👉 这是一个或许对你有用 的社群
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
-
《项目实战(视频)》:从书中学,往事中**"练"**
-
《互联网高频面试题》:面朝简历学习,春暖花开
-
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
-
《精进 Java 学习指南》:系统学习,互联网主流技术栈
-
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
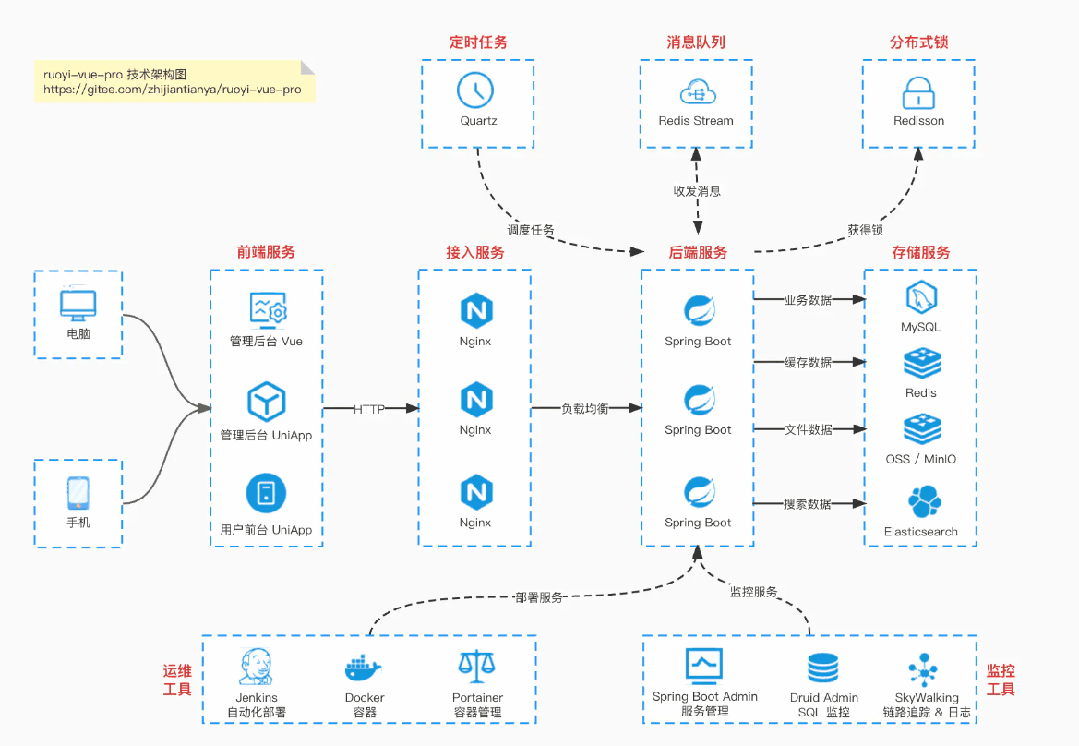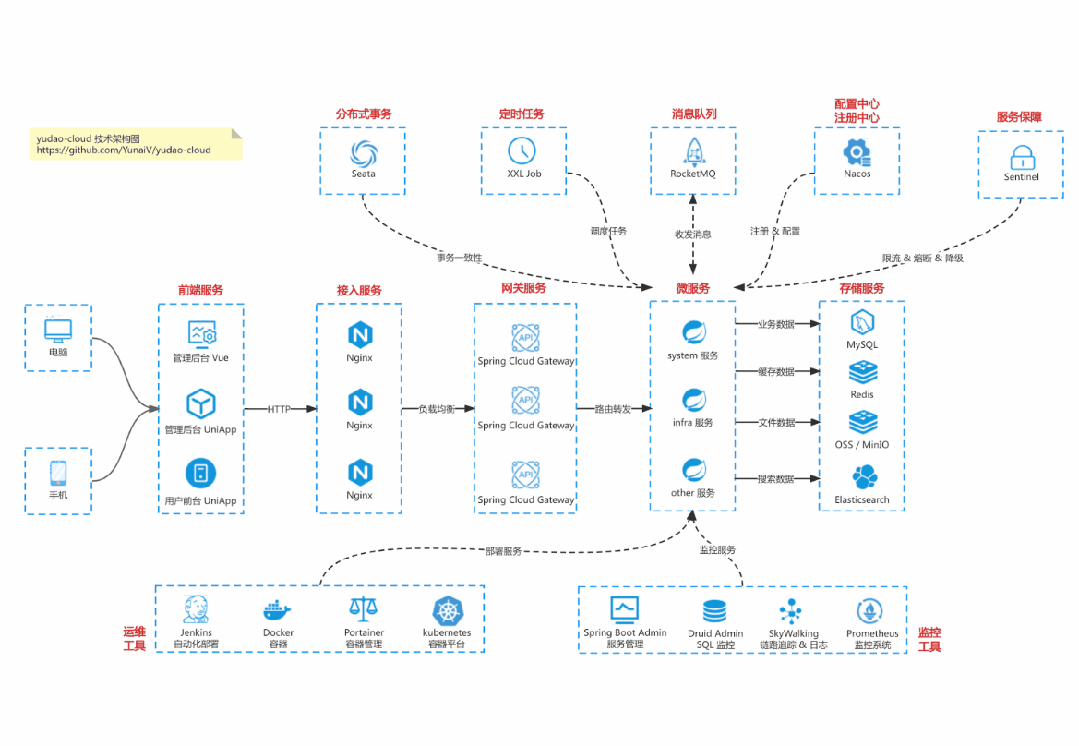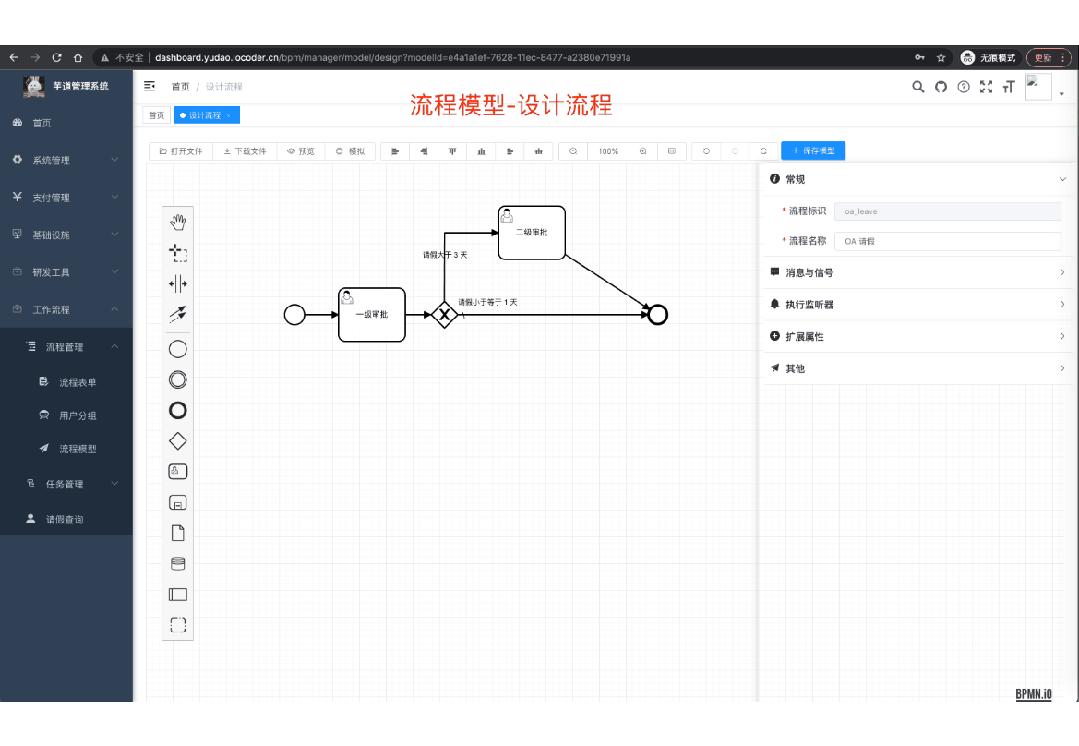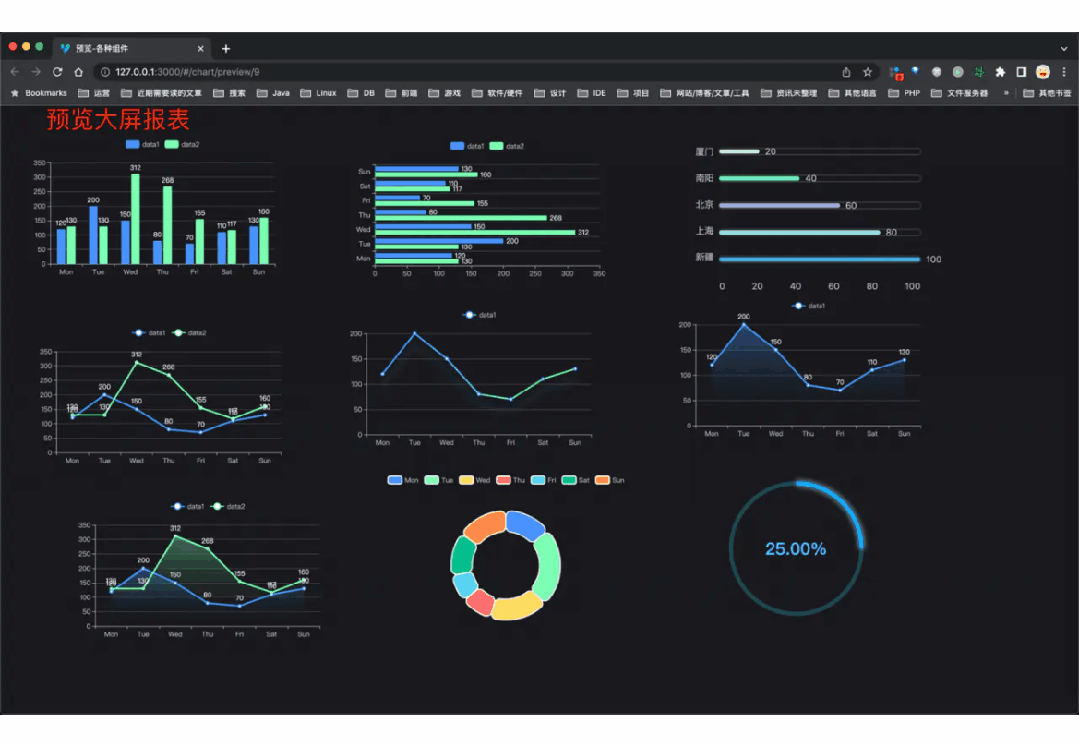
国产Star破10w的开源项目,前端包括管理后台、微信小程序,后端支持单体、微服务架构
RBAC权限、数据权限、SaaS多租户、商城 、支付、工作流、大屏报表、ERP、CRM 、AI大模型、IoT物联网等功能:
【国内首批】支持 JDK17/21+SpringBoot3、JDK8/11+Spring Boot2双版本
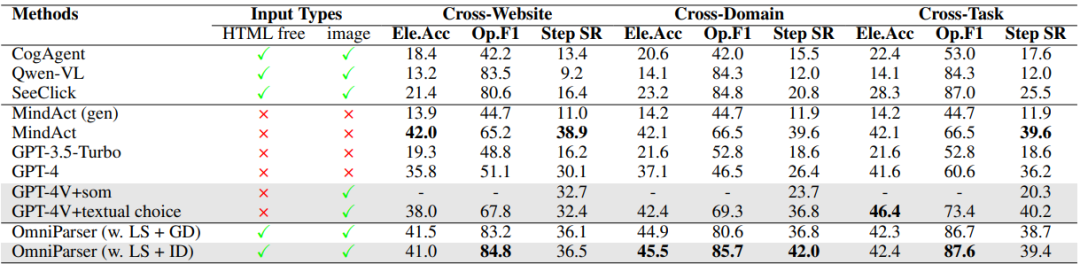
AI Agent 想要操控你的电脑,第一步得先看懂屏幕 。这件事说起来简单,做起来极难------屏幕上的按钮、图标、文本框对人类是直觉,对 AI 却是一堆像素噪声。
微软开源的 OmniParser 就是来解决这个问题的:把任意 UI 截图解析成结构化的可操作元素 ,让 AI 真正"看懂"界面。
GitHub 地址:https://github.com/microsoft/OmniParser
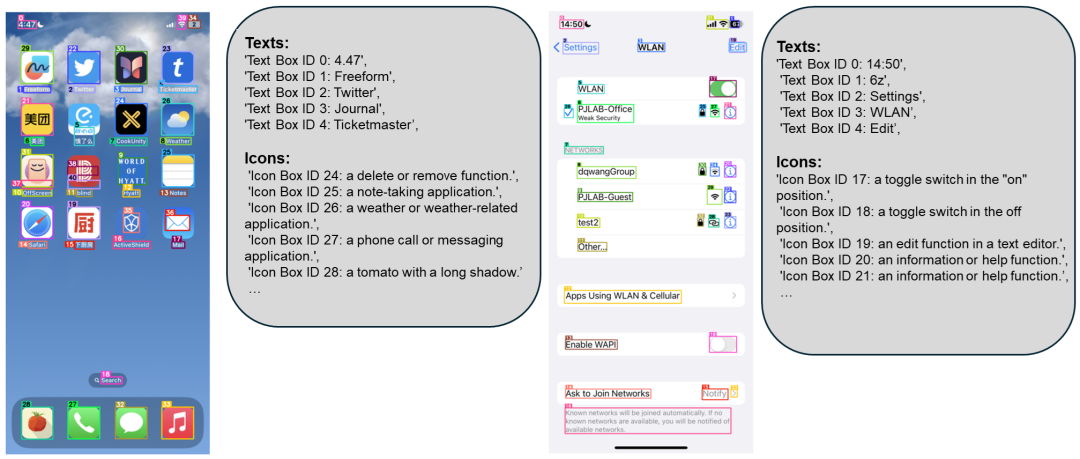
它到底做了什么?
一句话:截图进去,结构化数据出来。
OmniParser 接收一张 UI 截图和用户任务描述,输出两样东西:
-
解析后的截图 :在原图上叠加边界框和数字 ID,标记出每一个可交互元素的位置
-
局部语义信息 :提取屏幕上的文本内容,并为图标生成自然语言描述
简单说,它是 AI Agent 的"眼睛" ------有了它,大模型才知道屏幕上第 3 号按钮是"发送",第 7 号输入框是"搜索栏"。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
技术实现:三个模型各司其职
OmniParser 用 Python 开发,底层组合了三个关键模型:
-
YOLO :负责检测屏幕上的可交互区域(按钮、图标、输入框等),速度快、精度高
-
Florence :微软自研视觉模型,负责图标的语义理解和描述生成
-
BLIP2 :补充视觉-语言对齐能力,增强对复杂 UI 元素的理解
这套组合拳的好处是各模型只干自己擅长的事 ,不存在一个大一统模型勉强干所有活的尴尬。检测归检测,理解归理解,分工明确。
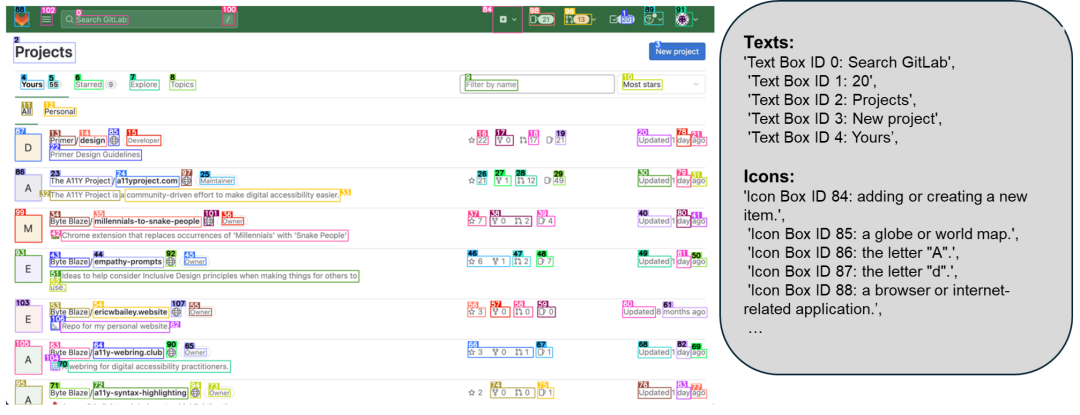
上图是可交互区域检测的效果 ------边界框基于网页 DOM 树中提取的可交互区域生成,训练数据来源真实可靠。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
真正的价值:打通大模型到桌面操作的最后一环
OmniParser 支持与 GPT-4V 等主流多模态大模型集成。这意味着你可以搭建这样的链路:
用户下指令 → 大模型理解意图 → OmniParser 解析屏幕 → 定位目标元素 → 执行点击/输入操作
这就是桌面自动化(RPA)的 AI 化路径。相比传统 RPA 靠写死的坐标和元素选择器,OmniParser 的方案对界面变化的容忍度高得多 ------因为它理解的是语义,不是像素坐标。
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,"长按 "或"扫描"下方二维码噢:

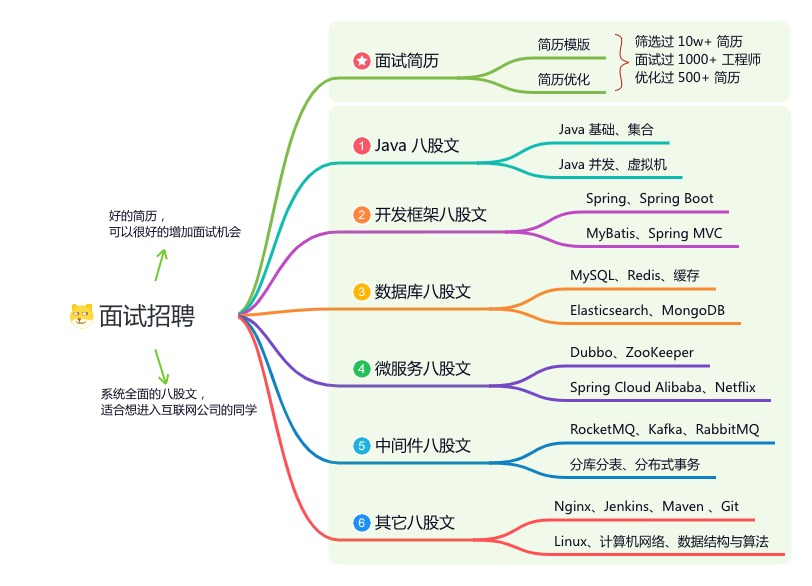
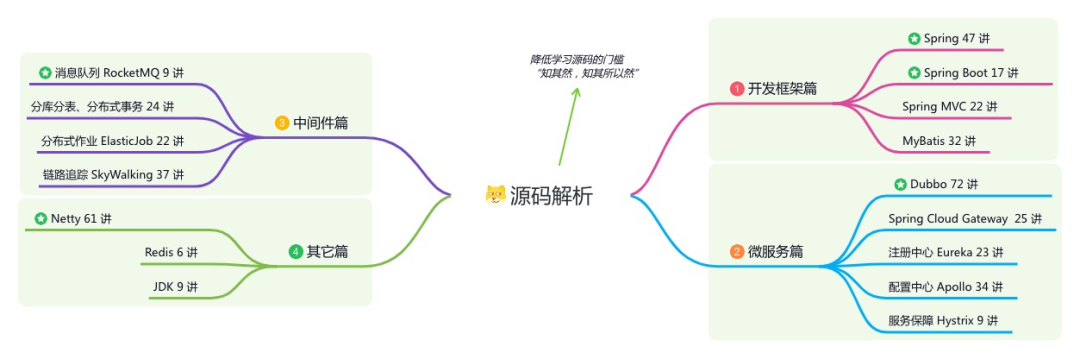
星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
go
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)