这是一篇非常具有突破性的自然语言处理(NLP)领域的大模型论文。这篇由蚂蚁集团(Ant Group)领衔撰写的论文《LLaDA2.0: Scaling Up Diffusion Language Models to 100B 》,标志着离散扩散语言模型(Discrete Diffusion LLMs, dLLMs)首次成功扩展到了千亿(100B)参数规模。
传统的大模型(如GPT-4, Llama 3, Qwen)几乎全是基于自回归(Autoregressive, AR)架构的,即从左到右逐字生成。而LLaDA2.0采用的是扩散(Diffusion)架构,支持全局双向理解和并行生成。
以下是对这篇论文的详细深度解读:
一、 核心动机与背景 (Why do this?)
- 自回归(AR)模型的局限性:
- 推理瓶颈: 从左到右逐个生成token,导致推理速度受限,难以实现大规模并行化。
- 上下文单向性: 严格的因果结构(只能看前面的词)在处理需要双向推理、全局理解的复杂任务时并非最优。
- 扩散语言模型(dLLM)的潜力与现状:
- dLLM通过"随机掩码重建(Masked Denoising)"的方式生成文本,天生支持并行生成 和完全双向上下文。
- 痛点: 之前的dLLM(包括LLaDA 1.0)规模都在8B及以下。从头训练千亿规模的扩散模型成本极其高昂,且缺乏成熟的基础设施支持。
论文的解决方案: 不从头训练! 而是提出一种巧妙的训练范式,将已经训练好的强大自回归模型(AR)"无缝改造(Convert)"成扩散语言模型(dLLM),从而继承AR模型的强大知识。
二、 核心技术与创新点 (How they did it?)
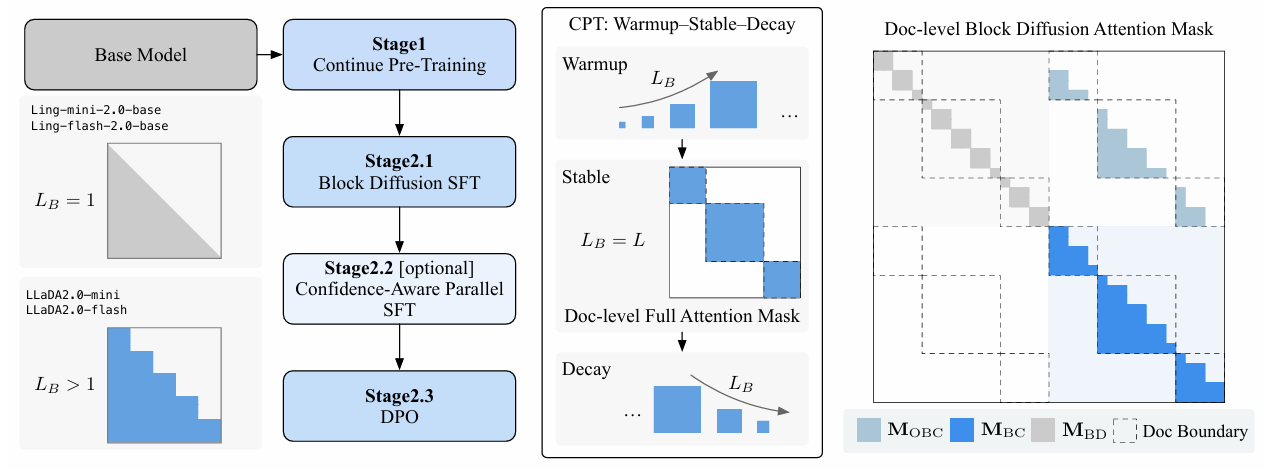
- 图2:将自回归(AR)模型转换为掩码扩散语言模型(MDLM)的渐进式训练框架示意图 。持续预训练阶段通过调度块大小 LBL_{B}LB 实现预热-稳定-衰减(Warmup-Stable-Decay)策略,让注意力掩码的适配过程平滑、稳定且高效。后训练阶段沿用相同的块扩散配置,执行指令监督微调(SFT)、置信度感知并行SFT以及直接偏好优化(DPO)。右侧面板展示了文档级块扩散注意力掩码 :该掩码将多个带噪样本与干净样本拼接为单一输入序列(如 xnoisy1,...,xclean1,...x_{noisy 1}, ..., x_{clean 1}, ...xnoisy1,...,xclean1,...),从而实现高效向量化前向传播。前向传播过程中会组合使用块对角掩码(MBDM_{BD}MBD)、偏移块因果掩码(MOBCM_{OBC}MOBC)与块因果掩码(MBCM_{BC}MBC)。
这篇论文最大的贡献在于提供了一套完整的"AR转Diffusion"的炼丹配方,分为三大阶段:
1. 连续预训练 (Continual Pre-training) ------ 创新的 WSD 策略
AR模型习惯了从左到右生成,直接让它做全图随机去噪,会导致模型崩溃、遗忘已有知识。为此,作者提出了 Warmup-Stable-Decay (WSD) 块级扩散训练策略:
- 知识铺垫:块扩散(Block Diffusion, BDLM)。不同于全序列扩散,块扩散将文本切分成块,块与块之间从左到右(AR),但块内部进行扩散去噪。这允许保留KV-Cache,有利于推理。
- Warmup (预热期 - 逐步扩大视野): 初始阶段,将"块大小(Block Size)"设为1(等同于AR),然后逐步增加到4、32、64,直到4096。这让模型平滑地适应越来越大的双向上下文掩码。
- Stable (稳定期 - 掌握扩散规律): 块大小固定在4096(等同于对全序列做MDLM扩散)。在这个阶段用大规模语料狂烧,让模型彻底掌握扩散和去噪的动态规律。
- Decay (衰减期 - 回归高效结构): 训练后期,把块大小再缩回较小的尺寸(如32)。这样既保留了全局双向理解能力,又恢复了块扩散(BDLM)在推理时的高效性(可复用KV-Cache、支持变长生成)。
关键技巧:文档级注意力掩码 (Document-level Attention Mask)
为了提高训练效率,通常会把多篇不相关的短文档拼成一个长序列。但在双向扩散中,如果不加限制,模型会跨越文档边界胡乱关联。作者设计了专门的注意力掩码,严格将注意力限制在单篇文档内,保证了语义的一致性。
图2右侧的解读:图2右侧展示的文档级块扩散注意力掩码,就像一张被精密切割的方形注意力地图:一条垂直中线将其平分为左右两半,左半对应带噪序列xtx_txt,右半对应干净序列x0x_0x0,同时多条水平和垂直的虚线(文档边界)又将整张地图分割成多个互不连通的独立文档区块;在左半部分的带噪区域内,浅蓝色的块对角掩码沿着对角线排列成一个个整齐的小正方形,每个小正方形对应一个带噪文本块,块内所有格子全亮(允许注意力流动),块外全暗(禁止关注),把带噪序列切成了一个个彼此隔绝的独立房间,每个房间里的token只能互相看见,绝看不到其他房间的任何内容。
这种掩码设计,最终让我们能将多个带噪-干净样本对拼接成一个长序列进行高效向量化前向传播,一次计算就能完成所有块的去噪训练,实现了训练效率与语义正确性的完美平衡。
注意到,在LLADA2.0中,将噪声序列和干净序列拼接是LLADA1.0没有的,这种操作可以视为是块扩散语言模型(BDLM)特有的向量化训练优化。
2. 对齐与微调 (Post-training)
把模型变聪明的关键步骤,包括SFT(监督微调)和DPO(人类偏好对齐)。
- 互补掩码 (Complementary Masking): SFT时,每次对一段文本生成两个掩码(一个是随机掩码,另一个是它的反向掩码)。这样保证每个token在一次训练中必定被模型看到一次,数据利用率达到100%,消除采样偏差。
- 核心创新:置信度感知并行训练 (CAP, Confidence-Aware Parallel Training)!
- 目的:为了极致的推理速度。 扩散模型之所以能并行解码,是因为它能在一步中猜出多个词。如果模型不自信,并行效率就低。
- 做法: 引入了一个额外的"置信度损失"。当模型预测正确某个token时,强迫它进一步降低预测熵(即让模型变得更"笃定"、更"锐利")。
- 结果: 这一招让 LLaDA2.0 的推理速度直接起飞。
- 扩散版 DPO: 针对扩散模型修改了DPO的目标函数,使用ELBO(证据下界)来代替传统的对数似然进行偏好对齐。
三、 实验结果与性能表现 (Results)
论文发布了两个模型:LLaDA2.0-mini (16B) 和 LLaDA2.0-flash (100B),并开源。它们与同等规模的最强AR模型(Qwen3系列、Ling系列)进行了对比。
- 综合能力全面逼近甚至超越 AR:
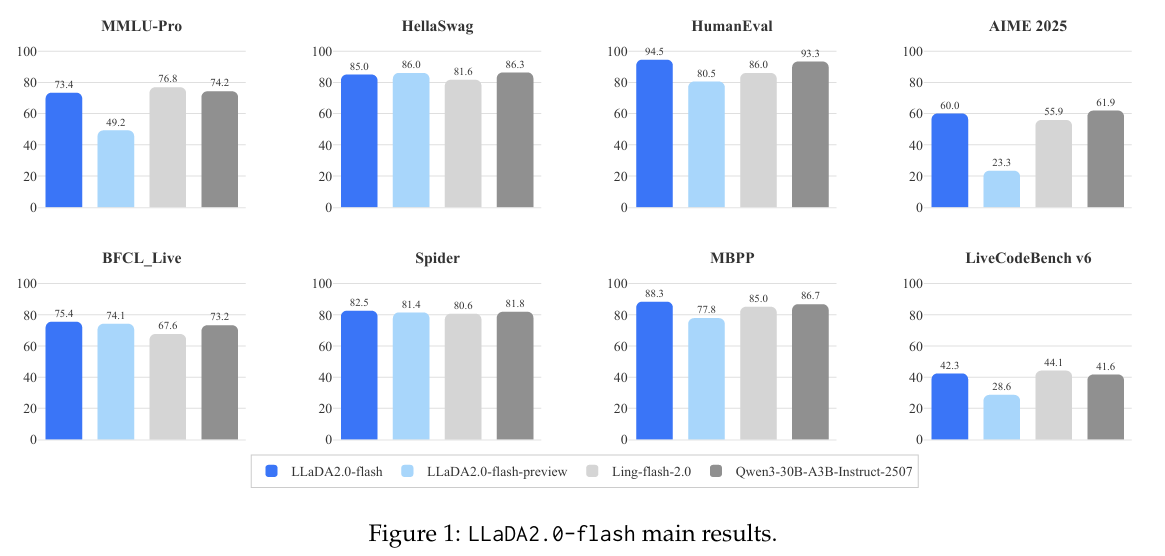
- 在47个基准测试中,LLaDA2.0-flash (100B) 平均分 73.18,与 Qwen3-30B-A3B-Instruct (73.60) 旗鼓相当。
- 在复杂推理和结构化任务上展现出扩散架构的先天优势:
- 代码 (Coding): LLaDA2.0-flash 在 HumanEval 上得分高达 94.51,超越所有对比的AR模型。
- 数学 (Math): AIME 2025 得分 60.00,极其强悍。
- Agent与工具调用: 在BFCL v3上得分领先。这表明由于扩散模型可以看到"未来"的上下文,它在需要全局规划的任务(如代码生成、工具调用)上具有天然优势。
- 推理速度大爆发(得益于CAP策略和块扩散):
- 在推理测试中,LLaDA2.0-flash-CAP 达到了惊人的 535 TPS (Tokens Per Second)。
- 相比之下,同等规模的AR模型(Qwen3, Ling)速度只有 237~256 TPS。速度翻倍! 彻底打破了"扩散模型推理慢"的刻板印象。
四、 工程基础设施 (Infrastructure)
训练千亿参数的扩散模型面临巨大挑战。作者使用了基于 Megatron-LM 的架构。
- 数值稳定性修复: 从AR转Diffusion时,由于AR模型在预训练时从未见过
[MASK]token,该token的权重会衰减到0。如果直接训练会导致梯度爆炸。作者巧妙地在初始阶段给 MASK 嵌入向量添加高斯噪声,稳定了训练。 - 计算加速: 针对块扩散特殊的注意力掩码,定制了基于 cuDNN 的后端,相比原生实现提速 1.3倍,节省 90% 显存。
- 推理引擎: 适配了 SGLang 等现代推理框架,支持 KV-Cache 复用。
五、 总结与意义
《LLaDA2.0》是一篇具有里程碑意义的论文:
- 打破了规模天花板: 证明了离散扩散语言模型(dLLM)完全可以扩展到千亿参数(100B)级别。
- 提供了极具实用价值的"捷径": 证明了不需要花费极高成本从头预训练dLLM,"AR初始化 + 渐进式改造(WSD)" 是一条完全可行的康庄大道。这对于整个开源社区将是一个巨大的启发。
- 解决了速度痛点: 通过 BDLM 架构和 CAP 训练,扩散模型实现了比传统 AR 模型快两倍的生成速度。
- 展示了 Agentic LLM 的新可能: 在代码和数学等需要逻辑规划的领域,dLLM 展现出的超越 AR 模型的潜力,为未来的 Test-Time Scaling (测试时计算扩展) 和复杂推理模型打开了新的大门。