
思考
- AI 评测还能客观反映 AI 能力吗?
- AI 测评是 AI 落地的主要考量吗?
- 通用大模型在数据库行业能落地吗?
1. AI 落地的瓶颈:不可计算
关于近期 "AI 评测坐标系坍塌" 的说法,我认为这并非指评测体系的崩溃,而是标志着评测标准正经历一场深刻的范式转移,一个 "新坐标系" 的大基建时代正在到来!
目前,AI 落地的瓶颈不是 "智力不够" ,而是 "不可计算" 。因为在所有核心生产环境中,"未知" 远比 "不能" 更让人感到寒意。
1.1 "未知" 比 "不能" 更可怕
所谓 "不能",指的是技术的上限 ,我们可以靠工程规避,靠冗余弥补;但 "未知" 则是确定性的坍塌。

如果一名技术负责人,得知某个 AI 生成的逻辑有 1% 的概率会导致不可预知的系统崩溃,且你无法量化这个 1% 会在什么时候、什么边界触发,那么对于他来说,这个 AI 的价值就不是 99% 的增效,而是 100% 的风险炸弹。
正是这种由于缺乏 "边界感" 而产生的决策瘫痪,促使我们必须快步构建新坐标系。
1.2 为什么 AI 选型陷入"决策黑盒"?

为什么以往的 AI 选型会进入"决策黑盒"?因为我们面临三大困境:
- 不知道怎么测:究竟要测哪些方面。
- 没成本测:模拟工业级测试场景成本极高,测试程序开发成本高,测试数据准备成本高。
- 信息差:不知道哪个模型适合自己场景。
如何才能击穿这个黑盒呢?
2. 从 Aha Moments 到"到底能不能用"

2.1 我们经历过的 AI 惊艳时刻
- 🧠 能思考
- 📝 会写诗
- 🖼️ 能生图
- 🎞️ 能生视频
我们已经经历了太多的 "Aha Moments"。看到模型会写诗、能思考、能生图、生视频,令我们惊艳欢呼。但欢呼之后,生产环节真正关心的是:它到底能不能帮我干活?
2.2 AI 评测标准的价值
在 AI 进入生产环节的深水区时,市场急需一个声音来判定"好坏"。回顾历史,ImageNet 的地位之所以高不可攀,是因为它锚定了视觉能力的基准。

而最近爆火的 LMArena 之所以估值高达 17 亿美金,本质上是因为它在大模型最混乱的时候,告诉了用户谁更好用。

在评测的过程中,测评榜单固然需要参考,但更重要的是判定 AI 能否从"做对题"向 "干成事"。
2.3 考试泄题与"红皇后效应"
经济学中有一个古德哈特定律(GoodHart's Law):"当一个指标成为目标时,它就不再是一个好的指标。"
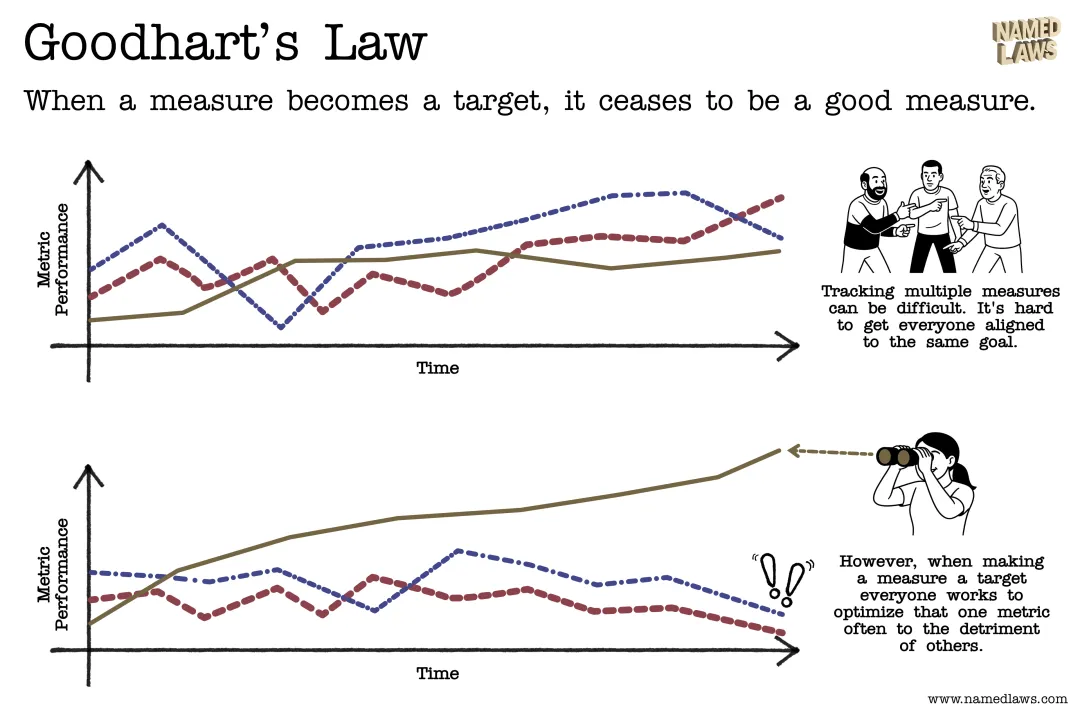
为什么我们需要这么多榜单?因为现在的通用榜单已经面临严重的"数据污染"。
通用榜单的困境(以数据库行业为例)
标准榜单的题目会在互联网上广泛传播,不可避免地混入训练数据中。所以你会看到模型能背出所有的 Oracle 语法,但一旦我们把题目中的变量名改一改,或者把逻辑嵌套稍作调整,原本的高分模型会瞬间崩盘。
那么真正有效的测评榜单是能够持续更新"题库" 的榜单,要看模型是"记住了"答案,还是"算出了"答案。
3. 照妖镜:SCALE
SCALE 就是这样一款持续更新的,专门用于测评大模型 SQL 能力的榜单。 
2025 年 12 月,SCALE 更新生产级数据集 2.0。这不是一次简单的题库扩容,而是一次"照妖镜"式的压力测试。
| 模型 | SCALE 1.0 | SCALE 2.0 | 跌幅 |
|---|---|---|---|
| DeepSeek | 71.6 | 51.5 | -20.1 (-28%) |
| Gemini 3 Pro | 72.0 | 64.0 | -8.0 (-11%) |
结果让很多所谓的"优等生"露出了马脚:
- DeepSeek:在旧坐标系里是 71.6 的高分,但在 2.0 数据集面前直接暴跌到了 51.5,跌幅近 30%。
- Gemini 3 Pro:也从原本亮眼的 72 分回落到了 64 分。
3.1 消失的分数 = AI 的"滤镜"
这消失的分数,就是 AI 的"滤镜"。只有这层滤镜被挤掉后,你才知道谁才是真正能在生产环境下、在没见过考题的情况下帮你解决问题的"实战专家"。
为什么 SCALE 能把这些"优等生"打回原形?
因为 SCALE 的"题库"是基于 ActionTech 客户现场的几千条"烂数据"和真实事故构建的。这不是简单的考试,这是对模型的压力演习。
3.2 别做"冤大头",专业化 > 大而全
经过实测证明,在 SQL 这个垂直领域,GPT-4 Mini 的很多指标优于其庞大的全量版 GPT-5 Chat !
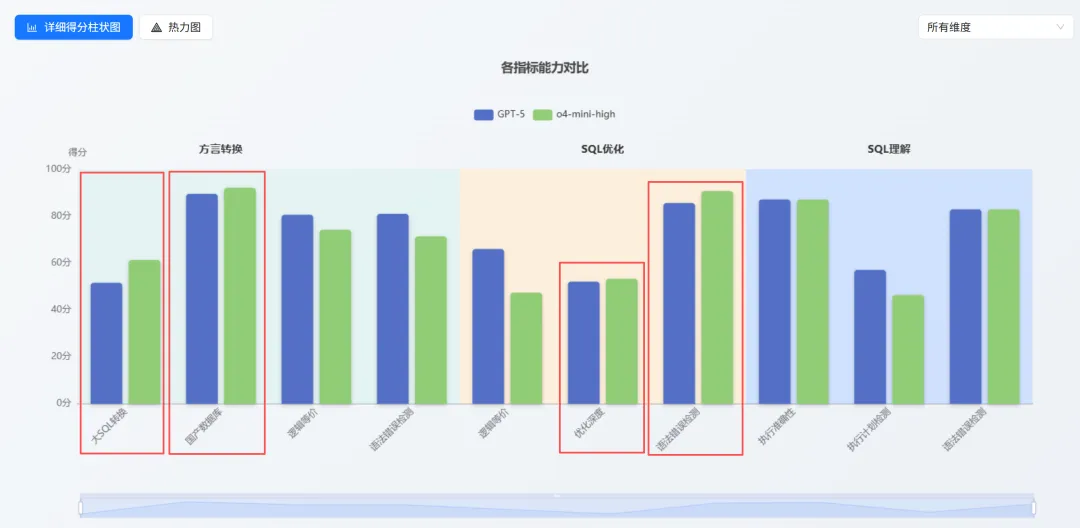
Big is not always better. Specialized is enough.
企业选型误区
- ❌ 只看通用榜单 → 选最贵模型
- ❌ 浪费算力成本
- ❌ 引入更多推理不确定性
对于企业来说,如果你只看通用榜单选了最贵的模型,你不只是在浪费算力成本,你甚至在引入更多的推理不确定性。
3.3 从 ICU 病房到压力演习
SCALE 的数据来源
- ❌ 不是教科书例题
- ✅ 近十年真实事故代码
- ✅ 金融/电信/电力/零售 "翻车"案例
近十年,我们在金融、电信、电力等行业直面数百起因 SQL 缺陷引发的生产事故------从毫秒级延迟到核心系统宕机,每个高危场景都是被按下暂停键的**「高危手术」**。
在这些真实故障面前,通用大模型在学术榜单上磨炼出来的"套路"失效了。SCALE 存在的目的,不是为了证明模型不行,而是为了倒逼模型学会识别物理执行计划,学会在国产化迁移等真实落地场景中,精准地切换方言和决策。
3.4 三位一体的混合评估机制
不只是看 SQL 是否能跑通,还要把评估拆解成三个维度:
- 客观评估:针对语法正确性
- 主观评估 :针对逻辑等价性和方言转换
- 由多个高能力模型交叉打分
- 混合评估(核心):针对 SQL 优化的
3.5 优化规则如何炼成?
很多人好奇:这些决定模型胜负的"优化规则"到底是怎么定出来的?是专家拍脑门吗?
绝对不是。
首先,要对数据先进行挖掘。以优化方向来说,一本书中如果能挖出 10 多条优化方向。人读一本书以天/周为单位,AI 读一本书以分钟为单位。我们为此构建了一套极其复杂的 "高保真生产模拟器"。它可以精准模拟不同量级、不同架构的各种异构生产场景。
高保真生产模拟器工作流程
markdown
1. AI + 资源库挖掘优化方向
↓
2. 投入模拟器压测
↓
3. 专家团队逻辑审计
↓
4. 收录进 SCALE先利用 AI 挖掘潜在的优化方向,然后将这些规则投入模拟器进行海量的自动化压测。只有在那套复杂的模拟引擎中被验证为实战有效,并最终通过我们专家团队的严苛逻辑审计,才能被收录进 SCALE 的**"真理库"**。
双保险机制
- 🤖 模拟器:异构生产场景自动化验证
- 👨💼 专家审计:逻辑严苛性把关
这套 "模拟器 + 专家经验" 的双保险,确保了 SCALE 的评分标准不是纸上谈兵,而是真正的 "物理执行感知" 评估。
4. 从"学术竞赛"到"落地评估"
4.1 给技术负责人的选型新思路
最后,把话题再拉回到大家关心的 ROI 上。AI 的测评正在经历从"学术竞赛"向"落地评估"的转型。
如果你是技术负责人,你应该这样问自己:"这个模型在 SCALE 2.0 面前,能否像一名合格的工程师一样,稳定解决复杂 SQL 问题?"
如果答案是否定的,那它就不该进入你的核心系统。如果一个模型在我们的"大型 SQL 转换" 指标上表现不佳,那就意味着它在真实生产环境中会给你埋雷。
4.2 SCALE 的目标
AI for DB 的终极形态不是一个聊天框,而是一个能自主运维、自主调优的 SQL Agent。
- 精准选型:能针对自己的需求找到合适的模型
- 场景匹配:明确应用场景:优化?国产化?还是其他类型?
- 产品评估:如果自研了 AI 产品,能知道做得好不好
SCALE 的使命,就是成为这类 "SQL 智能体" 的入职资格证。
为专业 SQL 任务,选专业 AI 模型。
如果你也在为 AI 选型犯难,欢迎访问我们的官网,了解最新的 SCALE 评测报告,找到真正适合你生产场景的模型。
我们坚持:📅 每月更新、🔄 生产反哺、🏭 生产溯源
在这个坐标系重构的时代,我们希望同大家一起寻找 AI 真正的生产力价值。