我正在开发 DocFlow,它是一个完整的 AI 全栈协同文档平台。该项目融合了多个技术栈,包括基于
Tiptap的富文本编辑器、NestJs后端服务、AI集成功能和实时协作。在开发过程中,我积累了丰富的实战经验,涵盖了Tiptap的深度定制、性能优化和协作功能的实现等核心难点。
如果你对 AI 全栈开发、Tiptap 富文本编辑器定制或 DocFlow 项目的完整技术方案感兴趣,欢迎加我微信 yunmz777 进行私聊咨询,获取详细的技术分享和最佳实践。
如果你对 OpenClaw 也感兴趣,也欢迎添加我微信,我拉你进交流群
很多做了一段时间 Agent 开发的人,都会冒出一种奇怪的失落感------明明在做"最前沿的 AI 应用",但每天干的事情和普通后端开发没啥区别:读数据、调接口、存结果、处理格式。
这种感觉其实非常精准。说明你已经看穿了目前市面上大多数 AI 应用的真面目,不过是通过胶水代码连接不同数据源和服务的系统。
但如果只停在这里,会错过一个更重要的认识:Agent 和传统 CRUD 的根本差异,不在于你调了多少接口,而在于"决策权"交给了谁,以及你如何处理那些无法被穷举的"不确定性"。
核心逻辑的变化,从硬编码到概率推理
传统业务系统里,if-else 是确定性的。开发者在写代码时,就已经预判了所有可能的分支,逻辑路径在 deploy 那一刻就已经完全固化。
typescript
// 传统 CRUD:逻辑路径写死在代码里
if (order.status === "PAID") {
await shipOrder(order.id);
} else if (order.status === "PENDING") {
await sendReminder(order.userId);
} else {
await logUnhandledStatus(order.status);
}Agent 的逻辑根本不是这么运作的。你把工具的用途用自然语言描述出来,模型根据当前的对话上下文,概率性地判断要不要调用它、传什么参数进去。
typescript
const tools: ChatCompletionTool[] = [
{
type: "function",
function: {
name: "ship_order",
description:
"当用户明确表示已完成支付,或系统确认订单状态为已支付时,发起发货流程。若用户只是咨询发货进度,不应调用此工具。",
parameters: {
type: "object",
properties: {
orderId: { type: "string", description: "订单唯一标识符" },
priority: {
type: "string",
enum: ["normal", "express"],
description: "发货优先级,默认为 normal",
},
},
required: ["orderId"],
},
},
},
];
const response = await openai.chat.completions.create({
model: "gpt-4.1",
messages: conversationHistory,
tools,
tool_choice: "auto",
});
const toolCall = response.choices[0].message.tool_calls?.[0];
if (toolCall?.function.name === "ship_order") {
const args = JSON.parse(toolCall.function.arguments) as {
orderId: string;
priority?: "normal" | "express";
};
await shipOrder(args.orderId, args.priority ?? "normal");
}关键点就在这里:你最终还是要写代码处理返回值,但中间那个"判断用户意图、决定执行哪个操作"的过程,不再是你写的条件判断,而是 LLM 的语义理解。这一层"决策权的让渡",是两者最本质的差异。
更微妙的是,你写的那段 description 字符串,实际上变成了系统行为的一部分。传统 CRUD 里,逻辑写在代码里,可以被静态分析、单元测试覆盖。而 Agent 的行为边界,部分藏在自然语言里,测试难度和不确定性都随之上升。
接口协议的演变,从手动对接到工具标准化
在传统开发里,你对接一个外部 API,流程通常是:
- 看文档,理解数据结构
- 写类型定义,手动组装请求参数
- 处理各种奇怪的错误码和返回格式
- 维护一份内部的封装层,隔离外部变化
到了 Agent 开发,这套流程变成了:把 API 的能力定义成一份 JSON Schema,让模型"看懂"这个工具能做什么、需要什么参数。工具描述的质量,直接决定了模型调用的准确率。
Function Call 解决的是单个模型和工具的对接问题。MCP(Model Context Protocol)则把这个过程彻底标准化------不管你用的是 Claude、GPT,还是 DeepSeek,只要服务提供方遵循 MCP 协议,Agent 就可以像接入 USB 设备一样无缝使用外部能力,包括数据库、搜索服务、本地文件系统、甚至另一个 AI 服务。
从工程角度看,这确实只是"换了一套接口协议"。但标准化带来的意义在于:工具可以在不同的 Agent、不同的模型之间复用,工具市场得以形成,开发者不再需要为每一个 LLM 重新写一遍对接代码。
这个演进方向很像当年从 SOAP 到 REST,再到 OpenAPI 规范的历程。每一次标准化,都会让生态扩张一个量级。
为什么很多人觉得"换汤不换药"
在 LangChain 这类框架下,这种感觉会尤其强烈。原因主要有两个。
第一,工程化的碎片极多。现在做 Agent 开发,80% 的精力都在处理 ChatPromptTemplate 的格式化、OutputParser 的解析逻辑、Memory 的上下文维护、Runnable 的链路拼装。这些工作和处理数据库连接池、管理事务、封装 DAO 层没有本质区别,都是繁琐的工程细节,只是套了一层 AI 的外壳。
第二,大多数"Agent"其实只是语义路由器。用户问 A,调工具 A,返回结果。整个流程是线性的、确定性的,和传统的请求-响应模式几乎相同。更直白地说,这种 Agent 不过是把原来的 if-else 路由,换成了"让 LLM 来决定调哪个函数"。能力边界没有变,只是路由逻辑的实现方式变了。
这种形态的 Agent 当然像 CRUD,因为它本来就没有超出 CRUD 的范畴。
真正让 Agent 和 CRUD 拉开距离的,是当任务本身无法被预先拆解、执行路径需要在运行时动态生成的时候。
真正的差异,出现在多步推理和自我纠错里
当任务变得复杂,无法用一次工具调用解决时,Agent 的价值才开始显现。
以"分析两家公司最近两个季度的财报并写一份竞争格局对比"为例,传统系统需要你预先设计好完整的工作流:先搜索 A 公司财报,再搜索 B 公司财报,提取关键数据,写入临时存储,最后调用生成模块输出结论。每一步的路径、每一步的数据格式,都要在代码里明确指定。
而用 ReAct(Reasoning + Acting)模式,模型可以自主循环规划和执行,不需要你把执行路径完全写死:
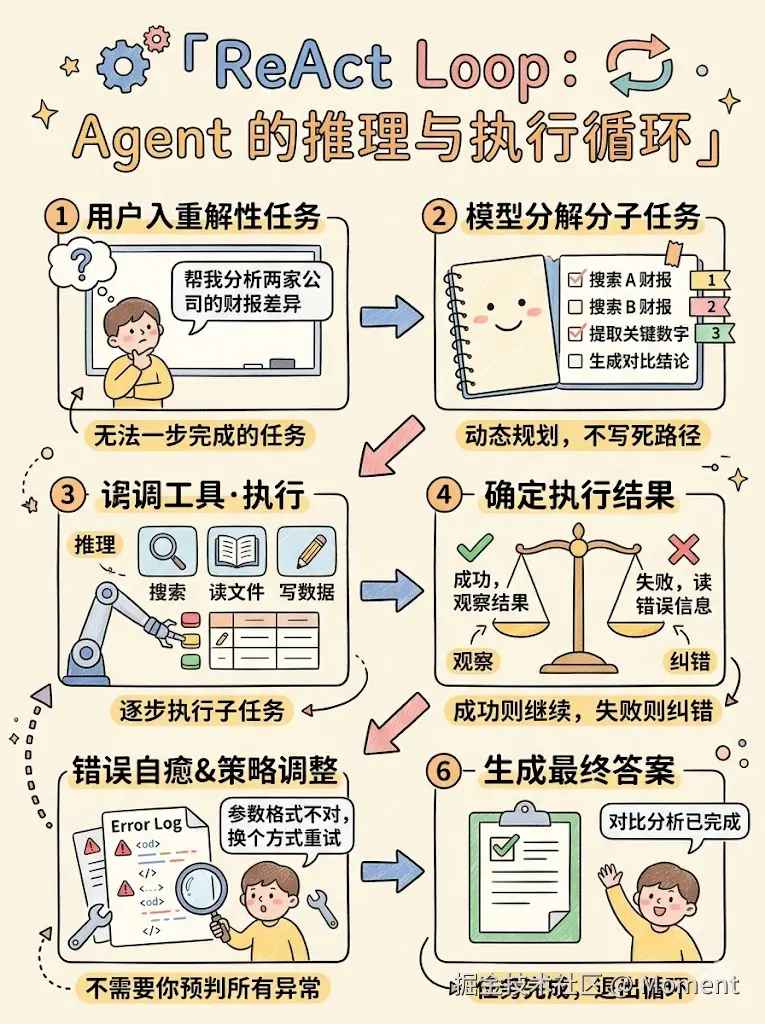
上图展示了 ReAct 循环的完整链路:模型接到复杂任务后,先动态拆解步骤,再进入"调用工具 → 观察结果 → 决定下一步"的循环,遇到失败时自动纠错调整策略,直到任务完成才退出。
这里有两个在传统 CRUD 里很难实现的能力,值得单独拆出来看。
动态规划,执行路径在运行时生成
传统系统里,你写代码时就要把所有执行路径确定下来。遇到没预见到的情况,系统要么报错,要么走 fallback。
Agent 里,模型可以根据上一步的结果,动态决定下一步做什么。搜索接口返回空数据?换个关键词再搜一次。第一家公司的财报在 PDF 里、第二家在网页上?模型会自己选合适的工具去读,不需要你提前为这种"格式不统一"的情况写分支处理。
执行路径是在推理过程中生长出来的,不是在编码时被预先铸造的。
错误自愈,异常不再是需要穷举的边界情况
当工具报错时,Agent 可以把错误信息读回上下文,自己判断是参数格式问题、权限问题还是业务逻辑问题,然后决定下一步策略。
typescript
interface AgentMessage {
role: "user" | "assistant" | "tool";
content: string;
tool_call_id?: string;
}
interface AgentState {
messages: AgentMessage[];
retryCount: number;
}
async function runReActLoop(
initialMessages: AgentMessage[],
maxRetries: number = 5,
): Promise<string> {
const state: AgentState = {
messages: [...initialMessages],
retryCount: 0,
};
while (state.retryCount < maxRetries) {
const response = await openai.chat.completions.create({
model: "gpt-4.1",
messages: state.messages,
tools,
});
const message = response.choices[0].message;
state.messages.push({
role: "assistant",
content: message.content ?? "",
});
if (!message.tool_calls || message.tool_calls.length === 0) {
return message.content ?? "";
}
for (const toolCall of message.tool_calls) {
try {
const result = await executeTool(
toolCall.function.name,
JSON.parse(toolCall.function.arguments),
);
state.messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: JSON.stringify(result),
});
} catch (error) {
// 把错误信息原样喂回给模型,让它自己决定怎么处理
state.messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: `Error: ${(error as Error).message}`,
});
state.retryCount++;
}
}
}
throw new Error(`Agent 超过最大重试次数 ${maxRetries}`);
}传统系统里要实现类似能力,需要提前把所有可能的错误类型都枚举出来,针对每种错误写对应的恢复逻辑。Agent 不需要------你只要把错误信息给到模型,它自己会推理出下一步。
这不是魔法,而是把"异常处理的决策逻辑"从代码迁移到了模型的推理能力上。
Agent 架构的三个层次
可以把目前的 Agent 开发用一个简单的分层来理解:
| 层次 | 形态 | 特征 |
|---|---|---|
| 语义路由层 | Prompt + 单次工具调用 | if-else 的 AI 替代品 |
| 动态执行层 | ReAct 循环、多步规划 | 执行路径在运行时生成 |
| 自主代理层 | 多 Agent 协作、持久状态 | 接近"数字员工"形态 |
目前大多数 Agent 产品停留在第一层,少数进入第二层,真正做到第三层的极少。
停留在第一层的 Agent,很快会被更自动化的低代码平台取代,因为本质上它们就是把接口调用包了一层自然语言的壳。真正的门槛在于:
- 如何设计高质量的
RAG检索流水线,让模型在推理时拿到足够准确的上下文,而不是把无关信息一股脑塞进去 - 如何构建高可靠的工具集,保证工具的输入输出契约稳定,减少模型在格式解析上消耗的额外推理
- 如何管理 Agent 的执行状态,让长程任务在中途中断后可以从断点恢复,而不是从头重来
- 如何设计多 Agent 的协作边界,让不同专长的子 Agent 各司其职,而不是把所有能力堆给一个 Agent
从 LangChain 到 LangGraph 的思维跃迁
如果你已经在用 LangChain,建议花时间研究一下 LangGraph。这不是简单的框架升级,而是一个思维模型的切换。
SequentialChain 的思路是:输入 → 步骤 A → 步骤 B → 输出。这个模型对线性任务很够用,但一旦遇到需要循环、分支、并行的场景,就会开始变扭曲。
LangGraph 把 Agent 看作一个有状态的图(Stateful Graph)。每个节点是一个处理单元,可以是 LLM 调用,也可以是工具执行,甚至是一个子 Agent;节点之间通过共享状态(State)传递数据,边可以是条件边,根据状态的值决定下一步跳到哪个节点。
typescript
import { StateGraph, END } from "@langchain/langgraph";
interface GraphState {
messages: AgentMessage[];
planSteps: string[];
currentStep: number;
isComplete: boolean;
}
const graph = new StateGraph<GraphState>({
channels: {
messages: { reducer: (a, b) => [...a, ...b] },
planSteps: { default: () => [] },
currentStep: { default: () => 0 },
isComplete: { default: () => false },
},
});
graph.addNode("planner", plannerNode);
graph.addNode("executor", executorNode);
graph.addNode("evaluator", evaluatorNode);
graph.addConditionalEdges("evaluator", (state) => {
if (state.isComplete) return END;
if (state.currentStep >= state.planSteps.length) return "planner";
return "executor";
});
graph.setEntryPoint("planner");在这个模型下,你会发现自己在设计的不是"代码流程",而是"决策拓扑"------哪些节点可以并行、哪些节点需要等待上游结果、失败时应该回溯到哪个检查点。这和传统的业务流程设计有相似之处,但多了一层:每个节点的行为可以由 LLM 的推理驱动,而不是硬编码的条件判断。
"Agent 开发是高级 CRUD"这个判断是对的。但停在这里,就像说"编程不过是操作内存"一样------技术上没错,却少了最关键的那层:你在这些机制之上,能搭出什么来。
CRUD 给你的是确定性和可控性,代价是所有路径都需要被预先设计。Agent 给你的是泛化能力和动态性,代价是不确定性和更高的调试难度。两者不是替代关系,而是在不同场景下各有优劣的工具。
真正难的不是"学会怎么调 API",而是在一个充满不确定性的系统里,设计出足够可靠的架构,让模型的概率性能力在你能接受的误差范围内稳定运行。