

OmniText 是一个免训练 的通用视觉文本操作框架,它通过在扩散模型推理阶段直接干预注意力分布 (实现无幻觉的文本擦除)并结合隐空间优化(动态计算 Loss 更新潜变量以精准控制内容与风格),在零微调成本下统一了图像文本的擦除、编辑与风格迁移等多项复杂任务。
1. 痛点:现在的 AI 修改图片文字有多笨?
想象一下,你有一张非常酷的电影海报,你想把上面的电影名改成你朋友的名字,并且保留原本那种带有火焰、3D效果的炫酷字体 ;或者你只想把海报角落的几行字擦除掉。
如果让现在的 AI(哪怕是 GPT-4o 这样的顶尖大模型)来做,通常会翻车:
- 擦不干净(幻觉问题):当你让 AI 擦除文字时,它看到旁边还有其他字,就会"自作聪明"地在你要擦除的地方瞎编出一些类似文字的乱码,而不是还原成干净的背景。
- 字体学不像:AI 很难完美模仿图片里原有的特殊字体和排版。
- 容易结巴:AI 写字时经常会多写几个字母,比如把 "APPLE" 写成 "APPPLLE"。
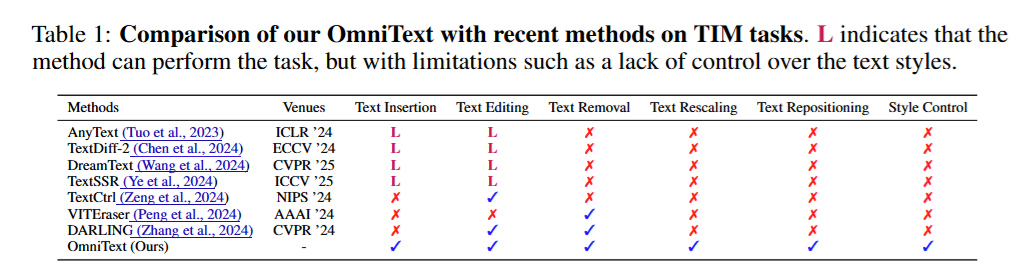
- 功能太单一:以前的 AI 大多是"偏科生",有的只会加字,有的只会擦字,没有一个能同时搞定所有任务的"全科生"。
2. OmniText 是什么?它能干啥?
OmniText 是一个**"全能型选手(Generalist)"**。只需这一个工具,你就能对图片里的文字进行各种"魔法操作":
- 擦除(Removal):把字抹掉,完美还原背景。
- 编辑(Editing):把 A 词改成 B 词,完美保持 A 的字体风格。
- 插入(Insertion):在空白处加字,并且能模仿图片里其他字的风格(甚至能给你一张参考图,让它照着参考图的字体写字)。
- 缩放和移动(Rescaling & Repositioning):把字变大变小,或者挪个位置,背景还能自动补全。
3. 核心黑科技:它是怎么做到的?
这篇论文最牛的地方在于它是 "免训练(Training-Free)" 的。也就是说,作者没有花费高昂的算力去从头教一个 AI,而是巧妙地"调教"了现有的 AI(基于一个叫 TextDiff-2 的模型),改变了 AI 生成图片时的 "注意力(Attention)" 机制。
什么是注意力?其实就是 AI 在画图时"眼睛往哪儿看"。
- Cross-Attention(交叉注意力) :决定了 AI 画出来的内容对不对(比如你让它写"CAT",它有没有少写个T)。
- Self-Attention(自注意力) :决定了 AI 画出来的风格像不像(比如它会参考周围的像素,决定用什么颜色和特效)。
基于这两个发现,作者用了两招:
第一招:蒙上眼睛来擦除(解决擦除时的乱码)
当你想擦除文字时,AI 会忍不住去偷看周围的字,导致它画出乱码。OmniText 使用了"自注意力反转(SAI)"和"交叉注意力重分配(CAR)"技术。说白了,就是强行把 AI 看向文字的"视线"切断,逼着它只看背景。这样,AI 就能乖乖地把字擦掉,补上干净的背景了。
第二招:照猫画虎来写字(完美模仿字体风格)
当你想要模仿某种字体写新字时,OmniText 用了一个叫"网格技巧(Grid Trick)"的拼图法:它把带有目标字体的**"参考图"和你要修改的 "目标图"**拼在一起丢给 AI。
同时,它给 AI 定了两个严格的规矩(Loss functions):
- 内容规矩:你的眼睛必须死死盯着我让你写的单词,绝对不能写错字母(控制内容)。
- 风格规矩 :你的画笔必须去抄那张"参考图"里的颜色和纹理(控制风格)。
在这样严格的把控下,AI 就能写出既拼写正确,又完美还原神仙字体的文字了。
这篇论文 《OmniText: A Training-Free Generalist for Controllable Text-Image Manipulation》 提出了一种基于隐扩散模型(Latent Diffusion Models, LDMs)的免训练(Training-Free)文本图像操作通用框架。其核心思想是通过在采样阶段操纵和优化 Cross-Attention 和 Self-Attention 的特征图,解决当前视觉文本生成/编辑模型在多任务(尤其是擦除和细粒度风格迁移)上的痛点。
以下是这篇论文的深度技术拆解:
1. 研究动机与当前痛点 (Motivation & Limitations)
当前的文本图像操作(Text Image Manipulation, TIM)通常被分为擦除(Removal)、编辑(Editing)和插入(Insertion)等独立任务。尽管现有的 LDM(如 TextDiff-2, AnyText 等)在文本插入上表现不错,但作为 Generalist 存在三个致命缺陷:
- 无法直接进行文本擦除 (Inability for Text Removal) :给定一个 mask 和空 prompt(
""),由于 Self-Attention 会捕捉周围(unmasked)的文本特征,模型极易产生文本幻觉(Text Hallucinations)或生成乱码纹理。 - 缺乏显式的风格控制 (Uncontrollable Style Fidelity):无法精细控制生成文本的字体、颜色、排版等风格。
- 拼写准确率不稳定 (Character Duplication):在 mask 区域较大时,模型经常生成重复的字符。
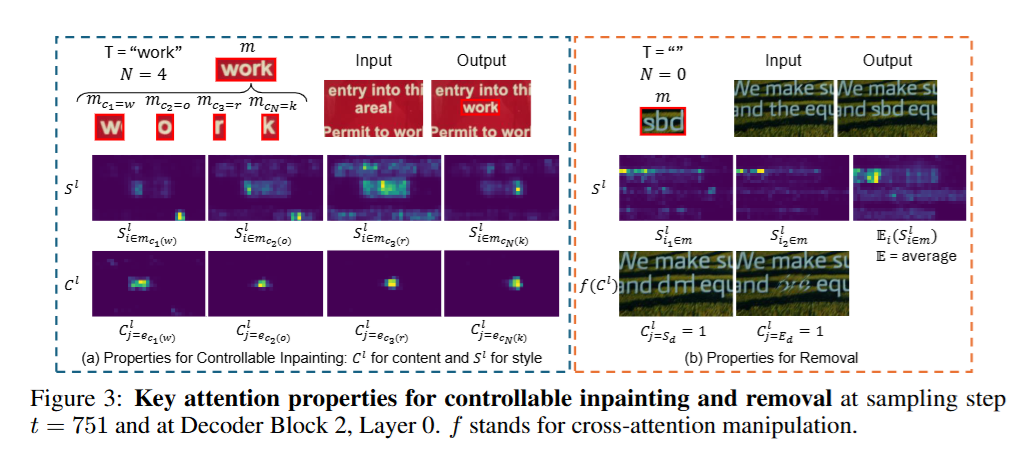
2. 核心技术发现 (Attention Mechanism Insights)
作者对 Backbone(选用 TextDiff-2 这一基于 U-Net 的文本修复模型)的注意力机制进行了深入的可视化与统计分析,得出了指导算法设计的两个核心结论:
- Cross-Attention 控制内容对齐 (Content Alignment) :文本 prompt 中的具体字符 token(如 ckc_kck)在 Cross-Attention map 中会精确关注到对应的空间像素区域(mckm_{c_k}mck)。
- Self-Attention 控制风格迁移 (Style Transfer):在 mask 区域内生成字符时,Self-Attention 会高响应地 attend 到周围的真实文本或相似字符上,以此来决定生成的字体和风格。
3. 算法架构与具体实现 (Methodology)
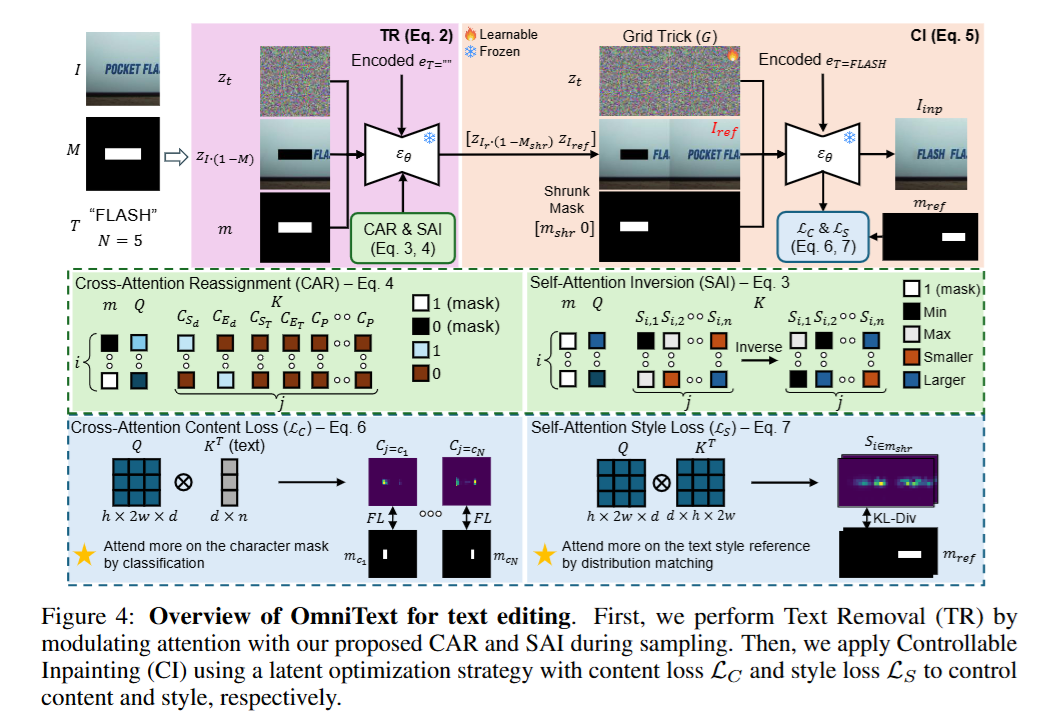
基于上述洞察,OmniText 被设计为由两个高度模块化的核心组件构成:文本擦除 (TR) 和 可控修复 (CI)。
A. 文本擦除模块 (Text Removal, TR)
为了在不微调模型的情况下抑制文本幻觉,作者提出了对注意力图的直接干预:
- 自注意力反转 (Self-Attention Inversion, SAI) :
在采样的前 50% steps 中,对目标 mask 内的 Self-Attention 权重进行线性反转映射(max + min - current)。这强制斩断了生成区域对周围文本特征的依赖,迫使模型将注意力转移到背景纹理上。 - 交叉注意力重分配 (Cross-Attention Reassignment, CAR) :
在整个采样过程中,使用分段函数手动干预 Cross-Attention map。具体做法是:将 unmasked 区域的注意力强制分配给 Start-of-description token (SdS_dSd) 以促进背景重建;将 masked 区域的注意力强制分配给 End-of-description token (EdE_dEd) 以彻底抑制字符生成。
B. 可控修复模块 (Controllable Inpainting, CI)
这是一个基于隐空间优化 (Latent Optimization) 的模块。作者通过在早期的去噪 steps (如 0%, 20%, 40% 阶段) 中计算特定 Loss 并用 Adam 优化器反向传播更新当前步的噪声潜变量 ztz_tzt,来实现内容和风格的双重解耦控制:
- 用于风格特征提取的 Grid Trick :
受视频编辑中的时空一致性方法启发,作者将输入的 target latent 和 reference image latent 在空间维度(Width)上拼接(Concat),形成一个 H×2WH \times 2WH×2W 的网格作为输入。这使得 U-Net 的 Self-Attention 能够跨区域计算,从而将参考图像中的文本风格"传递"到目标区域。 - 交叉注意力内容损失 (Cross-Attention Content Loss, LC\mathcal{L}_CLC) :
为了解决字母重复生成(拼写错误)的问题,作者将生成任务转化为"二分类问题"。采用 Focal Loss 来约束特定字符 token j=ckj=c_kj=ck 的 Cross-Attention 分布:强制其在给定的对应字符 mask (mckm_{c_k}mck) 内有高响应,而在该区域外低响应。Focal Loss 很好地缓解了字符所占像素极少带来的正负样本不平衡问题。 - 自注意力风格损失 (Self-Attention Style Loss, LS\mathcal{L}_SLS) :
通过计算目标 mask 区域内的 Self-Attention 概率分布与 Reference text mask 归一化后分布之间的 KL 散度 (KL-Divergence)。通过最小化这个 KL 散度,强制模型在生成新文本时,像素级地去参考 Reference image 中的字体特征。
总的 Latent Optimization 目标函数为:L=λCLC+λSLS\mathcal{L} = \lambda_C \mathcal{L}_C + \lambda_S \mathcal{L}_SL=λCLC+λSLS。
4. 实验与评估 (Experiments & Benchmark)
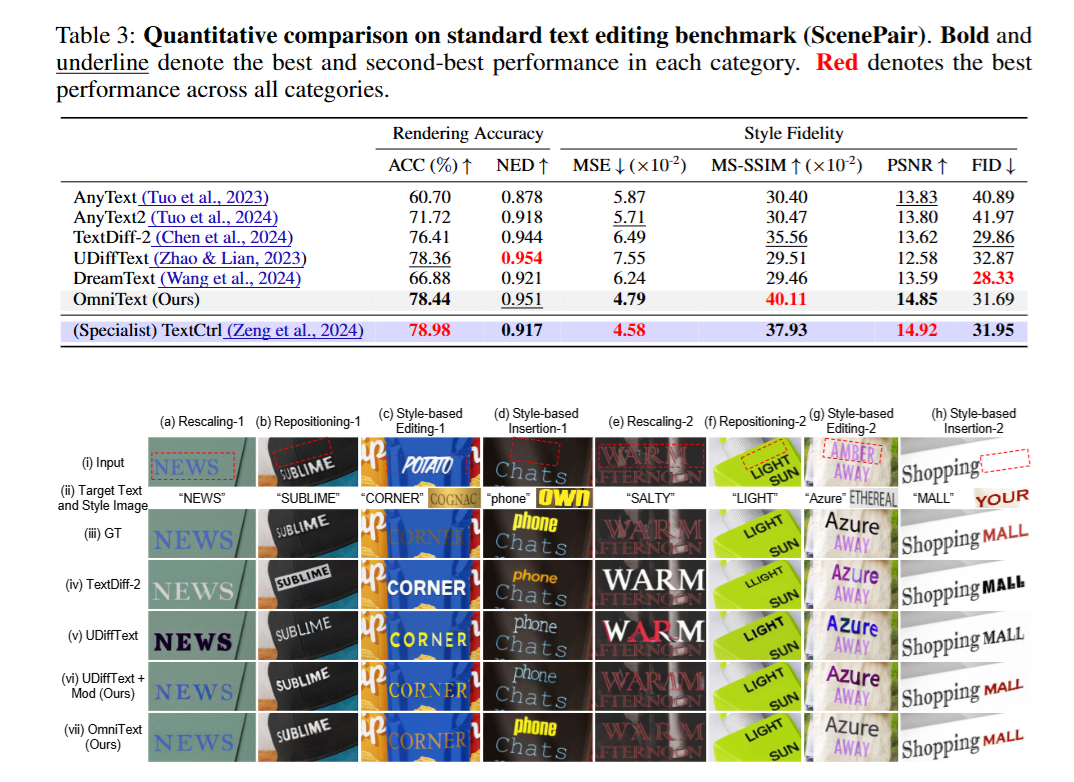
由于现有的 TIM 数据集任务单一,作者构建了 OmniText-Bench,包含 150 个真实场景的 mockup(涵盖海报、包装、服装等),并标注了完整的 mask、参考图和 Ground Truth,支持评测 5 种复合任务:删除、重缩放、重定位、带风格参考的插入、带风格参考的编辑。
性能表现:
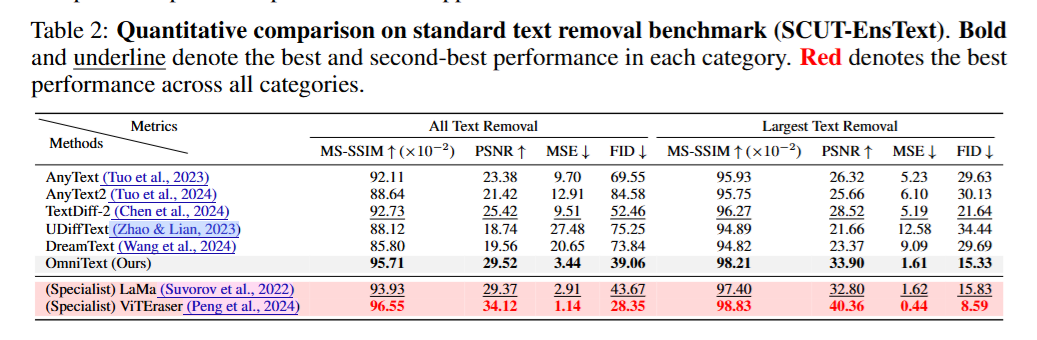
- Text Removal (SCUT-EnsText):在不需要针对擦除任务进行专门训练的前提下,OmniText 的 PSNR, MS-SSIM, FID 均超越了所有的 Generalist 模型(如 AnyText2, DreamText 等),并且达到了逼近 Specialist 模型(如 LaMa, ViTEraser,甚至在 FID 上优于 LaMa)的 SOTA 水平。
- Text Editing (ScenePair):在保持原有风格(Style Fidelity)和渲染准确率(ACC, NED)上,优于 TextDiff-2 Baseline 和其他通用模型;在风格保真度的各项指标上甚至超越了专门训练的编辑模型 TextCtrl。
扩散模型(Diffusion Models)在免训练编辑领域中最核心、也最trick的技术:隐空间优化(Latent Optimization) ,或者叫 推理期优化(Inference-Time/Test-Time Optimization)。
在传统的深度学习观念中,Loss 算出来是为了求梯度去更新**模型权重(θ\thetaθ)的。但在 OmniText(以及类似 Attend-and-Excite 等免训练工作)中,模型的权重 θ\thetaθ 是完全冻结(Frozen)**的。
这里的 Loss 并不是用来更新模型,而是用来**更新当前步的输入噪声(即潜变量 ztz_tzt)**的。
1. 核心原理:梯度流向了哪里?
在扩散模型的反向去噪采样(Denoising Sampling)过程中,每一步我们都有一个带噪的潜变量 ztz_tzt。OmniText 在特定的采样步 ttt 中,会临时将 ztz_tzt 设置为叶子节点并允许求导(在 PyTorch 中即 z_t.requires_grad = True)。
具体的计算图流向如下:
- Forward Pass(前向传播) :把开启了梯度的 ztz_tzt 输入到冻结的 U-Net 中。
- Feature Extraction(截获特征) :在 U-Net 前向传播的过程中,不只拿到预测的噪声 ϵ\epsilonϵ,而是拦截并提取出网络特定层(如 Decoder 某几层)的 Cross-Attention Map (CCC) 和 Self-Attention Map (SSS) 。注意,这些 Attention Map 此时构成的计算图是连通到 ztz_tzt 的。
- Loss Computation(计算损失) :利用提取出的 Attention Map,计算论文提出的内容损失 LC\mathcal{L}_CLC 和风格损失 LS\mathcal{L}SLS:
Ltotal=λCLC+λSLS \mathcal{L}{total} = \lambda_C \mathcal{L}_C + \lambda_S \mathcal{L}_S Ltotal=λCLC+λSLS - Backward Pass(反向传播) :对总 Loss 进行
backward()。此时,梯度 ∇L\nabla \mathcal{L}∇L 会沿着计算图反传,穿过 Attention 层、穿过整个 U-Net,最终落到输入的潜变量 ztz_tzt 上 ,即得到 ∇ztL\nabla_{z_t} \mathcal{L}∇ztL。 - Latent Update(潜变量更新) :使用 Adam 优化器,根据梯度来微调 ztz_tzt 本身:
zt′←zt−η⋅Adam(∇ztL) z_t' \leftarrow z_t - \eta \cdot \text{Adam}(\nabla_{z_t} \mathcal{L}) zt′←zt−η⋅Adam(∇ztL) - Denoising Step(正常去噪) :拿到优化后的 zt′z'tzt′ 后,再用它进行标准的扩散步更新(如 DDIM step),生成下一步的 zt−1z{t-1}zt−1。
2. 为什么更新 ztz_tzt 能起作用?(直觉解释)
你可以把扩散模型的去噪过程想象成一个下山的过程(流形空间映射)。
- 模型(U-Net)的权重决定了山脉的地形。
- ztz_tzt 是你当前所在的位置。
- 如果你顺着默认路径走,可能会走到一个"风格不对"或"拼写错误"的谷底(局部最优)。
- Latent Optimization 的作用是 :在下山的半路上(特定的 timestep ttt),停下来环顾四周(算一下 Attention),发现势头不对,于是给 ztz_tzt 施加一个微小的外力(梯度更新) ,强行把 ztz_tzt 往旁边推一点,把它推到一个"更倾向于关注参考风格"或者"更倾向于关注正确字符位置"的轨迹上。
当 ztz_tzt 被稍微修改后,U-Net 在下一次看这个 ztz_tzt 时,它的注意力机制就会自然而然地(按照你设定的 Loss 期望)落在正确的地方。
3. 工程实现上的细节(The Devil is in the Details)
如果你要在工程上复现这个逻辑,论文的附录(Appendix E)透露了几个关键的操作细节,证明这并不是每一步都做的简单操作:
- 并不是所有 Step 都优化 :
如果每一步都做反向传播,推理速度会慢到无法接受,且后期改变 ztz_tzt 容易引入高频噪声破坏图像质量。OmniText 选择在去噪过程的早期阶段 (布局和总体风格形成期)进行干预。具体是在去噪进度的 0%(初始噪声), 20%, 和 40% 这三个节点进行。 - 多轮迭代(Iterative Update) :
在这三个特定的节点停下来时,不是只更新一次。而是把这一个 timestep 的状态作为一个 Optimization Loop,运行 Adam 优化器 20 次迭代。确保 Attention Map 的分布被充分"纠正"后,再继续后续的扩散去噪。 - Self-Attention Manipulation (SAM) 辅助提效 :
作者在工程实践中发现,只靠 LC\mathcal{L}_CLC 回传梯度,有些时候内容还是控不住(梯度消失或不够强)。于是他们加了一个强干预的 Trick:在算 Loss 的同时,强制把字符区域内的 Self-Attention 矩阵替换为单位矩阵(Identity Matrix III) ,这就阻断了字符内像素去瞎看其他地方的可能,强制梳理了梯度流,使得 LC\mathcal{L}_CLC 的梯度能更有效地作用到 ztz_tzt 上。
在推理(Inference)阶段,模型当然是**拿不到Ground Truth(最终完美修改好的结果图)**的。
这里所说的**"拼在一起"(即论文中的 Grid Trick),拼的其实是 "正在生成的带噪过程图(Masked Input)"和"参考图(Reference Image)"**。
推理时,模型到底"看"到了什么?
这是一个基于 Inpainting(图像修复)架构的扩散模型。在标准的 Inpainting 任务中,U-Net 在 timestep ttt 的输入通常是 3 个张量在 Channel 维度的 Concat:
- ztz_tzt :当前步的纯噪声或带噪潜变量(尺寸 H×WH \times WH×W)。
- zI⋅(1−M)z_{I \cdot (1-M)}zI⋅(1−M) :被抠了洞的输入图(Masked Input)。也就是你要修改的原图,但你要改字的区域被涂黑了。
- mmm:你要改字的 Mask 区域(0和1构成的单通道掩码)。
现在,引入 Grid Trick(网格拼接技巧):
为了让模型能在生成文字时"抄"到特定字体的风格,作者在推理前向传播时,在**空间维度(Width 维度)**上把输入强行拉宽了一倍,变成了一个 H×2WH \times 2WH×2W 的网格:
- 左半边(正在生成的编辑区) :
就是上面提到的那套常规输入。当前带噪的潜变量 ztz_tzt + 被抠了洞的原图 + 目标区域的 Mask。这半边就是在问模型:"请你根据 Prompt,在这个洞里画出新的字"。 - 右半边(参考区) :
放入的是**参考图(Reference Image, IrefI_{ref}Iref)**的特征,并且它的 Mask 设置为全 0(意思是告诉模型:右边这半边你什么都不用改,保持原样就行)。
拼接后的实际 Input 张量长这样:
- 噪声特征拼接 :zt, zIrefz_t, \\ z_{I_{ref}}zt, zIref (左边是带噪目标,右边是干净的参考图)
- 条件图拼接 :zIr⋅(1−Mshr), zIrefz_{I_r \\cdot (1-M_{shr})}, \\ z_{I_{ref}}zIr⋅(1−Mshr), zIref (左边是被抠洞的背景,右边是参考图)
- Mask拼接 :mshr, 0m_{shr}, \\ 0mshr, 0 (左边是要生成的区域,右边是0不需要生成)
这样拼在一起有什么奇效?(Self-Attention 的越界访问)
当你把这个 H×2WH \times 2WH×2W 的超宽张量丢进 U-Net 时,魔法发生在 Self-Attention(自注意力) 层。
在计算 Self-Attention 时,左半边(也就是 Mask 洞里正在生成像素的区域)会计算自己与整个 H×2WH \times 2WH×2W 空间中所有 Token 的相似度。
因为右半边放着包含绝美字体的"参考图",左半边正在生成的字符 Token 就会**"跨过中线",把注意力(Attention Weight)打到右半边的参考字上**,从而把颜色、纹理、笔锋等特征直接 Value 过来。
同时,配合我之前提到的 自注意力风格损失 (LS\mathcal{L}_SLS),模型会强行干预这个过程,拉大这种"跨界参考"的权重,逼着左半边生成的字去"抄"右半边的风格。
补充一个常见场景的细节
- 如果是"更换字体风格"(Style-based Editing):右半边的参考图就是用户额外提供的一张带有某种特定字体的图片。
- 如果是"普通的修改错别字"(Standard Editing) :右半边的参考图就是你要修改的这张原图本身(未抠洞之前的样子)!因为你希望新生成的字,和原图中已经被抹掉的老字的风格一模一样。