << "NO\n";
else {
for (int i = (n & 1);i < n - 1;i += 2) {
if (s[i] == s[i + 1] && s[i] != '?') {
cout << "NO\n";
return;
}
}
cout << "YES\n";
}
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}法二:状态压缩dp
我们将\(a\)视作0,\(b\)视作1,原串形如\(0101\dots 01\)或者\(0101\dots 010\)
注意到,每次操作结束后,原串将变化为\(0\dots 0,0 \dots 1, 1\dots 0, 1\dots 1\)四个状态的其中一种,因此我们用二进制数\(00,01,10,11\)来表示这四种状态,分别对应着\(0,1,2,3\)
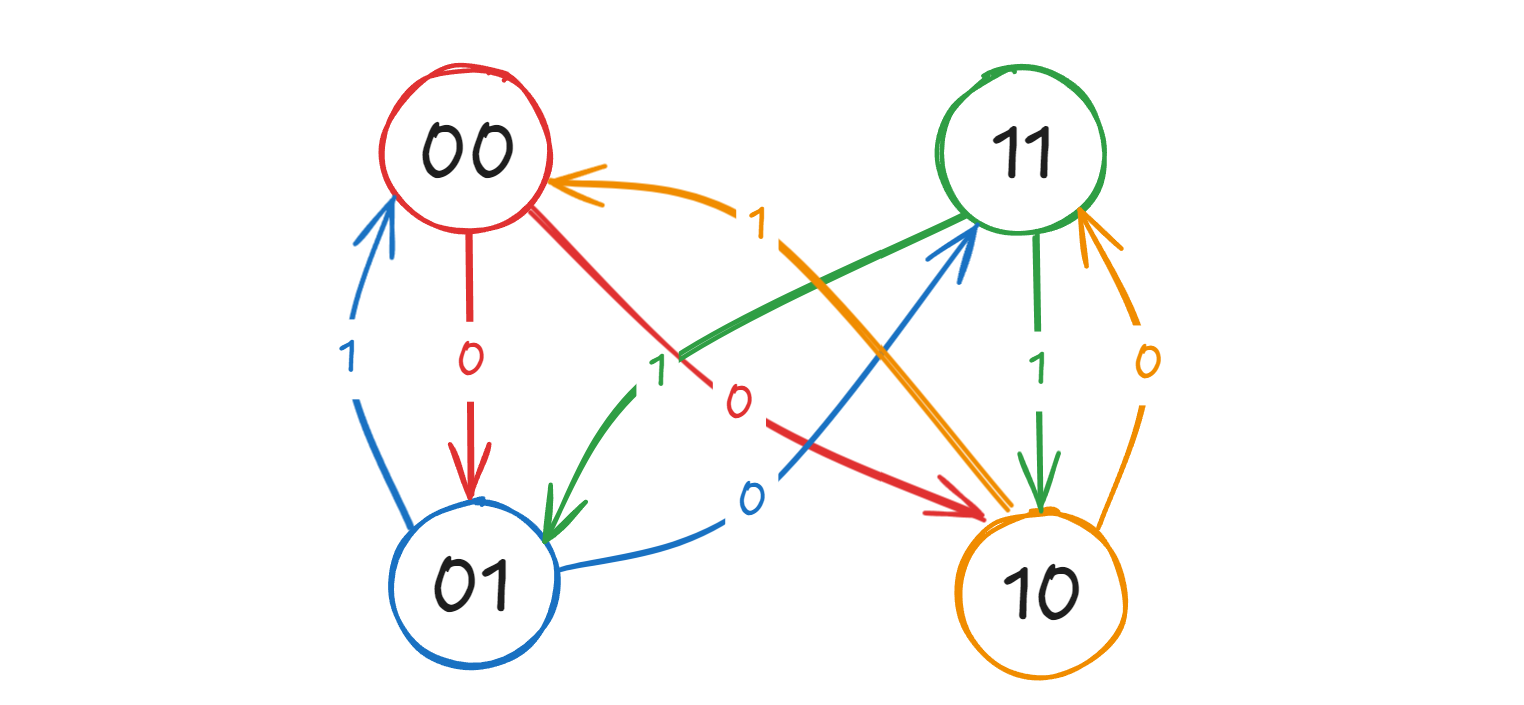
我们可以画出这样的转移状态图,其中:
\s\\xrightarrow{c}s\^{\*} \\
表示原串从状态\(s\)的头或者尾删去一个元素可以转移到状态\(s^{*}\)
状态设计:
\(bool\ \ dpimask\):是否可以利用原串生成目标串的\(1\sim i\),并且生成完后原串状态为\(mask\)
初始状态:
- 如果\(n\)是奇数,那么原串初始状态就为\(0\dots0\),即\(dp000=1\)
- 如果\(n\)是偶数,那么原串初始状态就为\(0\dots 1\),即\(dp00 1=1\)
我们对状态建边,接下来遍历目标串,目标串的当前字符就可以视作为\(c\),只走边权为\(c\)的路径即可实现dp的转移
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
bool e[4][2][4];
void solve() {
int n;cin >> n;
string s;cin >> s;
rep(i, 0, 3) {
rep(j, 0, 1) {
rep(k, 0, 3)e[i][j][k] = 0;
}
}
e[0][0][1] = e[0][0][2] = 1;
e[1][0][3] = 1;e[1][1][0] = 1;
e[2][0][3] = 1;e[2][1][0] = 1;
e[3][1][1] = e[3][1][2] = 1;
vector<bool>dp(4);
if (n & 1)dp[0] = 1;
else dp[1] = 1;
rep(pos, 0, n - 1) {
vector<bool>ndp(4);
rep(i, 0, 3) {
if (!dp[i])continue;
if (s[pos] == 'a') {
rep(nxt, 0, 3) {
if (e[i][0][nxt])ndp[nxt] = 1;
}
} else if (s[pos] == 'b') {
rep(nxt, 0, 3) {
if (e[i][1][nxt])ndp[nxt] = 1;
}
} else {
rep(nxt, 0, 3) {
if (e[i][0][nxt])ndp[nxt] = 1;
if (e[i][1][nxt])ndp[nxt] = 1;
}
}
}
dp = ndp;
}
rep(i, 0, 3) {
if (dp[i]) {
cout << "YES\n";
return;
}
}
cout << "NO\n";
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}C1. 失落的文明(简单版)
双指针
这是问题的简单版。两个版本之间的区别在于,在这个版本中,你只需为一个序列计算一个值。只有当你解决了这个问题的所有版本后,才能进行 hack。
我们定义一个生成包含 \(m+k\) 个整数的序列的算法如下:
首先,接收一个包含 \(m\) 个整数的序列 \(x\) 作为输入。如果 \(k=0\),立即终止并返回序列 \(x\)。
然后,选择任意索引 \(1 \leq i \leq |x|\),并在元素 \(x_i\) 之后立即插入 \((x_i+1)\)。
如果 \(x\) 中恰好包含 \(m+k\) 个整数,则终止并返回序列 \(x\)。否则,返回第二步。
爱丽丝知道,一个古代文明曾使用这个算法来安全地隐藏他们的秘密。爱丽丝想了解他们想要隐藏的知识,但从算法的输出推断输入并非易事。
给定一个包含 \(n\) 个整数的序列 \(a\),确定可以给定作为算法输入以生成 \(a\) 的最短序列的长度。
思路
经过观察,每个元素都有一个位于左侧、可以生成自己的最小元素,我们把这个元素叫做关键元素
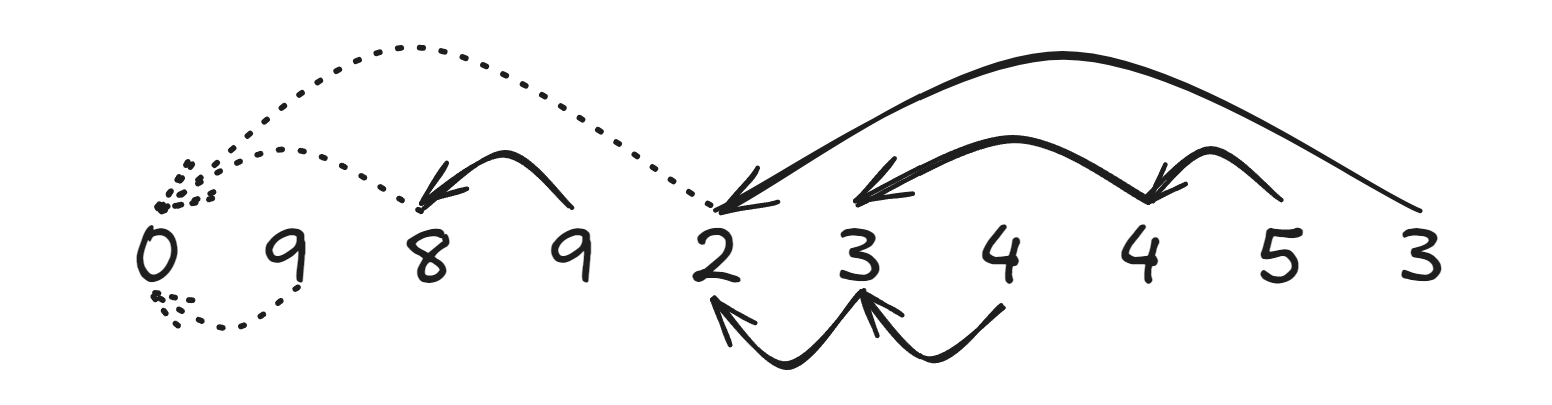
以样例为例子:
\\\begin{align} \\begin{array}{l} \&9\&\&8\&\&9\&\&2\&\&3\&\&4\&\&4\&\&5\&\&3 \\\\ \&9\&\\bigg\|\&8\&\&9\&\\bigg\|\&2\&\&3\&\&4\&\&4\&\&5\&\&3 \\end{array} \\end{align} \\
我们可以把序列拆分为三段,每段内的元素的关键元素就是这段的左端点,而左端点本身的关键元素不存在,可以记作0
我们从左到右遍历序列,将当前的关键元素记作\(last\)
如果发现\(ai>ai-1+1\)或者\(ai\leq last\),那么当前元素都不能由\(last\)生成,需要新开一个段
此时对关键元素为\(last\)的段进行结算,\(ans++\),更新\(last=ai\)即可
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
void solve() {
int n;cin >> n;
vector<int>a(n + 1);
a[0] = -5;
int last = -5, ans = 0;
rep(i, 1, n) {
cin >> a[i];
if (a[i] > a[i - 1] + 1 || a[i] <= last) {
ans++;
last = a[i];
continue;
}
}
cout << ans << '\n';
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}C2. 失落的文明 (困难版)
数学
这是该问题的困难版本。两个版本的区别在于,在这个版本中,你必须计算所有子段的值之和。只有当你解决了该问题的所有版本后,才能进行 hack。
让我们定义一种生成包含 \(m+k\) 个整数的序列的算法如下:
- 首先,接收一个包含 \(m\) 个整数的序列 \(x\) 作为输入。如果 \(k=0\),则立即终止并返回序列 \(x\)。
- 然后,选择任意索引 \(1 \le i \le |x|\),并在元素 \(x_i\) 之后立即插入 \((x_i + 1)\)。
- 如果 \(x\) 恰好包含 \(m+k\) 个整数,则终止并返回序列 \(x\)。否则,返回第二步。
Alice 知道这个算法被一个古老文明用来安全地隐藏他们的秘密。Alice 想要学习他们想要隐藏的知识,但从算法的输出推断输入并不是一件容易的事。
对于一个包含 \(n\) 个整数的序列 \(b\),我们定义 \(f(b)\) 为:能够通过该算法生成 \(b\) 的最短输入序列的长度。
给定一个包含 \(n\) 个整数的序列 \(a\),请计算以下各项之和的值:
\\\sum_{l=1}\^n \\sum_{r=l}\^n f(\[a_l, a_{l+1}, \\dots, a_r) \]
换句话说,你必须找到 \(a\) 的所有子段\(^*\) \(c\) 的 \(f(c)\) 之和。
思路
依旧以样例作为例子:
区别于上一题的关键元素,我们考虑能够生成这个元素的最近的元素,叫做最近关键元素,元素\(ai\)的最近关键元素记作\(Li\)
那么如何预处理\(Li\)呢?
可以使用\(set<pair<int,int>>\)来存储\(\{ 元素的值 ,元素下标 \}\),用于维护当前段内的元素信息
如果新增的元素是属于当前集合的,那么就可以\(lower\_bound\)找到最近的生成元素,满足\(apos<ai\)并且\(pos<i\)
如果新增元素已经不属于当前集合,那么就清空集合,开一个新的段
为了计算所有合法的区间,我们先倒序遍历右端点,在固定右端点的情况下枚举左端点
我们把所有情况计算的答案打表:
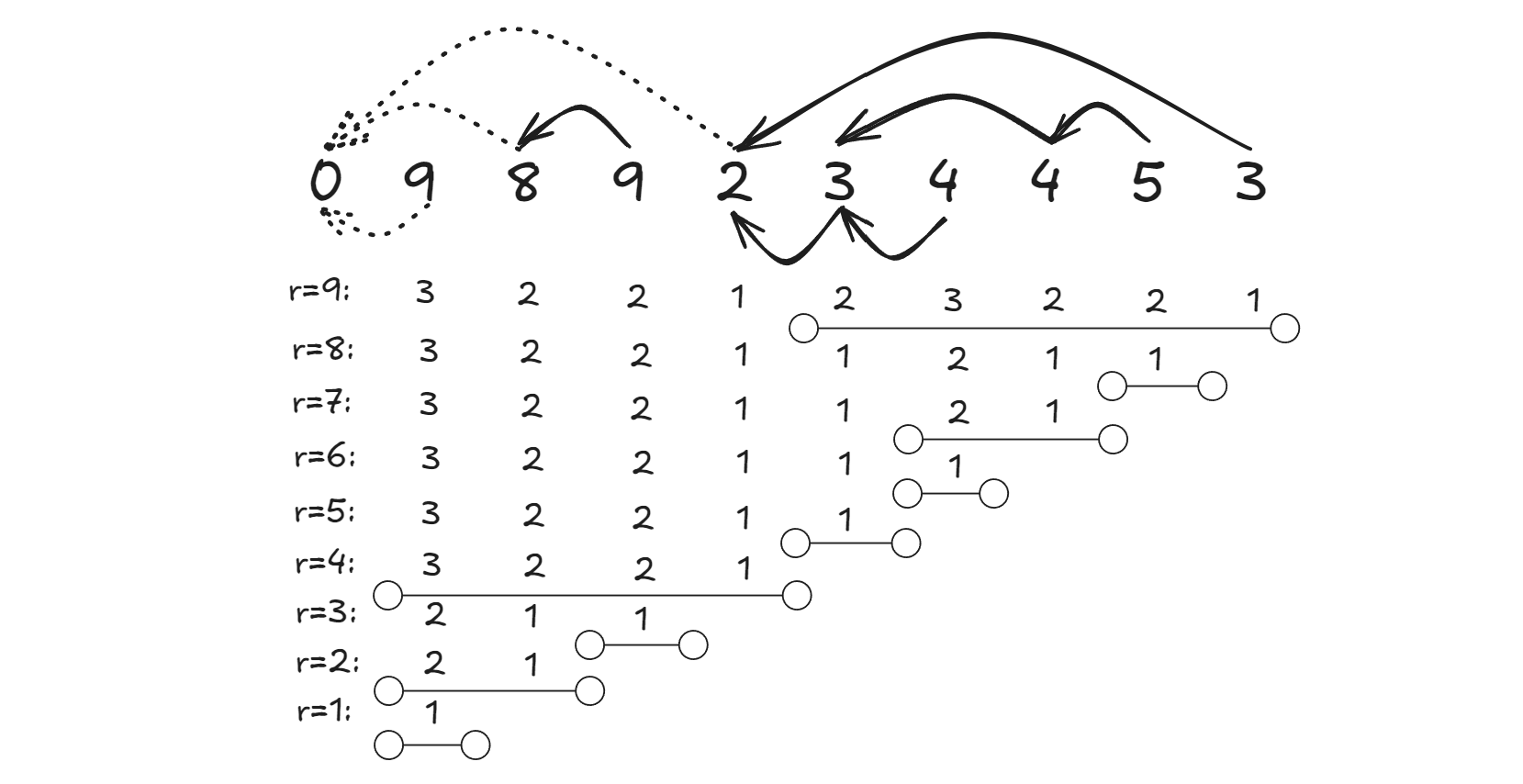
观察到:\(r\)在转移的时候,将会把\(Lr+1\sim r\)这一段区间的答案全部减一
因此,我们可以将每个元素的贡献视作一个个区间,采用分贡献的方式来计算答案
在\(r\)从\(n\)遍历到1的这\(n\)个时刻中,区间\(L\[i+1,i]\)的贡献将在\(1\leq r\leq i\)的时刻对答案有贡献,在\(i<r\leq n\)的时刻没有贡献
这就像把每个区间比喻成灯泡,一开始全都亮着,随着时间的推移依次慢慢关闭,那么总贡献实际上就是每个灯泡的单位时间贡献乘以亮着的时间,也就是区间长度乘以留存时间
\ans=\\sum_{i=1}\^{n}{(n-i+1)\\times (i-L\[i)} \]
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
void solve() {
int n;cin >> n;
vector<int>a(n + 1);
vector<int>l(n + 1);
a[0] = -5;
int last = -5, ans = 0;
set<pair<int, int>>s;//val,id
rep(i, 1, n) {
cin >> a[i];
if (a[i] > a[i - 1] + 1 || a[i] <= last) {
last = a[i];
s.clear();
l[i] = 0;
} else {
auto it = s.lower_bound({ a[i],0 });
it--;
l[i] = it->second;
}
s.insert({ a[i],i });
}
rep(i, 1, n) {
ans += (n - i + 1) * (i - l[i]);
}
cout << ans << '\n';
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}D. 记忆数字
数学 #构造
有 \(2n\) 张卡片,上面写着数字 \(1, 1, 2, 2, \dots, n, n\)。换句话说,对于所有 \(j=1, 2, \dots, n\),都恰好有 \(2\) 张写着数字 \(j\) 的卡片。每张卡片的正面只写有一个数字。
你将玩一个翻牌游戏。最初,所有 \(2n\) 张卡片都背面朝上(没有数字的一面)放置。在每一轮中,你恰好翻开两张卡片。如果这两张卡片的数字相同,你就丢弃这两张卡片;否则,你将它们翻回原来的位置。当所有 \(2n\) 张卡片都被丢弃时,你就赢了。请注意,你不需要同时翻开两张卡片,因此你可以在看到第一张卡片的数字后,再决定第二张卡片的选择。
考虑以下用于玩游戏的"贪心"算法。最初,\(2n\) 张卡片被随机排列成一排。然后你在每一轮的策略如下:
- 如果有两张你之前翻开过且数字相同的卡片,翻开这两张卡片。
- 否则,翻开目前为止第一张\(^*\)从未被翻开过的卡片。假设这张卡片上的数字是 \(x\)。
- 随后,如果还有另一张你之前翻开过且数字为 \(x\) 的卡片,翻开那张卡片。
- 否则,翻开目前为止(包括本轮)第一张\(^*\)从未被翻开过的卡片作为第二张。
可以证明,该算法的策略在每一轮都是唯一确定的。
你必须解决关于上述算法的以下问题:
给定 \(n\) 和 \(k\),请找到一种 \(2n\) 张卡片的排列方式,使得上述算法恰好需要 \(k\) 轮才能赢得游戏。
此外,如果不存在这样的排列方式,请报告。
思路
先考虑最少的轮数和最多的轮数
如果按照\(1,1,2,2,3,3,\dots ,n,n\)的方式进行排列,此时轮数最少,答案为\(n\)
如果按照\(2,1,3,2,4,3,\dots ,n,n-1,n,1\)排列,此时轮数最多,答案为\(n+n-1\)
为什么这样排轮数最多呢?
对于每个数字,选取与他相同的数字必定会消耗一轮,也就是消耗\(n\)轮,剩余的操作都是多余的操作,我们需要尽可能最大化多余的操作数
因此必定不能让玩家轻易地选到两个相同的
按照上述方法排列,每次必须要翻开两个新的卡才会发现一对相同的(1次多余操作),并且翻新卡的操作与选取相同的操作互不影响,则两两选会多出n-1次多余操作,这样能够使得多余操作最大化
因此可以先对\(k\)的范围进行判断,\(n\leq k\leq 2n-1\)
接下来需要想办法控制多余操作次数
观察到,如果记\(f(n)\)为最大化操作次数后长度为\(n\)的序列,那么\(f(n),f(n-1),f(n-2)\dots\)存在递推,他们的前缀是相同的
比如:
\\\begin{align} \&f(4)=\\{ 2,1,3,2,4,3,4,1 \\}\\\\ \\\\ \&f(5)=\\{ 2,1,3,2,4,3,5,4,5,1 \\}\\\\ \\\\ \&f(6)=\\{ 2,1,3,2,4,3,5,4,6,5,6,1 \\} \\end{align} \\
那么,如果想要在\(n=6\)的时候只多操作3次,那么其实等价于在\(f(4)\)的基础上最小化操作次数,因为\(f(4)\)的多余操作数为3:
\\\{ 2,1,3,2,4,3,4,1,5,5,6,6 \\} \\
因此我们可以通过改变序列前缀的方式来控制多余操作次数,后缀直接将两个相同元素放一起就行
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
void solve() {
int n, k;cin >> n >> k;
if (k < n || k>2 * n - 1) {
cout << "NO\n";return;
}
cout << "YES\n";
int cnt = k - n;
vector<int>ans(2*n + 1);
rep(i, 1, cnt) {
ans[2 * i] = i;
ans[2 * i - 1] = i + 1;
}
ans[2 * (cnt + 1)] = 1;
ans[2 * (cnt + 1) - 1] = cnt + 1;
rep(i, cnt + 2, n) {
ans[2 * i] = ans[2 * i - 1] = i;
}
rep(i, 1, 2 * n)cout << ans[i] << " ";cout << '\n';
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}ps:E、F都是我看官方题解补的题,思路与官方一致
E. 操纵的括号序列
字符串 #dp #计数DP
每个测试点的时限:2.0 秒
每个测试点的内存限制:256 MB
合法括号序列是指由 '(' 和 ')' 组成的序列,通过在序列中插入任意数量的 '1' 和 '+',可以将其转换为合法的数学表达式。例如,序列 "()(()())" 是合法括号序列,而 "())(()" 或 "(()" 则不是。
给定一个合法括号序列 \(S\)。
让我们考虑将一个子序列\(^*\)向右位移。形式上,当一个子序列 \(S_{i_1}S_{i_2} \dots S_{i_k}\) 向右位移时,所选下标处的字符将同时按以下方式重新赋值:
\S_{i_1} \\leftarrow S_{i_k} \\
\S_{i_2} \\leftarrow S_{i_1} \\
\S_{i_3} \\leftarrow S_{i_2} \\
\\\dots \\
\S_{i_k} \\leftarrow S_{i_{k-1}} \\
换句话说,第 \(j\) 个选定下标处的元素会被重新赋值为位移前第 \(((j-2) \bmod k + 1)\) 个选定下标处的字符。
例如,当 \(S\) 为 "()(()())" 时,位移子序列 \(S_2 S_4\) 会使 \(S\) 变为 "((())())"。另一方面,位移 \(S_2 S_3 S_5\) 会使 \(S\) 变为 "())((())"。
请计算有多少个非空子序列,使得 \(S\) 在向右位移后仍然是一个合法括号序列。由于答案可能很大,你只需要输出答案对 \(998244353\) 取模后的结果。
思路
对于一个括号串,如何判断它是否是合法的?
将\((\)视作\(+1\),\()\)视作\(-1\),如果该序列所有位置前缀和的值都\(\geq 0\),那么这就是一个合法的括号串
设\(prei\)为\(1\sim i\)的前缀和
假设我们选取了\(s_{k_{1}},s_{k_{2}},\dots s_{k_{t}}\)作为子串,并进行一次右移操作,发现:
- 在\(1\leq i<k_{1}\)时,\(prei\)的值不会发生改变,由于原串是合法串,所以\(1\sim k_{1}\)必定合法
- 在\(k_{t}<i\leq n\)时,\(prei\)的值不会发生改变,由于原串是合法串,所以\(k_{t}\sim n\)必定合法
所以我们讨论\(i=k_{j}\)的情况,对于\(prek_{j}\),在右移后他将变为\(prek_{j}-s_{k_{j}}+s_{k_{t}}\) - 如果\(s_{k_{t}}==+1\),那么变化量\(-s_{k_{j}}+s_{k_{t}}=1-s_{k_{j}}\geq 0\),对前缀和的合法性没有影响
- 如果\(s_{k_{t}}==-1\),那么变化量\(-s_{k_{j}}+s_{k_{t}}=-1-s_{k_{j}}\leq 0\)
- 如果\(s_{k_{j}}==-1\),那么变化量\(-s_{k_{j}}+s_{k_{t}}=-1+1= 0\),对前缀和的合法性没有影响
- 如果\(s_{k_{j}}==1\),那么变化量\(-s_{k_{j}}+s_{k_{t}}=-1-1= -2\),这就要求\(pres_{k_{j}}\geq 2\)
因此,如果\(s_{k_{t}}==+1\),那么前面的子序列怎么选都可以,那么每个\(j<i\)的位置就两种状态,选与不选,方案数为\(2^{i-1}\)
如果\(s_{k_{t}}==-1\),那么我们需要对\(s_{j}==+1\)的位置进行特殊考虑
状态设计:
\(dpi\)表示\(1\sim i\)中,多连接一个\(s_{k_{t}}=-1\)后仍然合法的子序列数量
状态转移:
\\\begin{align} \&设S_{i}满足:\\\\ \\\\ \&\\min_{j\\in S_{i}}\\{ pre\[j \}\geq 2\\ \\ &\forall j\in S_{i}\implies j<i\ ,\ s_{j}=+1 \end{align} \]
\dp\[i=1+\sum_{j\in S_{i}}dpj+\sum_{j<i\ ,\ s_{j}==-1}dpj \]
- 多加一个1代表子序列长度为1的时候也合法
- 所有\(s_{j}=-1\)的位置都必须有\(prej\geq 2\)
- \(s_{j}==+1\)的位置没有限制
为了快速得到\(j\in S_{i}\),设\(Li\)为\(i\)左侧距离\(i\)最近的\(prepos<2\)的位置\(pos\)
则\(\sum_{j\in S_{i}}dpj\)可以转化为\(\sum_{Li-1<j<i\ ,\ s_{j}==-1}dpj\)
为了快速得到\(s_{j}==+1\)与\(s_{j}==-1\)位置的dp值之和,设\(pre_{l}i=\sum_{s_{j}==+1\ ,\ j\leq i}dpj\),\(pre_{r}i=\sum_{s_{j}==-1\ ,\ j\leq i}dpj\)
则转移可以优化为:
\dp\[i=1+pre_{l}i-1-pre_{l}L\[i-1]+pre_{r}i-1 \]
最后我们可以在递推的时候算答案:
- 如果\(s_{i}==+1\),此时没有限制,\(ans+=2^{i-1}\)
- 如果\(s_{i}==-1\),此时使用dp值,\(ans+=dpi\)
注意dp中有减法,取模要先加模
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
const int mod = 998244353;
int n;
constexpr int qpow(int a, int b) {
int ans = 1;a %= mod;
while (b) {
if (b & 1) { ans *= a; ans %= mod; }
a *= a;a %= mod;b >>= 1;
}
return ans % mod;
}
void solve() {
cin >> n;
string s;cin >> s;
vector<int>prel(n + 1);
vector<int>prer(n + 1);
vector<int>dp(n + 1);
vector<int>pre(n + 1);
vector<int>L(n + 1);
rep(i, 1, n) {
int add = 0;
if (s[i - 1] == '(')add = 1;
else add = -1;
pre[i] = add;
if (i - 1 >= 1) {
pre[i] += pre[i - 1];
L[i] = L[i - 1];
}
if (pre[i] < 2)L[i] = i;
}
int ans = 0;
rep(i, 1, n) {
dp[i] = 1 + prel[i - 1] - prel[L[i - 1]] + prer[i - 1] + mod;
dp[i] %= mod;
if (s[i - 1] == '(')prel[i] = dp[i];
else prer[i] = dp[i];
if (i - 1 >= 1) {
prel[i] += prel[i - 1];
prer[i] += prer[i - 1];
prel[i] %= mod;
prer[i] %= mod;
}
if (s[i - 1] == '(') {
ans += qpow(2, i - 1);
ans %= mod;
} else {
ans += dp[i];
ans %= mod;
}
}
cout << ans << '\n';
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}F. 非二分查找与查询
STL #数学
对于一个由 \(m\) 个整数组成的序列 \(b\),集合 \(S(b)\) 被定义为满足以下条件的元组 \((i, j, k)\) 的集合:
- \(i, j, k\) 是整数;
- \(1 \le k < m\);
- \(1 \le i < j \le m - k + 1\);
- 对于 \(b\) 中的每一个元素 \(v\),\(v\) 在 \(b_i, b_{i+1}, \\dots, b_{i+k-1}\) 和 \(b_j, b_{j+1}, \\dots, b_{j+k-1}\) 中出现的次数相同。
例如,当 \(b = 1, 2, 1, 2\) 时,元组 \((1, 3, 2)\) 是 \(S(b)\) 的一个元素,因为 \(1\) 和 \(2\) 在 \(b_1, b_2\) 和 \(b_3, b_4\) 中都恰好各出现了一次。
此外,我们在正整数序列上定义了两个函数:
- \(k_{max}(b)\) 定义为 \(S(b)\) 中所有元素 \((i, j, k)\) 的 \(k\) 的最大值;
- \(f(b)\) 定义为 \(S(b)\) 中满足 \(k = k_{max}(b)\) 的不同元素 \((i, j, k)\) 的数量。
特别地,当集合 \(S(b)\) 为空时,定义 \(k_{max}(b) = 0\) 且 \(f(b) = 0\)。
给你一个包含 \(n\) 个整数的序列 \(a\)。请回答 \(q\) 个如下类型的查询:
- \(i \ x\):将 \(a_i\) 的值修改为 \(x\)。然后,求出 \(k_{max}(a)\) 和 \(f(a)\) 的值。
请注意,更新是持久的。换句话说,一个查询中的修改会影响后续的所有查询。
思路
本题的破题点非常巧妙:\(k_{max}\)必定为序列中相同元素下标之差的最大值
比如样例1的时刻2:
\\\begin{align} \\begin{array} {l} \&1\&2\&2\&1\&5 \\end{array} \\end{align} \\
两个元素1的下标之差为3,\(k_{max}=3\),为什么呢?
形如\(x_{p},a,b, \dots ,z,x_{q}\)的部分,必定可以选取区间\(p,q-1\)与\(p+1,q\)这两个区间,出现的元素数量必定一致。因此,找到相同元素相隔最远的距离即为\(k_{max}\)
在确定\(k_{max}(a)\)后如何求\(f(a)\)呢?
继续以样例1为例,取时刻3:
\\\begin{align} \\begin{array} {l} \&1\&2\&2\&1\&2 \\end{array} \\end{align} \\
显然\(k_{max}=3\),无论是1还是2,下标差值最大都为3
因此,我们现在区间的长度已经固定为3,找出合法的区间起点对\(i,j\)即可
记\(firstx\)为元素\(x\)第一次出现的位置,\(first1=1,first2=2\)
此时,\(i,j\)可以在\(1,3\)中任选,答案为\(C_{3}^{2}=3\)
为什么是\(1,3\)?
我们知道,形如\(x_{p},a,b, \dots ,z,x_{q}\)的部分,必定可以选取区间\(p,q-1\)与\(p+1,q\)这两个区间,而我们已经确定了区间长度,只需要确定区间起点即可确定一个区间,所以对于元素\(x\)而言,区间起点在\(p,p+1\)中选择即可
那么形如\(x_{p},y_{p+1},\dots\)的部分呢?(假设元素\(x,y\)的最大差值都为\(k_{max}\))
- 对\(x\)而言,可以在\(p,p+1\)选择
- 对\(y\)而言,可以在\(p+1,p+2\)选择
- 两个区间可以合并为\(p,p+2\)
因此,只要在\(p,p+2\)中任选两个作为区间起点,这两个区间必定合法
记\(lenx\)为元素\(x\)的下标最大差值
因此,假如\(\forall x\in S\to lenx=k_{max}\),当\(a_{i},a_{i+1},\dots,a_{i+t}\in S\)时,区间合并后为\(p,p+t+1\),对答案的贡献为\(C_{t+1}^{2}\)
因此,我们只需要关注所有\(lenx==k_{max}\)的元素的\(firstx\),以及他们是否连续,将连续的段进行区间合并,每个区间由一个个连续的\(firsti\)组成,计算每个区间对答案的贡献即可
本题的另一大难点就在于,如何动态地维护这些连续的区间
我们使用\(set<pair<int,int>>lrN\)来存储区间,其中\(lri\)存放\(len=i\)的区间
每次将位置\(i\)的值修改为\(x\)的时候,需要先将原先的信息\(original\_len,original\_val\)所对应的区间信息进行修改
修改完后再将新的信息\(len,val\)更新进对应的区间信息中
\(ansk\)表示\(lr k\)中所有区间的贡献
- 函数\(del(k,x)\)用于将\(lr k\)中包含\(x\)的区间\(L,R\)分裂为\(L,x-1,x+1,R\),并且需要考虑无法分裂的种种情况
- 函数\(add(k,x)\)用于在\(lr k\)中将\(L,x-1,x+1,R\)合并为\(L,R\),并且需要考虑无法合并的种种情况
- 在\(del\)与\(add\)的过程中,动态更新\(ansk\)
此外,创建一个\(multiset<int>len\)用于维护当前的最大下标差值,用于确定\(k_{max}\)
最后输出\(k_{max},ansk_{max}\)即可
写代码的时候需要多注意集合的判空,否则非常容易越界!
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
const int N = 2e5 + 5, Q = 1e5 + 5;
int a[N], n, q, ans[N];
set<pair<int, int>>lr[N];
constexpr int C(int x) {
return x * (x - 1) / 2;
}
void add(int k, int x) {
if (k <= 0)return;
int L = x, R = x;
auto& s = lr[k];
auto it = s.lower_bound({ x,0 });
if (it != s.end() && it->first == x + 1) {
auto [l, r] = *it;
R = r;
ans[k] -= C(r - l + 2);
s.erase(it);
}
it = s.lower_bound({ x,0 });
if (it != s.begin() && (--it)->second == x - 1) {
auto [l, r] = *it;
L = l;
ans[k] -= C(r - l + 2);
s.erase(it);
}
s.insert({ L,R });
ans[k] += C(R - L + 2);
}
void del(int k, int x) {
if (k <= 0)return;
auto& s = lr[k];
auto it = s.lower_bound({ x + 1,0 });
if (it != s.begin()) {
it--;
auto [L, R] = *it;
if (L > x || R < x)return;
s.erase(it);
ans[k] -= C(R - L + 2);
if (x - 1 >= L) {
s.insert({ L,x - 1 });
ans[k] += C(x - 1 - L + 2);
}
if (x + 1 <= R) {
s.insert({ x + 1,R });
ans[k] += C(R - (x + 1) + 2);
}
}
}
void solve() {
cin >> n >> q;
vector<set<int>>pos(n + 1);
rep(i, 1, n) {
cin >> a[i];
pos[a[i]].insert(i);
lr[i].clear();
ans[i] = 0;
}
lr[0].clear();ans[0] = 0;
multiset<int>len;
rep(i, 1, n) {
if (pos[i].size()) {
int k = *pos[i].rbegin() - *pos[i].begin();
len.insert(k);
add(k, *pos[i].begin());
}
}
// cout << "HERE" << endl;
rep(i, 1, q) {
int x, val;cin >> x >> val;
if (!len.size()) {
cout << "0 0\n";continue;
}
int orilen = *pos[a[x]].rbegin() - *pos[a[x]].begin();
len.erase(len.find(orilen));
del(orilen, *pos[a[x]].begin());
pos[a[x]].erase(x);
if (pos[a[x]].size()) {
int nowlen = *pos[a[x]].rbegin() - *pos[a[x]].begin();
len.insert(nowlen);
add(nowlen, *pos[a[x]].begin());
}
a[x] = val;
if (pos[a[x]].size()) {
orilen = *pos[a[x]].rbegin() - *pos[a[x]].begin();
len.erase(len.find(orilen));
del(orilen, *pos[a[x]].begin());
}
pos[a[x]].insert(x);
int nowlen = *pos[a[x]].rbegin() - *pos[a[x]].begin();
len.insert(nowlen);
add(nowlen, *pos[a[x]].begin());
int ma = *len.rbegin();
if (!ma)cout << "0 0\n";
else cout << ma << " " << ans[ma] << '\n';
}
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}G1. 单调黑白矩阵 (简单版)
bitset #数学 #STL
这是该问题的简单版本。两个版本的区别在于,在这个版本中,\(n\) 和 \(q\) 的限制较小。只有当且仅当你解决了该问题的所有版本后,才能进行 hack。
一个大小为 \(n \times n\) 的黑白矩阵是指一个具有 \(n\) 行和 \(n\) 列的矩阵,其中每个单元格都被涂成了黑色或白色。令黑白矩阵 \(C\) 中单元格 \((r, c)\) 的颜色表示为 \(Cr, c\)。
如果一个矩阵 \(C\) 满足以下条件,我们就称其为单调的:
不存在两行 \(1 \le i < j \le n\) 和两列 \(1 \le k < l \le n\) 满足以下三个条件:
- \(Ci, k = Cj, l\);
- \(Cj, k = Ci, l\);
- \(Ci, k \neq Cj, k\)。
现有一个大小为 \(n \times n\) 的黑白矩阵 \(M\),最初所有单元格均为白色。请处理 \(q\) 个如下类型的查询:
- \(r \ c\):将矩阵 \(M\) 中单元格 \((r, c)\) 的颜色修改为黑色。然后,判断 \(M\) 是否为单调矩阵。
对于每个查询,保证单元格 \((r, c)\) 在查询前的颜色为白色。
请注意,更新是持久的。换句话说,一个查询中的颜色修改会影响后续的所有查询。
思路
我们将白色视作\(0\),黑色视作\(1\),那么整个矩阵就可以变为\(n\)行二进制数
如果存在矩阵不单调的情况,那么必然出现下面的两种情况之一:
\\\begin{align} \\begin{array} {l}\&1\&\\dots\&0 \\\\ \&0\&\\dots\&1 \\end{array}\\quad \\begin{array} {l}\&0\&\\dots\&1 \\\\ \&1\&\\dots\&0 \\end{array}\\end{align} \\
如果矩阵单调,那么任取四个数字必然是下面的情况:
\\\begin{align} \\begin{array} {m}\&0\&\\dots\&0 \\\\ \&1\&\\dots\&1 \\end{array}\\quad \\begin{array} {m}\&1\&\\dots\&0 \\\\ \&1\&\\dots\&1 \\end{array}\\quad\\begin{array} {m}\&0\&\\dots\&1 \\\\ \&1\&\\dots\&1 \\end{array}\\quad \\begin{array} {m}\&1\&\\dots\&1 \\\\ \&1\&\\dots\&1 \\end{array} \\end{align} \\
或者是两行位置互换,共8种可能
结论 :矩阵单调 \(\iff\) 任意两行 \(a, b\) 满足包含关系(\(a \subseteq b\) 或 \(b \subseteq a\))。
用位运算表示:\((a \ \& \sim b) == 0\) 或 \((\sim a \ \& \ b) == 0\)。
我们记\(pd(a,b)=(a\&\sim b\neq0||\sim a\&b\neq0)\)
因此,只要存在两行\(a,b\)使得\(pd(a,b)=1\),那么必然不单调
为了快速判断是否存在这样的\(a,b\),我们将上述\(pd\)的这种双向关系改为单向的偏序关系,\(pd(a,b)=(a\&\sim b\neq 0)\),如果\(pd(a,b)\),则\(a\preceq b\)
为了快速判断,我们将行按黑格子个数 cnt 排序,在单调矩阵中,排序后的行必须构成一个"包含链":\(S_{p_1} \subseteq S_{p_2} \subseteq \dots \subseteq S_{p_n}\)
也就是说,假设现在有一个新的行状态\(x\),排序后位于\(\{ \dots,p,x,q, \dots \}\)的位置,而\(p\preceq q\),因此只要\(p\preceq x\)并且\(x\preceq q\),那么就不会破坏单调性
因此,我们可以开一个\(set\)来模拟这个过程,用一个\(tot\)记录当前有多少个不合法的偏序对,如果修改成功后\(tot==0\),那么就是\(YES\),否则就是\(NO\)
为了优化时间复杂度,采用\(bitset\)来存储二进制数,复杂度为\(O\left( Q\cdot \frac{N}{64} \cdot \log N\right)\)
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
const int N = 25005;
int n, q;
bitset<N>bs[N];
int cnt[N];
bool pd(int a, int b) {
if (!a || !b)return 0;
return (bs[a] & ~bs[b]).any();
}
void solve() {
cin >> n >> q;
set<pair<int, int>>s;//cnt,id
rep(i, 1, n)s.insert({ 0,i }), bs[i] = 0, cnt[i] = 0;
int tot = 0;
rep(i, 1, q) {
int r, c;cin >> r >> c;
auto it = s.lower_bound({ cnt[r],r });
int pre = 0, nxt = 0;
if (it != s.begin())pre = prev(it)->second;
if (next(it) != s.end())nxt = next(it)->second;
if (pre && pd(pre, r))tot--;
if (nxt && pd(r, nxt))tot--;
if (pre && nxt && pd(pre, nxt))tot++;
s.erase(it);
bs[r][c] = 1;
cnt[r]++;
s.insert({ cnt[r],r });
it = s.lower_bound({ cnt[r],r });
pre = 0, nxt = 0;
if (it != s.begin())pre = prev(it)->second;
if (next(it) != s.end())nxt = next(it)->second;
if (pre && pd(pre, r))tot++;
if (nxt && pd(r, nxt))tot++;
if (pre && nxt && pd(pre, nxt))tot--;
if (!tot)cout << "YES\n";
else cout << "NO\n";
}
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}G2. 单调黑白矩阵 (困难版)
数学
这是该问题的困难版本。两个版本的区别在于,在这个版本中,\(n\) 和 \(q\) 的限制非常大。只有当你解决了该问题的所有版本后,才能进行 hack。
一个大小为 \(n \times n\) 的黑白矩阵是指一个具有 \(n\) 行和 \(n\) 列的矩阵,其中每个单元格都被涂成了黑色或白色。令黑白矩阵 \(C\) 中单元格 \((r, c)\) 的颜色表示为 \(Cr, c\)。
如果一个矩阵 \(C\) 满足以下条件,我们就称其为单调的:
不存在两行 \(1 \le i < j \le n\) 和两列 \(1 \le k < l \le n\) 满足以下三个条件:
- \(Ci, k = Cj, l\);
- \(Cj, k = Ci, l\);
- \(Ci, k \neq Cj, k\)。
现有一个大小为 \(n \times n\) 的黑白矩阵 \(M\),最初所有单元格均为白色。请处理 \(q\) 个如下类型的查询:
- \(r \ c\):将矩阵 \(M\) 中单元格 \((r, c)\) 的颜色修改为黑色。然后,判断 \(M\) 是否为单调矩阵。
对于每个查询,保证单元格 \((r, c)\) 在查询前的颜色为白色。
请注意,更新是持久的。换句话说,一个查询中的颜色修改会影响后续的所有查询。
思路
本题思路是询问\(Gemini\)得来,其中有许多组合数学的专业知识
在 Hard 版本中,\(N, Q\) 达到了 \(2 \cdot 10^6\),简单版的 Bitset \(O(QN/64)\) 已经彻底跑不动了,我们需要一个 \(O(N+Q)\) 的"降维打击"做法。
破题点:利用平方和作为"指纹"判定单调性
这里涉及到一个组合数学的硬核结论:Gale-Ryser 定理。
- 理论值:共轭分拆 (Conjugate Partition)
设行黑格数序列为 \(R\)。我们定义一个理论上的列分布 \(R^*\):\(R^*_k\) 表示"黑格子数量 \(\ge k\) 的行数"。- 定理推论:矩阵单调 \(\iff\) 实际的列黑格数序列 \(C\) 是理论序列 \(R^*\) 的一个排列。
- 指纹识别:主控性与平方和
在数学上,列分布 \(C\) 的"集中度"永远不会超过 \(R^*\)。- 只要列分布的平方和 \(\sum C_i^2\) 达到了理论上限 \(\sum (R^*_i)^2\),那么 \(C\) 就一定是 \(R^*\) 的一个排列,矩阵也就一定是单调的。
具体维护:
我们只需要实时维护两个"指纹":
sumC:实际每一列黑格数的平方和 \(\sum (cntC_j)^2\)。sumR:理论共轭序列的平方和 \(\sum (R^*_k)^2\)。
利用平方差公式 \((x+1)^2 - x^2 = 2x+1\),我们可以在 \(O(1)\) 时间更新:
- 涂黑 \((r, c)\) 时:
sumC增加 \(2 \times cntCc + 1\)。sumR增加 \(2 \times sufRcntR\[r + 1] + 1\)。(其中 \(sufRk\) 即 \(R^*_k\),表示当前黑格数 \(\ge k\) 的行数)。
只要 sumC == sumR,答案就是 YES。
代码
cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
#define rep(i,a,b) for(int i=(a);i<=(b);i++)
#define per(i,a,b) for(int i=(a);i>=(b);i--)
const int N = 2e6 + 5;
int n, q, cntC[N], cntR[N], sufR[N];
int sumC, sumR;
void solve() {
cin >> n >> q;
rep(i, 1, n)cntC[i] = cntR[i] = sufR[i] = 0;
sumC = sumR = 0;
int tot = 0;
rep(i, 1, q) {
int r, c;cin >> r >> c;
sumC += 2 * cntC[c] + 1;
cntC[c]++;
sumR += 2 * sufR[cntR[r] + 1] + 1;
sufR[cntR[r] + 1]++;
cntR[r]++;
if (sumC == sumR)cout << "YES\n";
else cout << "NO\n";
}
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
int t = 1;
cin >> t;
while (t--)solve();
}