Q:MySQL中的回表是什么?
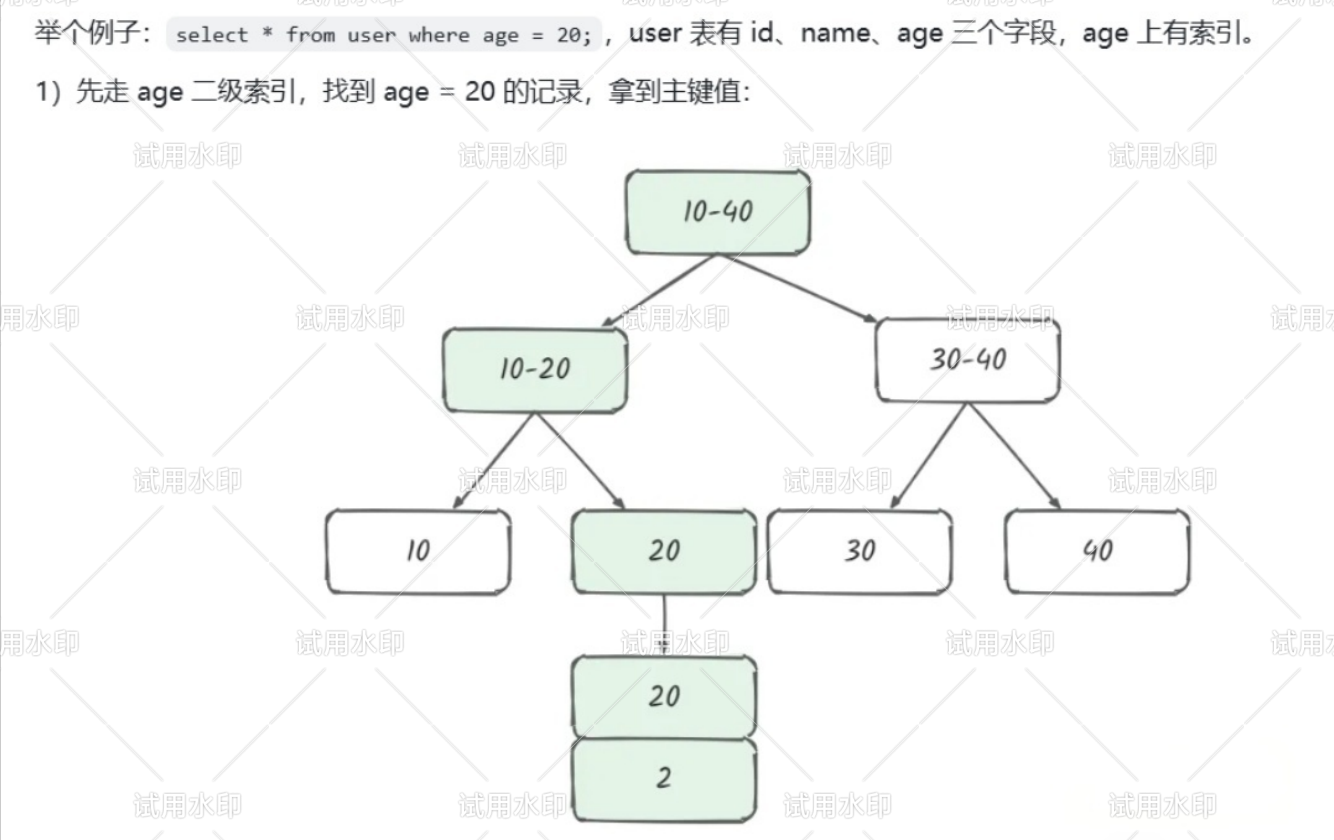
回表是二级索引的B+树进行查找的一个操作,二级索引存储索引和主键值 ,聚簇索引存储完整数据,当对二级索引的数据进行查询是,查到他的主键值,在通过主键值,查到对应的数值,用一个形象的比喻来说,相当于查字典时候,你通过拼音(二级索引)查到相应的页码(聚簇索引),在通过页面找到对应页面,获得这个词语的完整解释. 简单来说就是二级索引不够用,需要再借助一次主键索引
举一个简单的例子 select* from user where age=20;由于二级索引存储的是索引和主键值,即age 和 id,没有name,所以先通过二级索引拿到主键值2,在通过主键值2去聚簇索引拿到name
Q:如何避免回表,减少回表?
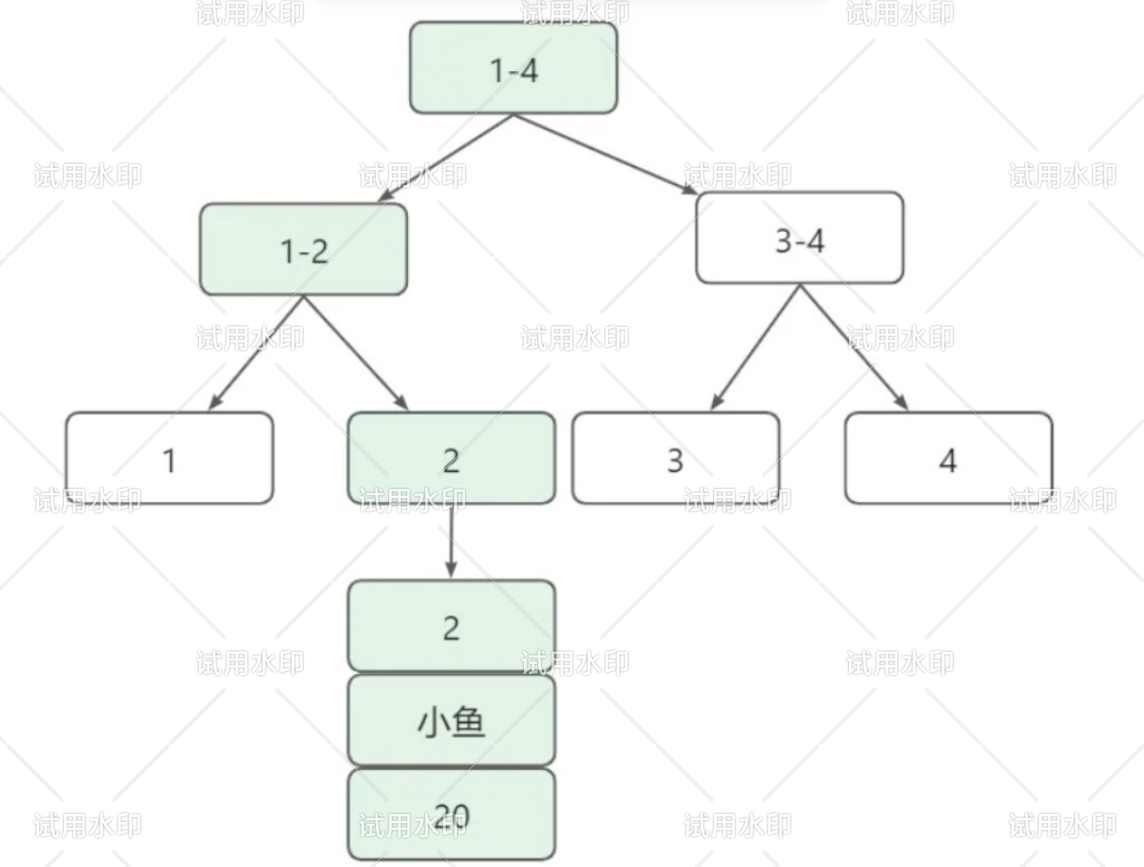
A:(1)覆盖索引,比如上方的例子,可以把索引值改成(name,age),那么索引值是name,age,主键值是id,索引的叶子节点存储了name ,age ,id,直接就可以查到数据,不用回表
(2)索引下移
MysSQL5.6之后引入的,例如 select*from user where age = 20 and name like "张";之前的mysql是先拿到age=20数据,然后全部回表拿到完整数据,再在server层进行过滤
5.6之后,可以直接通过like在引擎层过滤一遍,不符合条件的直接跳过不回表,减少了大量的回表
(3)减少select *的使用
Q:回表的性能代价?
A:通过二级索引拿到的主键值不是连续的,比如拿到age=20,存储age=20的数据很多,而且他不是顺序存储,进行查询时,需要定位到不同的页面,同时带来大量的I/O
顺序I/O可以预读磁盘,一次可以读大量的连续数据,随机I/O每次都要重新寻址,磁盘来回转,很慢,导致性能大幅度下降
Q:怎么判断一个查询有没有回表?
执行Explain 看extra,如果显示的是Using index ,则说明覆盖索引,不需要再次回表,如果无Using index ,则需要回表,如果遇到type这种情况,有时候也需要回表
Q:在Mysql中建索引需要哪些注意事项?
A:1:索引不是越多越好,会占用空间,索引也是需要维护的,索引太多,代价比较大
2:大量重复的字段不要建立索引,例如性别,效率不高
3:长字段不要建立索引,例如text,longtext
4:表的修改频率远远高于查询频率的时候,不建立索引
5:频繁出现在where后面的字段,要建立索引,
6:order by, group by,distint 后面出现的字段,建立索引,因为涉及到排序,分组,去重,而所以是有序的,可以加快速度