你有没有遇到过这种场景------
你写了一个函数,需要接受一个"回调",但这个回调可能是:一个普通函数、一个 lambda 表达式、一个仿函数(函数对象),甚至是一个 bind 表达式。
你心想:"这可咋整?难道要我写一堆重载?或者模板套模板?要是能用一种统一的方式存储和传递它们就好了。"
正当你抓耳挠腮时,C++11 给你送来了一位"万能劳务中介"------std::function。
它是一个通用的多态函数包装器,能够存储、复制和调用任何可调用对象。
那么今天我们就来扒一扒这个"万能劳务中介"的底裤。
std::function是什么
std::function 是 C++11 引入的一个标准库模板类,它本质上是一个通用的多态函数封装器。
通俗点说:它就是一个可以存储、复制、调用任何可调用对象的"万能盒子"------只要那个可调用对象的签名(即参数类型和返回类型)和这个盒子对得上。
它在头文件:' #include ' 中。
它的声明长这样(简化版):
c++
template<class Signature>
class function;这里 Signature 是一个函数类型,比如 int(int, double) 表示这个 function 接受两个参数(int 和 double),返回 int。
完整的类模板还有一堆成员函数、类型定义和运算符重载,但最核心的骨架就是:
c++
template<class R, class... Args>
class function<R(Args...)> {
// 构造函数、赋值、swap、operator bool、operator() 等
};也就是说,当你写下 std::function<int(int, double)> func 时,编译器实际上为你生成一个专门处理签名 int(int, double) 的 function 特化版本。
任何可以调用的、其参数和返回值类型与Signature兼容的实体。
包括普通函数、函数指针、lambda、std::bind生成的函数对象、函数对象类(重载operator()的类的实例)、成员函数指针(需要指定对象)等。
注意,它要求可调用对象的拷贝是可用的,因为std::function通常存储其副本。
基本用法示例
让我们抛开枯燥的理论,直接开始动手!
普通函数
我们先定义一个简单的函数:
c++
#include <functional>
#include <iostream>
int cook(int a, int b) {
std::cout << a << " + " << b << " = " << a+b << std::endl;
return a + b;
}然后直接把函数名赋值给 std::function,简单粗暴。
c++
int main()
{
std::function<int(int, int)> func = cook; // 函数名自动退化成函数指针
func(3, 5); // 输出:3 + 5 = 8
return 0;
}无需加工,简单直接。
函数指针
与普通函数一样:
c++
int (*funcPtr)(int,int) = cook; // 定义函数指针
std::function<int(int,int)> func2 = funcPtr;
func2(7, 2); // 输出:7 + 2 = 9lambda表达式
Lambda 是 C++ 里最灵活的可调用对象,std::function 自然来者不拒。
c++
auto lambda = [](int a, int b) {
std::cout << a << " * " << b << " = " << a * b << std::endl;
return a * b;
};
std::function<int(int, int)> func3 = lambda;
func3(4, 6); // 输出:4 * 6 = 24在上述代码中,lambda表达式创建了一个闭包对象,
然后被存储在std::function(int<int,int>)类型的对象func3中。
当func3被调用时,std::function内部机制会解包lambda表达式的闭包状态。
仿函数
只要一个类重载了 operator(),它的实例就是一个函数对象。
c++
struct Multiplier {
int operator()(int a, int b) const {
std::cout << a << " * " << b << " = " << a * b << std::endl;
return a * b;
}
};
Multiplier mul; // 创建函数对象
std::function<int(int, int)> func4 = mul;
func4(3, 7); // 输出:3 * 7 = 21std::bind 产生的绑定表达式
std::bind 可以把一部分参数固定下来,生成一个可调用对象。
c++
int add(int a, int b, int c) { // 三个参数的函数
std::cout << a << " + " << b << " + " << c << " = " << a + b + c << std::endl;
return a + b + c;
}
auto bound = std::bind(add, 10, std::placeholders::_1, 20); // _1用来占位,是将来传入的第一个参数
std::function<int(int)> func5 = bound; // 注意签名变成了 int(int)
func5(5); // 输出:10 + 5 + 20 = 35std::bind 使用占位符来表示未绑定的参数,这些占位符决定了在生成的新函数对象中如何传递参数。
常见的占位符有:
- std::placeholders::_1
- std::placeholders::_2
- std::placeholders::_3
- 等等
成员函数指针
成员函数指针不能直接存进 std::function,因为它需要绑到一个对象上才能调用。
常见的包装方式有两种:std::bind 或 lambda。
方法1:使用 std::bind:
c++
struct Chef {
void cookDinner(int count) const {
std::cout << "count value: " << count << std::endl;
}
};
Chef myChef;
auto boundMember = std::bind(&Chef::cookDinner, &myChef, std::placeholders::_1);
std::function<void(int)> func6 = boundMember;
func6(3); // 输出:count value: 3方法2:使用 lambda:
c++
std::function<void(int)> func7 = [&myChef](int count) {
myChef.cookDinner(count);
};
func7(5); // 输出:count value : 5成员函数就像一个需要主人才能启动的机器人,你得用 bind 或 lambda 给它配上主人,然后 std::function 才能愉快地指挥它。
另一个 std::function 对象
std::function 本身也是可拷贝的,所以你可以把一个 std::function 赋值给另一个(只要签名相同)。
c++
std::function<int(int, int)> original = cook;
std::function<int(int, int)> copy = original; // 拷贝构造
copy(2, 4); // 输出:2 + 4 = 6这就像俄罗斯套娃一样。
std::function 凭借类型擦除,让 C++ 的函数式编程变得异常灵活。
你可以把各种不同"形状"的可调用对象统一成同一种类型,放进容器、作为回调参数、或者实现策略模式。
它唯一的"代价"就是运行时可能有一次间接调用(类似虚函数),但这点开销在大多数场景下都可以忽略不计。
使用技巧与注意事项
现在我们要讨论一些陷阱和技巧。
空状态检查
std::function 默认构造出来是空的,里面啥也没有。
如果你胆敢直接调用它:
c++
std::function<int(int, int)> empty;
int result = empty(1, 2); // 抛出 std::bad_function_call 异常程序会当场给你好看。所以,调用之前一定要检查它是不是空的:
c++
if (empty) // operator bool 检查是否存储了可调用对象
{
empty(1, 2);
}
else
{
std::cout << "std::function is nullptr." << std::endl;
}你也可以主动赋值为nullptr清空它:
c++
std::function<int(int,int)> func = someCallable;
func = nullptr; // 现在 func 又空了性能开销
我们先来看一段代码:
c++
auto lambda1 = []() {};
std::function<void()> func = lambda1;
std::cout << "lambda1 sizeof: " << sizeof(lambda1) << std::endl;
std::cout << "func sizeof: " << sizeof(func) << std::endl;程序输出:
c++
lambda1 sizeof: 1
func sizeof: 64(上述输出的std::function大小,因编译器和平台而不同)
为什么空 lambda 的大小是 1:
- 因为lambda {} 没有任何捕获,是一个空类类型(closure type)。
- C++ 规定,任何对象都必须拥有唯一的地址。为了让同一个空类的不同对象能够有不同的地址,编译器会给空类隐含地添加一个无用的字节(或类似机制),因此 sizeof 通常返回 1。
std::function 的大小为什么会这么大?
std::function 是一个类型擦除的包装器,它可以存储任何可调用对象(函数指针、lambda、函数对象等)。
为了实现这种通用性,它内部需要:
- 存储实际的可调用对象(或指向它的指针)
- 存储一组"管理函数"的指针,用于复制、销毁、调用等操作(类似于虚表)
- 支持小对象优化:对于小型可调用对象(如空 lambda),直接存储在对象内部,避免堆分配;对于大型对象,则在堆上分配,并在 std::function 内部只保存一个指针。
因此,std::function 对象内部通常会包含一个联合体(union),既可以容纳足够大的静态缓冲区,又可以容纳指向堆上控制块的指针。
此外,还需要几个指针来指向管理函数。
为了直观,我们假设一个简化版的 std::function 布局,它包含:
- 一个函数指针(指向调用前的处理)
- 一个指向"管理表"的指针(包含复制、销毁等操作)
- 一个联合体(_Storage),用于存放实际可调用对象(小对象优化)或指向堆上控制块的指针。
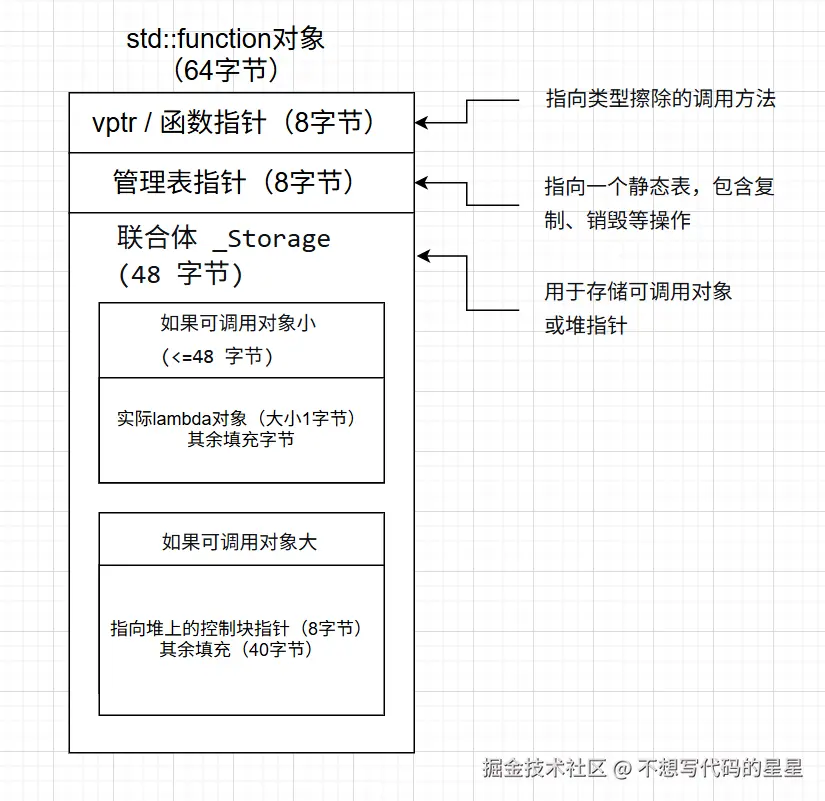
堆上的控制块(当不使用小对象优化时)可能长这样:
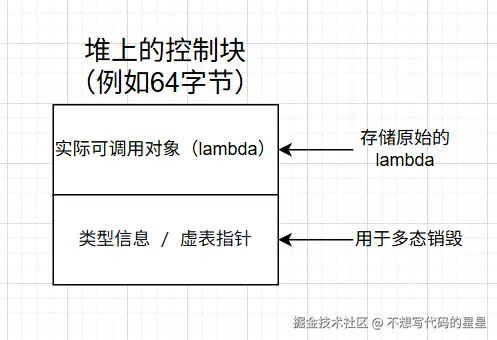
当使用小对象优化时,lambda 直接存放在 _Storage 中,不需要额外堆分配。
由于 lambda 是空对象,它正好被放进静态缓冲区中,所以没有堆分配开销。
但 std::function 对象本身依然保留了完整的存储空间(64 字节),以便能处理更大的可调用对象。
总结:std::function 是类型擦除容器,内部包含一个静态缓冲区(用于小对象优化)和若干管理指针,因此体积较大。
返回引用的陷阱
std::function 可以返回引用,比如 std::function<int&(int)>。这就有意思了------如果它内部存储的可调用对象返回了一个局部变量的引用,那你就得到了一个悬垂引用,程序可能随时崩溃。
看一个作死的例子:
c++
std::function<const std::string& ()> badFunc = []() -> const std::string& {
std::string local = "temporary";
return local; // 返回局部对象的引用
}; // lambda 结束,local 销毁
std::string s = badFunc();
std::cout << s << std::endl; // 未定义行为,访问已销毁的对象同样,如果 lambda 通过引用捕获了一个局部变量并返回它,也可能出问题。
因此我们应该按值返回,而不是返回引用。
或者确保被引用的对象生命周期长于 std::function。
应用场景
回调函数
假设你需要调用某个库函数,并希望它在某个时刻"回拨"你的代码------比如下载完成时通知你、定时器到期时执行你的逻辑。这就是回调函数。
因为std::function的回调函数的签名是固定的(比如 void(int)),但具体要执行的动作可以是普通函数、lambda 或者成员函数。
std::function 可以统一这些类型,让你轻松传递。
代码示例:
c++
void download(std::function<void(int)> onComplete)
{
// 模拟下载
int result = 42;
onComplete(result); // 下载完成,回调
}
void myCallback(int x) { std::cout << "下载完成,结果:" << x << std::endl; }
int main()
{
download(myCallback); // 普通函数
download([](int x) { std::cout << "lambda: " << x << std::endl; }); // lambda
return 0;
}程序输出:
makefile
下载完成,结果:42
lambda: 42策略模式的实现
策略模式定义了一系列算法,将它们一个个封装起来,并使它们可以相互替换。
策略模式让算法的变化独立于使用算法的客户。通常的结构包括:
- 策略接口:定义所有支持的算法的公共接口。
- 具体策略:实现策略接口的具体算法。
- 上下文:持有对策略对象的引用,负责调用策略。
通俗点来说就是你有一个排序算法,但允许用户自定义比较规则;或者一个压缩工具,支持多种压缩算法。这就是策略模式。
std::function 让策略的传递变得简单,不需要定义一堆策略接口类。
下面看一段代码:
c++
class DataProcessor
{
private:
std::function<int(int, int)> strategy;
public:
void setStrategy(std::function<int(int, int)> s) { strategy = s; }
int compute(int a, int b) { return strategy(a, b); }
};- std::function<int(int, int)> 是一个通用的函数包装器,可以存储任何可调用对象,只要它接受两个 int 并返回 int。这里它充当了策略接口的角色。
- setStrategy:允许客户端在运行时动态设置具体的策略。参数 s 可以是任何符合签名的可调用对象。
- compute:执行当前策略,将两个整数传递给策略对象并返回结果。
使用示例:
c++
DataProcessor dp;
dp.setStrategy([](int a, int b) { return a + b; });
std::cout << dp.compute(3, 4) << std::endl; // 输出:7
dp.setStrategy(std::multiplies<int>()); // 标准库函数对象
std::cout << dp.compute(3, 4) << std::endl; // 输出:12- 第一次 setStrategy 传入一个 lambda 表达式,实现了加法运算。
- 第二次 setStrategy 传入标准库函数对象 std::multiplies,它重载了operator() 执行乘法。
第二次调用会覆盖第一次设置的策略,因此dp 最后一次设置的策略将是乘法。
策略模式的好处:
- 开闭原则:新增策略无需修改 DataProcessor 类,只需定义新的可调用对象并传递给 setStrategy。
- 运行时灵活性:可以在程序运行中根据条件改变算法。
- 解耦:DataProcessor 不依赖具体的算法实现,只依赖抽象的 std::function 签名。
函数表(命令分发)
假设你需要根据用户输入的命令字符串,执行对应的操作,比如命令行工具中的 help, quit等。
那么你可以建立一个从字符串到函数的映射(函数表),根据输入快速找到并调用对应的函数。
std::function 能统一所有命令函数的签名。
c++
std::map<std::string, std::function<void()>> commands;
commands["help"] = [] { std::cout << "显示帮助信息" << std::endl; };
commands["quit"] = [] { exit(0); };
std::string cmd;
std::cout << "Enter help or quit: " << std::endl;
while (std::cin >> cmd)
{
if (commands.count(cmd)) commands[cmd]();
else std::cout << "未知命令" << std::endl;
}程序输出:
bash
Enter help or quit:
help
显示帮助信息
add
未知命令
quit线程池
假设线程池需要接收用户提交的任务(可以是任何可调用对象),并在某个线程中执行。
使用 std::function:任务五花八门,但线程池只需要知道任务无参数无返回值(或统一签名)即可。
std::function 可以擦除具体类型,让线程池只关心调用。
c++
class ThreadPool {
private:
std::vector<std::thread> workers;
std::queue<std::function<void()>> tasks;
public:
void enqueue(std::function<void()> task)
{
tasks.push(task);
// 通知一个工作线程取任务...
}
// ... 线程执行循环
};
ThreadPool pool;
pool.enqueue([] { std::cout << "任务1" << std::endl; });
pool.enqueue(std::bind(someFunction, 42));总结
std::function在性能敏感的代码中,记得考虑它带来的间接开销;在只需要一种类型的场景,auto 可能更合适。
但只要需要类型擦除、统一容器或接口,std::function 绝对是不二之选。