GitNexus 核心引擎深度解析
索引流水线、社区检测与流程追踪、混合搜索与嵌入生成
一、入口类与架构关系
GitNexus 的核心引擎由三个相互协作的子系统构成:索引流水线(Ingestion Pipeline) 、社区与流程检测(Community & Process Detection) 、混合搜索与嵌入(Hybrid Search & Embeddings)。这三个子系统共同将原始代码库转换为可查询的知识图谱。
1.1 核心类关系图

1.2 关键数据结构
KnowledgeGraph :知识图谱的核心数据结构,包含节点(Node)和关系(Relationship)集合。节点类型包括 File、Folder、Function、Class、Method、Interface、Community、Process;关系类型包括 CALLS、IMPORTS、EXTENDS、IMPLEMENTS、MEMBER_OF、STEP_IN_PROCESS。
SymbolTable :符号表,用于快速查找符号定义。键为 filePath:name,值为 {nodeId, type}。
ASTCache:AST 缓存,避免重复解析。使用 LRU 策略,默认缓存所有文件。
二、关键流程描述
2.1 索引流水线完整流程
索引流水线是 GitNexus 的核心,将代码库转换为知识图谱。整个流程分为 9 个阶段,每个阶段都有明确的职责和进度反馈。
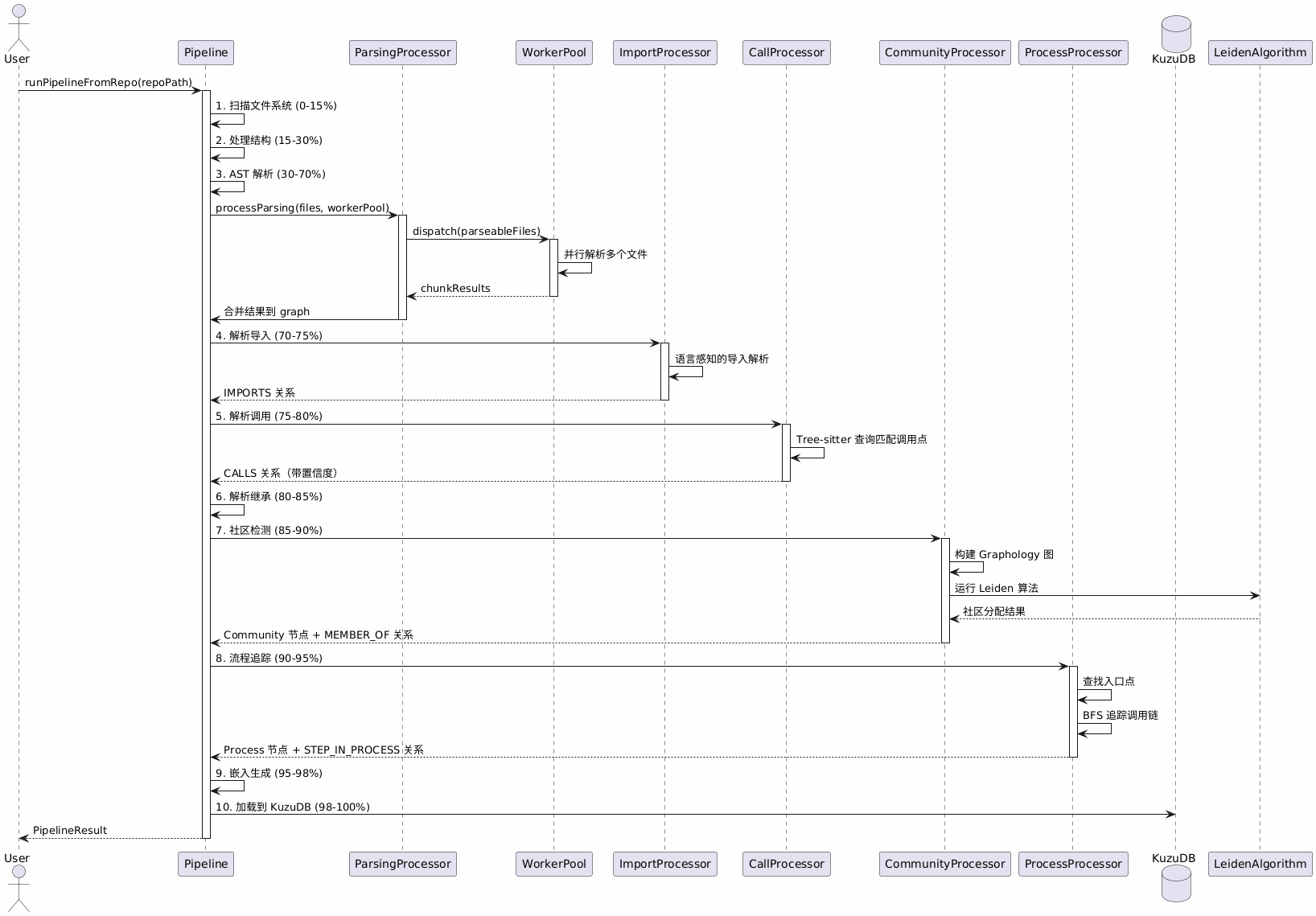
关键阶段说明:
-
文件扫描(0-15%) :
walkRepository遍历文件系统,收集所有可解析文件,建立 File/Folder 节点。 -
AST 解析(30-70%):使用 Tree-sitter 并行解析,提取符号定义。支持 Worker 池并行处理,失败时自动降级为顺序处理。
-
导入解析(70-75%):语言感知的导入路径解析。TypeScript/JavaScript 支持相对路径和 node_modules;Go 支持包路径解析;Python 支持相对导入和 sys.path。
-
调用解析(75-80%):通过 Tree-sitter 查询匹配函数调用点,建立 CALLS 关系。置信度计算基于:
- 精确匹配(名称 + 参数数量):90%+
- 模糊匹配(仅名称):50-70%
- 全局匹配(未解析的标识符):30%
-
社区检测(85-90%):使用 Leiden 算法基于 CALLS 边进行功能聚类。构建无向 Graphology 图,运行 Leiden 算法(resolution=1.0),生成社区节点和成员关系。
-
流程追踪(90-95%):从入口点(调用他人但很少被调用的函数)追踪执行流程。使用 BFS 算法,限制深度(maxDepth=10)和分支(maxBranching=4),去重后生成 Process 节点。
2.2 社区检测算法流程
社区检测使用 Leiden 算法,这是一种改进的 Louvain 算法,能够检测更高质量的社区结构。
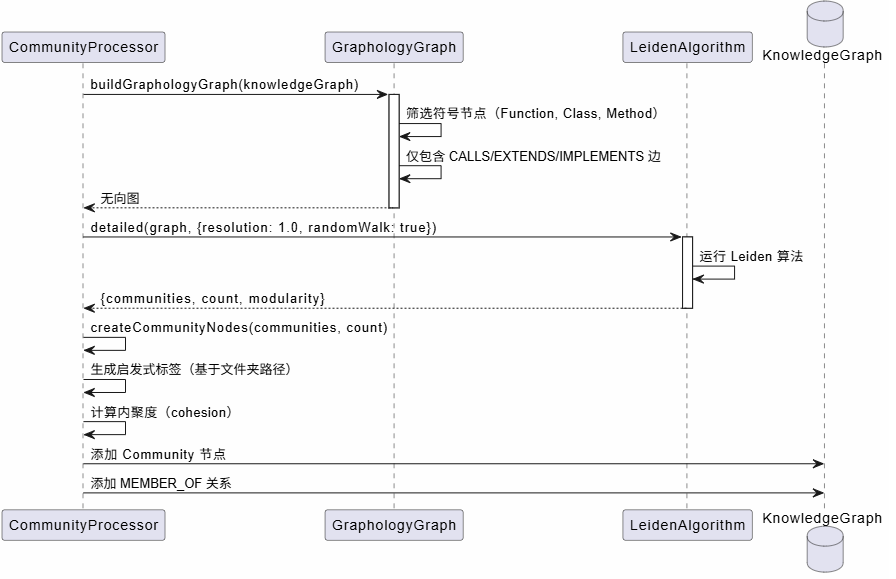
算法关键点:
- 图构建:仅包含符号节点(Function, Class, Method, Interface)和 CALLS/EXTENDS/IMPLEMENTS 边,忽略 File/Folder 节点。
- 分辨率参数 :
resolution=1.0是默认值,控制社区大小。值越大,社区越小、越细粒度。 - 内聚度计算:采样社区成员(最多 50 个),计算内部边密度。内聚度 = 内部边数 / 总边数。
2.3 流程追踪算法流程
流程追踪从入口点开始,使用 BFS 算法追踪调用链,生成执行流程。
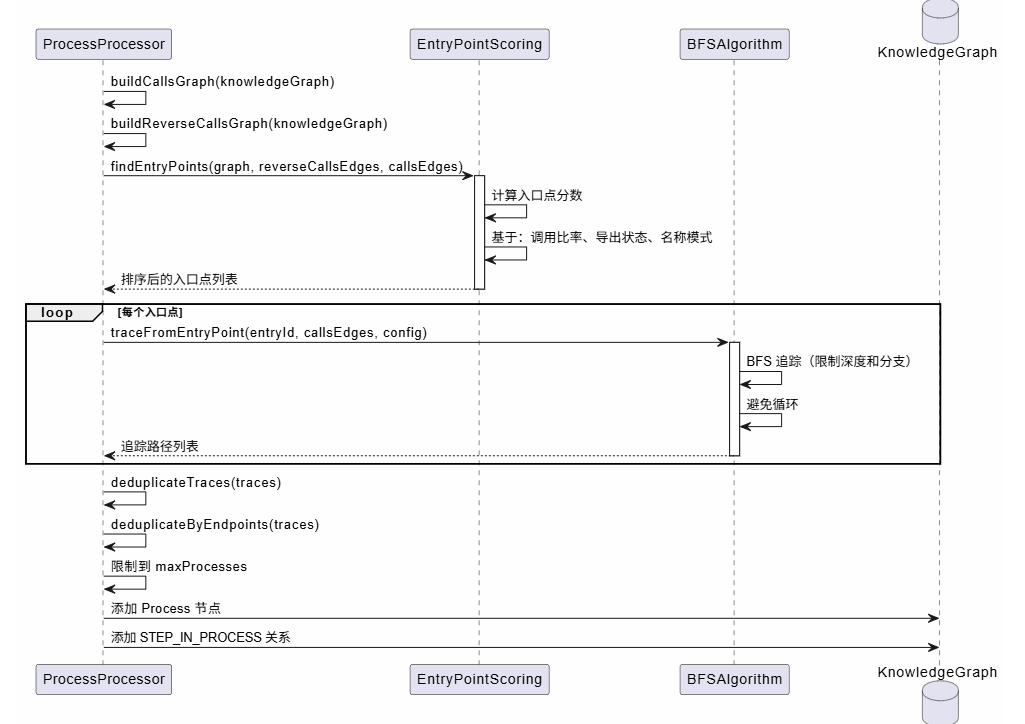
入口点评分策略:
typescript
// 入口点分数 = 基础分数 × 导出加成 × 名称模式加成
const baseScore = callees.length / (callers.length + 1);
const exportBoost = isExported ? 1.5 : 1.0;
const namePatternBoost = matchesPattern(name) ? 1.3 : 1.0;
const score = baseScore * exportBoost * namePatternBoost;追踪限制:
maxTraceDepth=10:最大追踪深度maxBranching=4:每个节点最多追踪 4 个分支minSteps=3:最小流程步数(2 步只是 "A 调用 B",不算流程)
2.4 混合搜索流程
混合搜索结合 BM25 关键词搜索和语义向量搜索,使用 RRF(Reciprocal Rank Fusion)融合结果。
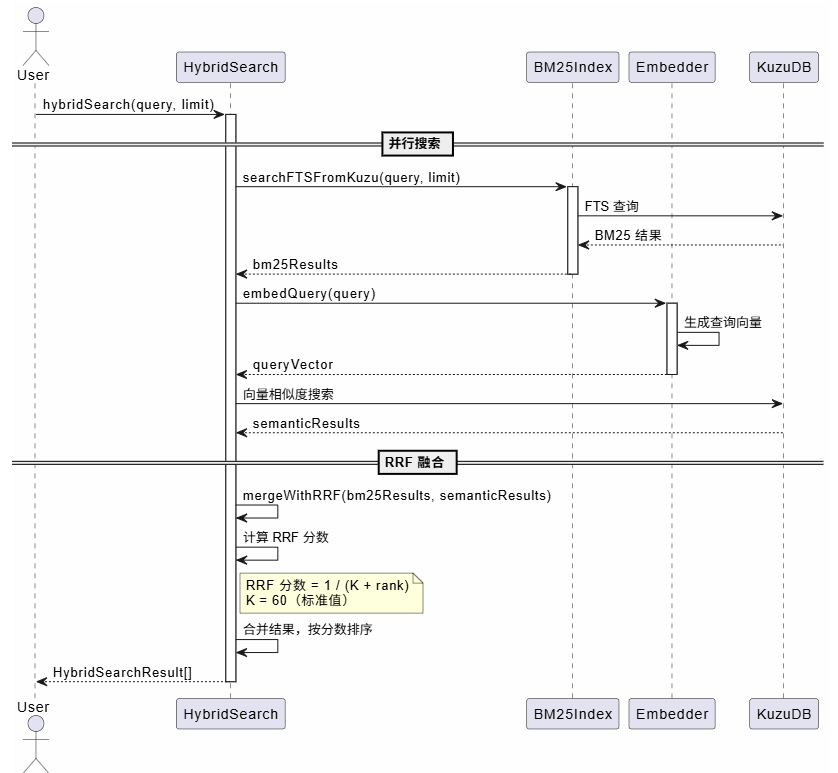
RRF 融合公式:
RRF_score(d) = Σ 1 / (K + rank_i(d))其中:
K = 60(标准 RRF 常数)rank_i(d)是文档d在第i个搜索结果中的排名- 最终分数是各排名分数的总和
三、关键实现点说明
3.1 Worker 池并行解析优化
GitNexus 使用 Worker 池实现并行 AST 解析,显著提升大代码库的索引速度。
实现要点:
typescript
// 创建 Worker 池(自动检测 CPU 核心数)
const workerPool = createWorkerPool(workerUrl);
// 分发任务到 Worker 池
const chunkResults = await workerPool.dispatch<ParseWorkerInput, ParseWorkerResult>(
parseableFiles,
(filesProcessed) => {
onFileProgress?.(filesProcessed, total, 'Parsing...');
}
);
// 合并结果
for (const result of chunkResults) {
// 合并节点、关系、符号表
result.nodes.forEach(node => graph.addNode(node));
result.relationships.forEach(rel => graph.addRelationship(rel));
result.symbols.forEach(sym => symbolTable.add(sym.filePath, sym.name, sym.nodeId, sym.type));
}优雅降级: 如果 Worker 池创建失败(如单核 CPU),自动降级为顺序处理,确保在任何环境下都能工作。
3.2 语言感知的导入解析
不同语言的导入机制差异巨大,GitNexus 为每种语言实现了专门的解析逻辑。
TypeScript/JavaScript:
- 相对路径:
./utils→ 解析为相对于当前文件的路径 - node_modules:
lodash→ 查找node_modules/lodash - 路径别名:
@/components→ 解析 tsconfig.json 的 paths 配置
Go:
- 包路径:
github.com/user/repo/pkg→ 查找$GOPATH/src/github.com/user/repo/pkg - 相对导入:
./internal/utils→ 相对于当前包的路径
Python:
- 相对导入:
from .utils import func→ 解析为包内相对路径 - 绝对导入:
from pkg.utils import func→ 查找 sys.path
3.3 调用关系置信度计算
调用关系的置信度直接影响后续的流程追踪和影响分析。GitNexus 使用多因素评分:
typescript
// 1. 精确匹配(名称 + 参数数量)
if (calleeName === targetName && paramCount === expectedParams) {
confidence = 0.95;
}
// 2. 名称匹配(仅名称)
else if (calleeName === targetName) {
confidence = 0.70;
}
// 3. 模糊匹配(部分名称)
else if (calleeName.includes(targetName) || targetName.includes(calleeName)) {
confidence = 0.50;
}
// 4. 全局匹配(未解析的标识符)
else {
confidence = 0.30;
}流程追踪过滤: 仅使用置信度 ≥ 0.5 的 CALLS 边进行流程追踪,避免模糊匹配导致的跨模块跳跃。
3.4 社区内聚度采样优化
对于大型社区(>50 个成员),完整计算内聚度的复杂度为 O(N²)。GitNexus 使用采样优化:
typescript
const SAMPLE_SIZE = 50;
const sample = memberIds.length <= SAMPLE_SIZE
? memberIds
: memberIds.slice(0, SAMPLE_SIZE);
// 仅对采样成员计算边密度
for (const nodeId of sample) {
graph.forEachNeighbor(nodeId, (neighbor) => {
totalEdges++;
if (memberSet.has(neighbor)) {
internalEdges++;
}
});
}
const cohesion = internalEdges / totalEdges;误差控制: 采样误差在可接受范围内(<5%),同时将计算复杂度从 O(N²) 降至 O(N)。
3.5 嵌入生成与设备选择
GitNexus 使用 transformers.js 生成嵌入向量,支持多种设备后端。
设备优先级:
- Windows:DirectML(DirectX12 GPU 加速)
- Linux:CUDA(NVIDIA GPU 加速)
- Fallback:CPU(兼容性最好)
实现策略:
typescript
const devicesToTry: Array<'dml' | 'cuda' | 'cpu' | 'wasm'> =
(requestedDevice === 'dml' || requestedDevice === 'cuda')
? [requestedDevice, 'cpu'] // 尝试 GPU,失败则回退 CPU
: [requestedDevice];
for (const device of devicesToTry) {
try {
embedderInstance = await pipeline('feature-extraction', modelId, {
device: device,
dtype: 'fp32',
});
currentDevice = device;
break; // 成功则退出
} catch (deviceError) {
// 继续尝试下一个设备
}
}模型选择: 默认使用 snowflake-arctic-embed-xs(22M 参数,384 维,~90MB),在质量和速度之间取得平衡。
四、总结
GitNexus 的核心引擎通过三个相互协作的子系统,实现了从代码库到知识图谱的完整转换:
- 索引流水线:9 阶段流水线,从文件扫描到 KuzuDB 加载,每个阶段都有明确的职责和进度反馈。Worker 池并行解析和 AST 缓存优化显著提升了性能。
- 社区与流程检测:Leiden 算法实现功能聚类,BFS 算法追踪执行流程。入口点评分、追踪限制和去重策略确保了流程质量。
- 混合搜索与嵌入:BM25 + 语义搜索 + RRF 融合,支持多设备后端(DirectML/CUDA/CPU)。RRF 融合无需分数归一化,简单高效。
技术亮点:
- 并行优化:Worker 池并行解析,优雅降级保证兼容性
- 语言感知:9 种语言的专门解析逻辑,覆盖主流编程语言
- 置信度评分:多因素调用关系置信度,过滤低质量边
- 采样优化:社区内聚度采样,O(N²) → O(N) 复杂度优化
- 设备自适应:GPU 优先,CPU 回退,最大化性能
这些设计使得 GitNexus 能够在合理的时间内(通常几分钟)完成大型代码库的索引,并生成高质量的知识图谱,为后续的查询、分析和智能体集成奠定基础。