前言
IndexTTS2 是 哔哩哔哩开源的 TTS 模型,用于克隆音色并生成 AI 音频,能做到带有高兴、愤怒、悲伤等情感控制
虽然已经出来半年了,可依然属于 T0 级别
在这里查看/听到官网示例效果:index-tts.github.io/index-tts2....
感觉怎么样?心动了吗?快来跟我一起部署吧!(官方文档坑还是挺多的,我已经帮大家踩过了)
1. 下载 IndexTTS2
🌐 官网:github.com/index-tts/i...
1.1 通过 git 下载
1.1.1 检查 Git-LFS 是否初始化
因为 IndexTTS2 使用了 Git LFS 管理音频文件,所以我们需要确保电脑中存在 Git LFS,才能 git clone 时正常拉取音频文件
从 Git for Windows v2.7.0 (2016年) 起,已经集成了 Git LFS 组件。无需单独下载
先查看当前 git 版本
bash
git -v
再确认是否安装 Git LFS
bash
git lfs version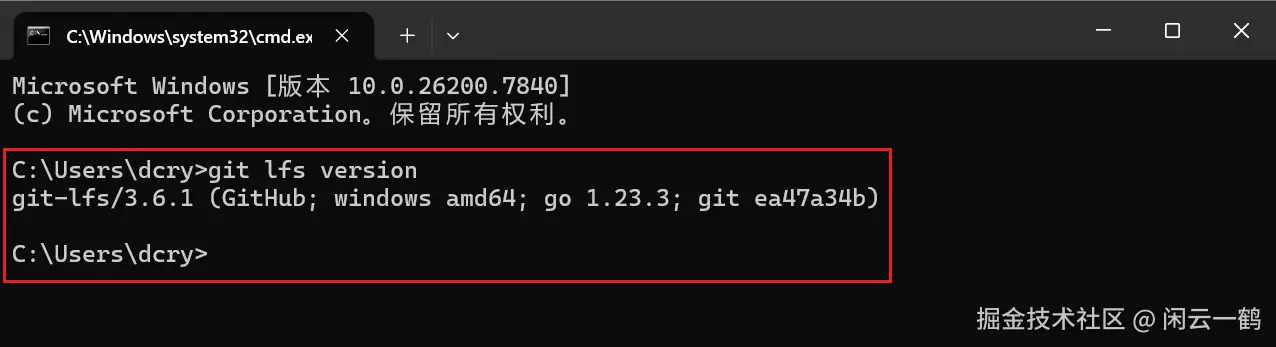
最后验证是否启动了 Git LFS
bash
git config --get-regexp filter.lfs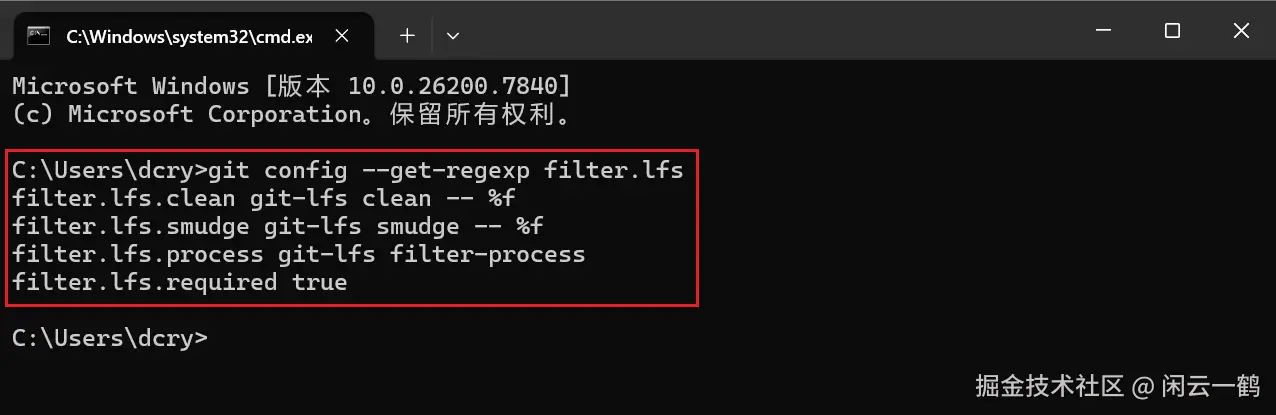
只要看到这个 clean、smudge、process 等内容就说明初始化成功
txt
filter.lfs.clean=git-lfs clean -- %f
filter.lfs.smudge=git-lfs smudge -- %f
filter.lfs.process=git-lfs filter-process
filter.lfs.required true如果发现自己没启动 Git LFS,运行命令启动
bash
git lfs install有关 Git LFS 的更多知识可以查阅我的另一篇文章
📝 《Git LFS 扫盲教程 - 你不会还在用 Git 管理大文件吧?》:juejin.cn/post/761265...
1.1.2 克隆 IndexTTS2 代码仓库
1.1.2.1 git clone
通过 git 下载并进入 index-tts 项目
bash
git clone https://github.com/index-tts/index-tts.git && cd index-tts本来我是应该在这里放一张 git clone 成功的截图的,可是碰到 Git LFS 流量限额了,所以就没办法截图了(小问题,别紧张,大家看到后面就知道了)
官方文档说要用 git lfs pull 命令下载大文件,这点不必听它的,git clone 实际上就已经把音频文件拉下来了(在 examples 目录下),git clone 知道哪些是大文件,并能通过 Git LFS 去找服务器下载原件
如果 git clone 过程中下载速度缓慢的话,大家可以运行 ping github.com 命令看下自己的延迟大不大,是否存在丢包
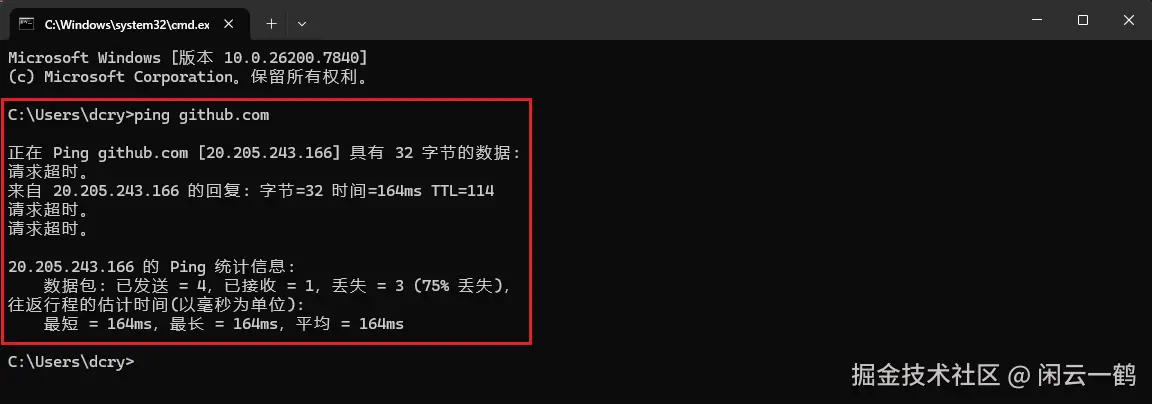
像这种情况不仅延迟大,丢包还严重,git clone 是肯定拉不下来代码的
也可以运行 tracert github.com 命令测试自己和 github 的连接情况
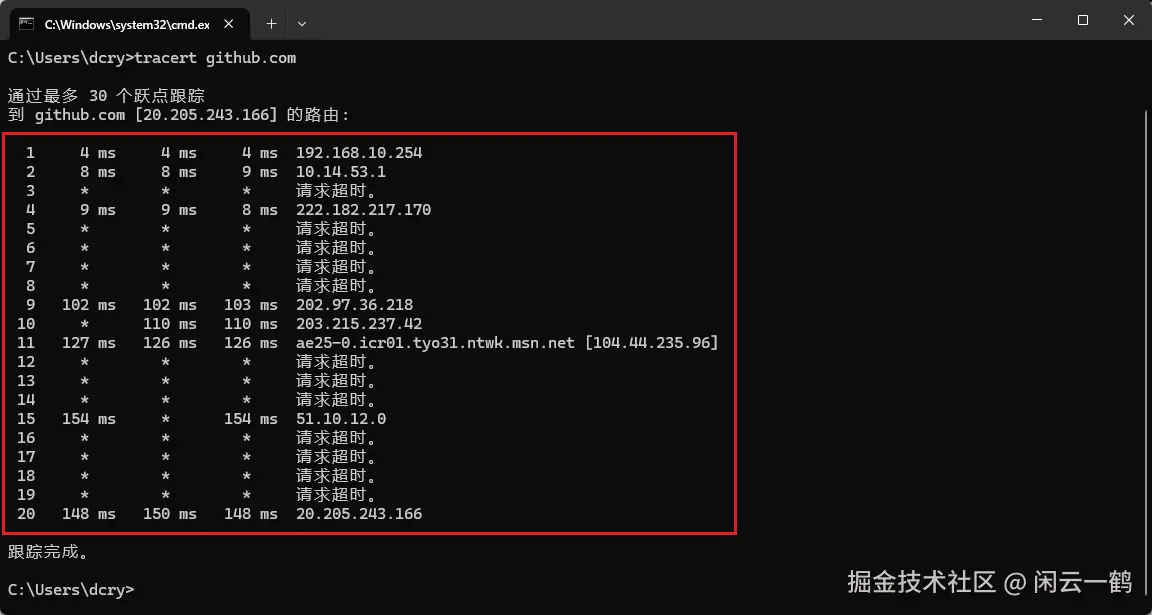
可以看到路径异常复杂、绕路严重,也证明和 github 的连接不稳定
1.1.2.2 解决 git clone 速度慢
-
打开
TUN(虚拟网卡)模式(推荐)因为一些众所周知的原因,不方便直接教人使用魔法工具,大家自行搜索关键词进行操作吧。
TUN(虚拟网卡)模式能接管系统所有流量,开了 TUN后,无论是
ping github.com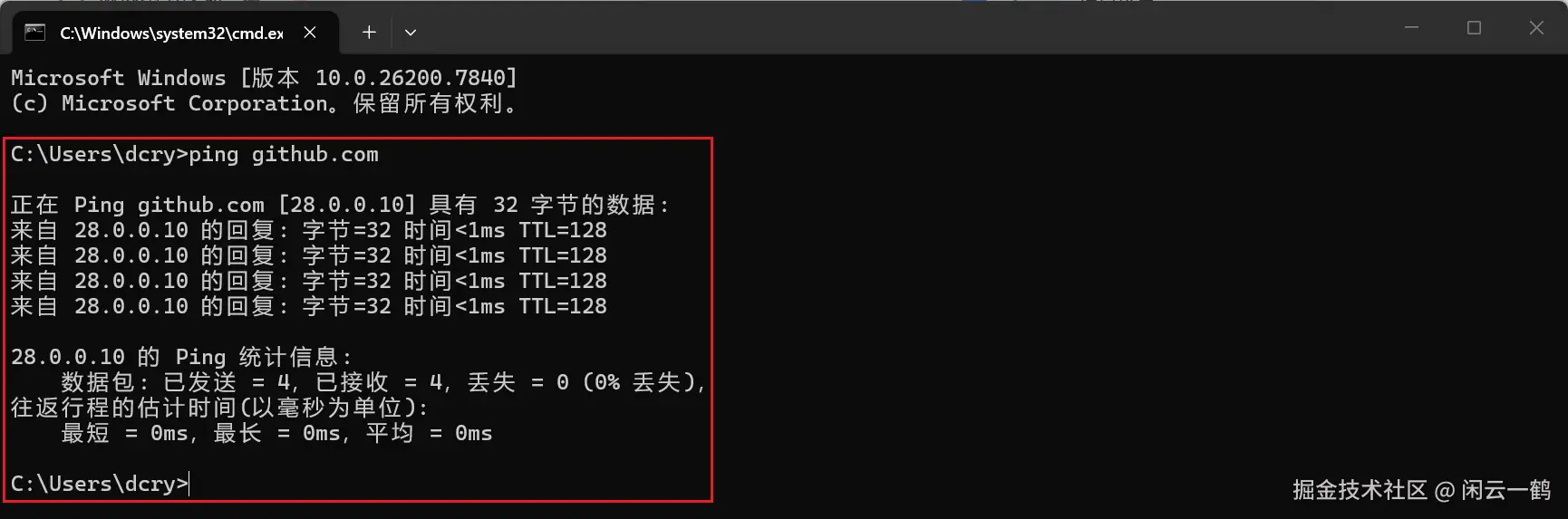
还是
tracert github.com都非常的稳定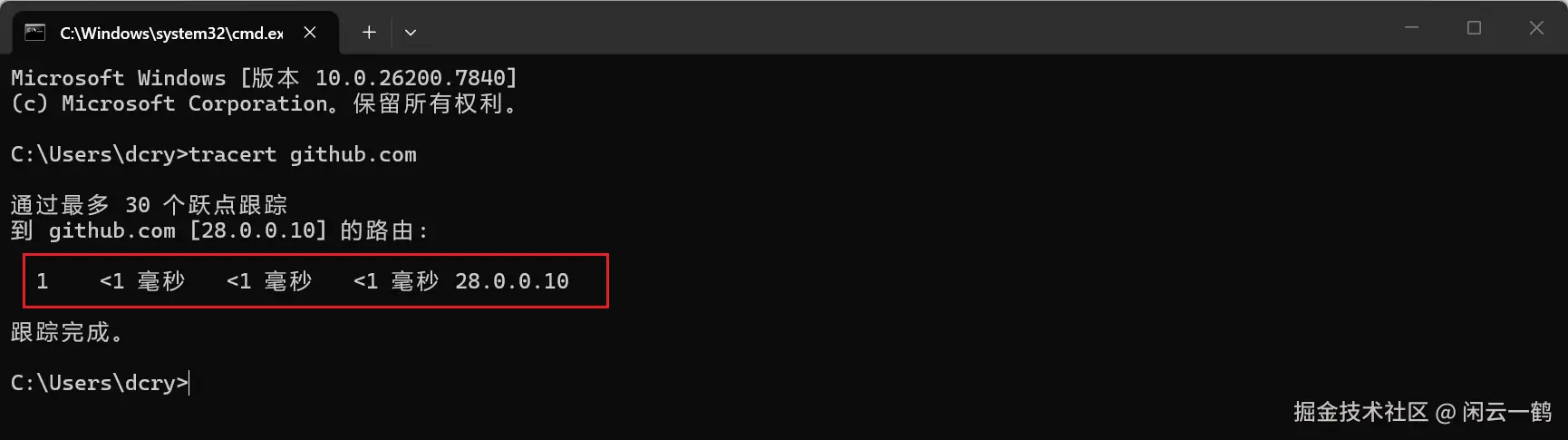
-
给 Git 配置代理端口(proxy)
打开你的魔法工具的软件设置,找到系统代理端口,我的端口是 7897
在终端输入以下两行
bashgit config --global http.proxy http://127.0.0.1:7897 git config --global https.proxy http://127.0.0.1:7897配置完后,git 下载就会走魔法工具的代理端口了,重新运行克隆命令:你会发现速度瞬间飙升
下载完后,如果想重置回默认,运行
git config --global --unset http.proxy即可
1.1.2.3 解决 Git LFS 流量限额
⚠️ 注意:你克隆项目的时候可能会碰到这个错误:"此存储库已超出其 LFS(大型文件存储)预算。负责预算的账户应增加预算以恢复访问权限"
是因为 IndexTTS2 仓库的 Git LFS 流量额度已经用完,Git LFS 有每月配额限制,额度用完了就无法拉取项目中的音频文件,所以 examples 目录下是空的
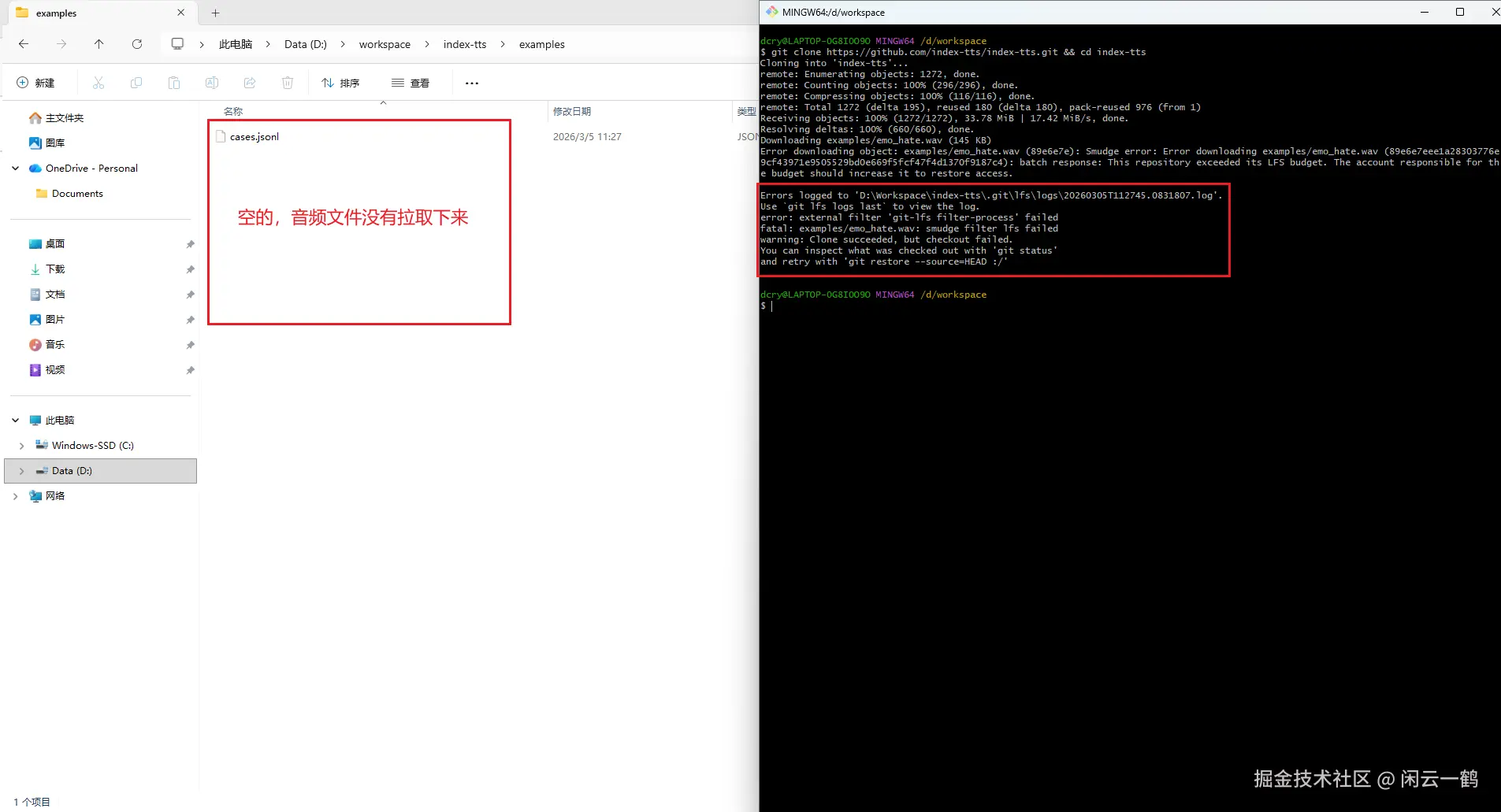
只能从 github 手动下载并放到 examples 目录(具体教程参考下面的 1.2 下载 zip 压缩包 章节)
Git LFS 流量额度每月初自动重置,我 3 月 3 号的时候就可以正常拉取,今天 3 月 5 号就限额了。害,看来 IndexTTS2 仓库是挺火爆的
1.2 下载 zip 压缩包
没有魔法工具的话也可以直接下载 zip 压缩包:Code -> Download ZIP
这种方式拉取的项目,由于没运行 git ,所以就没执行到 git lfs 命令,所以 examples 目录下只有几百字节的"指针文件"
需要单独下载这几个演示音频文件到 examples 目录
打开浏览器:github.com/index-tts/i... → 每个 .wav 文件点进去 → 点击右上角 Download raw file
下载后放到你项目根目录下的 examples 里即可
1.3 通过镜像站克隆
国内的 GitHub 镜像加速站有 kgithub.com 和 ghproxy.com
不推荐使用第三方镜像库,怕有毒(个人意见)

2. 安装依赖
官方推荐并且使用的是 uv 包管理器,所以我们用 uv 来安装项目依赖。不会 uv 的同学可以看我的另一篇文章
📝 《Python 入门(一)- 用 UV 管理 Python》:juejin.cn/post/760585...
在 index-tts 文件夹内执行命令
bash
uv sync --extra webui命令解释:使用 uv 同步环境并安装 WebUI 插件
⚠️ 注意:Windows 系统中安装 DeepSpeed 容易报错导致整个安装流程中断(Windows 默认没有 Linux 那样完善的 C++ 开发环境,如 GCC、库依赖等,经常报"缺少编译器"或"链接失败"的错误),并且我的 8G 显存配合 FP16 已经足够流畅,IndexTTS-2 模型本身不大(几 GB),使用 DeepSpeed 的提升感并不明显,所以我不使用 --all-extras(--all-extras 表示安装全部可选功能),只装基础环境和 WebUI 相关组件
👉 如果中国大陆地区用户下载缓慢,可选用国内镜像:
阿里云镜像
bash
uv sync --extra webui --default-index "https://mirrors.aliyun.com/pypi/simple"或者清华大学镜像
bash
uv sync --extra webui --default-index "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple"3. 模型下载
3.1 ModelScope(魔搭社区)下载模型
国内用户推荐在 ModelScope(魔搭社区)下载模型,不推荐 Hugging Face(抱抱脸)下载(服务器在国外),ModelScope 上的 IndexTeam/IndexTTS-2 镜像和 HuggingFace 上的权重文件是一模一样的(MD5 校验一致)
ModelScope 是直连杭州/北京的阿里云服务器,国内直连,速度快,完全不消耗魔法工具的流量,而且带宽往往能跑满你的物理网速
安装 modelscope 工具
bash
uv tool install "modelscope"
通过 modelscope 下载模型
bash
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints模型会自动下载到 checkpoints 文件夹,下载完后 checkpoints 文件夹里会有 config.yaml + 所有 .pth 文件
尴尬的是,完全照着官方文档操作,走到这一步后,下载模型报了这个错误:ModuleNotFoundError: No module named 'pkg_resources' ,没有找到 pkg_resources 模块
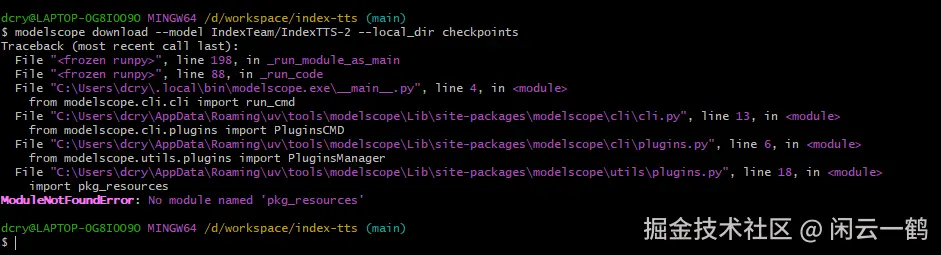
原因是 ModelScope 依赖 setuptools 包(pkg_resources 是它的子模块),但 uv tool install "modelscope" 没自动拉取 setuptools 这个包
在传统的 pip 安装习惯中,setuptools 通常是默认自带的,uv 是一个非常现代、精简的包管理器。为了追求速度和纯净,uv 在创建工具环境时默认不会安装 setuptools 这种老旧的兼容包
官方文档没有提到这个错误,估计是因为他们可能是在已经装过很多库的旧环境里测试的,而我的环境太"干净"了
3.2 解决 No module named 'pkg_resources' 错误
第一步:卸载当前有问题的 modelscope 工具
bash
uv tool uninstall modelscope第二步:添加依赖到项目
bash
uv add modelscope setuptools wheel第三步:通过项目环境下载
bash
uv run modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints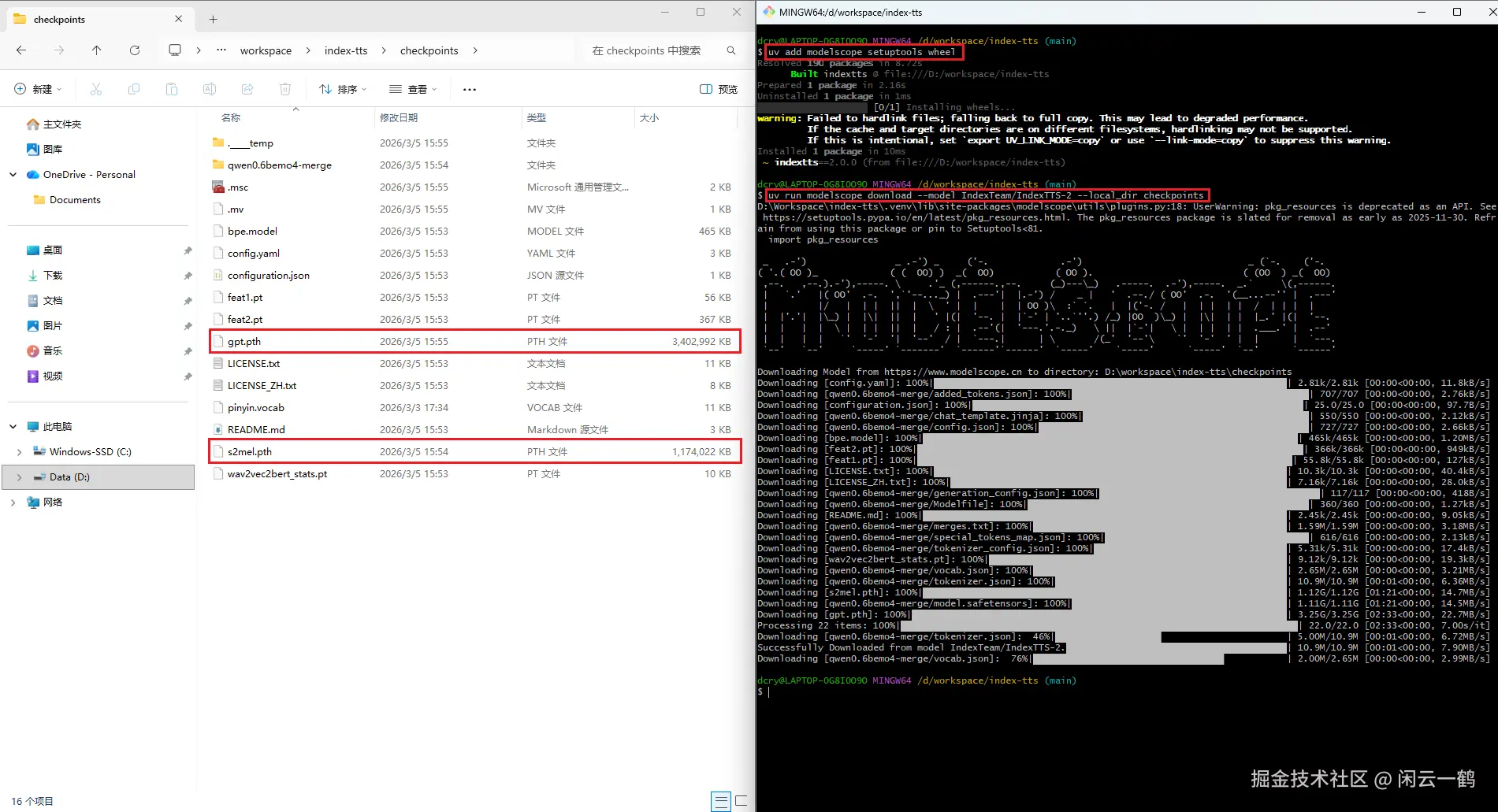
🔍 下载完成后,请检查 checkpoints 文件夹,确认里面有以下核心文件:config.yaml(核心配置文件),pinyin.vocab(语音合成必备的拼音字典),.pth 后缀的大文件(几 GB 大小的模型权重本体)
4. CUDA 介绍与 PyTorch GPU 加速检测
如遇 CUDA 相关报错,请确保已安装 NVIDIA CUDA Toolkit 12.8 及以上,这句话是官方文档说的。实际上是因为 uv sync 只装了 PyTorch 自带的 CUDA Runtime 运行时库,如果你在启动时加了 --cuda-kernel(或代码里写了 use_cuda_kernel=True),就可能报错
CUDA 是一个统称(就像"微软 Office")。而 CUDA Runtime 和 CUDA Toolkit 是它的两个组成部分
4.1 CUDA Runtime
CUDA Runtime 是运行时库:cudart.dll、cublas 等,只用于运行模型
当你在前面安装依赖运行 uv sync 命令时,uv 会根据项目根目录下的配置文件(pyproject.toml 或 uv.lock),自动为你安装匹配该项目的 PyTorch,PyTorch 包里已经自带了 CUDA Runtime,CUDA Runtime 是让 PyTorch 能够调用显卡运算 AI 模型;如果没有 CUDA Runtime,AI 模型只能靠 CPU 算,速度会慢 10-50 倍,原本几秒生成的语音可能要跑几分钟
可以运行下面的命令检测机器是否有 GPU,以及是否安装了GPU 版本的 PyTorch
bash
uv run tools/gpu_check.py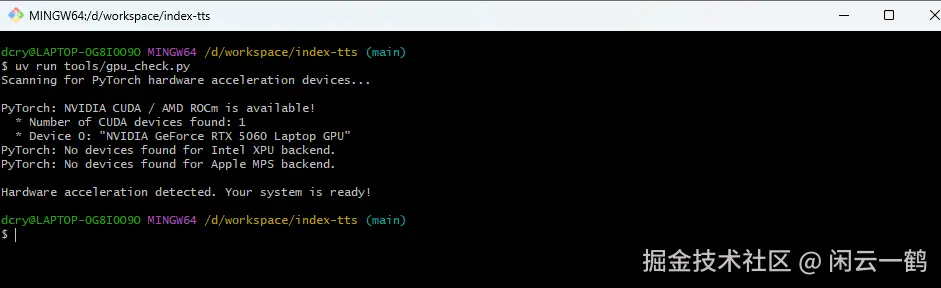
看到 Hardware acceleration detected. Your system is ready! 这句话就表明已检测到我的电脑有 GPU 硬件加速,可以直接使用了
输出显示未检测到 GPU 硬件加速,常见原因包括 Windows 系统的显卡驱动太旧(如果驱动版本低于 PyTorch 所需的最低 CUDA 版本要求,PyTorch 将无法调用显卡硬件,从而回退到 CPU 模式)、无兼容 NVIDIA 显卡,或 PyTorch 版本不匹配。记得去 NVIDIA 官网更新驱动,或确认自己电脑是否或者开启有独立显卡。
运行命令 nvidia-smi,查看电脑 CUDA 版本(看右上角:会显示 CUDA Version),这是驱动支持的 CUDA Runtime 上限。要求:驱动 CUDA Version ≥ PyTorch 内置 Runtime 版本(可用 uv run -c "import torch; print(torch.version.cuda)" 查看);Toolkit(如需安装)版本应匹配 PyTorch Runtime 版本。
4.2 CUDA Toolkit
CUDA Toolkit 是完整开发工具包:nvcc 编译器 + 头文件 + 样本
通常来说,有 CUDA Runtime 就足够了,不需要主动去装 CUDA Toolkit。一是模型大(好几GB),二是一般也用不着(不需要编译功能,装了浪费空间 + 时间)
只有你以后想追求极致速度(再快 20-30%,取决于显卡型号),才需要从 NVIDIA 官网手动安装 CUDA Toolkit ,然后启动时开启 "CUDA内核加速" 功能(--cuda-kernel)。对于我 8GB 这样的低内存显卡,建议先不开这个选项测试,避免显存不足。
🌐 CUDA 下载地址:developer.nvidia.com/cuda/toolki...
5. 启动 IndexTTS2
5.1 通过 WebUI 启动
安装完成后,直接运行以下命令启动可视化界面:
bash
uv run webui.py --fp16--fp16:开启 FP16 推理模式,能让显存占用减半(正常计算用 32 位浮点数,FP16 减半为 16 位)且几乎不损失音质
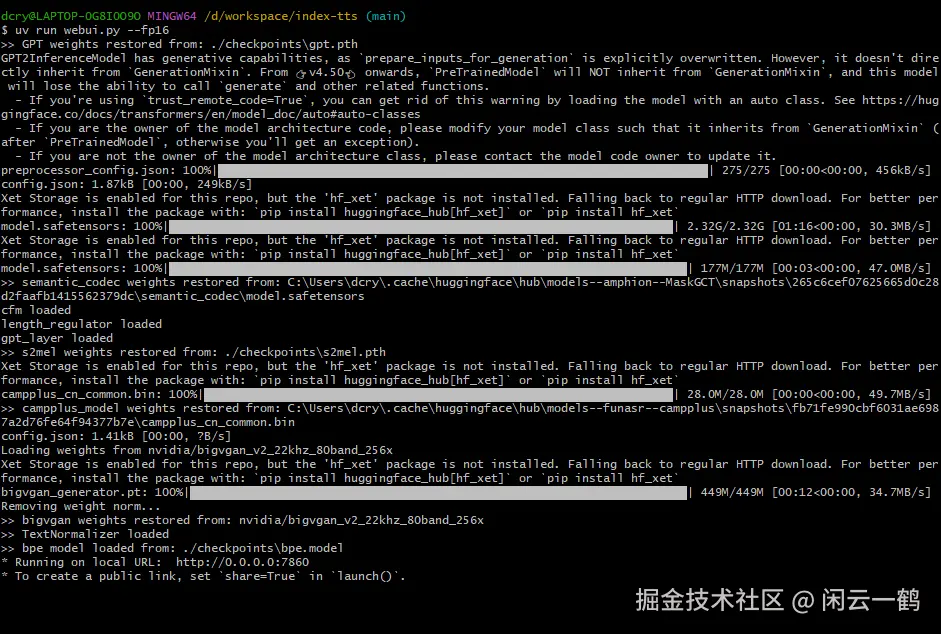
如果弹出确认框,点击允许
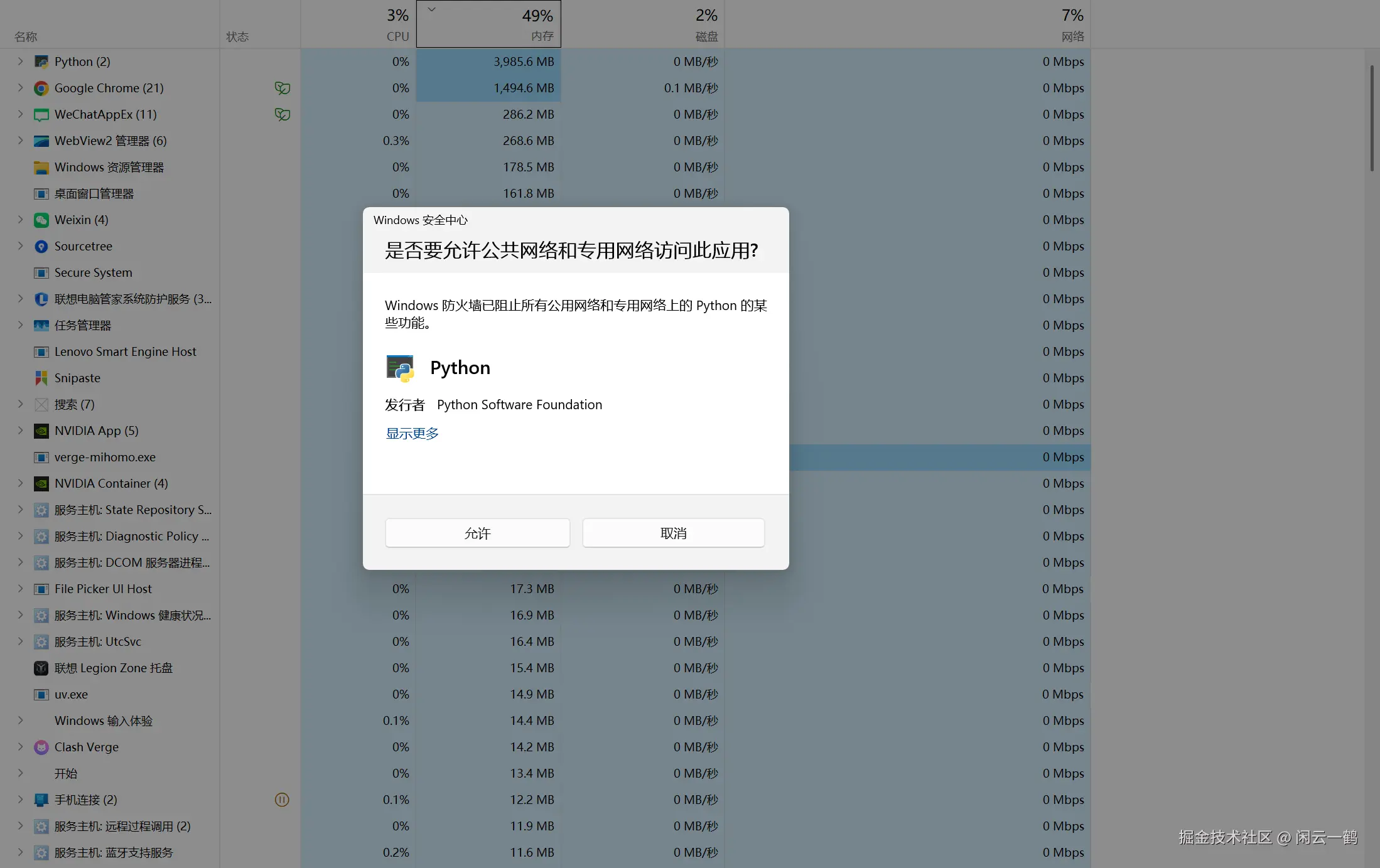
启动成功后,终端会显示一个地址(通常是 http://127.0.0.1:7860),将其复制到浏览器打开即可开始使用。
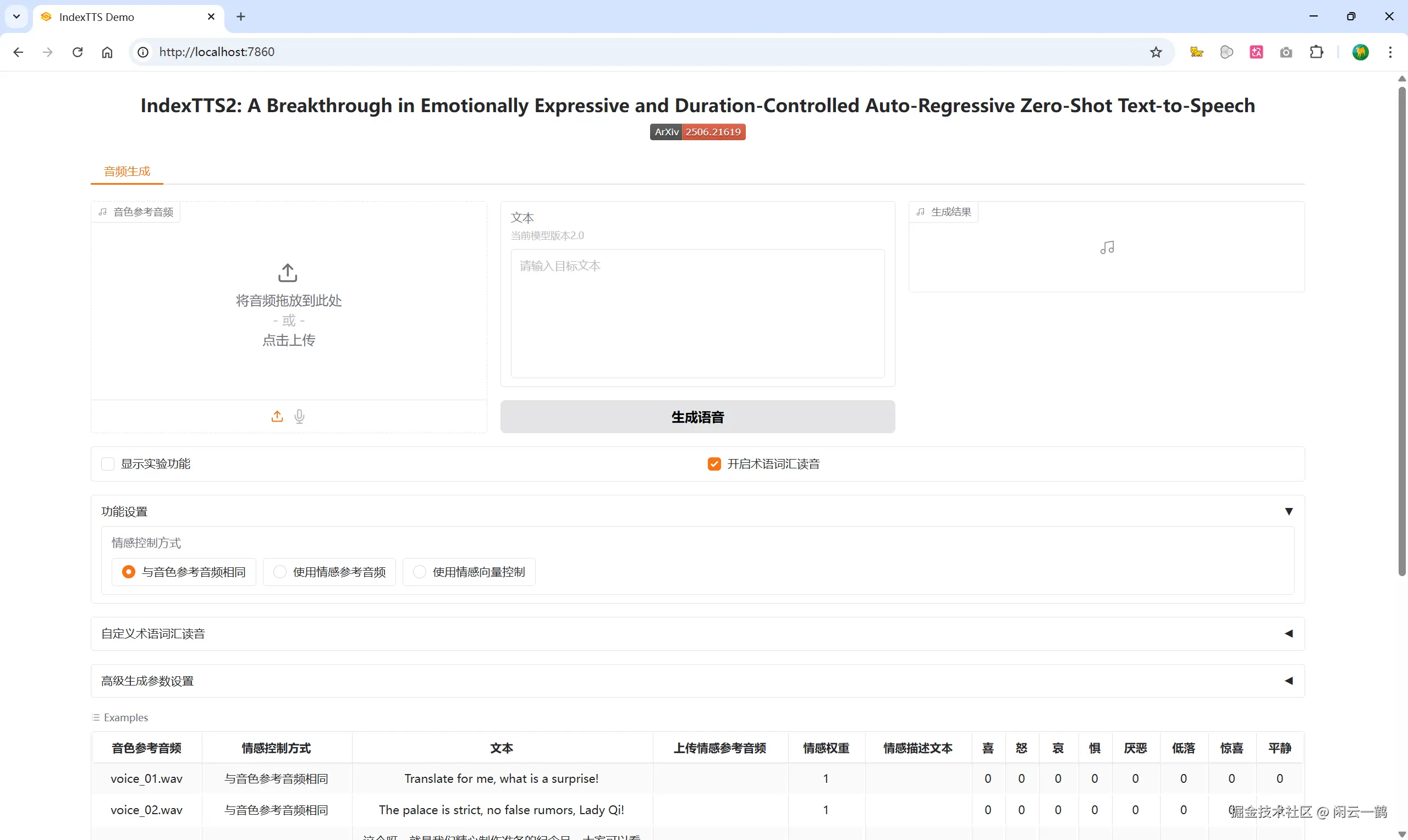
启动成功!撒花🎉🎉🎉
查看 webui 命令行的全部选项
bash
uv run webui.py -h5.2 通过 Python 脚本启动
不推荐,因为 webui.py 启动已经足够基础的使用了,并且使用脚本启动还要下载 facebook/w2v-bert-2.0 模型,并且这个模型默认从 Hugging Face 下载,还需要更改 infer_v2.py 文件的 w2v-bert-2.0 模型路径
反正就是,我懒得去折腾了,部署 IndexTTS2 模型没花费我多少时间,写教程花了我好几天的时间,/(ㄒoㄒ)/~~,我只想赶快完结这个教程好研究其它的东西
当然,如果有巨多的点赞收藏和评论要我出教程那我可以为了大家再花时间搞一搞
6. 使用 IndexTTS2
6.1 使用示例音频生成
IndexTTS2 项目 examples 文件夹里面提供了 14 条示例音频文件,点击示例选项提供的音频,编辑自定义文字内容,IndexTTS2 模型会根据示例音频的音色生成 AI 音频
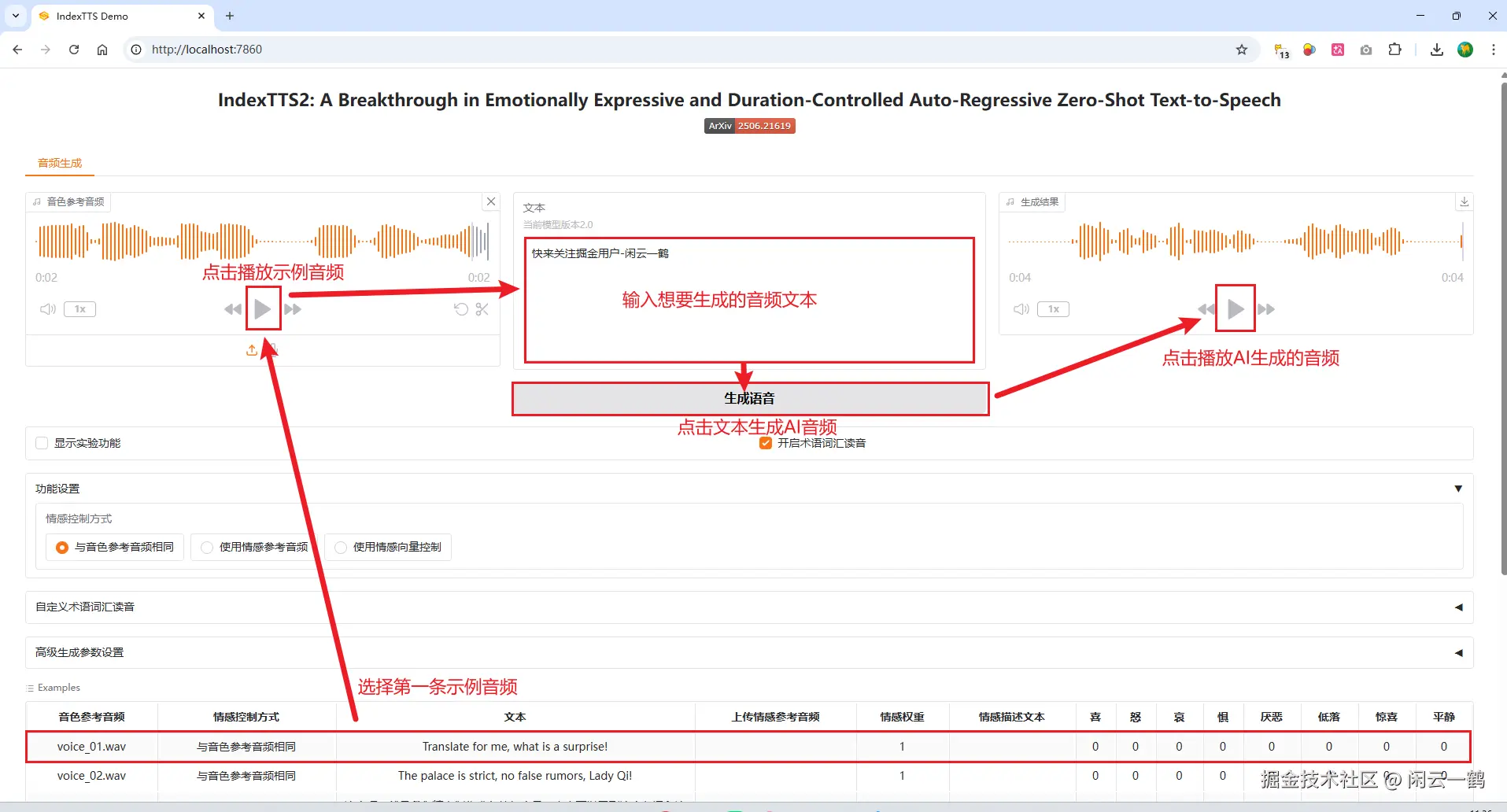
我的电脑配置为 windows 系统,8GB 显存,32GB 内存
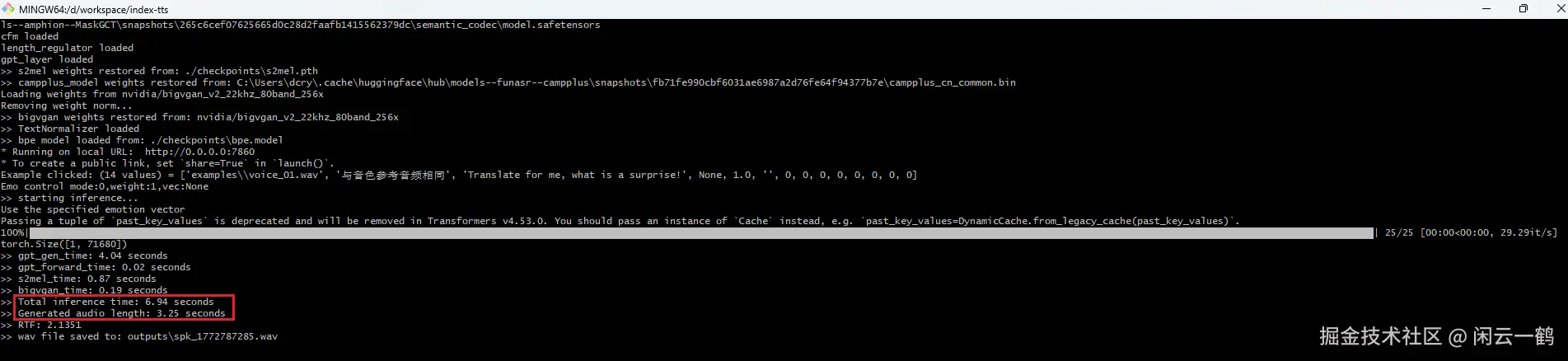
生成 3.25 秒左右的音频时间为 6.94 秒,非常的快啊!!
点击下载按钮可以将生成的 AI 音频保存到电脑
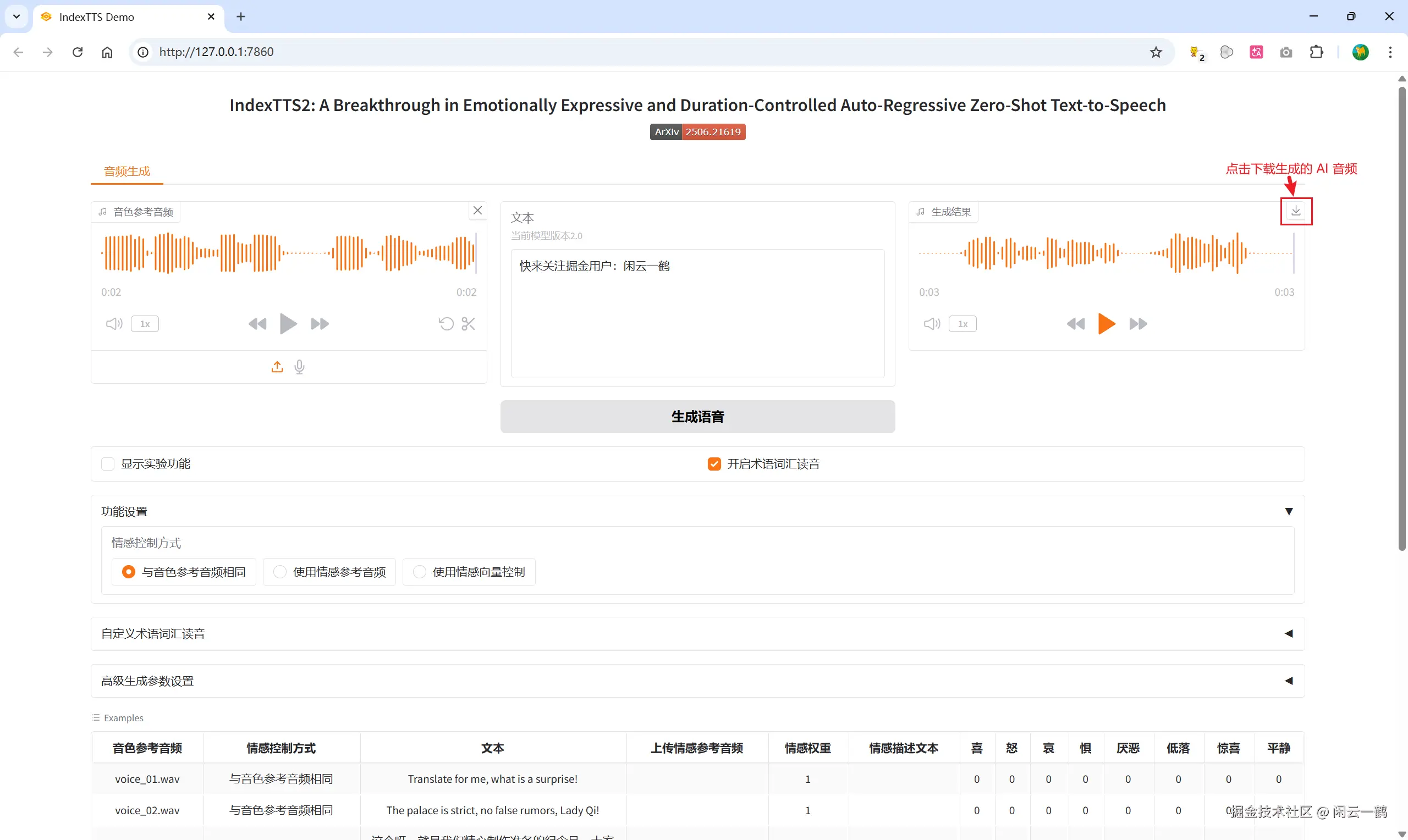
6.2 使用自定义音频生成
也可以根据自定义音频文件进行 AI 生成
上传一段你想要模仿的人声音频(3-10 秒效果最好),在文本框输入你想让它说的话,点击"合成"即可 生成 AI 语音
我用手机的录音机功能,读了一段按 0-10 自增顺序的数字录音。然后导入电脑上传到 IndexTTS2,文本内容依然是"快来关注掘金用户:闲云一鹤",效果确实很棒,完全就像是我自己说的话,只不过生成 AI 音频的时间,比官方提供的示例音频文件速度慢了不少,应该是官方提供的音频做了某些优化
除了根据音色生成音频外,IndexTTS2 还能根据上传声音中的高兴、愤怒、悲伤等情绪生成 AI 音频,甚至还能手动调整每种情绪的数值,操作很简单,本教程就不举例了,大家快来部署到自己的电脑自行尝试吧!