大模型时代已经到来,作为前端同学如何在业务中切入模型的调用,我认为组件库是一个非常好的着手点。接下来就跟着我一起来完成一个基于Langchain的AI助手吧。
1.效果展示
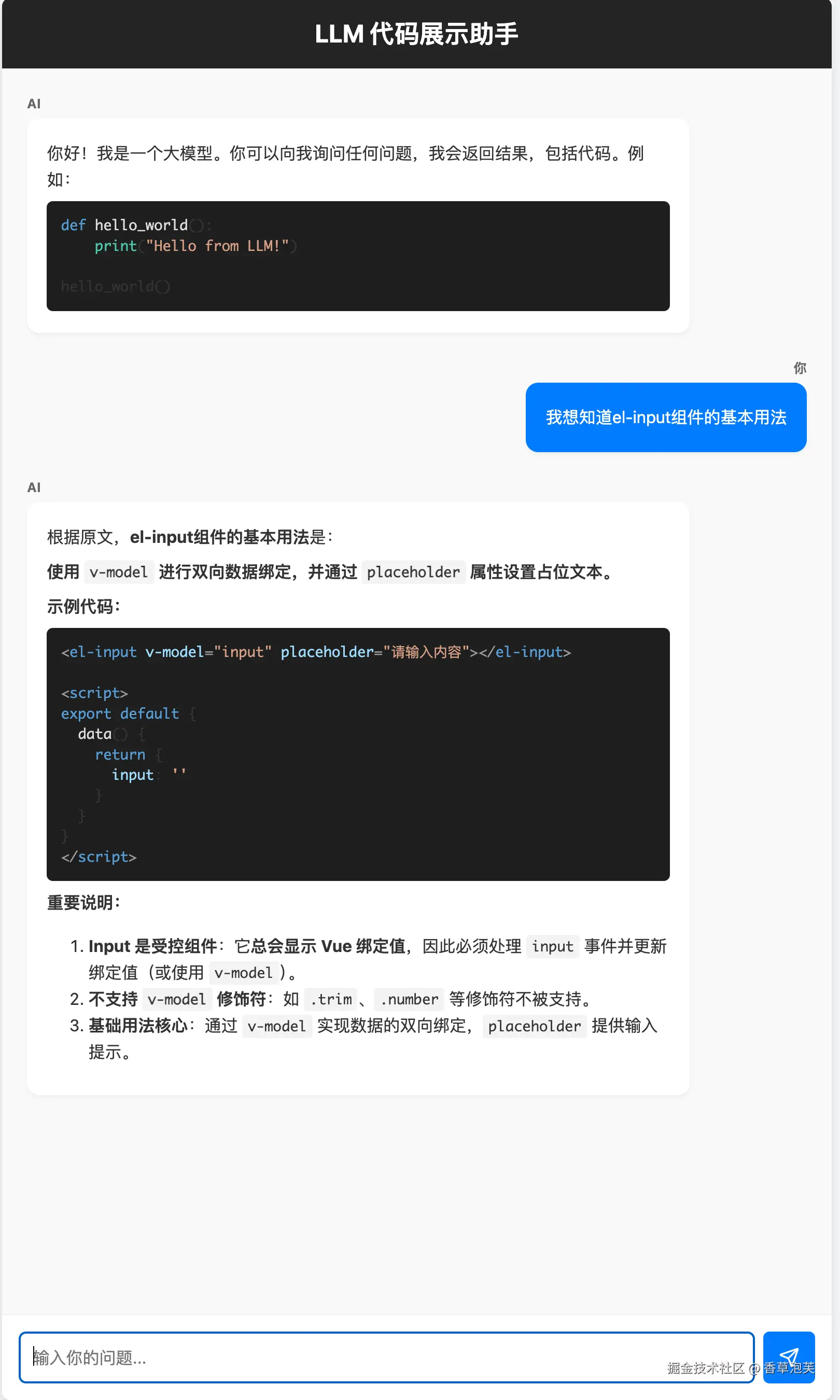 最终效果就是通过自然语言询问AI助手某个组件属性和用法,这比通过查文档快得多,当然也可以直接接入到MCP中,在代码中直接使用AI助手来完成代码补全。
最终效果就是通过自然语言询问AI助手某个组件属性和用法,这比通过查文档快得多,当然也可以直接接入到MCP中,在代码中直接使用AI助手来完成代码补全。
2.流程设计
先大体展示一下助手的整个流程设计
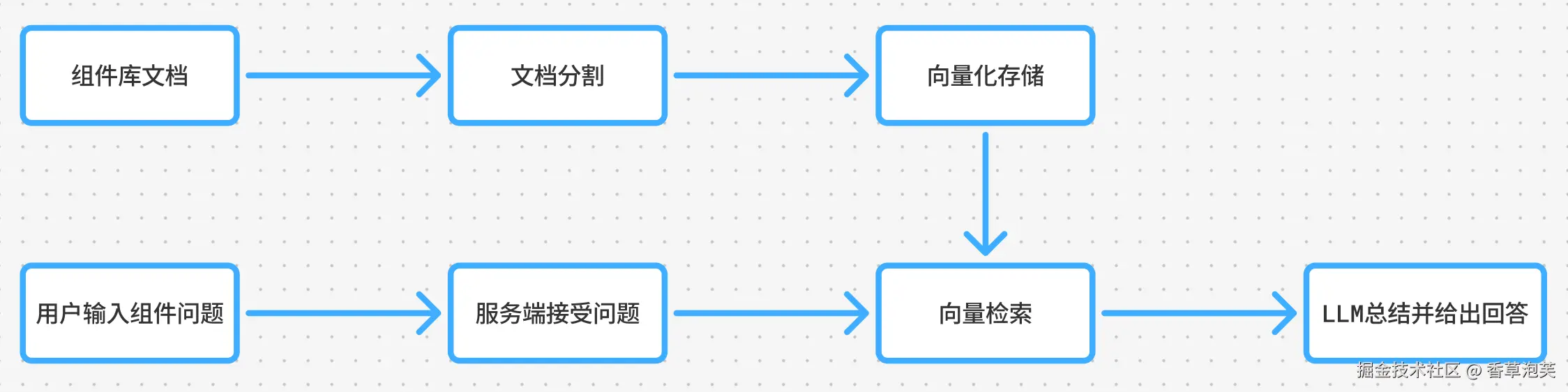
上面有两条工作流,第一条是向量存储的过程,首先需要组件库的文档说明示例,再将文档读取转化为字符串,接着使用Langchain框架自带的RecursiveCharacterTextSplitter进行片段分割,最后使用embedding进行向量化存储。
第二条工作流为Nodejs服务+Langchain框架+LLM模型共同工作给出回答,首先服务端接受用户输入的问题,然后根据用户提问在向量存储库中进行RAG检索,最终结合LLM大模型给出答案。
3.准备工作
首先实现第一条工作流中的第一步,创建一个服务端项目,这里我使用的是Express框架。项目目录如下:

别担心我们会一步一步实现所有代码。
3.1.服务器搭建
在app目录下创建index.js文件
js
import express from 'express';
import fs from 'fs';
import path from 'path';
const app = express();
const port = process.env.PORT || 3000;
// 解析 JSON 请求体
app.use(express.json());
// 跨域设置
app.use((req, res, next) => {
res.header('Access-Control-Allow-Origin', '*');
res.header('Access-Control-Allow-Methods', 'GET, POST, PUT, DELETE, OPTIONS');
res.header('Access-Control-Allow-Headers', 'Content-Type, Authorization');
if (req.method === 'OPTIONS') {
return res.sendStatus(200);
}
next();
});
// API 路由
const apiRouter = express.Router();
// 聊天接口
apiRouter.post('/chat', async (req, res) => {
const { question } = req.body;
if (!question) {
return res.status(400).json({ error: 'Question is required' });
}
try {
// 获取请求体
res.json({ content: '请求成功' });
} catch (error) {
console.error('Error during chat:', error);
res.status(500).json({ error: 'Internal server error' });
}
});
// 使用/api路由前缀
app.use('/api', apiRouter);
// 启动服务器
app.listen(port, () => {
console.log(`Server is running on port ${port}`);
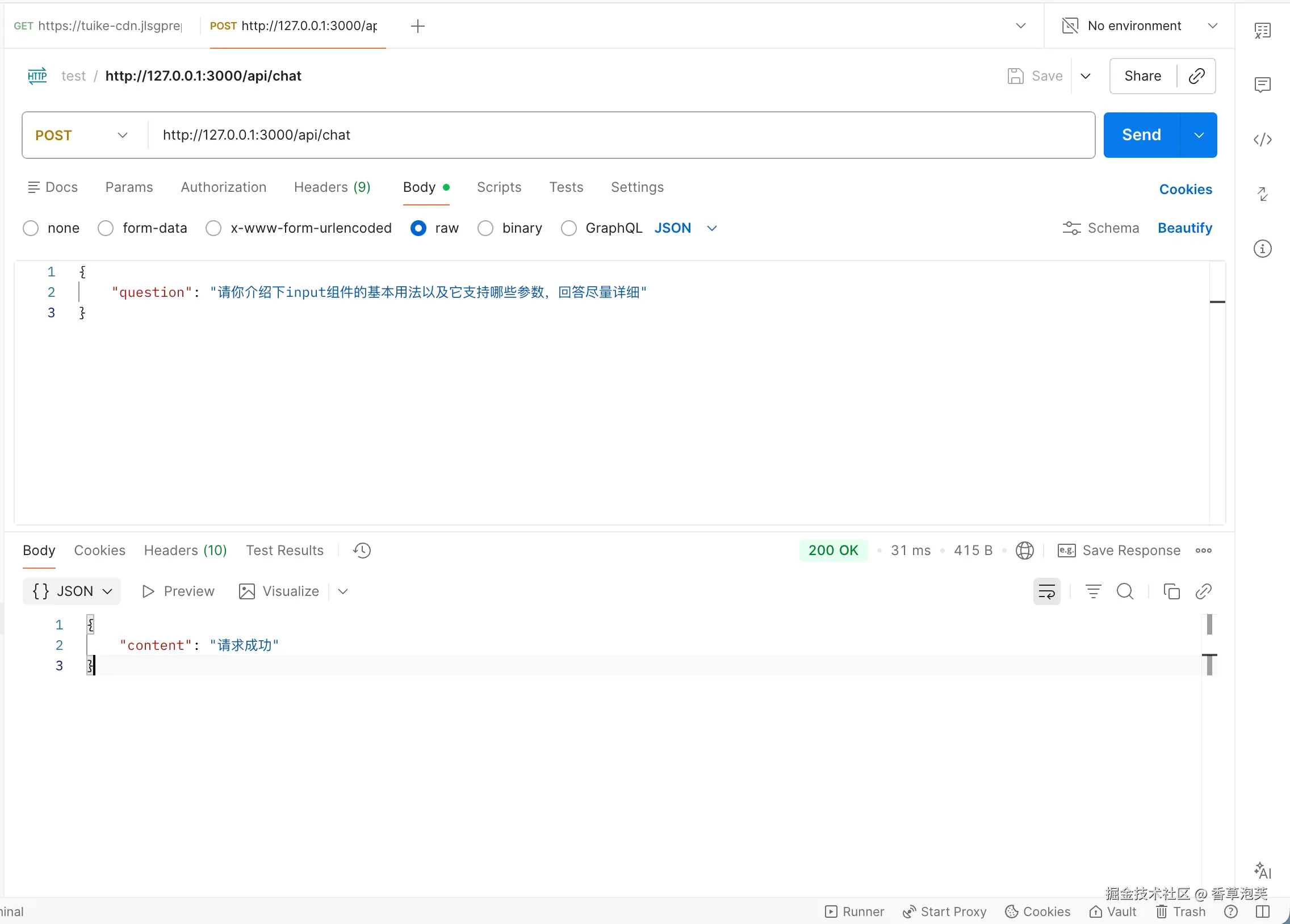
});这里只是简单的通过了Express创建了一个服务,并且创建了一个/chat接口,用于接收前端返回的用户提问。使用postman调用试试:
3.2.创建智能体
在agent目录下创建index.js文件。这里我们先使用Langchain实现一个简单的智能体,在开始之前我们先安装一下依赖:
bash
# 安装 LangChain 核心库、OpenAI 集成包和 dotenv (用于管理环境变量)
npm install langchain @langchain/core @langchain/openai dotenv接着需要去deepseek官网申请一下apikey,这里简单演示一下:
1.第一步:选择API开放平台
2.第二步:注册完成后进行充值
3.第三步:生成apikey
4.第四步:在项目根目录创建.env并写入DEEPSEEK_API_KEY=你申请的apikey

在完成以上步骤后,在新创建的index.js文件中,写入如下代码:
js
import dotenv from 'dotenv';
import { ChatOpenAI } from "@langchain/openai";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { StringOutputParser } from "@langchain/core/output_parsers";
// 读取env中的环境变量存入process.env中
dotenv.config();
// 1. 初始化模型
const model = new ChatOpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
model: 'deepseek-chat',
configuration: {
baseURL: 'https://api.deepseek.com',
},
});
// 2. 创建提示词模板
const promptTemplate = ChatPromptTemplate.fromMessages([
["system", "你是一个专业的翻译助手。请将用户输入的语言翻译成 {target_language}。"],
["human", "{text}"],
]);
// 3. 创建输出解析器
const outputParser = new StringOutputParser();
// 4. 组装链
export const chain = promptTemplate.pipe(model).pipe(outputParser);以上实现的是一个翻译助手的Agent,将原语言翻译为目标语言。实现过程是通过pipe方法组合模型、提示词和输出解释器 为chain,最终导出给外部使用。如果不太懂这几个方法的作用,可以先去Langchain文档中查阅对应的说明。
接着在app目录index.js中新增调用chain的代码:
js
import { chain } from '../agent/index.js';
//...省略一些代码
apiRouter.post('/chat', async (req, res) => {
const { question } = req.body;
if (!question) {
return res.status(400).json({ error: 'Question is required' });
}
try {
// 新增代码
const result = await chain.invoke({
target_language: question.target_language,
text: question.text,
});
res.json({ content: result });
} catch (error) {
console.error('Error during chat:', error);
res.status(500).json({ error: 'Internal server error' });
}
});这里新增了接收target_language和text,chain会自动传递给ChatPromptTemplate作为参数。这里贴出调用参数:
js
// 参数:
{
"question": {
"target_language": "法语",
"text": "你好,今天天气怎么样?"
}
}然后我们使用postman调用试试看: 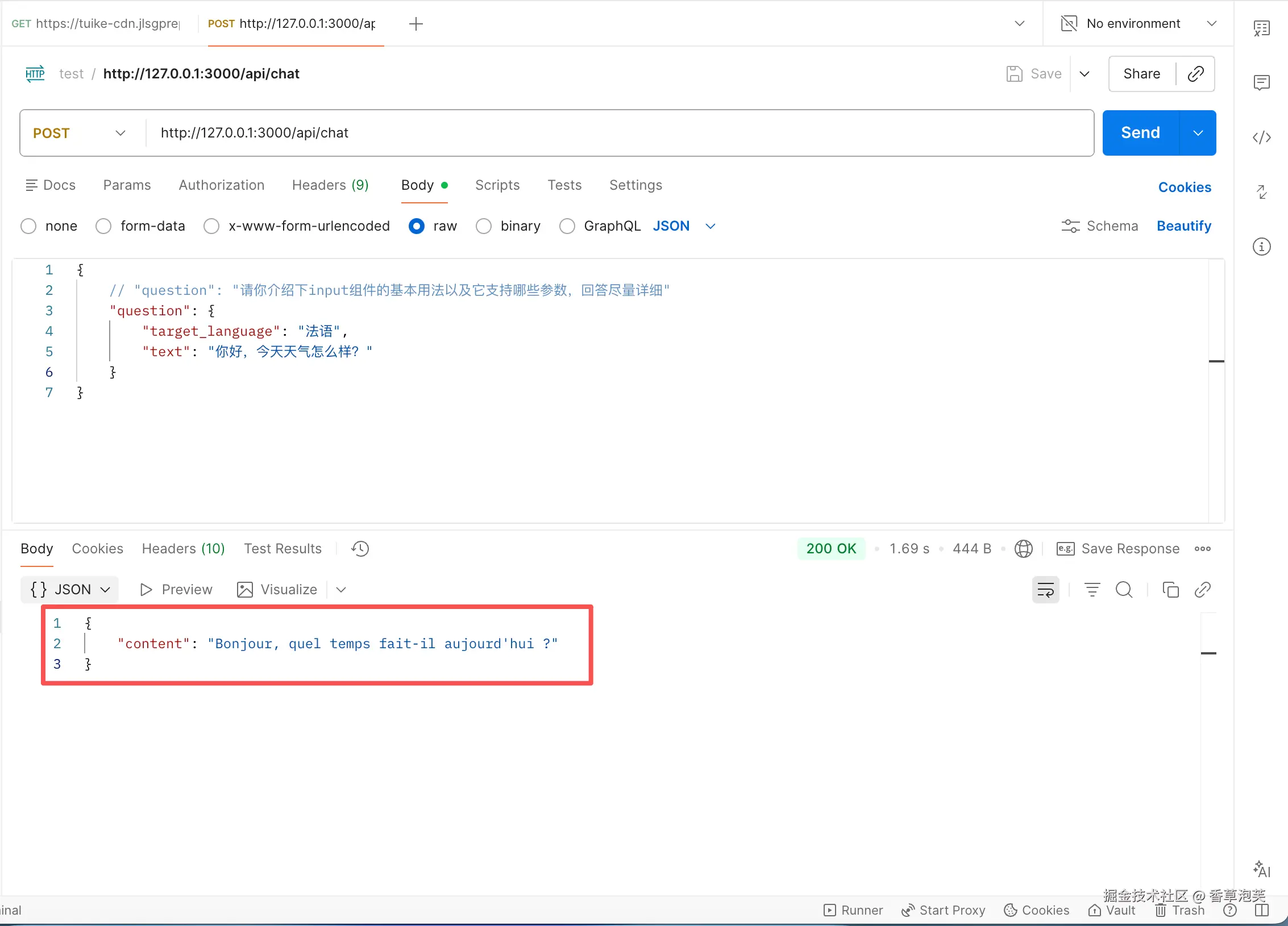
成功输出了大模型给出的结果,将中文翻译为法语。
3.RAG
接下来正式进入到第一个工作流的搭建过程,目的是给大语言模型提供组件库的上下文信息。
首先我们需要有组件库的说明文档,我使用了element-ui的button组件和input组件,并且做了将el前缀替换为fl前缀的操作,因为想和elment-ui官网做个区别。这里给出替换后的文件地址:github.com/boyzzy1995/...
然后开始文档的切片操作。
3.1.切片
这里首先提出一个问题,为什么要做切片,直接使用完整的文档不可以吗?这里先不做回答,先看切片怎么做。
3.1.1.创建文本分割器
在agent目录的index.js文件中新增saveVectorStore方法:
js
import { RecursiveCharacterTextSplitter } from '@langchain/textsplitters';
async function saveVectorStore() {
// 读取docs目录下的所有md文件内容
const docsContents = readFromMDFiles('docs');
// 创建分词器
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500, // 每个文本块的最大字符数
chunkOverlap: 20, // 相邻块之间的重叠字符数
});
}第三行代码为读取docs目录下的md文件,并转为字符串格式,这个方法不做过多介绍。重点在RecursiveCharacterTextSplitter这是Langchain框架提供的递归字符文本分割器。
简单说明一下两个参数:
-
chunkSize
- 含义 :每个文本片段最多包含 500 个字符
- 目的 :
- 控制输入 LLM 的文本长度,避免超出上下文窗口
- 让检索更精准(小块比大块更容易匹配)
- 减少无关信息干扰,提高回答质量
-
chunkOverlap
- 含义 :相邻两个文本块之间有 20 个字符的重叠
- 目的 :
- 保持上下文连贯性,避免在边界处丢失语义
- 防止关键信息被切分到两个不连续的块中
- 提高检索召回率(重叠部分会在多个块中出现)
工作原理(递归分割过程):RecursiveCharacterTextSplitter 使用多级分隔符列表,按优先级逐步分割:
text
默认分隔符顺序(从大到小):
1. "\n\n" → 段落级别
2. "\n" → 句子级别
3. " " → 单词级别
4. "" → 字符级别(最后手段)假设有 1000 字符的文档,使用 chunkSize=500, chunkOverlap=20:
lua
原文:|------------------------------------------1000 字符------------------------------------------|
分割后:
|---- Chunk 1 (0-500) ----|
|---- Chunk 2 (480-980) ----|
|---- Chunk 3 (960-1000) ----|
重叠区域: [20 字符] [20 字符]重叠的作用:
- Chunk 1 末尾 和 Chunk 2 开头 有 20 字符相同
- 即使关键词恰好在边界,也能在两个块中都找到
这里的chunkSize=500和overlap=20并不是固定的,需要根据当前的使用环境来决定,可以进行适当的调整来确定检索的正确率。
3.1.2.分割文档
接着用分割器进行文档分割:
js
import { Document } from "@langchain/core/documents";
// 保存向量库
async function saveVectorStore() {
// 读取docs目录下的所有md文件内容
const docsContents = readFromMDFiles('docs');
// 创建分词器
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 20,
});
// 将所有文档内容合并后进行分割, 并生成向量
const allText = docsContents.join('\n\n');
const docs = [new Document({ pageContent: allText })];
const splitDocs = await splitter.splitDocuments(docs);
}这里新增了三行代码。
第一行是将多个组件文档通过\n\n特殊换行符进行连接,上文的RecursiveCharacterTextSplitter会识别特殊分隔符进行分割切片。
第二行通过Document对象进行包装,Document对象可以理解成Langchain对所有类型的数据的一个统一抽象,其中包含
pageContent文本内容,即文档对象对应的文本数据metadata元数据,文本数据对应的元数据,例如 原始文档的标题、页数等信息,可以用于后面Retriver基于此进行筛选。
第三行通过splitter分割器对文档进行分割,打印一下结果看一下:
js
console.log(splitDocs[0]);取数组下标0看一下第一个Document对象:
js
{
pageContent: '## Button 按钮\n' +
'常用的操作按钮。\n' +
'\n' +
'### 基础用法\n' +
'\n' +
'基础的按钮用法。\n' +
'\n' +
':::demo 使用`type`、`plain`、`round`和`circle`属性来定义 Button 的样式。\n' +
'\n' +
'```html\n' +
'<fl-row>\n' +
' <fl-button>默认按钮</fl-button>\n' +
' <fl-button type="primary">主要按钮</fl-button>\n' +
' <fl-button type="success">成功按钮</fl-button>\n' +
' <fl-button type="info">信息按钮</fl-button>\n' +
' <fl-button type="warning">警告按钮</fl-button>\n' +
' <fl-button type="danger">危险按钮</fl-button>\n' +
'</fl-row>',
metadata: { loc: { lines: { from: 1, to: 18 } } },
}可以看到pageContent已经分割完成了,并且metadata标识了段落在文档中开始行和结束行。
再来看下标为1的Document对象:
js
console.log(splitDocs[1]);输出结果为:
js
{
pageContent: '<fl-row>\n' +
' <fl-button plain>朴素按钮</fl-button>\n' +
' <fl-button type="primary" plain>主要按钮</fl-button>\n' +
' <fl-button type="success" plain>成功按钮</fl-button>\n' +
' <fl-button type="info" plain>信息按钮</fl-button>\n' +
' <fl-button type="warning" plain>警告按钮</fl-button>\n' +
' <fl-button type="danger" plain>危险按钮</fl-button>\n' +
'</fl-row>',
metadata: { loc: { lines: { from: 20, to: 28 } },
}嗯?不是说设置了chunkOverlap会有重叠部分吗,怎么没有呢?
原因分析: 从文档和输出结果来看:
- 文档0长度380,文档1长度305 - 两个文档都远小于
chunkSize: 500 - 分割点 :
RecursiveCharacterTextSplitter会优先按语义边界 (如段落\n\n、代码块等)分割
button.md 的内容,它包含多个 ::: 包裹的代码块(demo 块),RecursiveCharacterTextSplitter 会在这些语义边界处分割,而不是强制按字符数切割。
关键点:
chunkOverlap只在强制切割(当文本超过 chunkSize 时)才会生效- 当文本按语义边界分割后,如果每个块都小于
chunkSize,就不会触发重叠逻辑
所以要看到重叠效果只要调小chunkSize即可。例如我这里将chunkSize改为100,效果如下:
js
Document {
pageContent: '## Button 按钮\n常用的操作按钮。\n\n### 基础用法\n\n基础的按钮用法。',
metadata: { loc: { lines: [Object] } },
}
Document {
pageContent: '### 基础用法\n' +
'\n' +
'基础的按钮用法。\n' +
'\n' +
':::demo 使用`type`、`plain`、`round`和`circle`属性来定义 Button 的样式。',
metadata: { loc: { lines: [Object] } },
}可以看到前后两个Document对象中的pageContent出现了重叠部分。至此切片部分就已经完成了。
3.2.向量化(embedding)
向量化工程需要借助模型的embedding能力。
3.2.1 embedding处理
Langchain中的核心embedding方式有两种:
- 第三方大模型 Embedding(最常用):这是实际开发中使用最多的类型,对接主流 AI 厂商的嵌入接口,需要 API Key,优点是效果好、开箱即用。
- OpenAI Embeddings :
OpenAIEmbeddings(包括 GPT-3.5/4 系列的 text-embedding-ada-002 等) - Anthropic Embeddings :
AnthropicEmbeddings(Claude 系列的嵌入模型) - Google Vertex AI Embeddings :
VertexAIEmbeddings(Google PaLM/CGemini 嵌入) - Cohere Embeddings :
CohereEmbeddings(专注文本嵌入的专用模型) - Azure OpenAI Embeddings :
AzureOpenAIEmbeddings(微软 Azure 部署的 OpenAI 嵌入) - 百度 / 阿里 / 腾讯国内厂商 :如
BaiduWenxinEmbeddings(文心一言嵌入)、ZhipuAIEmbeddings(智谱清言)等(需安装 langchain-community 扩展)
- OpenAI Embeddings :
代码示例:
js
import { OpenAIEmbeddings } from "@langchain/openai";
// 初始化嵌入模型(需配置 OPENAI_API_KEY 环境变量)
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small", // 可选:text-embedding-ada-002、text-embedding-3-large
apiKey: process.env.OPENAI_API_KEY,
batchSize: 512, // 批量处理文本的大小
});
// 生成文本嵌入
async function getEmbedding() {
const text = "黄金投资的核心逻辑是美元和实际利率";
const embedding = await embeddings.embedQuery(text); // 单文本嵌入(查询用)
// const embeddingsList = await embeddings.embedDocuments([text1, text2]); // 多文本嵌入(文档用)
console.log("嵌入向量长度:", embedding.length); // text-embedding-3-small 输出 1536
}
getEmbedding();- 本地运行的 Embedding(无 API 依赖):无需联网、无调用成本,适合隐私敏感或离线场景,缺点是需要本地部署模型,效果略逊于云端模型。
- Hugging Face 本地模型 :
HuggingFaceTransformersEmbeddings(需安装 @xenova/transformers) - Sentence Transformers :基于
HuggingFaceEmbeddings封装的轻量版 - LLaMA/Alpaca 本地嵌入:需结合本地大模型框架(如 llama.cpp)
代码示例(本地 HuggingFace Embedding):
js
import { HuggingFaceTransformersEmbeddings } from "@langchain/community/embeddings/hf_transformers";
// 初始化本地嵌入模型(自动下载轻量模型,首次运行需联网)
const embeddings = new HuggingFaceTransformersEmbeddings({
model: "Xenova/all-MiniLM-L6-v2", // 轻量开源嵌入模型,适合本地运行
modelName: "Xenova/all-MiniLM-L6-v2",
cacheDirectory: "./models", // 模型缓存目录,避免重复下载
});
// 生成本地嵌入
async function getLocalEmbedding() {
const text = "黄金不涨的核心原因是美元走强和降息预期推迟";
const embedding = await embeddings.embedQuery(text);
console.log("本地嵌入向量长度:", embedding.length); // all-MiniLM-L6-v2 输出 384
}
getLocalEmbedding();这里我们只是为了教学,就使用ollama方式本地使用一个小模型。
- 首先下载ollama
 2. 在ollama界面中输入直接下载即可
2. 在ollama界面中输入直接下载即可qllama/bge-m3:latest
这样本地就部署了一个用于embedding的小模型,然后我们进入编码阶段。
在agent/index.js文件中新增如下代码:
js
import { OllamaEmbeddings } from '@langchain/ollama';
// embedding 初始化
const embeddings = new OllamaEmbeddings({
model: 'qllama/bge-m3:latest',
baseUrl: 'http://localhost:11434',
});
// 保存向量库
async function saveVectorStore() {
// 读取docs目录下的所有md文件内容
const docsContents = readFromMDFiles('docs');
// 创建分词器
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500, // 每个文本块的最大字符数
chunkOverlap: 20, // 相邻块之间的重叠字符数
});
// 将所有文档内容合并后进行分割, 并生成向量
const allText = docsContents.join('\n\n');
const docs = [new Document({ pageContent: allText })];
const splitDocs = await splitter.splitDocuments(docs);
const vector = await embeddings.embedDocuments(splitDocs.map(doc => doc.pageContent));
}这段代码新增了embedding初始化模型使用qllama/bge-m3:latest,并且baseUrl指定http://localhost:11434为本地ollama运行模型的地址。
最后一行使用embedDocuments对文档片段进行向量化。
js
console.log(vector[0]);log看看向量化后的是什么东西
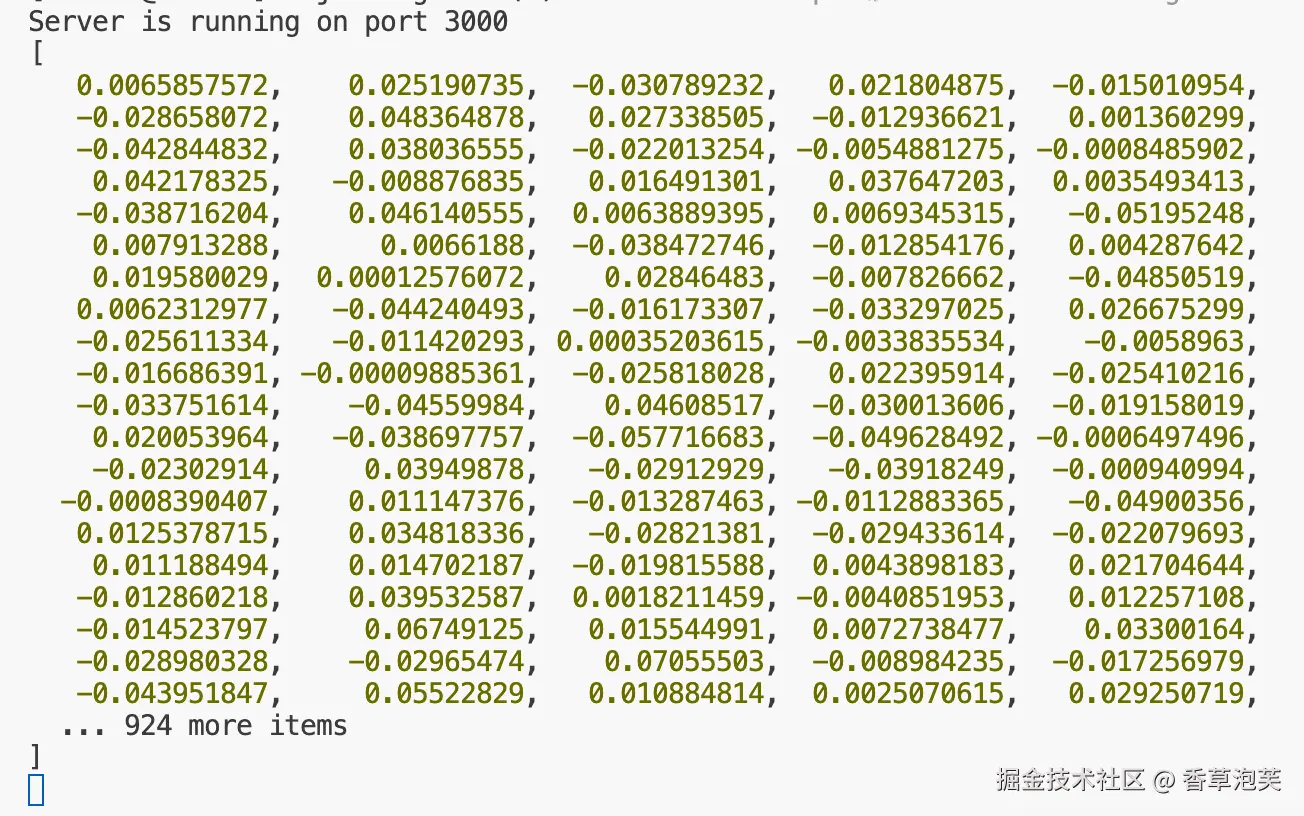
可以看到是一串number类型的数组,有正有负。那么这些数字有什么含义呢?也就是向量的含义。
这是一个 1024 维的向量(显示 100 个,还有 924 个),每个数字代表文本在一个高维空间中的坐标位置。
简单说:把文字变成了计算机能理解的数字坐标。原来计算机不懂我们所说文字的含义,但是通过转成向量,可以通过进行数学计算,比如计算距离(余弦相似度)来判断文字含义的相似度。如果不使用向量,只能通过文字匹配来进行检索。准确度会远不如向量检索。
至此已经完成了文档向量化。
3.2.1.为什么要做切片
现在可以回答这个问题了,但我们换个问题,如果不做切片会怎么样?
假设直接把整个 button.md + button.md(可能几万字)一起向量化:
js
// 反面教材:不切分的后果
const allText = "Button 组件文档内容... Input 组件文档内容..."; // 5000+ 字符
const vector = await embeddings.embedQuery(allText); // 得到一个向量问题1:检索精度极差
用户问: "Button 组件怎么设置禁用状态?"
没有切片时:
- 向量库中只有 1 个大向量(包含 Button + Input 所有内容)
- 检索返回的是这个"大杂烩"向量
- 结果:找回整篇文档,混杂大量无关信息(Input 用法、其他组件等)
有切片后:
- 向量库中有 N 个精准向量(每个都是独立知识点)
- 检索直接定位到 "Button 禁用属性" 相关的那一小块
- 结果:精确返回相关内容,无干扰信息
问题 2:LLM 上下文窗口限制
即使检索到了,LLM 也处理不了:
js
// 假设检索到 10 个未切片的大文档
const context = doc1 + doc2 + ... + doc10; // 可能 50,000+ 字符
// 传给 LLM 时:
const prompt = SYSTEM_TEMPLATE + context + question;
// ❌ 超出模型 token 限制(如 GPT-4 默认 8K/128K)切片的好处:
js
// 只返回 Top 10 最相关的切片(每块 500 字符)
const context = chunk1 + chunk5 + chunk8 + ...; // 约 5000 字符
// ✅ 精炼且完整,不会超出限制总结:切片带来的核心优势
| 维度 | 不切片 | 切片后 |
|---|---|---|
| 检索精度 | 粗粒度,返回大量无关内容 | 细粒度,精准定位知识点 |
| 向量质量 | 语义模糊,多个主题混合 | 语义清晰,单一主题 |
| LLM 效率 | 容易超出 token 限制 | 精炼上下文,节省 token |
| 回答质量 | 混杂无关信息,易混淆 | 聚焦相关内容,准确清晰 |
| 系统性能 | 单次处理大文本,慢 | 并行处理小块,快 |
| 可维护性 | 全量更新成本高 | 支持增量更新 |
3.1.3.存储向量
接下来需要对向量进行持久化,因为如果文档数量过多,每次运行都需要进行embedding会非常耗时。所以这里我们使用facebook开源的faiss-node进行本地化存储。
安装依赖
bash
npm install @langchain/community faiss-node --save@langchain/community1.1.8以上已经自带了faiss,可以简化部分操作。
js
import { FaissStore } from '@langchain/community/vectorstores/faiss';
// 保存向量库
async function saveVectorStore() {
// 读取docs目录下的所有md文件内容
const docsContents = readFromMDFiles('docs');
// 创建分词器
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500, // 每个文本块的最大字符数
chunkOverlap: 20, // 相邻块之间的重叠字符数
});
// 将所有文档内容合并后进行分割, 并生成向量
const allText = docsContents.join('\n\n');
const docs = [new Document({ pageContent: allText })];
const splitDocs = await splitter.splitDocuments(docs);
// const vector = await embeddings.embedDocuments(splitDocs.map(doc => doc.pageContent));
// 使用FaissStore保存向量库
const vectorStore = await FaissStore.fromDocuments(splitDocs, embeddings);
// 保存向量库
await vectorStore.save(path.join(process.cwd(), './db'));
}最后两行新增代码,使用FaissStore.fromDocuments内置方法来向量化文档。然后保存到db文件夹目录中。

如果运行成功,将会在工作目录里创建db和db目录里的两个文件。
faiss.index - 向量索引文件
- 格式:二进制文件(FAISS 原生格式)
- 作用 :存储文档的向量数据 和索引结构
- 内容:高维向量 + 用于快速相似度搜索的索引结构(如 IVF、HNSW 等)
- 特点:只能被 FAISS 库读取,人类无法直接阅读
docstore.json - 文档存储文件
- 格式:JSON 文件
- 作用 :存储原始文档内容(pageContent 和 metadata)
- 内容:每个文档的 ID、文本内容、元数据(如来源行号等)
- 特点:人类可读,可以看到分割后的文本片段
搜索流程:
- 用户输入查询 → 转成向量
- faiss.index → 快速找到最相似的向量(返回文档ID)
- docstore.json → 根据ID获取原始文本内容
- 返回给用户
3.1.4.检索
在这一小节中,会使用问题去向量数据库中检索最相关内容进行返回。
在agent/index.js文件中新增方法getChain并将该方法导出,因为在app中会使用:
js
export async function getChain() {
// 增加一个方法判断db目录是否存在,不存在则先创建文件夹再执行保存向量库
const dbDirectory = path.join(process.cwd(), './db');
if (!fs.existsSync(dbDirectory)) {
fs.mkdirSync(dbDirectory);
await saveVectorStore();
}
// 加载向量库
const vectorStore = await FaissStore.load(path.join(process.cwd(), './db'), embeddings);
// 创建检索器
const retriever = vectorStore.asRetriever(10);
// 将检索到的文档转换为字符串
const convertDocsToString = (docs) =>
docs.map((doc) => doc.pageContent).join('\n\n');
// 创建检索chain,用于将检索到的文档转换为字符串
const contextRetrieverChain = RunnableSequence.from([
(input) => input.question,
retriever,
convertDocsToString,
]);
return contextRetrieverChain;
}这里判断db目录是否存在,不存在则执行创建向量化操作,存在则通过Faiss加载向量库。然后asRetriever(10)只加载前10个最相关的片段。再通过RunnableSequence.from创建chain,chain做的操作就是将input.question传入给retriever,由retriever去做向量检索,然后将返回的片段转化为字符串返回。
在app/index.js中引入刚刚导出的getChain:
js
import { getChain } from '../agent/index.js';
// ...省略代码
const chain = await getChain();
// API 路由
const apiRouter = express.Router();
// 聊天接口
apiRouter.post('/chat', async (req, res) => {
const { question } = req.body;
if (!question) {
return res.status(400).json({ error: 'Question is required' });
}
try {
// 获取请求体
const result = await chain.invoke({ question});
res.json({ content: result });
} catch (error) {
console.error('Error during chat:', error);
res.status(500).json({ error: 'Internal server error' });
}
});使用postman调用一下chat接口:
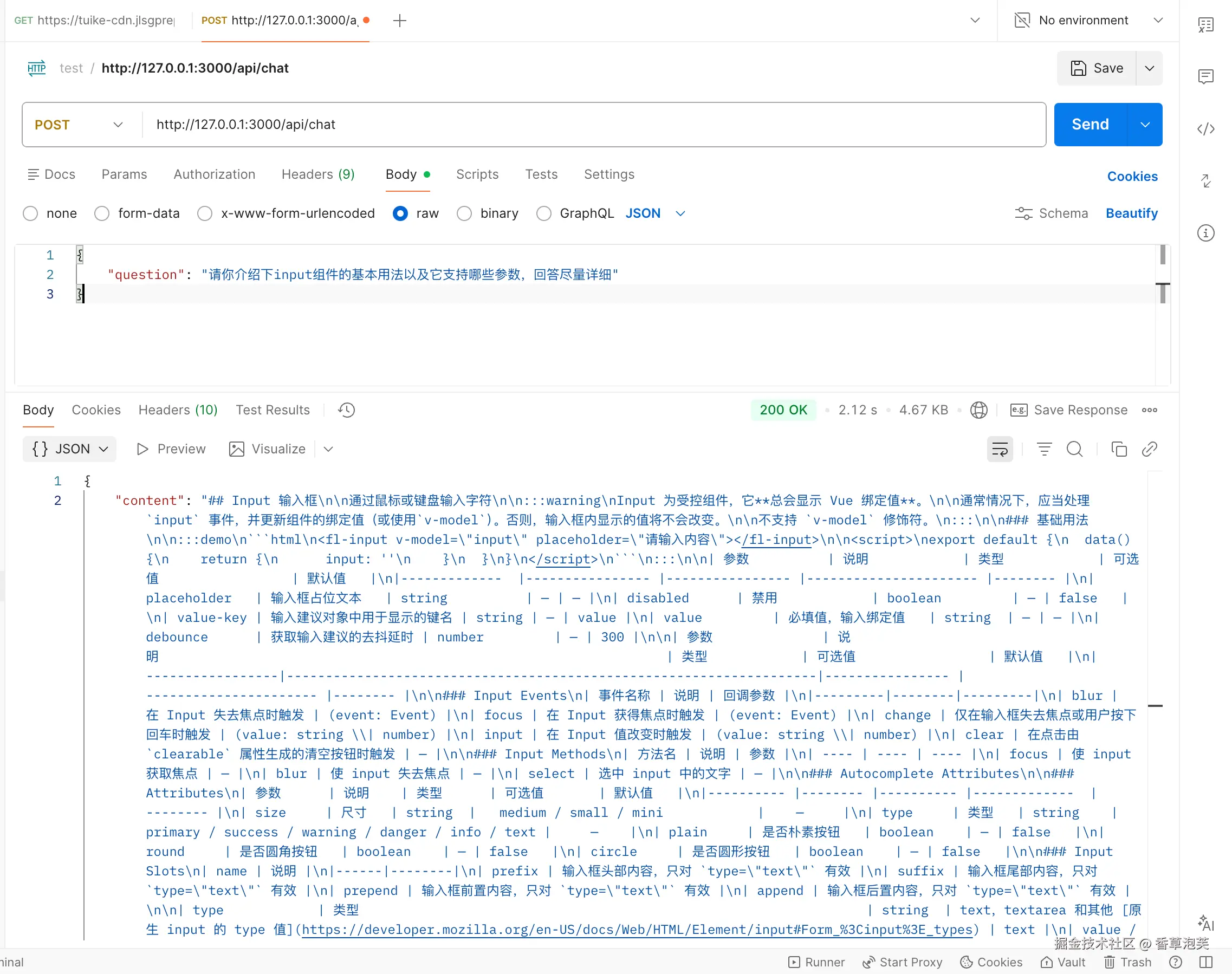
检索返回了和我们提问相关的文档片段。
3.1.5.增强生成
上面返回了检索结果,但是还有一些相关的内容,因此后面我们还需要使用LLM进行总结,也就是增强。
我们使用上面提到的DeepseekV3的模型,来创建一下model:
js
import { ChatOpenAI } from '@langchain/openai';
export async function getChain() {
// 增加一个方法判断db目录是否存在,不存在则先创建文件夹再执行保存向量库
const dbDirectory = path.join(process.cwd(), './db');
if (!fs.existsSync(dbDirectory)) {
fs.mkdirSync(dbDirectory);
await saveVectorStore();
}
// 加载向量库
const vectorStore = await FaissStore.load(path.join(process.cwd(), './db'), embeddings);
// 创建检索器
const retriever = vectorStore.asRetriever(10);
// 将检索到的文档转换为字符串
const convertDocsToString = (docs) =>
docs.map((doc) => doc.pageContent).join('\n\n');
// 创建检索chain,用于将检索到的文档转换为字符串
const contextRetrieverChain = RunnableSequence.from([
(input) => input.question,
retriever,
convertDocsToString,
]);
// 声明 LLM 变量
const model = new ChatOpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
model: 'deepseek-chat',
configuration: {
baseURL: 'https://api.deepseek.com',
},
});
}然后就需要声明我们给LLM的提示词了。提示词可以分为系统提示词和用户提示词,我们来写一下:
js
const SYSTEM_TEMPLATE = `
你是一个熟读组件库的专家,精通根据组件库的文档详细解释和回答问题,你在回答时会引用组件库的文档。
并且回答时仅根据原文,尽可能回答用户问题,如果原文中没有相关内容,你可以回答"原文中没有相关内容",
以下是原文中跟用户回答相关的内容:
{context}
`;
const prompt = ChatPromptTemplate.fromMessages([
['system', SYSTEM_TEMPLATE],
['human', '现在,你需要基于原文,回答以下问题:\n{question}`'],
]);系统提示词是基本原则,我们要让LLM根据原文进行回答,如果原文内容没有则直接回答没有,减少LLM幻觉问题。
最后再构建一个chain来整合一下完成的RAG流程:
js
const ragChain = RunnableSequence.from([
RunnablePassthrough.assign({
context: contextRetrieverChain,
}),
prompt,
model,
new StringOutputParser(),
]);
return ragChain;这里将检索chain产生的结果作为上下文,以及声明的系统提示词和用户提示词一起传递给LLM,最终将LLM产生的结果转换为JSON字符串。
我们来试试:
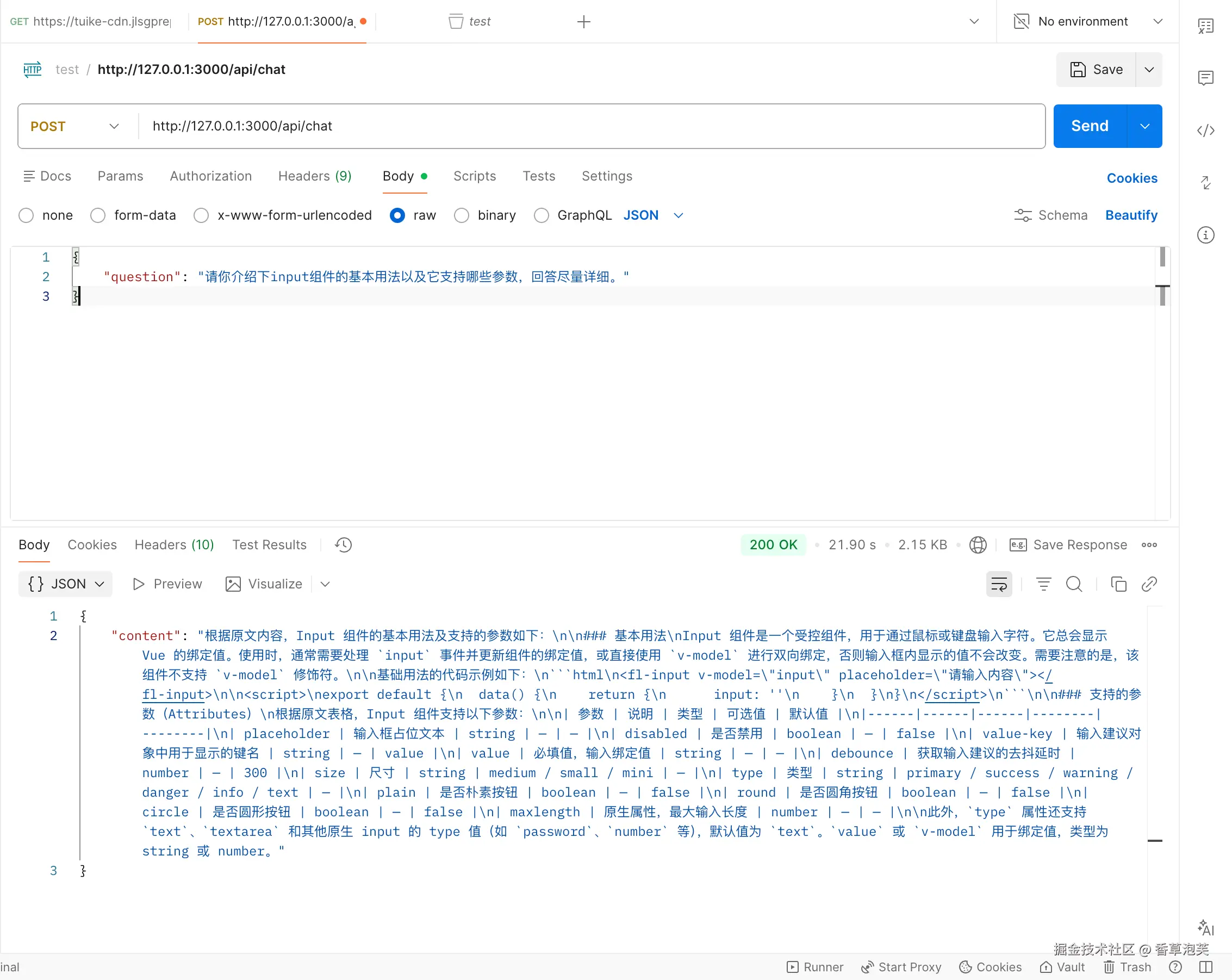
至此RAG基础的流程都已经完成了。
4.总结
本章暂时只完成基础的RAG部分,后续会继续补充记忆、搜索和前端交互界面。如果觉得写的还不错,可以点点赞收藏一下。当然写的不好的地方也可以指出,在评论区进行交流哈。