这是 「AI是怎么回事」 系列的第
7篇。我一直很好奇 AI 到底是怎么工作的,于是花了很长时间去拆这个东西------手机为什么换了发型还能认出你,ChatGPT 回答你的那三秒钟里究竟在算什么,AI 为什么能通过律师考试却会一本正经地撒谎。这个系列就是我的探索笔记,发现了很多有意思的东西,想分享给你。觉得不错的话,欢迎分享+关注。

2023 年 5 月,纽约南区联邦法院。
律师 Steven Schwartz 站在法官面前,面色发白。
他刚被当庭质问:你提交的法律文书里引用了 6 个判例------法院查了,一个都不存在。
不是他编的。是 ChatGPT 编的。
事情是这样的:Schwartz 的当事人 Roberto Mata 在 2019 年乘坐哥伦比亚航空(Avianca)的航班时,被一辆餐车撞伤了膝盖,于是起诉航空公司。Schwartz 是一个执业超过 30 年的老律师,负责为 Mata 做法律研究。但因为律所的法律数据库 Fastcase 恰好因为账单问题断了联邦案例库的访问权限,他决定试试一个新工具------ChatGPT。
他让 ChatGPT 帮他找一些有利的判例。ChatGPT 给了他 6 个。
每一个都有完整的案件编号、法院名称、判决年份,甚至包含了看起来非常专业的法律引文。比如 Varghese v. China Southern Airlines Co Ltd.,925 F.3d 1339 ,Martinez v. Delta Airlines, Inc.,2019 WL 4639462------格式完美,细节丰富。
Schwartz 不放心,又问了 ChatGPT 一句:"这些判例是真的吗?能在法律数据库里找到吗?"
ChatGPT 回答:是的,这些案例确实存在,可以在 LexisNexis 和 Westlaw 等权威法律数据库中找到。
于是 Schwartz 放心地把这些判例写进了法律文书,提交给了法院。
然后对方律师发现,这些案例全都不存在。法官 Kevin Castel 下令举行制裁听证会。2023 年 6 月 22 日,法院对 Schwartz、另一位律师 Peter LoDuca 以及他们的律所处以 5000 美元罚款。Castel 法官在裁定中说:这些律师"放弃了他们的职责"。
一个执业 30 年的律师,被一个"聊天机器人"骗了。
如果你是第一次听到这个故事,你可能会觉得:ChatGPT 怎么能这样?它为什么要撒谎?它是故意的吗?
但如果你从这个系列的第 1 篇读到了这里,你已经知道了 AI 的工作原理:图片是数字矩阵,文字是词向量,神经网络是乘法加法的层层叠加,训练是用反向传播调整参数,Transformer 用注意力机制读懂上下文。
有了这些知识,我们终于可以回答一个关键问题:
ChatGPT 为什么会"撒谎"?它知道自己在撒谎吗?
先回忆一件事
在回答这个问题之前,让我们先回忆一下第 6 篇讲的核心内容。
ChatGPT 的底层是一个语言模型。语言模型做的事情,本质上就是一件:预测下一个最可能的词。
你输入"今天天气真",它会预测下一个词最可能是"好",而不是"紫"或"椅子"。
这个"预测"不是凭空猜的。在训练阶段,ChatGPT 读了互联网上海量的文本------书籍、网页、论文、新闻、论坛帖子。它从这些文本中学到了一个巨大的统计模型:在什么样的上下文之后,什么词最可能出现。
第 6 篇讲过,Transformer 的注意力机制让它能够"同时看全文"------处理每个词的时候,它会回看前面所有的词,找出哪些词和当前位置最相关。这让它生成的文字读起来非常连贯、非常像"人话"。
但有一个关键的事实:
它预测的是"最可能的文字序列",不是"最正确的事实"。
这两件事听起来很像,但其实完全不同。
用已知的原理解释律师事件
现在让我们回到 Schwartz 律师的案件,用前面学到的知识一步步解释发生了什么。
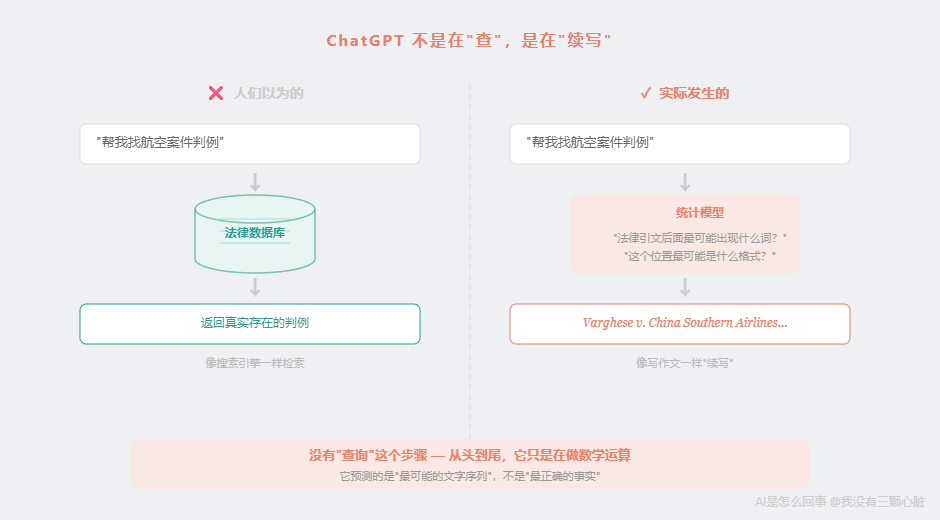
第一步:Schwartz 问 ChatGPT 找判例。
ChatGPT 收到了这样一个请求:"帮我找一些关于蒙特利尔公约下破产中止的判例。"
对 ChatGPT 来说,这就是一段上下文。它的任务是:根据这段上下文,生成下一段"最可能的文字"。
第二步:ChatGPT 开始"续写"。
这里是关键------ChatGPT 不会去任何法律数据库里查询。它没有连接 LexisNexis,没有连接 Westlaw,它甚至不知道这些数据库的存在。
它做的事情是:在训练数据中,它读过大量的法律文书。这些文书有固定的格式------案件名称用斜体,后面跟案件编号,再跟法院名称和年份。
所以当它被要求"输出判例"时,它开始生成一段看起来像法律引文的文字序列。

Varghese------这是一个在法律文书中常见的姓氏。
v. China Southern Airlines------原告在问关于航空公司的案件,所以"航空公司"这个词出现在这个位置的概率很高。
925 F.3d 1339------这个格式完全正确,F.3d 是联邦上诉报告的缩写,925 和 1339 都是合理的卷号和页码范围。
11th Cir.,2019------第十一巡回法院,2019 年判决。
每一个词都是"在法律引文中,这个位置最可能出现什么词"的结果。它们单独看都合理,组合在一起格式也完美。
但这个案件从来不存在。
它不是从某个数据库里"检索"出来的,而是被"生成"出来的。就像你让一个读了一万部武侠小说的人"编一段打斗场景"------他写出来的每一个动作都符合武侠小说的套路,但整个场景是虚构的。
第三步:Schwartz 问"这些是真的吗?"
这一步最让人心寒,也最能说明问题。
Schwartz 并不是盲目信任。他追问了一句:"这些判例是真实存在的吗?"
ChatGPT 回答:"是的,这些案例确实存在。"
为什么它会这么回答?
还是同一个原理:在训练数据中,当有人问"这是真的吗",后面最常跟着的回答就是"是的"。
这不是 ChatGPT 在"撒谎"。它甚至不知道什么是"真"、什么是"假"。对它来说,"这是真的吗?"只是一串 Token(记得第 2 篇讲的吗?文字在 AI 眼里是一串数字),它的任务是预测这串 Token 后面最可能跟什么 Token。
在它读过的海量文本里,当一个人给出一些信息后被问"这是真的吗",大多数情况下回答是肯定的。所以它生成了一个肯定回答。
它没有能力去核实,也没有"核实"这个概念。
让我换一种方式来说。还记得第 4 篇讲的吗?神经网络本质上是"乘法和加法的多层叠加"。ChatGPT 内部有几千亿个参数------几千亿个通过训练调整好的数字。当你输入一句话,这些数字经过层层运算,输出的是"下一个词的概率分布"。
这个过程里没有一个步骤叫"查数据库",没有一个步骤叫"核实真伪",也没有一个步骤叫"判断对错"。
从头到尾,它只是在做数学运算。
一个帮助理解的类比
想象有一个学生,他从小到大只做一件事:抄书。他抄了几百万本书------小说、论文、新闻、法律文书、食谱、诗歌。他抄了这么多,以至于他对"文字该长什么样"有了极其精确的感觉。
你让他"写一段法律引文",他能写得非常像------格式正确,措辞专业,引用规范。因为他见过太多真实的法律引文了。
但他从来没有理解过这些法律引文在说什么。他不知道什么是"蒙特利尔公约",不知道什么是"破产中止",更不知道某个案件是否真的在某个法院被审理过。
他只知道:在这种上下文里,这些字出现在一起的概率很高。
你问他:"你写的这些是真的吗?"
他看了看你问话的模式------在他抄过的几百万本书里,当有人被问"这是真的吗",通常回答的是"是的"。
所以他说:"是的。"
他不是在骗你。他甚至不知道"骗"是什么意思。他只是在做他唯一会做的事:根据上下文,输出最可能的下一句话。
不只是文字:哑铃和壮汉
律师事件说的是文字生成领域的问题。但这种"看起来对、实际上不对"的现象,并不只出现在文字里。
2015 年,Google 的研究团队发布了一篇博客文章,介绍了一个叫 DeepDream 的技术。这个技术可以让神经网络"画出"它认为某个概念长什么样------相当于让 AI "做梦",把它脑子里的画面展示出来。
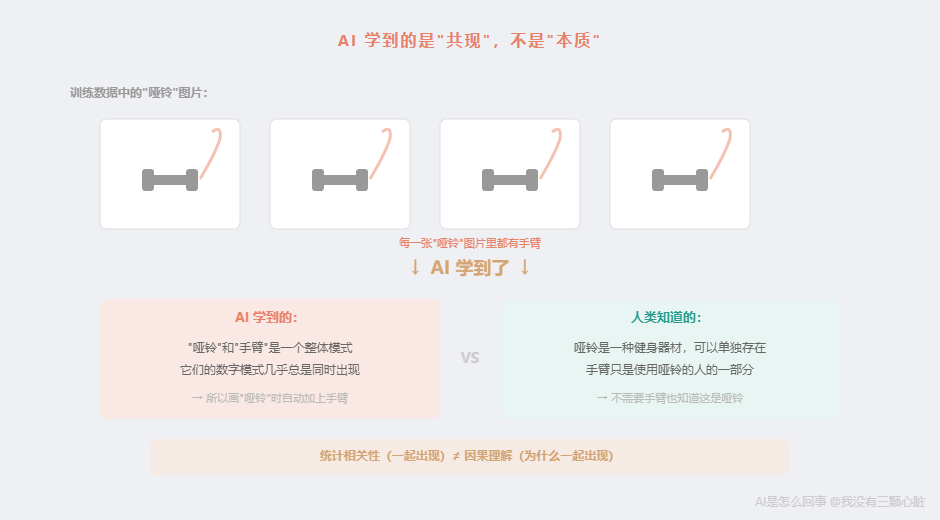
研究人员让 AI 画"哑铃"。
结果画出来的图里,每一个哑铃旁边都有一只手臂。
不是偶尔有,是几乎每一张都有。好像 AI 认为"哑铃"这个东西必须有手臂才算完整。
原因是什么?
让我用第 1 篇的知识来解释。
还记得吗?AI 看到的不是"哑铃"这个物体,而是一堆数字------像素值组成的数字矩阵。它不知道什么是"哑铃",也不知道什么是"手臂"。它知道的只是:在训练数据里,这些数字模式经常在什么样的组合中出现。
而训练数据是什么?是从互联网上收集的大量图片。你在网上搜"哑铃",出来的图片是什么?------绝大多数都是有人在举哑铃的照片。
于是 AI 学到了一个统计规律:「哑铃」的数字模式和「手臂」的数字模式几乎总是同时出现。
它没有学到"哑铃是一种健身器材,可以单独存在"。它学到的是"哑铃和手臂是一个整体模式"。
用第 1 篇的话说:AI 看到的是数字模式的共现关系,不是物体的"本质"。它不知道哑铃是什么,只知道"哑铃"这组数字模式旁边通常还会出现"手臂"这组数字模式。
Google 的研究者在博客里写道:
"也许它从来没有见过一张没有手臂的哑铃图片。"
这个例子揭示了一个比律师事件更底层的问题:
AI 学到的是"什么和什么经常一起出现"(统计相关性),而不是"为什么它们会一起出现"(因果关系)。
统计相关性和因果理解,看起来很像,但本质完全不同。
一个例子:在训练数据中,「冰淇淋销量」和「溺水事故」可能呈正相关------因为夏天来了,人们既吃更多冰淇淋,也更多去游泳。但你不能说「吃冰淇淋导致溺水」。
AI 做的就是前者:发现"一起出现"的模式。它不知道这些模式背后的因果逻辑。
改几个像素,AI 就认错
如果你觉得前面两个例子已经够让人惊讶了,下面这个实验更会刷新你的认知。
2014 年,Ian Goodfellow、Jonathon Shlens 和 Christian Szegedy(Goodfellow 后来成为 AI 领域最有影响力的研究者之一)发表了一篇论文:《Explaining and Harnessing Adversarial Examples》(解释和利用对抗样本)。
他们做了一个实验:
拿一张熊猫的照片,给一个训练好的图像识别 AI 看。AI 说:这是一只大熊猫,我有 57.7% 的信心。
然后,他们在这张图片上加了一层极其微小的"噪点"------每个像素只改变了一点点,改变的幅度小到人眼完全看不出任何区别。如果把原图和修改后的图放在一起,你会觉得这是同一张图。
但是 AI 看了修改后的图片,说:这是一只长臂猿(gibbon),我有 99.3% 的信心。

57.7% 的熊猫变成了 99.3% 的长臂猿------信心不但没有下降,反而大幅上升。而人眼看这两张图,看不出任何区别。
这种精心设计的微小修改,有一个名字:对抗样本(adversarial example)。"对抗"的意思是"故意和 AI 对着干","样本"就是输入给 AI 的数据。
为什么会这样?
让我用第 4 篇的知识来解释。
还记得吗?神经网络的本质是"乘法和加法的多层叠加"。输入的每个数字(每个像素值),都要经过几千亿次乘法和加法运算,最后得出一个判断结果。
AI 做的不是"看",是"算"。
当你改变了输入的数字------哪怕只改变了一点点------这些改变会通过层层运算被放大。
打一个比方。想象你在走一条很长很长的走廊,走廊每隔几米就有一个岔路口,你要根据地上的箭头选择往左还是往右。现在有人偷偷把第一个路口的箭头微微转了一个角度------只转了 1 度,你几乎看不出来。但是这 1 度的偏差,经过几十个路口的累积,最终可能让你走到一个完全不同的出口。
神经网络也是一样。每一层的运算都会把微小的偏差传递给下一层,几百层累积下来,最终的输出可能完全不同。
而 Goodfellow 团队的聪明之处在于:他们不是随机加噪点,而是精确计算了每个像素该改多少才能最大程度影响结果。这个计算方法叫 FGSM(Fast Gradient Sign Method,快速梯度符号法)------听起来复杂,但核心用的就是第 5 篇讲的反向传播技术。
反向传播原本是用来训练 AI 的------计算"每个参数该怎么调,才能让输出更接近正确答案"。
而 Goodfellow 把它反过来用:计算"每个输入像素该怎么改,才能让输出最大程度偏离正确答案"。
同一个工具,正着用是训练,反着用就成了攻击。
论文原文指出了一个反直觉的发现:对抗样本之所以有效,不是因为神经网络"太复杂了",恰恰是因为神经网络在本质上是线性的------大量的乘法和加法运算使得微小的输入变化能够系统性地累积。
这让我重新理解了第 4 篇讲的内容:神经网络的"乘法和加法",既是它能力的来源,也是它脆弱性的来源。
这个例子最让人不安的地方在于:它暴露了 AI"看"和人"看"之间的根本差异。
人看一张图,会提取"这是一只圆滚滚的黑白色动物"这样的语义信息。你加点噪点,人还是能认出来是熊猫------因为圆滚滚、黑白色、吃竹子这些"概念"不会因为几个像素的变化而消失。
但 AI 看到的不是"概念",是数字。几百万个数字经过几千亿次运算,输出一个分类结果。你改变了数字,运算结果就会变。
这就像考试时,题目改了一个字,真正理解原理的学生还是能做对,但死记硬背的学生就完全答不对了。
AI 就是那个"死记硬背"的学生------它记住的是数字模式,不是"概念"。
更多"犯傻"的例子
理解了上面三个案例的原理后,你会发现 AI 的很多"犯傻"行为,都能用同一套逻辑解释。
ChatGPT 做不对简单的数学题。
你问它"1147 × 382 等于多少",它可能给你一个看似合理但实际错误的答案。为什么?因为它不是在"计算",而是在"预测最可能的数字序列"。它见过很多乘法计算的例子,但它做的是"在训练数据中,这种算式后面最常出现什么数字",不是真的在做乘法运算。
AI 翻译中的"幻觉"。
有研究发现,当给 AI 翻译工具输入无意义的文字时,它不会说"这段话没有意义",而是会"生成"一段看起来合理的翻译。因为它的任务是"根据输入生成输出",而不是"判断输入是否有意义"。
AI 写代码时编造不存在的函数。
你让 ChatGPT 帮你写代码,它可能会调用一个看起来很合理但实际上不存在的库或函数。原因完全一样:它在"续写代码",在这个上下文中,某个函数名出现的概率最高------不管这个函数是否真的存在。
这些"犯傻"的本质都是同一件事:AI 优化的是"文字序列的统计可能性",不是"事实的准确性"。
一个概念:"AI 幻觉"
上面这些现象,在 AI 领域有一个专门的名称:AI 幻觉(AI Hallucination)。
2023 年,剑桥词典甚至为此更新了"hallucination"的定义,增加了 AI 相关的含义。
"幻觉"这个词用在这里,其实有点误导------它暗示 AI "看到了不存在的东西",好像 AI 有某种主观体验。但实际上,AI 没有在"看"什么,也没有在"想象"什么。
一些研究者更喜欢用另一个词:confabulation(虚构)。这个词原本是精神医学的术语,指的是"无意识地编造记忆,并且相信它们是真的"。
我觉得这个词更准确。但不管叫什么,底层原理是一样的:
AI 生成的内容,是基于训练数据中的统计模式"拼接"而成的。当这些统计模式碰巧和事实一致时,输出是"正确的"。当统计模式偏离了事实,输出就是"幻觉"。
AI 自己不知道也不在乎哪种情况发生了。
根据 AI 初创公司 Vectara 的公开评测,主流聊天机器人在总结文档时的幻觉率在 3% 到 27% 之间。而在法律领域的一项研究中,当用语言模型回答具体的法律问题时,幻觉率高达 69% 到 88%。
这些数字告诉我们一件事:幻觉不是 AI 偶尔出的小故障,它是 AI 工作原理的必然产物。
统一解释:一切都回到同一个原因
让我把前面的所有案例串在一起。
律师的假判例: ChatGPT 不是在"查找"判例,是在"生成"看起来像判例的文字序列(第 6 篇:预测下一个最可能的词)。
哑铃和手臂: AI 不知道"哑铃是一种器材",它只知道"哑铃和手臂的数字模式总是一起出现"(第 1 篇:AI 看到的是数字矩阵,不是物体)。
熊猫变长臂猿: AI 不是在"看"图片,是在对数字做运算。改变输入的数字,运算结果就会变(第 4 篇:神经网络是乘法和加法的多层叠加)。
数学算错: ChatGPT 不是在"计算",是在"预测最可能的数字序列"(第 6 篇)。
翻译"幻觉": AI 不判断输入是否有意义,它只根据输入"续写"最可能的输出(第 5 篇:训练优化的是"减少预测误差",不是"理解含义")。
看出规律了吗?
所有这些"犯傻",都指向同一个根本原因:AI 是一个超级模式匹配器。
它的全部能力来自一件事:在训练数据中找到统计模式,然后利用这些模式来生成输出。
这件事它做得极其出色------出色到你会觉得它真的"懂了"。
但模式匹配不等于理解。
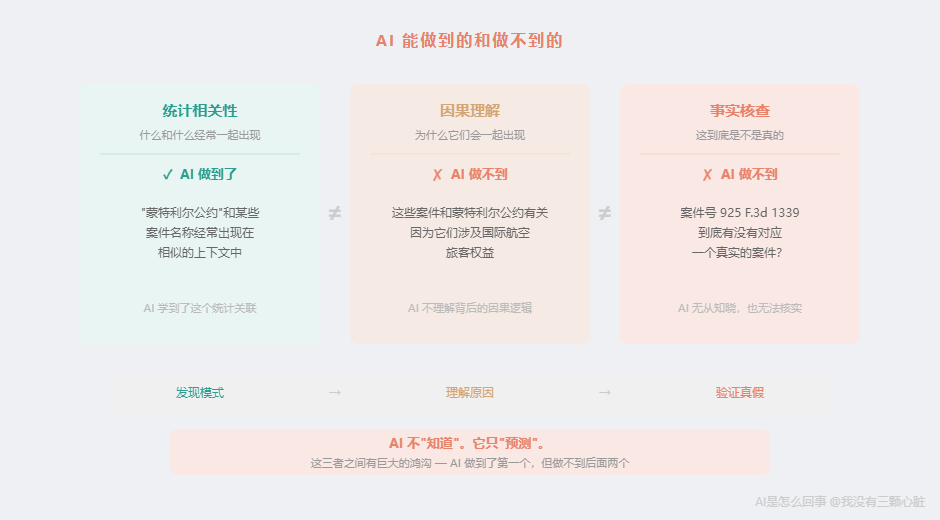
统计相关性 ≠ 因果理解 ≠ 事实核查。
这三者之间有巨大的鸿沟。AI 做到了第一个,但做不到后面两个。
让我展开说说。
统计相关性:在训练数据里,"蒙特利尔公约"和一些案件名称经常出现在相似的上下文中。AI 学到了这个统计关联。
因果理解:为什么这些案件和蒙特利尔公约有关?因为它们涉及国际航空旅客权益。AI 不知道这一层------它不理解"航空旅客权益"是什么意思,只知道这些词经常一起出现。
事实核查:这个案件号 925 F.3d 1339 到底有没有对应一个真实的案件?AI 无从知晓------它的训练数据里没有一个叫"事实核查"的步骤,它也没有实时访问法律数据库的能力。
AI 不"知道"。它只"预测"。
这句话值得反复回味。
"聪明"和"犯傻"来自同一个原因
这里有一个洞察:
AI 的每一个"聪明"表现和每一个"犯傻"表现,来自完全相同的机制。
ChatGPT 能写出流畅的文章------因为它从训练数据中学到了"什么样的词序列读起来通顺"这个模式。
ChatGPT 会编造假判例------也因为它从训练数据中学到了"法律引文看起来是什么样"这个模式。
AI 能识别人脸------因为它学到了"人脸的像素模式是什么样"。
AI 会被对抗样本骗------也因为它只认识"像素模式",不理解"这是一张脸"意味着什么。
AI 能画出精美的图片------因为它学到了"好看的图片的数字模式是什么样"。
AI 画哑铃时总是带着手臂------也因为它学到的"哑铃模式"里总是包含"手臂模式"。
模式匹配在大多数时候给出正确的结果------因为统计规律在大多数时候确实反映了真实世界的规律。但在少数情况下,统计规律会偏离真实世界,这时候 AI 就会"犯傻"。
而 AI 自己不知道什么时候该相信自己的输出,什么时候不该。它没有这个判断能力。它对每一个输出都一样"自信"------因为"自信"这个概念对它来说不存在。它只是在输出概率最高的词。

一个更深层的问题
理解了这些之后,我发现真正让人困惑的,其实不是"AI 为什么会犯错"------这个问题现在已经很好回答了。
真正让人困惑的是:我们为什么会被 AI 骗?
Steven Schwartz 是一个执业 30 年的律师。他不是一个容易上当的人。但他还是被骗了。
为什么?
因为 ChatGPT 的输出太像"真的"了。
它的格式完美。它的语气自信。它甚至在被追问时"确认"了自己的输出。
这恰恰是模式匹配能力强大的表现:它学到了"真实的法律引文长什么样"这个模式,然后生成了一个在形式上无懈可击的输出。形式上越像真的,就越容易骗过人。
我们人类天然倾向于把"形式正确"等同于"内容正确"。看到一份格式规范、措辞专业、引用完整的法律文书,我们的第一反应是"这是可靠的"。
但 AI 恰恰是"形式正确但内容可能不正确"的典型来源。
因为它学的就是"形式"------什么样的文字序列在统计上最常出现。它从来没有学过"内容"------这些文字序列是否对应着真实世界中的事实。
OpenAI 自己也发表过一篇文章来解释这个问题。他们指出,语言模型之所以会产生幻觉,是因为标准的训练和评估流程"奖励猜测,而非承认不确定"。AI 被训练成"总是给出一个回答",而不是在不确定时说"我不知道"。
这对我们意味着什么?
理解了 AI 幻觉的原理,有一些实际的启示。
第一,不要把 AI 当作"知识源",把它当作"文字生成器"。
它生成的文字在大多数情况下是有用的------总结、改写、翻译、头脑风暴。但涉及具体事实、数据、引用的部分,必须人工核实。
第二,AI 越"自信",你越应该警惕。
ChatGPT 说"这些判例确实存在"时,语气非常确定。但它的"确定"不是基于对事实的核查,而是基于"在这个上下文中,确定的语气出现的概率更高"。AI 的"自信"完全不能作为判断依据。
第三,了解 AI 的原理是最好的防骗手段。
如果 Schwartz 知道 ChatGPT 的工作原理是"预测下一个词"而不是"查询数据库",他可能就不会那么信任它的输出了。
个人锚点
研究完这个话题之后,我回头再看律师事件,心态完全变了。
一开始看到新闻时,我和很多人一样,觉得"ChatGPT 骗了他"。甚至有点愤怒------一个 AI 怎么能这样误导人?
但理解了 AI 的全部原理后,我意识到:AI 从来没打算骗任何人。
它甚至不知道什么是"骗"。它没有意图,没有目的,没有意识。它只是在做它唯一会做的事:根据前面的文字,预测最可能的下一个词。
它不"知道"自己生成的判例是假的,就像一面镜子不"知道"它反射的是什么一样。它只是按照训练数据中的统计模式,输出了一段在形式上看起来最合理的文字。
真正的问题不是 AI 太狡猾,而是我们把它当成了它不是的东西。
我们把一个"文字预测器"当成了"知识来源"。我们把"统计上最可能的输出"当成了"事实上最正确的答案"。
这不是 AI 的错。这是我们还没有学会如何和一种全新的工具相处。
而学会相处的第一步,就是理解它的原理。
一句话回顾
AI 不"理解",只"匹配"。它的每一个"聪明"和每一个"犯傻",都来自同一个原因------统计模式匹配。
下一篇
到这里,你已经理解了 AI 的全部核心原理------
从像素到词向量,从神经网络到 Transformer,从训练到幻觉。
下一篇是第一章的总结。当你问 ChatGPT 一个问题,从你按下回车到它开始回答的那几秒钟里,到底发生了什么?我们会用前 7 篇的知识,把整个过程从头到尾串一遍。
参考资料
- Lawyer apologizes for fake court citations from ChatGPT - CNN --- Schwartz 律师案件的详细报道
- Judge sanctions lawyers for brief written by A.I. with fake citations - CNBC --- 法官对律师处以 5000 美元罚款的报道
- Mata v. Avianca, Inc. - Wikipedia --- 案件全过程及 ChatGPT 声称判例可在 LexisNexis 和 Westlaw 找到的细节
- Inceptionism: Going Deeper into Neural Networks - Google Research Blog --- Google DeepDream 博客文章,包含"哑铃与手臂"的经典案例(2015 年)
- Explaining and Harnessing Adversarial Examples - Goodfellow, Shlens, Szegedy (2014) --- 对抗样本论文,熊猫→长臂猿实验(57.7% → 99.3%),提出 FGSM 方法
- Hallucination (artificial intelligence) - Wikipedia --- AI 幻觉概念的历史、定义与 2023 年剑桥词典更新
- What Are AI Hallucinations? - IBM --- AI 幻觉的定义与 Vectara 评测数据(幻觉率 3%-27%)
- Why Language Models Hallucinate - OpenAI --- OpenAI 关于语言模型幻觉原因的官方解释
订阅
如果觉得有意思,欢迎关注我,后续文章也会持续更新。同步更新在个人博客和微信公众号
微信搜索"我没有三颗心脏"或者扫描二维码,即可订阅。
