一、前言
2024年6月,阿里巴巴正式发布了Qwen系列模型的第二代------Qwen2。这不仅是一次版本迭代,更是一次在模型架构、多语言能力、上下文长度及核心性能上的全面革新 。作为开源社区的重要参与者,Qwen2以其在多个基准测试中的领先表现,迅速成为开发者关注的焦点。

二、核心架构与模型矩阵
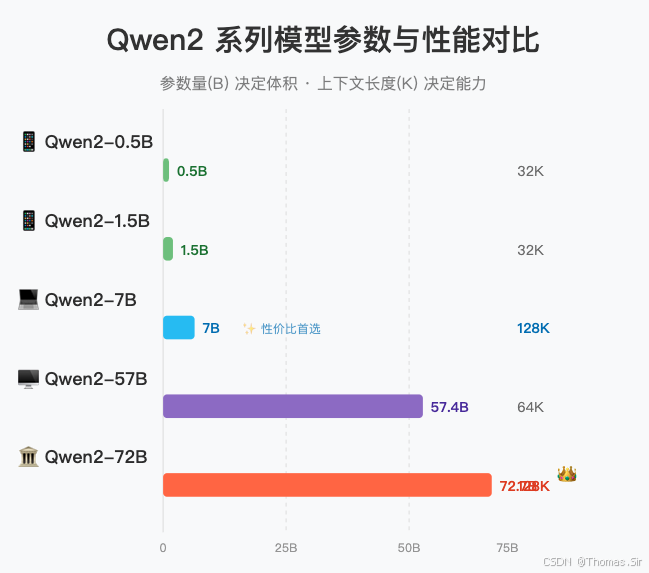
Qwen2系列提供了从0.5B到72B的完整参数规模矩阵,旨在满足从移动端到服务器端的多样化部署需求。其核心架构升级主要体现在三个方面:
🔧 关键技术升级
全系GQA与Tie Embedding
Qwen2在所有尺寸的模型上都采用了分组查询注意力(GQA),相比Qwen1.5仅在32B和110B上使用,此次升级显著降低了推理时的显存占用并提升了速度。针对小参数量模型,还引入了Tie Embedding技术,让输入和输出层共享参数,有效增加了非嵌入层参数的占比,提升了模型效率。
Tokenizer与多语言支持
Qwen2采用了包含151,643个常规token和3个控制token的统一BPE分词器,编码效率高。其训练数据在中文和英文基础上,新增了27种语言的高质量语料,显著提升了多语言理解和代码切换能力。
长上下文支持
所有预训练模型均在32K tokens的上下文长度上进行训练。通过YARN或DualChunkAttention等技术,Qwen2-7B-Instruct和Qwen2-72B-Instruct的上下文长度被扩展至128K tokens,使其能够处理超长文档。在"大海捞针"测试中,Qwen2-72B-Instruct能在128K长度内近乎完美地完成信息抽取任务。
三、性能表现与基准测试
根据官方技术报告和社区评测,Qwen2在多项核心能力上实现了跨越式提升,尤其在代码和数学领域表现突出。
| 模型规模 | 关键特性 | 突出表现 |
|---|---|---|
| Qwen2-72B | 最大开源模型,128K上下文 | 在自然语言理解、知识、代码、数学及多语言能力上全面超越Llama-3-70B及Qwen1.5-110B。 |
| Qwen2-7B | 平衡性能与效率 | 数学能力可媲美上一代的Qwen1.5-110B,在多个评测中超越同规模甚至更大规模的开源模型。 |
| Qwen2-57B-A14B | 混合专家(MoE)架构 | 以更少的激活参数实现高性能,支持64K上下文,在效率与能力间取得平衡。 |
| Qwen2-0.5B/1.5B | 超轻量级,支持32K上下文 | 适用于资源受限的边缘设备,所有小模型均采用GQA和Tie Embedding以优化性能。 |
在安全性方面,Qwen2-72B-Instruct在多语言不安全查询测试中,其生成有害响应的比例与GPT-4表现相当,并显著优于Mistral-8x22B等模型。
四、生态与应用
Qwen2秉承开源精神,除72B版本沿用Qianwen License外,其余模型均采用Apache 2.0许可证,极大降低了商业应用门槛。其生态与主流开源工具链深度集成:
- 微调与训练:支持Axolotl、Llama-Factory、Firefly、Swift、XTuner等框架。
- 量化与部署:兼容AutoGPTQ、AutoAWQ进行量化,可通过vLLM、TensorRT-LLM、Ollama等工具高效部署。
- 推理服务:可通过Hugging Face Transformers或vLLM轻松加载,并提供了与OpenAI API兼容的服务接口,方便集成。
- Agent与RAG:与LlamaIndex、CrewAI等Agent及检索增强生成框架良好兼容。
对于开发者而言,使用Hugging Face Transformers库是调用Qwen2最直接的方式。模型也支持通过vLLM部署为兼容OpenAI API的服务,极大简化了生产环境的集成流程。
从Qwen2到Qwen2.5的演进
在Qwen2发布约三个月后,阿里于2024年9月推出了Qwen2.5系列,这可以看作是Qwen2的一次重大增强迭代。
1. 知识与能力飞跃
Qwen2.5在多达18万亿token的最新数据集上进行了预训练,其在MMLU(通用知识)基准上的得分超过85分,代码(HumanEval)和数学(MATH)能力分别提升至85+和80+分。
2. 专业化模型分支
除了通用的Qwen2.5语言模型,还发布了专注于代码的Qwen2.5-Coder和专注于数学的Qwen2.5-Math等专家模型,在特定领域表现更为强悍。
3. 工程化增强
改进了对长文本生成(超过8K token)、结构化数据(如表格)理解、JSON格式输出稳定性以及对多样化系统提示词的适应能力,使其更适用于实际生产场景。
五、总结与展望
Qwen2的发布标志着阿里在大模型开源赛道进入了一个新的阶段。它通过全系GQA、扩展的上下文窗口、显著增强的代码与数学能力,以及更友好的开源协议,为开发者和企业提供了一个性能强劲且易于部署的基础模型选择。其后续的Qwen2.5版本则进一步巩固了其在知识、推理和工程化方面的优势。
从技术演进的角度看,Qwen系列清晰地展现了一条路径:从追赶,到并跑,再到在特定领域实现超越。其持续迭代也反映出大模型发展的核心趋势------不再是单纯追求参数规模,而是在架构优化、数据质量、专业化分工和工程易用性上寻求综合突破。
六、本地部署Qwen2实战指南
想要在本地运行强大的Qwen2模型,摆脱网络依赖与数据隐私顾虑?这份指南将带你从硬件准备到实战部署,一步步实现AI大模型的私有化推理 。
无论你是开发者、研究者,还是对AI技术充满好奇的探索者,都能找到适合自己的部署路径。
6.1、部署路径选择
根据你的技术背景和需求,主要有两种主流部署方式:Ollama一键部署 和手动环境搭建。
Ollama适合追求简便快捷的用户,而手动搭建则能提供更灵活的配置和深度控制。
Ollama:最简部署方案
(1)安装与环境配置
Ollama是一个专为本地运行大语言模型设计的开源框架,支持Windows、macOS、Linux和Docker。
Windows用户
访问官网下载安装包,按向导完成安装即可。
Linux/macOS用户
使用终端命令安装:
curl -fsSL https://ollama.com/install.sh | sh
(2)模型下载与运行
安装完成后,通过简单的命令行即可拉取并运行Qwen2模型:
bash
基础命令
# 拉取模型(以7B版本为例)
ollama pull qwen2:7b
# 运行模型进行交互
ollama run qwen2:7b版本注意:运行Qwen2需要Ollama版本≥0.1.42,否则可能出现乱码问题。
(3)Web界面增强体验
除了命令行交互,还可以部署Web界面获得更好的用户体验。
- 安装Node.js:从官网下载安装最新版本
- 下载ollama-webui:从GitHub获取开源项目
- 配置与启动 :安装依赖后运行
npm start- 浏览器访问:打开指定地址即可使用图形界面
手动部署:完全控制方案
对于需要深度定制和性能调优的用户,手动部署提供了更大的灵活性。以下是基于Python环境的完整部署流程。
(1)环境准备与硬件要求
💻 硬件配置
GPU:NVIDIA显卡(建议RTX 3060 12GB+)
CPU:8核以上,i7/Ryzen 7系列
内存:16GB以上
存储:30GB可用空间
📦 软件环境
Python:3.10+版本
PyTorch:2.0.0+(支持CUDA)
Transformers:4.37.0+
系统:Windows 10/11或Ubuntu 20.04+
🐍 Python环境配置
a. 使用Miniconda创建隔离环境
bash
# 创建并激活环境
conda create -n qwen25 python=3.10 -y
conda activate qwen25
# 安装核心依赖(国内用户建议使用清华源)
pip install torch==2.8.0 transformers==4.56.1 accelerate==1.10.1 -i https://pypi.tuna.tsinghua.edu.cn/simpleb. 环境验证代码
python
import torch
import transformers
print(f"PyTorch版本: {torch.__version__}") # 需≥2.0.0
print(f"Transformers版本: {transformers.__version__}") # 需≥4.37.0
print(f"CUDA是否可用: {torch.cuda.is_available()}") # 应返回True模型获取方式
方式一:Git工具克隆(推荐)
国内用户可使用GitCode镜像加速,下载速度更快。
bash# 克隆模型仓库(需安装Git LFS) git clone https://gitcode.com/mirrors/Qwen/Qwen2.5-7B-Instruct.git cd Qwen2.5-7B-Instruct # 检查文件完整性 ls -lh | grep "model-.*\.safetensors" # 应显示4个模型分片文件方式二:Hugging Face Hub下载
适合已配置huggingface-cli的用户,支持断点续传。
pythonfrom huggingface_hub import snapshot_download snapshot_download( repo_id="Qwen/Qwen2.5-7B-Instruct", local_dir="./Qwen2.5-7B-Instruct", local_dir_use_symlinks=False, resume_download=True # 支持断点续传 )
6.2、基础推理与优化
成功加载模型后,如何高效运行并优化性能是关键。以下提供标准部署代码及显存优化策略。
标准推理代码示例:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(
"./Qwen2.5-7B-Instruct",
torch_dtype="auto", # 自动选择最优精度
device_map="auto", # 自动分配设备
low_cpu_mem_usage=True # 降低CPU内存占用
)
tokenizer = AutoTokenizer.from_pretrained("./Qwen2.5-7B-Instruct")
# 构建对话历史
messages = [
{"role": "system", "content": "你是由阿里云开发的AI助手Qwen,擅长中文对话与任务执行。"},
{"role": "user", "content": "请解释什么是大语言模型的上下文窗口?"}
]
# 应用对话模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 推理生成
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512, # 生成最大长度
temperature=0.7, # 随机性控制(0-1,值越低越确定)
top_p=0.8 # 核采样参数
)
# 提取结果
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)显存优化策略对比
| 优化方案 | 显存占用 | 性能损耗 | 实现难度 |
|---|---|---|---|
| 标准BF16 | ~14GB | 0% | ⭐ |
| 8-bit量化 | ~8GB | <5% | ⭐⭐ |
| 4-bit量化 | ~5GB | <10% | ⭐⭐⭐ |
| CPU卸载 | 依配置而定 | 30-50% | ⭐⭐ |
8GB显存优化方案
通过8位量化技术,可在消费级显卡上运行70亿参数模型。
python
# 需安装bitsandbytes库:pip install bitsandbytes
from transformers import BitsAndBytesConfig
model = AutoModelForCausalLM.from_pretrained(
"./Qwen2.5-7B-Instruct",
load_in_8bit=True, # 启用8位量化
device_map="auto",
quantization_config=BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0 # 量化阈值调整
)
)6.3、常见问题与解决方案
部署过程中可能会遇到各种问题,这里整理了最常见的几个问题及其解决方案。
⚠️ 模型加载缓慢
首次加载模型时可能较慢,可启用离线模式避免网络检查。
export TRANSFORMERS_OFFLINE=1
🔤 中文输出乱码
确保使用正确的分词器配置,添加trust_remote_code参数。
tokenizer = AutoTokenizer.from_pretrained(
"./Qwen2.5-7B-Instruct",
trust_remote_code=True
)
⚡ 推理速度过慢
启用Flash Attention 2可显著提升推理速度,需要额外安装。
pip install flash-attn --no-build-isolation
6.4、性能对比与成本分析
本地部署不仅关乎技术实现,还需要考虑性能与成本的平衡。以下是本地部署与云端API的对比分析。
云端API(GPT-3.5)
按日均1000次请求计算:
约¥300/月
本地部署
24小时运行成本:
约¥65/月
(电费¥15 + 硬件折旧¥50)
经济优势
年节省约¥2820,硬件投资回收期<6个月。对于高频使用场景,本地部署具有显著的成本优势。
6.5、进阶应用与扩展
基础部署完成后,可以进一步探索模型的高级功能和应用集成,充分发挥Qwen2的潜力。
🔗 结合LangChain构建应用
将Qwen2集成到LangChain生态,构建更复杂的AI应用。
from langchain.llms import HuggingFacePipeline
from langchain.chains import LLMChain
创建问答链并运行
🎯 模型微调定制
使用LoRA等技术对模型进行微调,适配特定领域任务(需24GB+显存)。
pip install peft trl datasets
启动LoRA微调训练
📈 性能加速方案
使用vLLM等推理框架,可实现5-10倍的吞吐量提升。
安装vLLM加速框架
pip install vllm
启动高性能推理服务
6.6、写在最后的话
无论选择Ollama的便捷部署还是手动搭建的深度控制,Qwen2的本地化都为AI应用开发打开了新的大门。从硬件准备到性能优化,每一步都让大模型离个人计算更近一步。
技术的民主化不在于让复杂变简单,而在于让强大变得触手可及。现在,强大的AI推理能力已经可以在你的本地机器上运行------这不仅是技术的进步,更是创造力的解放。