SkyWalking日志异步采集架构

环境:
操作系统:macOS Monterey 12.7.6
Skywalking OAP:10.3.0
Skywalking Agent:9.5.0
Kafka:3.6.1 (kraft模式启动)
Kafka-map:1.3.2(Kafka图形工具)
ElasticSearch:8.11.1
Kibana:8.11.2
Java应用:Eureka及几个微服务应用
【干货】
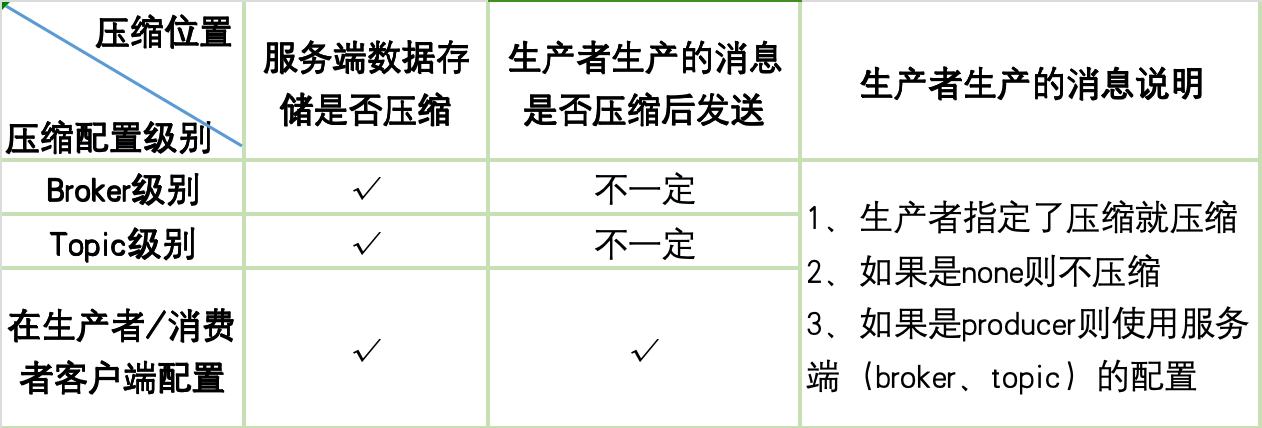
1、数据压缩在agent端指定(保证发送的消息及存储的消息都是压缩后的)
2、可以通过 plugin.kafka.producer_config 配置压缩工具/算法
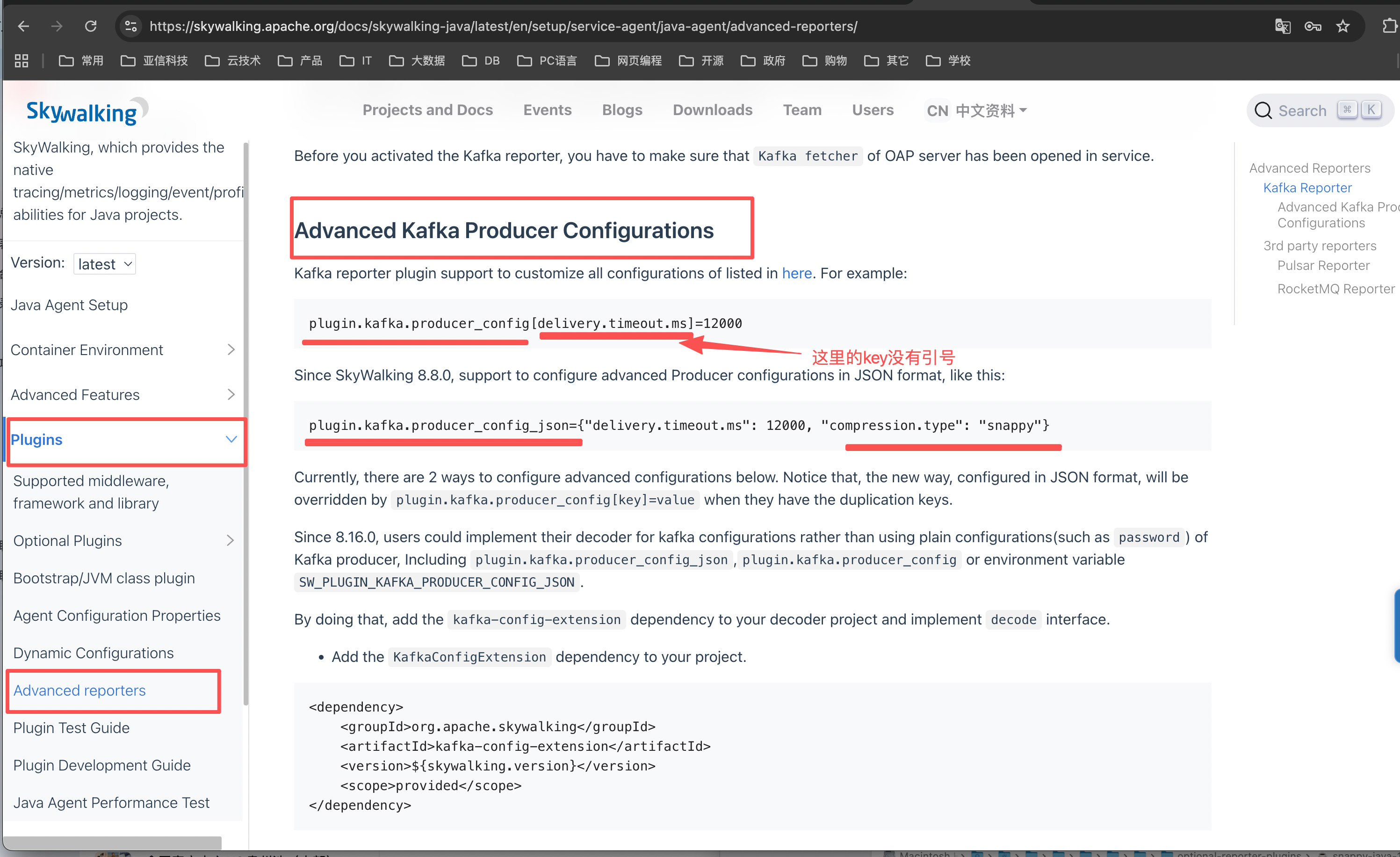
3、可以通过 plugin.kafka.producer_config_json 配置压缩工具/算法(skywalking agent 8.8.0+)
4、PRODUCER_CONFIG 覆盖 PRODUCER_CONFIG_JSON
5、PRODUCER_CONFIG配置的key需使用 -- 中括号,且key不能使用引号(单引用双引号都不行)
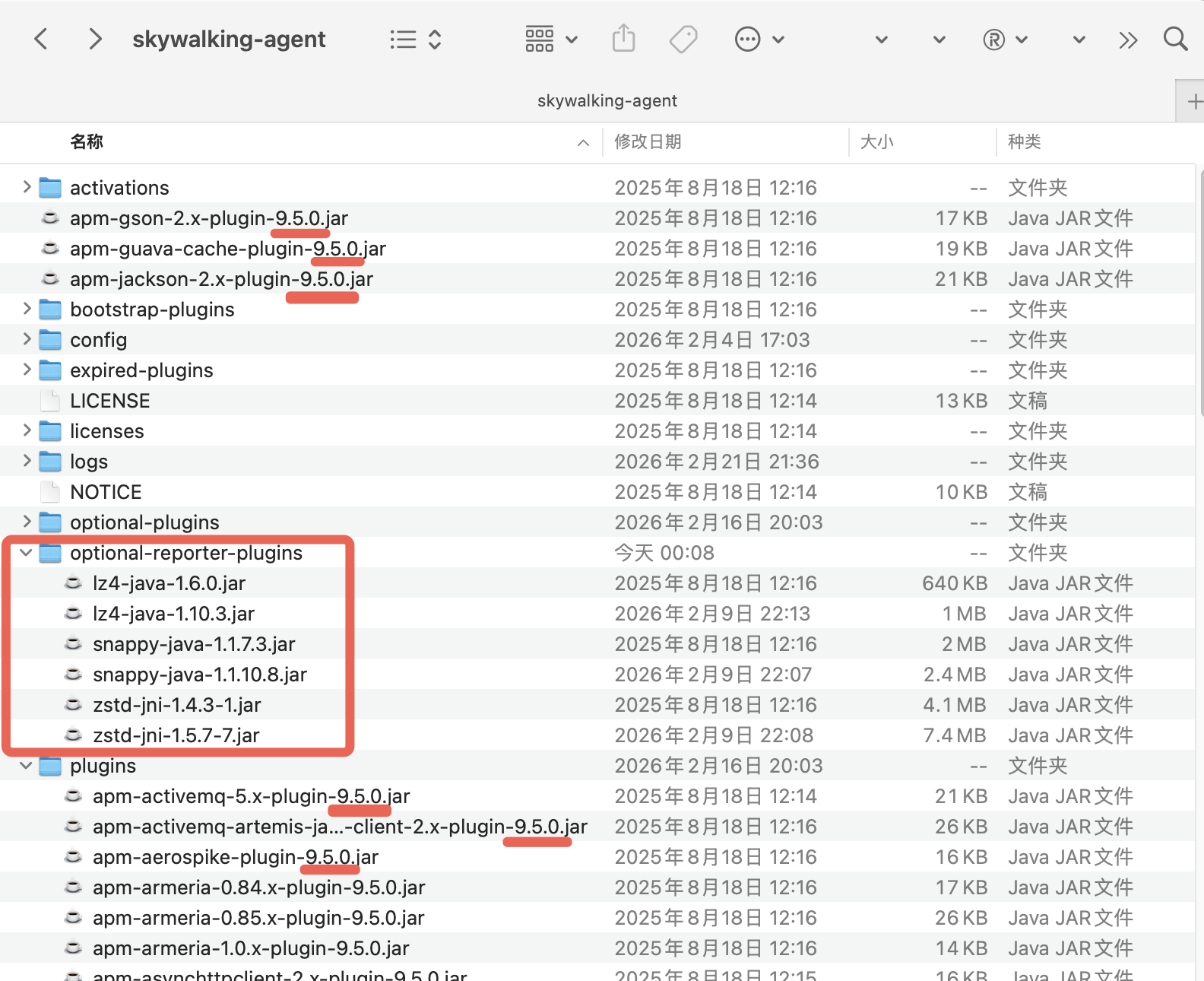
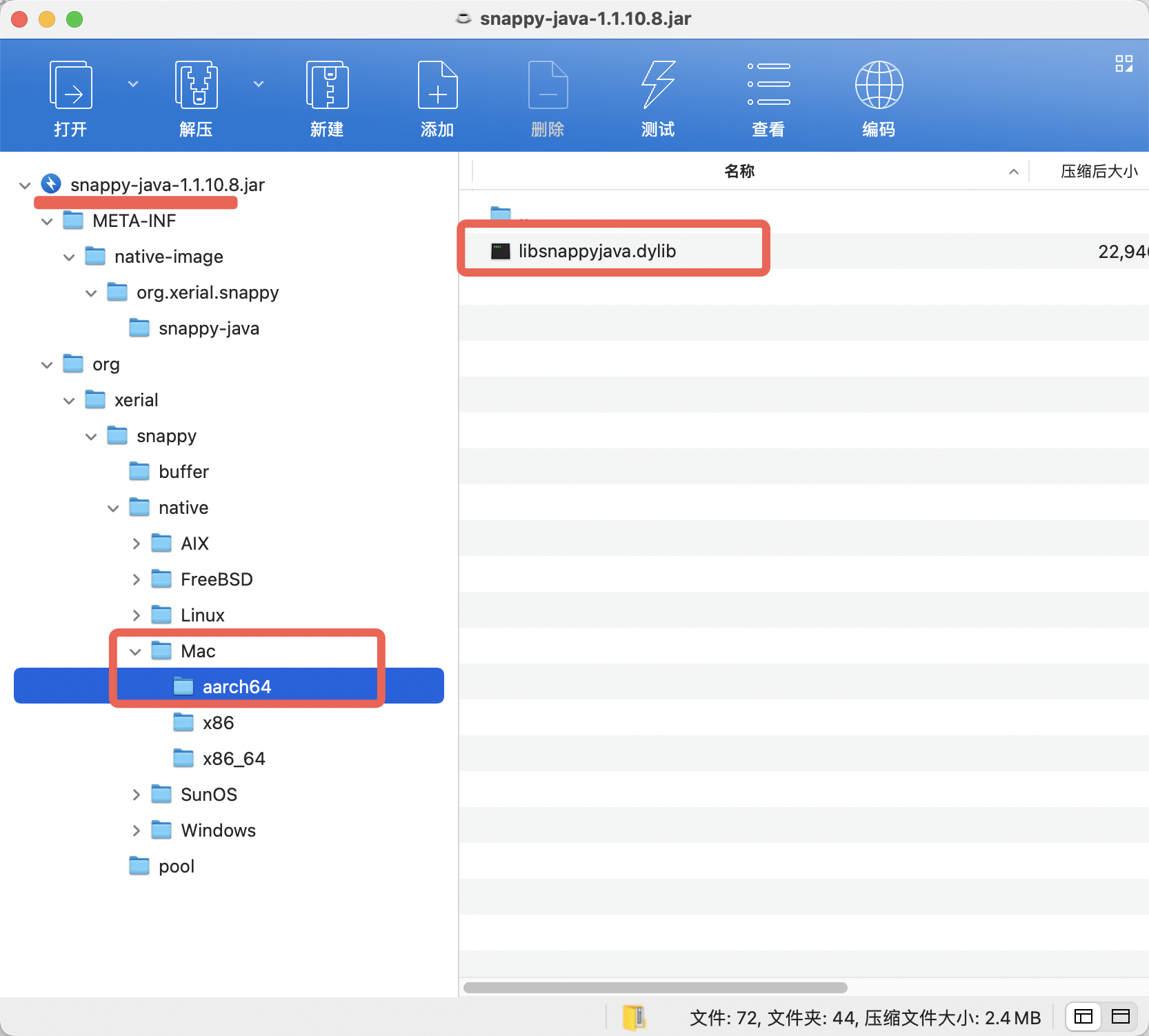
6、Skywalking agent 9.5.0(当前20260223最新版本)optional-reporter-plugins中的压缩工具不支持MacOS arm架构(里面没有其动态库),如在ARM 架构Mac OS上验证,可单独升级使用的压缩工具,如:snappy-java-1.1.7.3.jar ---->升级为snappy-java-1.1.10.8.jar
7、kafka客户端(图形)工具(如:CMAK、Kafka-map等)上看到的消息不管实际队列中有没有压缩,展示到界面上的都是解压后的(如果存储的是压缩后的数据工具会自动解压后展示到界面上)
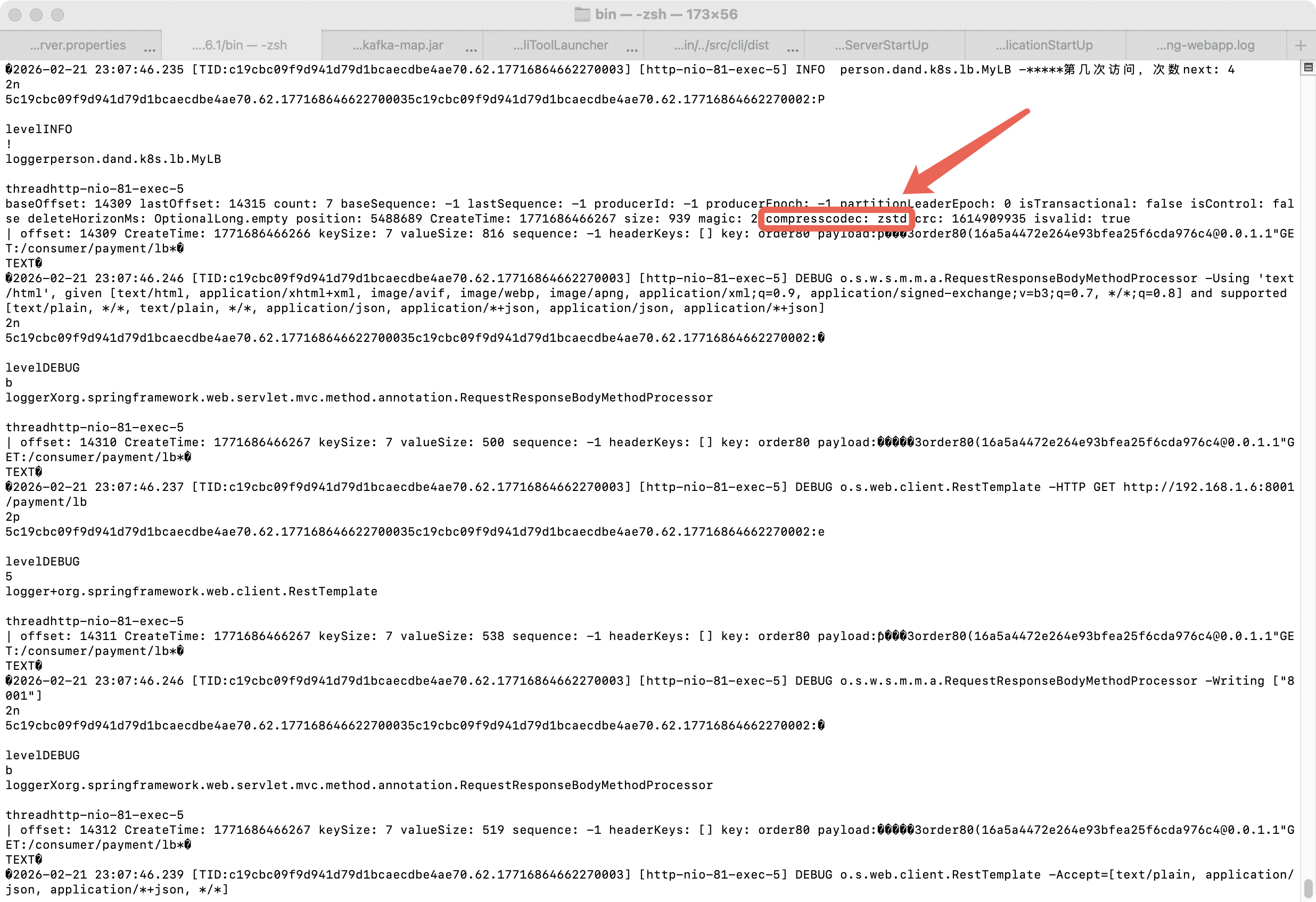
8、验证kafka队列中的数据是否是被压缩后的数据最权威的方法就是直接读取 Broker 上的日志文件,展示每条消息的压缩状态
分析过程:
1、图表说明kafka消息数据压缩
2、官方帮助文档压缩配置示例
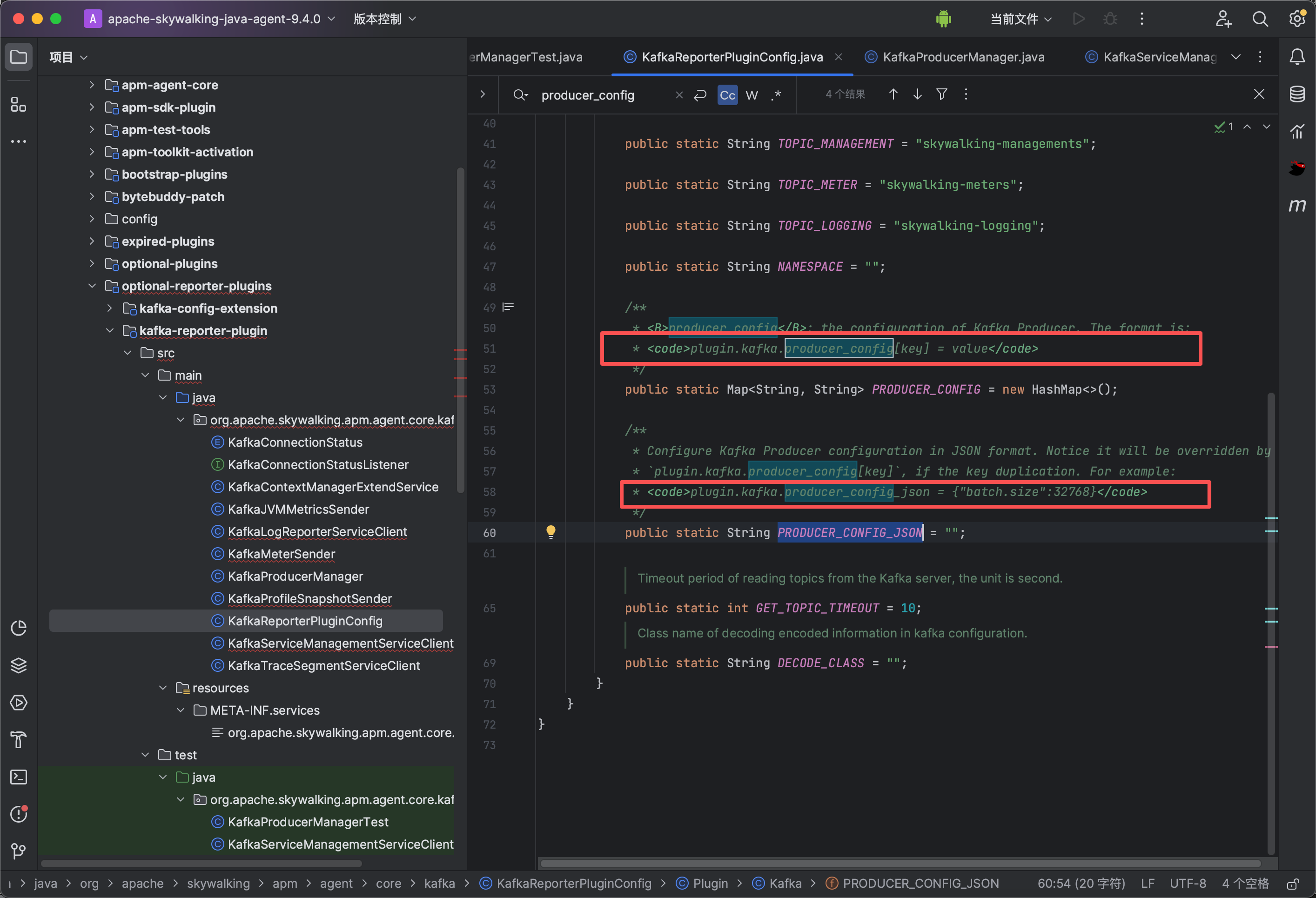
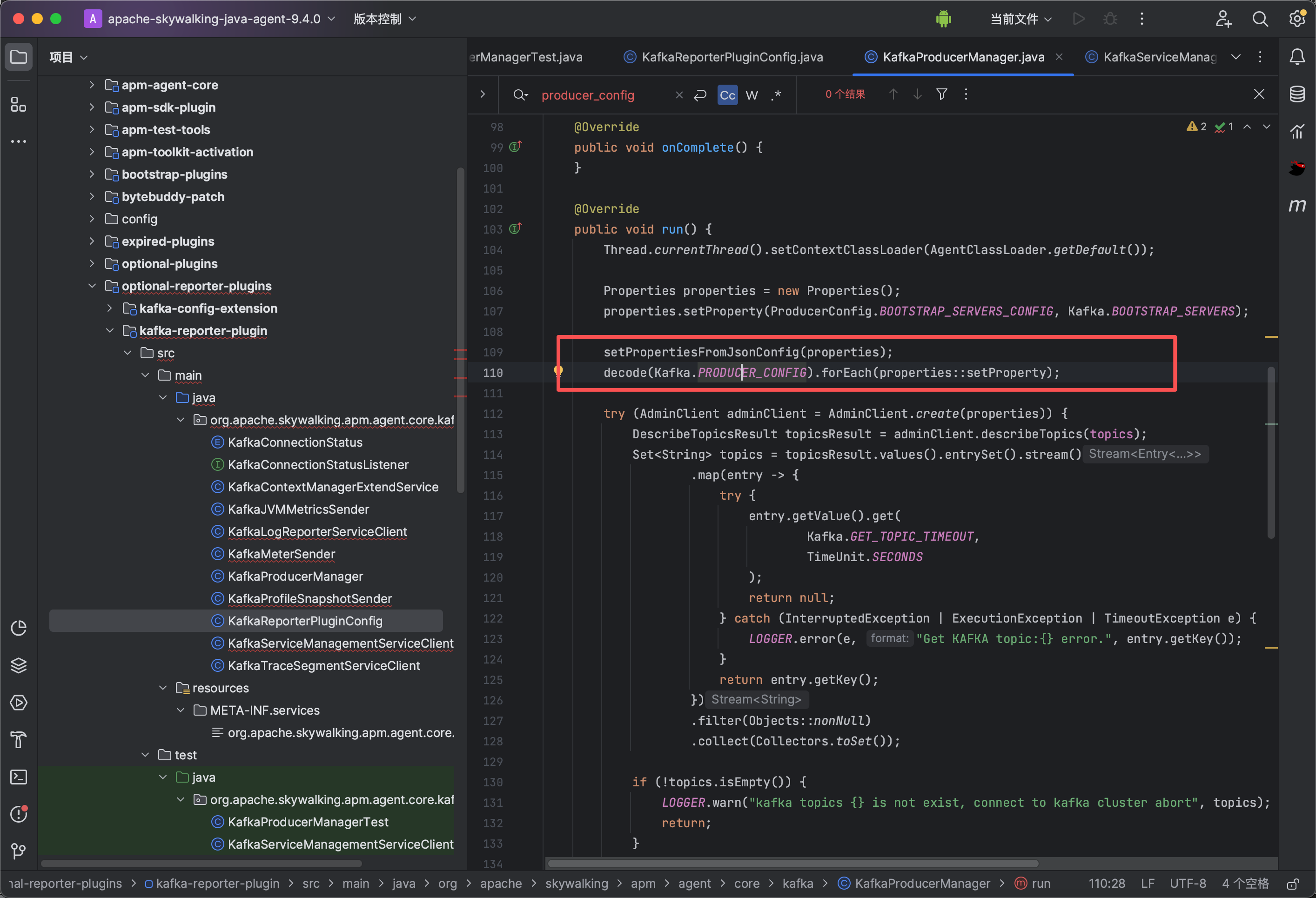
3、典型源代码分析
PRODUCER_CONFIG、PRODUCER_CONFIG_JSON
4、压缩工具(包含升级后的)
5、查看Broker日志验证数据压缩状态
6、Skywalking agent配置示例
仅agent中kafka配置部分
bash
plugin.kafka.producer_config[delivery.timeout.ms]=32000
plugin.kafka.producer_config[compression.type]=zstd
plugin.kafka.producer_config[acks]=0
plugin.kafka.producer_config[retries]=3
plugin.kafka.producer_config[batch.size]=32768
plugin.kafka.producer_config[linger.ms]=50
plugin.kafka.producer_config[request.timeout.ms]=30000
plugin.kafka.producer_config[buffer.memory]=33554432
plugin.kafka.producer_config[client.id]=${KAFKA_CLIENT_ID:mysys_sw_agent}
plugin.kafka.producer_config[max.in.flight.requests.per.connection]=10
plugin.kafka.producer_config[key.serializer]=org.apache.kafka.common.serialization.StringSerializer
plugin.kafka.producer_config[value.serializer]=org.apache.kafka.common.serialization.StringSerializer
# 与上面的方式两选一即可,两种都打开时 producer_config 会覆盖 producer_config_json
# plugin.kafka.producer_config_json={"delivery.timeout.ms":32000,"compression.type":"zstd","acks":0,"retries":3,"batch.size":32768,"linger.ms":50,"request.timeout.ms":30000,"buffer.memory":33554432,"client.id":crm_sw_agent,"max.in.flight.requests.per.connection":10,"key.serializer":"org.apache.kafka.common.serialization.StringSerializer","value.serializer":"org.apache.kafka.common.serialization.StringSerializer"}附件
附件一:最新压缩工具下载地址
20260223
https://repo1.maven.org/maven2/org/xerial/snappy/snappy-java/1.1.10.8/snappy-java-1.1.10.8.jar
https://repo1.maven.org/maven2/com/github/luben/zstd-jni/1.5.7-7/zstd-jni-1.5.7-7.jar
https://repo1.maven.org/maven2/at/yawk/lz4/lz4-java/1.10.3/lz4-java-1.10.3.jar
附件
附件二:Kafka几项核心的底层技术
Kafka 的高性能、高可靠性和高吞吐量,源于其一系列精妙的底层设计技术。以下是几项核心的底层技术:
1. 分区(Partition)与并行处理
Kafka 将每个主题(Topic)划分为多个分区,每个分区是一个有序的、不可变的消息日志。这种设计是 Kafka 实现高吞吐量和水平扩展的基础。
- 并行读写:生产者可以将消息并行写入不同的分区,消费者也可以并行地从多个分区拉取消息,极大地提升了系统的并发处理能力。
- 负载均衡:分区可以分布在集群中的不同 Broker 上,实现了数据的分布式存储和负载均衡。
- 顺序性保证 :Kafka 保证了分区内消息的严格顺序,虽然跨分区的消息顺序无法保证,但对于大多数场景,分区内有序已足够。
**2. 顺序写入与零拷贝(Zero-Copy)**
Kafka 充分利用了磁盘和操作系统的特性来优化性能。
- 顺序写入:消息被追加(Append)到分区日志文件的末尾,这种顺序写入方式避免了磁盘频繁的寻道操作,使得 Kafka 在普通机械硬盘上也能实现极高的写入吞吐量。
- 零拷贝技术 :当消费者读取消息时,Kafka 利用操作系统的
sendfile系统调用,直接将数据从磁盘文件缓冲区传输到网络缓冲区,避免了数据在内核态与用户态之间的多次拷贝。这显著降低了 CPU 开销,提升了网络传输效率。
3. 副本机制(Replication)与 ISR
为了保证数据的高可用性和可靠性,Kafka 引入了副本机制。
- Leader/Follower:每个分区有多个副本,其中一个被选举为 Leader,负责处理所有生产者和消费者的读写请求;其他副本为 Follower,仅从 Leader 异步拉取数据进行同步。
- ISR(In-Sync Replicas) :Kafka 维护一个"同步副本"列表(ISR),只有那些与 Leader 副本同步延迟在可接受范围内的 Follower 才会被包含在 ISR 中。**只有当消息被写入 ISR 列表中的所有副本后,生产者才会收到确认(ack=-1)**,这确保了即使 Leader 宕机,数据也不会丢失。
- 高可用性:当 Leader 宕机时,Kafka 会从 ISR 列表中选举出一个新的 Leader,保证服务不中断。
4. 批量处理与消息压缩
Kafka 通过批量操作来 amortize(分摊)网络和磁盘 I/O 开销。
- 批量发送 :生产者会将多条消息缓存起来,达到一定大小(
batch.size)或等待一定时间(linger.ms)后,再一次性发送给 Broker,减少了网络请求次数。 - 消息压缩:生产者可以在发送前对消息批次进行压缩(如 gzip、snappy、lz4),减少了网络传输的数据量和磁盘存储空间。Broker 在存储和传输时也以压缩格式处理,消费者在消费时再解压。
5. 分段日志(Segment)与索引
为了管理庞大的日志文件并实现高效的消息查找,Kafka 采用了分段和索引机制。
- **分段(Segment)**:每个分区的日志文件被切割成多个大小固定的段(Segment)文件。当一个段文件达到预设大小(如 1GB)时,Kafka 会创建一个新的段文件。这使得日志文件的管理和清理(如删除过期数据)更加高效。
- 索引文件 :每个段文件对应两个索引文件------偏移量索引 (.index)和时间戳索引(.timeindex)。偏移量索引采用稀疏存储方式,通过二分查找可以快速定位到消息在日志文件中的物理位置,实现了 O(log n) 的消息查找时间复杂度。
6. 消费者位移(Offset)管理
Kafka 将消费进度(即位移)的管理权交给了消费者,而非 Broker。
- 消费者自主管理 :消费者在消费消息后,会定期将自己消费到的位移(Offset)提交并保存(可保存在 Kafka 内部主题
__consumer_offsets或外部存储如 Redis 中)。 - 容错与重放:如果消费者宕机,重启后可以从最后一次提交的位移处继续消费,保证了"至少一次"(At-Least-Once)的语义。这种设计也允许消费者灵活地重放历史消息。