一、什么是机器学习?
让机器从数据里自己找规律,而不是人写死规则。
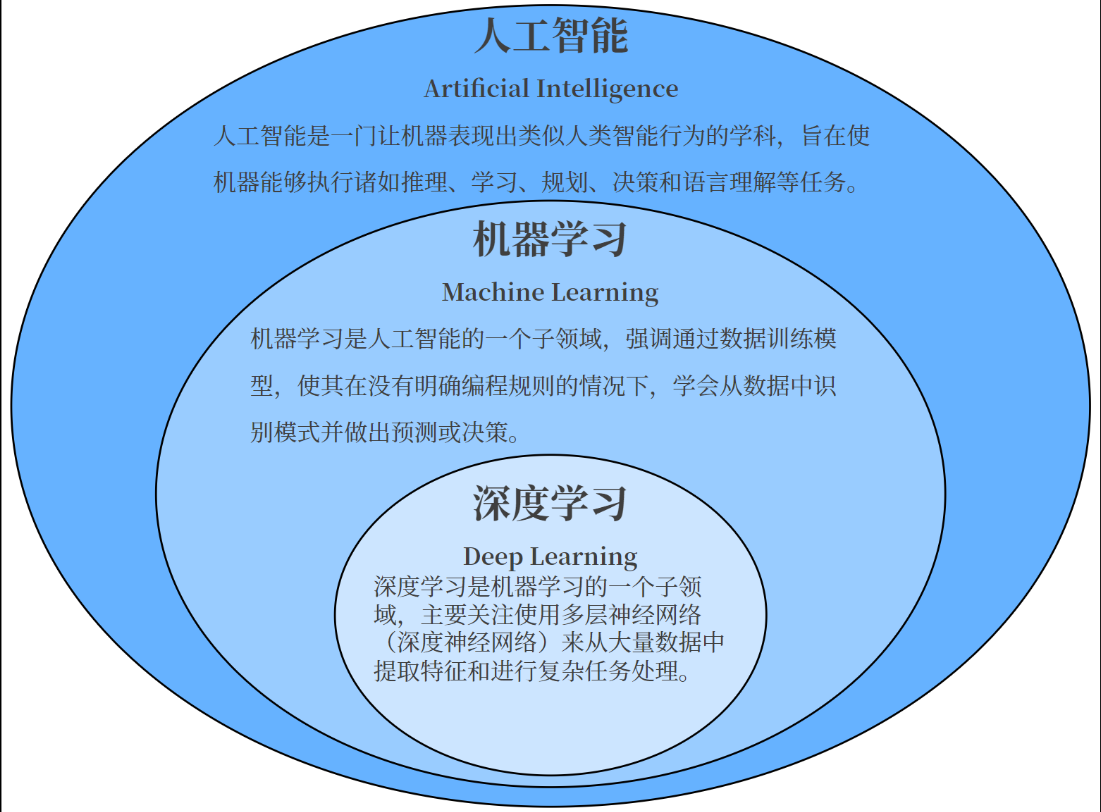
二 、人工智能、机器学习、深度学习有什么关系?
三、机器学习三要素
机器学习的方法一般主要由三部分构成:模型、策略和算法,可以认为:
机器学习方法 = 模型 + 策略 + 算法
- 模型(model):总结数据的内在规律,用数学语言描述的参数系统
- 策略(strategy):选取最优模型的评价准则
- 算法(algorithm):选取最优模型的具体方法
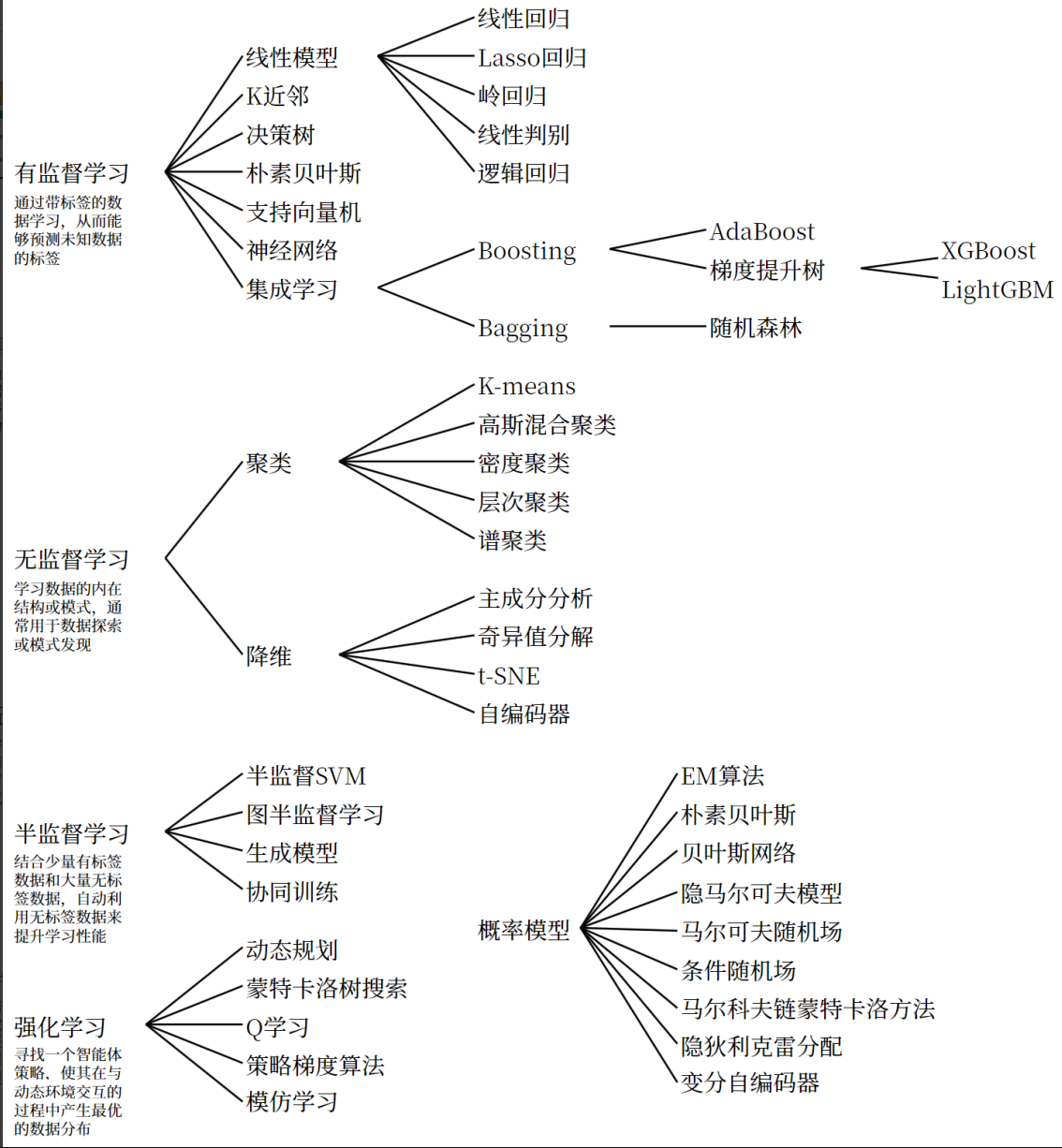
四、机器学习的图例汇总
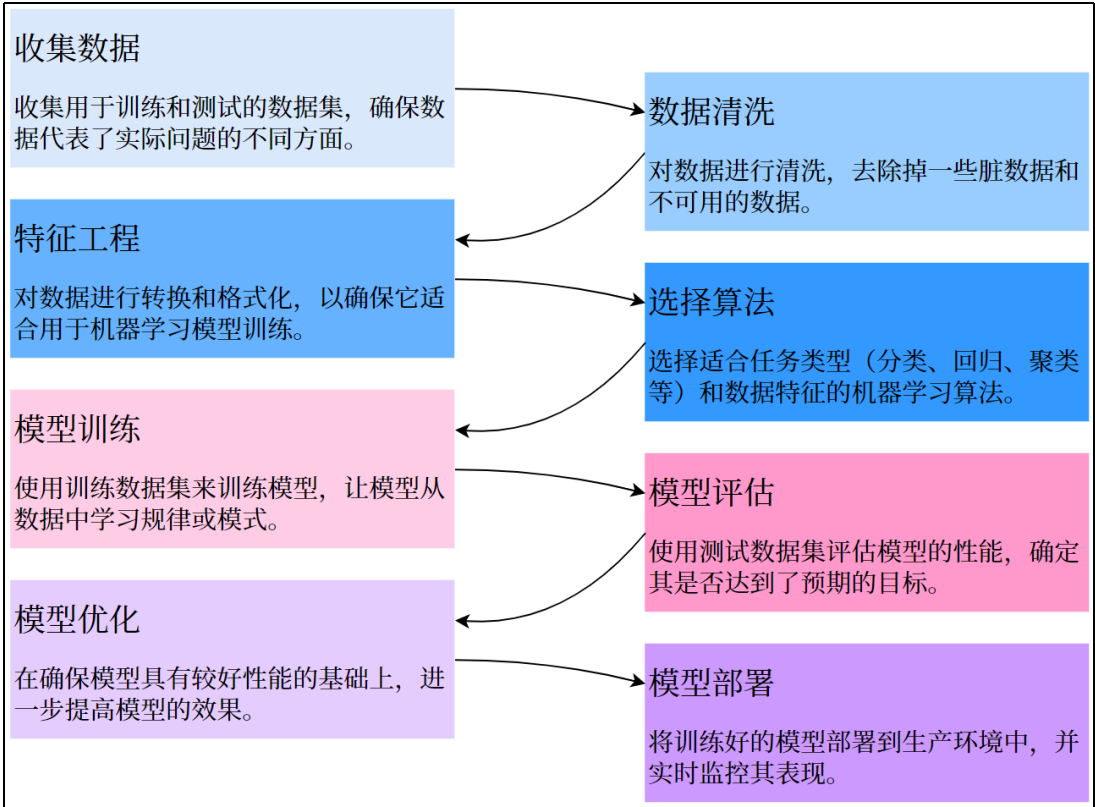
五、监督学习的建模流程
六、什么是特征工程?
特征工程(Feature Engineering)是机器学习过程中非常重要的一步,指的是通过对原始数据的处理、转换和构造,生成新的特征或选择有效的特征,从而提高模型的性能。
七、特征选取方法
1、皮尔逊相关系数
python
# 特征构造之相关系数:皮尔逊相关系数
import pandas as pd
advertising = pd.read_csv(r'E:/LLM/machine-learning/advertising.csv')
# print(advertising.head())
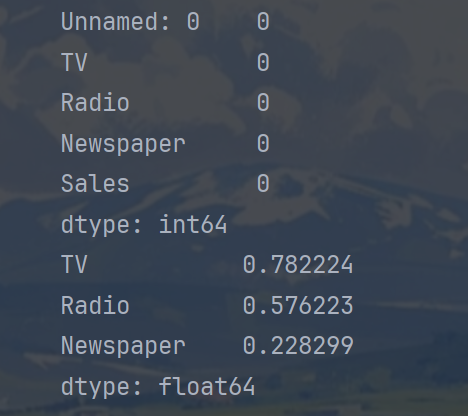
print(advertising.isnull().sum())
advertising.drop(advertising.columns[0],axis=1,inplace=True)
advertising.dropna(inplace=True)
x = advertising.drop('Sales',axis=1)
y = advertising['Sales']
print(x.corrwith(y,method = 'pearson'))运行结果如下:
python
import seaborn as sns
import matplotlib.pyplot as plt
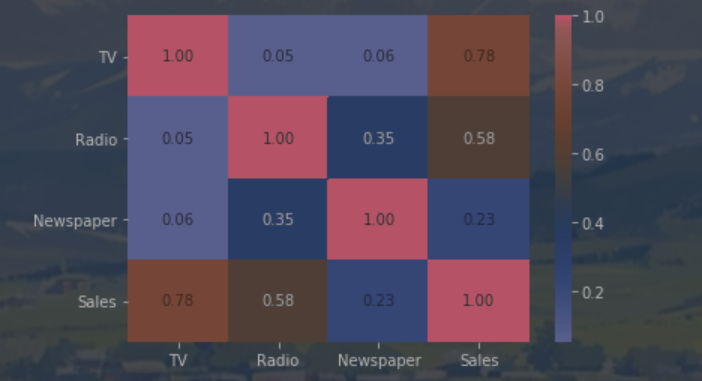
# 计算皮尔逊相关系数矩阵
corr_matrix = advertising.corr(method='pearson')
# 可视化热力图
sns.heatmap(corr_matrix,annot=True,cmap='coolwarm',fmt='.2f')
plt.show()运行结果如下:
2、斯皮尔曼相关系数
python
# 斯皮尔曼相关系数:两个变量直接的关系
import pandas as pd
# 每周学习时长
X =[[5],[8],[10],[12],[15],[3],[7],[9],[14],[6]]
# 数学成绩
y = [55,65,70,75,85,50,60,72,80,58]
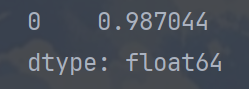
# 计算斯皮尔曼相关系数
X = pd.DataFrame(X)
y = pd.Series(y)
print(X.corrwith(y,method = 'pearson'))运行结果:
3、主成分分析
python
# 主成分分析:通过线性变换将高纬度数据投影到低纬度空间,同时保留数据的主要变化模式
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from mpl_toolkits.mplot3d import Axes3D
n_samples = 1000
# 第1个主成分方向
component1 = np.random.normal(0,1,n_samples)
# 第2个主成分方向
component2 = np.random.normal(0,0.2,n_samples)
# 第3个方向(噪声,方差较小)
noise = np.random.normal(0,1,n_samples)
# 构造3维数据
X = np.vstack([component1-component2,component1+component2,component2+noise]).T
# 标准化
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
# 应用PCA,将三维数据降维 到2维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_standardized)
# 可视化
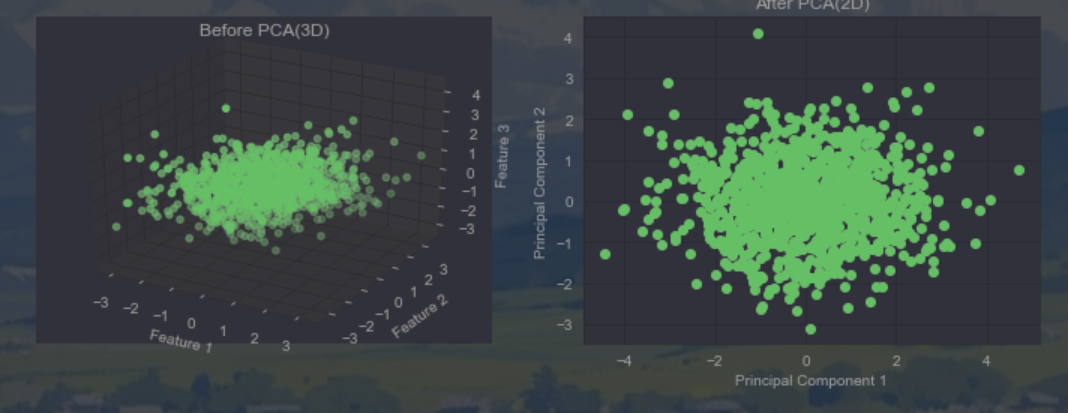
# 转换前的三维数据可视化
fig = plt.figure(figsize=(12,4))
ax1 = fig.add_subplot(121,projection='3d')
ax1.scatter(X[:,0],X[:,1],X[:,2],c='g')
ax1.set_title('Before PCA(3D)')
ax1.set_xlabel('Feature 1')
ax1.set_ylabel('Feature 2')
ax1.set_zlabel('Feature 3')
# 转换后的2维数据可视化
ax2 = fig.add_subplot(122)
ax2.scatter(X_pca[:,0],X_pca[:,1],c='g')
ax2.set_title('After PCA(2D)')
ax2.set_xlabel('Principal Component 1')
ax2.set_ylabel('Principal Component 2')
plt.show()运行结果如下:
八、模型评估
1、损失函数
对于模型一次预测结果的好坏,需要有一个度量标准。
对于监督学习而言,给定一个输入X ,选取的模型就相当于一个"决策函数"f ,它可以输出一个预测结果f(X) ,而真实的结果(标签)记为Y 。f(X) 和Y 之间可能会有偏差,我们就用一个损失函数 (loss function)来度量预测偏差的程度,记作 L(Y,f(X))。
(1)、损失函数用来衡量模型预测误差的大小;损失函数值越小,模型就越好;
(2)损失函数是f(X) 和Y的非负实值函数;
2、欠拟合和过拟合
欠拟合:模型在训练集和测试集上误差都比较大。模型过于简单,高偏差。
过拟合:模型在训练集上误差较小,但在测试集上误差较大。模型过于复杂,高方差。
九、梯度下降法
1、什么是梯度下降法?
梯度下降法(gradient descent)是一种常用的一阶优化方法,是求解无约束优化问题最简单、最经典的方法之一。梯度下降法是迭代算法,基本思路就是先选取一个适当的初始值,然后沿着梯度方向或者负梯度方向,不停地更新参数,最终取到极小值。
十、模型评估指标
1、回归模型常用评估指标:均方误差(MSE)
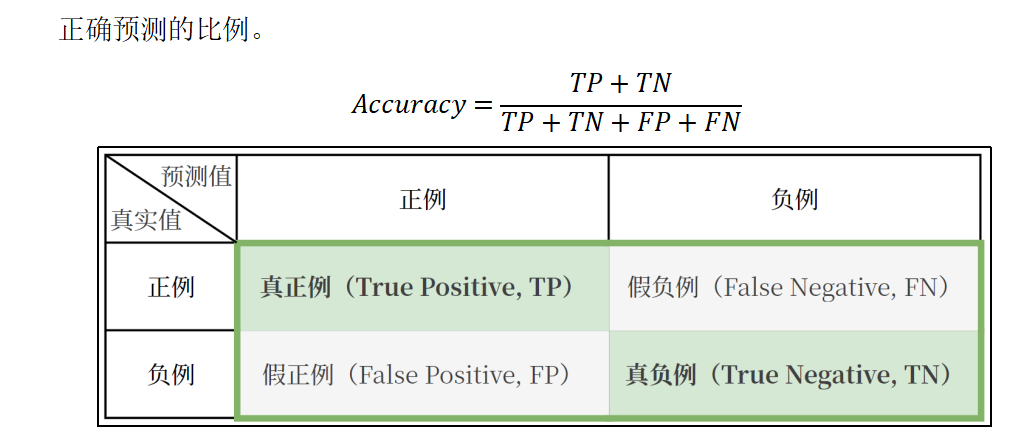
2、分类模型常用评估指标:准确率
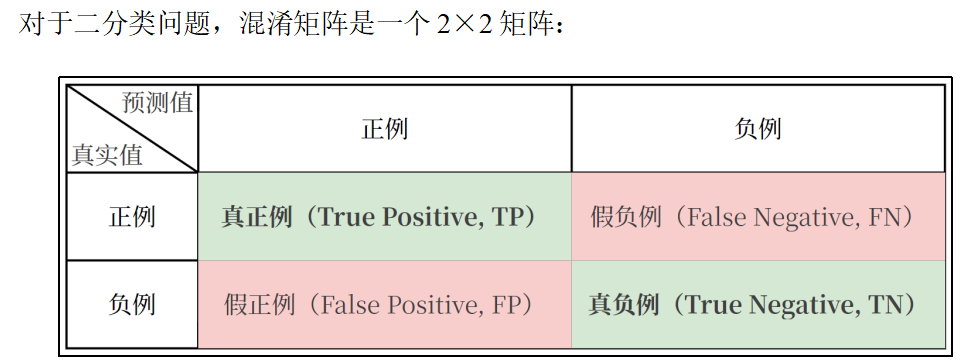
混淆矩阵
准确率
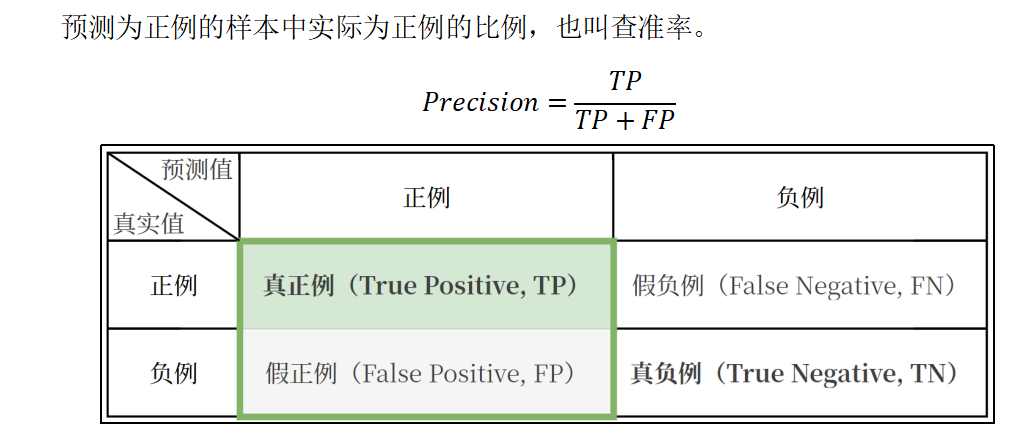
精确率
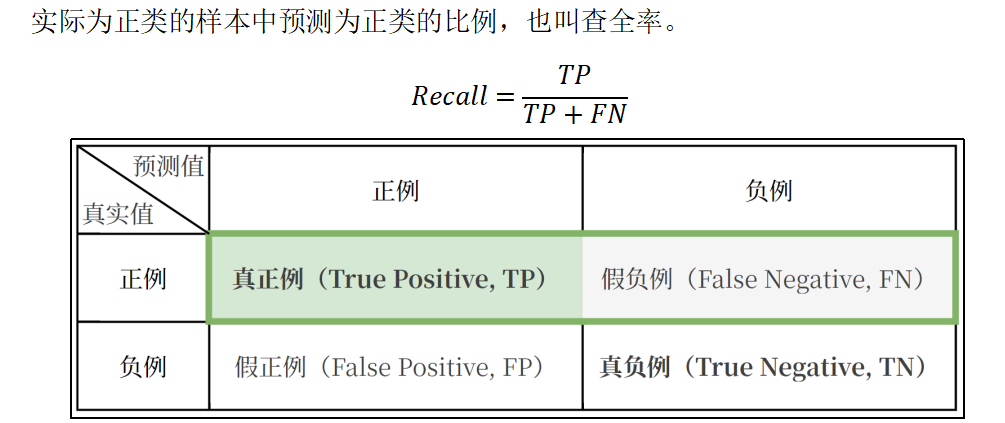
召回率
F1分数

ROC曲线

AUC
AUC值代表ROC曲线下的面积,用于量化模型性能。AUC值越大,模型区分正负类的能力越强,模型性能越好。AUC值=0.5表示模型接近随机猜测,AUC值=1代表完美模型。
最后用一个简单的代码示例来验证一下:
构建混淆矩阵
python
import pandas as pd
import seaborn as sns
from sklearn.metrics import confusion_matrix
label = ["猫", "狗"] # 标签
y_true = ["猫", "猫", "猫", "猫", "猫", "猫", "狗", "狗", "狗", "狗"] # 真实值
y_pred1 = ["猫", "猫", "狗", "猫", "猫", "猫", "猫", "猫", "狗", "狗"] # 预测值
matrix1 = confusion_matrix(y_true, y_pred1, labels=label) # 混淆矩阵
print(pd.DataFrame(matrix1, columns=label, index=label))
sns.heatmap(matrix1, annot=True, fmt='d', cmap='Greens')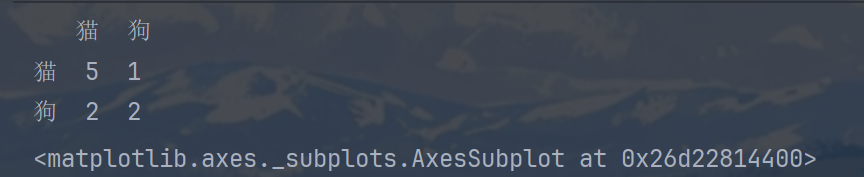
准确率
python
from sklearn.metrics import accuracy_score
label = ["猫", "狗"] # 标签
y_true = ["猫", "猫", "猫", "猫", "猫", "猫", "狗", "狗", "狗", "狗"] # 真实值
y_pred1 = ["猫", "猫", "狗", "猫", "猫", "猫", "猫", "猫", "狗", "狗"] # 预测值
accuracy = accuracy_score(y_true, y_pred1)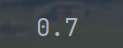
精确率
python
from sklearn.metrics import precision_score
label = ["猫", "狗"] # 标签
y_true = ["猫", "猫", "猫", "猫", "猫", "猫", "狗", "狗", "狗", "狗"] # 真实值
y_pred1 = ["猫", "猫", "狗", "猫", "猫", "猫", "猫", "猫", "狗", "狗"] # 预测值
precision = precision_score(y_true, y_pred1, pos_label="猫") # pos_label指定正例
print(precision)
召回率
python
from sklearn.metrics import recall_score
label = ["猫", "狗"] # 标签
y_true = ["猫", "猫", "猫", "猫", "猫", "猫", "狗", "狗", "狗", "狗"] # 真实值
y_pred1 = ["猫", "猫", "狗", "猫", "猫", "猫", "猫", "猫", "狗", "狗"] # 预测值
recall = recall_score(y_true, y_pred1, pos_label="猫") # pos_label指定正例
print(recall)