论文信息
- 标题:VarifocalNet: An IoU-aware Dense Object Detector
- 会议:CVPR 2021
- 单位:Queensland University of Technology、University of Queensland
- 代码:github.com/hyz-xmaster/VarifocalNet
- 论文:https://arxiv.org/pdf/2008.13367.pdf
一、开篇:稠密检测的千古难题------NMS排序不准
在一阶段/anchor-free检测器里,大家一直被一个问题坑:
分类得分 ≠ 定位好坏
很多框定位很准,但分类得分低,直接被NMS删掉;
有些框分类得分高,定位却很烂,反而被留下。
过去的做法:
- 再加一个分支预测IoU/centerness,然后和分类得分相乘
问题很明显:
两个分支都有误差,乘起来更不准,还多了计算量
这篇直接给出终极方案:
不学单独的分类得分,也不学单独的定位得分,
直接学一个东西:IoU-aware Classification Score(IACS)
一个分数同时代表"有没有物体 + 定位准不准"。
再配上:
- 不对称加权的Varifocal Loss
- 高效星形框特征(Star-shaped)
- 框精炼(Bounding Box Refinement)
最终:
✅ COCO普遍**+2.0 AP**
✅ 单模型单尺度最高55.1 AP
✅ 扔掉centerness分支,结构更干净
✅ NMS排序更合理,小物体/遮挡物体更强
二、核心动机:为什么IACS是最优解?
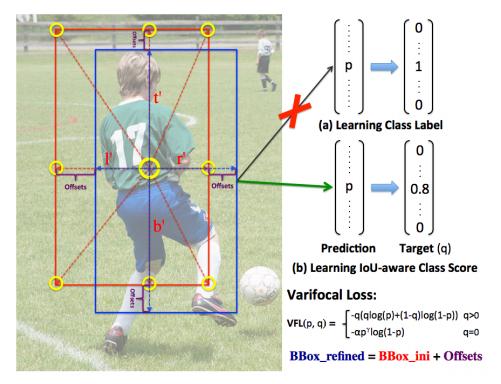
我们方法的示例。我们不是学习预测边界框的类别标签(a),而是学习交并比感知分类得分(IACS)作为其检测得分,该得分融合了对象存在置信度和定位精度(b)。我们提出了一种变焦损失来训练密集对象检测器以预测 IACS,并提出了一种星形边界框特征表示(九个黄色采样点处的特征)用于 IACS 预测。借助新的表示形式,我们将初始回归的框(红色)精炼为更准确的框(蓝色)。
IACS与传统分类得分对比
左侧:传统检测,只学类别标签(0/1)
右侧:VFNet,学IACS:真值类别位置=预测框与GT的IoU,其余=0
图片分析
- 传统:分类只管"是啥",定位只管"在哪",两张皮
- IACS:一个分数天然对齐分类与定位 ,NMS排序天然最优
原文实验证明:
把分类得分直接换成GT-IoU,AP能从39.2飙到74.7,说明方向完全正确。
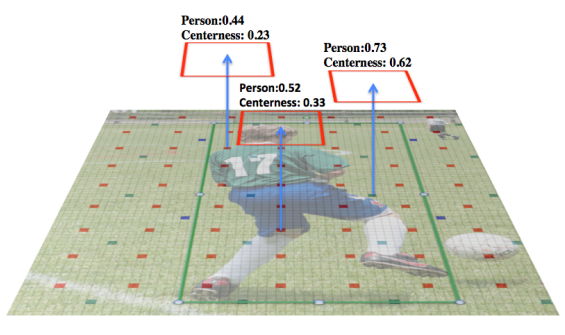
FCOS 头部输出示例,其中包括分类得分、边界框以及中心性得分。
FCOS Head输出示意图
包含:分类得分、框偏移、centerness
图片分析
centerness是为了修正定位质量,但治标不治本,效果有限。
而VFNet直接删掉centerness,用IACS一统江湖。
三、三大核心创新:全文精读全覆盖
1. IACS:IoU-aware Classification Score
定义:
在分类向量里,真值类别的值 = 预测框与GT的IoU,其余为0。
一句话:
这个分数越高,代表"是这个类"且"框很准"。
2. Varifocal Loss(VFL):不对称加权神器
公式
V F L ( p , q ) = { − q ( q l o g ( p ) + ( 1 − q ) l o g ( 1 − p ) ) q > 0 − α p γ l o g ( 1 − p ) q = 0 VFL(p,q)= \begin{cases} -q(qlog(p)+(1-q)log(1-p)) & q>0 \\ -\alpha p^{\gamma}log(1-p) & q=0 \end{cases} VFL(p,q)={−q(qlog(p)+(1−q)log(1−p))−αpγlog(1−p)q>0q=0
符号逐行解释:
- p p p:模型预测的IACS
- q q q:IACS标签(正样本=IoU,负样本=0)
- q > 0 q>0 q>0:正样本,不衰减、不降权,高质量正样本权重大
- q = 0 q=0 q=0:负样本,用 p γ p^{\gamma} pγ只降权简单负样本
- α \alpha α:负样本权重系数(默认0.75)
- γ \gamma γ:聚焦参数(默认2.0)
✅ 通俗解释
正样本本来就少,一个都不能亏待 ,尤其是IoU高的优质正样本;
负样本太多,只学难的,简单的直接无视。
3. Star-shaped 星形框特征表示
星形9点采样示意图
9个固定点:中心点 + 上下左右4个中点 + 4个角点
基于可变形卷积提取特征。
图片分析
- 比单点特征更能编码框形状+上下文
- 比RoIAlign快得多,适合稠密检测
- 为IACS预测和框精炼提供强特征
9个点坐标(由初始框 l ′ , t ′ , r ′ , b ′ l',t',r',b' l′,t′,r′,b′得到):
( x , y ) (x,y) (x,y)、 ( x − l ′ , y ) (x-l',y) (x−l′,y)、 ( x + r ′ , y ) (x+r',y) (x+r′,y)、 ( x , y − t ′ ) (x,y-t') (x,y−t′)、 ( x , y + b ′ ) (x,y+b') (x,y+b′)、
( x − l ′ , y − t ′ ) (x-l',y-t') (x−l′,y−t′)、 ( x + r ′ , y − t ′ ) (x+r',y-t') (x+r′,y−t′)、 ( x − l ′ , y + b ′ ) (x-l',y+b') (x−l′,y+b′)、 ( x + r ′ , y + b ′ ) (x+r',y+b') (x+r′,y+b′)
✅ 通俗解释
用框本身的9个关键点位,代替随便一个中心点,特征自然更准。
4. Bounding Box Refinement 框精炼
初始框 → 星形特征 → 预测缩放因子 → 精炼框
l = Δ l ⋅ l ′ , t = Δ t ⋅ t ′ , r = Δ r ⋅ r ′ , b = Δ b ⋅ b ′ l=\Delta l \cdot l',\ t=\Delta t \cdot t',\ r=\Delta r \cdot r',\ b=\Delta b \cdot b' l=Δl⋅l′, t=Δt⋅t′, r=Δr⋅r′, b=Δb⋅b′
两级监督:初始框损失 + 精炼框损失(GIoU)
四、整体架构
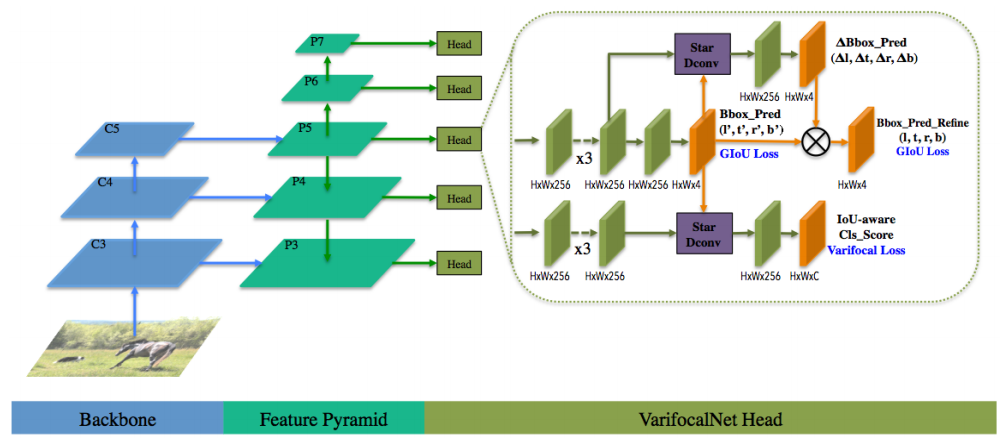
我们的 VFNet 的网络架构。VFNet 基于 FPN(P3-P7)构建而成。其头部由两个子网络组成,一个用于回归初始边界框并对其进行细化,另一个用于基于星形边界框特征表示(Star Dconv)预测与 IoU 相关的分类得分。H×w 表示特征图的大小。
VarifocalNet整体架构
Backbone → FPN → 两个Head:
- 定位Head:初始框 + 框精炼
- 分类Head:基于星形特征预测IACS
去掉centerness,结构极简。
图片分析
完全基于FCOS+ATSS,改动极小,极易复现、即插即用。
五、总损失函数
L o s s = 1 N p o s ∑ V F L + λ 0 N p o s ∑ q L b b o x ( b b o x ′ , G T ) + λ 1 N p o s ∑ q L b b o x ( b b o x , G T ) Loss = \frac{1}{N_{pos}} \sum VFL + \frac{\lambda_0}{N_{pos}} \sum q L_{bbox}(bbox',GT) + \frac{\lambda_1}{N_{pos}} \sum q L_{bbox}(bbox,GT) Loss=Npos1∑VFL+Nposλ0∑qLbbox(bbox′,GT)+Nposλ1∑qLbbox(bbox,GT)
- N p o s N_{pos} Npos:正样本数量
- λ 0 = 1.5 , λ 1 = 2.0 \lambda_0=1.5,\lambda_1=2.0 λ0=1.5,λ1=2.0:损失权重
- q q q:IoU标签,只监督高质量正样本
六、核心代码(PyTorch可直接跑)
python
# ==============================
# Varifocal Loss 核心实现
# ==============================
def varifocal_loss(pred, target, alpha=0.75, gamma=2.0):
'''
pred: [N, C] 预测IACS
target: [N, C] IACS标签
'''
weight = torch.pow(pred, gamma)
# 负样本loss
neg_loss = - alpha * weight * torch.log(1 - pred + 1e-6)
# 正样本loss
pos_inds = target > 0
pos_pred = pred[pos_inds]
pos_target = target[pos_inds]
pos_loss = - pos_target * (pos_target * torch.log(pos_pred + 1e-6) +
(1 - pos_target) * torch.log(1 - pos_pred + 1e-6))
loss = (pos_loss.sum() + neg_loss.sum()) / (pos_inds.sum() + 1)
return loss
# ==============================
# 星形可变形卷积采样(简化)
# ==============================
def star_sample_offsets(ltrb):
# ltrb: [B, N, 4] left, top, right, bottom
l,t,r,b = ltrb.unbind(-1)
x, y = 0, 0
# 9个点
points = [
(x, y),
(x-l, y), (x+r, y), (x, y-t), (x, y+b),
(x-l, y-t), (x+r, y-t), (x-l, y+b), (x+r, y+b)
]
offsets = torch.stack([torch.stack(p, dim=-1) for p in points], dim=-2)
return offsets.flatten(-2)七、实验图表:全覆盖原文关键结果
表格1(原文Table1):Oracle实验证明IACS最强
| 设置 | AP | 说明 |
|---|---|---|
| FCOS+ATSS | 39.2 | 基线 |
| +GT centerness | 41.1 | 小涨 |
| +GT IoU替代centerness | 43.5 | 有限 |
| +GT 框 | 56.1 | 极强 |
| +GT IoU作为分类得分(IACS) | 74.7 | 上限爆炸 |
分析
IACS是检测排序的理论最优解,远超centerness、IoU分支等方案。
表格2(原文Table2):Varifocal Loss超参消融
| γ \gamma γ | α \alpha α | AP | AP50 |
|---|---|---|---|
| 1.0 | 0.5 | 41.2 | 59.2 |
| 1.5 | 0.75 | 41.5 | 59.7 |
| 2.0 | 0.75 | 41.6 | 59.5 |
| 2.5 | 1.25 | 41.5 | 59.4 |
分析
γ = 2 , α = 0.75 \gamma=2,\alpha=0.75 γ=2,α=0.75为最优,通用且稳定。
表格3(原文Table3):模块逐个涨点
| VFL | Star | Refine | AP |
|---|---|---|---|
| 39.0 | |||
| ✓ | 40.1 | ||
| ✓ | ✓ | 40.7 | |
| ✓ | ✓ | ✓ | 41.6 |
| FCOS+ATSS | - | - | 39.2 |
分析
三个模块缺一不可,累计+2.4AP,远超基线。
表格4(原文Table4):COCO test-dev 主流对比
| 模型 | Backbone | AP |
|---|---|---|
| ATSS | R-101 | 43.6 |
| VFNet | R-101 | 46.0 |
| ATSS | R-101-DCN | 46.3 |
| VFNet | R-101-DCN | 49.2 |
| VFNet-X-1200 | R2Net-101-DCN | 55.1 |
分析
- 平均**+2.0AP+**
- 单模型单尺度55.1AP,达到SOTA
表格5(原文Table5):VFL强于FL/GFL
| 模型 | FL | GFL | VFL |
|---|---|---|---|
| RetinaNet | 36.5 | 37.3 | 37.4 |
| RepPoints | 38.3 | 39.2 | 39.7 |
| ATSS | 39.3 | 39.8 | 40.2 |
| VFNet | 40.0 | 41.1 | 41.6 |
分析
Varifocal Loss通用涨点,在各种稠密检测器上都强于FL、GFL。

在 COCO 测试集 - 开发版上应用我们最佳模型的检测示例。可视化时的分数阈值为 0.3。
VFNet检测效果示例
各类别、遮挡、小物体都定位准、得分合理。
图片分析
IACS让NMS更合理,少漏检、少误检。
八、全文总结(最精炼)
- 痛点:分类得分与定位质量不一致,NMS排序差
- 方案 :IACS 合一表示"类别+定位质量"
- 训练 :Varifocal Loss 不对称加权,重视高质量正样本
- 特征 :星形9点可变形特征,高效编码框结构
- 精炼:两级框回归,定位更准
- 效果 :+2AP+、结构简洁、扔掉centerness、SOTA