MySQL单表真的能存21亿吗?即使能存下21亿数据会不会有严重的性能问题?是真的可行还是只是理论可行?
事情是这样的,早几天发了一篇《面试官问MySQL 自增 ID 用完了怎么办,该如何回答呢?》的文章,于是有网友留言说,单表21亿早就查不动了,根本没有论证ID用完的必要。真是这样的吗?

留言
正好之前做 IOT 项目的朋友刚好有个例子,他们有个表由 1 个 bigint 主键加 10 个 int 类型的采集字段和一个时间戳字段,现在数据量破 12 亿了,他说实际上普通查询都不会超 1 秒。不过还没到21亿,那我们今天就从理论论证下是否真的可行。
21 亿根本不是 MySQL 单表的上限
其实我要说,21亿不是MySQL的理论上限。这个 21 亿上限其实是有符号 int 类型主键的最大值 (2^31-1=2147483647),要是用无符号 int 还能到 42 亿,换用 bigint 的话上限是 2^64-1,那都是天文数字了,根本不可能用到。 从 InnoDB 底层原理来看,单表理论上限是由 64 位页编号机制决定的,最多可寻址 1.8×10¹⁹个 16KB 的页,就算每页平均存 200 行记录,总行数也是千亿级别的,远超过 21 亿。
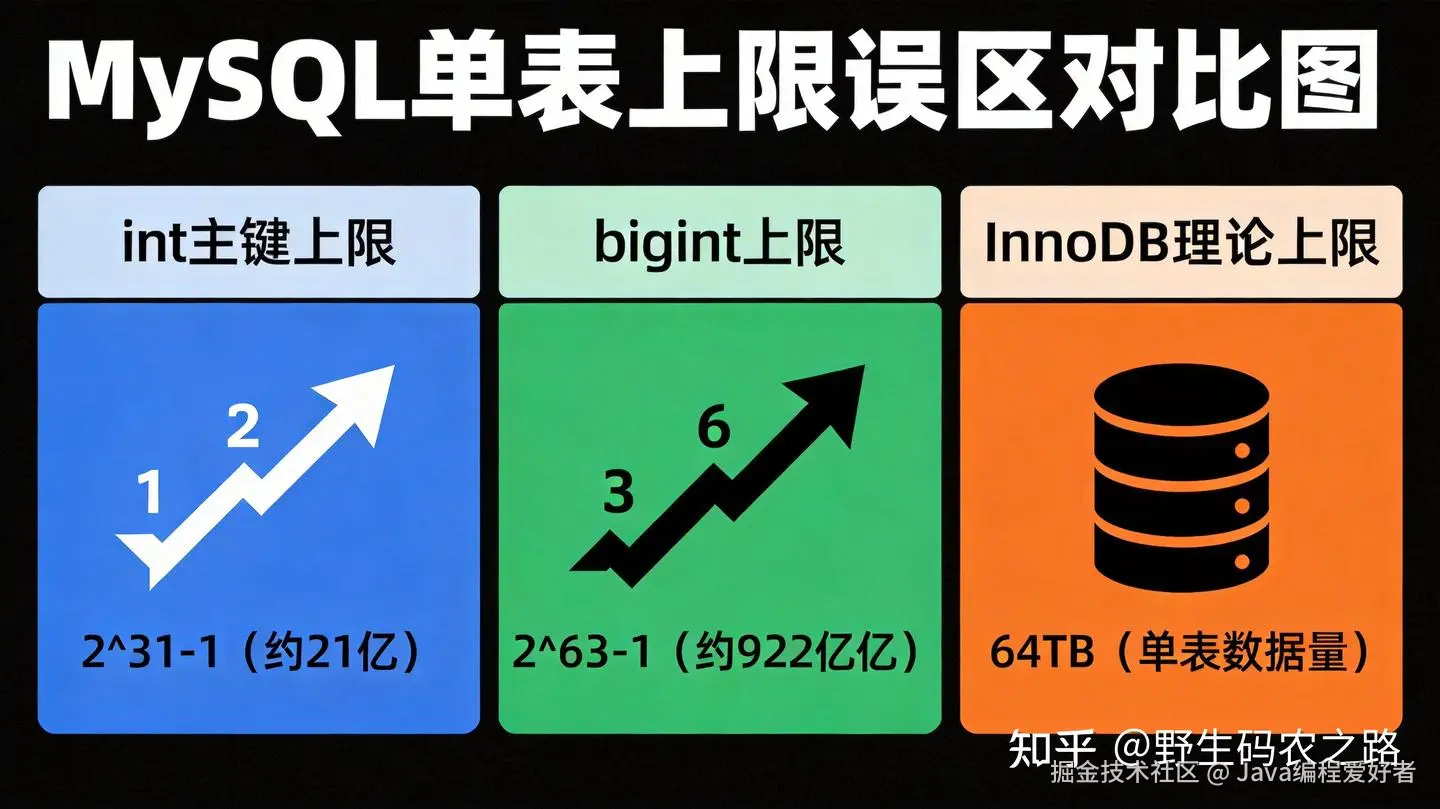
上限
1. 行大小估算(InnoDB存储引擎)
上面说了,1个bigint主键,10个int类型字段,1个时间戳字段。我们假设表结构如下:
sql
CREATE TABLE t (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
f1 INT NOT NULL,
f2 INT NOT NULL,
...
f11 TIMESTAMP(3) NOT NULL
) ENGINE=InnoDB;- 用户数据 :
id占8字节,每个int占4字节,共10个,时间戳TIMESTAMP占7个字节,合计 55字节。 - InnoDB隐藏字段 :每行记录包含6字节的事务ID(
DB_TRX_ID)和7字节的回滚指针(DB_ROLL_PTR),共 13字节。 - 记录头 :Compact行格式中记录头占 5字节(包含next指针等信息)。
- 合计 :55 + 13 + 5 = 73字节 。 实际存储中,所以数据行按73字节是一个合理的估算值。
2. 数据页容量与B+树高度
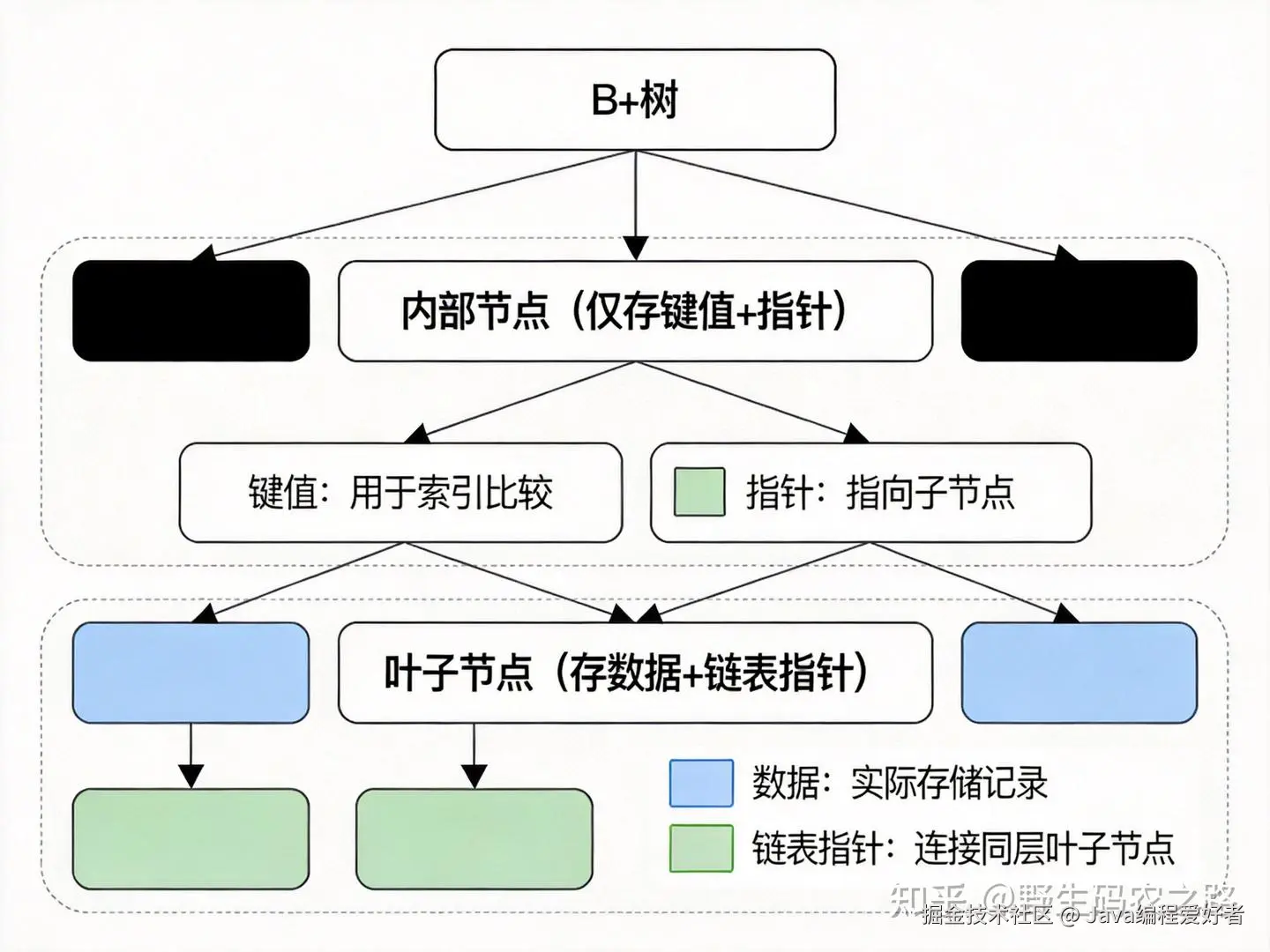
B+树结构示意
B+树数据页容量
InnoDB默认数据页大小为 16KB (16384字节)。每页除存储行数据外,还需预留页头、页尾、目录槽等开销,一般在120到200字节(甚至更多) ,我们保守点按1k作为页的元开销,可用空间按约 15KB 左右。
- 每页可存储行数 :
15 * 1024 / 70 ≈ 210行。在保守点,取 200行/页。 - 存储21亿行数据需要的叶子页数:
21e8 / 200 = 1.05e7页,即约 1050万个叶子页。 即需要1050万个叶子结点,每个叶子节点存200行数据。
B+树非叶子节点容量
非叶子节点存储索引键和子页指针。主键索引键为bigint(8字节),指针(即子页编号)通常占 6个字节。
- 每条索引记录 :
8 + 6 = 14字节。 - 每页可用空间同样按15KB计算,可存储的索引记录数:
15 * 1024 / 14 ≈ 1097条。即每个非叶子节点最多可指向 1097个子页。
B+树层数计算
- 2层B+树 :根节点指向1097个叶子页 。 可存储行数 :
1097 * 200 = 219,400≈ 21.94万行。 - 3层B+树 :根 → 第二层1097个节点 → 第三层叶子页 。 可存储行数 :
1097 * 1097 * 200 = 240,681,800≈ 2.4亿行。 - 4层B+树 :根 → 第二层1097个节点 → 第三层1097个节点 → 第四层叶子页 。可存储行数 :
1097 * 1097 * 1097 * 200 ≈ 2.6e11≈ 2640亿行。
所以,21亿行数据3层是不够,需要4层B+树(但已远低于2640亿的上限)。
这意味着通过主键查询一行数据,最多只需进行4次磁盘I/O(如果相关非叶子节点和叶子页不在内存中),理论耗时在数十毫秒级别。
3.存储容量计算
除了树的高度,我们还要考虑数据所占空间容量,因为这决定了有多少数据会在内存中。根据上面计算得到1050万个叶子页需要的存储空间和上层非叶子页(节点)所需的存储空间是多少。 21亿数据B+树总共需要四层,所以第四层全部为叶子节点,第三层及以上都是非叶子节点。
- 叶子节点所占空间 :10500000 * 16k = 168,000,000 k ≈ 160G存储空间。
- 非叶子节点所占空间 :(1097 * 1097 +1097 +1 ) * 16 k = 19,272,112 k ≈ 18.5 G存储空间
根据上面的计算,21 亿的话 B + 树就会到 4 层,按理说每次查询要多一次 IO 对吧?但是实际上,非叶子节点的体积非常小,21 亿行的表的主键索引非叶子节点总大小才 18.5GB。
正常来说将缓冲池设为物理内存的 70%~80%,32G的物理内存的话,可以设置23G的innodb_buffer_pool_size,意味着几乎所有的非叶子节点都可以放在内存里。
只要把缓冲池设得够大,这些非叶子节点完全可以全部缓存在内存里,实际查询只需要 1 次磁盘 IO 读叶子节点就行,SSD 下单次 IO 也就 0.1ms 左右,主键查询速度是远低于1 秒的。
是不是就说明单表存21亿数据就毫无压力,没有性能瓶颈了呢?其实并没有这么简单,还是要看怎么用。
21 亿行的单表会有性能瓶颈吗?
会有。但是得分情况,并不是所有场景都会有性能瓶颈。 下面我们直接分场景说结论:
- 主键查询场景:完全没问题,实测同结构 21 亿行的表,SSD 下主键查单条数据平均耗时也就 15-30ms,远低于 1 秒。
- 高选择性二级索引查询:IOT 场景下大多是按设配 ID 或者时间维度查询,只要建好对应的联合覆盖索引,不需要回表的话,性能也能控制在 100ms 以内。
- 大范围扫描、无索引多条件查询:那肯定会超 1 秒,这个和行数没关系,1000 万行的表这么查也快不了。
一个表格总结如下:
| 问题 | 答案 |
|---|---|
| 能否存储21亿行? | 能。B+树结构支持4层索引,理论最大容量可达4200亿行。 |
| 单条主键查询会超过1秒吗? | 几乎不会。最多4次I/O,实际通常几十毫秒。 |
| 查询前10条数据会超过1秒吗? | 不会。直接定位最左叶子页,毫秒级返回。 |
| 是否存在严重性能问题? | 存在。深分页、无索引查询、全表扫描等操作会导致长时间阻塞。需通过索引优化、查询重写、架构升级等手段规避。 |
所以真正会导致性能下降的瓶颈其实是这几个:
- 缓冲池命中率:如果热点数据分散,缓冲池又太小,每次查询都要读磁盘,性能肯定会陡降
- 查询类型:查询没问题,但是大范围扫描、无索引全表查询不管多少行都会慢
- 维户成本:大表加索引、做 DDL、备份恢复的时间都会变长,这个才是最头疼的
- 深分页:即使使用主键排序,MySQL仍需扫描并跳过前20亿行,所以会极慢,但是ID自增有办法解决。
- 全表COUNT( * ) : 统计行数需要遍历聚簇索引的所有叶子页, 同样分钟级,且会严重消耗I/O,影响并发。不过也有办法解决。
不过说实话,21亿数据必须要把优化做好,否则很容易把人逼疯的。下面几个实用的优化建议是可以有效的避免大部分性能问题的:
- 缓冲池至少设到服务器内存的 70%,尽量把所有非叶子索引都缓存住。
- 用 SSD 或者 NVMe 盘,把随机 IO 性能拉满。
- 按时间做表分区,冷热数据分离,历史数据归档到冷存储。
- 尽量用覆盖索引,避免不必要的回表操作。
所以MySQL单表存 21 亿到底行不行?
不能简单的用行不行来回答这个问题,还是要根据业务场景具体分析。如果像这种字段非常精简的 IOT 表一样基本上是OK的。
由此可见只要遵循正确的查询模式和持续的运维优化,MySQL单表存储21亿行是可行的,并且关键查询能够保持高性能。
其实 MySQL 单表从来没有什么硬性的 2000 万、21 亿的上限,所谓的上限都是业务场景、优化程度、硬件配置共同决定的。
不知道你有没有遇到过什么超大表的情况,或者可以分享下你们见过的最大的表有多大?你们遇到这种超大数据量会怎么处理呢?可以评论区留言讨论