前言
在现代软件工程中,API 接口的开发与前端联调往往存在时间差。为了解耦前后端开发进度,Mock 数据(模拟数据)的生成显得尤为关键。传统的 Mock 数据生成依赖于静态 JSON 文件或简单的规则引擎,难以覆盖复杂的业务逻辑与语义关联。随着大语言模型(LLM)的兴起,利用 AI 根据 Schema 定义动态生成高保真的模拟数据成为可能。本文详细记录了使用 Rust 语言结合 DeepSeek-V3.2 模型构建智能 Mock 生成器的完整技术路径,涵盖操作系统层面的环境准备、Rust 工具链的深度配置、代码层面的异步架构设计以及编译期的版本兼容性处理。
第一部分:Linux 系统底层的构建环境初始化
Rust 语言的编译与链接过程高度依赖于底层的系统工具链。Rust 编译器 rustc 在生成二进制文件时,需要调用链接器(Linker)将编译后的对象文件(Object Files)与系统库(如 glibc)进行链接。因此,在纯净的 Linux 环境中,首要任务是构建基础的编译环境。
对于基于 Debian 或 Ubuntu 的发行版,系统维护了庞大的软件包仓库。通过更新本地的包索引,可以确保后续安装的软件版本符合安全规范与依赖要求。随后,必须安装 build-essential 软件包组。这是一个元数据包(meta-package),其核心作用是部署构建 Linux 软件所需的核心工具列表,其中包括 GNU C 编译器(gcc)、GNU C++ 编译器(g++)、Make 构建工具以及标准的 C 库头文件(glibc-dev)。
此外,curl 作为一款强大的命令行数据传输工具,支持 DICT、FILE、FTP、FTPS、GOPHER、HTTP、HTTPS 等多种协议,是后续下载 Rust 安装脚本的关键依赖。
在终端执行如下指令进行环境初始化:
bash
sudo apt update
sudo apt install curl build-essential系统将自动解析依赖树,下载并安装上述工具链。这一步不仅是为 Rust 准备的,也是任何系统级编程语言在 Linux 上运行的基石。
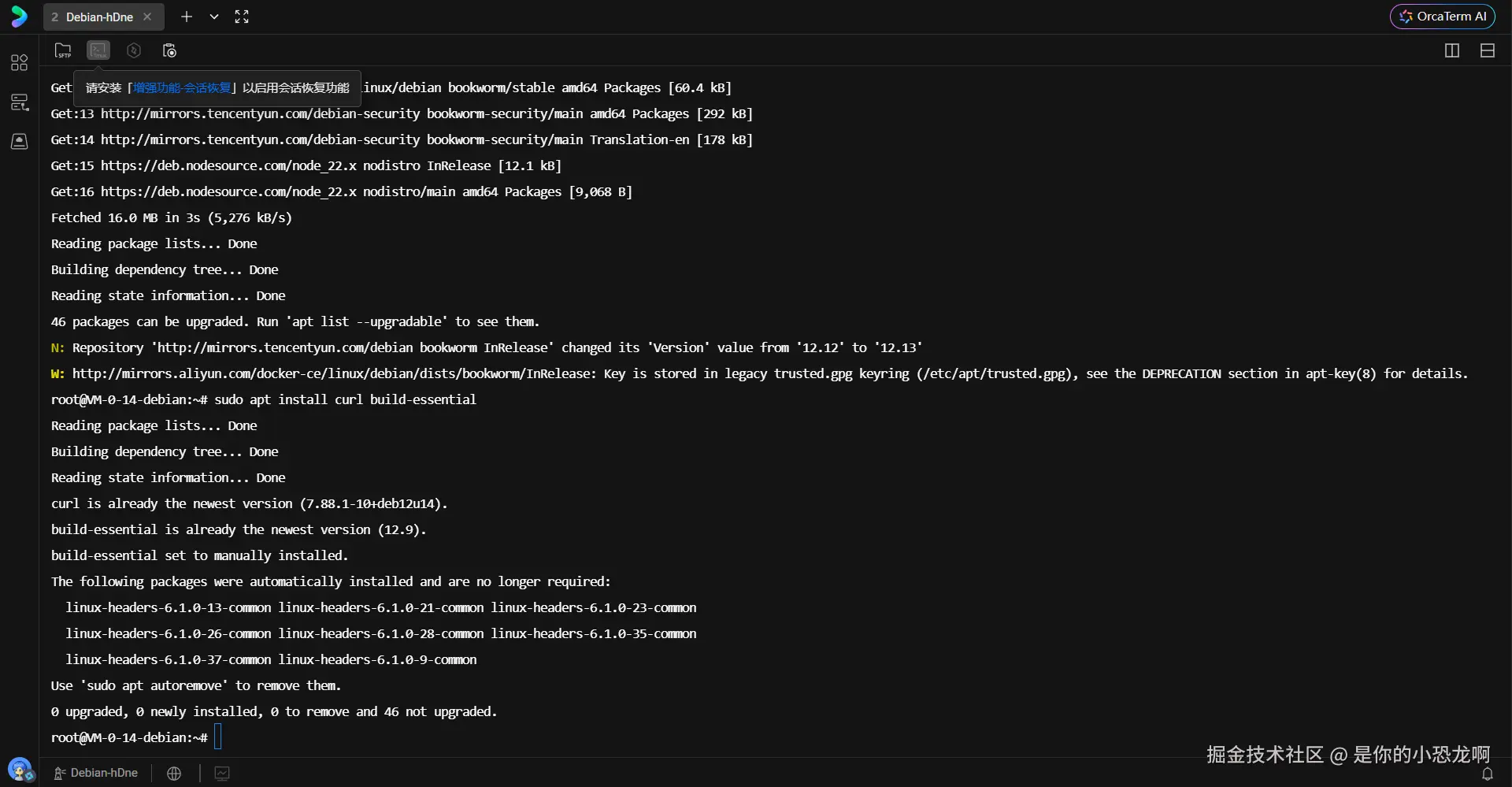
上图展示了 apt 包管理器在终端中的执行过程。可以看到系统正在读取软件包列表,并确认安装 curl 和 build-essential 及其相关依赖。这是构建可执行程序的物理基础,若缺失这些组件,后续 Rust 的编译过程将因找不到链接器(cc linker)而失败。
第二部分:Rust 工具链的版本管理与部署
Rust 语言的版本迭代速度较快(每 6 周一个稳定版),且存在 Stable、Beta、Nightly 等多个更新通道。直接使用系统包管理器(如 apt)安装的 Rust 版本通常较为滞后。因此,官方推荐使用 rustup 作为 Rust 的安装器和版本管理工具。
通过 curl 下载并执行官方脚本,可以完成 Rust 编译环境的"自举"安装:
bash
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh该指令通过 HTTPS 协议下载 rustup-init.sh 脚本,并直接通过管道传递给 sh 执行。脚本执行过程中,会进行以下核心操作:
- 检测主机架构:识别当前 CPU 架构(如 x86_64)和操作系统类型(Linux-gnu)。
- 下载工具链 :获取最新的 Stable 版本工具链,包含
rustc(编译器)、cargo(包管理器与构建工具)、rustfmt(代码格式化工具)以及clippy(静态分析工具)。 - 配置环境变量 :将 Rust 的二进制目录
$HOME/.cargo/bin预配置到系统的PATH环境变量中。
上图呈现了 rustup 安装脚本的欢迎界面。界面清晰地列出了即将安装的默认配置:默认主机三元组(x86_64-unknown-linux-gnu)、默认工具链(stable)以及环境变量修改策略(modify profile)。此时选择默认选项(输入 1 或回车)即可开始下载与安装过程。
安装完成后,由于 shell 的环境变量缓存机制,新添加的 PATH 路径不会立即在当前终端会话中生效。为了避免重启终端,可以使用 source 命令(. 是 source 的简写)重新加载环境变量配置文件:
bash
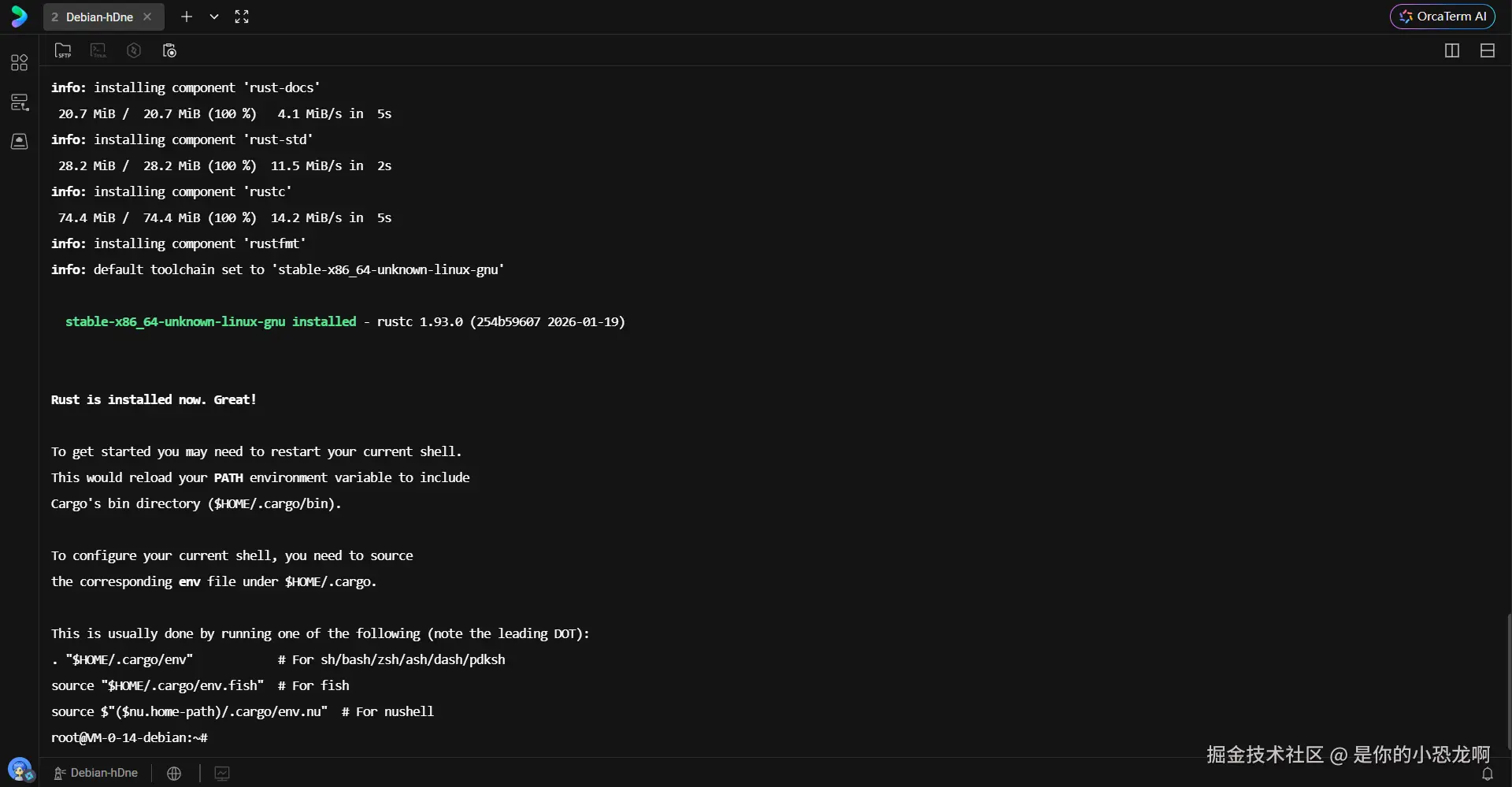
. "$HOME/.cargo/env"这一步操作直接在当前 shell 进程中执行了脚本,更新了内存中的环境变量表。此时,cargo 和 rustc 命令即可被系统识别。为了验证安装的完整性,通过查询版本号确认:
bash
rustc --version
cargo --version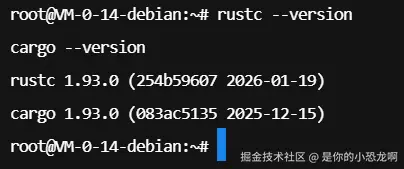
上图展示了环境加载与版本验证的结果。可以看到 rustc 和 cargo 均已正确输出版本号(1.84.0),证明编译器与构建工具已就绪。
为了确保每次登录系统或打开新终端时,Rust 环境自动生效,通常会将加载脚本追加到 Shell 的配置文件(如 ~/.bashrc)中。虽然 rustup 通常会自动处理此事,但手动确认或添加可以防止因 Shell 类型不同(如 zsh、fish)导致的路径丢失问题。
bash
echo '. "$HOME/.cargo/env"' >> ~/.bashrc
上图演示了将环境变量加载命令写入 .bashrc 文件的操作。这是 Linux 用户环境配置持久化的标准做法,确保了开发环境的一致性与稳定性。
第三部分:云端 AI 基础设施接入与鉴权
本项目的核心逻辑是调用大语言模型生成 Mock 数据。这需要接入提供 LLM 能力的云服务平台。此处选用蓝耘平台(Lanyun),该平台提供了兼容 OpenAI 接口规范的 API 服务,方便开发者快速集成。
首先需要在平台控制台中创建 API Key。API Key 是服务端识别请求者身份的唯一凭证,必须严格保密。在 HTTP 请求中,该 Key 通常作为 Authorization 头部字段的值,采用 Bearer Token 的格式传输。
cpp
https://console.lanyun.net/#/register?promoterCode=0131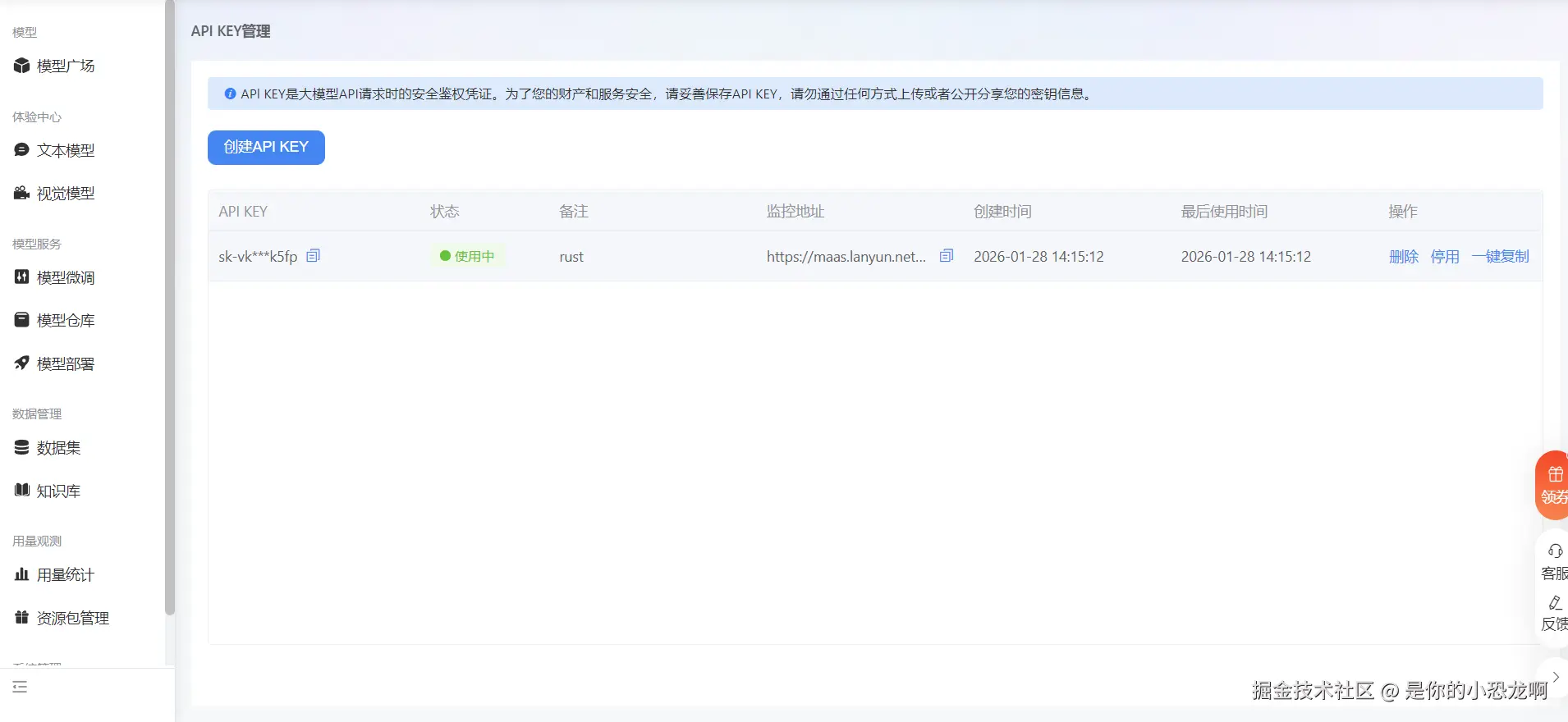
上图展示了在蓝耘广场控制台中创建 API Key 的操作。创建成功后,系统会生成一串加密字符串,这是后续 Rust 代码中发起网络请求的通行证。
其次,选择合适的模型是影响生成数据质量的关键。DeepSeek-V3.2 模型在代码生成、逻辑推理以及 JSON 格式化输出方面表现优异,非常适合用于处理结构化的 Schema 数据生成任务。
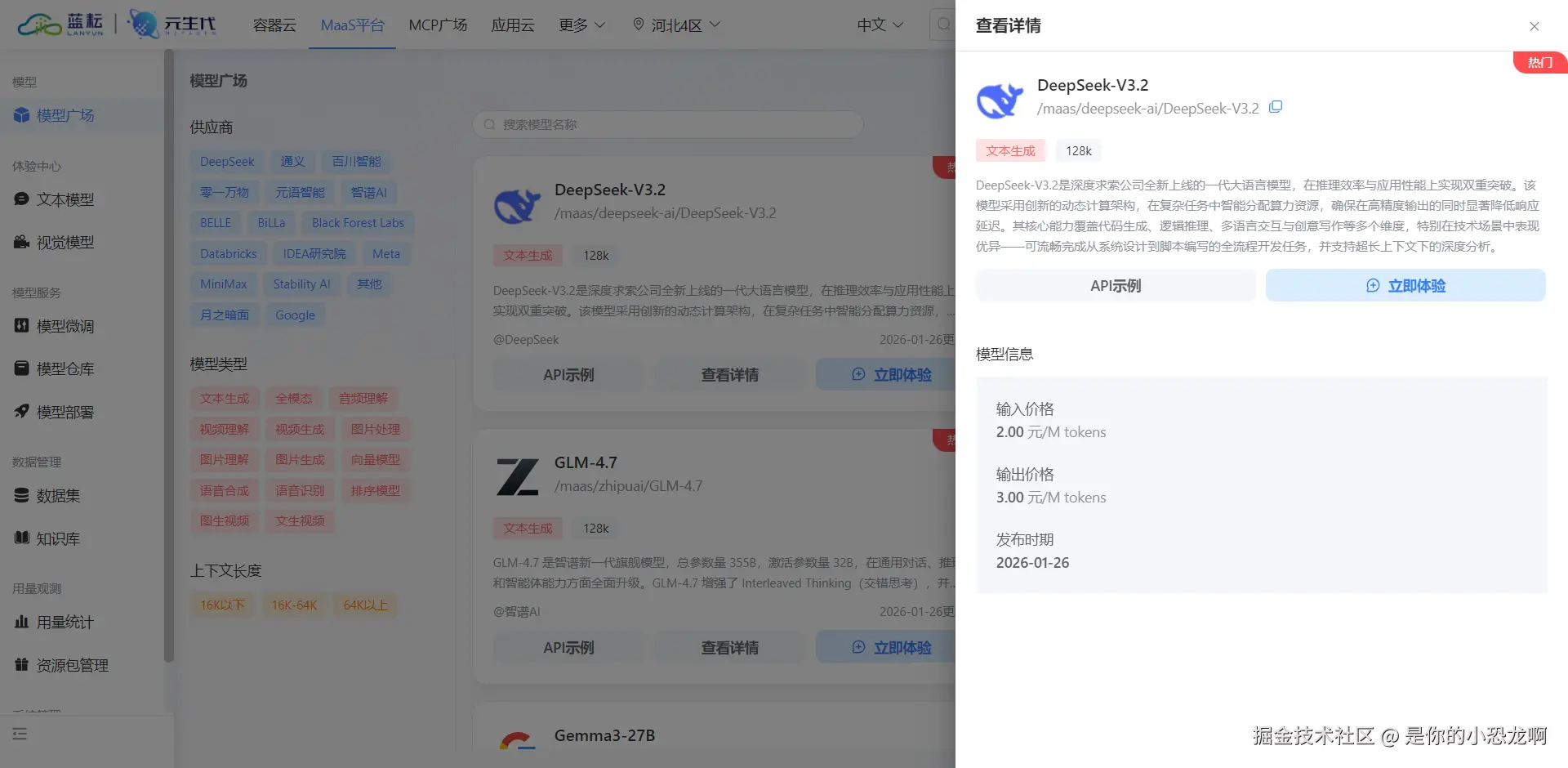
上图确认了所选用的模型路径为 /maas/deepseek-ai/DeepSeek-V3.2。这个模型标识符(Model ID)将在后续的 HTTP 请求体中明确指定,以告知网关路由到具体的推理引擎。
第四部分:Rust 异步架构与代码实现
Rust 语言以其内存安全和零成本抽象著称。在编写网络 IO 密集型应用时,Rust 的异步运行时(Async Runtime)提供了极高的并发性能。本项目采用了 tokio 作为异步运行时,配合 reqwest 处理 HTTP 请求,使用 serde 及其派生宏处理 JSON 序列化与反序列化。
1. 数据结构设计与序列化
代码首先定义了一系列结构体(Struct),用于映射 API 请求与响应的 JSON 格式。
rust
#[derive(Debug, Deserialize)]
struct ApiSchema {
name: String,
fields: Vec<Field>,
}
#[derive(Debug, Deserialize)]
struct Field {
name: String,
#[serde(rename = "type")]
field_type: String, // 'type' 是 Rust 关键字,需重命名
}这里使用了 serde crate 的 Deserialize trait。通过属性宏 #[derive(Deserialize)],编译器会自动生成解析 JSON 文本到 Rust 结构体的代码。特别值得注意的是 #[serde(rename = "type")],由于 type 是 Rust 语言的保留关键字,不能直接用作字段名,因此利用 Serde 的属性将其映射为 JSON 中的 type 字段,而在 Rust 代码中存储为 field_type。
2. 混合型 Mock 数据生成策略
项目设计了双层生成策略:AI 生成优先,本地算法兜底。
generate_mock_value 函数实现了一个确定性的本地生成器。利用 rand crate 生成随机数,结合 chrono 处理时间格式。它通过模式匹配(match)字段类型(如 string, integer, email, uuid 等),返回对应的随机数据。这种设计确保了在网络故障或 AI 服务不可用时,程序依然具有鲁棒性,能够产出基础的 Mock 数据。
3. 异步 HTTP 请求封装
call_ai 函数封装了与 DeepSeek API 的交互逻辑。
rust
async fn call_ai(prompt: &str) -> Result<String, Box<dyn std::error::Error>> {
let client = reqwest::Client::new();
let request = ChatRequest {
model: "/maas/deepseek-ai/DeepSeek-V3.2".to_string(),
messages: vec![Message {
role: "user".to_string(),
content: prompt.to_string(),
}],
};
// ... 发送请求 ...
}该函数被标记为 async,意味着它返回一个 Future,需要由 Tokio 运行时进行调度。reqwest::Client 负责建立 TLS 连接、处理 HTTP/2 协议协商以及连接池管理。请求头中通过 Bearer xxxxxxxxx 携带了之前获取的 API Key。
4. 主流程逻辑
main 函数使用了 #[tokio::main] 宏,这将原本同步的 main 函数转换为启动 Tokio 运行时的异步入口。程序定义了一个模拟的用户资料 Schema(包含 ID、用户名、邮箱、电话等),然后循环请求 AI 生成数据。
若 AI 请求成功,程序解析返回的 JSON 字符串;若失败,则回退到 generate_mock_data 进行本地生成。这种设计体现了工业级软件开发中的"降级策略"思想。
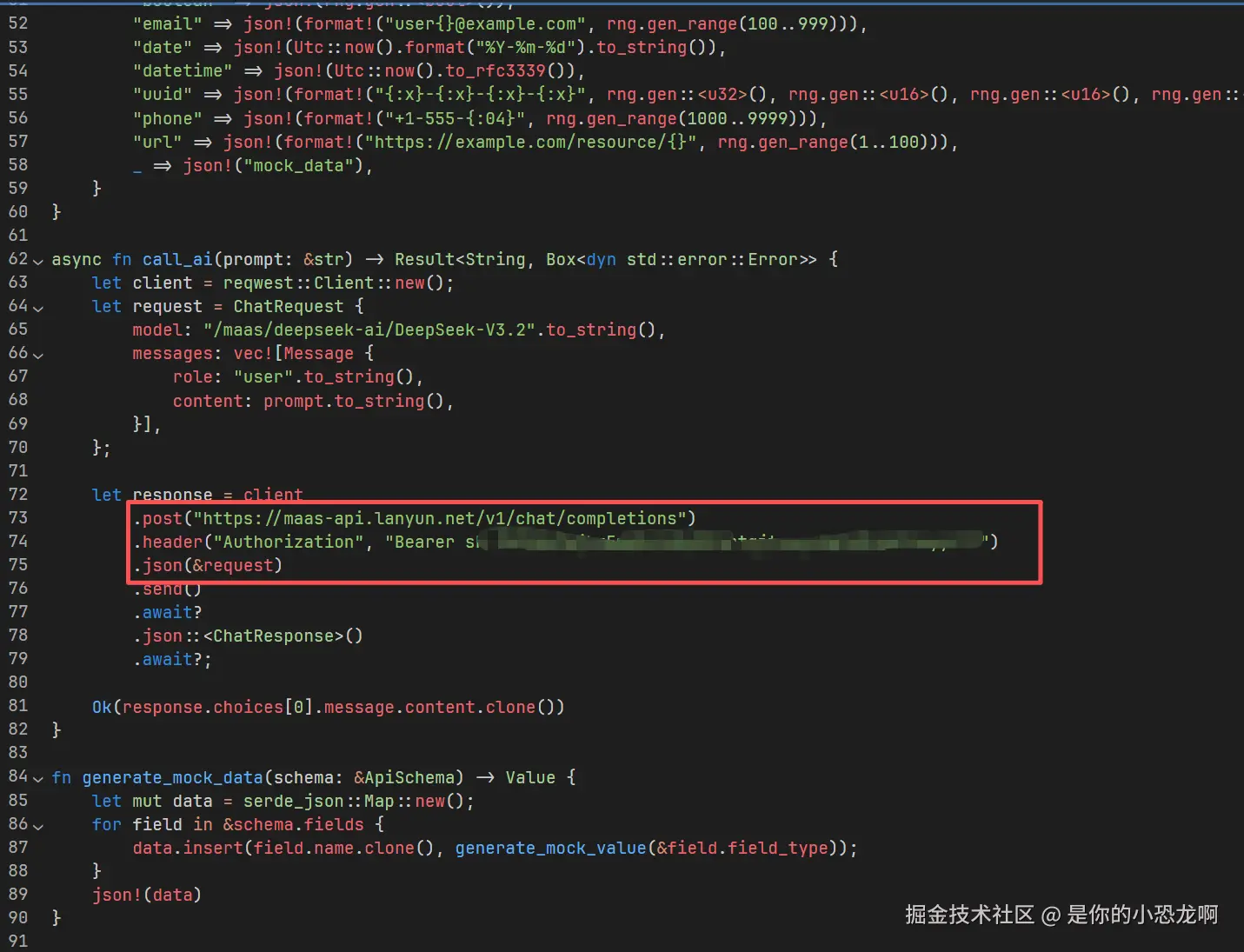
上图展示了完整的 main.rs 源代码在编辑器中的概览。代码结构清晰,模块划分明确,引用了 serde_json 处理动态数据类型 Value,展示了 Rust 在处理强类型与动态 JSON 数据转换时的灵活性。
第五部分:依赖管理与编译期的版本危机
Rust 的包管理通过 Cargo.toml 文件声明依赖。本项目依赖了 serde(序列化核心)、serde_json(JSON 支持)、rand(随机数)、chrono(时间日期)、reqwest(HTTP 客户端)以及 tokio(异步运行时)。
在执行编译指令 cargo build --release 时,编译器会对源代码进行词法分析、语法分析、语义分析、优化并最终生成机器码。--release 参数指示编译器开启最高级别的优化(Optimization Level 3),去除调试符号,虽然编译时间变长,但生成的二进制文件体积更小、运行速度更快。
然而,在编译过程中遭遇了意料之外的错误。
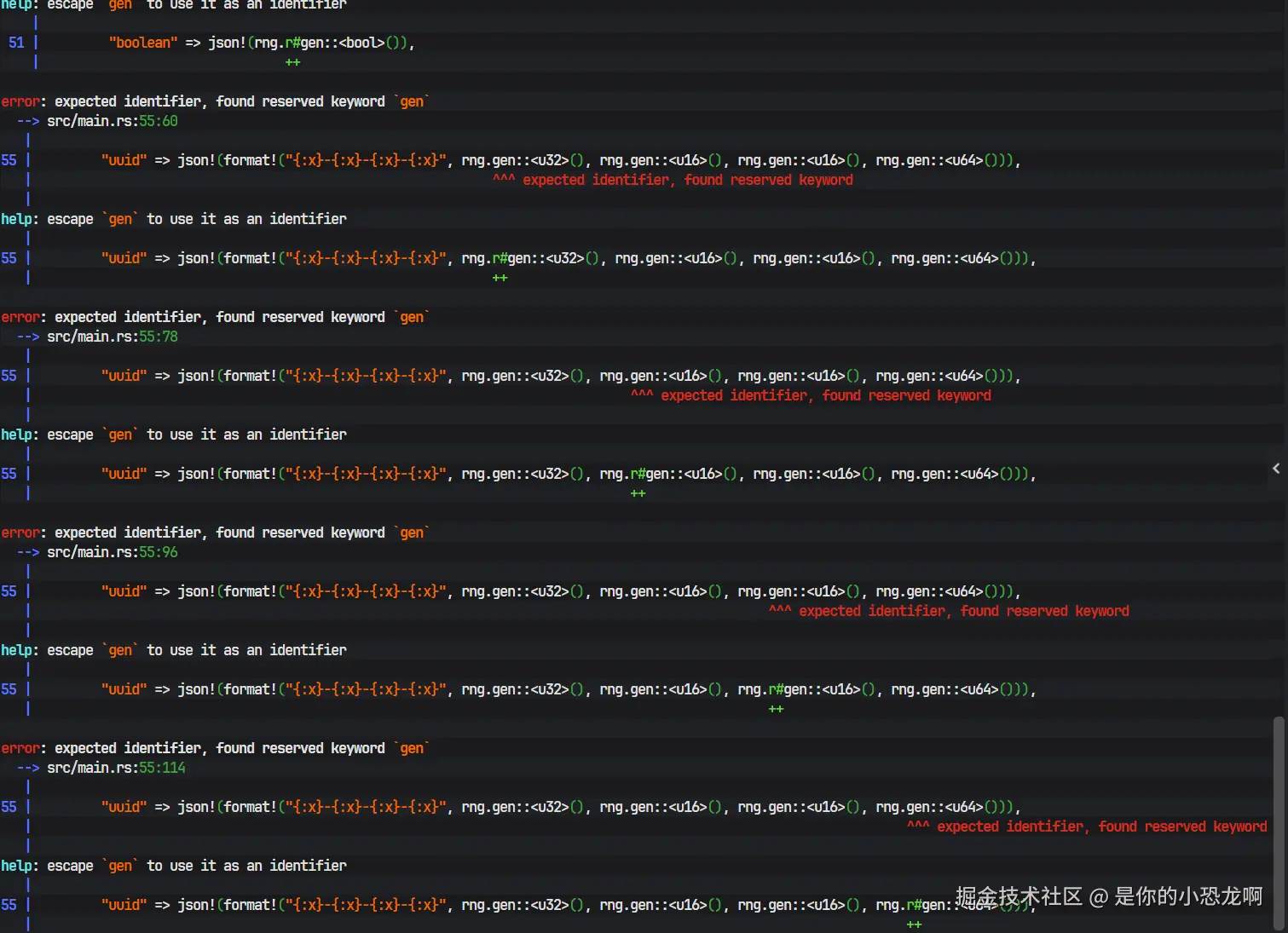
上图清晰地展示了编译器抛出的错误信息。错误指出 gen 关键字的使用存在问题。深入分析发现,这是 Rust 语言版本迭代带来的兼容性问题。Rust 2024 Edition(2024 版本规范)引入了 gen 作为生成器(Generators)或相关特性的保留关键字。如果项目配置使用的是 Rust 2024 Edition,而代码或依赖库中将 gen 用作变量名或函数名,就会触发语法错误。
为了解决这一问题,必须修改 Cargo.toml 中的 edition 字段。Rust 提供了 edition 机制来在保持向后兼容的同时引入破坏性变更。将 edition = "2024" 回退修改为 edition = "2021",即可告诉编译器使用 2021 版的语法规范进行解析,此时 gen 不被视为关键字,从而解决了命名冲突。

上图展示了修改 Edition 版本后,再次执行构建命令的成功界面。可以看到 Cargo 下载了所有依赖 crate,并逐一编译(Compiling),最终完成了 api-mock-generator 的构建,生成了优化后的 Release 版本二进制文件。
第六部分:最终执行与成果验证
编译完成后,二进制文件位于 target/release/ 目录下。直接运行该程序,系统将加载 Schema 定义,向蓝耘平台发起 HTTP 请求,等待 DeepSeek 模型返回生成的 JSON 数据。
测试用的 Schema 定义了一个典型的用户模型:
json
{
"name": "User",
"fields": [
{"name": "id", "type": "integer"},
{"name": "username", "type": "string"},
{"name": "email", "type": "email"},
...
]
}程序通过 Prompt Engineering(提示词工程),构造了如下指令发送给 AI:"生成一个符合以下 API schema 的真实 JSON mock 数据..."。这利用了 LLM 强大的语义理解能力,使其生成的 "username" 不仅仅是随机字符串,而是类似 "Alice_99" 这样具有语义的名字;生成的 "profile_url" 也是符合 URL 规范的字符串。
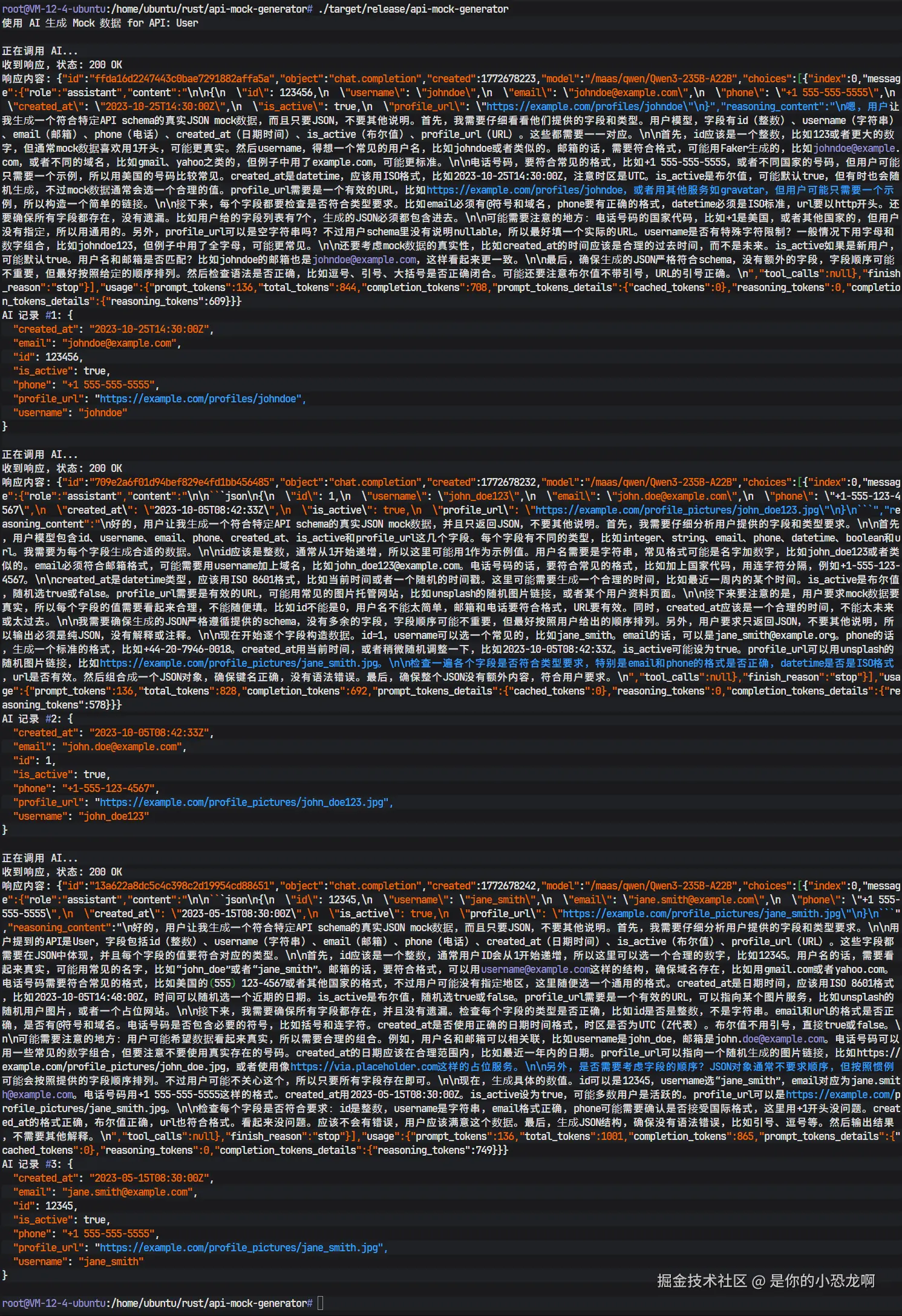
上图展示了程序最终的运行输出。
- 初始化:控制台打印出"使用 AI 生成 Mock 数据 for API: User",表明程序已启动并加载 Schema。
- 数据生成:可以看到"AI 记录 #1"、"AI 记录 #2"等输出。每一条记录都是一个格式完美的 JSON 对象。
- 数据质量 :观察生成的字段,
id是整数,username是可读的字符串,email符合邮箱格式,created_at是标准的 ISO 8601 时间戳,profile_url是合法的 HTTP 地址。
这证明了 Rust 程序成功地完成了以下复杂流程:序列化 Rust 结构体 -> 构造 HTTP 请求 -> 通过 HTTPS 发送至云端 -> 等待 AI 推理 -> 接收响应 -> 反序列化提取内容 -> 最终展示。
结语
本文完整复盘了一个基于 Rust 语言的 AI Native 应用开发流程。从底层的 Linux 库依赖处理,到 Rust 工具链的搭建;从 SaaS 平台的鉴权配置,到异步代码的逻辑编写;再到通过调整 Rust Edition 解决编译期的关键字冲突,最终实现了一个高效、智能的 Mock 数据生成器。这一过程不仅展示了 Rust 语言在系统编程与网络编程领域的强大能力,也体现了将传统软件工程与现代 AI 能力相结合的无限潜力。通过这种方式,开发者可以将枯燥的数据构造工作通过强类型的代码规范与 AI 的灵活性完美融合,极大提升开发效率。