@TOC
1. 背景
大概就是有那么一个数仓,然后简略结构如下:
从其他封闭系统产生的日志文件,经由本系统的后端部分近线解析,将结果直接存入MySQL,而后由数仓部分使用Python脚本洗入Hive,但这实在是太慢了。
在代码当中埋了一些输出点之后,经过对行为日志的分析,我们发现最慢的部分是在数据转换的Python脚本部分
更进一步地,Python脚本的结构大概是:
也就是说,MySQL当中存储的是JSON格式的数据,原设计是直接向Elasticsearch进行推送的,后来追加了一个存入Hive的通道
那么进一步分析Python脚本的流程,大概是:
问题就出现在,Python脚本对MySQL数据解析状态的更新上
由于采用的是UPDATE且附带WHERE条件,所以每次更新状态的时候,似乎都会把整个表锁上,详见这个^1^和这个^2^
而且由于这个表同时还有推送ES的一个通道,可能还有其他地方在同时访问,所以整张表会锁很久
2. 优化
找到了症结,接下来就是想办法了
既然问题出现在数据回流上,那么能不能想办法去掉这个步骤?
经过对MySQL表结构的分析,我们发现其中的某个字段与时间戳相关
也就是说,这张表的数据,在这个字段上是有序的
那么我们可以将这个字段作为关键字,记录此次数据处理到了哪个位置
优化后的大致结构如下:
这样一来,数仓部分对这张表就只有读取部分,去掉写入,不再产生相关的锁,大大提升了运行效率
3. 改造
3.1. 重构
但是好景不长,过了一段时间,这部分的表现又不如人意,于是决定重构,大致的结构如:
此次将日志文件直接解析到HDFS,再通过Bash直接建表到Hive,最后推送至ES
数仓结构大概是:
APP直接从ODS加工有两个考虑:
-
其一是某个特殊字段仅在
APP有效,所以DWD没有保存,只能从ODS取数 -
其二是提高并行度,使得
DWD和APP可以同时加工
除此之外还有控制结构:
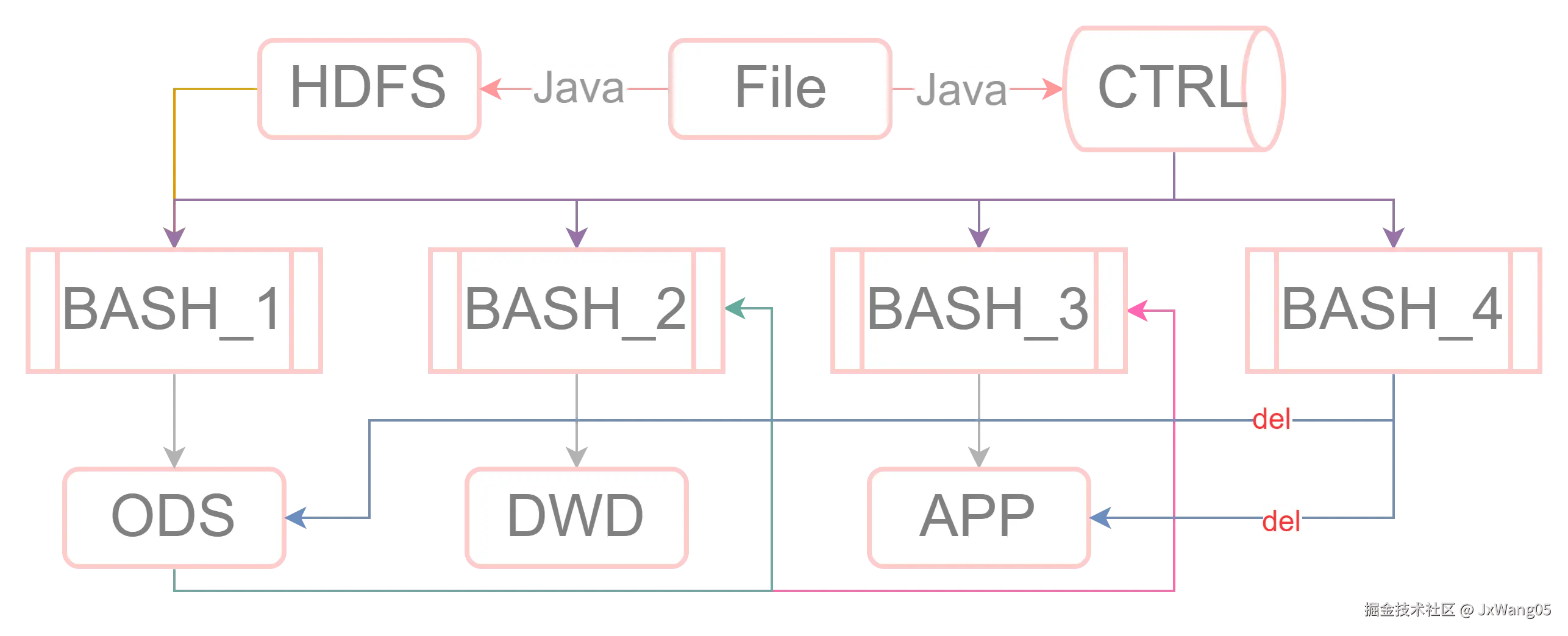 大概是,有四个控制脚本,有一个控制表
大概是,有四个控制脚本,有一个控制表
控制表的部分效果如下:
-
记录远程文件名称,及其解析到的对应的
HDFS文件的名称 -
记录该文件的解析状态,例如说已落
ODS
几个控制脚本的部分作用如下:
: 1.sh
markdown
1. 根据控制表当中的记录,选取还未处理的`HDFS`文件,在`Hive`当中建立对应的表
2. 处理完成之后更新这些记录的状态: 2.sh
markdown
1. 根据控制表当中的记录,选取已经落到`ODS`的表,加工数据到`DWD`
2. 处理完成之后更新这些记录的状态: 3.sh
markdown
1. 根据控制表当中的记录,选取已经落到`ODS`的表,加工数据到`APP`
2. 处理完成之后更新这些记录的状态: 3_5.sh
markdown
1. 根据控制表当中的记录,选取已经落到`APP`的表,推送数据到`ES`
2. 处理完成之后更新这些记录的状态
3. 此环节暂时跳过: 4.sh
markdown
1. 根据控制表当中的记录,选取已经落到`DWD`和`APP`的表,删除其在`ODS`的数据
2. 根据控制表当中的记录,选取已经推送到`ES`的表,且数据已过保留期限,删除其在`APP`的数据
3. 处理完成之后更新这些记录的状态该数仓使用Azkaban进行调度,设定自动任务为每10分钟自动运行一次。每次任务运行之前都会检查运行历史,如上次任务未结束则跳过此次运行,如连续失败五次则触发企业微信机器人进行预警,其他情况正常运行
由于各部分互不依赖,则可以设置成平行结构:
3.2. 优化
首先是关于bash_1的,我们发现解析到HDFS的文件体量过小,影响运行效率,故决定先进行一个HDFS文件的合并,使用hdfs dfs -cat,传入多个文件的路径,将其输出到Hive表的文件夹下,合并成为一个文件
然后是结构问题,原平行结构对环境的影响压力过大,在合并小文件后运行效率有所提升,在不触及数据更新容忍度的情况下,将Azkaban改为顺序结构,人为的加上依赖