基于 Spring Boot +Vue+ 通义千问的通用 AI 图像识别引擎设计与实现
作者:HUI4412
发布时间:2026-02-28
技术栈:Spring Boot | RestTemplate | 通义千问 VL | 多模态 AI
📖 前言
数字化转型卷到飞起的当下,每个开发者都在琢磨:咋用 AI 把打工人从重复劳动里解放出来?最近我就整了个实用活儿 ------上传专利证书图片,AI 自动扒关键信息填表单,主打一个 "解放双手,告别手敲"。
虽说大部分代码都是 AI 搭把手写的,但整个架构设计和工程化踩坑的过程,属实让我涨了不少经验。今天就把这个通用识别引擎的实现思路掰开揉碎讲讲,希望能给各位工友来点灵感~
🎯 项目背景
业务需求
搞科技创新管理系统的都懂,专利、著作权这些信息录入简直是 "职场酷刑":
- ❌ 手动录入慢到抠脚,还动不动输错
- ❌ 字段多到记不住,漏填一个就得返工
- ❌ 重复干活磨心态,纯纯浪费打工人时间
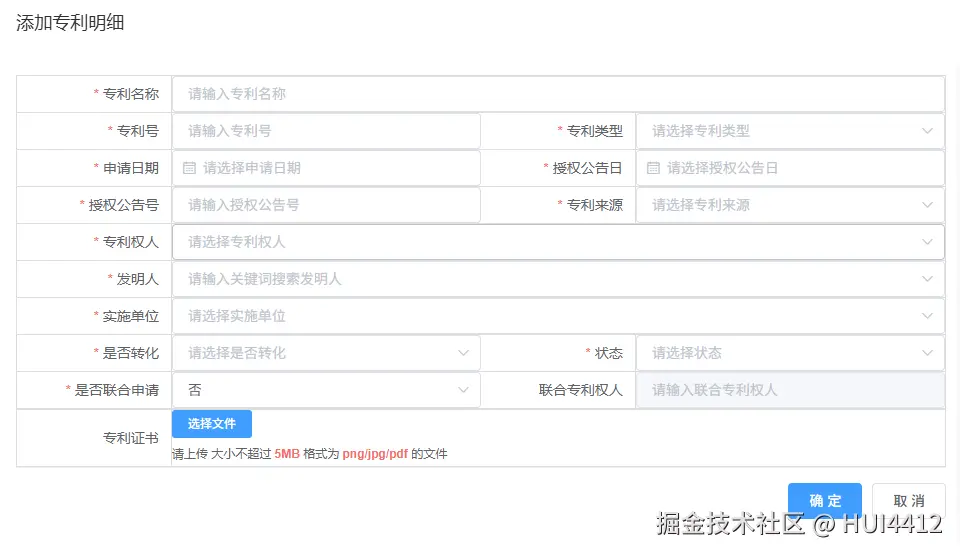
解决方案
咱直接搬出通义千问的多模态视觉模型(qwen3-vl-plus),主打一个 "机器代劳":
- ✅ 用户咔咔上传证书图片
- ✅ AI 火眼金睛识别关键字段
- ✅ 乖乖返回结构化数据
- ✅ 前端自动填表单,主打一个丝滑
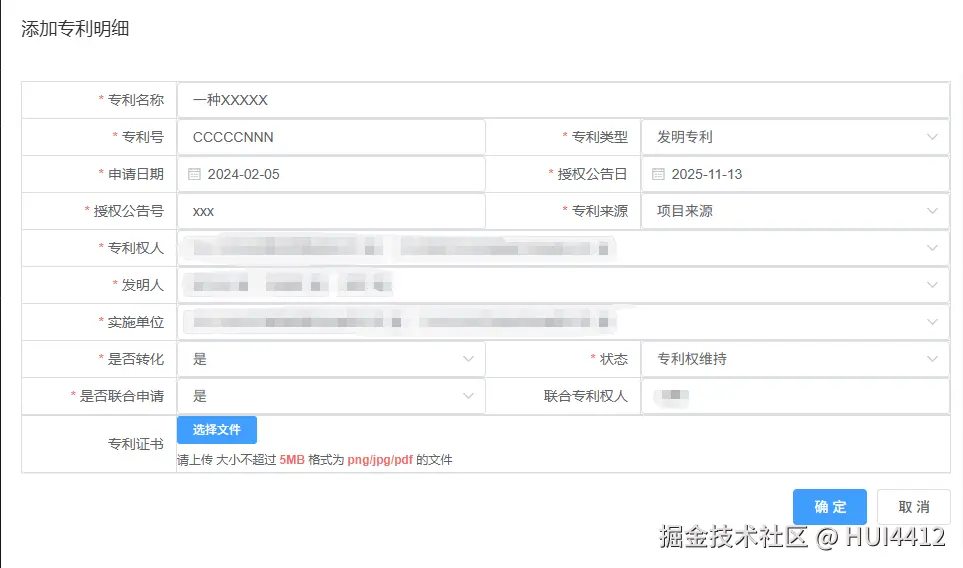
🏗️ 系统架构设计
整体架构图
plaintext
┌─────────────────────────────────────────────────────────┐
│ 前端层 │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 图片上传 │ → │ 结果展示 │ → │ 表单绑定 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 后端层 │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Controller │ → │ Service │ → │ 识别引擎 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ AI 服务层 │
│ ┌─────────────────────────────────────────────────┐ │
│ │ 通义千问 DashScope API (qwen3-vl-plus) │ │
│ └─────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘模块结构
plaintext
com.ls.qwen/
├── config/
│ └── QwenRestTemplateConfig.java # HTTP 客户端配置
└── VisionRecognitionEngine.java # 核心识别引擎设计理念:
- 配置与业务分家:HTTP 客户端单独配置,不跟业务代码搅和
- 通用 + 定制两手抓:引擎搞通用的,业务层只需要改改提示词就行
💻 后端核心实现
1. 专用 HTTP 客户端配置
AI 识别这活儿耗时长,得单独配超时时间,不然容易 "半路夭折":
java
@Slf4j
@Configuration
public class QwenRestTemplateConfig {
@Bean("qwenRestTemplate")
public RestTemplate qwenRestTemplate() {
log.info("初始化 qwenRestTemplate Bean...");
SimpleClientHttpRequestFactory factory = new SimpleClientHttpRequestFactory();
factory.setConnectTimeout(10000); // 连接超时 10 秒,够它喘口气了
factory.setReadTimeout(30000); // 读取超时 30 秒,给AI留足思考时间
log.info("qwenRestTemplate 初始化完成");
return new RestTemplate(factory);
}
}为啥要单独整个 RestTemplate?
- AI 请求又传图片又推理,耗时比普通接口久多了
- 用系统默认配置容易超时,白忙活一场
- 不同业务的 HTTP 客户端隔离开,出问题也好定位
2. 通用视觉识别引擎
这玩意儿就是整个模块的 "主心骨",抽象得明明白白,啥场景都能凑合用。
2.1 类结构
java
@Slf4j
@Component
public class VisionRecognitionEngine {
// 配置注入,不用硬编码,改配置文件就行
@Value("${dashscope.api-key}")
private String apiKey;
@Value("${dashscope.url}")
private String apiUrl;
@Value("${dashscope.model}")
private String model;
// 依赖注入,省心又好测
private final RestTemplate restTemplate;
private final ObjectMapper objectMapper = new ObjectMapper();
}2.2 核心处理流程(四步走,不绕弯)
plaintext
上传文件 → 校验(防乱传) → Base64 编码(AI认这格式) → 调用 API → 解析响应 → 返回结果2.3 统一接口设计
java
/**
* 通用识别方法(所有业务复用,主打一个偷懒)
* @param file 上传图片
* @param prompt 业务层传入的提示词
* @param requiredFields 业务字段列表
* @return 识别结果 Map
*/
public Map<String, String> recognize(
MultipartFile file,
String prompt,
List<String> requiredFields
) throws Exception {
validateFile(file);
String base64Image = Base64.getEncoder().encodeToString(file.getBytes());
String apiResponse = callDashScopeApi(base64Image, prompt);
return parseAndNormalize(apiResponse, requiredFields);
}设计精髓:
- ✅ 变与不变拎得清:流程固定死,提示词和字段按需改
- ✅ 业务层零重复:不管是识别专利、著作权还是标准,都用这一套逻辑,不用重复造轮子
2.4 文件校验机制
先把 "妖魔鬼怪" 挡在门外,省得后面出幺蛾子:
java
private void validateFile(MultipartFile file) {
if (file == null || file.isEmpty()) {
throw new IllegalArgumentException("图片不能为空!传个空文件逗我呢?");
}
if (file.getSize() > 10 * 1024 * 1024) {
throw new IllegalArgumentException("图片大小不能超过 10MB!太大了AI处理不过来");
}
String contentType = file.getContentType();
if (contentType == null || !contentType.startsWith("image/")) {
throw new IllegalArgumentException("仅支持图片文件!别传些奇奇怪怪的玩意儿");
}
}校验三要素(一个都不能少):
- ✅ 非空校验:别传空文件浪费算力
- ✅ 大小限制(10MB):AI 处理大文件容易卡
- ✅ 类型校验(image/*):只认图片,其他一概不收
2.5 调用大模型 API(OpenAI 兼容格式)
java
private String callDashScopeApi(String base64Image, String prompt) throws Exception {
// 构建多模态内容列表,图片+文字都安排上
List<Map<String, Object>> contentList = new ArrayList<>();
// 添加图片(用image_url格式,AI才认)
Map<String, Object> imageItem = new HashMap<>();
imageItem.put("type", "image_url");
Map<String, Object> imageUrl = new HashMap<>();
imageUrl.put("url", "data:image/jpeg;base64," + base64Image);
imageItem.put("image_url", imageUrl);
contentList.add(imageItem);
// 添加文本提示词,告诉AI该干啥
Map<String, Object> textItem = new HashMap<>();
textItem.put("type", "text");
textItem.put("text", prompt);
contentList.add(textItem);
// 构建消息对象
Map<String, Object> message = new HashMap<>();
message.put("role", "user");
message.put("content", contentList);
// 构建请求体
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", model);
requestBody.put("messages", Arrays.asList(message));
// 设置请求头,API Key得带好
HttpHeaders headers = new HttpHeaders();
headers.set("Authorization", "Bearer " + apiKey);
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<Map<String, Object>> request = new HttpEntity<>(requestBody, headers);
// 发送请求,坐等AI回复
ResponseEntity<String> response = restTemplate.postForEntity(apiUrl, request, String.class);
return response.getBody();
}OpenAI 兼容格式的好处(谁用谁知道):
- ✅ 业界通用款,换模型供应商也不用大改代码
- ✅ 文档多到看不完,出问题容易查
- ✅ 天生支持多模态,图片 + 文字一把抓
2.6 智能解析响应(三层降级,稳如老狗)
这部分是整个引擎最 "秀" 的地方,就算 AI 返回的格式乱七八糟,咱也能给它捋顺了。
java
private Map<String, String> parseAndNormalize(String apiResponse, List<String> fields) {
try {
JsonNode root = objectMapper.readTree(apiResponse);
// 第一层:提取原始内容(多路径兼容,不怕AI返回来的格式变样)
String rawContent = extractContent(root);
// 第二层:尝试解析为 JSON(优先选,最规整)
String cleanJson = rawContent
.replace("```json", "")
.replace("```JSON", "")
.replace("```", "")
.trim();
if (cleanJson.startsWith("{") || cleanJson.startsWith("[")) {
try {
// 修复不完整的 JSON(AI偶尔会忘加{},咱手动补)
if (!cleanJson.startsWith("{")) {
cleanJson = "{" + cleanJson;
}
if (!cleanJson.endsWith("}")) {
cleanJson = cleanJson + "}";
}
JsonNode jsonNode = objectMapper.readTree(cleanJson);
Map<String, String> result = new LinkedHashMap<>();
for (String field : fields) {
if (jsonNode.has(field)) {
result.put(field, jsonNode.get(field).asText("").trim());
} else {
result.put(field, "");
}
}
return result;
} catch (Exception jsonEx) {
log.warn("JSON 解析失败,换文本解析试试:{}", jsonEx.getMessage());
}
}
// 第三层:文本正则提取(JSON不行就硬扒,不能认输)
return parseFromText(rawContent, fields);
} catch (Exception e) {
log.error("解析翻车了:", e);
// 安全兜底:就算全失败,也返回空字段,系统绝不崩
return fallback(fields);
}
}三层降级策略(层层兜底,永不翻车):
plantext
┌─────────────────────────────────────┐
│ 第一层:JSON 解析(优先) │
│ - 扒掉markdown格式的```json外套 │
│ - 补全AI漏写的{},救不完整的JSON │
│ - 精准提取目标字段 │
└──────────────┬──────────────────────┘
│ 失败 ↓
┌──────────────▼──────────────────────┐
│ 第二层:文本正则提取 │
│ - 按"字段名:值"格式硬扒 │
│ - 不管AI咋排版,总能抠出关键信息 │
└──────────────┬──────────────────────┘
│ 失败 ↓
┌──────────────▼──────────────────────┐
│ 第三层:安全兜底 │
│ - 返回空字段Map,不影响前端使用 │
│ - 记好错误日志,方便后续排查 │
│ - 就算全错,系统也能正常跑 │
└─────────────────────────────────────┘文本解析实现(硬扒也要扒出来):
java
private Map<String, String> parseFromText(String text, List<String> fields) {
Map<String, String> result = new LinkedHashMap<>();
for (String field : fields) {
// 正则匹配"字段名:值",不管有没有空格都能匹配
String pattern = field + "\\s*[::]\\s*([^\\n,;,;]+)";
java.util.regex.Matcher m = java.util.regex.Pattern.compile(pattern).matcher(text);
if (m.find()) {
result.put(field, m.group(1).trim());
} else {
result.put(field, "");
}
}
return result;
}3. 配置文件
yaml
# application.yml
dashscope:
api-key: "sk-your-api-key-here" # 换成你自己的API Key,别直接用我的
model: "qwen3-vl-plus" # 模型版本,想换就换
url: "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions"配置设计原则(主打一个灵活):
- ✅ 敏感信息配置化:API Key 放配置文件,别写死在代码里
- ✅ 模型可切换:想换 qwen3-vl-base 或者其他模型,改个配置就行
- ✅ 环境隔离:开发、测试、生产环境用不同配置,不串味儿
4. 业务层实现示例
4.1 专利识别场景
java
@Service
public class PatentDetailServiceImpl implements PatentDetailService {
@Autowired
private VisionRecognitionEngine visionRecognitionEngine;
// 要识别的字段列表,想加想减直接改这儿
private static final List<String> PATENT_FIELDS = Arrays.asList(
"专利名称", "专利号", "授权时间", "专利权人", "发明人",
"专利类型", "是否转化"
);
@Override
public Map<String, String> recognizePatentImage(MultipartFile file) throws Exception {
log.info("开始识别专利图片啦,文件名:{}", file.getOriginalFilename());
String prompt = buildPatentPrompt();
log.info("提示词整好了,喊识别引擎干活咯");
// 一行代码搞定识别,主打一个省心
Map<String, String> result = visionRecognitionEngine.recognize(file, prompt, PATENT_FIELDS);
log.info("识别完事儿,结果长这样:{}", result);
return result;
}
private String buildPatentPrompt() {
return "麻烦你精准识别专利证书上的信息,只提以下字段:" +
String.join("、", PATENT_FIELDS) + "。\n\n" +
"要求:\n" +
"1. 所有字段都用字符串返回\n" +
"2. 日期格式必须是YYYY-MM-DD,别瞎写\n" +
"3. 多个名字用逗号分隔\n" +
"4. 必须返回纯纯的JSON,别带多余的废话\n" +
"5. 没找到的字段就返回空字符串";
}
}5. Controller 层实现
java
@RestController
@RequestMapping("/patent")
public class PatentDetailController {
@Autowired
private PatentDetailService patentDetailService;
/**
* 专利图片识别接口(前端调这个就行)
*/
@PostMapping("/ai/recognize")
public LSResult recognizePatentImage(@RequestParam("file") MultipartFile file) {
try {
Map<String, String> result = patentDetailService.recognizePatentImage(file);
return LSResult.success("识别成功!不用手动填啦", result);
} catch (Exception e) {
log.error("识别翻车了:", e);
return LSResult.error("识别失败咯:" + e.getMessage());
}
}
}🎨 前端实现
就说表单自动填这事儿,其他的咱不啰嗦
我的思路贼简单:拿到后端返回的 JSON,直接往表单变量上绑,主打一个 "懒人福音",代码如下
"由于当时写好了中文json,后面也懒得修改了,就这样吧"
前端实现要点
javascript
handleUploadSuccess(response, file, fileList) {
this.fileList = fileList
// 标记识别成功,给用户点反馈
this.recognitionSuccess = true;
if (response && response.data) {
this.recognitionResult = response.data;
}
// ========== 重点来咯 ==========
if (this.recognitionResult) {
this.form = {
...this.form,
// 基础字段直接映射,不用手动敲
patentName: this.recognitionResult['专利名称'] || '',
patentNumber: this.recognitionResult['专利号'] || '',
patentType: this.recognitionResult['专利类型'] || '',
applicationDate: this.recognitionResult['申请日期'] || '',
noticeDate: this.recognitionResult['授权公告日'] || '',
publicationNumber: this.recognitionResult['授权公告号'] || '',
patentSource: this.recognitionResult['专利来源'] || '',
// 多选组件字段也安排上
patentee: this.recognitionResult['专利权人'] || '',
inventor: this.recognitionResult['发明人'] || '',
implementationUnit: this.recognitionResult['实施单位'] || '',
// 状态类字段别落下
isConversion: this.recognitionResult['是否转化'] || '',
patentApplyStatus: this.recognitionResult['状态'] || '',
isJointApply: this.recognitionResult['是否联合申请'] || '',
jointApplicant: this.recognitionResult['联合专利权人'] || '',
};🎯 完整数据流
plaintext
前端上传图片(点一下按钮的事儿)
↓
后端 Controller 接招 (/patent/ai/recognize)
↓
Service 喊识别引擎干活 (recognizePatentImage)
↓
VisionRecognitionEngine.recognize() 一顿操作
↓
返回 Map<String, String> 格式的识别结果
↓
LSResult.success("识别成功", result) 告诉前端成了
↓
前端拿到JSON数据
↓
自动绑表单字段,用户直接提交就行后端返回示例(长这样):
json
{
"code": 200,
"msg": "识别成功!不用手动填啦",
"data": {
"专利名称": "一种高效节能装置",
"专利号": "ZL202310123456.7",
"授权时间": "2023-05-15",
"专利权人": "某某科技有限公司",
"发明人": "张三,李四",
"专利类型": "1",
"是否转化": "1"
}
}🏆 设计模式应用
1. 策略模式(Strategy Pattern)
换个提示词和字段列表,就能识别不同东西,主打一个 "一招鲜吃遍天":
java
// 专利识别策略
recognize(file, patentPrompt, patentFields);
// 著作权识别策略(换汤不换药)
recognize(file, softwarePrompt, softwareFields);- 模板方法模式(Template Method)
流程固定死,只改参数就行,不用重复写代码:
java
public Map<String, String> recognize(...) {
validateFile(file); // 步骤 1:先校验,别瞎传
encodeToBase64(file); // 步骤 2:转Base64,AI认这个
callApi(base64, prompt); // 步骤 3:调API,让AI干活
parseResponse(response); // 步骤 4:解析结果,返给前端
return result;
}3. 责任链模式(Chain of Responsibility)
解析的时候层层降级,总有一款能行:
plaintext
JSON 解析 → 文本解析 → 安全兜底💡 技术亮点总结
1. 高度抽象的通用性
- ✅ 业务层只需要关心提示词 和字段列表,其他不用管
- ✅ 识别逻辑完全解耦,想识别啥就改改提示词,贼灵活
- ✅ 新增识别场景零代码重复,主打一个偷懒不重复造轮子
2. 健壮的容错机制
plaintext
多层降级:JSON → 文本 → 空字段兜底就算 AI 返回的格式乱七八糟,咱的系统也能稳如老狗,绝不崩溃。
3. OpenAI 格式兼容
- ✅ 用业界通用格式,后续想换 OpenAI、智谱这些模型,改个配置就行
- ✅ 不用大改代码,省不少事儿
4. 依赖注入设计
- ✅ 专用 RestTemplate 配置,不跟其他 HTTP 请求抢资源
- ✅ 方便做单元测试,出问题也好定位
5. 完善的日志记录
java
// INFO:记清楚业务流程,方便排查
log.info("开始专利图片识别,文件名:{}", file.getOriginalFilename());
// DEBUG:调试的时候能看详细信息
log.debug("API 原始响应:{}", apiResponse);
// WARN:降级处理也记下来,知道哪儿出问题了
log.warn("JSON 解析失败,尝试其他方式解析:{}", jsonEx.getMessage());
// ERROR:异常堆栈记全,方便定位bug
log.error("DashScope 调用异常", e);📝 总结
这个 qwen 模块代码量不多,但设计得是真 "香",主打一个 "小而美、简而精"。靠着 AI 辅助写代码,再加上人工把控架构设计,实现了:
✅ 通用性:一套代码支持多场景,想识别啥就改改提示词
✅ 健壮性:多层降级兜底,就算 AI 抽风也不崩
✅ 可维护性:配置清晰,日志完善,出问题一眼就能看出来
✅ 可扩展性:新增场景零代码重复,偷懒也能偷得有水平
这事儿也告诉咱:现代程序员得驾驭 AI,而不是被 AI 牵着鼻子走------AI 帮咱写代码省时间,咱来把控架构和逻辑,分工明确效率才高。
希望这篇文章能给你带来点启发!要是有啥问题或者更好的想法,欢迎在评论区唠唠~
🔗 参考资料
版权声明:本文为原创技术文章,转载请注明出处。