本文介绍阿斯利康团队近日公开的开源多肽分析平台------Peptide-Tools Web Server的线上使用及本地部署。本文是第一部分,介绍多肽等电点的相关研究和Peptide-Tools预测等电点(pl)的应用。
Peptide-Tools可快速、可靠地评估肽分子的理化性质,包括等电点、摩尔消光系数和化学稳定性,可处理包含非天然氨基酸、化学修饰或复杂末端结构的肽分子。
Peptide-Tools的介绍文章于2025年12月30发表在国际权威期刊Journal of Chemical Information and Modeling,标题为Peptide-Tools--Web Server for Calculating Physicochemical Properties of Peptides。
代码:https://github.com/AstraZeneca/peptide-tools
文章:https://pubs.acs.org/doi/10.1021/acs.jcim.5c02296
引言
肽类治疗药物 (PTs)
近年来,肽类治疗药物(PTs)引起了越来越多的关注,填补了小分子药物和生物制剂(如抗体)之间的空白。与小分子相比,PTs 能够靶向浅表的结合口袋;与生物制剂相比,PTs 可以降低免疫原性并减少生产成本。生物活性肽可能来源于天然物质,包括内源性激素和毒素,也可以通过噬菌体展示等实验方法或合理设计策略(如表位模拟物设计)来发现。为了提高生物活性肽的效力、体内稳定性和口服生物利用度,通常会引入非天然氨基酸(nCAAs)、序列中氨基酸之间的共价连接子以及主链修饰。此外,肽类常与分子载荷结合,用于靶向递送应用。其他研究领域致力于使用肽纳米结构进行药物递送和半导体制造。一些肽已被证明能选择性地与材料结合,以改善其生物相容性。肽水凝胶已被证明具有抗菌活性,有助于伤口愈合。
肽纯化与表征的挑战
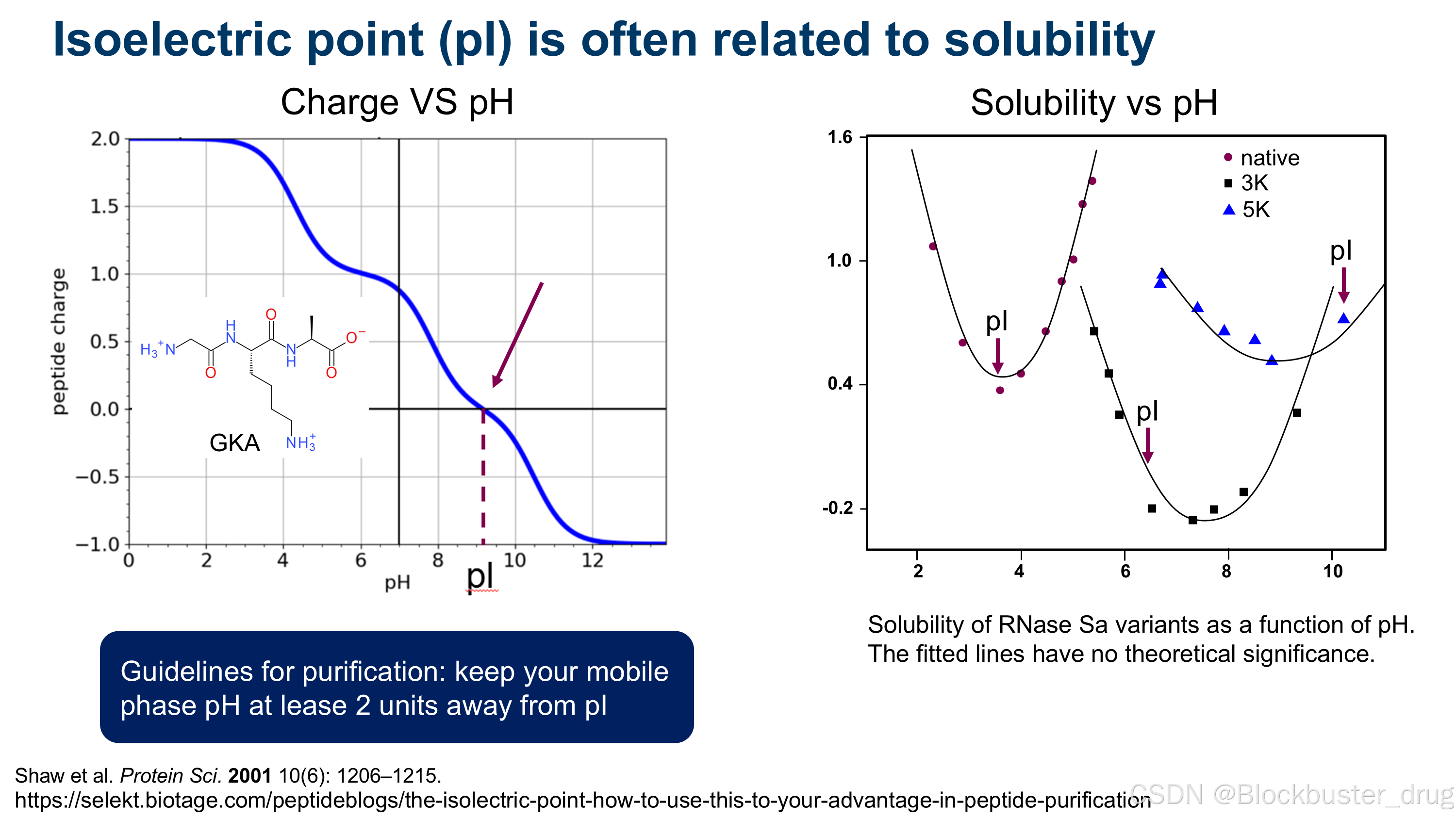
分析肽的电荷状态和等电点(pI)有助于解决肽设计中的若干挑战,包括提高溶解度、防止聚集和消除合成副产物。这些挑战会使肽的合成和纯化变得困难且耗时。此外,这些问题还可能导致不必要的免疫原性或毒性。在药物化学优化的设计阶段,肽的可开发性是一个关键考量因素,特别是对于那些打算配制成溶液型注射药物的肽。一种常见的策略是将设计序列的 pI 调整到远离生理 pH 的值,以增强肽的溶解度并实现稳定的液体配方。同样,在纯化过程中,通常通过将流动相的 pH 调整到远离肽的 pI,来最小化肽与反相液相色谱柱之间不希望的疏水相互作用。此外,通常可以对杂质的性质(例如,氨基酸偶联失败或二硫键还原)做出有根据的猜测,预测其电离状态,并战略性地选择流动相的 pH,以实现色谱峰的分离,即使是对结构相似的化合物也是如此。
一、多肽的等电点的概念及估算
多肽的等电点 (isoelectric point,简称 pI )是指该多肽在水溶液中净电荷为零时的 pH 值。在该 pH 条件下,多肽分子不带电,因此在电场中不会发生迁移。等电点是蛋白质和多肽的重要理化性质之一,对分离纯化(如等电聚焦、离子交换色谱)、溶解度、稳定性等具有重要意义。
多肽的净电荷与等电点
- 多肽由多个氨基酸通过肽键连接而成。
- 氨基酸残基中的可电离基团包括:
- N端氨基(---NH₃⁺)
- C端羧基(---COO⁻)
- 侧链可电离基团(如 Asp/Glu 的羧基、Lys 的氨基、Arg 的胍基、His 的咪唑基、Cys 的巯基、Tyr 的酚羟基等)
这些基团在不同 pH 下会质子化或去质子化,从而影响整个多肽的净电荷。
等电点计算原理
等电点 pI 是使多肽正电荷总数 = 负电荷总数(即净电荷为 0)时的 pH 值。
一般步骤:
-
列出所有可电离基团及其 pKa 值
包括:
- N 端 α-氨基(通常 pKa ≈ 8.0--9.0)
- C 端 α-羧基(通常 pKa ≈ 3.0--3.5)
- 各氨基酸侧链的 pKa(如 Asp ≈ 3.9,Glu ≈ 4.3,His ≈ 6.0,Cys ≈ 8.3,Tyr ≈ 10.1,Lys ≈ 10.5,Arg ≈ 12.5)
-
按 pKa 值从小到大排序
-
找出净电荷由正变负(或由负变正)的两个相邻 pKa 值
- 对于酸性多肽 (含较多 Asp/Glu),pI 通常位于两个最低的酸性 pKa之间;
- 对于碱性多肽 (含较多 Lys/Arg/His),pI 通常位于两个最高的碱性 pKa之间;
- 对于中性多肽,pI 通常位于一个酸性与一个碱性 pKa 之间。
-
取这两个 pKa 的平均值作为 pI 的近似值
\\text{pI} = \\frac{\\text{pKa}_1 + \\text{pKa}_2}{2}
注意:此方法适用于简单情况。对于复杂多肽(多个可电离基团),需使用更精确的数值方法(如 Henderson-Hasselbalch 方程迭代求解净电荷为零的 pH)。
多肽等电点计算举例说明
例1:三肽 Ala-Lys-Glu
- 可电离基团:
- N端 NH₃⁺:pKa ≈ 8.0
- C端 COOH:pKa ≈ 3.5
- Lys 侧链 NH₃⁺:pKa ≈ 10.5
- Glu 侧链 COOH:pKa ≈ 4.3
排序 pKa:3.5(C端)、4.3(Glu)、8.0(N端)、10.5(Lys)
计算各 pH 区间净电荷:
- pH < 3.5:所有酸性基团质子化(中性),碱性基团质子化(+2)→ 净电荷 +2
- 3.5--4.3:C端去质子(--1),Glu仍质子(0),碱性+2 → 净 +1
- 4.3--8.0:C端--1,Glu--1,碱性+2 → 净 0
- 8.0--10.5:N端去质子(0),Lys仍+1,酸性--2 → 净 --1
净电荷为 0 的区间在 4.3--8.0 之间,但需找电荷从 +1 到 --1 跨越 0 的两个 pKa 。实际上,在 4.3(Glu)之后电荷变为 0,在 8.0(N端)之后变为 --1。因此,pI 应在 Glu 和 N端之间?但注意:此时有两个正电荷(N端+Lys)和两个负电荷(C端+Glu)------当两个酸性基团都去质子、两个碱性基团都质子时,净电荷为 0。
更准确的做法是:找出使正负电荷相等的两个最邻近的 pKa。这里,失去第一个正电荷发生在 N端(pKa=8.0),而最后一个负电荷在 Glu(pKa=4.3)。但由于有两个正电荷(N端和 Lys),需考虑电荷变化点。
实际常用方法:
- 酸性残基数 = 1(Glu)+ C端 = 2 个酸性基团
- 碱性残基数 = 1(Lys)+ N端 = 2 个碱性基团
→ 属于"两性"多肽,净电荷为零时,pI 在中间两个 pKa 之间。
按排序:3.5, 4.3, 8.0, 10.5
净电荷变化:
- 在 pKa=4.3 后:--2(酸性)+2(碱性)= 0
- 在 pKa=8.0 后:--2 +1 = --1
所以净电荷为 0 的区间上限是 8.0,下限是 4.3。但严格来说,当有两个正电荷和两个负电荷时,pI 是中间两个 pKa 的平均值 ,即 (4.3 + 8.0)/2 = 6.15
实际软件(如 ExPASy ProtParam)会更精确计算,但手算常取中间两个相关 pKa 的平均。
例2:只含酸性氨基酸的多肽(如 Asp-Asp)
- 可电离基团:C端(pKa≈3.5)、两个 Asp 侧链(pKa≈3.9)
- 总共 3 个酸性基团,无碱性
- 净电荷始终 ≤ 0
- pI 出现在两个最低的 pKa 之间(因为要让一个基团质子化(0),其余去质子(--)以达到净 --1 和 0 的交界)
排序:3.5, 3.9, 3.9
净电荷:
- pH < 3.5:全质子,净 0
- 3.5--3.9:一个去质子,净 --1
→ 所以 pI 在 3.5 和 3.9 之间 → pI ≈ (3.5 + 3.9)/2 = 3.7
多肽等电点(pI)是其净电荷为零时的 pH 值,可通过识别使其正负电荷平衡的两个关键 pKa 并取平均来估算。对于复杂多肽,推荐使用专业软件进行精确计算。
手动计算适用于短肽,长肽或蛋白质建议使用软件:
- ExPASy ProtParam (https://web.expasy.org/protparam/)
- Compute pI/Mw tool
- Python 库 :如
biopython中的IsoelectricPoint模块 - EMBOSS pepstats
这些工具基于更完整的 pKa 数据集(如 DTASelect、Bjellqvist 或 EMBOSS 标准)并采用迭代算法求解净电荷为零的 pH。
等电点的深度理解
- 不同来源获得的 pKa 值略有差异(受微环境影响)
- 二硫键、修饰(磷酸化、乙酰化等)会影响 pI
- 多肽构象在极端 pH 下可能改变 pKa
- 等电点 ≠ 溶解度最低点(虽然通常接近)
二、Peptide-Tools等电点计算方法
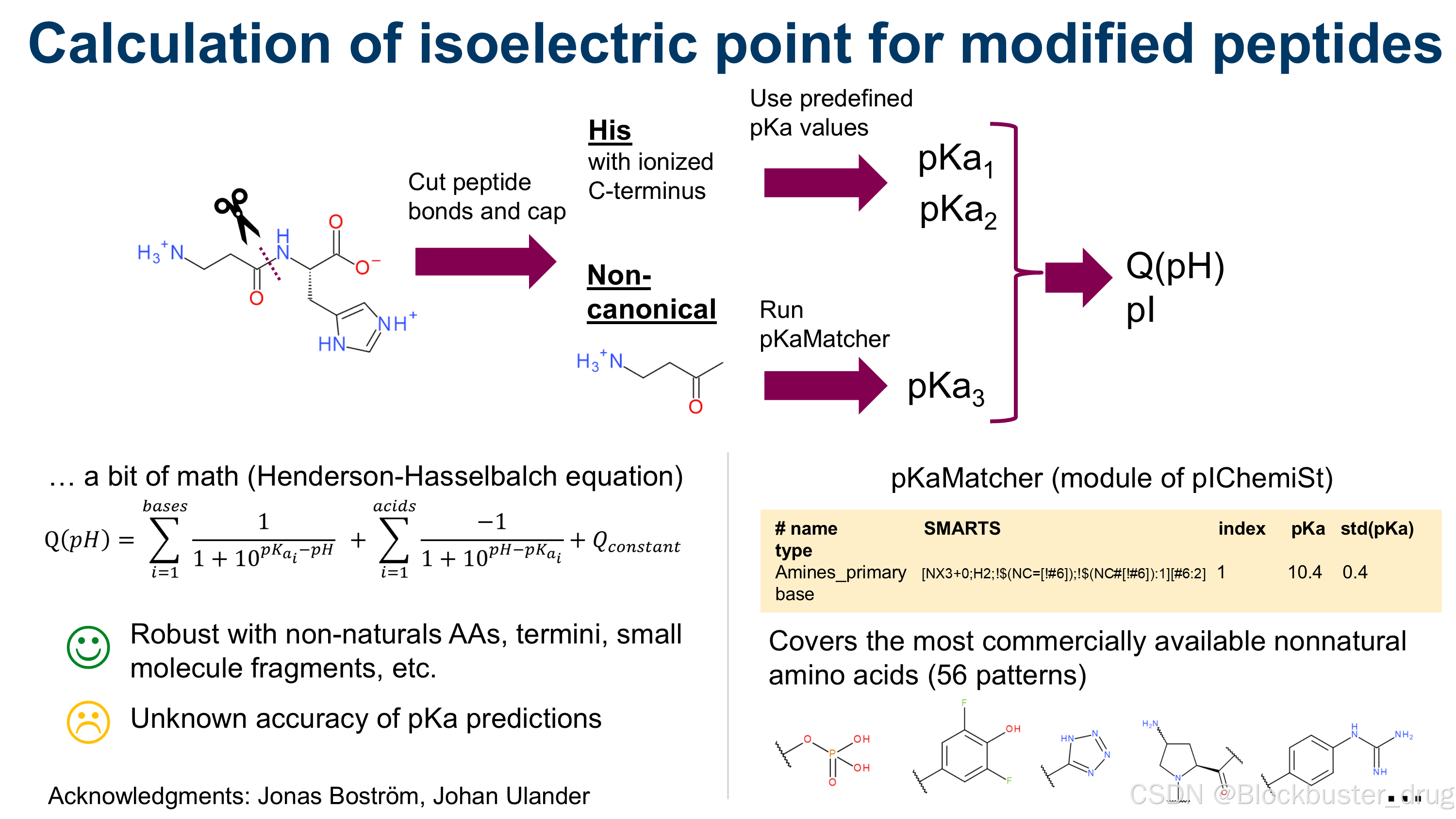
使用分子结构作为输入计算等电点
等电点使用 pIChemiSt 模块计算,该方法考虑了 nCAAs 对 pI、等电区间和电荷-pH 曲线的影响。有关该方法及其验证的详细信息可在文献中找到。
以下是该方法的工作原理概述:天然氨基酸侧链和可电离末端的电离参数在几组预定义的 pKa 表值中查找。使用的 pKa 数据集包括:IPC2_peptide、IPC_peptide、ProMoST、Gauci、Grimsley、Thurkill、Lehninger、Toseland。反过来,非天然氨基酸的可电离基团及其对应的 pKa 由 pKaMatcher 分配,该模块在 pIChemiSt 中作为默认的 pKa 预测器实现。该模块已通过验证,可覆盖制药应用中常用的 PTM 和 nCAAs。然后,根据 Henderson-Hasselbalch 方程,将所有可电离基团的表格化和计算出的 pKa 线性组合起来,以计算蛋白质或肽的电荷随 pH 的变化(公式 1)。
公式 1: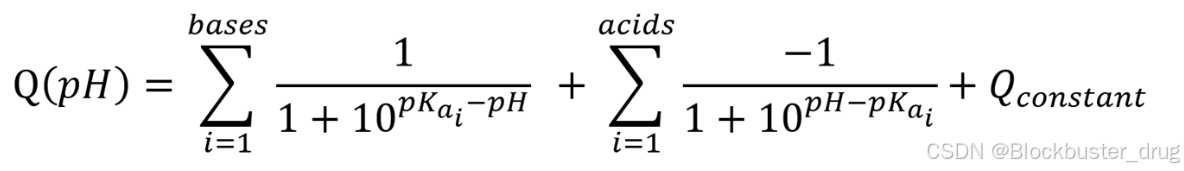
其中,两个求和分别遍历分子的所有碱性和酸性基团;pKai 是第 i 个碱性或酸性中心的电离常数的负对数值;Q_constant 代表与恒定电离的分子基团(如季铵盐或烷基吡啶鎓阳离子)相关的分子实体的永久电荷。pI 通过数值二分法确定净电荷为零时的 pH 值。
使用 FASTA 序列作为输入计算等电点
最新版本的 pIChemiSt 也支持 FASTA 作为输入。肽末端的电离状态可以在 Peptide-Tools 界面中设置为额外的输入参数。此外,服务器提供了一个选项,可以从计算中排除 Cys 侧链。
天然氨基酸的 pKa 数据集
我们使用与我们关于 pIChemiSt 的出版物中描述的相同的天然氨基酸 pKa 数据集。一些 pKa 数据集源自实验测量(Grimsley、Thurlkill、Toseland),一些是为了重现实验数据而构建的(IPC_Peptide 和 IPC_Protein 的两个版本),还有一些是通过将实验数据与 Hammett-Taft 推导的电子效应相结合而构建的(初始 Bjellqvist、扩展 Bjellqvist、Gauci)。还包括其他常用的数据集,尽管它们的来源无法从文献中推断(ProMoST、DTASelect、Rodwell、EMBOSS、Nozaki)。请注意,源自教科书(Lehninger、Solomons)的 pKa 值可能对应于通过电位滴定法得出的单个氨基酸的实验数据。
三、Peptide-Tools多肽性质预测的网络服务
Peptide-Tools网页操作页面(Peptide-Tools.com)
在功能上,该平台可以系统性地计算肽分子的等电点(pI)、不同 pH 条件下的电荷变化,并给出电荷--pH 曲线。同时,它还可预测 205、214 和 280 nm 三个常用波长下的摩尔消光系数,为肽溶液浓度测定和光谱实验提供重要参考。此外,Peptide-Tools 还内置了针对肽分子常见化学不稳定性风险的结构识别模块,可自动提示如去酰胺化、氧化、二硫键重排等潜在问题,对配方设计和稳定性研究具有实际指导意义。
Peptide-Tools是一个用于计算天然和修饰肽性质(包括其 pI)的网络服务器,该服务器通过集成我们之前在此期刊中描述的工具 pIChemiSt 来实现。我们实现了常见化学风险的结构警报,这些风险是制剂工作者在处理肽溶液时可能遇到的。此外,我们计算了在三个波长(280、214、205 nm)下的 MEC,这些波长常用于肽的表征。**值得注意的是,在预测 MEC 时目前会忽略 nCAAs。**该服务器支持常见的 2D 分子格式(MOL、SDF、SMILES)和 FASTA 序列表示。该工具在 2D 图上运行;3D 坐标目前被忽略。该服务器免费使用,代码在 Apache 2 许可下分发。
从使用体验上看,Peptide-Tools 既适合单条肽序列的快速交互式分析,也支持多分子批量计算并导出 CSV 或 SDF 文件,非常契合药物研发中的日常工作流程。

网络服务器计算等电点
输入
网络服务器实现了一个图形用户界面(GUI),支持多种输入格式。可以上传 SDF、CSV、SMILES 或 FASTA 格式的文件。否则,提供一个文本框,以便直接将 SDF、MOL、SMILES 或 FASTA 格式的数据粘贴到 Web 表单中。对于 FASTA 输入,GUI 还公开了复选框来配置肽末端的电离状态、一个用于输入系统中二硫键数量的选项,以及一个复选框,用于在计算中忽略剩余的 Cys 侧链巯基。当使用 SDF、MOL 或 SMILES 格式时,这些复选框将被忽略,因为相应的信息可以直接从结构中推导出来。服务器还支持多结构输入。
计算
Peptide-Tools 网络服务器的 GUI 构建在一个命令行界面(CLI)包装器之上,该包装器根据输入格式调用不同的计算。
输出
如果输入仅包含单个分子,服务器将直接在浏览器中显示结果(见图 2)。如果输入包含多个分子,服务器将提供一个链接以下载包含计算结果的文件。如果输入是 SDF,结果文件将是 SDF 格式;如果输入是 SMILES 或 FASTA,结果文件将是 CSV 格式。
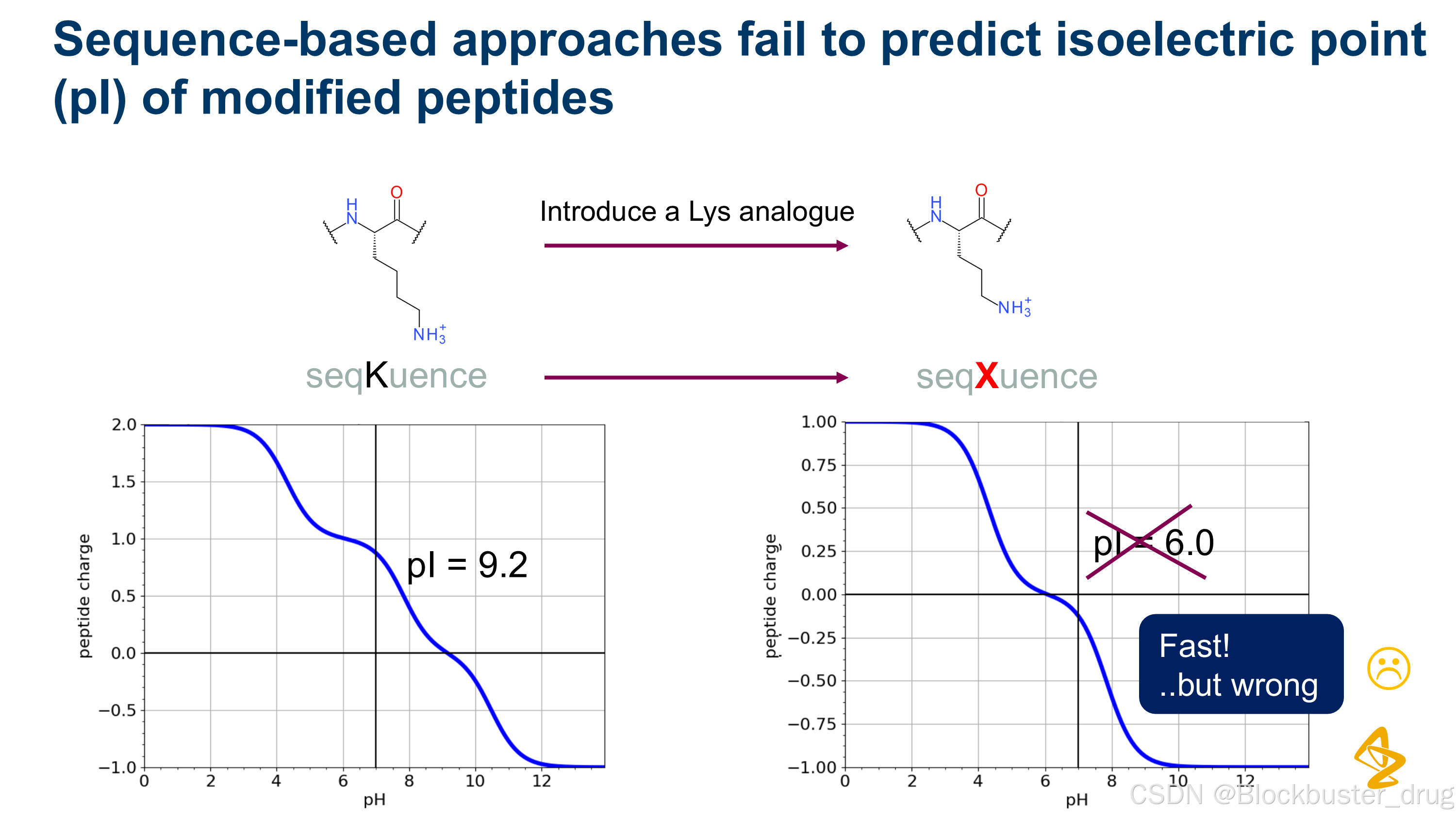
尽管社区对此有明确的需求,但可用于预测修饰肽性质的便捷工具仍然缺乏。大多数可用的网络服务都专注于天然氨基酸肽或蛋白质,有些支持常见的翻译后修饰(PTMs),只有少数扩展到有限的 nCAA 集合。在计算性质时,优选使用 MDL MOL 或 SMILES 等分子格式来表示化合物结构,因为与序列符号相比,它们保留了更高水平的细节。这在处理可电离的肽末端或非天然侧链时尤为重要,因为它们会显著影响肽的性质。HELM 或 BILN 是替代格式,但这些格式尚未被大多数化学工具包接受,并且需要定义单体数据才能正确表示修饰序列。
四、Peptide-Tools本地计算
工具 pIChemiSt 在 Apache 2.0 许可下发布,可通过阿斯利康的 GitHub 仓库访问:https://github.com/AstraZeneca/peptide-tools。
pIChemiSt本地安装:
-
下载
-
在conda环境中安装
conda create -n pichemist python=3.9
conda activate pichemist
pip install pichemist
或者,在本地编译安转:
cd peptide-tools/pIChemiSt
pip install .要使用ACD预测非天然氨基酸的pKa值,请确保有ACD license,相应的命令perceptabat是可执行的。
-
pIChemiSt使用
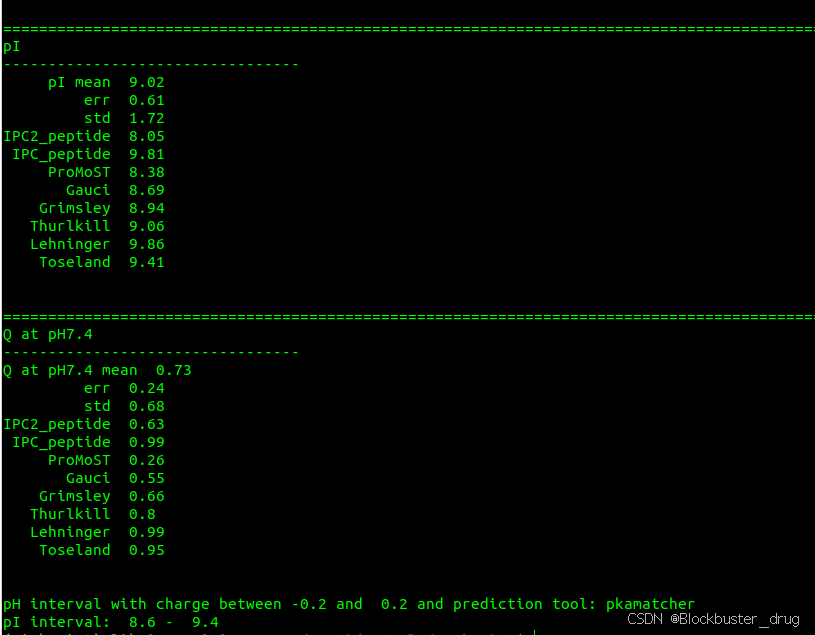
pichemist -i test/examples/payload_1.smi --method pkamatcher
结果显示:
bash
# 使用SMILES字符串作为输入
pichemist -i "N[C@@]([H])(CS)C(=O)N[C@@]([H])(CC(=O)N)C(=O)N[C@@]([H])(CS)C(=O)N[C@@]([H])(CC(=O)N)C(=O)O" -if smiles_stdin
# 使用SMILES字符串作为输入并输出JSON到控制台
pichemist -i "C([C@@H](C(=O)O)N)SSC[C@@H](C(=O)O)N" -if smiles_stdin -of json
# 使用FASTA格式作为输入
# 注意FASTA格式默认假设C端和N端是可电离的
pichemist -i "MNSERSDVTLY" -if fasta_stdin
# 使用封端处理的FASTA格式(即C端和N端不可电离)
# 可通过移除对应参数标志来调整配置
# 该配置也可用作"技巧":将环状肽以线性FASTA序列形式输入
# 因为其末端会被视为不可电离状态
pichemist -i "MNSERSDVTLY" -if fasta_stdin --ionizable_nterm false --ionizable_cterm false
# 使用SDF格式作为输入
pichemist -i test/examples/payload_4.sdf -if sdf
# 输出SDF格式
pichemist -i test/examples/payload_1.smi -o results.sdf -of sdf
# 输出JSON到控制台
pichemist -i test/examples/payload_1.smi -of json
# 绘制pH/电荷曲线图
pichemist -i test/examples/payload_1.smi --plot_ph_q_curve
# 绘制pH/电荷曲线图(使用自定义前缀'plot')
pichemist -i test/examples/payload_2.smi --plot_ph_q_curve -pp "plot"
# 打印片段pKa值
pichemist -i test/examples/payload_1.smi --print_fragment_pkas
# 使用ACD替代pKaMatcher
pichemist -i test/examples/payload_1.smi --method acd
# 使用ACD处理SMILES字符串
pichemist -i "NCCC(=O)N[C@@H](Cc1c[nH]cn1)C(=O)O" --method acd -if smiles_stdin
pIChemiSt主要能力
- 从任意2D化学结构(SMILES、SDF、FASTA)出发 ,自动识别并切割酰胺键,还原为氨基酸单体。
- 对每个单体:
- 若为天然氨基酸 → 从多个权威 pKa 数据集查表;
- 若为非天然氨基酸 → 使用:
- 内置 pKaMatcher(基于 SMARTS 模式匹配)
- 或商业工具 ACD/Percepta GALAS(需许可证)
- 计算:
- 等电点(pI):基于多个 pKa 数据集,输出均值、标准差、误差范围;
- pH = 7.4 时的净电荷(Q);
- pI 区间:定义为净电荷 ∈ --0.2, +0.2 的 pH 范围;
- pH--Q 曲线图(可选绘图);
- 各片段的 pKa 值(调试用)。
pIChemiSt支持的 pKa 数据集(天然氨基酸)
| 数据集名称 | 特点简述 |
|---|---|
IPC2_peptide |
专为肽链优化的最新 IPC 数据 |
IPC_peptide |
经典 IPC 肽 pKa 集 |
ProMoST |
适用于质谱模拟 |
Gauci |
实验测定值,偏酸性侧链校正 |
Rodwell |
教科书常用参考 |
Grimsley |
考虑微环境效应 |
Thurlkill |
高精度实验拟合 |
Solomon |
生物化学经典教材数据 |
Lehninger |
广泛使用的生化标准 |
EMBOSS |
生物信息学常用(如 ProtParam) |
Toseland |
新增高精度集(见论文) |
💡 优势 :不依赖单一 pKa 来源,而是集成多套参数 ,给出 pI 的不确定性估计(std/err),提升结果可靠性。
API(嵌入工作流)
from pichemist.api import pichemist_from_dict
result = pichemist_from_dict(input_dict, method="pkamatcher", ...)
print(result[1]['pI']['pI mean']) # 获取平均 pI何使用计算出的性质来促进肽类治疗药物优化的示例
a. 胰高血糖素类似物 :传统的胰高血糖素制剂在生理 pH 下溶解度低,需要在使用前立即用酸性水溶液(pH<3)重构干粉,这在紧急治疗严重低血糖时可能不切实际。胰高血糖素类似物(如 IUB7631 和 dasiglucagon)在生理 pH 下表现出显著改善的溶解度。这种改善在很大程度上是由于它们的等电点转移到了酸性范围。值得注意的是,dasiglucagon 可作为即用型自动注射笔使用,这在患者便利性和应急准备方面取得了重大进步。
b. 胰淀素类似物 :胰淀素受体的天然配体是肽,其特点是清除率高,并且有显著的形成淀粉样纤维的倾向。Kruse 等人证明,脂化作用改善了半衰期,但其系列化合物的溶解度、纤维化和化学稳定性仍然是问题。在进一步的多参数优化工作中,由于二硫键的化学稳定性和在中性和碱性 pH 下能最大限度地减少 Asn 残基的脱酰胺,因此更倾向于使用酸性制剂。因此,设计了一个新的化合物系列,其 pI 为中性或碱性,以确保在酸性 pH 下具有良好的溶解度和稳定性。这种方法积极影响了保质期,并有助于避免注射部位因沉淀引起的免疫反应。这项工作促成了长效胰淀素受体激动剂 cagrilintide 和 NN1213 的开发。
c. 阿斯利康内部项目:天然和修饰肽的自动化 pI 计算已整合到阿斯利康的多个项目中,以指导设计思路,旨在避免不溶性和聚集,并延长作用持续时间。这些计算对多个管线项目的进展产生了积极影响。
**Peptide-Tools/**pIChemiSt 技术亮点与创新
-
结构驱动而非序列驱动
不依赖 FASTA,可处理含非天然氨基酸、修饰、杂环、D-型氨基酸的复杂肽。
-
智能切割酰胺键
由 Jonas Boström 贡献的算法,能准确从 2D 结构中识别肽键并水解为残基。
-
SMARTS 模式匹配非天然残基
Johan Ulander 提出的策略,将未知结构映射到最相似天然氨基酸模板。
-
不确定性量化
报告 pI 的标准差和误差区间,避免"伪精确"。
-
开源 + 可扩展
支持开发者添加新 pKa 集或改进 pKaMatcher 规则。
五、pI 预测的局限性
pI 预测方法依赖于 Henderson-Hasselbalch 方程的线性组合,该方程假设分子内不同基团的电离状态是独立的。当可电离中心在序列中相距较远时,这种近似通常是有效的。
此外,pIChemiSt 模型并未完全考虑静电作用力、范德华力、其他非键合作用力或 3D 分子环境等因素,而这些因素都会显著影响 pKa 值。然而,通过使用源自实验数据的预定义 pKa 数据集,这些相互作用被间接捕获,从而使其影响能在预测中得到部分反映。
应谨慎执行基于 FASTA 的计算,因为序列表示法无法捕获肽末端或非天然氨基酸的电离信息。当化学修饰可能影响 pI 计算时,建议使用 MOL 或 SMILES 格式作为输入。
总结与结论
IChemiSt 的定位
pIChemiSt 是目前少有的、真正"结构感知"的等电点预测工具,突破了传统仅依赖氨基酸序列的限制,特别适用于:
- 合成肽药物(含非天然单元)
- 环肽、分支肽、修饰肽
- 计算化学与 AI 肽设计中的 pI 快速评估
- 需要误差估计的严谨科研场景
在本工作中,我们描述了 Peptide-Tools,这是一个用于预测天然和修饰肽等电点及其他相关性质的网络服务器。Peptide-Tools 相对于现有网络服务的主要优势在于集成了 pIChemiSt,当输入以 SDF、MOL 或 SMILES 格式提供的 2D 化学结构时,该工具会考虑非天然氨基酸(nCAAs)、非氨基酸片段和 PTMs 的贡献。该服务器还支持 FASTA 序列作为 pI 计算的输入。无论输入类型如何,服务器都会识别与所提供肽分子结构或序列相关的常见制剂化学稳定性风险。
缩写词
nCAAs: 非天然氨基酸
pI: 等电点
PT: 肽类治疗药物
PTM: 翻译后修饰
SI: 支持信息
参考文献
- 主论文 :
pIChemiSt: Structure-Based Isoelectric Point Prediction for Peptides and Proteins
J. Chem. Inf. Model. 2023, 63, 5, 1380--1390
DOI: 10.1021/acs.jcim.2c01261