在传统的软件开发模式中,我们的潜意识里会这样认为:一个业务对象,就必然对应数据库里的一张物理表。
比如我们要开发一个问卷系统,很自然地会建立 Survey(问卷表)、Question(题目表)、Response(答卷表)。表里定义好具体的列:title 是 VARCHAR,score 是 Int,createdAt 是 DateTime。各司其职,结构清晰。当平台只有几十、上百个客户,且他们的业务流程基本一致时,这套做法不仅高效,而且非常优雅。
但是,现代企业级 SaaS(比如低代码平台、极其灵活的 CRM 系统)面临的核心挑战是:极端的个性化诉求规模化。
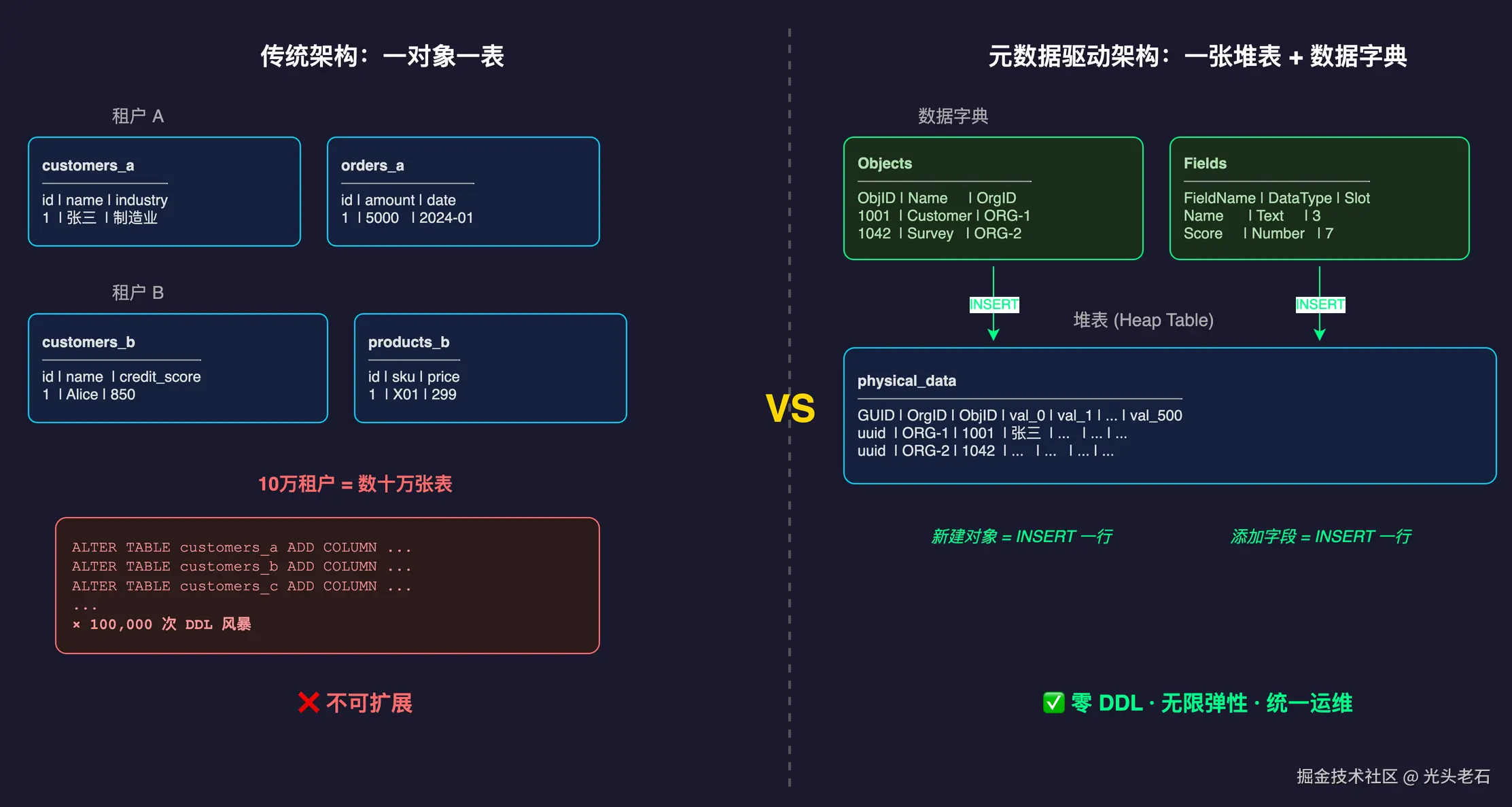
假如遇到这样的场景,你的平台服务了很多个企业客户(租户)。 A 企业希望在问卷里加一个"所属行业"字段; B 企业希望加一个"紧急程度"字段; C 企业甚至想完全新建一个叫"问卷回访跟进"的全新业务模块。 如果坚持"一对象一表"的传统架构,我们很快会遇到下面的问题:
- 触发 DDL 风暴 (Data Definition Language Storm) :当上百个租户各自在界面上点击"添加字段"时,后台就要向数据库发送几十万条
ALTER TABLE ADD COLUMN语句。DDL 操作通常会锁表(Metadata Lock),这在处于高并发读写状态的生产型数据库中,无异于自杀。 - 运维与管理的无底洞:如果为每个租户单独建表,1 万租户 × 50 张表 = 50 万张表。数据库的数据字典(系统表)会因为海量的元数据而极度膨胀。让备份、升级、统一修改字段都变得很困难。
- 隔离性极其脆弱:多租户环境下,由于大家的 Schema 完全长得不一样了,一套统一的代码体系很难去处理所有边缘情况,最后往往陷入"代码里写满 if-else 处理不同租户特殊逻辑"的泥潭。
面对这些困难,业界诞生了一个这样的架构选择:彻底放弃让应用层直接操作数据库结构。
数据库在低代码平台眼中,退化成了一个纯粹的、钝感的数据仓库。 它不关心、也不知道具体的业务模型长什么样。 至于"系统里有哪些表、表里有哪些字段"这种原本属于 DBMS 级别的工作,被"上架"到了应用层来管理。
这就是**元数据驱动架构(Metadata-driven Architecture)**的起点。
用元数据描述结构:通用数据字典 (UDD)
为了在应用层"维护"一套数据库系统的逻辑,我们需要引入一个至关重要的概念:元数据 (Metadata)。
如果说普通的业务数据记录的是"张三考了 95 分",那么元数据记录的就是"系统里有一个叫『问卷』的表,并且它有一列叫『分数』"。简单来说,元数据就是"描述数据的数据"。
管理这些元数据的数据,我们称之为 通用数据字典 (Universal Data Dictionary, UDD)。
它的核心思想是:既然底层数据库不让我们自由建表了,那我们就拿两张普通的表当"户口本",把用户想要的表结构"登记"在册。
具体来说,系统里只需要永远固定存在这两张表:
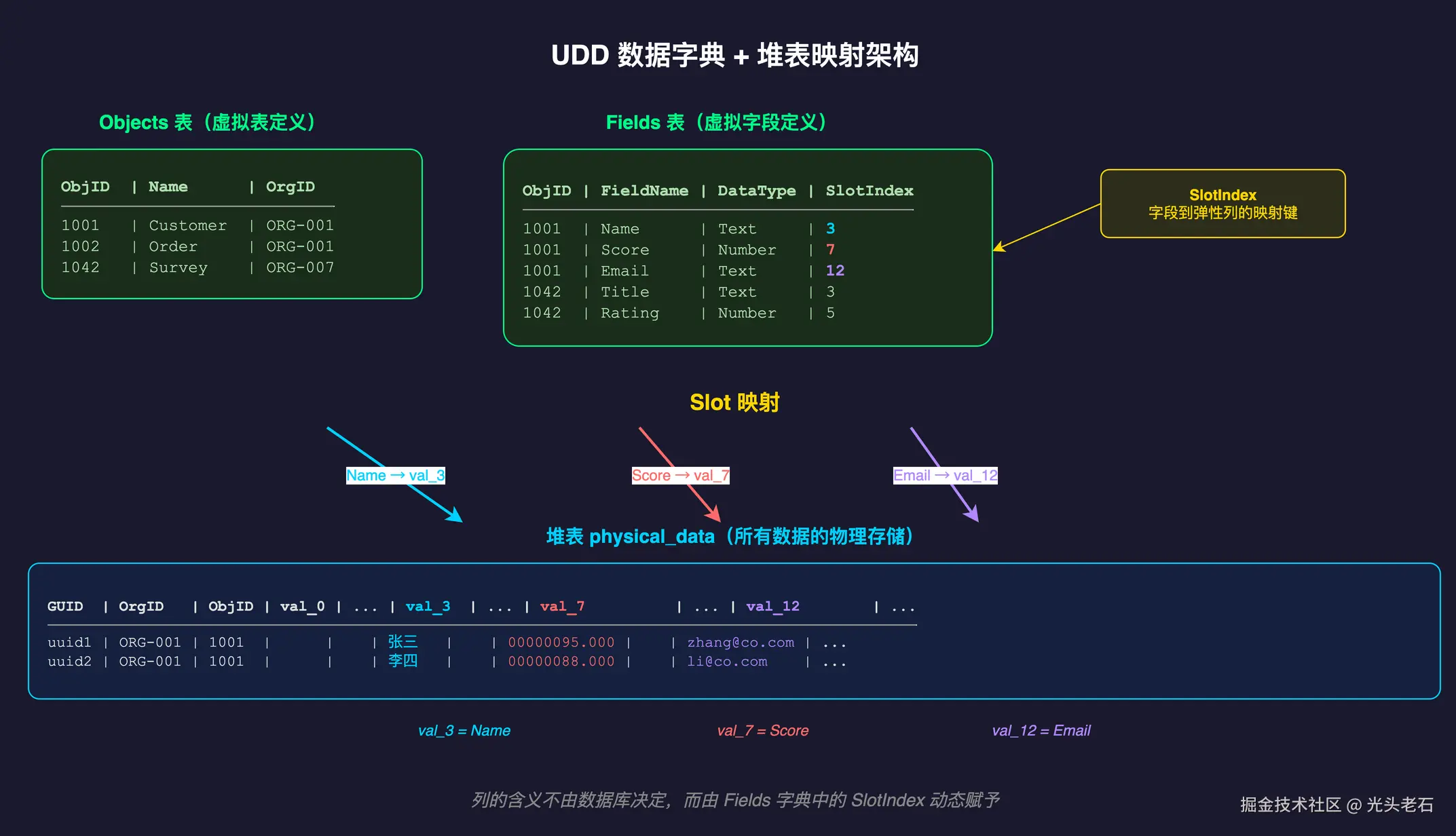
1. Objects 表(登记"有什么表")
当你在低代码后台点击"新建表单"并命名为"问卷调查"时,底层并没有执行神圣的 CREATE TABLE。 系统只是往 Objects 这张表里,像普通记账一样插入了一行: "嘿,客户 A 新建了一个叫 Survey(问卷)的虚拟表,ID 给它算作 1001 吧。"
2. Fields 表(登记"表里有什么列")
知道了有问卷表,还得知道问卷里有什么字段。Fields 表就是用来记这个的。
每当你在页面上拖拽生成一个"问卷标题"的输入框,系统就往 Fields 表里加上一行: "客户 A 的 Survey 表里,多了一个叫 Title(标题)的文本字段。并且我规定,填写在这里的内容,未来统一存放到第 0 号储物格(SlotIndex: 0)里。"
理解关键点:在这个体系里,修改系统结构不再是高危的数据库操作(DDL),而变成了最简单的增删改查(CRUD)。表结构,本身也化作了普通的数据。
数据存储: 堆表与弹性列机制
上一节,我么把数据结构建好了。下一个问题是:真正的业务数据,到底存在哪里?
既然应用层不能动态建表,那唯一的解法就是:提前建好一张超级巨大的"万能表",把所有客户、所有表单的数据,全部大杂烩一样强行塞进去。
这张底层物理表,我们管它叫 堆表 (Heap Table) 。 你可以把它想象成一张行和列都无限向外延展的超级 Excel 表格。
它的结构极其无脑暴力,大致长这个样子:
| 唯一ID | 租户是谁 | 这是什么表 | 储物格_0 (val_0) |
储物格_1 (val_1) |
储物格_2 (val_2) |
... |
|---|---|---|---|---|---|---|
| 1 | 客户A | 问卷表 | 用户满意度调查 | 5分 | 进行中 | ... |
| 2 | 客户A | 订单表 | iPhone 15 Pro | 8999元 | 顺丰发货 | ... |
| 3 | 客户B | 请假表 | 病假 | 老婆不舒服 | 1天 | ... |
请仔细观察这张表的最右侧,跟着密密麻麻的 val_0, val_1 到 val_500。 这些列被称为 弹性列 (Flex Columns) ,而且它们全都是兼容性最强的文本类型 (VARCHAR)。
堆表本身是一只没有任何感情的吞金兽,它完全不关心自己存的是问卷的名字、手机的价格,还是请假的天数。那到底谁知道 val_1 存的是什么鬼东西?
答案是:上一节讲到的 Fields 字典! 这两者的配合机制(Slot 映射)如下:
- 前端发请求:"把客户 A 的 iPhone 订单价格拿给我看看"。
- 翻译官(字典表)在脑子里翻译:"iPhone 订单价格... 对客户 A 来说,这玩意儿被登记在
val_1这个储物格里!" - 翻箱倒柜(抛向数据库):直接用原生 SQL 执行
SELECT val_1 FROM 堆表 WHERE ID = 2。
就是这么简单。对底层的关系型数据库来说,这里完全不存在运行时的动态改表,也就是查一个固定列而已。 堆表负责死心塌地屯放数据,字典表作为"翻译密码本"负责解释这行数据到底是什么意思。 两套系统严丝合缝地咬合,完成了极其精彩的欺骗。
全用 VARCHAR 的代价与规范化格式
这种设计带来新的问题:
所有弹性列都是 VARCHAR 字符串,那我们怎么做大于、小于的范围比较?数字 95 和 100 怎么排序?日期 2024-01-01 和 2024-02-01 怎么查区间?
按照常规的字符串字典序逻辑,字符串 "100" 是排在 "95" 前面的(因为首字符 1 小于 9)。如果我们把 Score=100 和 Score=95 原封不动作为字符串存进去,那么 ORDER BY Score DESC 的结果将是彻头彻尾的灾难。
这是所有的元数据架构必须跨过的一道硬核工程门槛。既然底层的原生数值类型和日期类型被我们人为抹杀掉了,我们就必须在应用层用一套严密的逻辑把规则补回来。这套机制被称为 规范化格式 (Canonical Format)。
它的核心思想是:在把强类型的业务数据实际写入 val_N 弹性列之前,必须先经过一道编码层,将其强制转换为能够直接用于数据库比较运算符(>、<、BETWEEN、ORDER BY)的、符合标准字典序的字符串。
以下是一些关键的规范化规则:
| 逻辑类型 | 原始输入值 | 规范化后的字符串表示 | 工程原理与优势 |
|---|---|---|---|
| Number | 95 |
"00000095.000" |
预先定义好总位数和小数位。左边补零对齐,保证字符串字典序等同于数值大小序。 |
| Number | -3 |
"-0000003.000" |
处理负数时逻辑更复杂(需翻转补码),此处为简化展示,核心目的是解决负数排序。 |
| Date | 2024-01-15 |
"2024-01-15T00:00:00Z" |
严格采用 ISO 8601 格式,高位是年,低位是秒。时间维度的顺推恰好也是字典序的顺推。 |
| Boolean | true |
"1" |
布尔值直接降维为单字符的 "1" 或 "0"。 |
这套设计的本质是一笔架构层面的交易:我们刻意牺牲了底层数据存储的可读性,并付出了序列化/反序列化的计算开销,以此换取了整个平台架构在极大规模下的极致弹性。
在庞大的全是大文本的宽表上做 SQL 索引,其扫描效率和命中率在面临千万级数据时会直线下降。这个被称为"元数据性能税"的问题,是所有成熟架构后续必须攻克的下一个高峰,我们将在后续文章(透视表与查询优化)中集中讨论如何偿还这笔债。
一条数据的完整端到端旅程
我们把上面所有概念串在一起,看看在真实的系统中,一次普通的数据保存到底经历了怎样的一生。
应用场景 :某个平台管理员在 Web 前端的问卷管理界面中,提交了一份新问卷的基础信息:{Title: "用户满意度调查", Status: "进行中"}。
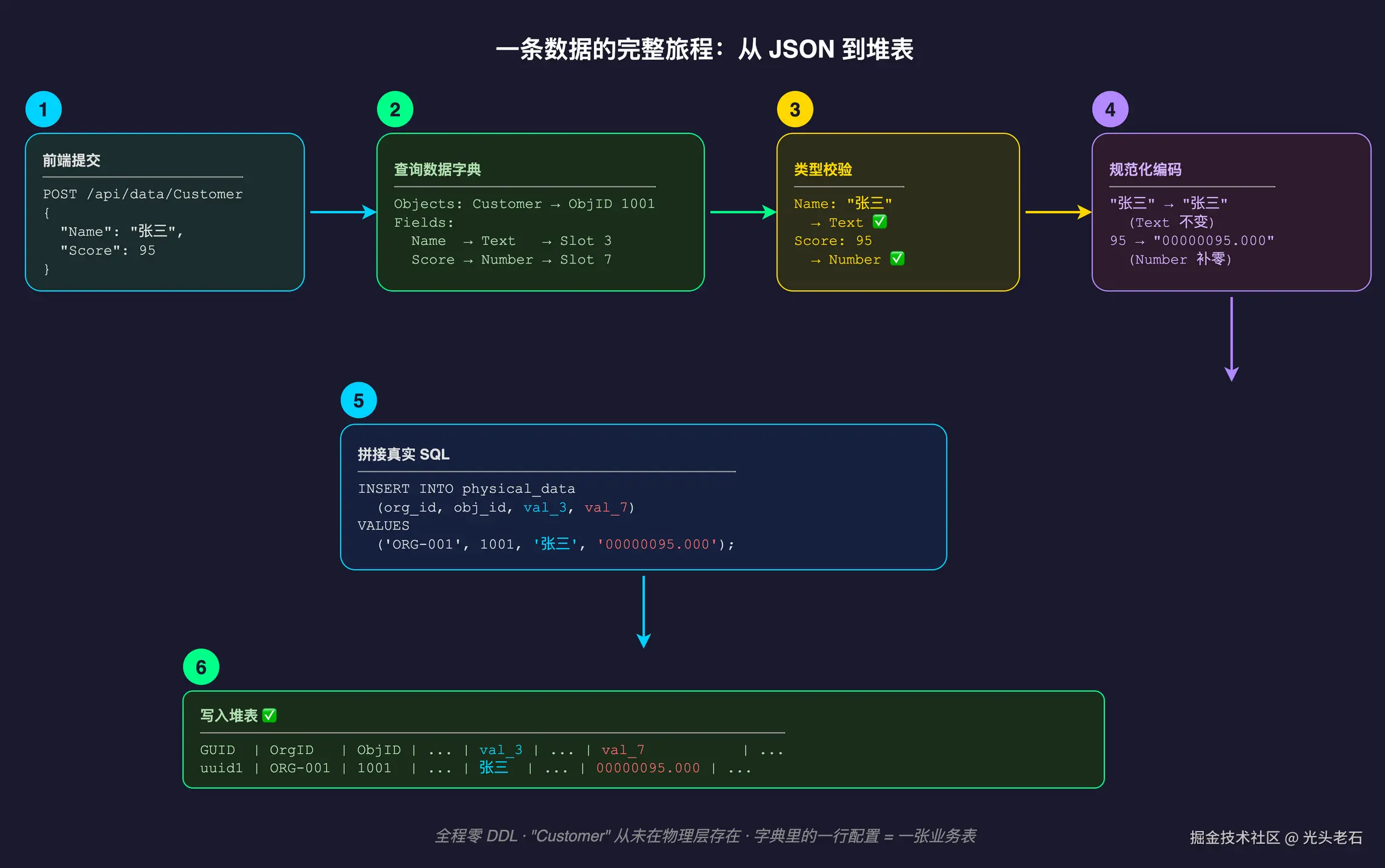
Step 1 · 流量入口与鉴权 (API Layer)
前端发起了 HTTP 请求。网关拦截后解析出这是 ORG-001 租户的流量,明确目标是要操作 Survey 这个模型。
http
POST /api/data/Survey
{ "Title": "用户满意度调查", "Status": "进行中" }Step 2 · 唤醒元数据字典 (Metadata Lookup)
引擎的核心拦截器登场。它拿着 "Survey" 这个关键次去查询(通常是内存缓存里的)Objects 表,得到了这个虚拟模型的内部 ID 为 1001。 接着查询 Fields 表,拉取到了这个模型下的所有字段配置及最重要的物理槽位:
| 逻辑字段名 | 逻辑类型 | 物理层 SlotIndex | 是否必填 |
|---|---|---|---|
| Title | Text | 0 | Yes |
| Status | Text | 1 | No |
Step 3 · 运行期强制校验与规范化编码 (Validation & Encoding)
引擎把请求中的 JSON 体拉过来进行对比:
"用户满意度调查"→ 对应 Title 字段。系统检查其长度、是否符合纯文本规范。因为是 Text 类型,直接保持原样保留为待插入字符串。"进行中"→ 对应 Status 字段。校验通过,保持原样。 (如果包含数字,就会在此处被格式化为前补零字符串)
Step 4 · 虚实转换:拼接最终物理 SQL (SQL Generation)
引擎拿着内存里已经编码好的干净数据,根据字典提供的映射关系,开始拼接能够在底层 PostgreSQL/MySQL 里直接运行的 SQL 文本。注意这里的列名已经被替换成了真正的物理列名 val_0, val_1。
sql
INSERT INTO physical_data
(org_id, obj_id, val_0, val_1, created_at)
VALUES
('ORG-001', 1001, '用户满意度调查', '进行中', '2026-03-01T12:00:00Z');Step 5 · 落盘与响应 (Persistence)
关系型数据库默默地执行了这条标准的 DML 语句,将数据持久化到堆表,并返回写入成功。引擎再将结果封装成 JSON 返回给前端。
回顾这一切:整个请求过程中,没有触发过任何一次 DDL 锁。被外界视作核心支柱的 Survey 这张业务表,自始至终在物理层面都不存在过 ------ 它只是配置系统里静静躺着的一行设置。而在平台的用户端视角看来,他们的录入、查询操作,却与使用专属 MySQL 实例并无二致。
小结
元数据驱动的核心并不是消灭了结构,而是做了一次巧妙的维度提升。
我们将传统数据库赖以生存的 Schema 骨架从底层剥离,强行搬到了更高一层的"应用层数据字典"中。这层额外的中间层间接性,赋予了平台很强的生命力和扩展弹性。无论租户是一千、一万还是十万,无论他们想要定义怎样千奇百怪的表单和数据模型,底层物理依然是一张纹丝不动、便于统一治理和灾备的超级宽表。
只要你的系统存在"极端允许用户在运行时定义数据结构"的需求,这套宽表+字典模型几乎是目前工业界唯一可行的顶层解法。