
Motivation
从vision encoder, Architecture:MoE/Dense, multimodal data,world modeling,scaling laws of UMMs 等几个方面对Native multimodal pretraining 进行探索;
Contribution
4 Suggestions

a. RAE 对于视觉理解和生成是最优的;
b.视觉和文本数据是互补的, 并且在下游任务中表现出协同效应;
c.UMMs能够从各类数据的预训练中naturally 走向world modeling, 并且涌现出各种能力;
d.MoE 是一种effective and efficient 结构,并且促成了modality specialization;
Findings
通过IsoFLOP 分析发现vision 相比较于language 更加data-hungry;并且进一步证明MoE更适合用来建模多模态统一理解生成模型;
模型结构和数据介绍:
model
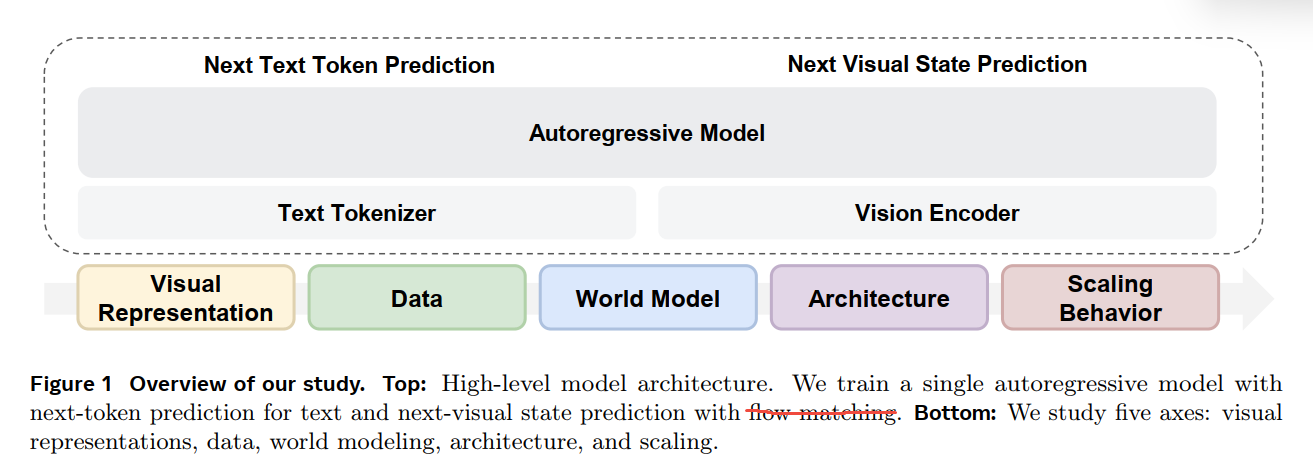
· 采用TransFusion结构,next-token for Language and diffusion for vision gen;
· hybrid attention,language 采用causal,vision 采用block-wise,每个视频帧内部share attn;
· 采用LLaMA3 text encoder;
· modality-specific FFNs:即text 和vision 不共享参数,而是各自拥有自己的参数;相当于2 experts,并且视觉和语言各自一个专门的expert (后文探索了改为MoE);
Data

520B text + 520B Multuimodal data 总计1T tokens
web text;
youtube video at 1FPS;
paired image-text data;
action-conditioned navigation 轨迹 I+T --> I ;
Cambrian-7M dataset 用作VQA 任务的微调,1 epoch;
Evaluation
Representation AutoEncoder
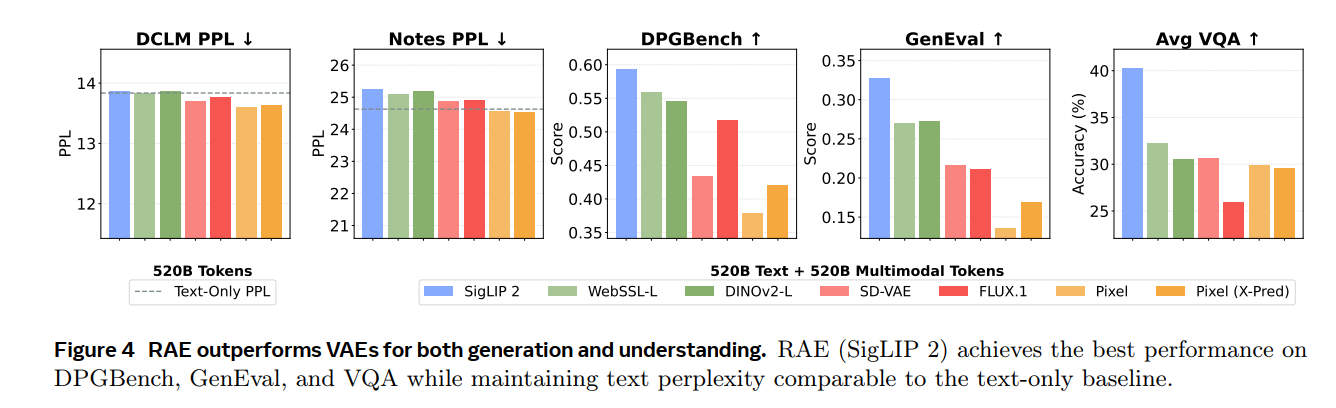
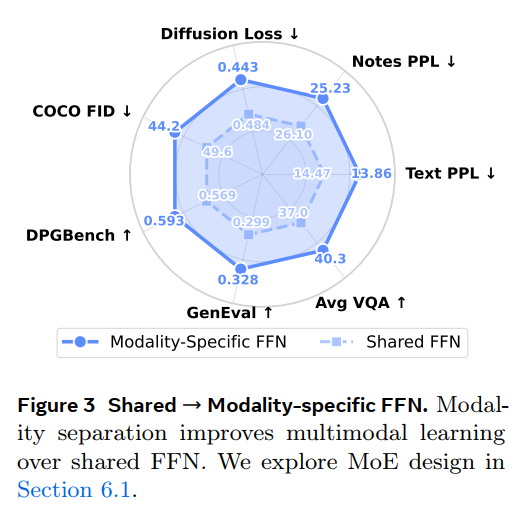
· finding1:最终结果是RAE这种方式效果最好;(这里的生成只测试了文生图,但是没有测试图像编辑)
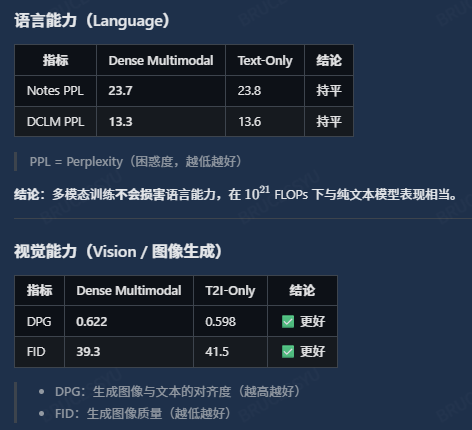
· finding2: 视觉模态并不会影响文本模态,比如前两个图表,并且发现多模态训练甚至会提升(相比较于纯文本的训练);
· finding3:single encoder也能产生很好的理解生成能力,尤其是除了VQA之外,在geneval和dpgbench上也取得了优于vae的效果;
· finding4: JIT(kaiming)虽然生成能力落后比较多,但是理解上相差不是特别多(作者认为继续scaling compute等可以做的更好);

Pretraining data composition
finding2:发现采用video+text的形式并不会特别影响语言的建模;这说明video data at least compatible with text, 并且有可能对language modeling有促进作用;这说明视觉表征并不是导致modality competition 的主要原因;
这里DCLM是in domain测试,而Notes是ood;作者认为ood效果变差,(This suggests that multimodalpretraining may introduce a minor trade-off in text generalization. )
对于退化问题做了进一步解释:a shift in the text distribution from introducing image captions

作者对于不同的caption数据做了对比,表格中的cosine distance和第二个图结果一致,证明caption和llm 分布差异越大,带来的退化就越严重;
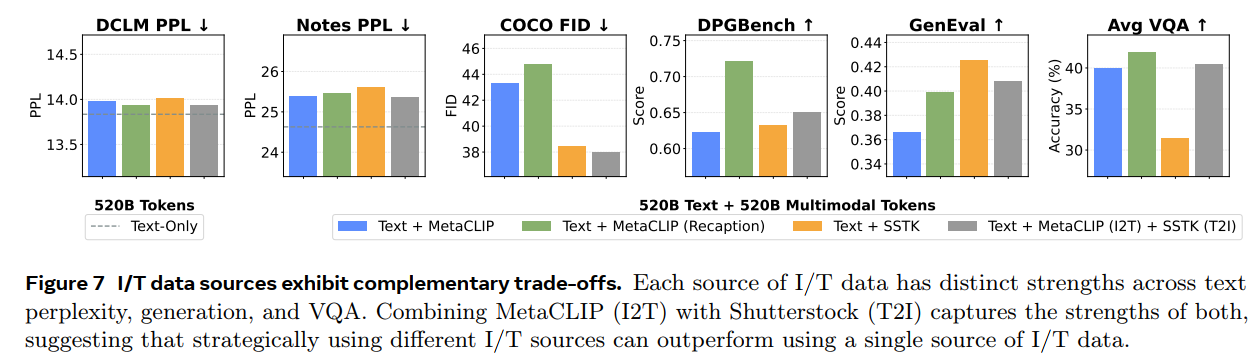
· finding6: ti pairs 对于视觉理解生成能力是非常重要的;而视觉理解任务能够从broader data diversity中收益;
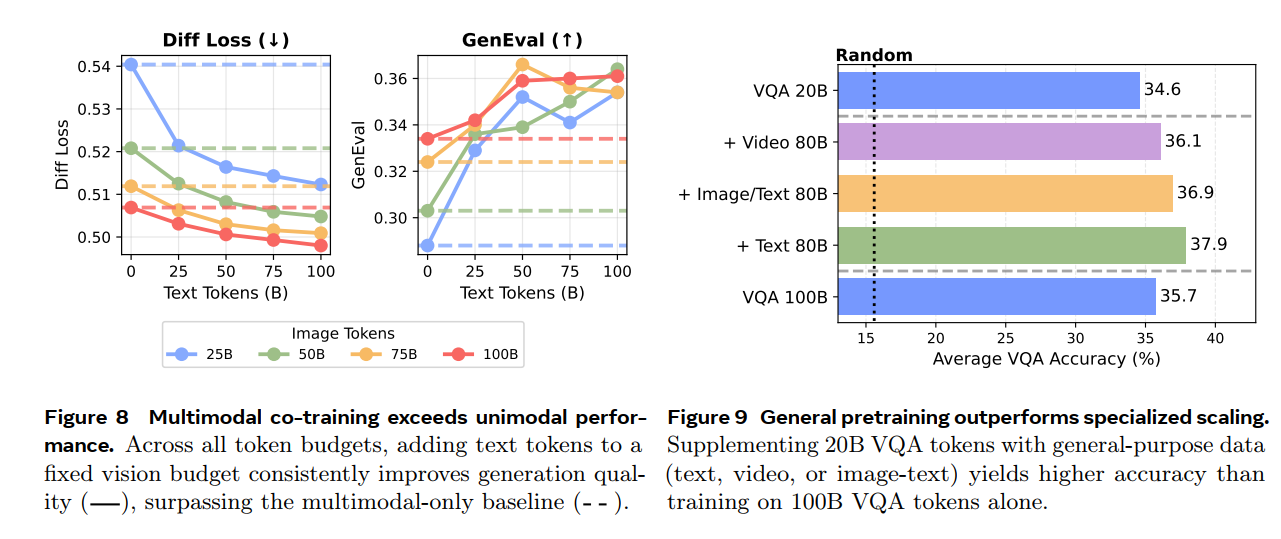
· finding7: language helps vision, vision minimally impacts language;(图8 固定image tokens数目,增加text tokens,diffusion loss逐步下降)
使用混合模态的数据,比单一模态的数据好(左图);使用多样的数据形式,比只采用VQA 数据要好(右图)只采用20B indomain data 然后加上异构的80B 数据会优于100B indomain data,说明diverse training 是更优越的)
Towards World Modeling

直接采用文本描述的action 作为输入,不需要修改模型结构;
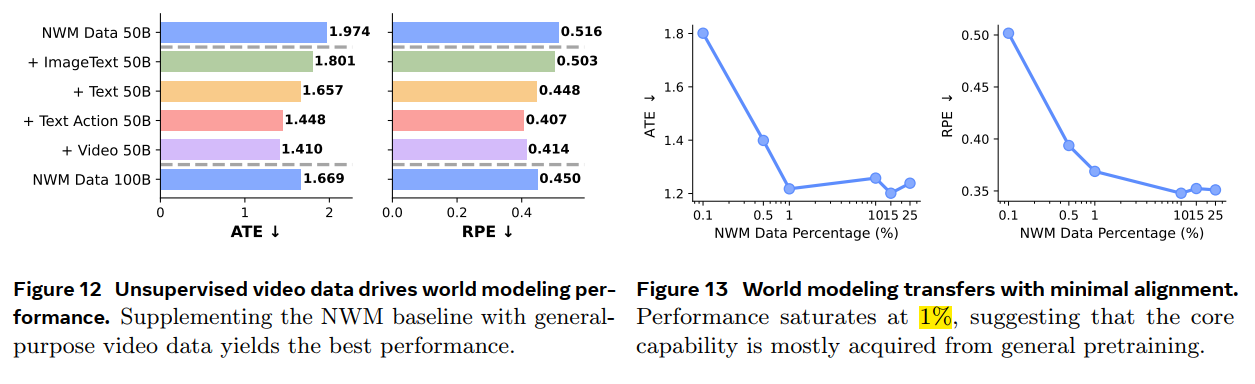
fig12:相比较于纯粹的NWM data-100B, 采用50BNWM data+other multimodal data可以实现更好的效果;
尤其是video data/text action;
作者认为这说明 world modeling 能力的解锁需要multimodal pretraining 而不是domain specific knowledge;
fig13:采用不同比例的NWM 和 general VQA ,总共200B,发现只用NWM 1%数据就可以解锁 world modeling 能力,同样证明这些能力来自于 general multimodal pretraining;

除了按键,还支持一些自然语言的描述;

Architecture Design-MoE
Granularity,Sparsity, Prediction Targets, Shared Experts;
Granularity
采用57B 文本/图像数据 half-half 混合进行验证;采用VAE 和 RAE 两种方式进行比较;
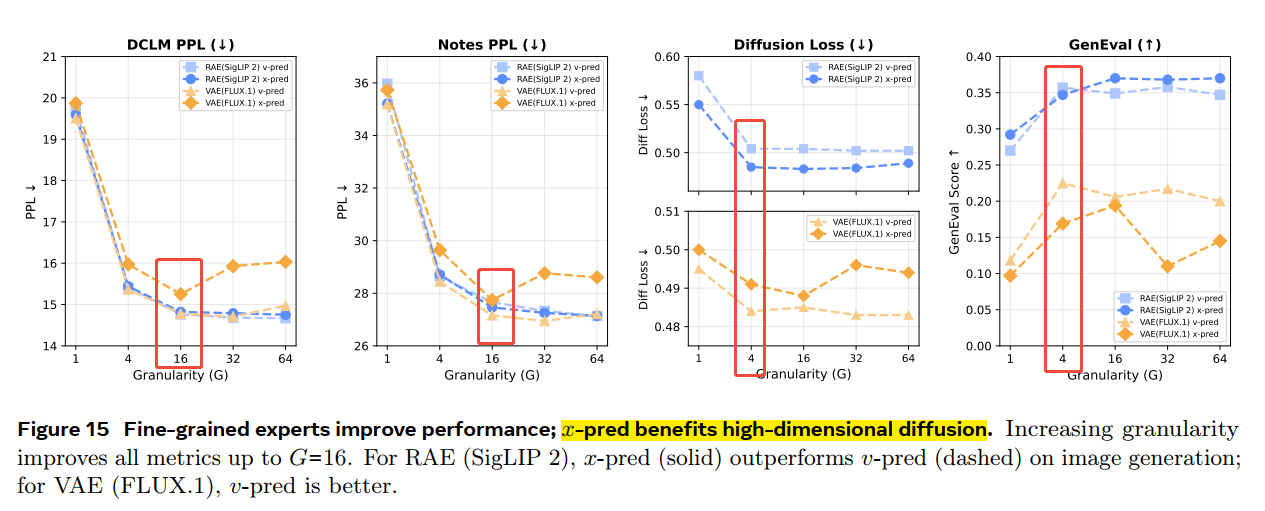

这里的Granularity 是指active expert number,或者说top-G路由;专家总数为16*G;这里采用FFN 比较常见的ratio=4,则随着granularity 增大,每个expert的dimension是降低的;因此激活维度是固定的8192;
如 G=1, expert_dim = 8192;
G=16,expert_dim = 512;
以上实验总的expert 数目为32, active expert 数目为16;
几点观察:
· granularity 越大,即分配的experts numer越多(每个expert 分配的dimension更小),效果越好(但也会饱和);
· RAE 生成效果更好;
Prediction target depends on visual representation:
· 对于RAE,x-pred 优于 v-pred, 对于VAE,v-pred优于 x-pred;
· 对于vision, 4 group就已经饱和,对于language 16 group会饱和, 因此作者认为 language benifits more(parameter-hungry);
Sparsity (Scaling Total Experts)
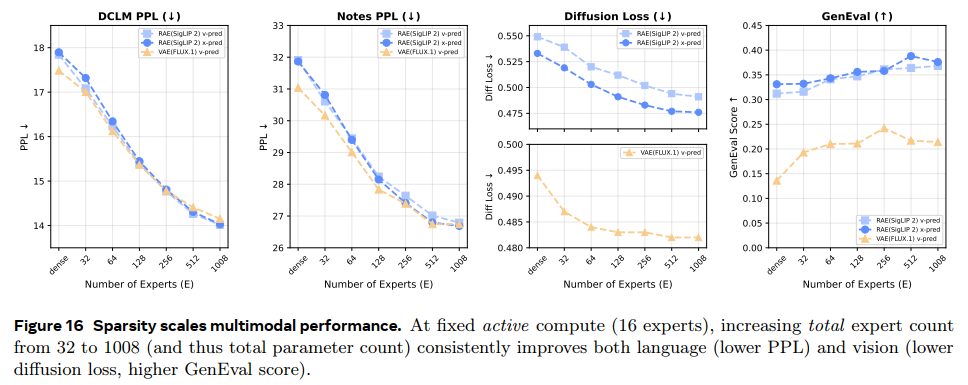
继续扩大total experts from 32 to 1008;
保持active expert number为16,持续扩大total expert,language 和vision 性能持续提升;
(不会有负载不均衡的现象吗?)
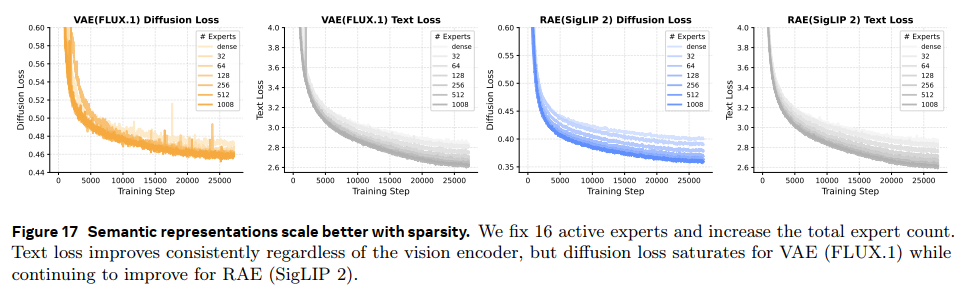
同样做了vae 和rae的对比,随着experts增多,RAE loss一直在降低,说明RAE scalability 更强;
Expert design choices
一共三种设计方案:
· 常规的top-16
· 一个全模态共享的expert + top-15;
· 一个text 共享expert + 一个vision 共享expert + top-14;
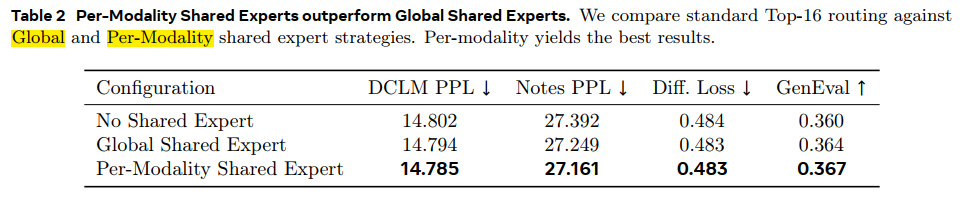
per-modality shared experts 效果更好;
Emergent Expert Specialization 验证不同模态倾向于激活的专家
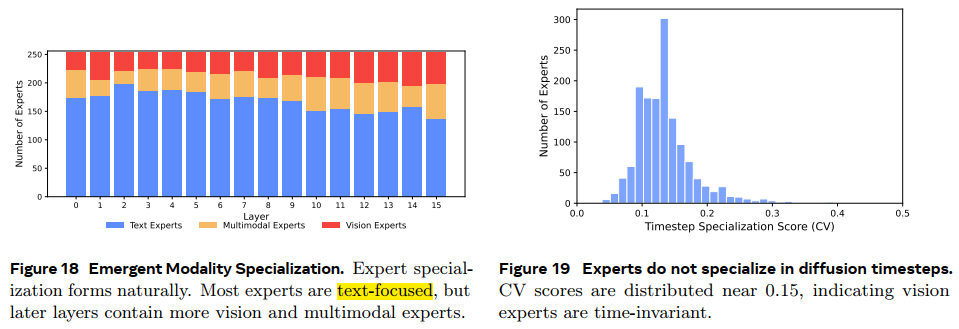
fig18:采用大致相等的数据去训练,发现language激活的experts数目更多;
fig19:激活的experts数目time-invariant,与time step无关(目的是探索Wan相关的动机,按照PSNR 区分两个experts)
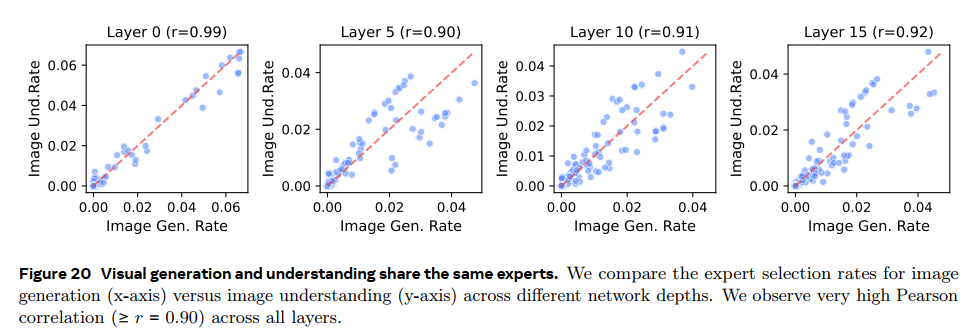
fig20:但是对于视觉理解/生成 的experts是比较集中的,重合度在90%左右;这说明视觉内部能够形成统一的表征;能够印证之前的工作结论----理解生成可以相互增益;
回顾几个结论:
Vision encoder.
比较VAE,RAE,BAGEL一样的双encoder, 最终RAE在理解和生成上效果都最好;
Parameter separation strategy.
与dense model, MoT相比,MoE实现了最好的效果,无论是理解还是生成;
除了性能之外,MoE还有一个优势,learning from data generally outperforms hand-crafted designs
Prediction target.
采用x-pred 提升了生成效果;
Knowledge-informed generation.
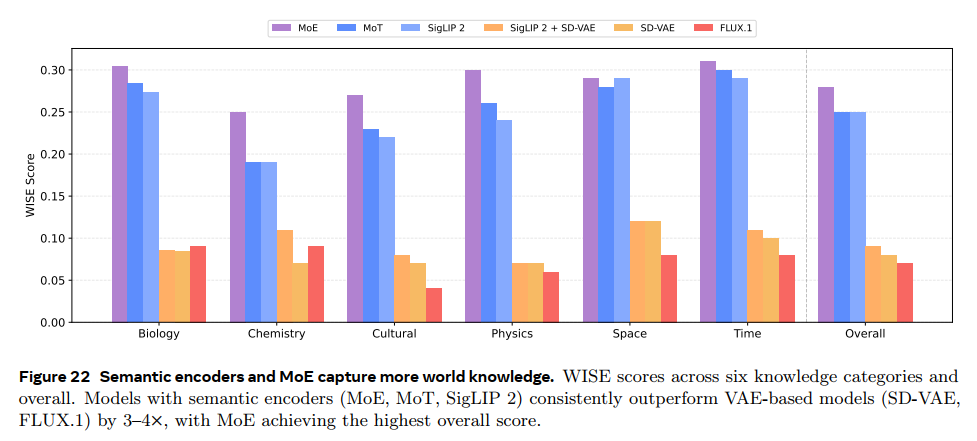
在WISE上进行world knowledge的生成测试,上图分别证明了RAE encoder的重要性以及MoE结构的优越性;

Scaling law of UMMs
研究问题如下
- 在统一多模态(语言+视觉)模型里,给定总算力 C,模型参数规模 N 和训练 token 数 D 应该怎么配最优?
- 稠密模型与 MoE 稀疏模型在这个问题上的规律是否不同?
- 多模态里语言与视觉的最优配比是否一致?
对于Dense Model:
FLOPs≈6ND≈C.
一个线性权重 w 在一次前向+反向中大约会被用到 3 次乘加(各含乘和加),合计约 6 次浮点运算。
意思是当总算力C 固定,模型参数N也固定的时候,训练的tokens = C/(6N);这样固定的C ,实际是一个反函数,能找到最佳的ND pairs;
对于MoE:
采用实际激活的参数值统计计算量;

a+b=1 目的是让左右式子的量纲一致;
Compute-optimal for dense models.
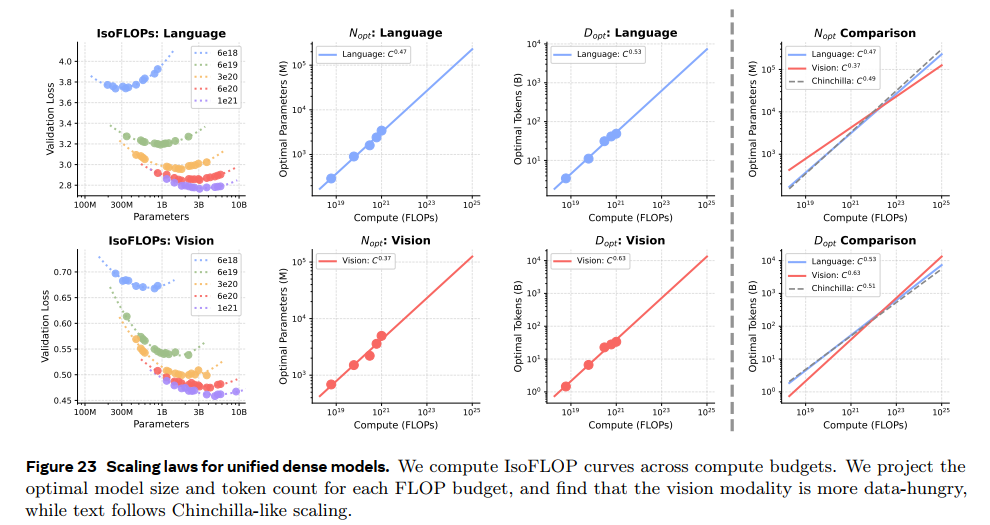
最终结果,对于Language:
Nopt = 0.47, Dopt=0.53
对于Vision
Nopt = 0.37, Dopt=0.63
这说明vision是data-hungry;
Compute efficiency for dense models.

Compute-optimal for MoE models.
终结果,对于Language:
Nopt = 0.41, Dopt=0.59
对于Vision
Nopt = 0.36, Dopt=0.64
这里参数发生了shift, 比如语言对数据的依赖程度变高了。作者解释如下

MoE compute efficiency. MoE 架构下,多模态联合训练是否能匹配单模态专用模型?
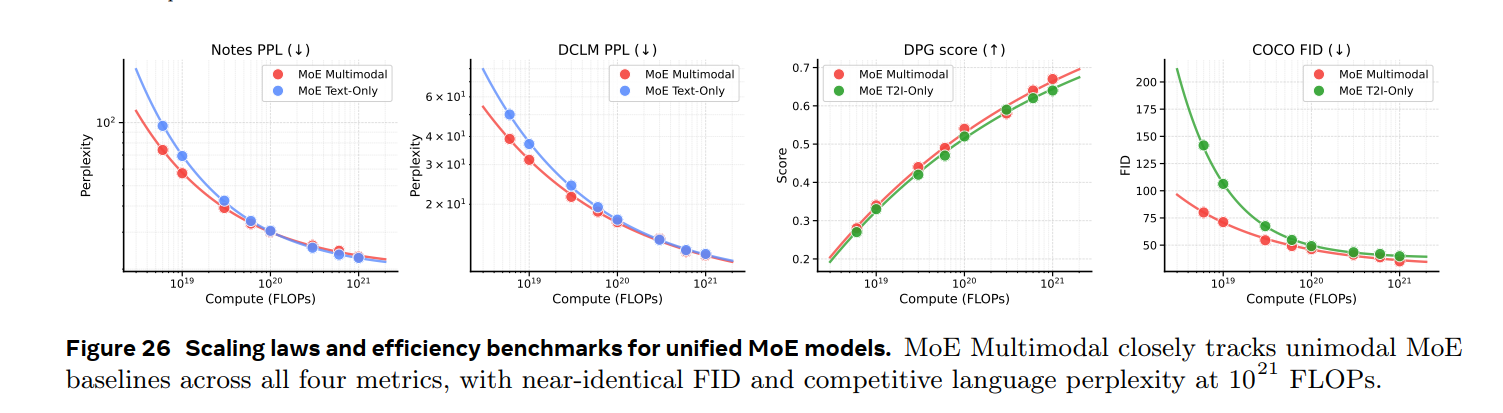
主要结论:
