大家好,我是锋哥。最近连载更新《嵌入模型与Chroma向量数据库 AI大模型应用开发必备知识》技术专题。
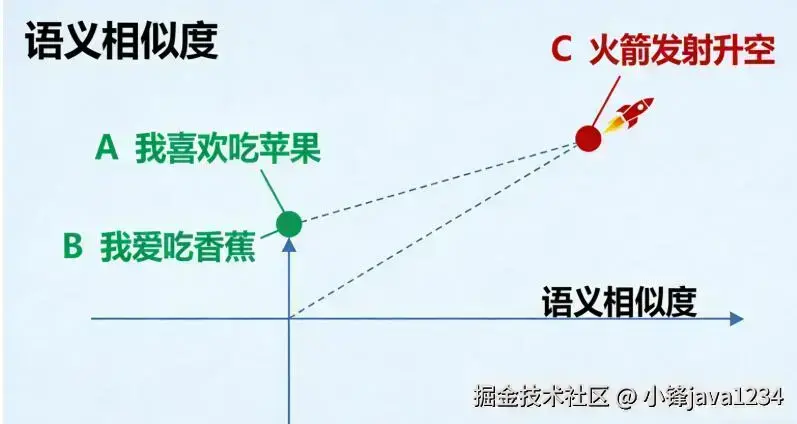 本课程主要介绍和讲解嵌入模型与向量数据库简介,Qwen3嵌入模型使用,Chroma向量数据库使用,Chroma安装,Client-Server模式,集合添加,修改,删除,查询操作以及自定义Embedding Functions。。。 同时也配套视频教程 《1天学会 嵌入模型与Chroma向量数据库 AI大模型应用开发必备知识 视频教程》
本课程主要介绍和讲解嵌入模型与向量数据库简介,Qwen3嵌入模型使用,Chroma向量数据库使用,Chroma安装,Client-Server模式,集合添加,修改,删除,查询操作以及自定义Embedding Functions。。。 同时也配套视频教程 《1天学会 嵌入模型与Chroma向量数据库 AI大模型应用开发必备知识 视频教程》
集合元数据
在创建集合时,你可以通过传递可选的metadata参数来为集合添加元数据键值对映射。这有助于为集合添加一般信息,如创建时间、集合中存储的数据描述等。
ini
from datetime import datetime
collection = client.create_collection(
name="my_collection",
embedding_function=emb_fn,
metadata={
"description": "my first Chroma collection",
"created": str(datetime.now())
}
)完整实例:
python
from datetime import datetime
import chromadb
chroma_client = chromadb.Client() # 创建Chroma客户端
print(chroma_client)
collection = chroma_client.create_collection(
name="my_collection",
metadata={
"description": "my first Chroma collection",
"created": str(datetime.now())
}
)
# 查看集合的元数据
print(collection.metadata)运行结果:
arduino
<chromadb.api.client.Client object at 0x000001E49AFC3610>
{'description': 'my first Chroma collection', 'created': '2026-02-19 16:14:11.930117'}获取集合
get_collection()方法获取集合
ini
collection = client.get_collection(name="my-collection")假如我们需要用一个集合,有的话就直接返回,没有的话就创建下,可以用get_or_create_collection()方法
ini
collection = client.get_or_create_collection(
name="my-collection",
metadata={"description": "..."}
)查看所有集合用list_collections()方法,默认返回100个。
ini
collections = client.list_collections()假如需要查询更多数据,或者分页查询集合,可以使用limit和offset参数:
ini
first_collections_batch = client.list_collections(limit=100) # get the first 100 collections
second_collections_batch = client.list_collections(limit=100, offset=100) # get the next 100 collections
collections_subset = client.list_collections(limit=20, offset=50) # get 20 collections starting from the 50th完整测试代码:
ini
import chromadb
chroma_client = chromadb.Client() # 创建Chroma客户端
print(chroma_client)
collection = chroma_client.create_collection(name="my_collection")
collection2 = chroma_client.get_or_create_collection(name="my-collection2")
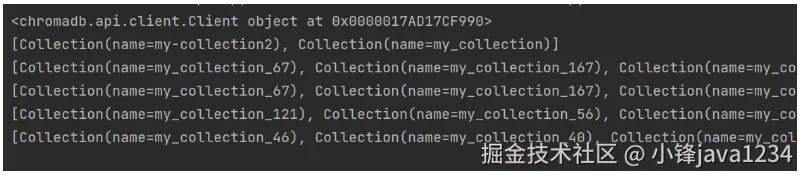
collections = chroma_client.list_collections()
print(collections)
for i in range(200):
chroma_client.create_collection(name=f"my_collection_{i}")
first_collections_batch = chroma_client.list_collections(limit=100) # get the first 100 collections
second_collections_batch = chroma_client.list_collections(limit=100, offset=100) # get the next 100 collections
collections_subset = chroma_client.list_collections(limit=20, offset=50) # get 20 collections starting from the 50th
collections = chroma_client.list_collections()
print(collections)
print(first_collections_batch)
print(second_collections_batch)
print(collections_subset)运行结果:
添加集合数据
使用.add方法将新记录插入到集合中。每条记录都需要一个唯一的字符串ID。
ini
collection.add(
ids=["id1", "id2", "id3"],
documents=["lorem ipsum...", "doc2", "doc3"],
metadatas=[{"chapter": 3, "verse": 16}, {"chapter": 3, "verse": 5}, {"chapter": 29, "verse": 11}],
)您必须提供文档、嵌入或两者都提供。元数据始终是可选的。当仅提供文档时,Chroma将使用集合的嵌入函数为您生成嵌入。 如果你已经计算了嵌入向量,请将它们与文档一起传递。Chroma会按原样存储这两者,而不会对文档进行重新嵌入。
ini
collection.add(
ids=["id1", "id2", "id3"],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2]],
documents=["doc1", "doc2", "doc3"],
metadatas=[{"chapter": 3, "verse": 16}, {"chapter": 3, "verse": 5}, {"chapter": 29, "verse": 11}],
)如果您的文档存储在其他位置,您可以仅添加嵌入和元数据。使用这些ID将记录与您的外部文档相关联。如果您的文档非常大,例如高分辨率图像或视频,这将是一种有用的模式。
ini
collection.add(
ids=["id1", "id2", "id3"],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2]],
metadatas=[{"chapter": 3, "verse": 16}, {"chapter": 3, "verse": 5}, {"chapter": 29, "verse": 11}],
)元数据:
元数据值可以是字符串、整数、浮点数或布尔值。此外,还可以存储这些类型的数组。
ini
collection.add(
ids=["id1"],
documents=["lorem ipsum..."],
metadatas=[{
"chapter": 3,
"tags": ["fiction", "adventure"],
"scores": [1, 2, 3],
}],
)操作注意一点:
如果你添加的记录的ID已经在集合中存在,该记录将被忽略,且不会抛出错误。若要覆盖集合中的数据,你必须更新数据。 如果提供的嵌入向量与集合中已有的嵌入向量的维度不匹配,将会引发异常。
修改集合数据
集合中记录的任何属性都可以使用 .update 进行更新:
ini
collection.update(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[{"chapter": 3, "verse": 16}, {"chapter": 3, "verse": 5}, {"chapter": 29, "verse": 11}, ...],
documents=["doc1", "doc2", "doc3", ...],
)如果在集合中未找到某个ID,则会记录一条错误,并忽略此次更新。如果提供的文档没有相应的嵌入信息,则会使用集合的嵌入函数重新计算嵌入信息。 元数据值可以包含数组 --- 请参阅"添加数据"以了解支持的元数据类型。 如果提供的嵌入向量与集合的维度不同,将引发异常。 Chroma还支持更新插入(upsert)操作,该操作可以更新现有项,如果这些项尚不存在,则将其添加。
ini
collection.upsert(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[{"chapter": 3, "verse": 16}, {"chapter": 3, "verse": 5}, {"chapter": 29, "verse": 11}, ...],
documents=["doc1", "doc2", "doc3", ...],
)如果集合中不存在某个id,则将根据add操作创建相应的条目。对于已存在id的条目,将根据update操作进行更新。
删除集合数据
Chroma支持通过.delete方法按ID从集合中删除项目。与每个项目相关的嵌入、文档和元数据都将被删除。
当然,这是一个具有破坏性的操作,且无法撤销。
ini
collection.delete(
ids=["id1", "id2", "id3",...],
).delete 也支持 where 过滤器。如果未提供任何 id,它将删除集合中所有符合 where 过滤条件的项。
ini
collection.delete(
ids=["id1", "id2", "id3",...],
where={"chapter": "20"}
)集合增删改查基本实例:
ini
import chromadb
chroma_client = chromadb.Client() # 创建Chroma客户端
collection = chroma_client.create_collection(name="my_collection")
# 添加
collection.add(
ids=["id1", "id2", "id3"],
documents=["lorem ipsum...", "doc2", "doc3"],
metadatas=[{"chapter": 3, "verse": 16}, {"chapter": 3, "verse": 5}, {"chapter": 29, "verse": 11}],
)
# 查询
results = collection.query(
query_texts=["doc"], # Chroma will embed this for you
n_results=3 # how many results to return
)
print(results)
# 修改
collection.update(
ids=["id1", "id2"],
documents=["new doc1", "new doc2"],
metadatas=[{"chapter": 3, "verse": 16}, {"chapter": 3, "verse": 5}],
)
# 查询
results = collection.query(
query_texts=["doc"], # Chroma will embed this for you
n_results=3 # how many results to return
)
print(results)
# 删除
collection.delete(ids=["id1", "id2"])
# 查询
results = collection.query(
query_texts=["doc"], # Chroma will embed this for you
n_results=3 # how many results to return
)
print(results)运行输出:

集合配置
了解如何配置 Chroma 集合索引设置和嵌入函数。
Chroma 集合具有一个属性configuration,用于决定其嵌入索引的构建和使用方式。我们为这些索引配置使用默认值,这些默认值应该能够为大多数使用场景提供开箱即用的出色性能。您在集合中选择使用的嵌入函数也会影响其索引构造,并且包含在配置中。创建集合时,您可以根据不同的数据、准确性和性能要求自定义这些索引配置值。某些查询时配置也可以在集合创建后使用该.modify函数进行自定义。
HNSW 索引配置
space定义了嵌入空间的距离函数,从而定义了相似度。默认值为l2(平方 L2 范数),其他可能的值包括cosine(余弦相似度)和ip(内积)。

ef_construction决定索引创建过程中用于选择邻居的候选列表的大小。值越高,索引质量越高,但会占用更多内存和时间;值越低,索引构建速度越快,但精度会降低。默认值为 0100。ef_search此字段决定了在搜索最近邻居时使用的动态候选列表的大小。较高的值会探索更多潜在邻居,从而提高召回率和准确率,但会增加查询时间和计算成本;而较低的值则会导致搜索速度更快,但准确率更低。默认值为 0。100创建后可以修改此字段。max_neighbors是构建索引时图中每个节点可以拥有的最大邻居(连接)数。值越高,图越密集,搜索时的召回率和准确率越高,但会增加内存使用量和构建时间。值越低,图越稀疏,内存使用量和构建时间越短,但搜索准确率和召回率会降低。默认值为 016。num_threads指定在索引构建或搜索操作期间使用的线程数。默认值为multiprocessing.cpu_count()(可用 CPU 核心数)。此字段可在创建后进行修改。batch_size控制索引操作期间每个批次要处理的向量数量。默认值为 0。100此字段可在创建后进行修改。sync_threshold确定何时将索引与持久存储同步。默认值为1000。此字段可在创建后进行修改。resize_factor控制索引在需要调整大小时增长的幅度。默认值为 0。1.2此字段可在创建后进行修改。
例如,这里我们创建一个包含自定义值的space集合ef_construction:
参考配置:
ini
collection = client.create_collection(
name="my-collection",
embedding_function=OpenAIEmbeddingFunction(model_name="text-embedding-3-small"),
configuration={
"hnsw": {
"space": "cosine",
"ef_construction": 200
}
}
)