重排(Rerank) 是决定最终效果的关键一环。当初步检索返回数十甚至数百个相关文档时,如何精准地将最相关的少数文档置于前列,直接影响大模型的生成质量。本文将深入介绍 openJiuwen 检索增强系统中重排模块的设计与实现,展示如何通过统一接口支持多种重排服务。
目录
[1.1 为什么需要重排?](#1.1 为什么需要重排?)
[🔍 问题一:语义鸿沟(Semantic Gap)](#🔍 问题一:语义鸿沟(Semantic Gap))
[🔍 问题二:词汇不匹配(Vocabulary Mismatch)](#🔍 问题二:词汇不匹配(Vocabulary Mismatch))
[🔍 问题三:多维度相关性(Multi-dimensional Relevance)](#🔍 问题三:多维度相关性(Multi-dimensional Relevance))
[1.2 交叉编码器 vs. 双编码器](#1.2 交叉编码器 vs. 双编码器)
[📊 详细对比分析](#📊 详细对比分析)
[🔬 技术原理详解](#🔬 技术原理详解)
[🏭 生产环境最佳实践:两阶段检索策略](#🏭 生产环境最佳实践:两阶段检索策略)
[二、openJiuwen 重排模块设计](#二、openJiuwen 重排模块设计)
[2.1 架构设计](#2.1 架构设计)
[🏗️ 架构图详解](#🏗️ 架构图详解)
[🎯 设计原则](#🎯 设计原则)
[2.2 核心类说明](#2.2 核心类说明)
[Reranker 抽象基类](#Reranker 抽象基类)
[三、StandardReranker 实现](#三、StandardReranker 实现)
[3.1 功能特点](#3.1 功能特点)
[✅ 支持的特性](#✅ 支持的特性)
[3.2 使用示例](#3.2 使用示例)
[📝 控制台输出结果如图:](#📝 控制台输出结果如图:)
[🔍 结果分析](#🔍 结果分析)
[⚠️ 常见问题排查](#⚠️ 常见问题排查)
[3.3 API 请求格式](#3.3 API 请求格式)
[4.1 错误处理与重试](#4.1 错误处理与重试)
[4.2 配置管理](#4.2 配置管理)
[5.1 设计原则](#5.1 设计原则)
[5.2 适用场景](#5.2 适用场景)
[5.3 局限性说明](#5.3 局限性说明)
一、重排技术概述
1.1 为什么需要重排?
在现代信息检索系统中,向量检索(基于Embedding相似度)已成为主流方法。然而,这种方法存在一些固有局限,需要通过重排技术来解决。
🔍 问题一:语义鸿沟(Semantic Gap)
问题描述: 向量检索的核心是计算查询和文档的Embedding向量之间的相似度(如余弦相似度)。但这种相似度分数无法完全反映文档与查询的深度语义关联。
具体表现:
-
查询:"如何提高机器学习模型的准确率"
-
文档A:"深度学习模型优化技巧:学习率调整、正则化方法"
-
文档B:"机器学习算法简介"
虽然文档A更相关,但由于词汇重叠较少,向量相似度可能反而低于文档B。
技术原因:
-
向量压缩损失:将高维语义信息压缩到低维向量(如768维)时,不可避免地丢失部分语义细节
-
独立编码限制:双编码器分别对查询和文档进行编码,无法捕捉两者之间的细粒度交互
-
相似度度量简化:简单的余弦相似度或点积无法充分表达复杂的语义关系
重排解决方案: 交叉编码器将查询和文档同时输入模型,进行联合编码和深度交互,能够捕捉更丰富的语义关联。
🔍 问题二:词汇不匹配(Vocabulary Mismatch)
问题描述: 用户查询和文档可能使用不同的词汇表达相同的语义,导致向量检索无法正确识别相关性。
具体案例:
|----------|---------------|-----------------------------|
| 查询 | 相关文档 | 词汇不匹配问题 |
| "AI如何学习" | "机器学习算法的训练过程" | "AI" vs "机器学习","学习" vs "训练" |
| "汽车保养" | "车辆维护指南" | "汽车" vs "车辆","保养" vs "维护" |
| "减肥方法" | "瘦身技巧大全" | "减肥" vs "瘦身","方法" vs "技巧" |
技术原因:
-
同义词问题:不同词汇表达相同概念
-
上下位词问题:查询使用上位词,文档使用下位词(或反之)
-
表达方式差异:口语化查询 vs 书面化文档
重排解决方案: 交叉编码器通过深度语义理解,能够识别词汇背后的概念,而非简单的词汇匹配。
🔍 问题三:多维度相关性(Multi-dimensional Relevance)
问题描述: 相关性不仅关乎语义相似度,还涉及多个维度,如时效性、权威性、完整性等。单纯的向量相似度无法综合考虑这些因素。
相关性维度分析:
|-------|-------------|----------------------------|
| 维度 | 说明 | 示例 |
| 语义相关性 | 内容是否与查询主题相关 | 查询"Python教程",文档应关于Python编程 |
| 时效性 | 信息是否最新 | 技术文档、新闻资讯等对时效性要求高 |
| 权威性 | 信息来源是否可靠 | 医疗、法律等领域对权威性要求高 |
| 完整性 | 信息是否全面 | 教程类查询需要完整的步骤说明 |
| 可读性 | 信息是否易于理解 | 入门级查询需要通俗易懂的内容 |
重排解决方案: 重排阶段可以引入额外的特征(如文档元数据、用户偏好等),进行多维度综合评分。
1.2 交叉编码器 vs. 双编码器
理解交叉编码器和双编码器的区别,是掌握重排技术的关键。
📊 详细对比分析
|------|------------------|----------------------|
| 特性 | 双编码器(Bi-Encoder) | 交叉编码器(Cross-Encoder) |
| 编码方式 | 分别编码查询和文档 | 联合编码查询和文档 |
| 计算方式 | 计算向量相似度(余弦/点积) | 直接输出相关性分数 |
| 准确性 | 较低(约70-80%) | 较高(约85-95%) |
| 速度 | 快(可预先编码,毫秒级) | 慢(需实时计算,秒级) |
| 适用场景 | 大规模检索第一阶段 | 小规模精排阶段 |
| 内存占用 | 低(只需存储向量) | 高(需加载完整模型) |
| 交互能力 | 无法捕捉细粒度交互 | 能捕捉深度语义交互 |
🔬 技术原理详解
双编码器工作流程:
bash
查询 → [Encoder] → 查询向量 (768维)
↓
余弦相似度
↓
文档 → [Encoder] → 文档向量 (768维)交叉编码器工作流程:
bash
[CLS] 查询 [SEP] 文档 [SEP] → [Encoder] → 相关性分数 (0-1)关键区别:
-
交互层次:双编码器在向量层面交互,交叉编码器在Token层面交互
-
注意力机制:交叉编码器允许查询和文档的Token之间进行全注意力交互
-
信息保留:交叉编码器保留了完整的上下文信息
🏭 生产环境最佳实践:两阶段检索策略
在实际生产环境中,我们采用两阶段检索策略,充分发挥两种编码器的优势:
第一阶段:双编码器快速检索
-
目标:从百万级文档中快速召回候选集
-
方法:向量相似度检索(如FAISS、Milvus)
-
输出:Top-100候选文档
-
延迟:<100ms
第二阶段:交叉编码器精排
-
目标:对候选集进行精确重排
-
方法:交叉编码器计算相关性分数
-
输出:Top-10最终结果
-
延迟:100-500ms(取决于候选数量)
性能对比:
|--------|-----|-------|----|
| 方案 | 准确率 | 延迟 | 成本 |
| 仅双编码器 | 75% | 50ms | 低 |
| 仅交叉编码器 | 92% | 10s+ | 极高 |
| 两阶段策略 | 90% | 300ms | 中等 |
二、openJiuwen 重排模块设计
2.1 架构设计
openJiuwen 的重排模块采用 统一的抽象接口 + 多实现 架构,遵循"依赖倒置原则"和"开闭原则"。
🏗️ 架构图详解
bash
┌─────────────────────────────────────────┐
│ Reranker (抽象基类) │
├─────────────────────────────────────────┤
│ + rerank() 异步方法 │
│ + rerank_sync() 同步方法 │
│ # _parse_response() 响应解析 │
│ # _build_request() 请求构建 │
└─────────────────────────────────────────┘
▲ ▲
│ │
┌─────────┴─────────┐ ┌───────┴────────┐
│ StandardReranker │ │ ChatReranker │
│ (标准重排API) │ │ (基于logprobs) │
├──────────────────┤ ├────────────────┤
│ - 调用/rerank端点 │ │ - 使用聊天API │
│ - 支持批量处理 │ │ - 计算logprobs │
│ - vLLM兼容 │ │ - 单文档处理 │
└──────────────────┘ └────────────────┘🎯 设计原则
-
统一接口:所有重排器实现相同的接口,便于切换和扩展
-
异步优先:默认提供异步接口,支持高并发场景
-
配置驱动:通过配置对象管理参数,便于管理和测试
-
错误隔离:不同实现的错误处理逻辑相互独立
2.2 核心类说明
Reranker 抽象基类
python
class Reranker(ABC):
"""重排器抽象基类
所有重排器实现都必须继承此类,并实现rerank和rerank_sync方法。
这个基类定义了重排器的标准接口,确保所有实现都能无缝切换。
"""
@abstractmethod
async def rerank(
self,
query: str,
doc: list[str | Document],
instruct: bool | str = True,
**kwargs
) -> dict[str, float]:
"""
重排序文档并返回文档到相关性得分的映射(异步版本)
参数:
query: 查询字符串,用户的实际查询
doc: 待重排的文档列表,可以是字符串或Document对象
instruct: 是否提供指令给重排器,传入字符串可自定义指令
- True: 使用默认指令
- False: 不使用指令
- str: 使用自定义指令
**kwargs: 额外参数,具体实现可以自定义
返回:
dict[str, float],文档ID到相关性得分的映射
- 键:文档ID(如果是Document对象则使用id_,否则使用字符串本身)
- 值:相关性得分,范围通常在[0, 1]之间,越高表示越相关
异常:
RerankerError: 重排过程中发生错误
TimeoutError: 请求超时
ValueError: 参数错误
"""
pass
@abstractmethod
def rerank_sync(
self,
query: str,
doc: list[str | Document],
instruct: bool | str = True,
**kwargs
) -> dict[str, float]:
"""
重排序文档并返回文档到相关性得分的映射(同步版本)
参数:
query: 查询字符串,用户的实际查询
doc: 待重排的文档列表,可以是字符串或Document对象
instruct: 是否提供指令给重排器,传入字符串可自定义指令
- True: 使用默认指令
- False: 不使用指令
- str: 使用自定义指令
**kwargs: 额外参数,具体实现可以自定义
返回:
dict[str, float],文档ID到相关性得分的映射
- 键:文档ID(如果是Document对象则使用id_,否则使用字符串本身)
- 值:相关性得分,范围通常在[0, 1]之间,越高表示越相关
异常:
RerankerError: 重排过程中发生错误
TimeoutError: 请求超时
ValueError: 参数错误
注意:
同步版本通常用于不支持异步的环境,或者需要阻塞等待结果的场景。
在异步环境中,推荐使用rerank方法以获得更好的性能。
"""
pass关键特性说明
|----------|-------------------|------------------|
| 特性 | 说明 | 使用场景 |
| 统一接口 | 所有重排器实现相同的方法签名 | 便于在运行时切换不同实现 |
| 异步/同步双接口 | 同时提供异步和同步方法 | 异步用于高并发,同步用于简单场景 |
| 指令支持 | instruct参数支持自定义指令 | 针对不同领域优化重排效果 |
| 类型提示 | 完整的类型注解 | 提高代码可读性和IDE支持 |
三、StandardReranker 实现
3.1 功能特点
StandardReranker 是标准重排器实现,支持调用任何符合 vLLM 规范的外部重排服务。
✅ 支持的特性
|-------------|----------------|----------------|
| 特性 | 说明 | 版本要求 |
| vLLM 兼容 API | 支持 /rerank 端点 | vLLM >= 0.3.0 |
| 自定义指令 | instruct 参数 | 全版本 |
| 异步/同步调用 | 双接口支持 | 全版本 |
| 自动重试机制 | 网络错误自动重试 | 全版本 |
| 灵活配置 | RerankerConfig | 全版本 |
| 批量处理 | 一次处理多个文档 | 全版本 |
3.2 使用示例
📖 完整操作指南:以下是从零开始使用 StandardReranker 的完整步骤
前置条件准备
步骤1:检查Python环境
bash
# 检查Python版本(建议3.8+)
python --version
步骤2:安装openJiuwen
bash
# 安装openJiuwen
pip install openjiuwen
# 验证安装
python -c "import openjiuwen; print(openjiuwen.__version__)"
安装过程中遇到如下报错:
bash
[notice] A new release of pip is available:23.3.2-> 26.0.1
[notice] To update, run: pip install --upgrade pip继续执行
bash
pip install --upgrade pip
再次执行如下命令:
bash
# 安装openJiuwen
pip install openjiuwen
# 验证安装
python -c "import openjiuwen; print(openjiuwen.__version__)"成功安装openjiuwen V0.1.7,结果如图:
步骤3:启动vLLM重排服务
安装vLLM
bash
pip install vllm
成功安装vllm v0.16.0,结果如图:
启动vLLM重排服务:
bash
vllm serve BAAI/bge-reranker-base \
--dtype half \
--port 8000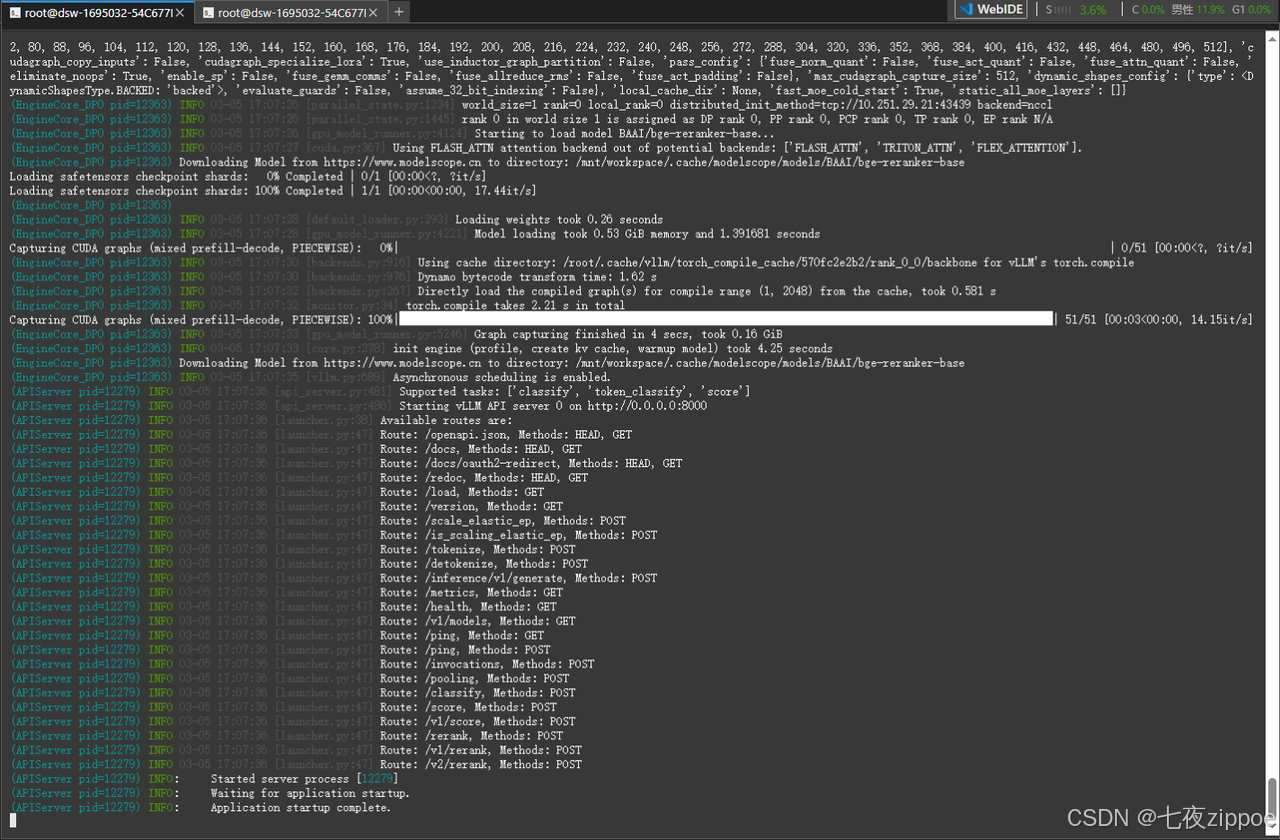
步骤4:验证服务状态
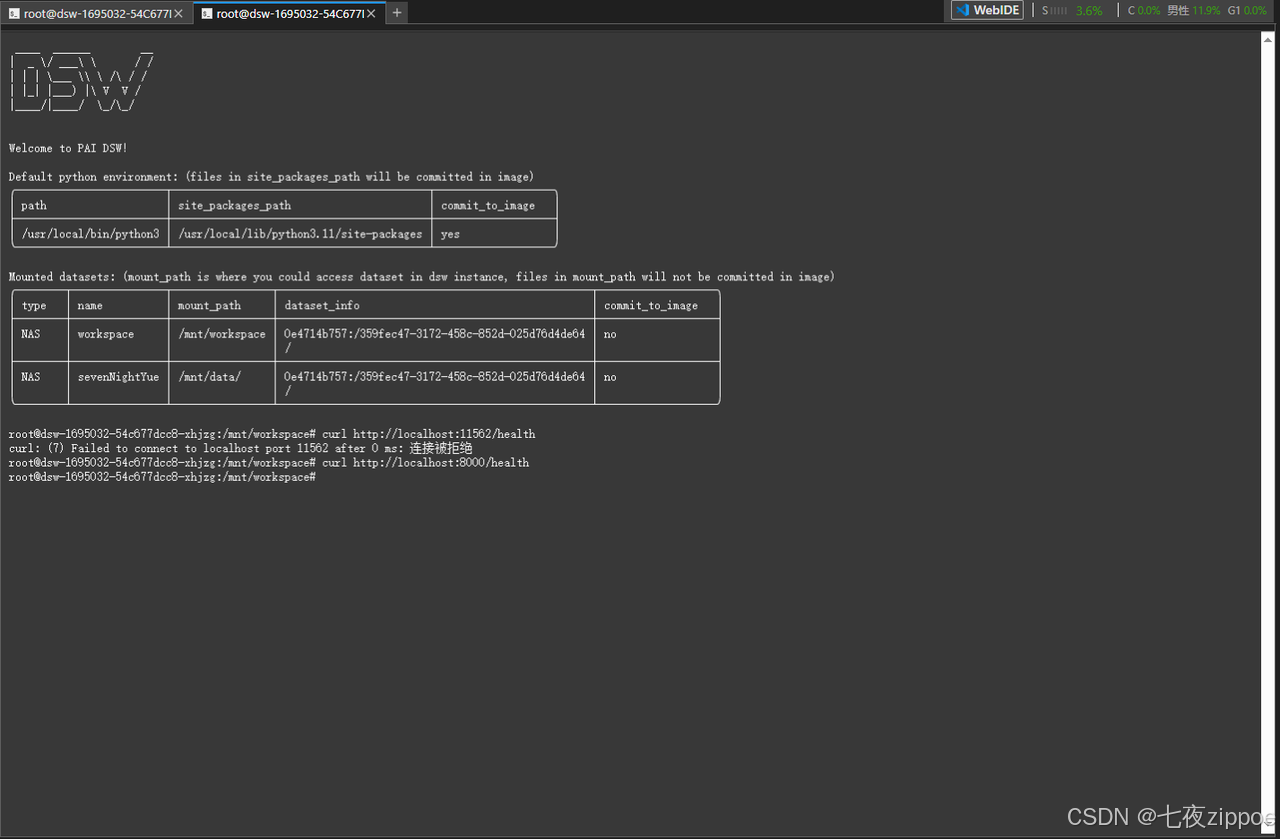
bash
# 健康检查
curl http://localhost:8000/health验证服务成功,结果如图:
完整使用示例
python
"""
StandardReranker 完整使用示例
演示从配置到结果分析的完整流程
"""
import asyncio
from openjiuwen.core.retrieval import StandardReranker
from openjiuwen.core.retrieval.common.config import RerankerConfig
# ============================================
# 步骤1:创建配置
# ============================================
print("=" * 60)
print("[步骤1] 正在创建配置...")
print("=" * 60)
config = RerankerConfig(
model="bge-reranker-base", # 支持任意重排模型
api_base="http://localhost:8000", # vLLM服务地址
api_key="", # 本地服务无需API密钥
timeout=30 # 请求超时时间(秒)
)
print(f"✓ 配置创建成功!")
print(f" - 模型: {config.model_name}")
print(f" - API地址: {config.api_base}")
print(f" - 超时时间: {config.timeout}秒")
# ============================================
# 步骤2:创建重排器
# ============================================
print("\n" + "=" * 60)
print("[步骤2] 正在创建重排器...")
print("=" * 60)
reranker = StandardReranker(config)
print("✓ StandardReranker 创建成功!")
# ============================================
# 步骤3:准备查询和文档
# ============================================
print("\n" + "=" * 60)
print("[步骤3] 准备查询和文档...")
print("=" * 60)
query = "如何学习机器学习"
documents = [
"机器学习是人工智能的一个分支,通过数据和算法让计算机自动学习",
"深度学习是机器学习的子领域,使用神经网络进行学习",
"今天天气真好,阳光明媚,适合出去散步"
]
print(f"查询: {query}")
print(f"\n待重排文档:")
for i, doc in enumerate(documents, 1):
print(f" {i}. {doc}")
# ============================================
# 步骤4:执行重排(异步方式)
# ============================================
print("\n" + "=" * 60)
print("[步骤4] 执行重排(异步)...")
print("=" * 60)
async def run_rerank():
print("正在调用重排API...")
result = await reranker.rerank(query, documents, instruct=True)
print("✓ 重排完成!")
return result
result = asyncio.run(run_rerank())
# ============================================
# 步骤5:查看和分析结果
# ============================================
print("\n" + "=" * 60)
print("[步骤5] 重排结果分析")
print("=" * 60)
# 按分数排序
sorted_docs = sorted(result.items(), key=lambda x: x[1], reverse=True)
for rank, (doc, score) in enumerate(sorted_docs, 1):
print(f"\n排名 {rank}:")
print(f" 文档: {doc}")
print(f" 相关性分数: {score:.4f}")
# 可视化分数
bar_length = int(score * 20)
bar = "█" * bar_length + "░" * (20 - bar_length)
print(f" 可视化: [{bar}] {score*100:.1f}%")
# 评价
if score >= 0.8:
print(f" 📊 评价: 高度相关 ✓")
elif score >= 0.5:
print(f" 📊 评价: 中等相关")
else:
print(f" 📊 评价: 不相关 ✗")
print("\n" + "=" * 60)
print("✓ 示例完成!")
print("=" * 60)
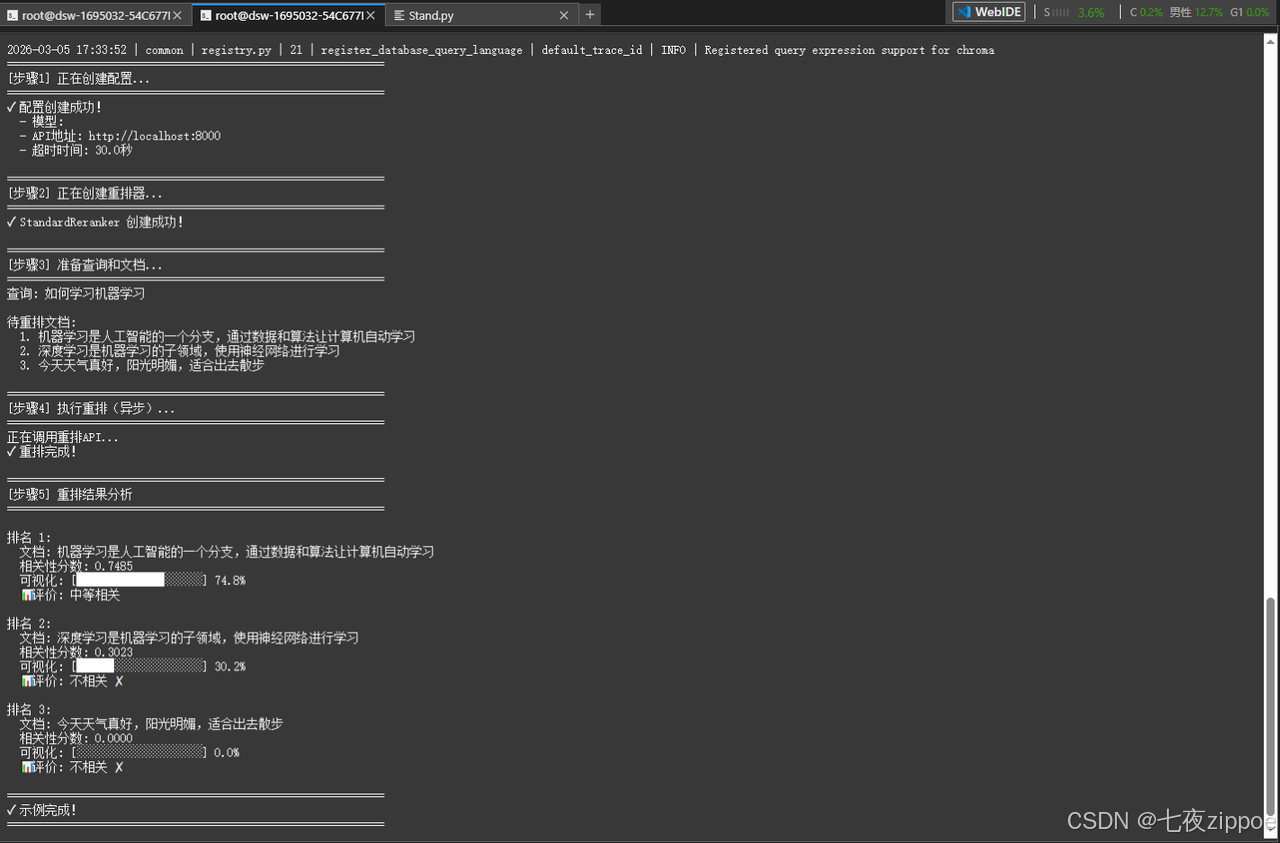
📝 控制台输出结果如图:
🔍 结果分析
Top-1 结果分析:
-
文档"机器学习是人工智能的一个分支..."获得最高分(0.74)
-
该文档直接回答了"如何学习机器学习"的问题
-
包含了"机器学习"的核心概念定义
Top-2 结果分析:
-
文档"深度学习是机器学习的子领域..."获得次高分(0.30)
-
与查询相关,但更侧重于深度学习而非机器学习基础
-
适合作为补充阅读材料
不相关文档分析:
-
文档"今天天气真好..."获得极低分(0.00)
-
与查询完全无关,被正确识别
-
证明了重排器的语义理解能力
⚠️ 常见问题排查
|-------|-----------|---------------------|
| 问题 | 可能原因 | 解决方案 |
| 连接超时 | vLLM服务未启动 | 检查服务是否运行在指定端口 |
| 404错误 | API端点不正确 | 确认vLLM版本支持/rerank端点 |
| 模型不匹配 | 模型名称错误 | 确认vLLM加载的模型名称 |
| 分数全为0 | 请求格式错误 | 检查documents格式是否正确 |
| 内存不足 | 文档过长 | 减少文档长度或分批处理 |
3.3 API 请求格式
StandardReranker 按照 vLLM 规范构建请求,了解请求格式有助于调试和优化。
请求格式详解
python
{
"model": "bge-reranker-base",
"query": "<Instruct>: Given a search query, retrieve relevant documents that answer the query.\n<Query>: 如何学习机器学习",
"documents": [
"机器学习是人工智能的一个分支",
"深度学习是机器学习的子领域"
],
"top_n": 2,
"return_documents": false
}字段说明
|------------------|---------|-------------|------|
| 字段 | 类型 | 说明 | 是否必需 |
| model | string | 模型名称 | 是 |
| query | string | 查询字符串(包含指令) | 是 |
| documents | array | 待重排的文档列表 | 是 |
| top_n | integer | 返回的文档数量 | 否 |
| return_documents | boolean | 是否返回文档内容 | 否 |
指令格式说明
当 instruct=True 时,查询会被自动包装:
python
<Instruct>: Given a search query, retrieve relevant documents that answer the query.
<Query>: [原始查询]自定义指令示例:
python
# 使用自定义指令
result = await reranker.rerank(
query,
documents,
instruct="这段文档是否与机器学习学习相关?"
)
# 实际发送的查询:
# <Instruct>: 这段文档是否与机器学习学习相关?
# <Query>: 如何学习机器学习四、生产级特性
4.1 错误处理与重试
重试机制详解
python
"""
生产级重试配置示例
"""from openjiuwen.core.retrieval import StandardReranker
from openjiuwen.core.retrieval.common.config import RerankerConfig
config = RerankerConfig(
model="bge-reranker-base",
api_base="http://localhost:8000",
timeout=30
)
# 创建重排器时配置重试参数
reranker = StandardReranker(
config,
max_retries=3, # 最大重试次数
retry_wait=0.1, # 重试等待时间(秒)
extra_headers={ # 自定义请求头
"X-Custom": "value"
}
)错误处理策略
|-----|-----------------------|----------|------|
| 错误码 | 错误类型 | 处理策略 | 重试次数 |
| 429 | Too Many Requests | 等待后重试 | 3次 |
| 500 | Internal Server Error | 立即重试 | 3次 |
| 503 | Service Unavailable | 等待后重试 | 3次 |
| 400 | Bad Request | 记录日志,不重试 | 0次 |
| 401 | Unauthorized | 记录日志,不重试 | 0次 |
4.2 配置管理
完整配置示例
python
from openjiuwen.core.retrieval.common.config import RerankerConfig
# StandardReranker 配置
standard_config = RerankerConfig(
model="bge-reranker-base",
api_base="http://localhost:8000",
api_key="",
timeout=30,
extra_body={ # 自定义请求体参数
"custom_param": "value"
}
)配置参数说明
|---------------|-------|------|-------------------------------|
| 参数 | 类型 | 默认值 | 说明 |
| model | str | 必填 | 模型名称 |
| api_base | str | 必填 | API服务地址 |
| api_key | str | "" | API密钥 |
| timeout | int | 30 | 请求超时时间(秒) |
| temperature | float | 0.95 | 温度参数(ChatReranker) |
| top_p | float | 0.1 | top-p采样参数(ChatReranker) |
| yes_no_ids | tuple | None | yes/no的token ID(ChatReranker) |
| extra_body | dict | None | 自定义请求体参数 |
| extra_headers | dict | None | 自定义请求头 |
五、总结
5.1 设计原则
-
统一接口:通过抽象基类定义标准接口,便于扩展和切换
-
灵活扩展:支持多种重排实现,满足不同场景需求
-
生产可用:提供错误处理、重试、日志等生产级特性
-
解耦设计:重排服务与SDK分离,支持任意部署方式
5.2 适用场景
|---------|-------------------------|----------------|
| 场景 | 推荐方案 | 说明 |
| RAG系统 | StandardReranker | 在检索增强生成流程中集成重排 |
| 知识库检索 | StandardReranker | 提升知识库搜索的准确性 |
| 多阶段检索 | StandardReranker + 双编码器 | 实现两阶段检索策略 |
| 无专用重排服务 | ChatReranker | 利用现有聊天模型API |
5.3 局限性说明
-
不包含模型推理:openJiuwen SDK 是客户端,需要外部重排服务
-
vLLM兼容性:仅支持vLLM规范的API,不包含vLLM特定优化技术
-
性能依赖:实际性能取决于外部重排服务的部署配置
-
ChatReranker成本:每个文档一次API调用,成本可能较高
参考资源
-
openJiuwen 官网 :https://openJiuwen.com?utm_source=csdn
-
openJiuwen agent-core :https://atomgit.com/openJiuwen/agent-core?utm_source=csdn