Claude Code 的工程哲学:缓存与工具设计的真实教训 | 经验分享
最近读了 Claude Code 团队公开的两篇工程博客,一篇讲 Prompt Caching,一篇讲工具设计。读完之后最大的感受是:做 Agent 产品,技术选型和算法只是门槛,真正拉开差距的是工程细节上的反复打磨。
这两篇文章表面上讲的是两个独立话题,但放在一起看,它们其实在回答同一个问题------如何让一个长时间运行的 AI Agent 在成本、延迟和能力之间找到平衡。

缓存不是优化,是地基
Prompt Caching 的原理并不复杂:API 会缓存请求前缀的计算结果,下次遇到相同前缀时直接复用。但 Claude Code 团队把这件事做到了什么程度呢?他们对缓存命中率设了告警,命中率下降会被当作生产事故来处理。
这个态度本身就说明了问题。缓存命中率直接决定了每个用户的使用成本和响应速度,而成本又反过来决定了订阅计划能给多大的用量额度。换句话说,缓存效率不只是一个技术指标,它直接影响商业模型。
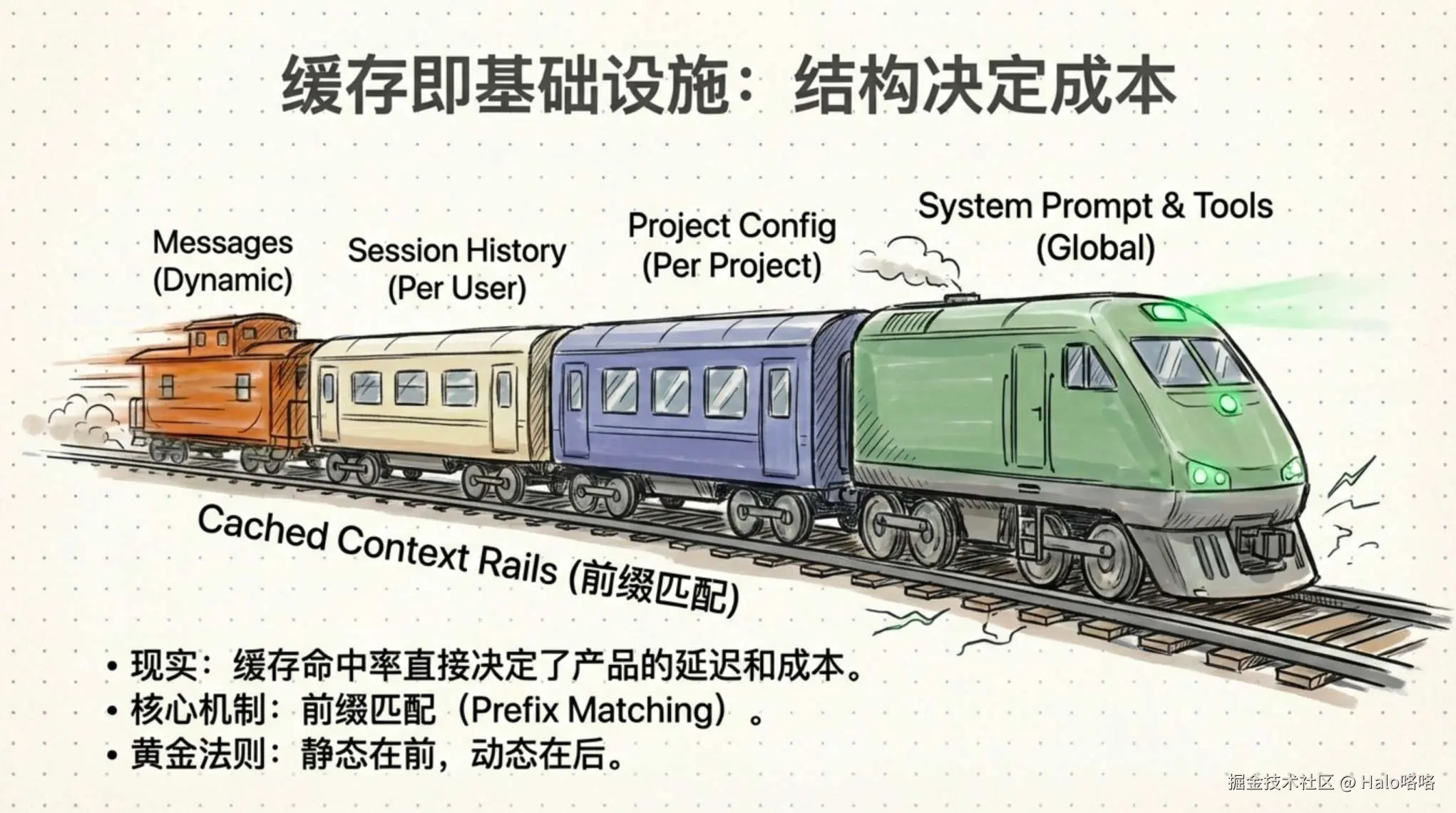
缓存的核心机制是前缀匹配。不是模糊匹配,不是语义匹配,就是从第一个字符开始逐字比对。这意味着请求内容的排列顺序变得异常重要:静态的东西放前面,动态的东西放后面。Claude Code 的排列是这样的:
┌──────────────────────────────────────┐
│ 1. 静态系统提示词 & 工具定义 │ ← 全局缓存(所有用户共享)
├──────────────────────────────────────┤
│ 2. Claude.MD(项目配置) │ ← 项目级缓存
├──────────────────────────────────────┤
│ 3. Session Context(会话上下文) │ ← 会话级缓存
├──────────────────────────────────────┤
│ 4. Conversation Messages(对话消息)│ ← 每轮递增
└──────────────────────────────────────┘从上往下,内容的变化频率递增,缓存的共享范围递减。所有用户共享最顶层的缓存,同一项目下的会话共享第二层,同一次会话共享第三层,只有最底部的对话消息是每轮都在增长的。
道理很简单,但执行起来处处是坑。他们踩过的那些坑,现在回看都不大,但当时每一个都足以让缓存完全失效:
| 踩坑操作 | 后果 |
|---|---|
| 在静态系统提示中放入精确到秒的时间戳 | 每秒都在打破缓存 |
| 工具定义的顺序在代码里是非确定性的 | 每次请求顺序不同,前缀不匹配 |
| 动态更新工具参数(如可调用的代理列表) | 参数一变,后续缓存全部失效 |
围绕缓存做设计,而不是事后补救
一旦理解了前缀匹配的脆弱性,很多设计决策就变得清晰了,虽然其中不少是反直觉的。Claude Code 团队踩过坑之后总结出了四条策略,每一条都指向同一个原则:不要碰前缀,把变化推到请求的末尾。
策略 1:用消息传递更新,不要改系统提示
问题:信息过时了(如日期、用户修改了文件),直觉是更新系统提示 后果:缓存未命中,整个前缀需要重新计算
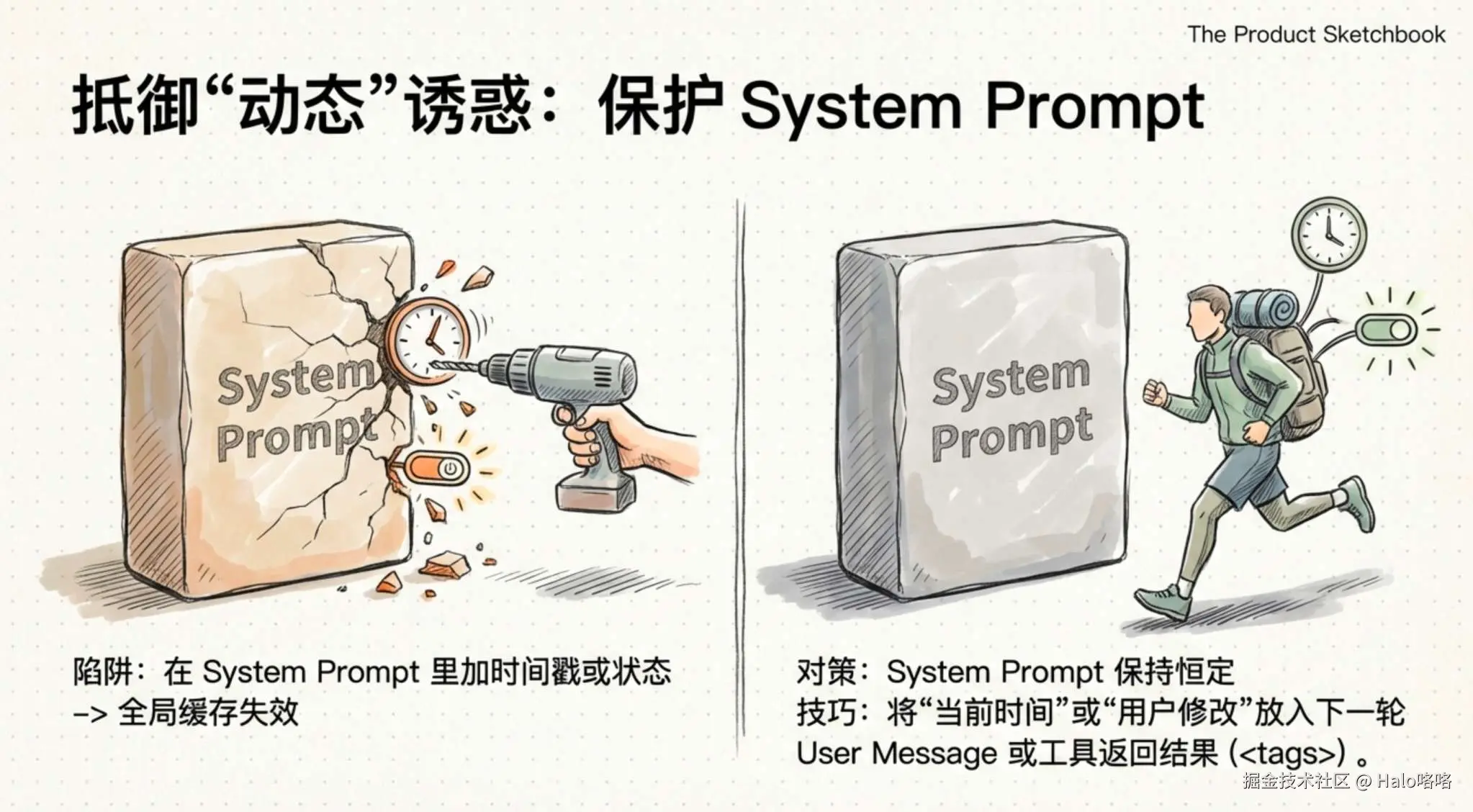
Claude Code 的做法是在下一轮对话的用户消息里插入一个标签来传递更新:
xml
<!-- 在下一轮 user message 中加入 -->
<system-reminder>现在是星期三</system-reminder>缓存前缀完全不受影响,模型也能读到最新信息。变化被推到了消息末尾,而不是去碰前面已经缓存好的内容。
策略 2:不要在会话中途切换模型
缓存是模型专属的,这会导致一个反直觉的现象:
如果你已经和 Opus 对话了 100k tokens,想问一个简单问题, 切换到 Haiku 反而比继续用 Opus 更贵------因为需要为 Haiku 从零重建整个缓存。
如果确实需要用不同模型处理子任务,正确的做法是用子代理:
rust
主会话 (Opus) --> 准备精简的"交接消息" --> 子代理 (Haiku) 独立完成任务两边各自维护自己的缓存,互不干扰。Claude Code 中的 Explore agents 就是这样使用 Haiku 的。
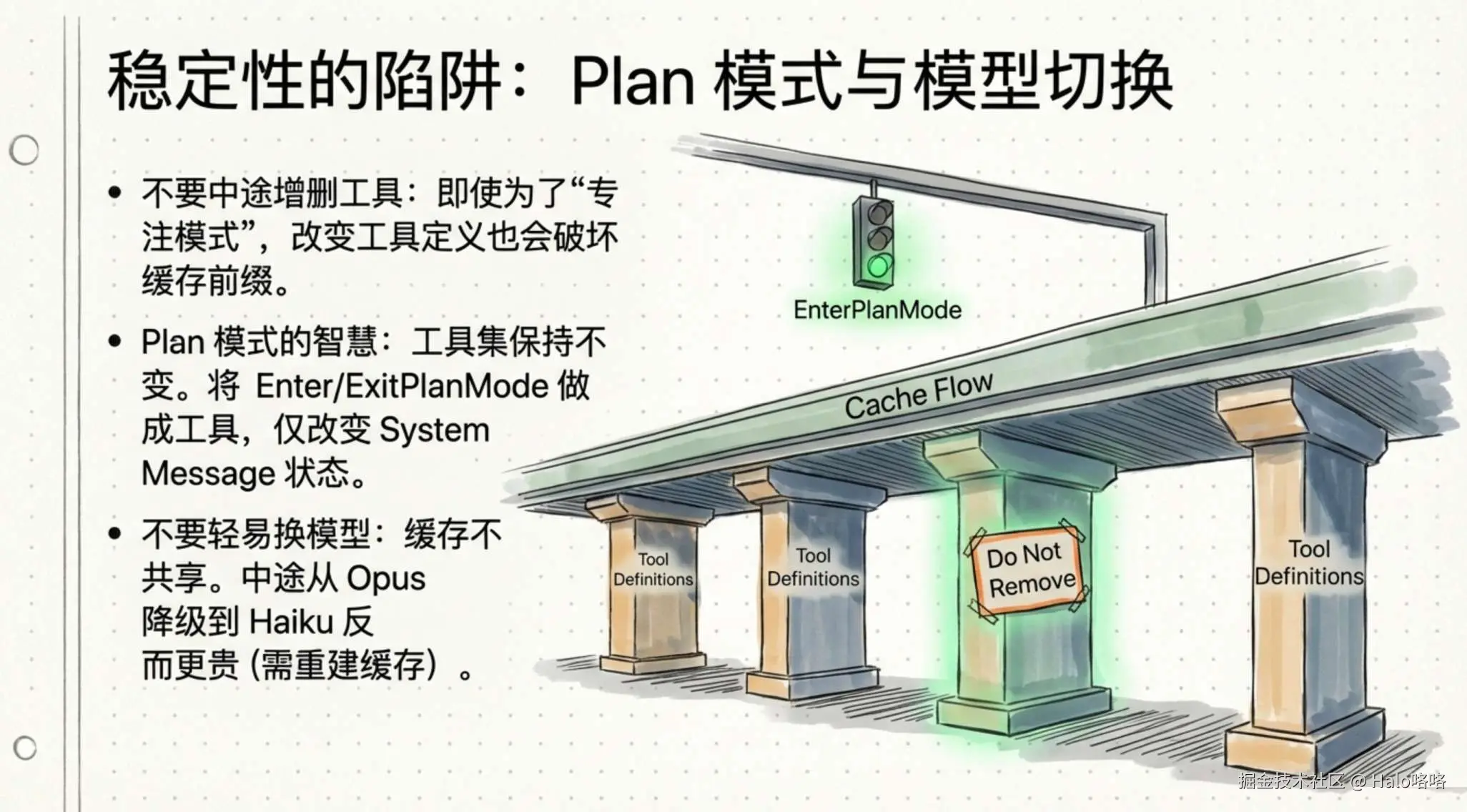
策略 3:不要增删工具,用工具建模状态转换
工具定义属于缓存前缀的一部分,增删任何工具都会使整个对话的缓存失效。但产品需求确实存在------计划模式下不应该让模型编辑文件,工具搜索场景下不可能把几十个 MCP 工具的完整定义都塞进请求。
Claude Code 对这两个场景分别设计了方案。
Plan Mode:用工具代替开关
直觉做法是进入计划模式时把工具集替换为只读工具,但这会破坏缓存。实际做法是保留所有工具,把状态切换本身做成工具:
lua
所有工具始终存在于请求中
|-- EnterPlanMode (工具) --> 进入计划模式
|-- ExitPlanMode (工具) --> 退出计划模式用户切换计划模式时,工具定义一个字都不变,模型只是收到一条消息说"你现在在计划模式,不要编辑文件,探索完了调用 ExitPlanMode"。缓存完美命中。附带的好处是,因为进入计划模式是一个工具调用而不是外部开关,模型在遇到复杂问题时可以自己决定先进计划模式想清楚再动手。
Tool Search:延迟加载而非移除
Claude Code 可能有数十个 MCP 工具,全部包含太昂贵,但中途移除会破坏缓存。解决方案是 defer_loading 机制:
css
缓存前缀中始终包含:
Tool A: { name: "tool_a", ...完整定义 }
Tool B: { name: "tool_b", ...完整定义 }
Tool C: { name: "tool_c", defer: true } <-- 轻量级存根
Tool D: { name: "tool_d", defer: true } <-- 轻量级存根
Tool E: { name: "tool_e", defer: true } <-- 轻量级存根
ToolSearch: { ... } <-- 发现工具用的工具不需要的工具不会被删除,而是保留为只有名字的轻量级存根。模型需要时通过 ToolSearch 工具去查找和加载完整 schema。缓存前缀里永远是同一组存根,顺序固定,内容不变。
策略 4:上下文压缩要复用父对话的前缀
当对话超出上下文窗口需要压缩时,简单实现和缓存安全实现的差距非常大。
错误的做法:
lua
新的 API 调用 {
system_prompt: "请总结以下对话", <-- 不同的系统提示
tools: [], <-- 没有工具
messages: [整个对话历史] <-- 完全不匹配缓存
}
// 结果:全部 token 按全价计费正确的做法:
lua
新的 API 调用 {
system_prompt: 与父对话完全相同, <-- 缓存命中
tools: 与父对话完全相同, <-- 缓存命中
user_context: 与父对话完全相同, <-- 缓存命中
messages: [
...父对话的所有消息, <-- 缓存命中
{ role: "user", content: "请压缩以上对话" } <-- 唯一的新 token
]
}
// 结果:只有压缩指令本身是新 token代价是需要预留一部分上下文空间作为"压缩缓冲区",确保有足够空间容纳压缩消息和摘要输出。但比起全价重算所有 token,这点空间浪费可以忽略。
工具设计:匹配模型,而不是匹配需求
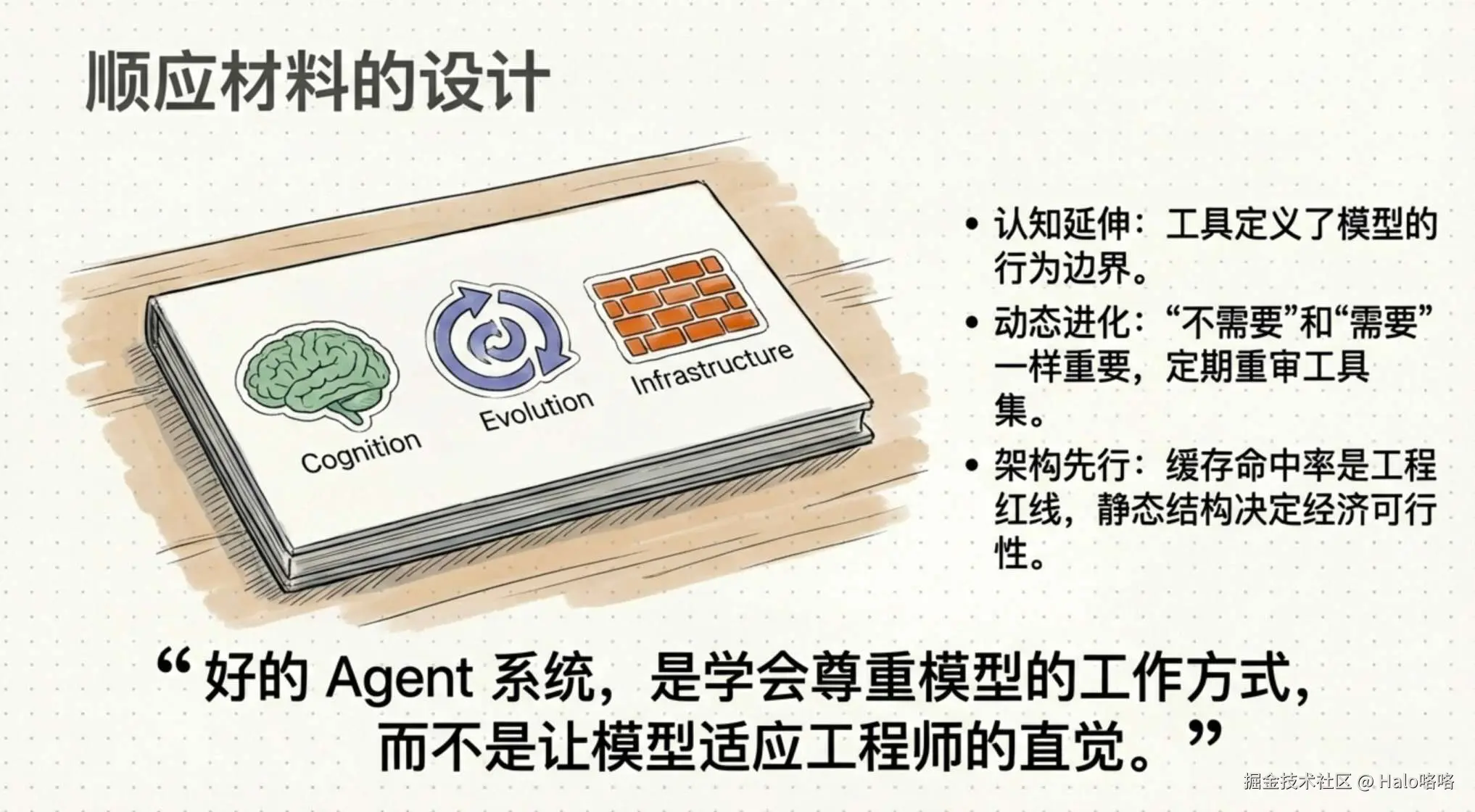
第二篇文章讲的是怎么给 Agent 设计工具,核心观点可以用一句话概括------工具要适配模型的能力和认知方式,不是你觉得合理就行。
团队用了一个类比:面对一道数学难题,你想要纸、计算器还是电脑,取决于你自己的能力。给一个不会编程的人一台电脑,不如给他一个计算器。Agent 的工具设计也是同样的逻辑,你得先理解模型擅长什么、会怎么使用工具,然后根据这些观察来设计。
这不是坐在那里想就能想明白的事情。团队反复提到的一个词是"观察"------读模型的输出,看它怎么调用工具,哪些调用是流畅的哪些是别扭的。
三次失败才做对一个提问工具
AskUserQuestion 工具的迭代过程是个好例子。目标很明确:让模型能更好地向用户提问,降低沟通来回的次数。
less
graph LR
A["尝试 #1<br/>ExitPlanTool<br/>加参数"] -->|混淆模型| B["尝试 #2<br/>修改输出格式<br/>解析 Markdown"]
B -->|输出不可靠| C["尝试 #3<br/>AskUserQuestion<br/>独立工具 ✅"]
style A fill:#ff6b6b,color:#fff
style B fill:#ffa94d,color:#fff
style C fill:#51cf66,color:#fff三次尝试,每次失败的原因都不一样:
| 尝试 | 方案 | 失败原因 |
|---|---|---|
| #1 | 在 ExitPlanTool 上加一个 questions 数组参数 | 同时要求出计划又要提问,模型搞不清重点。用户回答和计划冲突时更混乱 |
| #2 | 修改输出指令,让模型用约定的 Markdown 格式提问 | 模型有时多加句子,有时漏选项,有时直接换格式。靠指令约束输出始终不可靠 |
| #3 ✅ | 创建独立工具,有明确的 schema 定义输入结构 | 结构化保证格式,多选项保证质量,模型调用自然流畅 |
第三版之所以成功,不只是因为 schema 能强制约束输出格式,更关键的是团队原文里提到的一句话:"Claude seemed to like calling this tool"。模型愿不愿意用这个工具、用起来是不是自然,比工具本身设计得是否优雅更重要。一个模型不爱用的工具,设计再精巧也是摆设。

曾经的帮手变成了枷锁
TodoWrite 到 Task Tool 的演化讲的是另一个教训:模型在进步,工具设计的假设需要跟着更新。
arduino
TodoWrite(初期)
│
├── 问题1:Claude 经常忘记 Todo
│ └── 应对:每 5 轮插入系统提醒
│
├── 问题2:提醒反而限制了模型
│ └── Claude 觉得必须死守列表,不敢根据情况调整
│
└── 问题3:Opus 4.5 擅长子代理,但子代理怎么共享 Todo?
└── 原有设计根本没考虑这种场景
│
▼
Task Tool(进化版)
├── 支持任务间的依赖关系
├── 跨子代理共享和更新进度
└── 模型可以自由修改、删除任务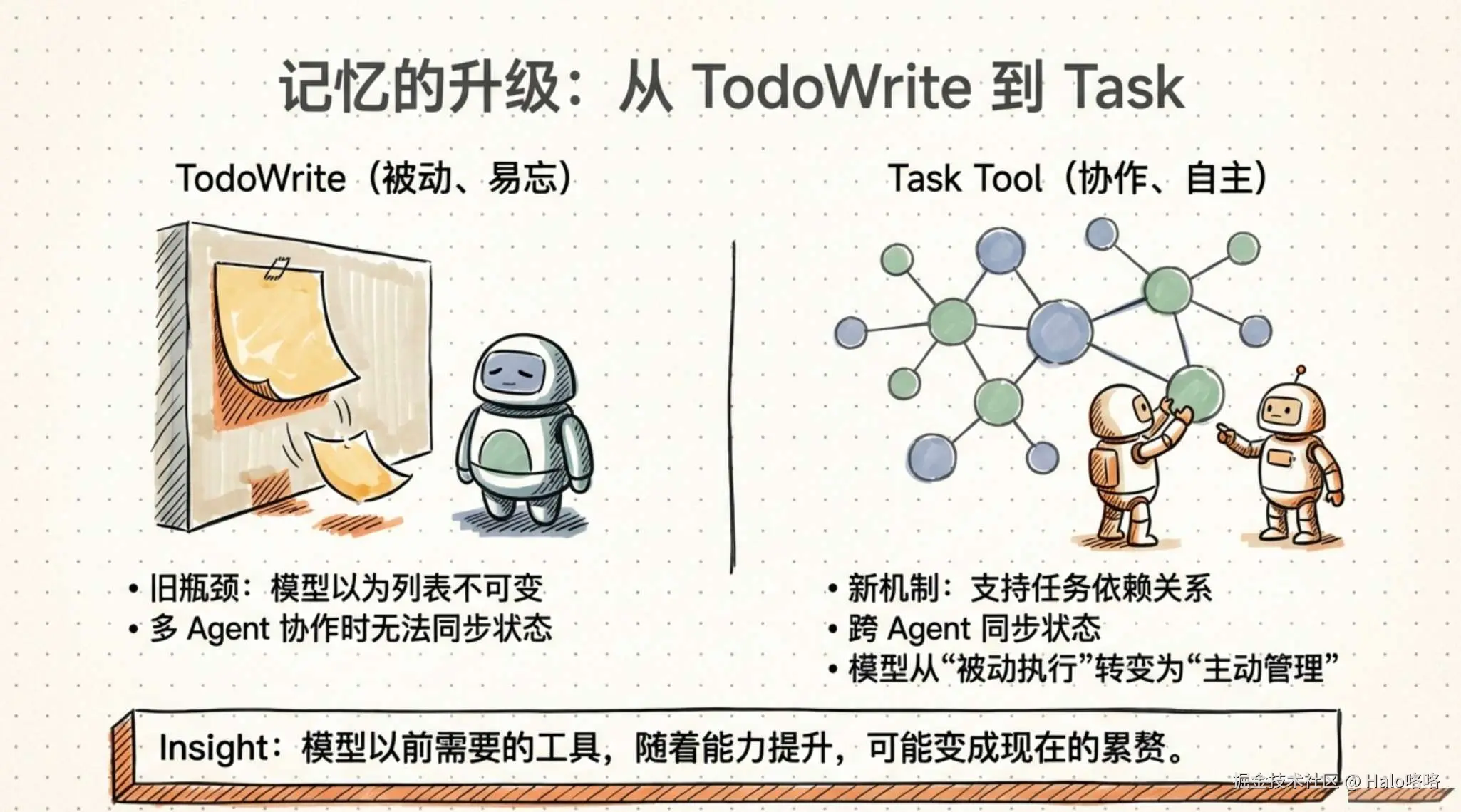
底层理念从"帮模型记住该做什么"变成了"帮多个 Agent 协调工作"。这件事的启示很明确:每次模型升级,都应该重新审视现有工具是否还合适。坚持支持少数几个能力接近的模型,工具设计的迭代成本会低很多。
让 Agent 自己找信息,而不是喂给它
搜索工具的演化是这两篇文章里我觉得最有意思的部分。
less
graph TD
A["RAG 向量数据库"] -->|需要索引、环境脆弱、模型被动接收| B["Grep 工具"]
B -->|模型主动搜索,但只有单层| C["Agent Skills + 文件引用"]
C -->|递归发现,多层深入| D["嵌套搜索:跨多层文件精确定位"]
style A fill:#868e96,color:#fff
style B fill:#4dabf7,color:#fff
style C fill:#845ef7,color:#fff
style D fill:#51cf66,color:#fffClaude Code 最早用的是 RAG 向量数据库,提前索引代码库,用户提问时检索相关片段塞进上下文。这个方案在受控环境下效果不错,但到了真实用户的各种开发环境里就很脆弱了------不同的语言、框架、项目结构都会影响索引质量。更根本的问题是,模型是被动接收上下文的,拿到的信息是否是它真正需要的,完全取决于检索系统的质量。
后来团队给模型加了 Grep 工具,让它自己搜索代码库。一个看似很小的改变,但效果出乎意料地好。模型知道自己在找什么,搜索策略会根据任务动态调整,不再依赖预建的索引。
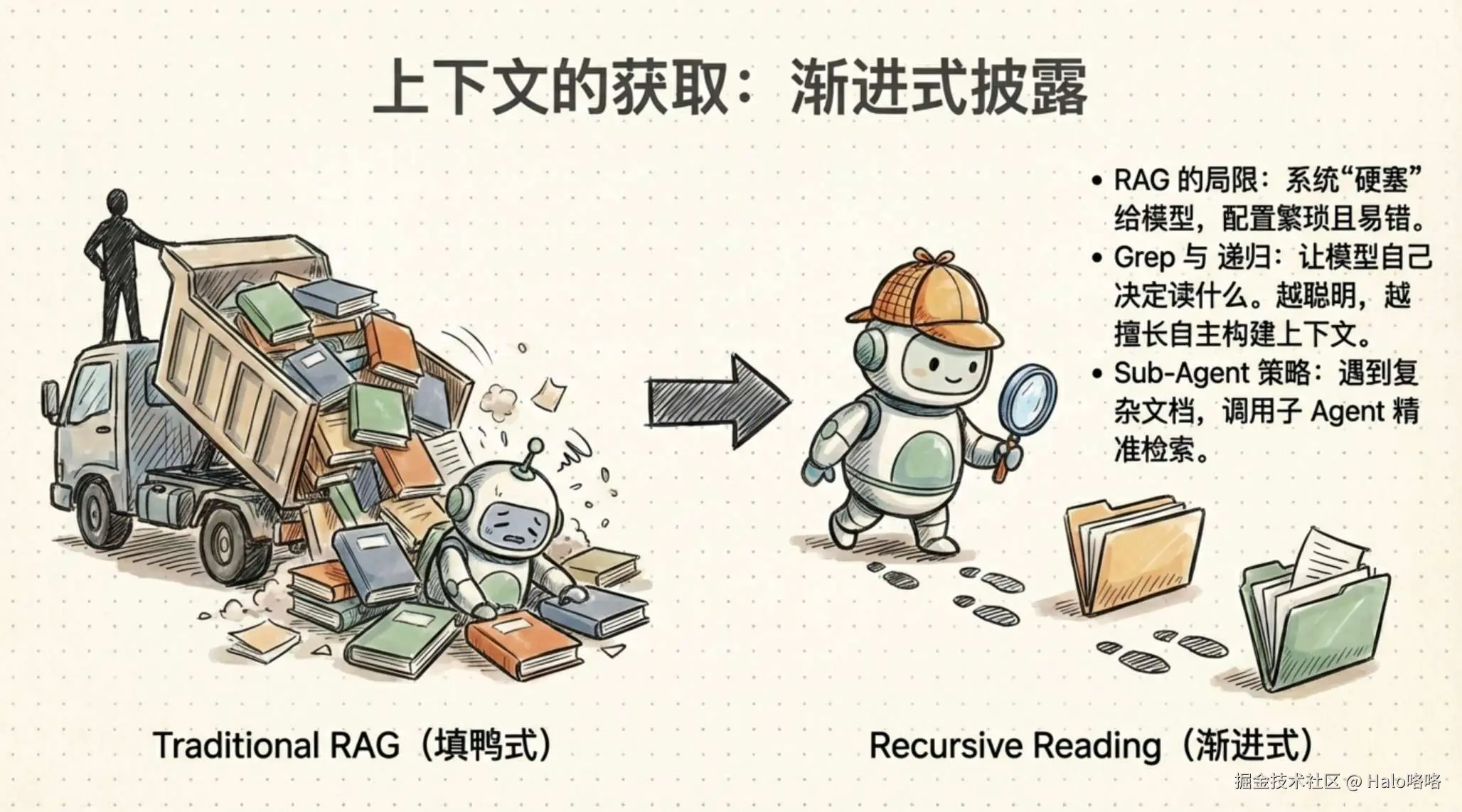
这个思路后来被提炼成了一个设计模式:
渐进式发现(Progressive Disclosure)
让 Agent 通过探索来逐步发现相关上下文,而不是一次性塞给它所有信息。
具体做法:
- Claude 可以读取 Skill 文件
- Skill 文件中引用其他文件
- 模型可以递归地阅读这些引用
- 常见用法:通过 Skill 教 Claude 如何使用 API 或查询数据库
一年时间里,Claude 从"几乎不能自己构建上下文"进化到了"能跨多层文件做嵌套搜索来找到精确所需的上下文"。
渐进式发现不只用在代码搜索上,还解决了其他场景的信息供给问题。比如用户有时会问 Claude Code 自身的用法------怎么配置 MCP、某个斜杠命令是干什么的。团队评估了几种方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 全写进系统提示 | 简单直接 | 用户很少问,平时占用上下文,干扰正常写代码 |
| 给文档链接让模型自行搜索 | 不增加工具 | 模型会把大段搜索结果塞进上下文,实际只需要一个答案 |
| Guide 子代理 ✅ | 不增加工具,专人专事 | 有专门的搜索指令,精准返回答案 |
最终做了一个 Guide 子代理,主模型检测到用户在问关于自身的问题时,把问题交给它处理。整个过程没有给主模型增加任何新工具,但能力确实扩展了。
加工具之前先想清楚
Claude Code 目前大概有 20 个工具,团队对新增工具的态度非常谨慎。每多一个工具,模型在每次决策时就多一个选项要考虑。工具集膨胀不只是维护成本的问题,它直接影响模型的决策质量。
从上面这些案例里可以提炼出几条判断标准:
能不能不加工具就解决? 子代理和 Skill 文件都是在不增加工具数量的前提下扩展能力的方式。Guide 子代理解决了文档查询的需求,渐进式发现解决了上下文构建的需求,都没有给主模型的工具列表添一项。
工具的 schema 能不能保证输出可靠? 如果同样的效果可以通过输出格式指令实现,但格式指令不能保证模型总是遵守,那就应该做成工具。AskUserQuestion 的第二版到第三版的转变就是这个逻辑。
模型用起来自然吗? 这一条没有量化标准,只能靠观察。给模型一个新工具之后,看它在各种场景下是怎么调用的,调用得是否合理、是否流畅。如果模型经常在不该用的时候用它,或者该用的时候不用,说明工具的定义和模型的认知之间有错位。
最后还有一条容易忘记的:这个工具以后还需要吗?模型的能力在持续提升,一年前需要的辅助轮,今天可能已经是多余的负担。
对于正在做 Agent 产品的人来说,最实际的建议可能就是:从第一天起就围绕缓存设计架构,然后花大量时间观察模型怎么使用你给它的工具。前者是工程问题,有明确的对错;后者更接近手艺,需要耐心和经验积累。