
提要
本文是笔者5年前写的文章。部分内容可能已过时,但是总体逻辑应该是没有变的。满纸荒唐言,一把辛酸泪,都云作者痴,谁解其中味

1.概况
天下分久必合,合久必分。如果人类的整个历史算一个长河的话,服务器的历史与之对比,顶多只能算一条小溪流。当我们透过这条溪流,回看Intel、AMD、IBM、ARM等服务器的体系架构的演变和变迁,赫然发现,哪怕是那么小的一条溪流,也重复着同样分分合合的故事。太阳底下永远没有新鲜事。如果NUMA是分,UMA就是合,当Intel、AMD的历代芯片持续在NUMA和UMA间拉锯的时候,分合之间,体现了工程师对成本、性能乃至硬件对软件友好度的综合考量。
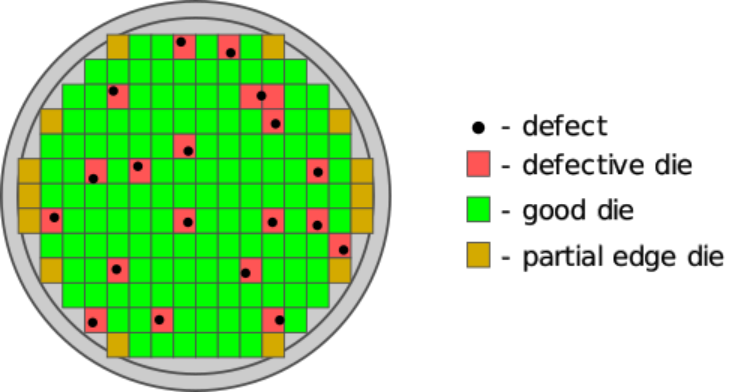
服务器芯片的设计,总是一个关于性能和成本的综合考虑,需要在天使和魔鬼之间,精准地拿捏分寸。通常来讲,把硬件资源增多(比如更多的CPU core、内存、四通八达的总线)意味着更高的性能;而把芯片的DIE做小,意味着更低的成本。因为DIE切割地越小,越意味着一个wafer有效利用的空间越大;同时也意味着,wafer里面的defect,能污染的区域占比更少,从而能提高DIE的良率。比如,整个wafer如果只划分一个DIE,有一个defect,良率就是0%。
把DIE做小,究竟可以省多少钱呢?AMD给我们算了一笔账,AMD的EPYC芯片,含有32个CPU core(64个线程),它的做法是,把每8个core做成一个DIE,让每个CPU包含4个DIE。如果直接把32个core做进一个DIE,和做成4个DIE,成本差距有多少呢?结论是造4个DIE的成本是造一个DIE的成本的59%1。
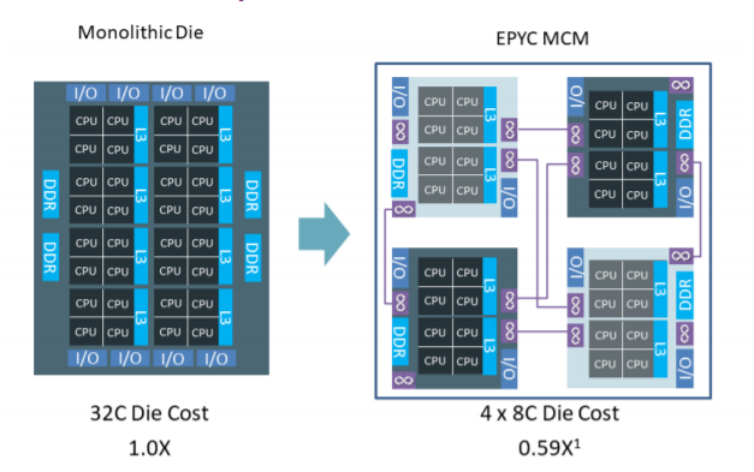
这样的拆分,固然降低了成本,但是也有它的副作用,就是每个CPU Socket里面,就有4个NUMA了,对于NUMA-aware做地比较差的软件,跨NUMA的访问会有明显的延迟增大和性能下降。EPYC的这一设计曾经为Intel所公开诟病,2017年,媒体曾广泛报道,Intel 批评AMD的EPYC是"inconsistent performance from 4 glued-together desktop dies"、"repurposed desktop products for servers"。这使得人们后来在较长的一段时间里,时常把AMD和"胶水"想到一块。(至2026 年的今日,Intel 的境况已是风云变幻,一些 Intel 的硬件驱动在社区中失去了维护者,沦为"孤儿"。这实在令人扼腕叹息。Intel是一个无比伟大的公司,它在开源社区的贡献曾经如星汉般灿烂。)
这一诟病所指向的问题,也许是真实存在的。在成本之外,硬件的设计还需要考虑减小NUMA的复杂度,从而便利Linux软件更好地发挥硬件的性能。就Intel、AMD、IBM等服务器解决方案的拓扑发展历史来看,避免在CPU规模变大的情况下导致NUMA复杂度的随同增加是一个基本的设计诉求。我们基本可以看出2大发展规律:
1.尽可能在Socket内实现一致延迟
2.尽可能在Socket之间减小NUMA直径
NUMA直径指从一个NUMA到另外一个NUMA的最远hops数。假设一个CPU里面有4个DIE,每个DIE成为一个NUMA,如果4个DIE是这么接的:
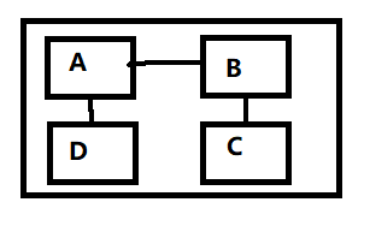
那么NUMA直径为3,因为从D到C要经过D-A(1hops)-B(2hops)-C(3hops)。
如果4个DIE是这么接的:
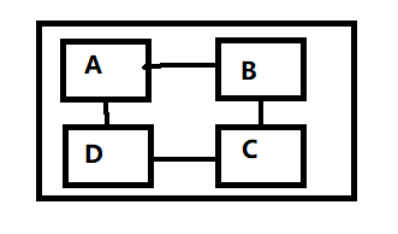
那么NUMA直径为2,因为从D到B要经过D-A(1hops)-B(2hops)。
如果4个DIE是这么接的:
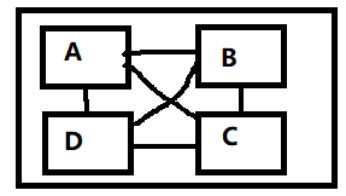
那么NUMA直径为1,因为从任何一个NUMA到另外一个NUMA都需要1hop。
2.尽可能在Socket实现一致延迟
2.1 Intel
Nehalem(2008年11月发布)、Sandy Bridge(2011年1月发布)、Haswell(2013年6月发布)、Broadwell(2014年10月发布)时代的Intel Xeon系列,基本是采用ring bus设计。对于ring这样的bus而言,如果ring上面的站点少,比如类似上海的内环,这个环本身的延迟会比较小;但是,如果站点太多了,连接太多的CPU,这个环就会很大,类似外环。你从浦东的尽头跑到浦西的尽头,这个延迟肯定是很大。所以XEON的思路是,CPU数量少的时候就一个环,再多就1.5个环,再继续多就2个环,每个环整体不大。有点类似你在浦东有个环,然后浦西有个环,至于浦东和浦西之间,通过南浦大桥和地下隧道等方式连接。
下图是发布于2016年5月的14nm Broadwell Xeon E5 V4 CPUs的架构图,图中的LCC、MCC、HCC分别代表Low Core Count(最多10个cores)、Medium Core Count(12-14个cores)和High Core Count(16个cores以上,2016年6月发布的E5-2699 v4和10月发布的E5-2699A v4、E5-2699R v4可达22个cores)。
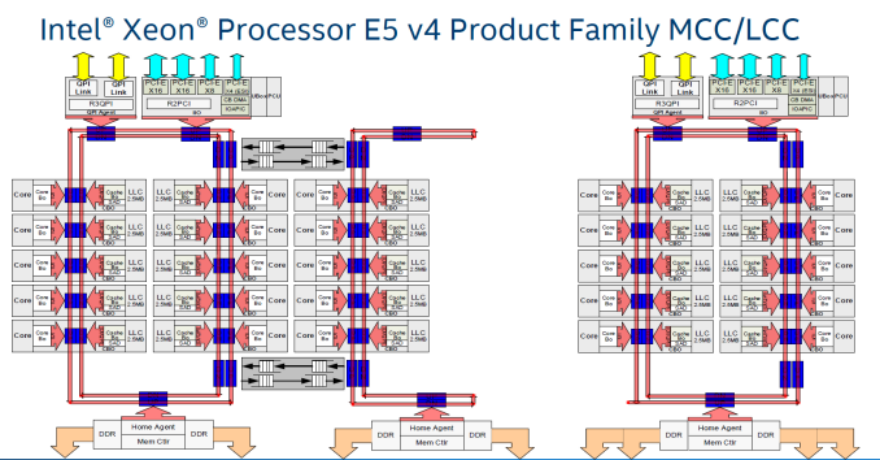
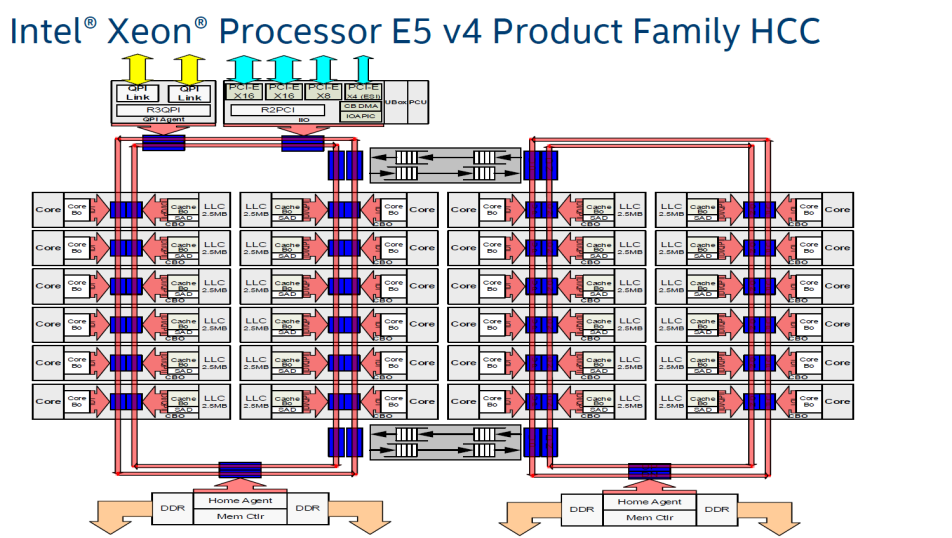
这个设计也带来一个比较大的问题,尽管浦东的人到浦东比较快,浦西的人到浦西比较快,但是浦东的人到浦西延迟会比较大,两个ring之间的通信延迟造成了基于ring的CPU的cluster-on-die(COD)问题。如果core的数量继续增加,大于24个core的时候,2个ring似乎也搞不定了。
所以,Intel Broadwell的后继者skylake server(2017年5月发布,一个DIE内可以容纳4-28个cores),全面抛弃了使用多年的ring bus,而转而构建了一个纵横互通的mesh网络:
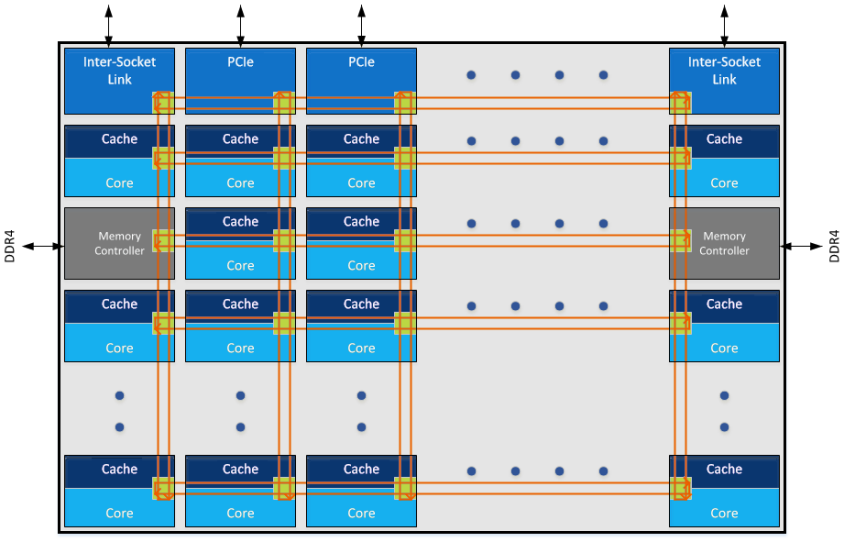
skylake server支持所谓的LCC(Low Core Count)、HCC(High Core Count)和XCC(Extreme Core Count)。
可以把skylake server采用的mesh理解为横向纵向都存在的多个半ring,这样mesh上面的每个节点,无论上下左右,交通都是通达的。
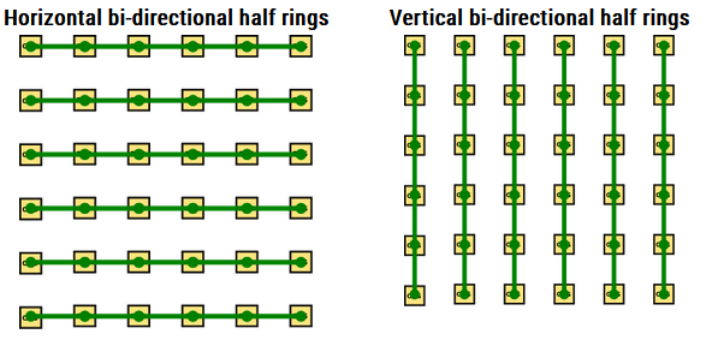
当mesh里面的节点太多,其实也无法保证报个节点访问内存的延迟是一样的,因为内存无法均匀分布,而在地理位置上呈现为一定的区域分布,一定的区域有DDR。比如在Skylake以及其下一代Cascade Lake的6*6的mesh上面,左右各有2个结点是接DDR的:
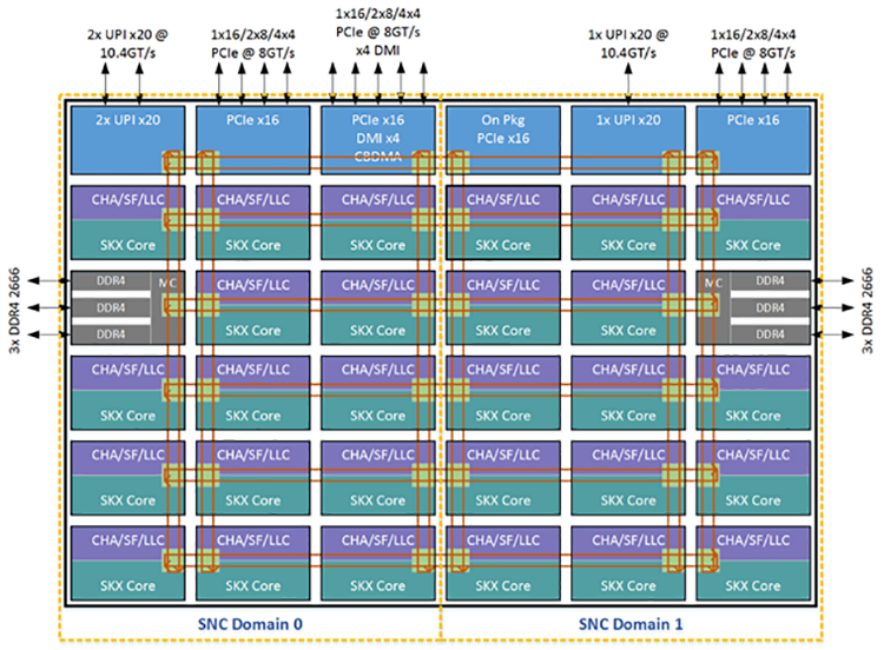
这衍生出了另外一个概念,就是sub-numa-cluster(SNC),每个SNC可以被配置为一个NUMA,取代了haswell/broadwell时代的cluster-on-die。但是,值得一提的,根据《Intel® 64 and IA-32 Architectures Optimization Reference Manual》2,开启和关闭SNC,只是轻微地影响同一个CPU内的内存访问延迟。对于一个典型的2-socket系统,关闭SNC,每个CPU一个NUMA,开启SNC,每个CPU 2个NUMA,整个系统共4个NUMA的情况下,延迟差异数据如下:
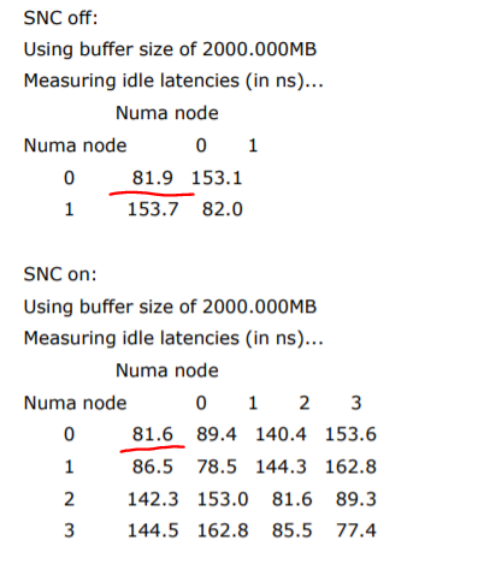
SNC off情况下,CPU访问本NUMA内存的延迟是81.9,而开启SNC的情况下,CPU内部的2个SNC访问自身内存的延迟仅仅减小0.3至81.9,所以SNC不太是Intel处理器应用场景的关键concern。
2.2 AMD
反观AMD这边厢,第一代EPYC(Naples,2017年6月发布)为了省钱,通过前述"胶水"技术把4个DIE"粘合"在一起,每个DIE可以包含8个cores(16个线程),它同时也支持2个socket的互联:
这个地方,我们发现一点,就是它的每个socket内的4个DIE,实际上是全联通的,这样意味着,Package内部的4个NUMA,彼此到达对方,只有1hop。但是抵达另外一个socket上面的DIE,显然要再增加一个hop,因此,典型的EPYC的node distance表如下,一共有8个NUMA:
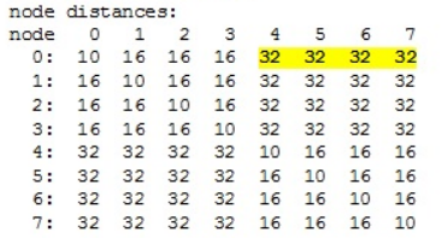
EPYC的这一设计在EPYC II(Rome,2019年8月发布)中被重大改变,第二代EPYC同样也还是想省钱,所以"胶水"这个总的路线不会变。但是,它顺带解决了第一代EPYC片内跨NUMA延迟的问题,采用一个星型设计,把内存和I/O独立出来,其他8个CPU DIE对称地访问内存、I/O DIE,从而简化了NUMA直径。每个CPU DIE上面8个核,这样每个package上面可以有64个核,128个线程。
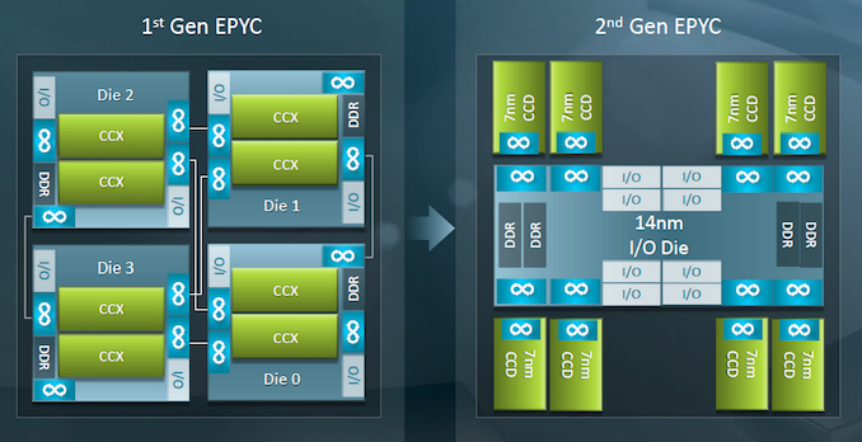
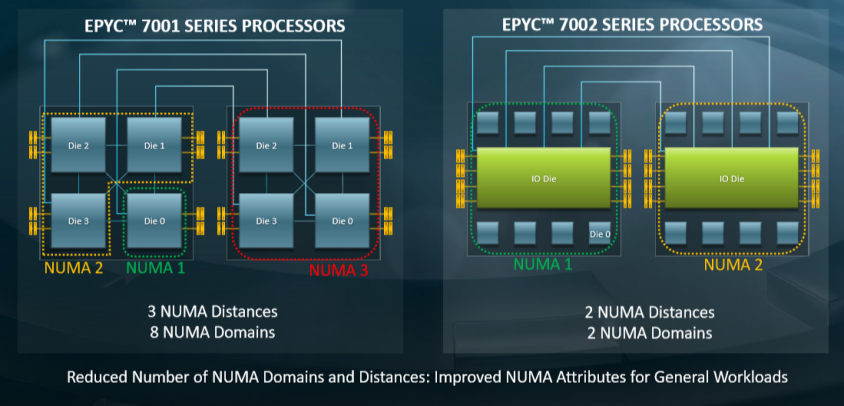
这个减小NUMA直径的改进,显然是AMD引以为豪的一个设计,所以AMD的幻灯片也不遗余力地宣传了这一点"Reduce System Diameter(NUMA domain)":

AMD宣称简化的NUMA直径(更少的NUMA hops),对许多通用的workload的性能带来了提升,无论是 single-socket还是two sockets的场景,无论是Windows Server 还是Linux。
新的EPYC 2代的node distance简单了许多:
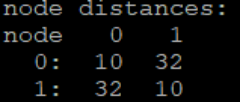
第三代EPYC(Milan)大体沿用了第二代Rome的架构,第4代EPYC(Genoa)尚未发布,但是似乎要"胶水"设计粘合很多的CPU DIE,让一个CPU上面可以支持6个CPU DIE,最大可达96个core(192个线程)。

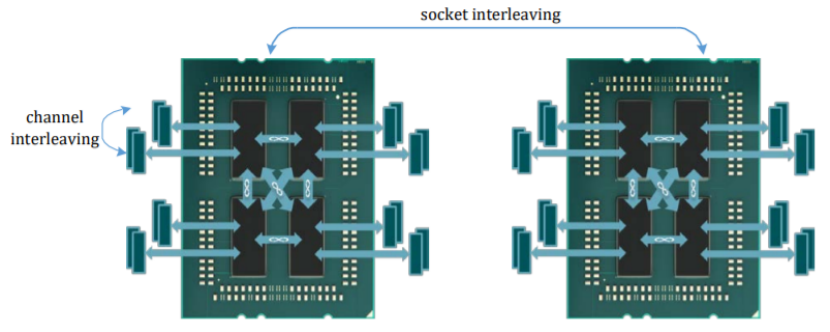
不过,与采用mesh之后的Xeon相似,把memory和I/O DIE中心话后的EPYC 2代,也有类似的延迟局部性问题。Rome实际上分成了quadrant,每个quadrant有2个CCD(Core Complex Dies),所以CCD有靠近自己的Memory controller和不靠近自己的memory controller之分。
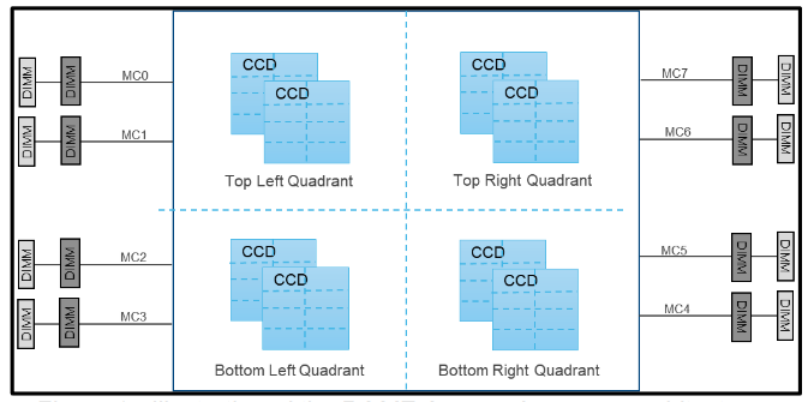
因此,Rome的BIOS实际可以配置NPS(Nodes Per Socket),可以设置为:
lNPS0: 2个socket看成1个NUMA;
lNPS1: 1个socket看成1个NUMA;
lNPS2: 1个socket看成2个NUMA;
lNPS4: 1个socket看成4个NUMA。
还有一点比较奇葩的,它还支持把共享L3的区域配置为一个NUMA,这样2-socket的系统可以有32个NUMA,相信这有助于特定的workload在CCD之间spread。
根据AMD的配置向导3建议,对于HPC场景,应用会因为pin CPU和memory而受益,因此它建议是使能NPS4。如果workload的NUMA aware不强,或者应用会因为NUMA复杂度高而降低,则建议配置为NPS1。
3.尽可能在socket之间减小NUMA直径
3.1 Intel的1-2-4-8socket系统
在多个CPU互联方面,显然历史的发展也更多地期待尽可能减小NUMA直径。比如Haswell/Broadwell时代的Xeon通常用2个QPI(Intel QuickPath Interconnect)来连接其他的CPU,因此可组如下2 socket的机器:
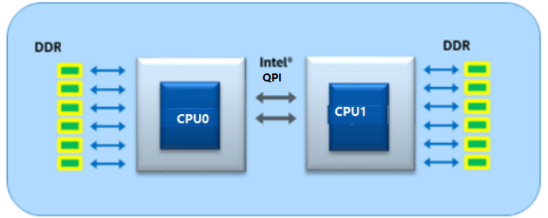
但是,组4socket的系统的时候就会组成一个ring(NUMA直径2hops):
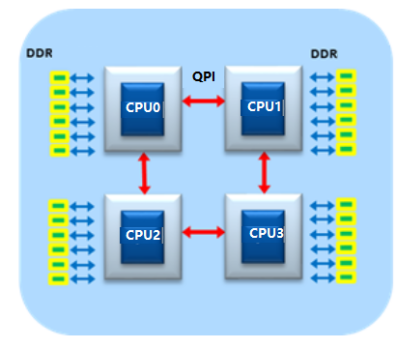
而skylake(server)通常有更多的UPI(Intel® Ultra Path Interconnect)link来连接旁边的CPU,因此组4 socket的机器的时候,可以组成一个crossbar(NUMA直径1hop)4:
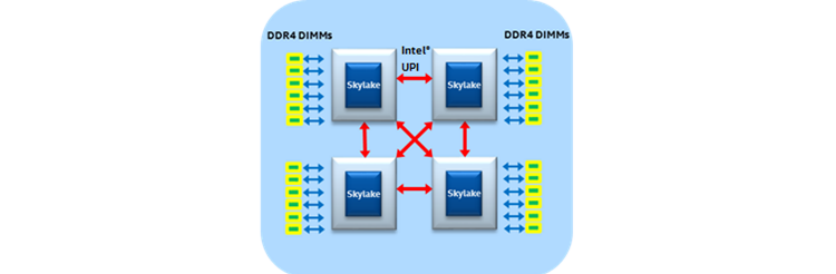
当然,有些skylake只激活了与其他CPU互联的3个UPI中的2个,4socket的情况下,就还是一个ring(NUMA直径2hops):
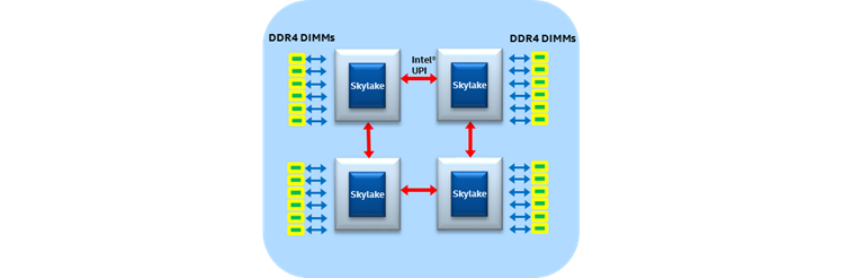
进一步地,不同于前一代处理器最多可以组成4 socket,skylake也可以组8socket(NUMA直径2hops):
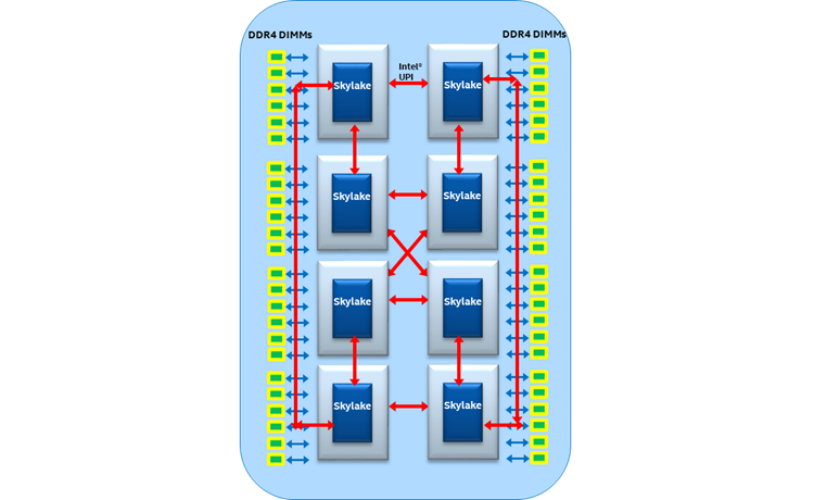
这里我们可以发现skylake及后续系列的一个显著优点,就是可以搭建1hop的4-socket系统和2-hops的8-socket系统,注意它的hops没有超过2。
当你凝视深渊的时候,深渊也在凝视着你。特别值得一提的是,一直被Intel诟病的AMD"胶水"设计,也被Intel skylake的后继者Cascade Lake的顶配Platinum 9200系列(发布于2019年4月)所采用,9282把两个28核的DIE粘合成一个56核/112线程的CPU(号称Multiple Chip Package,MCP),然后还可在2个CPU的4个DIE之间通过UPI进行全连通:
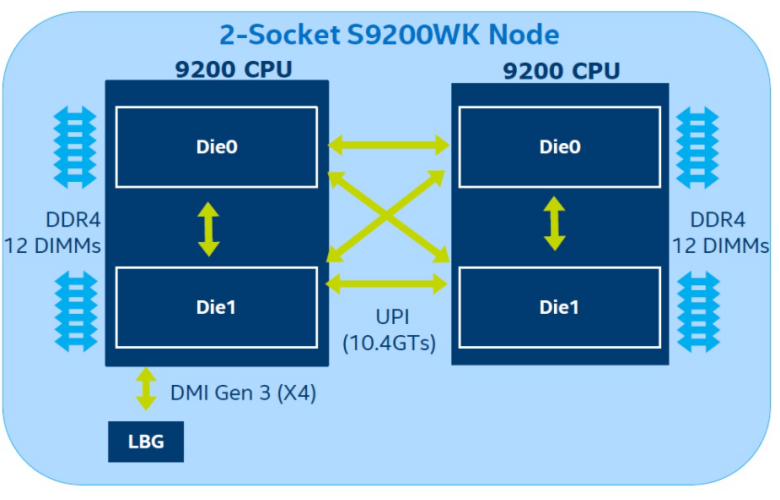
但是Intel的宣传资料特别提到一点"multi-chip processor with single hop latency from any of the CPU die to memory in a 2s node",所以跨socket的DIE和不跨Socket的DIE的延迟是一致的。但是,不可否认的是,9200的单CPU内部的2个DIE引入了NUMA问题。但是,2P的Platinum 9200仍然和1P的Platinum 9200一样,构成的是一个1hop的NUMA,可见Intel在解决延迟的一致性方面,是下了一番苦功夫的。
3.2 AMD EPYC NPS与NUMA直径
以AMD的EPYC 2代Rome为例,如果NPS=1,则2-socket的系统是一个1hop系统:

如果开启了NPS=2或者NPS=4,则成为一个类似EPYC一代时候2-socket的2hops系统:

3.3 IBM Power9 16-socket NUMA直径
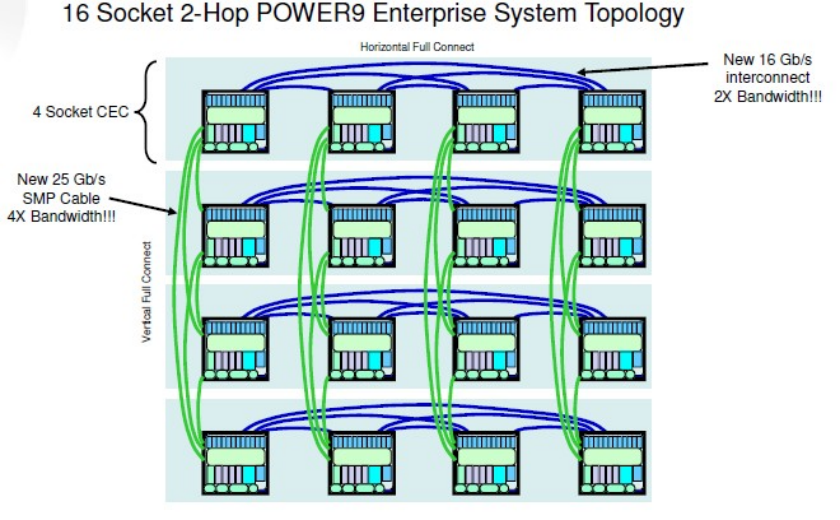
同样值得一提的是,IBM的Power9,哪怕多到16个socket,任何2个socket之间的距离也没有超过2hops:
3.4 Kunpeng920 3-hops问题
这也许解释了,为什么仅Kunpeng920出现了3hops的问题,而Linux内核调度器拓扑识别对NUMA直接大于2的支持是有问题的。笔者在2021年2月的如下commit对其进行了修复:
sched/topology: fix the issue groups don't span domain->span for NUMA diameter > 2
++https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=585b6d2723dc92++
因为Kunpeng920 2-socket的情况下,每个socket内部的DIE并没有实现相互全连接:
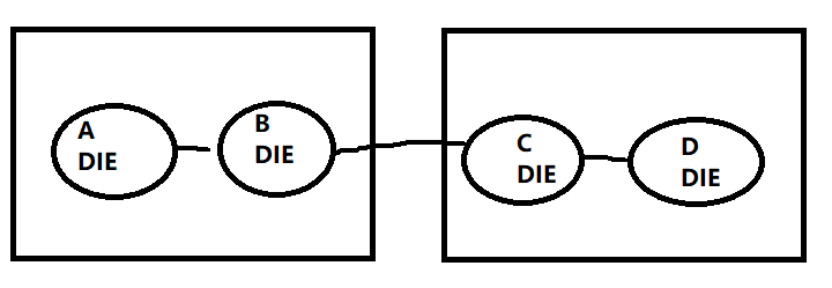
因此,从A到D,是一个3-hops的情况。这个与Intel Cascade Lake的Platinum 9200系列相似封装下,形成了较大的不同。
4.NUMA复杂度对软件的影响
4.1 搬砖的困扰
对于一个典型的UMA系统而言,任务跑在哪个CPU都一样,调度问题要简单地多。而对于一个NUMA系统而言,任务跑在不同的NUMA的CPU上,访问内存和I/O的延迟都会不一样,另外,带宽、cache同步时延等因子也会不同。所以在一个NUMA系统里面,任务就不能那边"任性"。
我们把NUMA的跳数想象成一个从你和你老婆,到你爸妈,再到你兄弟姐妹,再到你堂兄堂姐妹的系统。自己到老婆是0hop(在同一个NUMA,当然家里的小娃、狗狗也属于同一个NUMA,可以参与搬砖),到自己的爹妈是1hop,到兄弟姐妹是2hops,到堂兄弟姐妹是3hops,当然,你还可以有各种表亲,4hops,5hops什么的。

假设你现在要解决一个问题,比如一个典型的workload,这个workload就是往你家里搬10000块砖。当然,你的爹妈,你的兄弟姐妹,你的堂兄堂弟,你的远方亲戚,他们也同样有自己的0hop夫妻,1hop爹妈,2hops兄弟姐妹,这些人接到了同样的workload,就是往自己家里搬10000块砖。
正常的人类肯定是各自往各自家里搬砖,你爹妈往你爹妈家里搬,你往你家里搬,你哥和你嫂往你哥家里搬砖,各家的狗狗往各自家里搬砖。但是Linux的调度器并没有那么智能,它对任务的亲和度是缺乏足够的感知的。比如,实际结果可能是:你往你表弟家里搬,你姐往你家里搬,你老婆当然也可能往你家里搬,你家的狗狗可能往表弟家里搬砖,它整个分配是基于负载均衡和轻微意识的任务亲和,所以最终的结果是搬砖混战:
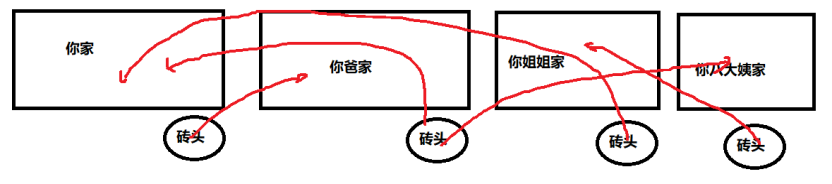
4.2 Linux搬砖混战
Linux是这么搬砖的:
假设现在启动一个workload要往自己家里搬10000块砖,我需要8个人来搬。对应代码逻辑:
perl
main(){ fork(); fork(); fork(); while(1);}Linux搬砖情况如下(4个NUMA都有人在往你家里搬砖):
这个时候,你跳出来问,Linux为什么这么蠢,从那么远的位置搬砖呢?因为Linux更多的是考虑负载均衡,而负载均衡在很多情况下都是正确的。比如我们把workload变成:总共要搬10000块砖(而不是往你家里搬),各自往最近的家里搬,总共达到10000块砖就算完成。那么,分布在各个家里搬,可能就比你一家八口全部出动往自己家里搬要快。原因很简单,你家里就一个大门(总线、带宽),大家搬砖的时候容易在门这里卡着;4家人各自往自己家里搬砖,就不会出现大门这里卡住的现象。
所以砖头往哪里搬,会直接影响到怎么排布任务的问题。而Linux的调度器傻就傻在,它其实不能知道砖头的去向问题(这个是workload本身的问题),所以它只能一根筋地采用最大化带宽、最大化资源的方法来布局。于是,这个识别workload具体特征的事情,应该是由用户自己来解决,比如我们的workload是往你家里搬1万块砖,我们就可以执行:
numactl -N 0 ./往我家里搬砖
如果目标是总体搬砖要快,我们就可以:
numactl --physcpubind=0,4,24,28,48,52,72,76 ./往各自家里搬砖
CPU 0,4; 24,28;48,52;72,76分别是NUMA0-NUMA3里面的有代表性的CPU。
当然,"往各自家里搬砖",我们也可以什么numactl都不做,最终搬砖速度会比numactl -N 0绑定到NUMA0搬砖要快。
这个时候可以看出,NUMA的复杂度越高,这个系统会变地越难控制。
我们先假设一个极限简单的case,就是你们家四世同堂,老人小孩住在一个四合院,然后所有人都一个NUMA。软件根本就没有那么多烦恼了,反正你随便搬砖,都是往自己家里搬。连numactl都根本不需要了。
我们再看一个极限复杂的case,就是你,你爸妈,你兄弟姐妹,你七大姑八大姨,你本家,你本家的姑姑的儿子的老婆的弟弟.....各自构成一个由近及远的NUMA,然后大家一起搬砖。由于每个人都以劳动为乐,你七大姑看到你搬砖这个痛苦,所以她开始把自家门前的砖往你家里搬;然后,你七大姑的儿子家,也起了个workload要搬砖了,你八大姨比较闲,于是跑去给七大姑的儿子搬砖,你七大姑父看你八大姨已经出动给自己儿子搬了,于是他把砖往你哥家里搬。反正,最后是一场混战。而且,搬砖的过程是一个动态的,这些人的立场都可能来回摇摆,因为Linux的调度器是一个分布式算法,没有任何一个CPU掌控全局。所以,可能一会儿是你爸在给你搬,一会是你姑在给你搬,所有的CPU和所有的任务都可能在来回摇摆。总之,Linux的调度器,在一个复杂的NUMA面前,基本是一个玩具。我们这个时候100%要借助numactl来搞了,对不起,用户面对这么多层次各异的亲戚,实际上也是懵逼的。所以,它大概率还是只能控制一些直系亲属,比如你爹妈,你兄弟姐妹;再远的亲戚一起考虑的话,也可能变成多个numactl再一起打群架,这个多个workload的numactl协商工作造成了极大的困扰。
那么,我们把问题再简化一下,就是一个1hop的NUMA系统,要么就是距离最近的自己,要么就是距离相对来说较远的亲属。这个时候,软件面对的问题要简单很多,就是只找自家人搬砖,还是也需要找亲属家的人搬砖。它如果找到了亲属家来搬砖,找谁家搬砖都是搬砖,谁家有闲人就找谁家,效果完全一样。所有的亲属平等地成为一个对称可用的资源库,这也是一种化零为整。这对于软件最终的运行性能,会呈现为很好的一致性,也使得问题的调试和定位更加轻松。
4.3 简化NUMA直径的好处
根据前面搬砖的故事可以得出,简化NUMA复杂度,可降低软件进行CPU、memory、I/O affinity处理的复杂度。假设192个core,只有2个NUMA(1hop)的话,每个NUMA有96个core,本身是非常丰富的本地资源,应付很多的workload都绰绰有余;再者,出现跨NUMA的情况的时候,由于NUMA的层次较低,即便完全不做NUMA控制,软件也不至于陷入层次复杂NUMA情况下的混战格局。
对于NUMA内外,都可以化零为整。比如,NUMA内部化零为整,就可以带来CPU等资源去碎片化的典型好处。一个典型场景是,当采用openstack等部署虚机的时候,常常采用虚机不跨NUMA的部署策略。所以在kunpeng920上,我们使能了DIE交织,将一个package,作为一个NUMA使用,这样在同样数量CPU的情况下,可以部署更多的虚机。但是,DIE交织增大了内存访问的延迟。因此,虚机能够直接不跨DIE的话,性能可以提升4%+。
参考文献:
1 AMD Optimizes EPYC Memory with NUMA
++https://www.amd.com/system/files/2018-03/AMD-Optimizes-EPYC-Memory-With-NUMA.pdf++
2 Intel® 64 and IA-32 Architectures Optimization Reference Manual
++https://software.intel.com/content/www/us/en/develop/download/intel-64-and-ia-32-architectures-optimization-reference-manual.html++
3 Advanced Micro DevicesHigh Performance Computing: Tuning Guide for AMD EPYC™ 7002 Series Processors
++https://developer.amd.com/wp-content/resources/56827-1-0.pdf++
4 Intel® Xeon® Processor Scalable Family Technical Overview
++https://software.intel.com/content/www/us/en/develop/articles/intel-xeon-processor-scalable-family-technical-overview.html++
5 IBM Power9 Features and Specifications
++https://www.slideshare.net/insideHPC/ibm-power9-features-and-specifications++