这是 「AI是怎么回事」 系列的第 12 篇。我一直很好奇 AI 到底是怎么工作的,于是花了很长时间去拆这个东西------手机为什么换了发型还能认出你,ChatGPT 回答你的那三秒钟里究竟在算什么,AI 为什么能通过律师考试却会一本正经地撒谎。这个系列就是我的探索笔记,发现了很多有意思的东西,想分享给你。觉得不错的话,欢迎分享+关注。
第一次看到这个系列?从第1篇开始最顺畅,直接读这篇也没问题。

2025 年 12 月,GPT-5.2 发布。我打开新闻,看到标题------"数学竞赛满分"。
我愣了一下。
上一篇我刚画完那条分界线:AI 的强弱取决于三个条件,三个问题就能判断。但现在 AI 连数学竞赛都满分了------如果它一直这样进步下去,我画的那条线,是不是已经过时了?
这种焦虑你一定也有。每隔几个月就有一条"AI 又突破了"的新闻------GPT-5.2 数学满分,推理模型 o3 编程惊人,基准测试不断被打穿。如果 AI 一直在进步,第 11 篇的"分界线"和"三问判断法",明年还能用吗?
答案是:能。
不只是明年------只要 AI 的底层原理不变,这个框架就不会过时。
为什么?让我从一个测试开始。
先做一个测试
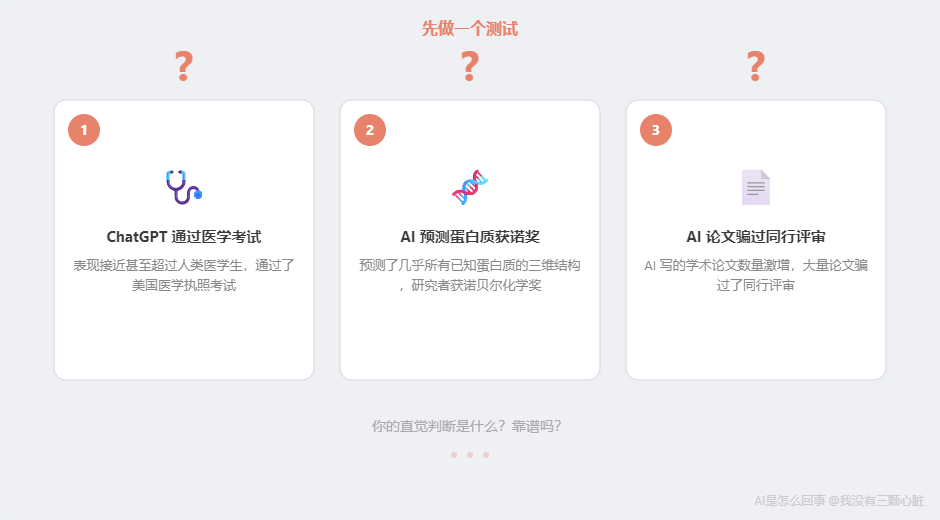
在展开之前,拿三条真实 AI 新闻做个测试。你试试凭直觉判断------靠谱吗?
新闻一:
"ChatGPT 通过了美国医学执照考试(USMLE),表现接近甚至超过人类医学生。"
新闻二:
"AI 预测了几乎所有已知蛋白质的三维结构,研究者获 2024 年诺贝尔化学奖。"
新闻三:
"AI 写的学术论文数量激增,大量论文骗过了同行评审。"
先记住你的直觉判断。等一下我们用三问判断法做一次速判------看看你的框架有没有内化。
AI 认知三角:把第二章装进口袋
经过第 9 到第 11 篇的层层分析,我们可以把第二章的全部核心知识压缩成一个极简框架。我把它叫做**「AI 认知三角」**。
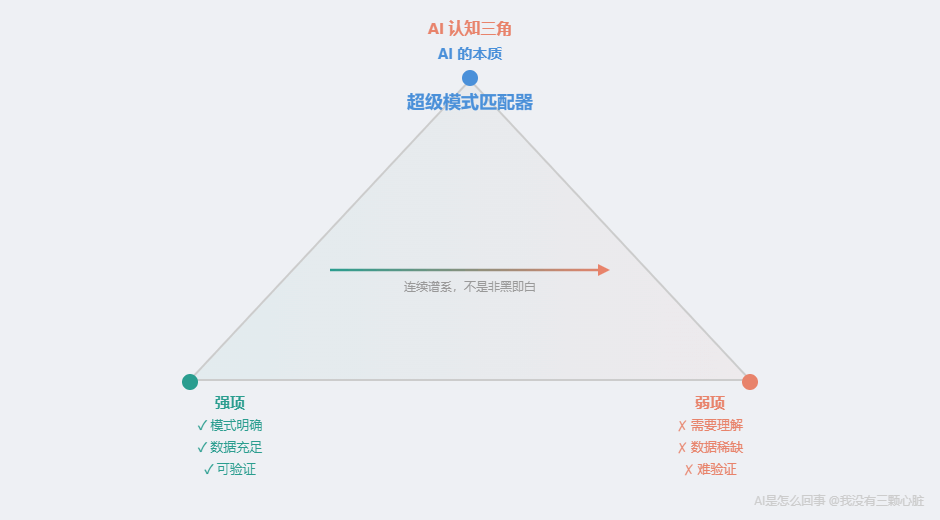
三个角,分别对应我们学过的三层知识:
顶角------AI 的本质:超级模式匹配器。 第一章的核心结论。第二章的每一个案例都在验证:ChatGPT 通过考试是模式匹配(第 9 篇),AI 画画不是"创造"而是从噪声中还原统计模式(第 10 篇),AlphaGo 赢棋、AlphaFold 预测蛋白质也是模式匹配(第 11 篇)。
左下角------强项三条件:模式明确、数据充足、可验证。 翻译、图像分类、蛋白质预测------凡是 AI 表现出色的领域,都满足这三个条件。
右下角------弱项三条件:需要理解、数据稀缺、难验证。 自动驾驶出错、AI 编造引用、算不对四位数乘法------凡是 AI 掉链子的地方,都踩中了至少一个。
这个三角形"永不过时"的原因: 它不依赖 AI 当前的能力水平,而是锚定在底层原理上。不管参数从千亿到万亿到十万亿,只要底层仍然是"在数据中寻找统计模式",这个三角形就成立。
为什么"做大"不能解决根本问题
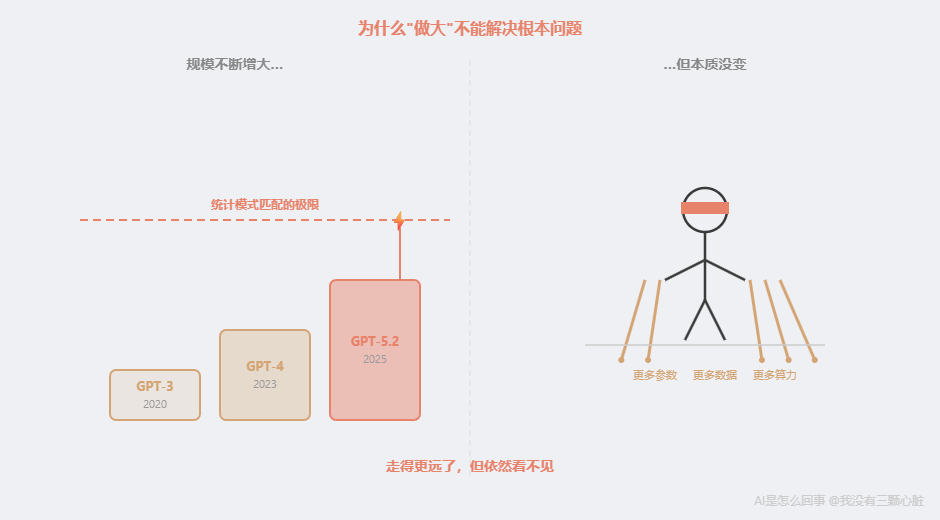
你可能会想:AI 变大变强了,不就能解决更多问题了吗?
确实。从 GPT-3(2020)到 GPT-4(2023),参数量翻了好几倍,能力飞跃------GPT-3 连律师考试都过不了,GPT-4 排进前 10%。到了 2025 年,GPT-5.2 在数学竞赛上拿下了满分。
但原理变了吗?
没有。 仍然是 Transformer 架构(第 6 篇),仍然是注意力机制,仍然是"预测下一个最可能的词"。变的是规模,不是本质。
"那推理模型呢?"你可能会想。2024-2025 年出现的推理模型(o1、o3)似乎换了一种玩法------让 AI 在回答前先"思考"。但第 9 篇告诉我们:推理模型在事实问答上幻觉率反而更高(33%-48%),Apple 研究发现换个数字就做错,高复杂度时所有模型崩溃至 0%。 连 OpenAI 联合创始人 Ilya Sutskever 都在 2025 年底公开表示:"再增加 100 倍规模会有所不同,但不会从根本上改变 AI 能力"。
不仅"做大"没改变本质,连"换一种思路(推理模型)"也没有突破根本局限。
这不只是我的判断。AI 领域最顶尖的科学家们都在讨论同一个问题。
Meta 首席 AI 科学家 Yann LeCun(2018 年图灵奖得主)公开表示,大语言模型是"通往 AGI 的一条岔路"------他认为仅靠预测下一个 Token 不可能实现通用智能。
认知科学家 Gary Marcus 多年来警告,统计模式匹配无法实现真正的理解。他举过一个有说服力的例子:大语言模型可以"复述国际象棋规则",甚至能正确回答"皇后能不能跳过骑士?"------但真的下棋时,却走出违规的棋步。它记住了关于规则的文字模式 ,但没有建立棋盘的内部模型。
回忆第 1 篇:AI"看"图片不是真的在看,是在数字矩阵中加减乘除。第 7 篇:AI"说话"不是真的在思考,是在续写统计上最可能的下一个词。
做大模型,就像给一个盲人更多的拐杖------走得更远了,但依然看不见。
突破天花板需要什么?
如果"做大"解决不了根本问题,什么能?
目前最被讨论的两个方向。但我不想只列方向名称就跳过------我想让你真正理解,为什么这两条路这么难走。
世界模型(World Models)
还记得第 11 篇那个自动驾驶事故吗?2016 年,一辆白色卡车横在高速路中间,Tesla 的 AI 把卡车白色车身识别成了天空的一部分,径直撞了上去。
当前的 AI 看到"大面积白色",匹配到"天空"这个模式,于是判断"前方无障碍,继续行驶"。它做的是模式匹配------在训练数据中,"大面积白色出现在道路上方"这个模式确实最常对应天空。
但人类不是这么处理的。人类司机看到前方有一个"物体"时,脑中会自动运行一个因果模拟:前方有东西 → 东西会挡路 → 继续开会撞上 → 我应该刹车。这个推理过程不依赖于那个东西是什么颜色、像不像天空------哪怕是你从未见过的东西,你也知道该减速。
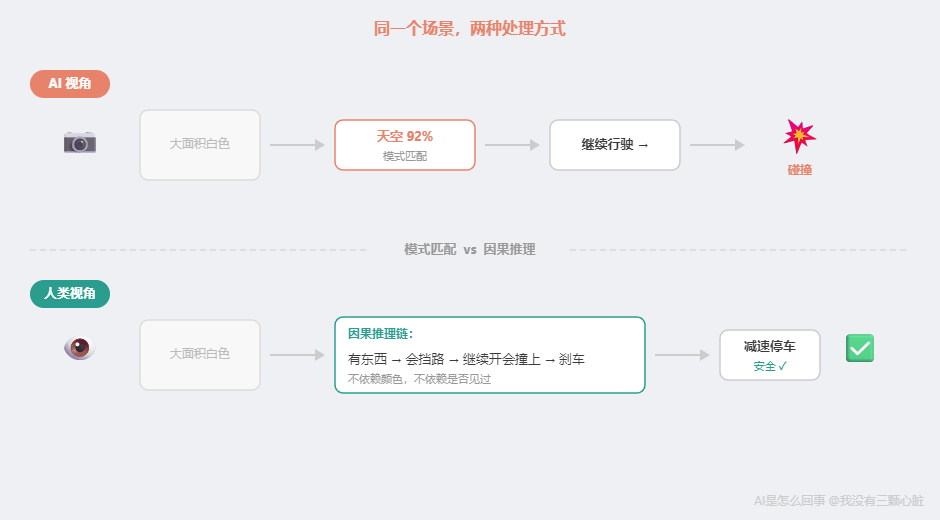
世界模型要做的,就是让 AI 内部拥有这种模拟。 不是在文字中匹配"苹果松手会掉下去"这句话,而是在内部建立对重力的模拟------输入"松手",自动推演出"掉落"。Yann LeCun 主攻的方向正是这个。
但为什么这么难?因为"在数据中找统计规律"和"在内部模拟物理世界"是两种完全不同的能力。现在的 AI 只会前者------你给它再多的数据、再大的参数量,它学到的仍然是"什么东西经常和什么东西一起出现"。它不理解"为什么"。从统计规律到因果模拟,不是把现有方法做得更好的问题,而是需要发明一种全新的内部表征方式------让 AI 内部有一个"世界",而不只是一本"词典"。
神经符号融合(Neuro-Symbolic AI)
再看 Gary Marcus 的国际象棋例子。大语言模型能"背诵"象棋规则------你问它"皇后能不能跳过骑士",它正确回答"不能"。但真的下棋时,它走出了让皇后穿越骑士的棋步。
这暴露了一个根本性的裂缝:AI 记住了"关于规则的文字",但没有在每走一步时去"检查这步棋是否符合规则"。前者是模式匹配------在训练数据中见过"皇后不能跳过其他棋子"这句话。后者是逻辑推理------在棋盘上逐步验证"从 A4 到 D7 的路径上有没有其他棋子"。
神经符号融合要做的,就是把这两种能力接在一起。 让神经网络负责"感知"------看懂棋盘、读懂题目,然后把结果交给符号逻辑系统------精确地检查规则、执行推理。一个负责"看",一个负责"想"。Gary Marcus 长期倡导的正是这个方向。
但难在哪?难在"接"这个动作本身。神经网络的语言是概率------"这步棋有 87% 的概率是好棋"。符号逻辑的语言是确定性------"这步棋合法或不合法"。把一个模糊的系统和一个精确的系统融合成一个整体,目前还没有人找到可靠的方法。就像让一个凭直觉做决定的人和一个只认规则的人合作------两个人各自很强,但配合起来经常互相矛盾。

为什么这些方向远比"做大模型"难
世界模型和神经符号融合有一个共同点:它们需要的不是改良现有机制,而是发明全新的机制。
当前 AI 的全部能力------理解文字、识别图像、生成代码------都来自同一个基础:在数据中找统计规律。这个机制经过十年的工程优化,已经非常成熟。从 GPT-3 到 GPT-5.2,本质上是同一条路走得更远------更多数据、更多参数、更多算力。
但世界模型需要 AI 学会"模拟",神经符号融合需要 AI 学会"推理"。这两种能力都不是"在更多数据中找更多统计规律"能得到的。它们要求一种全新的底层机制,并且还要和现有的模式匹配机制无缝整合。
这不是工程优化,是科学突破。 打个比方:从 GPT-3 到 GPT-5.2 是"修更宽的高速公路"------工程很大,但原理是现成的。而世界模型和神经符号融合是"发明飞机"------不是把路修得再好就能飞起来,你需要一套全新的物理原理。
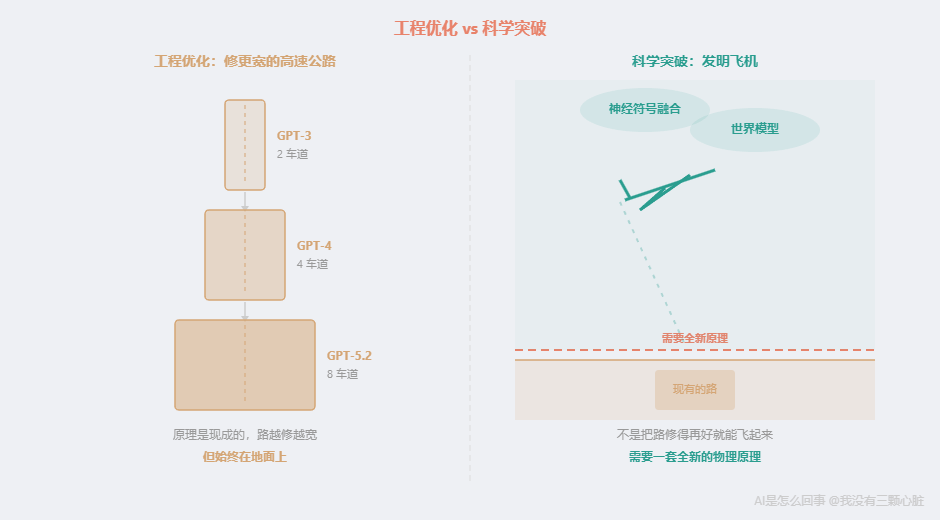
而第 9 篇提到的 ARC-AGI-2 基准测试(测试抽象推理能力),或许是目前最好的"突破探测器"------人类平均 60%,最好的 AI 只有 52.9%,而且人类能做对的题 100% 都能解决。当 AI 在 ARC-AGI 上真正超越人类的那一天,才是框架需要重新审视的时候。
那 AGI(通用人工智能)还有多远?根据 AI Impacts 对 AI 研究者的大规模调查(2023),约半数专家认为到 2047 年有 50% 的概率实现 AGI,但也有研究者认为 2032 年实现 AGI 的可能性极低。
这意味着什么?在可预见的未来,AI 的底层仍然是统计模式匹配。你的框架是安全的。
新闻速判
好了,回到开头的三条新闻。现在用三问判断法做一次速判。
新闻一:ChatGPT 通过了美国医学执照考试
三问速判:选择题是典型模式匹配任务 ✓ 训练数据中有海量医学教科书和考试材料 ✓ 选择题有标准答案可验证 ✓ ------三个条件全满足。
完全靠谱。ChatGPT(GPT-3.5)确实在 USMLE 三部分均接近或达到约 60% 的及格线,GPT-4 更是在大部分科目达到 83%-100%。
但"通过考试"不等于"能行医"------考试有标准答案,真实诊断没有。模式匹配的胜利,不是"AI 可以当医生"的证据。
新闻二:AI 预测蛋白质结构获诺贝尔奖
三问速判:从序列到结构是明确的映射(模式匹配)✓ 几十年积累 17 万个高质量数据(充足)✓ 可和实验测定直接对比(可验证)✓ ------三个条件完美满足。
教科书级别的案例。当三个条件完美满足时,AI 可以做出诺贝尔奖级别的贡献。
新闻三:AI 写的学术论文骗过了同行评审
三问速判:
- 格式层面:写出"看起来像论文的文字"是模式匹配 ✓ 论文格式的训练数据充足 ✓
- 内容层面:做出"有科学价值的研究"不是模式匹配 ✗ 真正的创新意味着训练数据里没有的东西 ✗ "有没有科学价值"需要深入审查 ✗
Wiley 旗下的 Hindawi 撤回了超过 11,300 篇论文,其中相当部分涉及"论文工厂"和 AI 生成内容。斯坦福研究者发现约 17% 的同行评审可能由 AI 生成。
AI 能写出"像"论文的东西,但"像"不等于"是"------它不关心真假。

速查表
把三问的不同组合整理成一张速查表:
| 模式匹配? | 数据充足? | 能验证? | AI 可信度 | 你该怎么做 |
|---|---|---|---|---|
| 是 | 是 | 是 | 很高 | 放心用,抽查即可 |
| 是 | 是 | 否 | 中等 | 用,但关键部分人工复核 |
| 是 | 否 | --- | 较低 | 谨慎用,AI 可能在"编" |
| 否 | --- | --- | 低 | 仅做参考,必须专家复核 |

四条永不过时的原则
速查表给了快速判断的工具,但工具背后需要原则支撑。
原则一:把 AI 当助手,不要当专家
AI 是世界上最好的助手,但不是专家。助手帮你做事,专家替你做决定。这个区别至关重要。
原则二:场景越常见,AI 越可靠
场景越常见,AI 越可靠。场景越罕见,AI 越不可靠。
原则三:关键信息永远要验证
AI 不会对你撒谎------因为它不知道什么是"谎言"。但它会用极其自信的语气告诉你一个不存在的东西。涉及事实信息------数据、日期、人名、引用------永远自己验证。
原则四:今天的判断框架,明年依然适用
AI 会继续变强------能处理更复杂的任务、犯更少的低级错误。但只要底层仍是统计模式匹配,判断框架就依然有效。

个人锚点
写到这里,我想回头看看第二章这趟旅程。
第 9 篇的时候,我拆解 ChatGPT 的"成绩单"------从 2023 年的 GPT-4 到 2026 年的推理模型------发现"AI 有多聪明"这个问题本身就是错的,连研究 AI 的人也在困惑。那一刻,第一章的"超级模式匹配器"从抽象概念变成了可以解释真实现象的工具。
第 10 篇,我拆解 AI 绘画,发现"创造"也只是另一种模式匹配。核心模型从文字扩展到了图像,经受住了第二次验证。
第 11 篇,我们把所有领域摆在一起,一条分界线从数据中浮现。散落的知识连成了一张地图,三问判断法从地图中长了出来。
到了这一篇,我们把地图折叠成了一个可以装进口袋的指南针------AI 认知三角。更重要的是,我们看到了天花板:不是 AI 不够大,而是"在数据中找统计规律"这个方法本身有极限。突破需要的不是更大的模型,而是全新的科学原理。
让我最有感触的是一个认知上的转变。第 9 篇之前,我看 AI 新闻的方式是"AI 又能做什么了"------每条新闻都让我在"太厉害了"和"好像也不行"之间摇摆。第 12 篇之后,我看 AI 新闻变成了"这属于谱系的哪个位置"------三个问题一过滤,每条新闻都有了清晰的定位。
不是 AI 变了,是我看 AI 的眼睛变了。
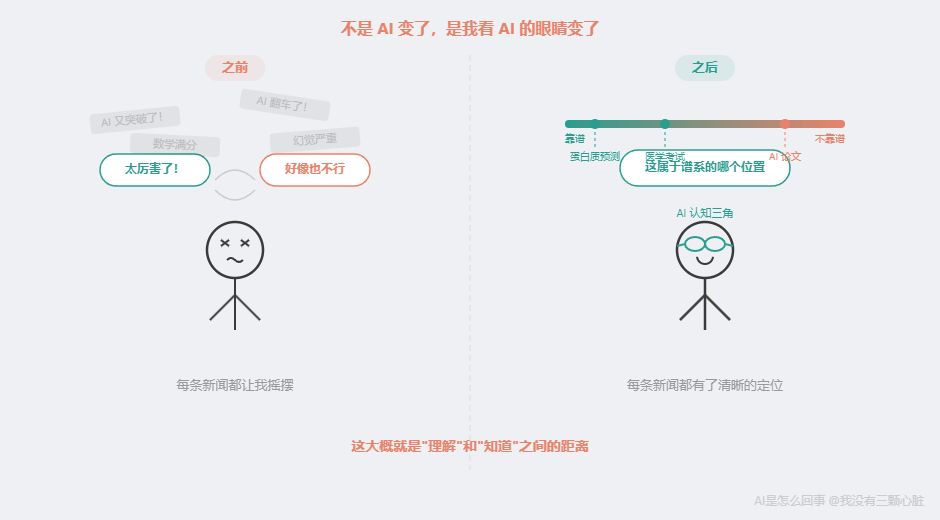
这大概就是"理解"和"知道"之间的距离。
第二章完整回顾
| 篇目 | 核心知识 | 一句话总结 |
|---|---|---|
| 第 9 篇 | AI 智能的碎片化,RLHF,推理模型悖论 | "AI 有多聪明"是错误的问题------连 AI 研究者也在困惑 |
| 第 10 篇 | Diffusion 模型,CLIP | "创造"也是模式匹配------从噪声中还原统计模式 |
| 第 11 篇 | 能力全景图,模式匹配谱系,三问判断法 | AI 的强弱取决于三个条件,三个问题就能判断 |
| 第 12 篇 | AI 认知三角,天花板,四条原则 | 框架锚定在 AI 的原理上,而非当前能力 |
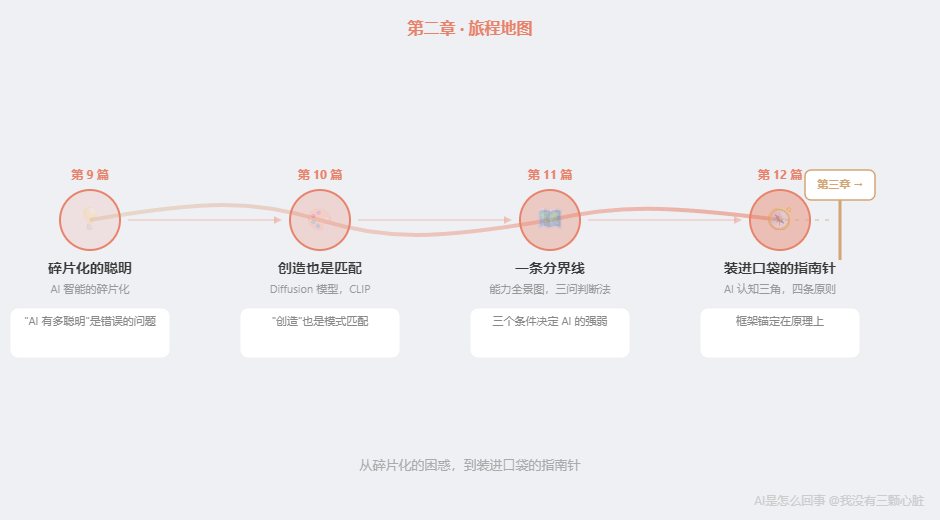
第二章的承诺: 读完这 4 篇,你将知道 AI 各领域的能力边界在哪里,理解什么条件下 AI 靠谱、什么条件下不靠谱,并且掌握一套可以随身携带的判断框架。
现在,你做到了吗?
如果做到了------欢迎来到第三章。
一句话回顾
AI 认知三角锚定的是 AI 的本质,不是它的当前能力。只要底层仍是统计模式匹配,三问判断法就不会过时------真正永不过时的,是你的判断力。
下一篇预告
你现在装备齐全了。
第一章,我们拆开了黑箱------AI 是什么?超级模式匹配器。
第二章,我们画出了边界------AI 靠不靠谱?三个条件决定一切。
但还有一个最实际的问题没回答:
知道了这些,怎么用好 AI?
同一个 ChatGPT,为什么有人用它效率翻 10 倍,有人觉得它"很蠢"?为什么同一句话换一种问法,回答质量就天差地别?
下一篇,我们从原理角度回答这个问题。你会发现,"怎么用好 AI"的答案,全部藏在我们前面 12 篇拆解过的原理里。
参考资料
- Kung, T.H., et al. (2023). Performance of ChatGPT on USMLE. PLOS Digital Health . https://pmc.ncbi.nlm.nih.gov/articles/PMC9931230/
- Brin, D., et al. (2023). Comparing ChatGPT and GPT-4 Performance in USMLE. Scientific Reports . https://www.nature.com/articles/s41598-023-43436-9
- Nobel Prize in Chemistry 2024. https://www.nobelprize.org/prizes/chemistry/2024/press-release/
- Van Noorden, R. (2024). AI tools tackle paper mill fraud. Chemistry World . https://www.chemistryworld.com/features/ai-tools-tackle-paper-mill-fraud-overwhelming-peer-review/4022253.article
- Liang, W., et al. (2024). Monitoring AI-Modified Content in Academic Peer Review. arXiv . https://arxiv.org/abs/2403.07183
- The Decoder. (2024). The case against predicting tokens to build AGI. https://the-decoder.com/the-case-against-predicting-tokens-to-build-agi/
- Marcus, G. (2025). The Great AI Retrenchment has begun. Substack . https://garymarcus.substack.com/p/the-great-ai-retrenchment-has-begun
- EA Forum. (2024). AGI by 2032 is extremely unlikely. https://forum.effectivealtruism.org/posts/sQSCqpm9Ymwiu8rdb/agi-by-2032-is-extremely-unlikely
- EA Forum. (2025). Highlights from Ilya Sutskever's November 2025 interview. https://forum.effectivealtruism.org/posts/iuKa2iPg7vD9BdZna/highlights-from-ilya-sutskever-s-november-2025-interview
- ARC Prize. (2025). ARC Prize 2025 Results Analysis. https://arcprize.org/blog/arc-prize-2025-results-analysis
订阅
如果觉得有意思,欢迎关注我,后续文章也会持续更新。同步更新在个人博客和微信公众号
微信搜索"我没有三颗心脏"或者扫描二维码,即可订阅。
