不同的操作系统上运行的JVM是不一样的,都专门为不同到的操作系统开发了一个jvm。
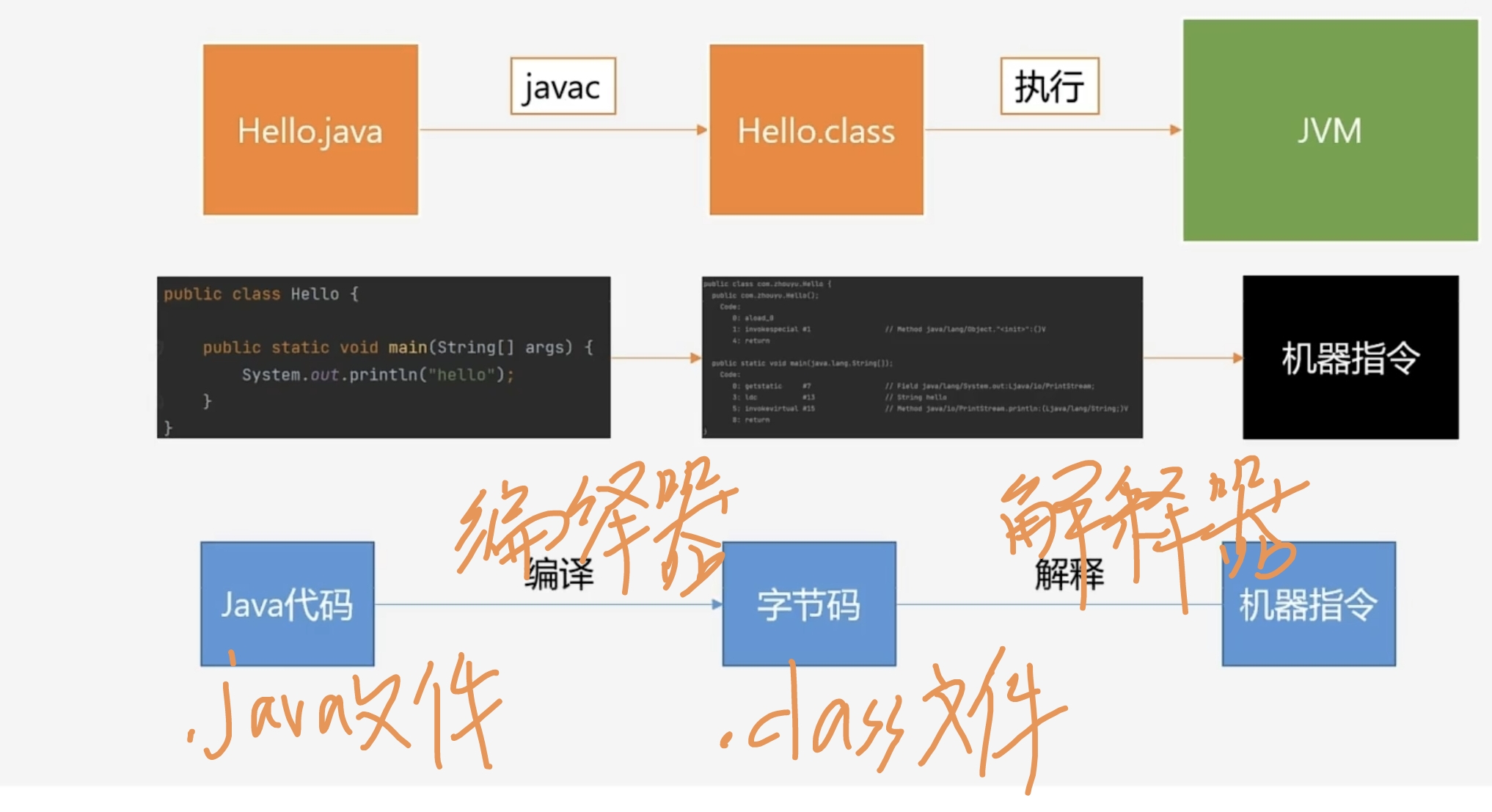
java是编译+解释合一的,如果直接用jvm解释java文件,就是解释型语言,速度会变慢,先编译好,等运行的时候就只要解释就行,速度会快很多。
JVM是建立在操作系统上的,Java虚拟机屏蔽了开发人员与操作系统的直接接触,我们在通过Java编写程序时,只需要负责编写Java代码即可,关于具体的执行则会由JVM加载字节码后翻译成机械指令交给OS执行。
在Java之前,无论是C语言还是汇编等这类的底层语言开发出的程序,在不同的环境/系统下都需要进行重新编译代码后才能执行的。而Java则反其道而行之,不再需要根据不同的环境而改变自己的代码,而是自己架构出了一个平台,开发人员编写出的代码只需要能够在自己平台上执行即可,完全屏蔽了开发者与操作系统的接触,而这个Java自身架构出的平台则被称为JVM。
JVM具有跨语言性,任何一门语言只要能够转换成JVM能识别读取的class文件,都能够被JVM接受并执行。
JDK、JRE、JVM:

虚拟机的两种架构:
虚拟机主要有两种架构模型,一种是基于栈式的,另一种则是基于寄存器式的。从性能上说,基于寄存器模型会比基于栈式的虚拟机性能更好,但是从移植性上看,栈式的虚拟机会远强于基于寄存器模型的虚拟机。
基于栈式的虚拟机(JVM):
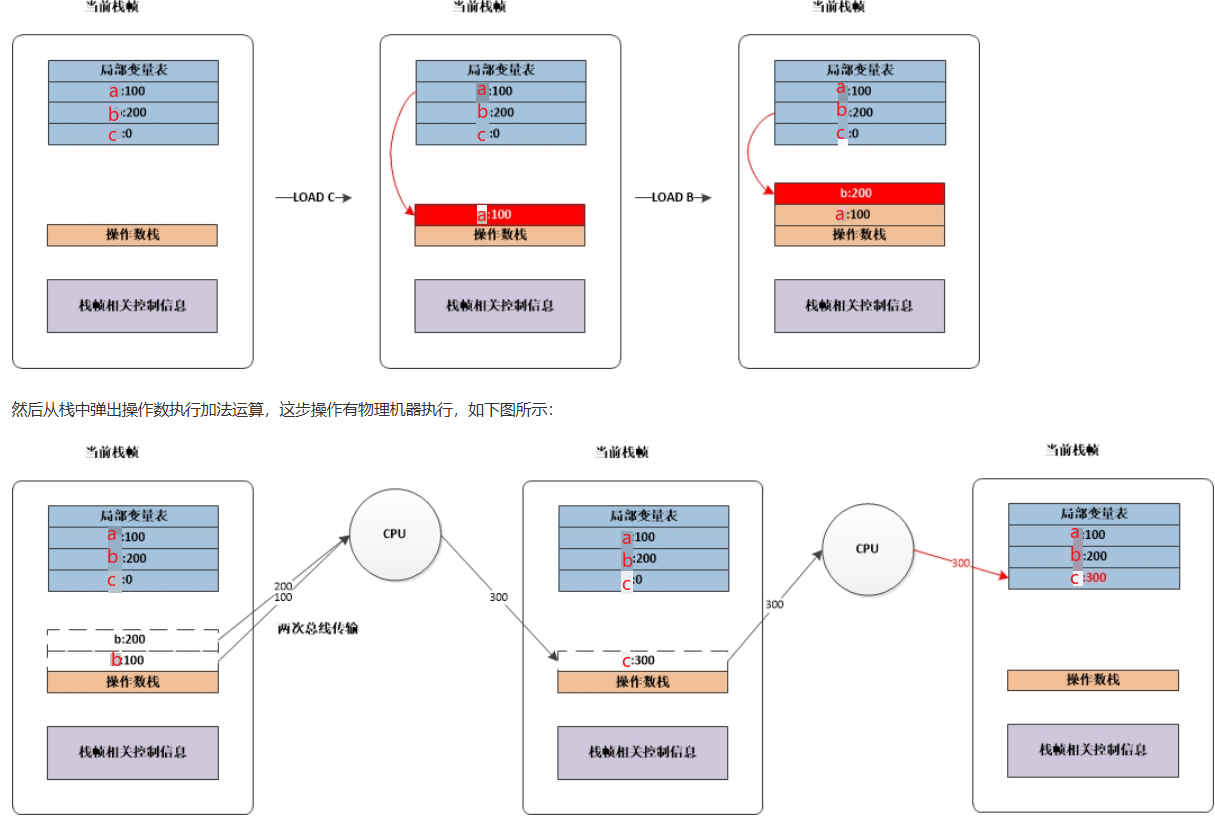
基于栈式指的是虚拟机在执行指令时,采用的方式是基于栈的指令集,会将需要执行的指令一条条的压入栈中,主要有入栈和出栈两种操作,计算结果最终存储在栈中。基于栈式的虚拟机都会存在一个操作数栈的概念,虚拟机在真正运算时,都是通过操作数栈进行操作,与内存进行交互,简单来说就是无论任何操作,都需要通过操作数栈进行。这种模型的虚拟机最大的好处在于可以无视硬件、物理架构。当然,缺点也非常明显,因为无论什么操作都要经过操作数栈,所以性能会低一些。
Java的JVM、Python的CPython、.Net的CLR等虚拟机都是基于这种栈式模型的。
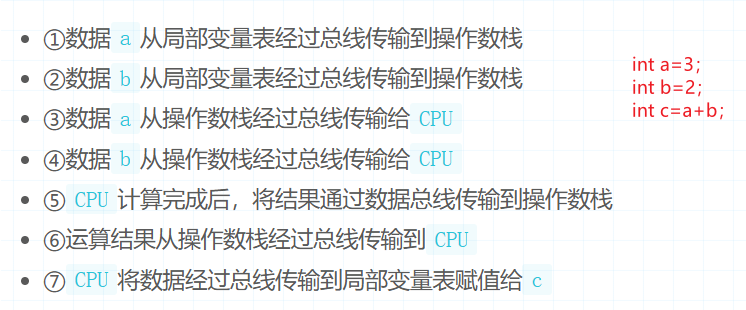
从如上步骤可以看出,一次简单的加法运算就需要经过七次总线传输,因为所有操作都要经过操作数栈的原因,所以效率方面会低许多。
基于寄存器的虚拟机:
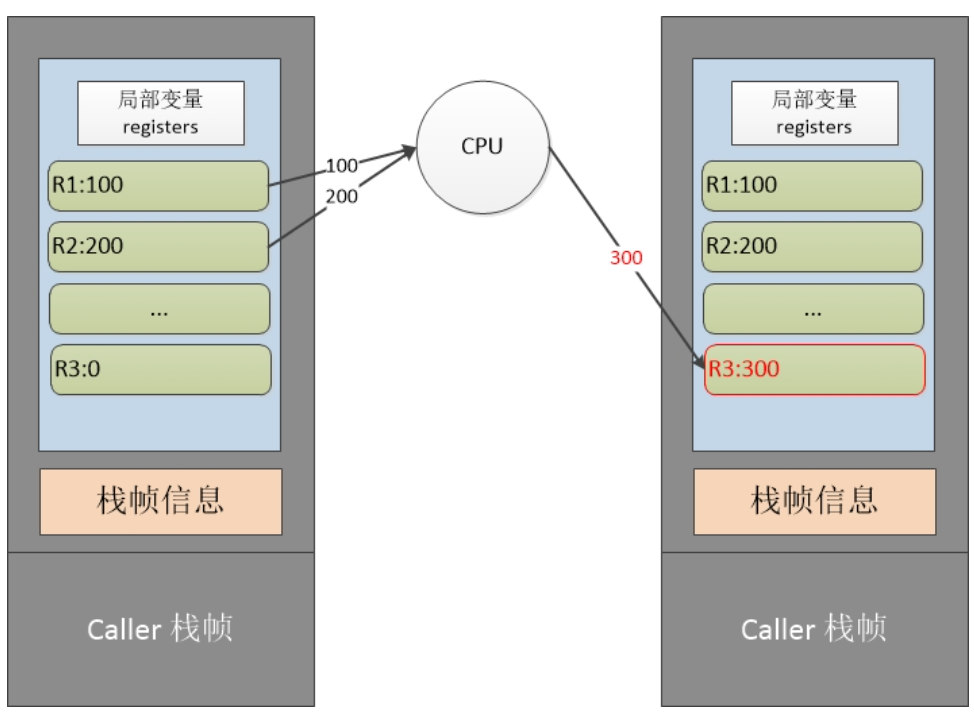
基于寄存器模型的虚拟机存在很多虚拟寄存器的概念,用于模拟CPU中真实PC寄存器,但它们往往都以别名存在,如R1、R2、R3等,在执行时,执行引擎需要对这些别名进行解析,然后找出具体操作数的位置,然后取出操作数进行操作。这些虚拟的寄存器也并不是直接在CPU中的,而是和操作数栈一样,位于运行时栈中,通过一个数组(运行时栈帧中的连续内存空间)存储所有的虚拟寄存器。
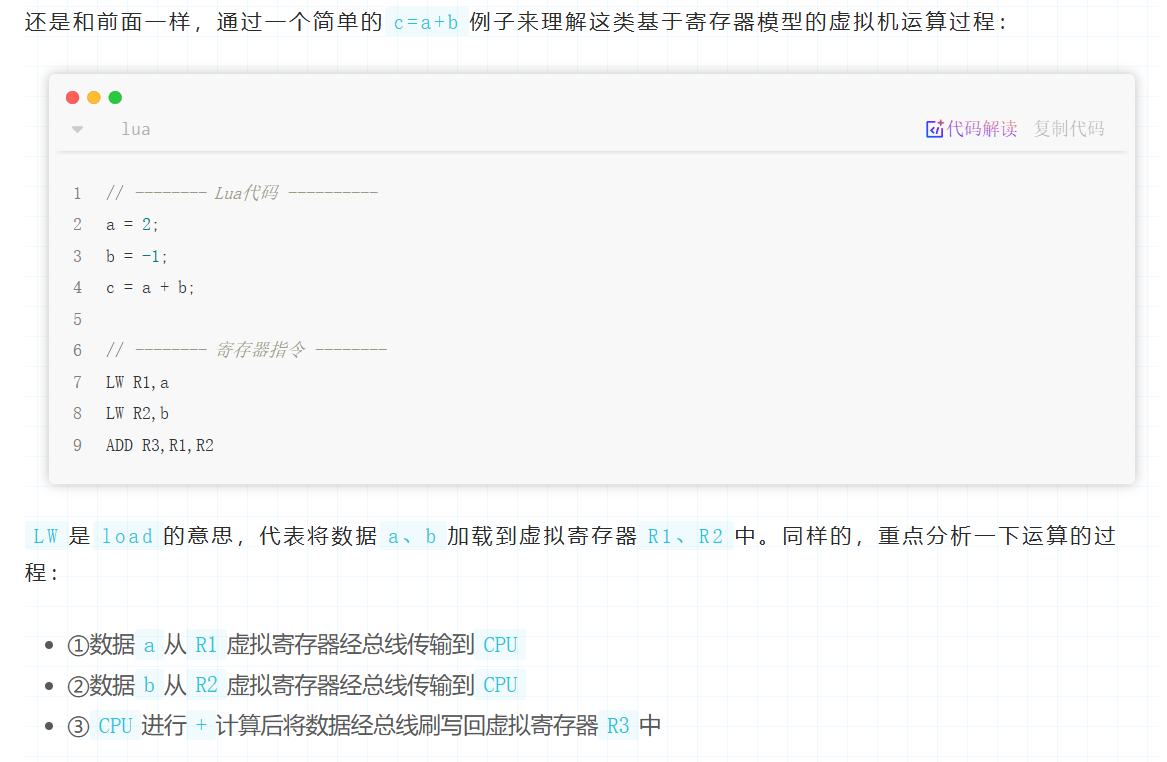


其实"寄存器"的概念只是当前栈帧中一块连续的内存区域。这些数据在运算的时候,直接送入物理CPU进行计算,无需再传送到operand stack上然后再进行运算。例如"ADD R3, R2, R1"的示意图就如下所示:


JVM的生命周期:
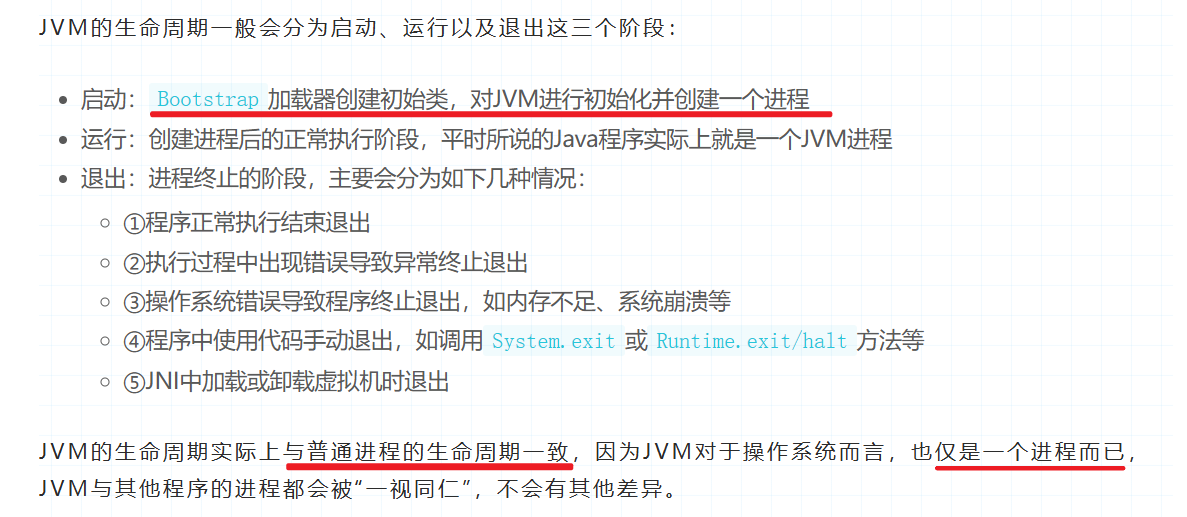
JVM在Java程序开始执行的时候,它才运行,程序结束的时它就停止。
一个Java程序会开启一个JVM进程,如果一台机器上运行三个程序,那么就会有三个运行中的JVM进程。
JVM中的线程分为两种:守护线程和普通线程
守护线程是JVM自己使用的线程,比如垃圾回收(GC)就是一个守护线程。
普通线程一般是Java程序的线程,只要JVM中有普通线程在执行,那么JVM就不会停止。
现在占绝对地位的虚拟机为HotSpot。

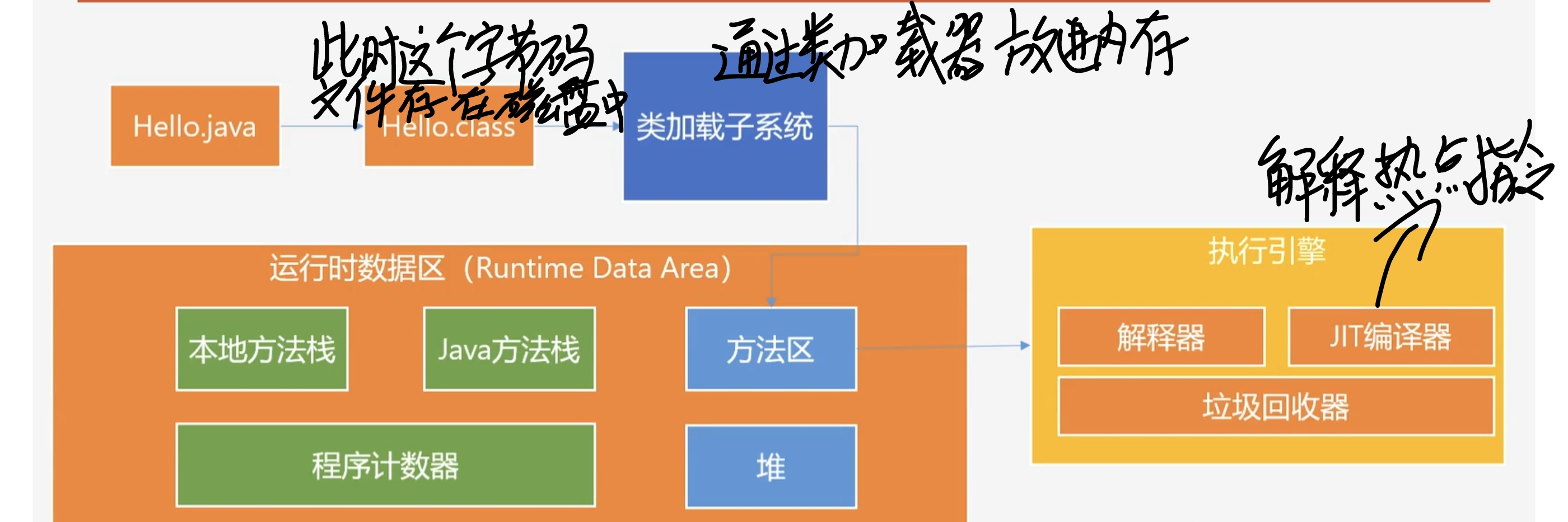
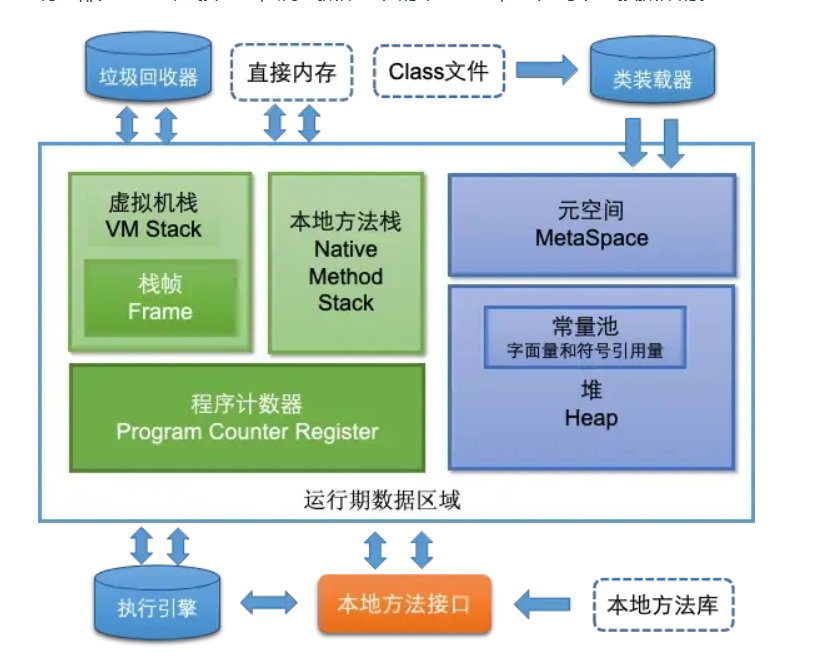
运行时数据区是在内存中的,是专门分给JVM的一块内存区域。
一个 JVM 实例对应一个进程。JVM 的运行时数据区由这个 JVM 实例管理。内存中可以有多块运行时数据区。
如果在一台机器上运行多个 JVM 实例,每个 JVM 都会独立分配运行时数据区。
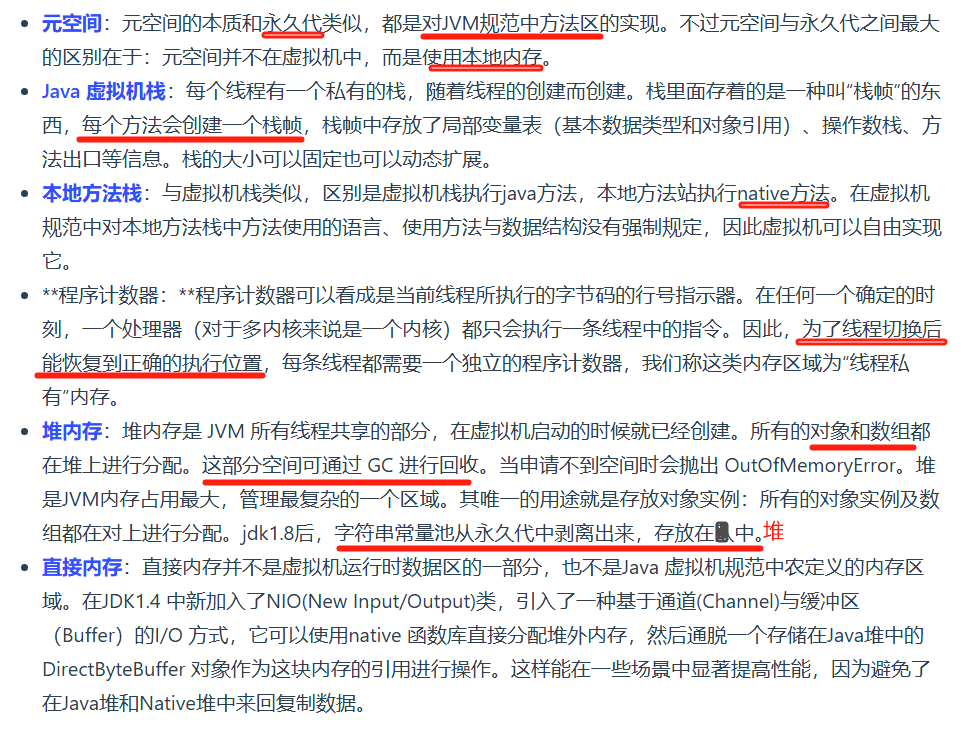
这里面的程序计数器和cpu的寄存器中的程序计数器不是同一个。jvm中的程序计数器线程私有,记录的是当前的线程的字节码指令地址是一个逻辑概念;而寄存器中的程序计数器是硬件寄存器,记录的是cpu的机器指令地址。
本地方法栈:调用native方法,不会创建栈帧,而是通过动态链接并直接调用该方法;
方法区:存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码数据。
在jdk1.8中不存在方法区,原方法区被分成两部分;1:加载的类信息,2:运行时常量池;类信息保存在元数据区,运行时常量池保存在堆。
栈占空间小,由操作系统管理
堆占空间大,由jvm管理
Java虚拟机一般是由多个模块一起组成的,主要可分为类加载子系统、执行引擎子系统、运行时数据区、垃圾回收子系统以及本地接口和本地方法库。
什么是JVM内存模型?
定义了Java程序在运行时如何管理内存,包括内存的划分、访问、线程间的可见性( 多线程环境中如何保证共享变量可见性,通过内存屏障、volatile关键字和同步机制 )和一致性等