GIT仓库 | 项目概述 | OpenHarness 源码 | OpenHarness 架构说明
版本 :v0.2.0 | 阶段 :P1 是 Web 服务可用版 | 日期 :2026-04-22 描述:P1 是 Web 服务可用版,在 P0 Agent 核心能力基础上,构建完整的 Web 服务闭环------SSE 流式对话、简历渲染下载、记忆管理 API、用户配置、工具系统 API,实现单用户完整流程。
功能预览
一、核心成果
| 模块 | 交付物 | 核心价值 |
|---|---|---|
| 简历渲染与下载 | Markdown → PDF/HTML 渲染引擎 + 快照持久化 + 5 个 API 端点 | 对话生成简历后可即时下载,会话淘汰后简历仍可访问 |
| 记忆管理 API | 5 个 CRUD 端点 + 简历上传 + 记忆注入提示词 | 用户上传简历后自动注入对话上下文,"越用越好用" |
| 用户配置 | UserSettings 模型 + 2 个 API 端点 | 每用户独立配置模板偏好、语言风格、输出语言 |
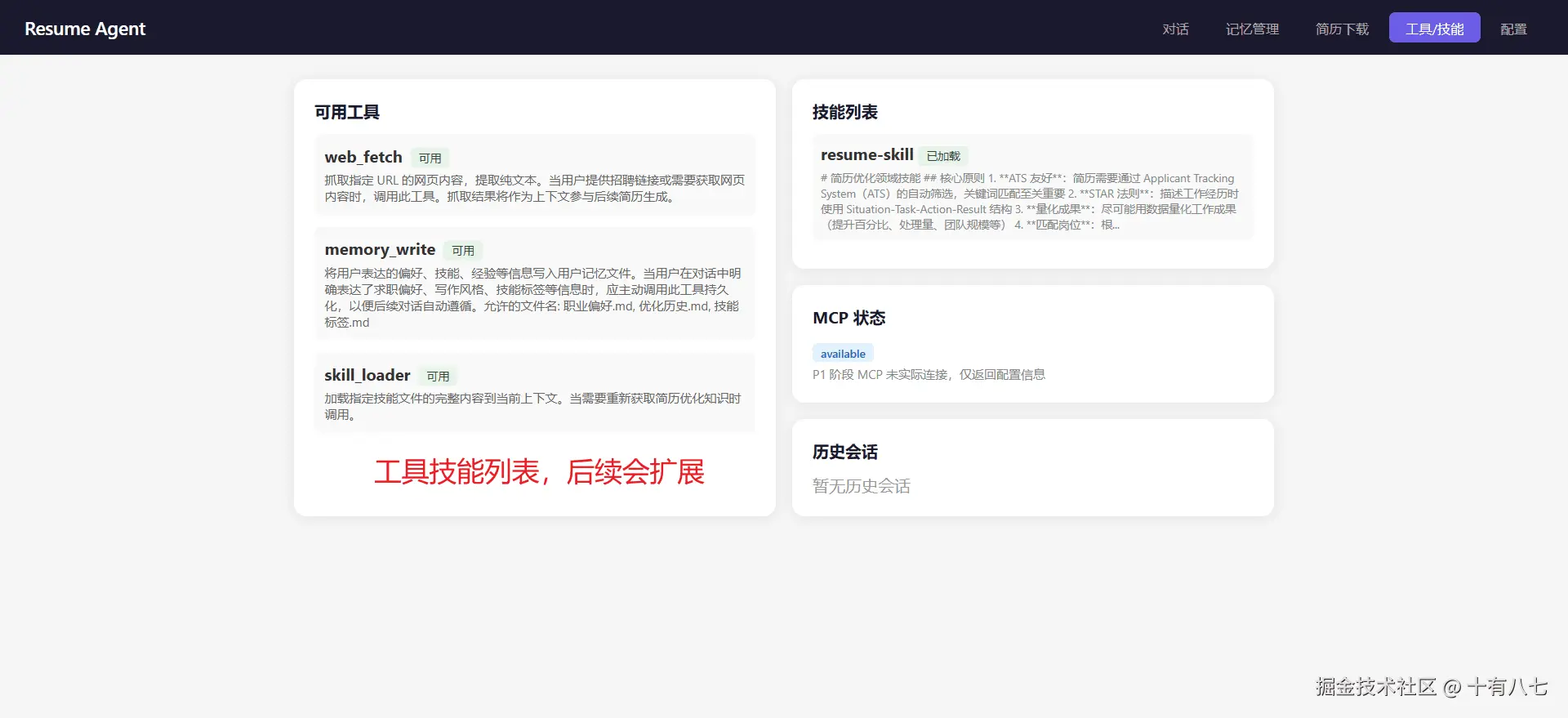
| 工具与系统 API | 工具列表 / MCP 状态 / Skill 列表 / 会话历史 5 个端点 | 可观测性 + 会话回溯,支撑前端验证页面 |
| 前端验证页面 | 5 Tab 面板(对话/记忆/简历/工具/配置) | 端到端可验证的交互界面 |
API 全景
bash
POST /api/chat SSE 流式对话
GET /api/resume 列出简历快照
GET /api/resume/{id}/download 下载简历(PDF/HTML/MD)
GET /api/resume/{id}/preview 预览简历
DELETE /api/resume/{id} 删除简历
GET /api/resume/templates 模板列表
GET /api/memory 记忆文档列表
GET /api/memory/{doc_name} 读取记忆文档
PUT /api/memory/{doc_name} 更新记忆文档
DELETE /api/memory/{doc_name} 删除记忆文档
POST /api/memory/upload 上传简历原文
GET /api/settings 获取用户配置
PUT /api/settings 更新用户配置
GET /api/tools 工具列表
GET /api/mcp/status MCP 状态
GET /api/skills Skill 列表
GET /api/sessions 会话列表
GET /api/sessions/{id} 会话详情二、成果展示
2.1 简历渲染与下载
三格式输出 --- 支持 PDF(fpdf2)、HTML(python-markdown + CSS 模板)、Markdown 原文三种下载格式,配合三套专业模板:
| 模板 | 风格 | 适用场景 |
|---|---|---|
professional |
简洁商务 | 互联网 / 科技 |
academic |
学术风格 | 高校 / 研究所 |
creative |
创意排版 | 设计 / 市场 |
快照解耦设计 --- 简历 ID 与会话 ID 解耦,LLM 生成简历后自动保存快照,通过 SSE 推送 resume_generated 事件,即使会话被 LRU 淘汰,简历仍可通过 resume_id 下载。
渲染队列 --- 基于异步 Queue + Lock 实现单并发渲染队列,60 秒超时保护,避免 PDF 渲染 OOM。
2.2 记忆管理
四类记忆文档:
| 文件 | 更新方式 | 容量限制 |
|---|---|---|
简历原文.md |
上传 API(LLM 不可修改) | 16 KB |
职业偏好.md |
LLM memory_write / API |
4 KB |
技能标签.md |
LLM memory_write / API |
4 KB |
优化历史.md |
LLM memory_write / API |
4 KB |
"越用越好用" --- 对话时自动加载用户记忆注入系统提示词,LLM 通过 memory_write 主动持久化用户偏好,后续对话自动遵循,无需重复说明。
2.3 用户配置
每用户独立配置文件 settings.json,支持:
| 配置项 | 默认值 | 说明 |
|---|---|---|
default_template |
professional |
默认简历模板 |
language_style |
professional |
语言风格(professional/casual/academic) |
output_language |
zh-CN |
输出语言 |
auto_save_resume |
true |
是否自动保存简历快照 |
2.4 工具系统
| 工具 | 类型 | 核心能力 |
|---|---|---|
memory_write |
写入工具 | LLM 主动写入用户偏好/技能/历史,白名单控制 + 容量控制 |
web_fetch |
只读工具 | 抓取 URL 网页内容(JD 解析),5 分钟缓存 + readability-lxml 提取 |
skill_loader |
只读工具 | LLM 主动加载 resume-skill.md 到上下文(长对话压缩后重新注入) |
三、核心实现
3.1 记忆注入提示词流程
记忆系统是 Resume Agent "越用越好用"的核心,关键在于将用户记忆文件自动注入系统提示词,使 LLM 在每次对话中都能感知用户的偏好和历史。
r
┌──────────────────────────────────────────────────────────────┐
│ 记忆注入提示词流程 │
└──────────────────────────────────────────────────────────────┘
POST /api/chat {prompt, session_id}
│
▼
SessionPool.get_or_create(user_id, session_id)
│
▼
build_resume_system_prompt(user_id)
│
├──① 基础角色提示词
│ RESUME_AGENT_SYSTEM_PROMPT
│ (角色定义 + 输出格式 + 工作原则 + 工具规范)
│
├──② 加载用户记忆文件
│ load_memory_documents(user_id)
│ └── 遍历 ~/.resume_agent/users/{user_id}/memory/*.md
│ ├── 简历原文.md → max 16KB
│ ├── 职业偏好.md → max 4KB
│ ├── 技能标签.md → max 4KB
│ └── 优化历史.md → max 4KB
│
├──③ 加载领域技能
│ load_resume_skill()
│ └── resume_agent/skills/resume-skill.md
│ (ATS 友好、STAR 法则、量化成果、关键词匹配)
│
▼
组装为完整 system_prompt:
┌─────────────────────────────────────────┐
│ # 角色定义 │
│ ... │
│ ## 用户专属记忆 │
│ ### 简历原文.md │
│ ```md │
│ 张三 | 前端工程师 | 5年经验... │
│ ``` │
│ ### 职业偏好.md │
│ ```md │
│ 偏好简洁风格,不要用 STAR 法式... │
│ ``` │
│ ## 简历优化技能指南 │
│ ... │
└─────────────────────────────────────────┘
│
▼
QueryEngine.submit_message(prompt)
│
▼
Agent Loop → DeepSeek API → 流式回复
│
├── LLM 识别用户偏好 → memory_write(doc_name="职业偏好.md", ...)
├── LLM 生成简历 → resume_generated SSE 事件
└── LLM 记录优化历史 → memory_write(doc_name="优化历史.md", ...)核心代码 (resume_agent/prompts/system_prompt.py):
python
async def build_resume_system_prompt(
user_id: str,
latest_user_prompt: str | None = None,
) -> str:
"""构建简历 Agent 的系统提示词,注入用户专属记忆。"""
# 1. 基础角色提示词
parts = [RESUME_AGENT_SYSTEM_PROMPT]
# 2. 加载用户记忆文件
memory_texts = load_memory_documents(user_id)
if memory_texts:
parts.append("\n## 用户专属记忆\n" + memory_texts)
# 3. 加载 resume-skill.md
skill_text = load_resume_skill()
if skill_text:
parts.append("\n## 简历优化技能指南\n" + skill_text)
return "\n".join(parts)3.2 memory_write 工具调用流程
memory_write 是 LLM 主动持久化用户信息的关键工具,通过白名单控制 + 容量限制确保安全与可控。
ini
┌──────────────────────────────────────────────────────────────┐
│ memory_write 工具调用流程 │
└──────────────────────────────────────────────────────────────┘
LLM 识别用户表达偏好/技能
│
▼
tool_use: memory_write(doc_name, content, mode)
│
▼
MemoryWriteTool.execute(arguments, context)
│
├── 从 context.metadata 获取 user_id
│
├── 白名单校验
│ doc_name ∈ {"职业偏好.md", "技能标签.md", "优化历史.md"} ?
│ ├── 否 → 返回 ToolResult(is_error=True)
│ └── 是 → 继续
│
├── 保护校验
│ doc_name == "简历原文.md" ? → 拒绝(仅通过上传 API)
│
├── write_memory_file(user_id, doc_name, content, mode)
│ │
│ ├── mode == "replace" ?
│ │ └── 直接覆盖写入
│ │
│ ├── mode == "append" ?
│ │ ├── 读取现有内容
│ │ └── 拼接: existing + "\n\n" + new_content
│ │
│ └── 容量控制
│ 超出 max_bytes (4KB)?
│ ├── append 模式: 保留新内容,截断旧内容
│ └── replace 模式: 直接截断
│
└── 返回 ToolResult(output="已成功写入记忆文件...")核心代码 (resume_agent/memory/manager.py):
python
WRITABLE_MEMORY_FILES = {"职业偏好.md", "技能标签.md", "优化历史.md"}
PROTECTED_MEMORY_FILES = {"简历原文.md"}
def write_memory_file(
user_id: str | None,
doc_name: str,
content: str,
mode: str = "append",
) -> Path:
if doc_name in PROTECTED_MEMORY_FILES:
raise ValueError(f"不允许通过 memory_write 修改 {doc_name},请使用上传 API")
if doc_name not in WRITABLE_MEMORY_FILES:
raise ValueError(f"不支持的记忆文件名: {doc_name}")
# ... 读取/拼接/容量控制 ...
# 容量控制:超出限制时,保留新内容,截断旧内容
if len(final_content.encode("utf-8")) > max_bytes:
if mode == "append" and existing:
keep_new = content.strip()
available = max_bytes - len(keep_new.encode("utf-8")) - 4
if available > 0:
final_content = existing[:available] + "\n\n" + keep_new
else:
final_content = keep_new[:max_bytes]
else:
final_content = final_content[:max_bytes]
path.write_text(final_content.strip() + "\n", encoding="utf-8")
return path3.3 简历渲染与快照持久化流程
lua
┌──────────────────────────────────────────────────────────────┐
│ 简历渲染与快照持久化流程 │
└──────────────────────────────────────────────────────────────┘
LLM 流式输出简历内容
│
▼
chat.py: _extract_resume_content(message)
│ 正则检测: ^#\s+.+\n.*(?:工作经历|教育背景|技能|...)
│
├── 匹配 → resume_md
│ │
│ ▼
│ save_resume_snapshot(user_id, resume_md)
│ │
│ ├── 生成 resume_id: resume_{timestamp}_{random}
│ ├── 保存到 ~/.resume_agent/users/{uid}/resumes/{resume_id}.md
│ ├── 清理超出 20 份的旧快照
│ │
│ ▼
│ SSE 推送: {"type": "resume_generated", "resume_id": "..."}
│
└── 不匹配 → 忽略
─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─
用户点击"下载 PDF"
│
▼
GET /api/resume/{resume_id}/download?format=pdf&template=professional
│
▼
resume_renderer.render_resume()
│
├── format=html → _markdown_to_html(md, template) → HTML+CSS
├── format=pdf → _render_pdf_sync(md, template)
│ └── fpdf2 渲染(跨平台字体搜索 Win/Mac/Linux)
└── format=markdown → 直接返回原文
│
▼
返回文件流渲染队列伪代码 (resume_renderer.py):
python
# 渲染队列:同时仅允许 1 个 PDF 渲染任务
_render_lock = asyncio.Lock()
_render_queue = asyncio.Queue()
async def _render_worker():
"""后台渲染工作协程,逐个消费队列中的渲染任务。"""
while True:
job = await _render_queue.get()
try:
result = await asyncio.wait_for(_do_render(job), timeout=60)
job.future.set_result(result)
except Exception as exc:
job.future.set_exception(exc)
async def render_resume(markdown_content, *, template, output_format, user_id, resume_id):
"""提交渲染任务到队列,等待结果。"""
await _ensure_render_worker() # 确保工作协程已启动
job = _RenderJob(markdown_content, template, output_format, user_id, resume_id)
job.future = asyncio.get_running_loop().create_future()
await _render_queue.put(job) # 入队
result = await job.future # 等待渲染完成
return result, job.resume_id3.4 用户配置双层架构
bash
┌──────────────────────────────────────────────────────────────┐
│ 用户配置双层架构 │
└──────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ 全局配置 ResumeAgentSettings │
│ ~/.resume_agent/settings.json │
│ │
│ api_format, base_url, model, api_keys │
│ max_sessions, idle_timeout, memory_*, mcp_servers │
│ → 环境变量 > settings.json > 默认值 │
└─────────────────────────────────────────────────────────┘
│
│ 每用户覆盖
▼
┌─────────────────────────────────────────────────────────┐
│ 用户配置 UserSettings │
│ ~/.resume_agent/users/{user_id}/settings.json │
│ │
│ default_template: professional │
│ language_style: professional │
│ output_language: zh-CN │
│ auto_save_resume: true │
│ → PUT /api/settings 部分更新 │
└─────────────────────────────────────────────────────────┘用户配置 API 伪代码 (backend/routes/settings.py):
python
@router.get("/settings")
async def get_user_settings_api(request):
user_id = _get_user_id(request)
return load_user_settings(user_id).model_dump()
@router.put("/settings")
async def update_user_settings_api(request, body):
user_id = _get_user_id(request)
current = load_user_settings(user_id) # 加载当前配置
update_data = {k: v for k, v in body.items() # 提取有效字段
if k in UserSettings.model_fields}
updated = current.model_copy(update=update_data) # 合并更新
save_user_settings(user_id, updated) # 持久化
return updated.model_dump()3.5 web_fetch 工具 --- JD 链接解析
ini
┌──────────────────────────────────────────────────────────────┐
│ web_fetch 工具流程 │
└──────────────────────────────────────────────────────────────┘
用户: "帮我优化简历,投递这个岗位:https://job.example.com/123"
│
▼
LLM 识别 URL → tool_use: web_fetch(url="https://job.example.com/123")
│
▼
WebFetchTool.execute()
│
├── 协议校验: 仅允许 http/https
│
├── 缓存检查: _url_cache[url] 是否在 5 分钟 TTL 内?
│ ├── 命中 → 直接返回缓存内容
│ └── 未命中 → 继续
│
├── httpx.AsyncClient.get(url, timeout=10s)
│ ├── 超时 → ToolResult(is_error=True)
│ └── HTTP 错误 → ToolResult(is_error=True)
│
├── _extract_text(html)
│ ├── 优先 readability-lxml (Document.summary())
│ │ └── 去除 HTML 标签 → 纯文本
│ └── 回退: <article>/<main> 标签 + 正则
│
├── 缓存结果: _url_cache[url] = (content, timestamp)
│
└── 截断: content[:max_length] + "\n\n... (内容已截断)"
│
▼
LLM 结合 简历原文 + JD 内容 → 生成匹配岗位的优化简历3.6 记忆 CRUD API 设计
bash
┌──────────────────────────────────────────────────────────────┐
│ 记忆 CRUD API 流程 │
└──────────────────────────────────────────────────────────────┘
GET /api/memory
│ 列出用户记忆目录下所有 *.md 文件
│ 返回: [{name, size_bytes, modified_at, writable}]
│ writable: doc_name ∈ WRITABLE_MEMORY_FILES
▼
GET /api/memory/{doc_name}
│ 读取指定记忆文件内容
│ 不存在 → 404
▼
PUT /api/memory/{doc_name}
│ body: {content, mode: "append"|"replace"}
│ doc_name == "简历原文.md" → 400(请用上传 API)
│ 调用 write_memory_file() → 白名单校验 + 容量控制
▼
DELETE /api/memory/{doc_name}
│ doc_name == "简历原文.md" → 400(不允许删除)
│ path.unlink() 删除文件
▼
POST /api/memory/upload
│ 接收 .md/.txt 文件
│ .pdf → 400(暂不支持解析)
│ 内容写入 memory/简历原文.md(容量控制 16KB)四、技术亮点
4.1 记忆安全与可控
| 机制 | 实现 |
|---|---|
| 白名单控制 | WRITABLE_MEMORY_FILES 限定 LLM 可写入的文件名 |
| 保护文件 | 简历原文.md 不允许 LLM 修改,仅通过上传 API |
| 容量控制 | 简历原文 16KB / 其他 4KB,超出自动截断 |
| 优先保留新内容 | append 模式下超出容量时截断旧内容,保留最新追加 |
4.2 快照解耦设计
简历快照使用 resume_id(非 session_id)作为唯一标识,确保:
- 会话被 LRU 淘汰后简历仍可下载
- 同一会话可生成多份简历
- 每用户最多 20 份快照,超出自动清理最旧的
4.3 渲染队列安全
asyncio.Lock保证同一时刻仅 1 个 PDF 渲染任务asyncio.Queue排队处理并发请求- 60 秒超时保护,防止 fpdf2 渲染卡死
- 跨平台字体搜索(Windows/macOS/Linux)
4.4 web_fetch 双层提取
- 优先使用
readability-lxml提取正文(精确度高) - 回退到
<article>/<main>标签 + 正则提取(兼容性好) - 5 分钟 URL 缓存,避免重复请求
- 协议校验仅允许 HTTP/HTTPS
五、关键文件索引
| 模块 | 文件 | 职责 |
|---|---|---|
| 记忆管理 | resume_agent/memory/manager.py |
记忆加载/写入/容量控制 |
| 记忆路径 | resume_agent/memory/paths.py |
用户记忆目录路径管理 |
| 提示词组装 | resume_agent/prompts/system_prompt.py |
系统提示词 + 记忆注入逻辑 |
| 用户配置 | resume_agent/config/settings.py |
全局/用户级配置加载 |
| 记忆写入工具 | resume_agent/tools/memory_write.py |
LLM 主动写入记忆 |
| 网页抓取工具 | resume_agent/tools/web_fetch.py |
URL 内容抓取 + JD 解析 |
| 技能加载工具 | resume_agent/tools/skill_loader.py |
LLM 主动加载 resume-skill |
| 简历渲染 | resume_agent/resume_renderer.py |
渲染队列 + 快照持久化 |
| PDF 渲染 | resume_agent/render_pdf.py |
fpdf2 Markdown → PDF |
| 记忆 API | backend/routes/memory.py |
记忆 CRUD + 简历上传 |
| 配置 API | backend/routes/settings.py |
用户配置读写 |
| 管理 API | backend/routes/admin.py |
工具/MCP/Skill/会话查询 |
| 对话端点 | backend/routes/chat.py |
SSE 流式对话 + 简历自动保存 |
| 简历 API | backend/routes/resume.py |
简历下载/预览/模板 |